SACGNet: A Remaining Useful Life Prediction of Bearing with Self-Attention Augmented Convolution GRU Network



Abstract
:1. Introduction
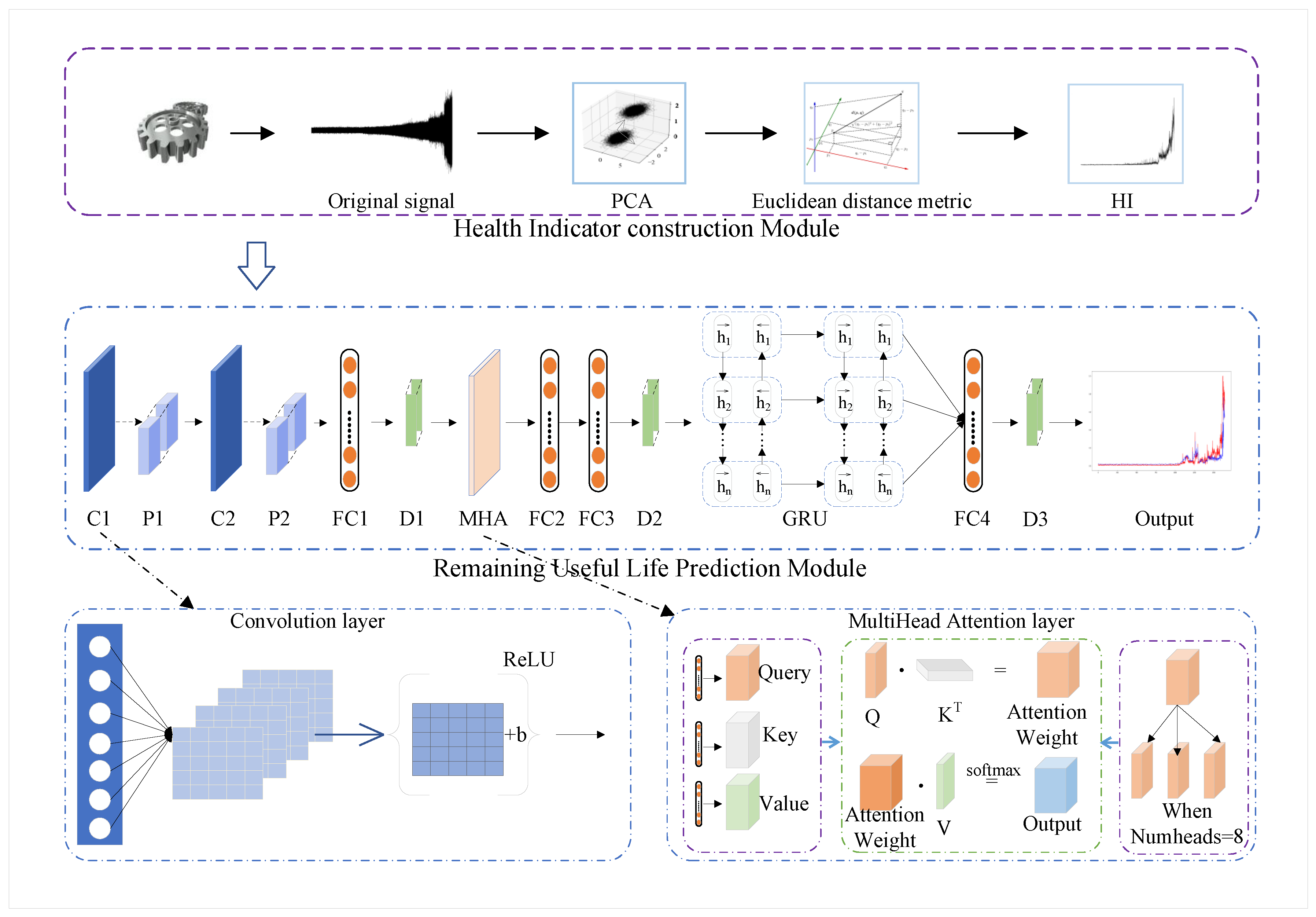
- We combine the PCA with Euclidean distance metric methods to construct a health indicator to tackle the problem of lack of RUL labels. Facing the high-dimensional and long-term series data, PCA can reduce the data dimensionality while retaining sufficient useful features. The Euclidean distance is to measure the similarity between data to distinguish the different degradation stages. Compared with the existing linear RUL labels, our HI is not only capable of representing the general degradation trend of bearings, but it also can retain more local features from the original vibration signal, which benefit the corresponding model’s learning and calculations.
- We design a novel self-attention augmented convolution GRU network (SACGNet) to predict the RUL. Combining the self-attention mechanism with a convolution framework can both adaptively assign greater weights to more important information and focus on local information. Furthermore, Gated Recurrent Units (GRU) are used to parse the long-term dependencies in weighted features so that SACGNet can utilize the important weighted features and focus on local features to improve the prognostic accuracy.
