
Multimodal Performance of GPT-4 in Complex Ophthalmology Cases

 , , , , , , , and
, , , , , , , and
Abstract
:1. Introduction
2. Materials and Methods
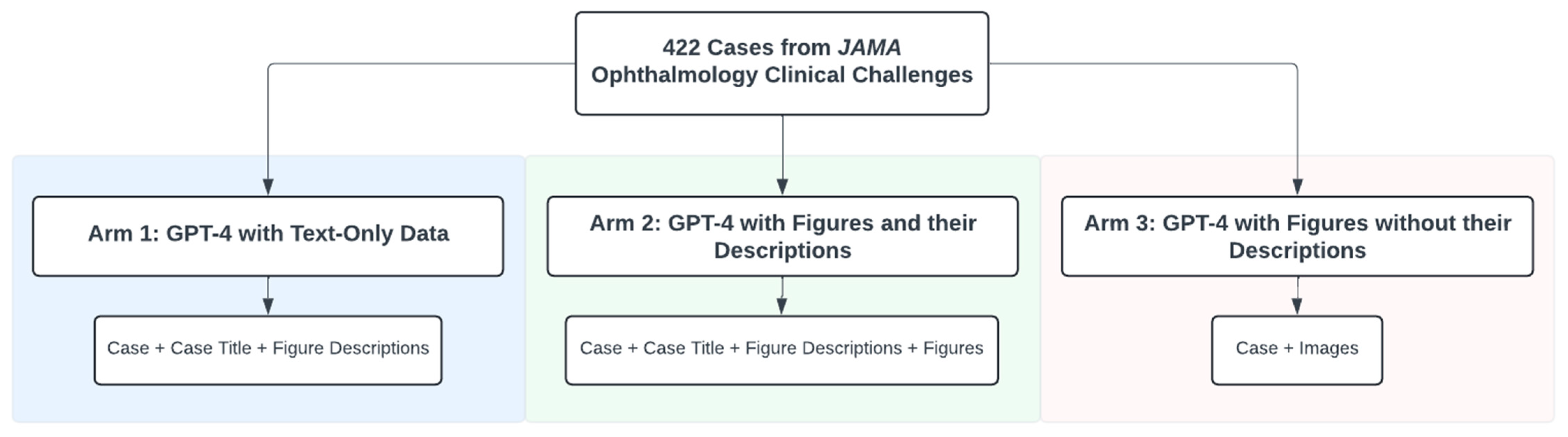
2.1. JAMA Ophthalmology’s Clinical Challenges
2.2. Study Arms
2.3. GPT-4 Access
2.4. Prompting Algorithm
2.5. Human Benchmarking
2.6. Statistical Analysis
3. Results
3.1. GPT-4 Without Figure Descriptions Requires Less Self-Corrective Prompting
3.2. GPT-4 Underperforms with Ophthalmic Figures Versus Text-Only Prompts
3.3. Adding Figure Descriptions Enhanced Diagnostic Accuracy of Image-Based Prompts
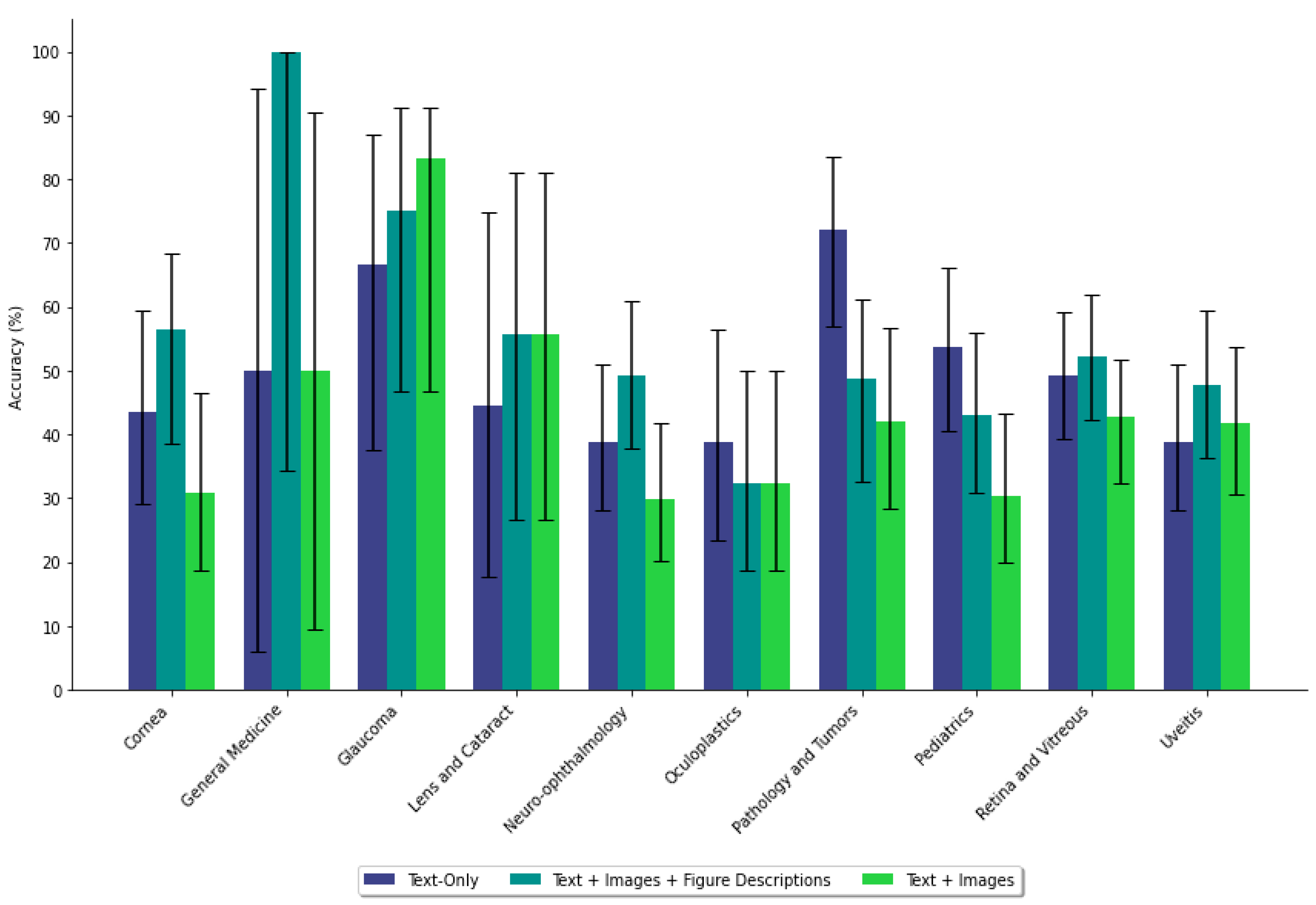
3.4. Impact of Figure Images on Accuracy Based on Case Characteristics
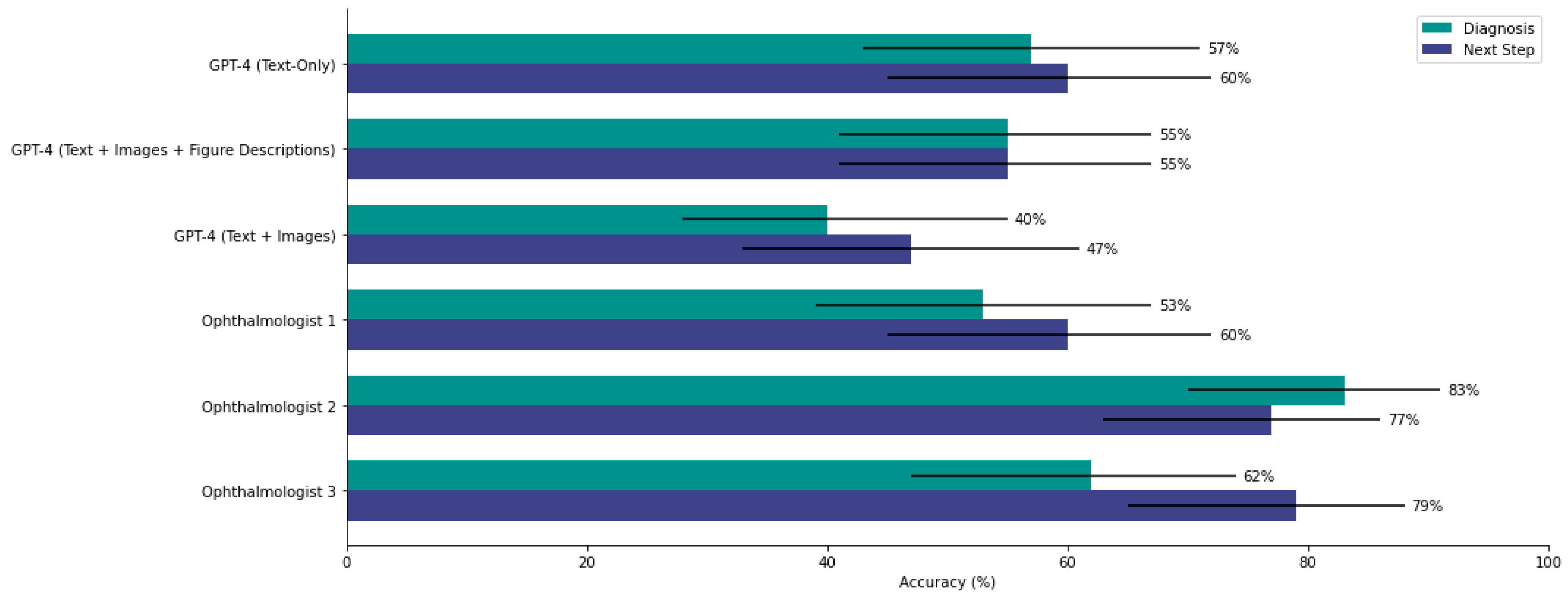
3.5. GPT-4 Prompted with Images Performs Similarly to Two of Three Ophthalmologists on Diagnosis
