4.1. Error Analysis
As already indicated, the imperfect classification performance achieved with deep learning is mainly due to the constraints of the text modality in medicine—the data lack the multimodal and multi-format information involved in treating and diagnosing actual human beings.
Underlying this, the more fine-grained failures seem to be related to the specificity of the respective ICD-10 categories.
While I21 (acute myocardial infarction) can be expected to be easily distinguishable because of its acute nature, I48 (atrial fibrillation and flutter) presents with a very specific measurable symptom, and I35 (nonrheumatic aortic valve disorders) is explicitly localized in the aortic valve, other categories often lack this degree of specificity.
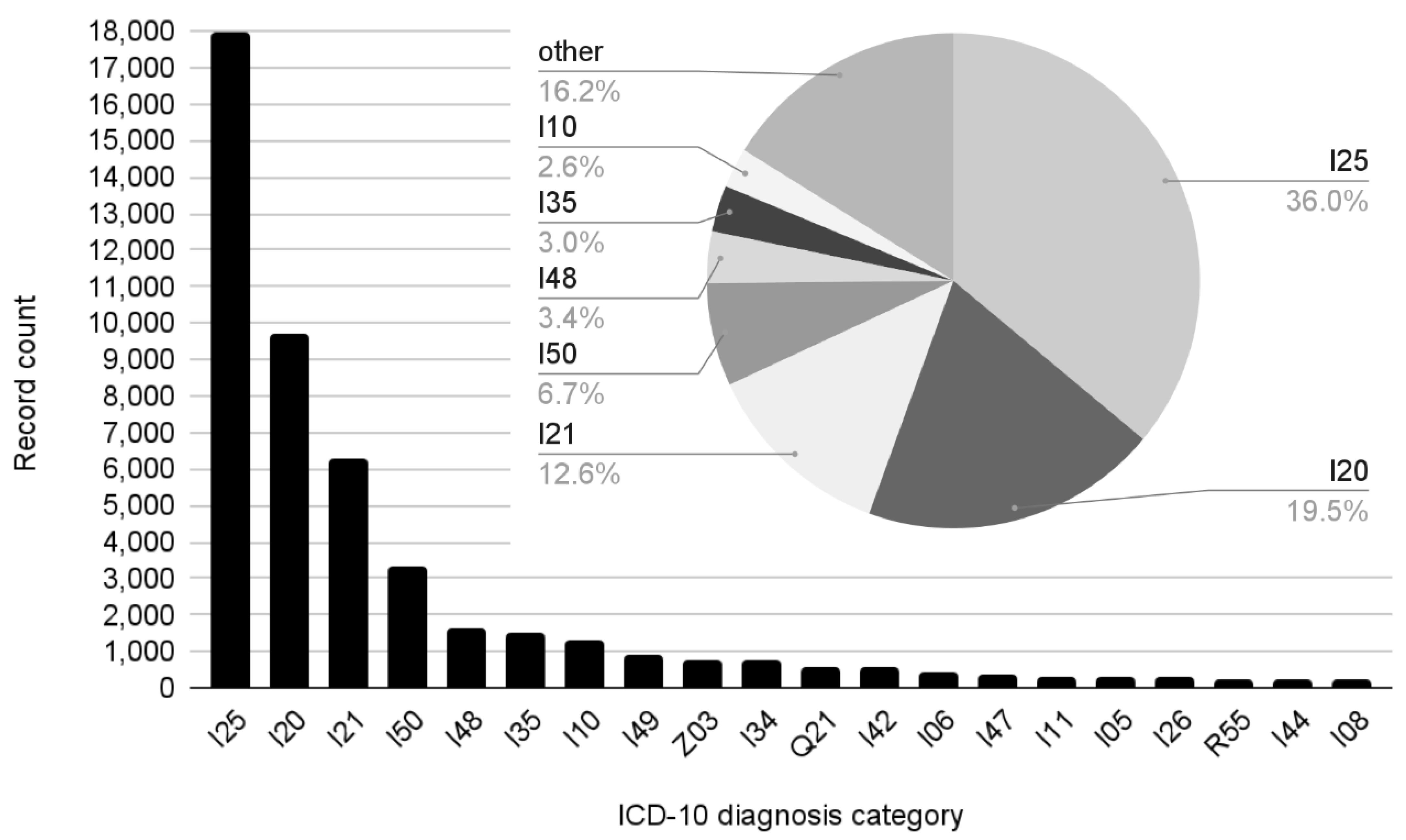
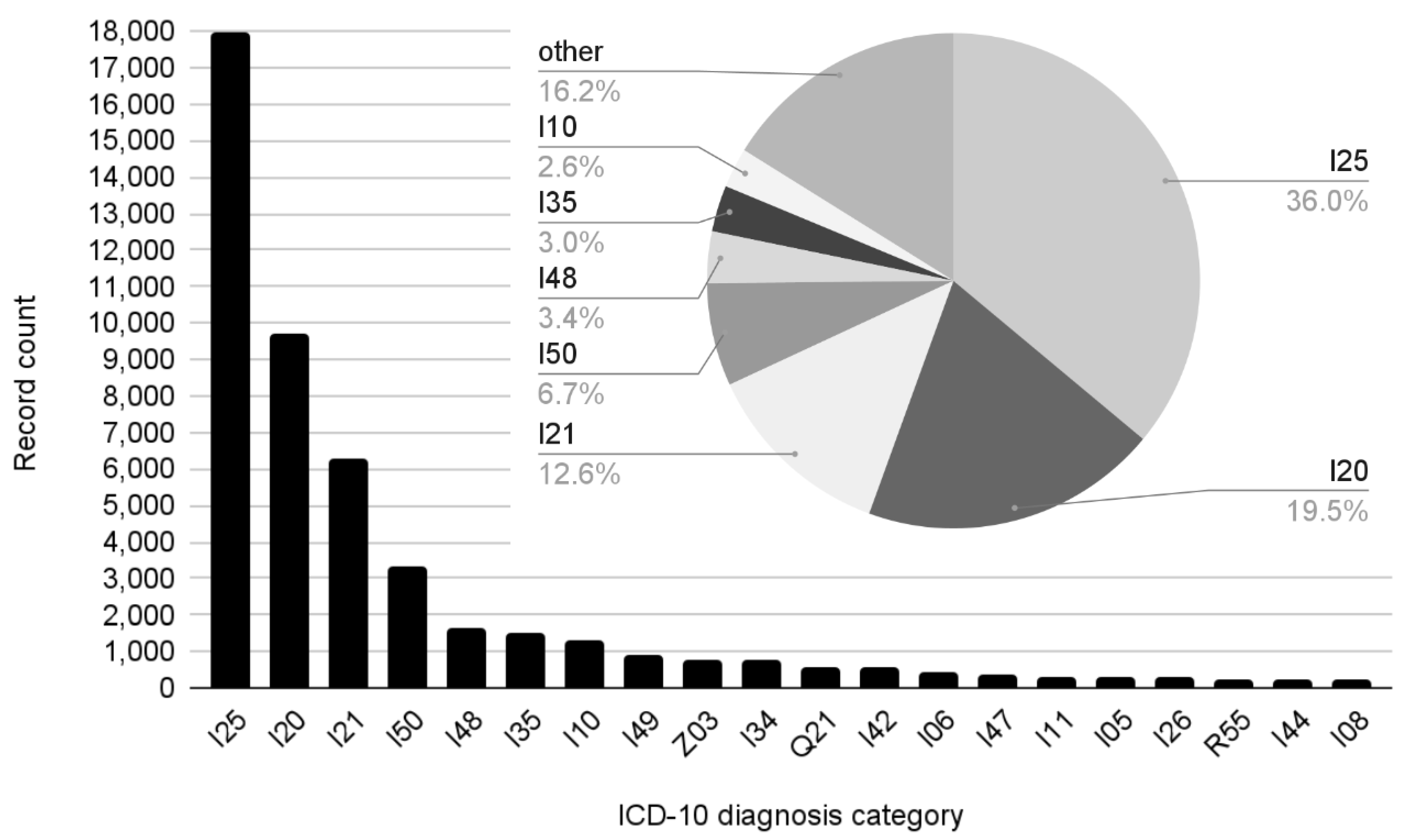
I25 (chronic IHD), by far the most populous ICD-10 category in our dataset, trailed behind other categories in terms of performance. This could have partially been due to the breadth of the category, which subsumes an unusual number of codes and conditions, but also due to its chronicity—patients suffering from chronic heart disease can be expected to be hospitalized in a variety of settings due to a variety of reasons, and the outcomes of treatment might range from finding very little to various isolated manifestations and interventions, diluting the specificity of the category for classification systems.