- Based on the designed HI and SACGNet, a novel remaining useful life prediction approach is proposed. We conduct ablation experiments and different comparison experiments on the PHM 2012 Challenge dataset and XJTU-SY bearing dataset. The experimental results prove the superiority of our proposed method.
2. Related Works
2.1. Health Indicator Construction
2.2. Prediction Model
3. Proposed Method
3.1. Health Indicator Construction Module
3.2. Remaining Useful Life Prediction Module
| Algorithm 1: Proposed SACGNet. |
| 1. The SACGNet algorithm for training is defined |
| as follows: |
| Input: Hyper-parameters of model (batch size, epoch, |
| dropout rate, learning rate, etc.), original signal |
| 2. |
| 3. By sliding window processing: |
| Each x represents a batch h, the number of a batch is i |
| 4. |
| 5. For do: |
| , |
| end |
| 6. Build SACGNet model |
| 7. w (parameters of the SACGNet) and b (biases) are initialized to zeros |
| 8. Input X and Y to train SACGNet |
| Output: Trained SACGNet model for prediction |
| END |
4. Experiments and Results
4.1. Dataset Description
4.2. Different HIs Results
4.3. Ablation Experiments
4.4. Results of Different Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Uckun, S.; Goebel, K.; Lucas, P.J. Standardizing research methods for prognostics. In Proceedings of the International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–10. [Google Scholar]
- Glowacz, A. Acoustic fault analysis of three commutator motors. Mech. Syst. Signal Process. 2019, 133, 106226. [Google Scholar] [CrossRef]
- Zarei, J.; Tajeddini, M.A.; Karimi, H.R. Vibration analysis for bearing fault detection and classification using an intelligent filter. Mechatronics 2014, 24, 151–157. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, W.; Kozik, J.; Piech, K.; Gutten, M.; Caesarendra, W.; Liu, H.; Brumercik, F.; Irfan, M.; Khan, Z.F. Detection of deterioration of three-phase induction motor using vibration signals. Meas. Sci. Rev. 2019, 19, 241–249. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, C.; Lasheras, F.S.; Roca-Pardinas, J.; de Cos Juez, F.J. A hybrid ARIMA–SVM model for the study of the remaining useful life of aircraft engines. J. Comput. Appl. Math. 2019, 346, 184–191. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, X.; Yan, K.; Zhu, Y.; Hong, J. A Study on Bearing Dynamic Features under the Condition of Multiball—Cage Collision. Lubricants 2022, 10, 9. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Singleton, R.K.; Strangas, E.G.; Aviyente, S. Extended Kalman filtering for remaining-useful-life estimation of bearings. IEEE Trans. Ind. Electron. 2014, 62, 1781–1790. [Google Scholar] [CrossRef]
- Saidi, L.; Benbouzid, M. Prognostics and Health Management of Renewable Energy Systems: State of the Art Review, Challenges, and Trends. Electronics 2021, 10, 2732. [Google Scholar] [CrossRef]
- Zhang, N.; Wu, L.; Wang, Z.; Guan, Y. Bearing remaining useful life prediction based on Naive Bayes and Weibull distributions. Entropy 2018, 20, 944. [Google Scholar] [CrossRef] [Green Version]
- Malhi, A.; Yan, R.; Gao, R.X. Prognosis of defect propagation based on recurrent neural networks. IEEE Trans. Instrum. Meas. 2011, 60, 703–711. [Google Scholar] [CrossRef]
- Liao, H.; Tian, Z. A framework for predicting the remaining useful life of a single unit under time-varying operating conditions. IEEE Trans. 2013, 45, 964–980. [Google Scholar] [CrossRef]
- Hu, L.; Hu, N.Q.; Fan, B.; Gu, F.S.; Zhang, X.Y. Modeling the relationship between vibration features and condition parameters using relevance vector machines for health monitoring of rolling element bearings under varying operation conditions. Math. Probl. Eng. 2015, 2015, 123730. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Si, X.S.; Hu, C.H. An age-and state-dependent nonlinear prognostic model for degrading systems. IEEE Trans. Reliab. 2015, 64, 1214–1228. [Google Scholar] [CrossRef]
- Hu, C.; Youn, B.D.; Wang, P.; Yoon, J.T. Ensemble of data-driven prognostic algorithms for robust prediction of remaining useful life. Reliab. Eng. Syst. Saf. 2012, 103, 120–135. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Peng, Y.; Zi, Y.; Jin, X.; Tsui, K.L. A two-stage data-driven-based prognostic approach for bearing degradation problem. IEEE Trans. Ind. Inform. 2016, 12, 924–932. [Google Scholar] [CrossRef]
- Giantomassi, A.; Ferracuti, F.; Benini, A.; Ippoliti, G.; Longhi, S.; Petrucci, A. Hidden Markov model for health estimation and prognosis of turbofan engines. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Washington, DC, USA, 28–31 August 2011; Volume 54808, pp. 681–689. [Google Scholar]
