
Risk-Profile and Feature Selection Comparison in Diabetic Retinopathy


 , ,
, ,  , and
, and 
Abstract
:1. Introduction
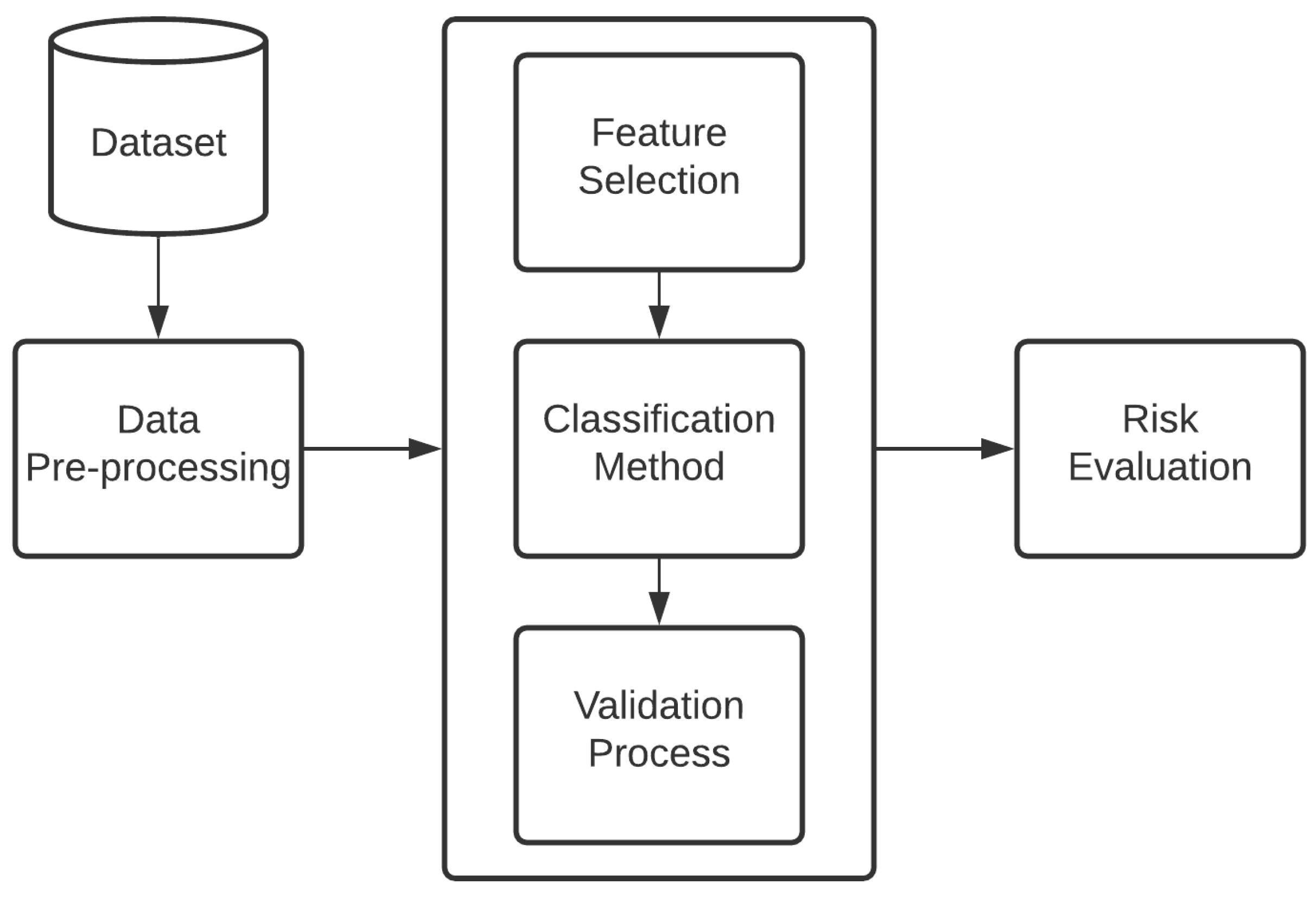
2. Materials and Methods
2.1. Data Description
2.2. Data Pre-Processing
2.3. Feature Selection
2.4. Classification Method
Random Forest
- First, the dataset having is given; the samples are randomly selected using the bootstrap method, which is used to create a new dataset .