Similarly, I10 (essential hypertension) shares its chronic nature, various possible reasons for hospitalization, and inconclusive discharge statements with I25.
The second and fourth most frequent ICD-10 categories in our dataset, I20 (unstable angina pectoris) and I50 (heart failure)—neither as chronic nor bad-performing as I25 and I10—serve to highlight the principle that broad categories with low specificity tend to present below-average performance in classification.
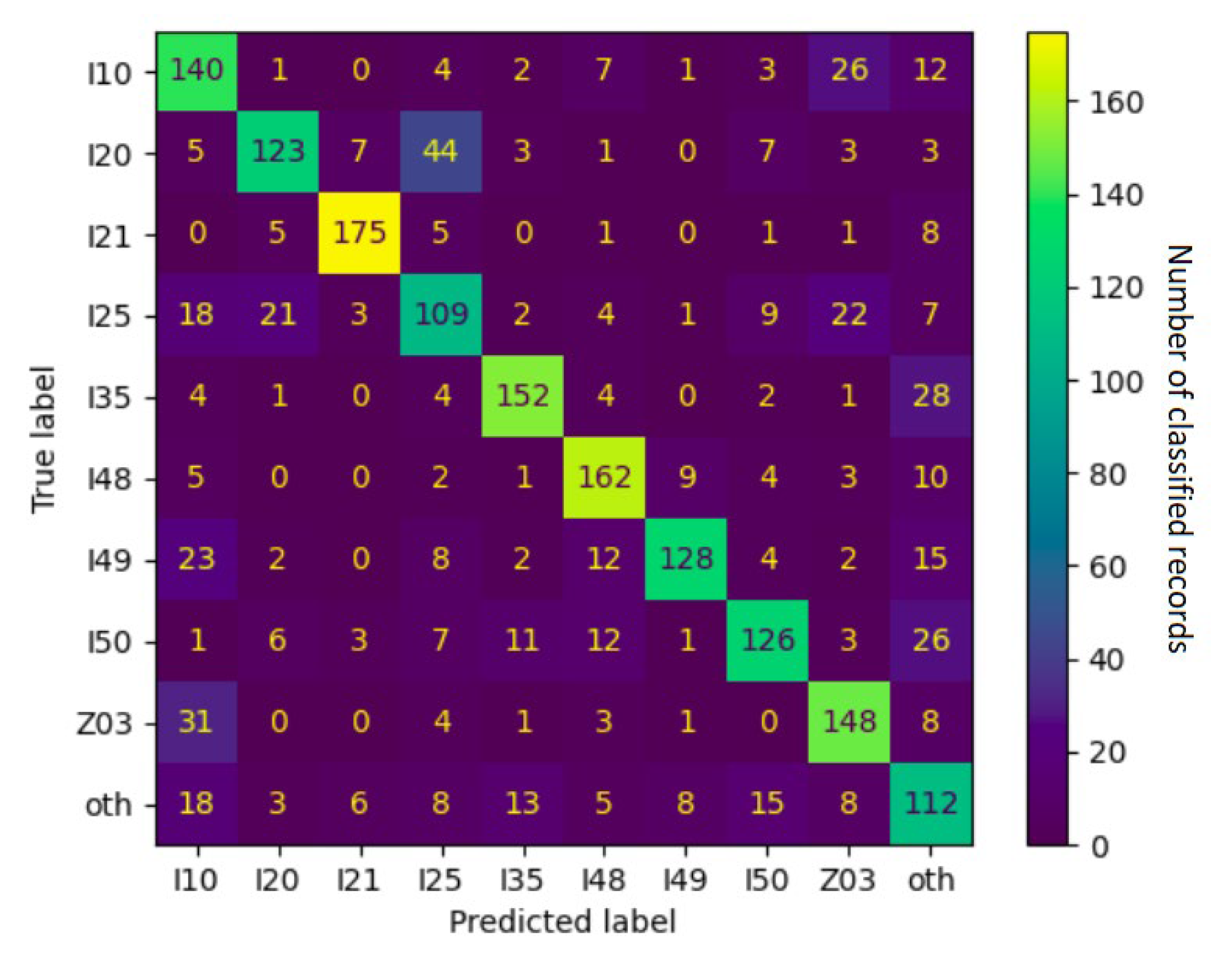
Table 6 also shows that the worst performing category of all was found to be “other”, which is a topic