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E. On the Opportunities and Risks of Foundation Models. 2022. Available online: https://arxiv.org/abs/2108.07258 (accessed on 1 October 2024).
- Wornow, M.; Xu, Y.; Thapa, R.; Patel, B.; Steinberg, E.; Fleming, S.; Pfeffer, M.A.; Fries, J.; Shah, N.H. The Shaky Foundations of Large Language Models and Foundation Models for Electronic Health Records. NPJ Digit. Med. 2023, 6, 135. [Google Scholar] [CrossRef] [PubMed]
- Chia, M.A.; Antaki, F.; Zhou, Y.; Turner, A.W.; Lee, A.Y.; Keane, P.A. Foundation Models in Ophthalmology. Br. J. Ophthalmol. 2024, 108, 1341–1348. [Google Scholar] [CrossRef] [PubMed]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Mihalache, A.; Huang, R.S.; Popovic, M.M.; Patil, N.S.; Pandya, B.U.; Shor, R.; Pereira, A.; Kwok, J.M.; Yan, P.; Wong, D.T.; et al. Accuracy of an Artificial Intelligence Chatbot’s Interpretation of Clinical Ophthalmic Images. JAMA Ophthalmol. 2024, 142, 321–326. [Google Scholar] [CrossRef]
- Agnihotri, A.P.; Nagel, I.D.; Artiaga, J.C.M.; Guevarra, M.C.B.; Sosuan, G.M.N.; Kalaw, F.G.P. Large Language Models in Ophthalmology: A Review of Publications from Top Ophthalmology Journals. Ophthalmol. Sci. 2024, 5, 100681. [Google Scholar] [CrossRef]
- Milad, D.; Antaki, F.; Milad, J.; Farah, A.; Khairy, T.; Mikhail, D.; Giguère, C.-É.; Touma, S.; Bernstein, A.; Szigiato, A.-A.; et al. Assessing the Medical Reasoning Skills of GPT-4 in Complex Ophthalmology Cases. Br. J. Ophthalmol. 2024, 108, 1398–1405. [Google Scholar] [CrossRef]
- Clinical Challenge. Available online: https://jamanetwork.com/collections/44038/clinical-challenge (accessed on 30 March 2025).