- Next, the RF algorithm is trained to generate a DT for every sample; subsequently, the unbiased error is estimated.
- In this step, the final prediction is calculated based on the number of votes of the DT.
- Finally, the samples that have not been selected in the training process can be used in the testing process to evaluate the performance of the classifier.
2.5. Validation Process
2.6. Risk Evaluation
- RR = 1.0, indicates no difference between the two groups.
- RR < 1.0, indicates a negative association; the risk of the microvascular complication (DR) decrease when the factor risk is present.
- RR > 1.0, indicates a positive association; the risk of the microvascular complication (DR) increase when the risk factor is present.
3. Experiments and Results
- Bad test = (0.5, 0.6)
- Regular test = (0.6, 0.75)
- Good test = (0.75, 0.9)
- Very good test = (0.9, 0.97)
- Excellent test = (0.97, 1) [24]
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Diabetes Association. Diagnosis and classification of diabetes mellitus. Diabetes Care 2014, 37, S81–S90. [Google Scholar] [CrossRef] [Green Version]
- Atlas, I. International Diabetes Federation. IDF Diabetes Atlas, 9th ed.; International Diabetes Federation: Brussels, Belgium, 2019. [Google Scholar]
- Martins, R.B.; Ordaz-Briseño, S.A.; Flores-Hernández, S.; Bós, Â.J.G.; Baptista-Rosas, R.C.; Mercado-Sesma, A.R. Comparison of prevalence of diabetes complications in Brazilian and Mexican adults: A cross-sectional study. BMC Endocr. Disord. 2021, 21, 1–9. [Google Scholar] [CrossRef]
- Ogunyemi, O.; Kermah, D. Machine learning approaches for detecting diabetic retinopathy from clinical and public health records. AMIA Annu. Symp. Proc. 2015, 2015, 983. [Google Scholar]
- Quezada, A.; Pedroza-Tobías, A.; Hernández-Alcaraz, C.; Fromow-Guerra, J.; Barquera, S. A Diabetic Retinopathy Screening Tool for Low-Income Adults in Mexico. Elimin. Health Disparities 2017, 14, 1. [Google Scholar]
- Prado-Serrano, A.; Guido-Jiménez, M.A.; Camas-Benitez, J.T. Prevalencia de retinopatía diabética en población mexicana. Revista Mexicana de Oftalmología 2009, 83, 261–266. [Google Scholar]
- Wu, L.; Fernandez-Loaiza, P.; Sauma, J.; Hernandez-Bogantes, E.; Masis, M. Classification of diabetic retinopathy and diabetic macular edema. World J. Diabetes 2013, 4, 290. [Google Scholar] [CrossRef] [PubMed]
- Lam, C.; Yi, D.; Guo, M.; Lindsey, T. Automated detection of diabetic retinopathy using deep learning. AMIA Summits Transl. Sci. Proc. 2018, 2018, 147. [Google Scholar]
- Mansour, R.F. Deep-learning-based automatic computer-aided diagnosis system for diabetic retinopathy. Biomed. Eng. Lett. 2018, 8, 41–57. [Google Scholar] [CrossRef] [PubMed]