in its own right. This category is necessary in order to enable the classifier to issue true statements about the data. However, the designation means “any of the rest” of the total of 170 ICD-10 categories that, being rarer, are often highly specific. Plus, these smaller categories, more often than resembling each other, are marginally related to one of the larger categories. Thus, this inverted set of highly diverse training examples is difficult to learn by its very design.
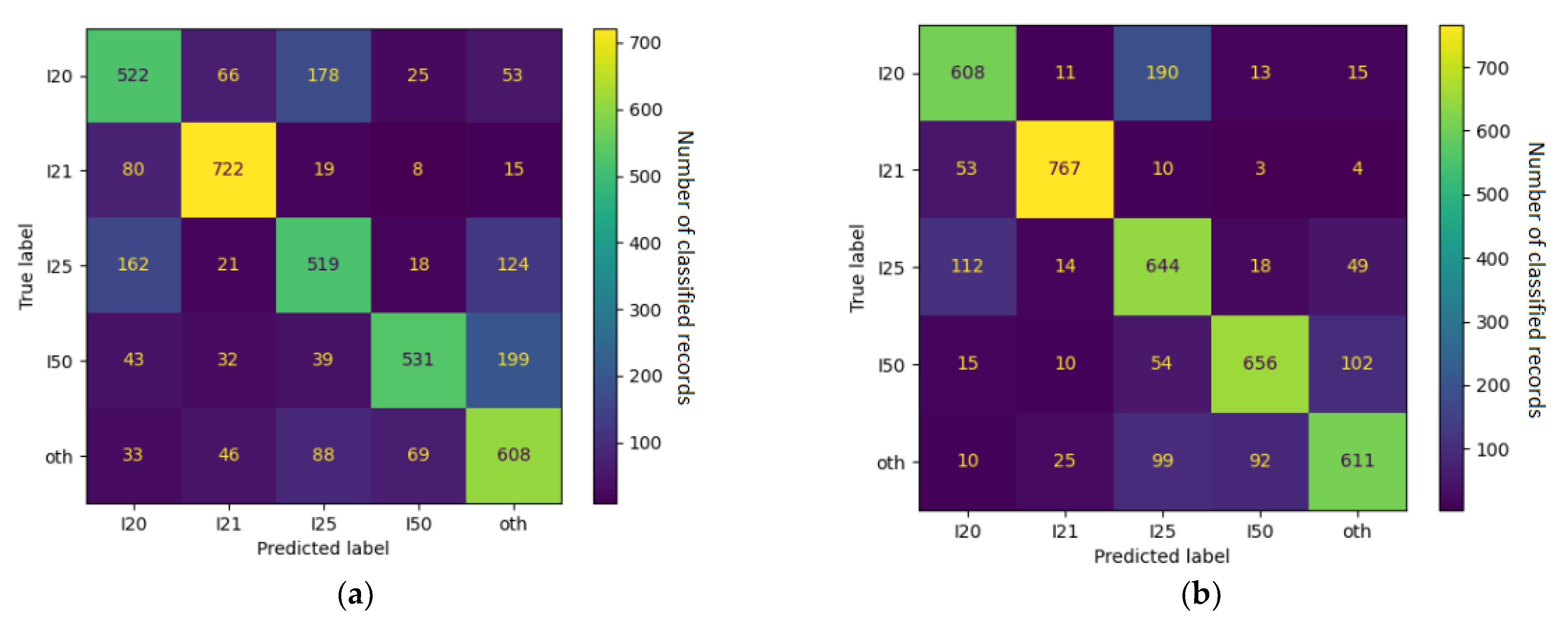
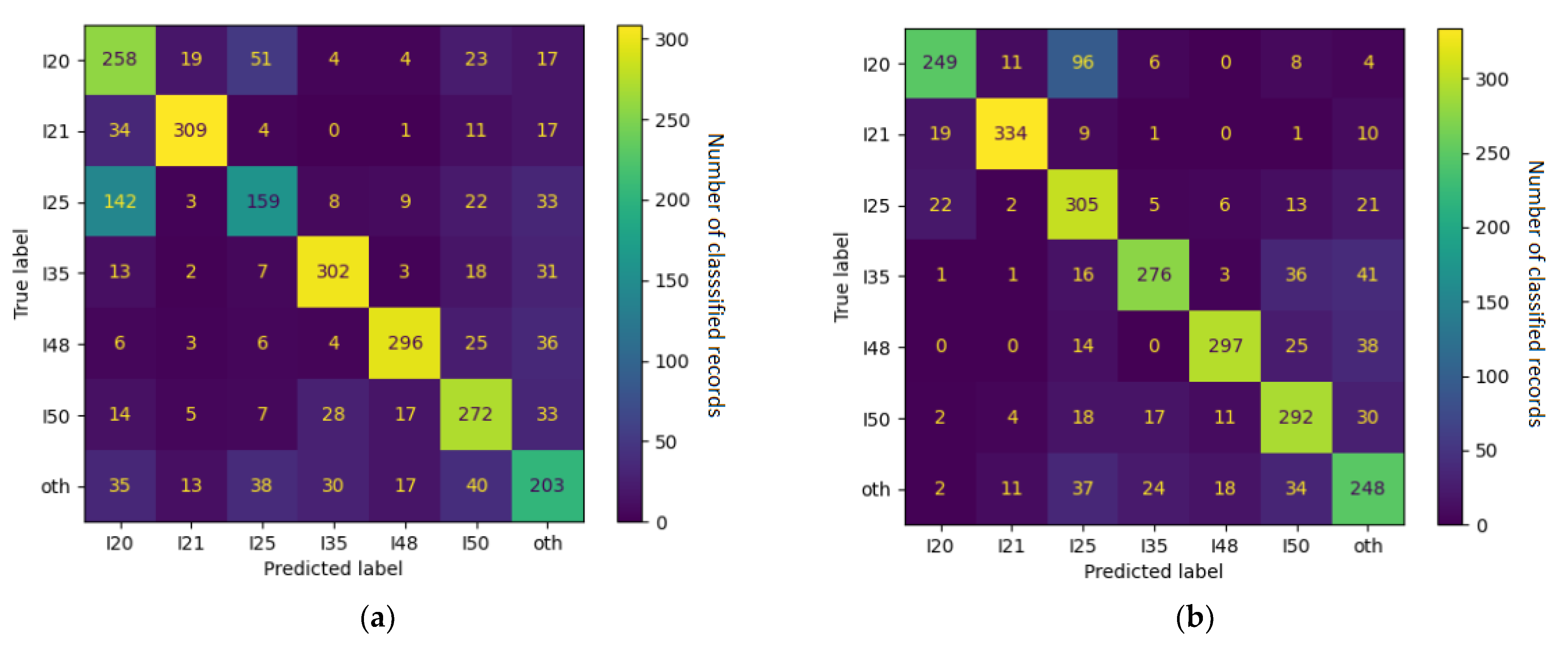
Upon the closer inspection of the confusion matrix in
Figure 8, we can see that the notoriously underperforming I25 (chronic IHD) was often misclassified as I10 (essential hypertension), I20 (unstable angina pectoris), and Z03 (suspected condition not found). These relationships were often mutual—I20 tended to be misclassified as I25 even more often and I10 was classified as Z03 just as often as the other way around. Together with the fact that they all belong to the vaguer end of the spectrum, this indicates objective reasons for the classifier’s underperformance—i.e., actual overlap in the reported symptoms and physical circumstances between the ICD-10 categories.