- McCannel, C.A.; Bhatti, M.T. The Basic and Clinical Science Course of the American Academy of Ophthalmology: The 50th Anniversary of a Unicorn Among Medical Textbooks. JAMA Ophthalmol. 2022, 140, 225–226. [Google Scholar] [CrossRef]
- Beutel, G.; Geerits, E.; Kielstein, J.T. Artificial Hallucination: GPT on LSD? Crit. Care 2023, 27, 148. [Google Scholar] [CrossRef] [PubMed]
- BT, B.; Chen, J.-M. Performance Assessment of ChatGPT versus Bard in Detecting Alzheimer’s Dementia. Diagnostics 2024, 14, 817. [Google Scholar] [CrossRef]
- Wang, L.; Xu, W.; Lan, Y.; Hu, Z.; Lan, Y.; Lee, R.K.-W.; Lim, E.-P. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. Available online: https://arxiv.org/abs/2305.04091v3 (accessed on 3 June 2024).
- GPT-4V(Ision) System Card. Available online: https://openai.com/index/gpt-4v-system-card/ (accessed on 3 June 2024).
- Mihalache, A.; Huang, R.S.; Mikhail, D.; Popovic, M.M.; Shor, R.; Pereira, A.; Kwok, J.; Yan, P.; Wong, D.T.; Kertes, P.J.; et al. Interpretation of Clinical Retinal Images Using an Artificial Intelligence Chatbot. Ophthalmol. Sci. 2024, 4, 100556. [Google Scholar] [CrossRef]
- Xu, P.; Chen, X.; Zhao, Z.; Shi, D. Unveiling the Clinical Incapabilities: A Benchmarking Study of GPT-4V(Ision) for Ophthalmic Multimodal Image Analysis. Br. J. Ophthalmol. 2024, 108, 1384–1389. [Google Scholar] [CrossRef] [PubMed]
- Kufel, J.; Paszkiewicz, I.; Bielówka, M.; Bartnikowska, W.; Janik, M.; Stencel, M.; Czogalik, Ł.; Gruszczyńska, K.; Mielcarska, S. Will ChatGPT Pass the Polish Specialty Exam in Radiology and Diagnostic Imaging? Insights into Strengths and Limitations. Pol. J. Radiol. 2023, 88, e430. [Google Scholar] [CrossRef]
- Rogasch, J.M.M.; Jochens, H.V.; Metzger, G.; Wetz, C.; Kaufmann, J.; Furth, C.; Amthauer, H.; Schatka, I. Keeping Up with ChatGPT: Evaluating Its Recognition and Interpretation of Nuclear Medicine Images. Clin. Nucl. Med. 2024, 49, 500–504. [Google Scholar] [CrossRef]
- Posner, K.M.; Bakus, C.; Basralian, G.; Chester, G.; Zeiman, M.; O’Malley, G.R.; Klein, G.R. Evaluating ChatGPT’s Capabilities on Orthopedic Training Examinations: An Analysis of New Image Processing Features. Cureus 2024, 16, e55945. [Google Scholar] [CrossRef]
- Collage Prompting: Budget-Friendly Visual Recognition with GPT-4V. Available online: https://arxiv.org/html/2403.11468v1 (accessed on 3 June 2024).