- Bora, A.; Balasubramanian, S.; Babenko, B.; Virmani, S.; Venugopalan, S.; Mitani, A.; de Oliveira Marinho, G.; Cuadros, J.; Ruamviboonsuk, P.; Corrado, G.S.; et al. Predicting the risk of developing diabetic retinopathy using deep learning. Lancet Digit. Health 2021, 3, e10–e19. [Google Scholar] [CrossRef]
- Alcalá-Rmz, V.; Maeda-Gutiérrez, V.; Zanella-Calzada, L.A.; Valladares-Salgado, A.; Celaya-Padilla, J.M.; Galván-Tejada, C.E. Convolutional Neural Network for Classification of Diabetic Retinopathy Grade. In Proceedings of the Mexican International Conference on Artificial Intelligence, Mexico City, Mexico, 12–17 October 2020; Springer: Berlin, Germany, 2020; pp. 104–118. [Google Scholar]
- Semeraro, F.; Parrinello, G.; Cancarini, A.; Pasquini, L.; Zarra, E.; Cimino, A.; Cancarini, G.; Valentini, U.; Costagliola, C. Predicting the risk of diabetic retinopathy in type 2 diabetic patients. J. Diabetes Complicat. 2011, 25, 292–297. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Fitriyani, N.L.; Anshari, M.; Stasa, P.; Svub, J.; Rhee, J. Deep Neural Network for Predicting Diabetic Retinopathy from Risk Factors. Mathematics 2020, 8, 1620. [Google Scholar] [CrossRef]
- Wang, R.; Miao, Z.; Liu, T.; Liu, M.; Grdinovac, K.; Song, X.; Liang, Y.; Delen, D.; Paiva, W. Derivation and Validation of Essential Predictors and Risk Index for Early Detection of Diabetic Retinopathy Using Electronic Health Records. J. Clin. Med. 2021, 10, 1473. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hajian-Tilaki, K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Casp. J. Intern. Med. 2013, 4, 627. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2013. [Google Scholar]
- Kuhn, M. Caret: Classification and Regression Training; R Package Version 6.0-86; Astrophysics Source Code Library: Cambridge, MA, USA, 2020. [Google Scholar]
- John, C.R. MLeval: Machine Learning Model Evaluation; R package Version 0.3; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Nakazawa, M.; Nakazawa, M.M. Package ‘fmsb’. In Functions for Medical Statistics Book with Some Demographic Data; 2017; Available online: https://cran. r-project. org/web/packages/fmsb/fmsb.pdf (accessed on 1 July 2021).
- Aragon, T.J.; Fay, M.P.; Wollschlaeger, D.; Omidpanah, A.; Omidpanah, M.A. Package ‘Epitools’. 2017. Available online: http://CRAN.R-project.org/package=epitools (accessed on 1 July 2021).
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Nagarajan, S.M.; Muthukumaran, V.; Murugesan, R.; Joseph, R.B.; Meram, M.; Prathik, A. Innovative feature selection and classification model for heart disease prediction. J. Reliab. Intell. Environ. 2021, 7, 1–11. [Google Scholar] [CrossRef]
- Jain, D.; Singh, V. Feature selection and classification systems for chronic disease prediction: A review. Egypt. Inform. J. 2018, 19, 179–189. [Google Scholar] [CrossRef]