Some of the relations were found to be unilateral: I25 tended to be misclassified as Z03, but Z03 was rarely ever thought to be I25; I25 was often regarded as I10, but I10 was unlikely to be classified as I25. This is even more telling regarding the relationships between ICD-10 categories because it specifies exactly where the unclarity resides. In this example, border cases of I25 frequently resembled the less serious categories of I10 and Z03 but not vice versa. The real-world correlate of this might be the preventive caution exercised in cardiology, calling attention to anomalies (however small) so that no potentially dangerous condition is left unattended.
The capability of classifiers to discover such relationships, especially if applied to larger datasets, has the potential to feed back into the medical domain and help reflect on the practices of differential diagnosing, possibly even drawing attention to previously unnoticed connections.
4.2. Medical Implications
The amount of data collected on a daily basis from hospital and outpatient healthcare systems is continuously growing [
25]. In order to organize gathered medical information, the ICD classification system was adopted by healthcare institutions worldwide to assign diagnosis codes into EHR summarizing patients’ medical encounters.
In light of public health challenges, CVDs remain the leading cause of death globally [
1,
26,
27]. Among them, CADs cover a group of clinical syndromes characterized by an imbalance between myocardial blood supply and demand that results in myocardial ischemia due to atherosclerotic plaque in the coronary arteries [
28]. A broad spectrum of CAD includes chronic coronary syndromes [
29,
30] (also referred as chronic IHD or stable CAD [I25]) and acute coronary syndromes covering unstable angina pectoris (I20) and myocardial infarction (I21). As a consequence, CADs may lead to ischemic cardiomyopathy, defined as HF (I50), which is diagnosed in 1–2% of the adult population [
31,
32,
33,
34,
35]. Furthermore, atrial fibrillation, one of the most prevalent cardiac arrhythmias, is a common comorbidity in HF patients, and both diseases have seen a rising number of incidences in recent years [
36,
37]. This has subsequently translated into a high number of outpatient and inpatient visits, generating tremendous amounts of medical information collected during routine clinical care. Medical providers process and organize these data into contextual information documenting them in the EHR system as clinical notes. However, the majority of information in the electronic documentation is stored in an unstructured format, making it challenging to analyze at scale [
38,
39]. Interestingly, advancements in the field of AI and NLP have enabled the in-depth evaluation of electronic medical data for research purposes, which, in turn, has strong practical potential.
For example, AI/NLP-based systems can be used to verify potential discrepancies between EHR-derived original ICD codes manually entered by clinicians and automatically generated ICD codes. Inappropriate diagnostic codes are being reported in an increasing number of publications including cases of stroke [
40], myocardial infarction [
41], and endocarditis [
42]. Tremendous discrepancies were also reported in the ambulatory care in documenting ICD-10 codes for six standardized clinical case scenarios. Only half of provided codes were appropriately annotated by clinicians, while approximately a quarter of ICD-10 codes were missing [
43]. Furthermore, a study on barriers affecting coding quality reported variability in the documents used for coding, increases in errors during transcriptions from paper due to extra actors, difficulties in choosing an appropriate code, and coding delay due to lack of resources and tools for coders [
44].
From a clinical perspective, miscoding may have serious negative consequences for patients. On the other hand, the analyses of high quality EHR-derived data may provide predictive models showing clinical trajectories for specific patient cohorts, as well as phenotype subsets of diseases [
41,
45,
46,
47,
48]. In a broader perspective, beyond automatic coding, the NLP-based approach has allowed for the building of predictive models [
49] and the phenomapping analyses of individuals with myocardial infarction [
50] and heart failure, which reflects heterogeneous clinical syndrome [
51,
52,
53]. Novel classification may help to define specific therapeutic strategies in this challenging group of HF patients [
54]. Moreover, multi-modal algorithms searching for myocardial infarction-related keywords, ICD codes, and information on percutaneous coronary intervention procedures in discharge summaries have increased the positive predictive value of detecting the ST-segment elevation myocardial infarction type in EHRs [
55].