- Rao, A.; Pang, M.; Kim, J.; Kamineni, M.; Lie, W.; Prasad, A.K.; Landman, A.; Dreyer, K.; Succi, M.D. Assessing the Utility of ChatGPT Throughout the Entire Clinical Workflow: Development and Usability Study. J. Med. Internet Res. 2023, 25, e48659. [Google Scholar] [CrossRef] [PubMed]
- Waisberg, E.; Ong, J.; Kamran, S.A.; Masalkhi, M.; Paladugu, P.; Zaman, N.; Lee, A.G.; Tavakkoli, A. Generative Artificial Intelligence in Ophthalmology. Surv. Ophthalmol. 2024, 70, 1–11. [Google Scholar] [CrossRef]
- Rebedea, T.; Dinu, R.; Sreedhar, M.; Parisien, C.; Cohen, J. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. arXiv 2023, arXiv:2310.10501. [Google Scholar]
- Chen, S.; Li, Y.; Lu, S.; Van, H.; Aerts, H.J.W.L.; Savova, G.K.; Bitterman, D.S. Evaluating the ChatGPT Family of Models for Biomedical Reasoning and Classification. J. Am. Med. Inform. Assoc. 2024, 31, 940–948. [Google Scholar] [CrossRef]
- Liu, S.; Wen, T.; Pattamatta, A.S.L.S.; Srolovitz, D.J. A Prompt-Engineered Large Language Model, Deep Learning Workflow for Materials Classification. Mater. Today 2024, 80, 240–249. [Google Scholar] [CrossRef]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Alkaissi, H.; McFarlane, S.I. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 2023, 15, e35179. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompting Data | Subspeciality | Diagnosis | Next Step | ||||
|---|---|---|---|---|---|---|---|
| Mean (%) | 95% CI (%) | p-Value | Mean (%) | 95% CI (%) | p-Value | ||
| Text-Only | Cornea | 43.6 | [29.1, 59.3] | 0.245 | 74.4 | [58.6, 85.6] | 0.0596 |
| Figures | 30.8 | [18.6, 46.5] | 53.8 | [38.5, 68.4] | |||
| Text-Only | General Medicine | 50.0 | [5.9, 94.1] | 1.00 | 100 | [100, 100] | 0.317 |
| Figures | 50.0 | [9.5, 90.5] | 50.0 | [9.5, 90.5] | |||
| Text-Only | Glaucoma | 66.7 | [37.6, 86.9] | 0.358 | 66.7 | [37.6, 86.9] | 1.00 |
| Figures | 83.3 | [46.8, 91.1] | 66.7 | [39.1, 86.2] | |||
| Text-Only | Lens and Cataract | 44.4 | [17.7, 74.9] | 0.644 | 66.7 | [33.3, 88.9] | 0.355 |
| Figures | 55.6 | [26.7, 81.1] | 44.4 | [12.1, 64.6] | |||
| Text-Only | Neuro-ophthalmology | 38.8 | [28.0, 50.9] | 0.280 | 58.2 | [46.2, 69.4] | 0.724 |
| Figures | 29.9 | [20.2, 41.7] | 61.2 | [49.2, 72.0] | |||
| Text-Only | Oculoplastics | 38.7 | [23.5, 56.5] | 0.602 | 74.2 | [56.3, 86.5] | 0.576 |
| Figures | 32.3 | [18.6, 49.9] | 67.7 | [47.0, 78.9] | |||
| Text-Only | Pathology and Tumors | 72.1 | [57.0, 83.4] | 0.0049 | 67.4 | [52.3, 79.7] | 0.812 |
| Figures | 41.9 | [28.4, 56.7] | 69.8 | [54.9, 81.4] | |||
| Text-Only | Pediatrics | 53.6 | [40.6, 66.1] | 0.013 | 62.5 | [49.2, 74.1] | 0.698 |
| Figures | 30.4 | [19.9, 43.3] | 58.9 | [44.1, 69.2] | |||
| Text-Only | Retina and Vitreous | 49.3 | [39.4, 59.2] | 0.360 | 60.7 | [50.6, 69.9] | 0.433 |
| Figures | 42.7 | [32.3, 51.7] | 55.1 | [44.2, 63.8] | |||
| Text-Only | Uveitis | 38.8 | [28.0, 50.9] | 0.724 | 55.2 | [43.2, 66.6] | 0.729 |
| Figures | 41.8 | [30.7, 53.7] | 52.2 | [39.1, 62.3] | |||
| Prompting Data | Subspeciality | Diagnosis | Next Step | ||||