- Awada, W.; Khoshgoftaar, T.M.; Dittman, D.; Wald, R.; Napolitano, A. A review of the stability of feature selection techniques for bioinformatics data. In Proceedings of the 2012 IEEE 13th International Conference on Information Reuse & Integration (IRI), Las Vegas, NV, USA, 8–10 August 2012; pp. 356–363. [Google Scholar]
- Ahmadpour, H.; Bazrafshan, O.; Rafiei-Sardooi, E.; Zamani, H.; Panagopoulos, T. Gully Erosion Susceptibility Assessment in the Kondoran Watershed Using Machine Learning Algorithms and the Boruta Feature Selection. Sustainability 2021, 13, 10110. [Google Scholar] [CrossRef]
- Iwendi, C.; Bashir, A.K.; Peshkar, A.; Sujatha, R.; Chatterjee, J.M.; Pasupuleti, S.; Mishra, R.; Pillai, S.; Jo, O. COVID-19 patient health prediction using boosted random forest algorithm. Front. Public Health 2020, 8, 357. [Google Scholar] [CrossRef]
- Priya, A.; Garg, S.; Tigga, N.P. Predicting anxiety, depression and stress in modern life using machine learning algorithms. Procedia Comput. Sci. 2020, 167, 1258–1267. [Google Scholar] [CrossRef]
- Chaurasia, V.; Pal, S. Applications of machine learning techniques to predict diagnostic breast cancer. SN Comput. Sci. 2020, 1, 1–11. [Google Scholar] [CrossRef]
- Habib, N.; Hasan, M.M.; Reza, M.M.; Rahman, M.M. Ensemble of CheXNet and VGG-19 feature extractor with random forest classifier for pediatric pneumonia detection. SN Comput. Sci. 2020, 1, 1–9. [Google Scholar] [CrossRef]
- Jenkins, A.J.; Joglekar, M.V.; Hardikar, A.A.; Keech, A.C.; O’Neal, D.N.; Januszewski, A.S. Biomarkers in diabetic retinopathy. Rev. Diabet. Stud. RDS 2015, 12, 159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, J.; Wong, T.Y. Current epidemiology of diabetic retinopathy and diabetic macular edema. Curr. Diabetes Rep. 2012, 12, 346–354. [Google Scholar] [CrossRef] [PubMed]
- Klein, R.; Klein, B.E.; Moss, S.E. Epidemiology of proliferative diabetic retinopathy. Diabetes Care 1992, 15, 1875–1891. [Google Scholar] [CrossRef] [PubMed]
- Pedro, R.A.; Ramon, S.A.; Marc, B.B.; Juan, F.B.; Isabel, M.M. Prevalence and relationship between diabetic retinopathy and nephropathy, and its risk factors in the North-East of Spain, a population-based study. Ophthalmic Epidemiol. 2010, 17, 251–265. [Google Scholar] [CrossRef]
- Liu, D.W.; Haq, Z.; Yang, D.; Stewart, J.M. Association between smoking history and optical coherence tomography angiography findings in diabetic patients without diabetic retinopathy. PLoS ONE 2021, 16, e0253928. [Google Scholar] [CrossRef]
- Klein, B.E.; Moss, S.E.; Klein, R.; Surawicz, T.S. The Wisconsin Epidemiologic Study of Diabetic Retinopathy: XIII. Relationship of serum cholesterol to retinopathy and hard exudate. Ophthalmology 1991, 98, 1261–1265. [Google Scholar] [CrossRef]
- Chang, Y.C.; Wu, W.C. Dyslipidemia and diabetic retinopathy. Rev. Diabet. Stud. RDS 2013, 10, 121. [Google Scholar] [CrossRef]