Importantly, erroneous coding impacts hospital-level quality metrics, having a broader influence on epidemiological studies that are used to build public health strategies [
56]. For example, the SILesian CARDiovascular (SILCARD) registry, built in collaboration between the Silesian Centre for Heart Diseases in Zabrze and the Regional Department of the Polish National Health Fund, was used to analyze causes of hospitalization and prognosis in CVD patients of the entire Silesian region inhabited by 4.6 million people. Specifically, data from 310 hospital departments and 1863 outpatient clinics specialized in cardiology, cardiac surgery, diabetology and vascular surgery contained information on 487,518 patients and 956,634 inpatient encounters. The primary ICD-10 and ICD-9 codes were used for statistical analysis, reporting high prevalences of HF and CADs, as well as declining trend in 1-year mortality among CVD patients [
57]. Similarly, populational trend evaluations were performed for atrial fibrillation [
58], left atrial appendage occlusion procedures [
59], transcatheter aortic valve implantation and surgical aortic valve replacement operations [
60], implantable cardioverter-defibrillators and cardiac resynchronization therapy [
61]. Furthermore, NLP technology allows for the in-depth EHR assessment of social determinants, which are non-medical factors impacting patient health outcomes [
62,
63,
64]. Leveraging this opportunity, AI systems can help to verify the correctness of the diagnoses, as well as provide valuable information on critical aspects associated with populational health.
It should be also mentioned that misclassification and inaccuracy in diagnostic codes are directly associated with the reimbursement process for healthcare institutions. For example, the down-grading of the ICD-10 code (i.e., miscoding I25 instead of I21) will categorize a CAD as chronic IHD instead of acute myocardial infarction, which has a higher billing rate. While discussing the economic perspective, it should be mentioned that the adoption costs of the novel ICD system are substantial and included the training of the users, as well as initial and long-term losses of productivity. In the U.S., it was estimated that costs of ICD-10 implementation ranged from
$425 million to
$1.15 billion, adding
$5–40 million per year in lost productivity [
65].
Another important aspect might be exemplified by the opportunity to reduce the documentation-related burden imposed on medical staff. Data from a cardiology outpatient clinic show medical providers spend approximately 50% of their time with electronic documentation and only 30% with patients [
4]. Of note, the ICD-10 coding process is time- and resource-consuming due to the complexity of coding rules (e.g., code orders, inclusion/exclusion criteria, and growing number of ICD-10 codes). It was estimated that for a professional disease coder, ICD-10 categorization may take ~0.5 h per case. Thus, an automatic AI-based system for imputing ICD-10 codes from free-text format might be implemented and synchronized with existing EHR systems to detect, red-flag, and potentially correct misclassified diagnostic codes. This could pave a way to ensure reliable clinical, administrative and reimbursement data for everyday practical applications and for research-oriented advanced downstream analysis [
3,
66].