|---|---|---|---|---|---|---|---|
| Mean (%) | 95% CI (%) | p-Value | Mean (%) | 95% CI (%) | p-Value | ||
| Text-Only | Cornea | 43.6 | [29.1, 59.3] | 0.258 | 74.4 | [58.6, 85.6] | 0.326 |
| Figures + Descriptions | 56.4 | [38.6, 68.4] | 64.1 | [45.9, 75.1] | |||
| Text-Only | General Medicine | 50.0 | [5.9, 94.1] | 0.317 | 100 | [100, 100] | 1.00 |
| Figures + Descriptions | 100 | [34.2, 100.0] | 100 | [34.2, 100.0] | |||
| Text-Only | Glaucoma | 66.7 | [37.6, 86.9] | 0.653 | 66.7 | [37.6, 86.9] | 0.219 |
| Figures + Descriptions | 75.0 | [46.8, 91.1] | 41.7 | [19.3, 68.0] | |||
| Text-Only | Lens and Cataract | 44.4 | [17.7, 74.9] | 0.637 | 66.7 | [33.3, 88.9] | 0.343 |
| Figures + Descriptions | 55.6 | [26.7, 81.1] | 44.4 | [12.1, 64.6] | |||
| Text-Only | Neuro-ophthalmology | 38.8 | [28.0, 50.9] | 0.223 | 58.2 | [46.2, 69.4] | 0.596 |
| Figures + Descriptions | 49.3 | [37.7, 60.9] | 62.7 | [50.7, 73.3] | |||
| Text-Only | Oculoplastics | 38.7 | [23.5, 56.5] | 0.569 | 74.2 | [56.3, 86.5] | 0.111 |
| Figures + Descriptions | 32.3 | [18.6, 49.9] | 54.8 | [34.8, 68.0] | |||
| Text-Only | Pathology and Tumors | 72.1 | [57.0, 83.4] | 0.0270 | 67.4 | [52.3, 79.7] | 0.651 |
| Figures + Descriptions | 48.8 | [32.5, 61.1] | 62.8 | [47.9, 75.6] | |||
| Text-Only | Pediatrics | 53.6 | [40.6, 66.1] | 0.257 | 62.5 | [49.2, 74.1] | 0.552 |
| Figures + Descriptions | 42.9 | [30.8, 55.9] | 67.9 | [54.8, 78.6] | |||
| Text-Only | Retina and Vitreous | 49.3 | [39.4, 59.2] | 0.665 | 60.7 | [50.6, 69.9] | 0.465 |
| Figures + Descriptions | 52.1 | [42.2, 61.8] | 55.2 | [44.2, 63.8] | |||
| Text-Only | Uveitis | 38.8 | [28.0, 50.9] | 0.296 | 55.2 | [43.2, 66.6] | 1.00 |
| Figures + Descriptions | 47.8 | [36.3, 59.5] | 55.2 | [41.9, 65.1] | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mikhail, D.; Milad, D.; Antaki, F.; Milad, J.; Farah, A.; Khairy, T.; El-Khoury, J.; Bachour, K.; Szigiato, A.-A.; Nayman, T.; et al. Multimodal Performance of GPT-4 in Complex Ophthalmology Cases. J. Pers. Med. 2025, 15, 160. https://doi.org/10.3390/jpm15040160
Mikhail D, Milad D, Antaki F, Milad J, Farah A, Khairy T, El-Khoury J, Bachour K, Szigiato A-A, Nayman T, et al. Multimodal Performance of GPT-4 in Complex Ophthalmology Cases. Journal of Personalized Medicine. 2025; 15(4):160. https://doi.org/10.3390/jpm15040160
Chicago/Turabian StyleMikhail, David, Daniel Milad, Fares Antaki, Jason Milad, Andrew Farah, Thomas Khairy, Jonathan El-Khoury, Kenan Bachour, Andrei-Alexandru Szigiato, Taylor Nayman, and et al. 2025. "Multimodal Performance of GPT-4 in Complex Ophthalmology Cases" Journal of Personalized Medicine 15, no. 4: 160. https://doi.org/10.3390/jpm15040160
APA StyleMikhail, D., Milad, D., Antaki, F., Milad, J., Farah, A., Khairy, T., El-Khoury, J., Bachour, K., Szigiato, A.-A., Nayman, T., Mullie, G. A., & Duval, R. (2025). Multimodal Performance of GPT-4 in Complex Ophthalmology Cases. Journal of Personalized Medicine, 15(4), 160. https://doi.org/10.3390/jpm15040160