- Müller, M.; Schönfeld, C.L.; Grammer, T.; Krane, V.; Drechsler, C.; Genser, B.; Kohnen, T.; Wanner, C.; März, W. Risk factors for retinopathy in hemodialysis patients with type 2 diabetes mellitus. Sci. Rep. 2020, 10, 1–10. [Google Scholar] [CrossRef]
- Van Leiden, H.A.; Dekker, J.M.; Moll, A.C.; Nijpels, G.; Heine, R.J.; Bouter, L.M.; Stehouwer, C.D.; Polak, B.C. Blood pressure, lipids, and obesity are associated with retinopathy: The hoorn study. Diabetes Care 2002, 25, 1320–1325. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Kumari, N.; Low, S.; Ang, K.; Yeo, D.; Yeoh, L.Y.; Liu, A.; Kwan, P.Y.; Tang, W.E.; Tavintharan, S.; et al. The association of serum creatinine and estimated glomerular filtration rate variability with diabetic retinopathy in Asians with type 2 diabetes: A nested case–control study. Diabetes Vasc. Dis. Res. 2018, 15, 548–558. [Google Scholar] [CrossRef] [PubMed]
- El Haddad, O.A.; Saad, M.K. Prevalence and risk factors for diabetic retinopathy among Omani diabetics. Br. J. Ophthalmol. 1998, 82, 901–906. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raman, R.; Rani, P.K.; Gnanamoorthy, P.; Sudhir, R.; Kumaramanikavel, G.; Sharma, T. Association of obesity with diabetic retinopathy: Sankara nethralaya diabetic retinopathy epidemiology and molecular genetics study (SN-DREAMS Report no. 8). Acta Diabetol. 2010, 47, 209–215. [Google Scholar] [CrossRef]
- Klein, R.; Klein, B.E. Body fat distribution and diabetic retinopathy in people with type 2 diabetes. JAMA 2016, 315, 1778–1779. [Google Scholar] [CrossRef] [PubMed]
- Monaghan, T.F.; Rahman, S.N.; Agudelo, C.W.; Wein, A.J.; Lazar, J.M.; Everaert, K.; Dmochowski, R.R. Foundational Statistical Principles in Medical Research: A Tutorial on Odds Ratios, Relative Risk, Absolute Risk, and Number Needed to Treat. Int. J. Environ. Res. Public Health 2021, 18, 5669. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Feature Category | Feature |
|---|---|
| Basic information | EDU, SAL, SEX, AGE, AGE DX, WHR, BMI, SBP, DBP USBP, UDBP |
| Biochemical indicators | GLU, UREA, CRE, CHOL, HDL, LDL, TG, TCHOLU, UHDL, ULDL, UTG, HBA1C, GFR |
| Additional information | GB, MF, PG, RG, AB, INS, LIPIDS TX, HA-TX |
| Output | DIABETIC RETINOPATHY |
| Feature | Cases (n = 149) | Controls (n = 149) |
|---|---|---|
| Education, p-value = <2.2 × | ||
| Elementary school Secondary school Technical school High school Professional Postgraduate | 25 (16.77%) 33 (22.14%) 24 (16.10%) 30 (20.13%) 34 (22.81%) 3 (2.01) | 39 (26.17%) 32 (21.47%) 17 (11.40%) 12 (8.05%) 44 (29.53%) 5 (3.35%) |
| Salary, p-value = <2.2 × | ||
| Less than $2000.00 Between $2000.00 and $5000.00 More than $5000.00 | 35 (23.48%) 66 (44.29%) 48 (32.21%) | 37 (24.83%) 63 (42.28%) 49 (32.88%) |
| Sex, p-value = <2.2 × | ||
| Female Male | 75 (50.33%) 74 (49.66%) | 98 (65.77%) 51 (34.22%) |
| Age (years) | 57 ± 9.96 | 55 ± 9.42 |
| Age DX (years) | 44.09 ± 7.55 | 45 ± 7.06 |