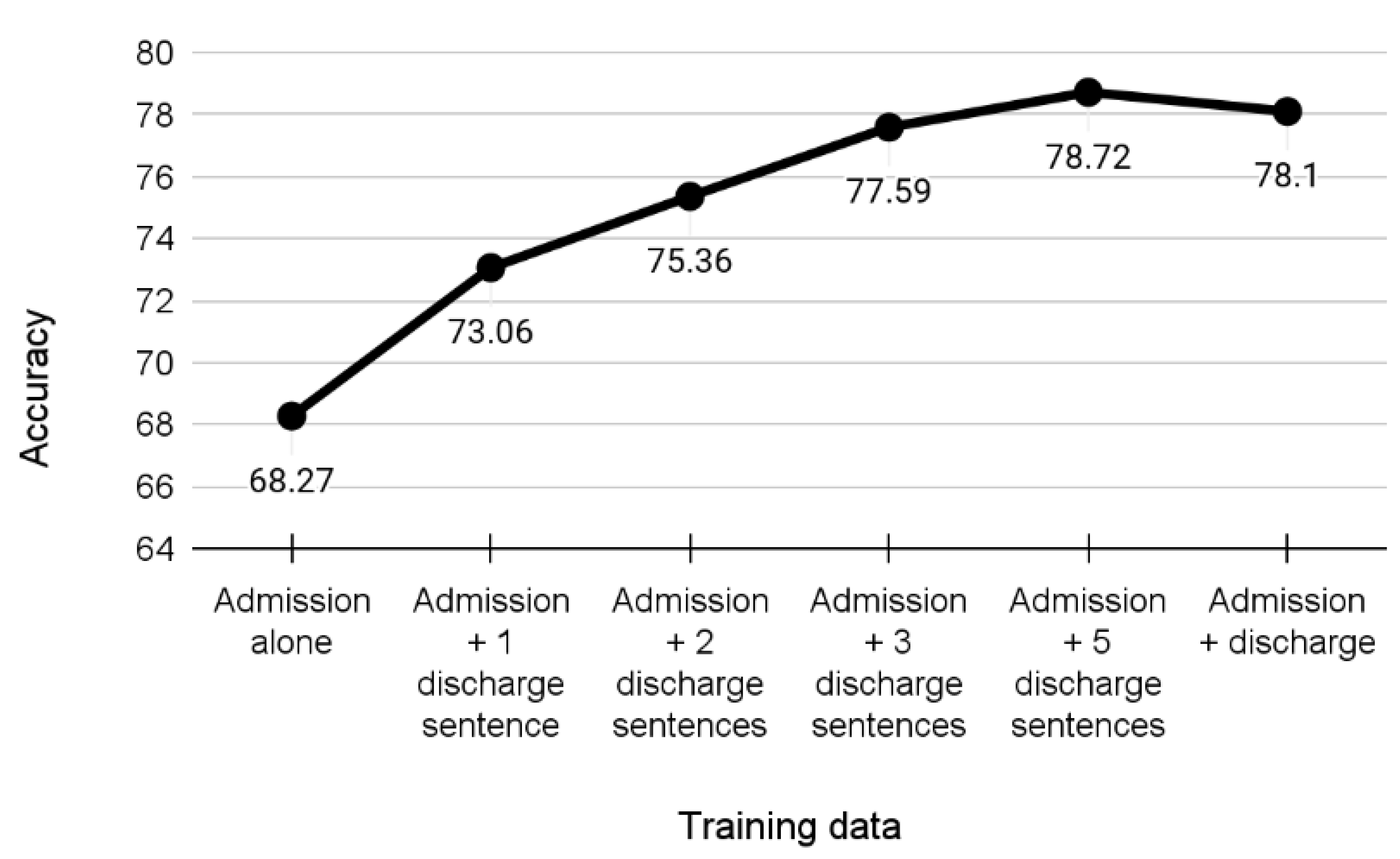
For this purpose, we explored the electronic medical database of GCM hospital, which is one of the largest hospitals in Poland. The Cardiology and Cardiac Surgery Centre of GCM has been specializing in the most complex medical procedures for over 35 years. Specifically, we explored the 3rd Department of Cardiology, which consists of 52 beds, including 12 cardiac intensive care unit beds, that generate a vast amount of non-English language medical data available for analysis. In light of the limited availability of standard medical vocabularies and NLP tools for Polish language information extraction, we aimed to test the efficacy of the current best deep learning models when predicting a patient’s diagnoses based on small selected subsets of the patient’s medical history. Our results demonstrated that the evaluated models significantly surpass other techniques and can offer fast and well-timed estimates of necessary follow-up procedures. From a practical standpoint, we plan to use the results of the current study to perform phenomapping analyses of patients presenting to the emergency department with chest pain to improve differential diagnosis efficacy. As a foundation, this approach could support medical providers in everyday clinical practice. Furthermore, we aim to apply the NLP/AI framework to simulate an economic impact of potentially miscoded diseases on the reimbursement process. It is essential for healthcare institutions to consider the financial aspect which is crucial to secure quality medical supplies, provide access to novel technologies and offer high standards of care.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}