| WHR (cm/cm) | 0.94 ± 0.07 | 0.91 ± 0.07 |
| BMI (kg/m2) | 29.55 ± 5.00 | 30.02 ± 5.07 |
| SBP (mmHg) | 125 ± 15.88 | 123.41 ± 14.95 |
| DBP (mmHg) | 81.93 ± 11.09 | 83.82 ± 11.11 |
| USBP (mmHg) | 122.32 ± 15.01 | 120.06 ± 13.92 |
| UDBP (mmHg) | 80.27 ± 10.65 | 82.14 ± 10.62 |
| Feature | Cases (n = 149) | Controls (n = 149) |
|---|---|---|
| Glucose (mg/dL) | 162.02 ± 70.44 | 165.51 ± 68.67 |
| Urea (mg/dL) | 38.14 ± 22.83 | 34.45 ± 16.91 |
| Creatinine (mg/dL) | 0.96 ± 0.59 | 0.84 ± 0.28 |
| Cholesterol (mg/dL) | 209.54 ± 46.38 | 219.55 ± 52.56 |
| HDL (mg/dL) | 39.24 ± 12.88 | 43.95 ± 13.34 |
| LDL (mg/dL) | 148.50 ± 39.13 | 154.86 ± 41.55 |
| Triglycerides (mg/dL) | 231.49 ± 157.77 | 214.16 ± 112.94 |
| TCHOLU (mg/dL) | 184.71 ± 40.29 | 201.58 ± 46.47 |
| UHDL (mg/dL) | 41.71 ± 12.40 | 45.64 ± 13.37 |
| ULDL (mg/dL) | 125.43 ± 33.15 | 138.04 ± 34.55 |
| UTG (mg/dL) | 208.07 ± 152.53 | 198.26 ± 111.44 |
| HBA1C (mmol/L) | 7.74 ± 3.15 | 7.47 ± 2.58 |
| GFR (mL/min) | 98.31 ± 41.27 | 101.88 ± 33.65 |
| Feature | Cases (n = 149) | Controls (n = 149) |
|---|---|---|
| Glibenclamide | ||
| 0 1 | 74 (49.66%) 75 (50.33%) | 87 (58.38%) 62 (41.61%) |
| Metformin | ||
| 0 1 | 35 (23.48%) 114 (76.51%) | 32 (21.41%) 117 (78.52%) |
| Pioglitazone | ||
| 0 1 | 147 (98.65%) 2 (1.34%) | 144 (96.64%) 5 (3.35%) |
| Rosiglitazone | ||
| 0 1 | 149 (100%) - | 149 (100%) - |
| Acarbose | ||
| 0 1 | 147 (98.65%) 2 (1.34%) | 148 (99.32%) 1 (0.67%) |
| Insuline | ||
| 0 1 | 103 (69.12%) 46 (30.87%) | 116 (77.85%) 33 (22.14%) |
| HA.TX | ||
| 0 1 | 100 (67.11%) 49 (32.88%) | 99 (66.44%) 50 (33.55%) |
| Lipids TX | ||
| 0 1 | 75 (50.33%) 74 (49.33%) | 96 (64.42%) 53 (35.57%) |
| p-Value | ||
|---|---|---|
| Features | Cases | Controls |
| Education | <2.2 × | <2.2 × |
| Salary | <2.2 × | <2.2 × |
| Sex | <2.2 × | <2.2 × |
| Age | <2.2 × | <2.2 × |
| Age DX | <2.2 × | <2.2 × |
| WHR | 4.054 × | <2.2 × |
| BMI | <2.2 × | <2.2 × |
| SBP | <2.2 × | <2.2 × |
| DBP | <2.2 × | <2.2 × |
| USBP | <2.2 × | <2.2 × |
| UDBP | <2.2 × | <2.2 × |
| Glucose | <2.2 × | <2.2 × |
| Urea | <2.2 × | <2.2 × |
| Creatinine | 0.515 | <2.2 × |
| Cholesterol | <2.2 × | <2.2 × |
| HDL | <2.2 × | <2.2 × |
| LDL | <2.2 × | <2.2 × |
| Triglycerides | <2.2 × | <2.2 × |
| TCHOLU | <2.2 × | <2.2 × |
| UHDL | <2.2 × | <2.2 × |
| ULDL | <2.2 × | <2.2 × |
| UTG | <2.2 × | <2.2 × |
| HBA1C | <2.2 × | <2.2 × |
| GFR | <2.2 × | <2.2 × |
| Glibenclamide | <2.2 × | <2.2 × |
| Metformin | 3.87 × | <2.2 × |
| Pioglitazone | <2.2 × | 0.02484 |
| Rosiglitazone | NA | NA |
| Acarbose | <2.2 × | 0.3189 |
| Insuline | <2.2 × | 1.224 × |
| HA.TX | <2.2 × | 8.107 × |
| Lipids TX | <2.2 × | 8.086 × |
| No. | Attribute | Feature Selection-Boruta |
|---|---|---|
| Norm Hits | ||
| 1 | Creatinine | 0.6355 |
| 2 | Lipids TX | 0.7054 |
| 3 | GFR | 0.7615 |
| 4 | WHR | 0.8316 |
| 5 | TCHOLU | 0.8537 |
| 6 | HDL | 0.8777 |
| Classifier | Sensitivity | Specificity | AUC |
|---|---|---|---|
| Random Forest | 0.6422 | 0.6169 | 0.69 |
| Reference | ||||
|---|---|---|---|---|
| 0 | 1 | Class. Error | ||
| Prediction | 0 | 91 | 58 | 0.3892 |
| 1 | 55 | 94 | 0.3691 | |
| Lipids Profile | Cases | Controls | Total |
|---|---|---|---|
| Lipids TX | 74 | 53 | 127 |
| GFR | 66 | 59 | 125 |
| WHR | 72 | 56 | 128 |
| TCHOLU | 45 | 69 | 114 |
| HDL | 139 | 133 | 272 |
| Creatinine | 37 | 24 | 61 |
| Total | 433 | 394 | 827 |
| Lipids Profile | Estimate | Lower | Upper |
|---|---|---|---|
| Lipids TX | 1 | NA | NA |
| GFR | 1.1310 | 0.8575 | 1.4916 |
| WHR | 1.0483 | 0.7889 | 1.3930 |
| TCHOLU | 1.4503 | 1.1257 | 1.8686 |
| HDL | 1.1716 | 0.9228 | 1.4876 |
| Creatinine | 0.9427 | 0.6490 | 1.3693 |
| Lipids Profile | Estimate | Lower | Upper |
|---|---|---|---|
| Lipids TX | 1 | NA | NA |
| GFR | 1.2466 | 0.7571 | 2.0575 |
| WHR | 1.0854 | 0.6596 | 1.7877 |
| TCHOLU | 2.1316 | 1.2759 | 3.5916 |
| HDL | 1.3342 | 0.8726 | 2.0494 |
| Creatinine | 0.9073 | 0.4815 | 1.6910 |
| Sensitivity | Specificity | AUC | |
|---|---|---|---|
| 32 features + RF | 0.5709 | 0.5634 | 0.61 |
| Boruta approach + RF | 0.6422 | 0.6169 | 0.69 |
| Classifier | Sensitivity | Specificity | AUC |
|---|---|---|---|
| RF | 0.6422 | 0.6169 | 0.69 |
| LR | 0.6714 | 0.5858 | 0.68 |
| SVM | 0.6647 | 0.5882 | 0.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maeda-Gutiérrez, V.; Galván-Tejada, C.E.; Cruz, M.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; García-Hernández, A.; Luna-García, H.; Gonzalez-Curiel, I.; Martínez-Acuña, M. Risk-Profile and Feature Selection Comparison in Diabetic Retinopathy. J. Pers. Med. 2021, 11, 1327. https://doi.org/10.3390/jpm11121327
Maeda-Gutiérrez V, Galván-Tejada CE, Cruz M, Galván-Tejada JI, Gamboa-Rosales H, García-Hernández A, Luna-García H, Gonzalez-Curiel I, Martínez-Acuña M. Risk-Profile and Feature Selection Comparison in Diabetic Retinopathy. Journal of Personalized Medicine. 2021; 11(12):1327. https://doi.org/10.3390/jpm11121327
Chicago/Turabian StyleMaeda-Gutiérrez, Valeria, Carlos E. Galván-Tejada, Miguel Cruz, Jorge I. Galván-Tejada, Hamurabi Gamboa-Rosales, Alejandra García-Hernández, Huizilopoztli Luna-García, Irma Gonzalez-Curiel, and Mónica Martínez-Acuña. 2021. "Risk-Profile and Feature Selection Comparison in Diabetic Retinopathy" Journal of Personalized Medicine 11, no. 12: 1327. https://doi.org/10.3390/jpm11121327
APA StyleMaeda-Gutiérrez, V., Galván-Tejada, C. E., Cruz, M., Galván-Tejada, J. I., Gamboa-Rosales, H., García-Hernández, A., Luna-García, H., Gonzalez-Curiel, I., & Martínez-Acuña, M. (2021). Risk-Profile and Feature Selection Comparison in Diabetic Retinopathy. Journal of Personalized Medicine, 11(12), 1327. https://doi.org/10.3390/jpm11121327