- Kumar, H.; Pai, S.P.; Sriram, N.; Vijay, G. Rolling element bearing fault diagnostics: Development of health index. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2017, 231, 3923–3939. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Xiong, X.; Shao, H. Rolling bearing health prognosis using a modified health index based hierarchical gated recurrent unit network. Mech. Mach. Theory 2019, 133, 229–249. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Data alignments in machinery remaining useful life prediction using deep adversarial neural networks. Knowl.-Based Syst. 2020, 197, 105843. [Google Scholar] [CrossRef]
- Zeming, L.; Jianmin, G.; Hongquan, J.; Xu, G.; Zhiyong, G.; Rongxi, W. A similarity-based method for remaining useful life prediction based on operational reliability. Appl. Intell. 2018, 48, 2983–2995. [Google Scholar] [CrossRef]
- Hinchi, A.Z.; Tkiouat, M. Rolling element bearing remaining useful life estimation based on a convolutional long-short-term memory network. Procedia Comput. Sci. 2018, 127, 123–132. [Google Scholar] [CrossRef]
- Wang, F.; Liu, X.; Deng, G.; Yu, X.; Li, H.; Han, Q. Remaining life prediction method for rolling bearing based on the long short-term memory network. Neural Process. Lett. 2019, 50, 2437–2454. [Google Scholar] [CrossRef]
- Ragab, M.; Chen, Z.; Wu, M.; Foo, C.S.; Kwoh, C.K.; Yan, R.; Li, X. Contrastive adversarial domain adaptation for machine remaining useful life prediction. IEEE Trans. Ind. Inform. 2020, 17, 5239–5249. [Google Scholar] [CrossRef]
- Cheng, Y.; Hu, K.; Wu, J.; Zhu, H.; Lee, C.K. A deep learning-based two-stage prognostic approach for remaining useful life of rolling bearing. Appl. Intell. 2021, 1–16. [Google Scholar] [CrossRef]
- Erdenebayar, U.; Kim, Y.; Park, J.U.; Lee, S.; Lee, K.J. Automatic Classification of Sleep Stage from an ECG Signal Using a Gated-Recurrent Unit. Int. J. Fuzzy Log. Intell. Syst. 2020, 20, 181–187. [Google Scholar] [CrossRef]
- Cao, Y.; Jia, M.; Ding, P.; Ding, Y. Transfer learning for remaining useful life prediction of multi-conditions bearings based on bidirectional-GRU network. Measurement 2021, 178, 109287. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z.; Jia, W.; Lin, X. Remaining useful life prediction using a novel feature-attention-based end-to-end approach. IEEE Trans. Ind. Inform. 2020, 17, 1197–1207. [Google Scholar] [CrossRef]
- Ma, M.; Mao, Z. Deep-convolution-based LSTM network for remaining useful life prediction. IEEE Trans. Ind. Inform. 2020, 17, 1658–1667. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Hauptmann, A.G. Simultaneous bearing fault recognition and remaining useful life prediction using joint-loss convolutional neural network. IEEE Trans. Ind. Inform. 2019, 16, 87–96. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Peng, W. Estimation of bearing remaining useful life based on multiscale convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 3208–3216. [Google Scholar] [CrossRef]
- Cheng, C.; Ma, G.; Zhang, Y.; Sun, M.; Teng, F.; Ding, H.; Yuan, Y. Online bearing remaining useful life prediction based on a novel degradation indicator and convolutional neural networks. arXiv 2018, arXiv:1812.03315. [Google Scholar]
- Ge, Y.; Liu, J.; Ma, J. Remaining Useful Life Prediction Using Deep Multi-scale Convolution Neural Networks. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1043, 032011. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, X. Convolutional neural network based on attention mechanism and Bi-LSTM for bearing remaining life prediction. Appl. Intell. 2021, 52, 1–16. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 32, 1–10. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2020, 86, 105919. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Zhao, R.; Guretno, F.; Yan, R.; Li, X. Machine remaining useful life prediction via an attention-based deep learning approach. IEEE Trans. Ind. Electron. 2020, 68, 2521–2531. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3286–3295. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12, London, UK, 23–27 September 2012; pp. 1–8. [Google Scholar]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A hybrid prognostics approach for estimating remaining useful life of rolling element bearings. IEEE Trans. Reliab. 2018, 69, 401–412. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Symobl | Operator | Kernel Size | Dimension |
|---|---|---|---|---|
| 1 | Input | Input signal | / | (None, 20, 2) |
| 2 | C1 | Convolution | 4 × 4 | (None, 20, 80) |
| 3 | P1 | Average pooling | 1 × 1 | (None, 20, 80) |
| 4 | C2 | Convolution | 4 × 4 | (None, 20, 80) |
| 5 | P2 | Average pooling | 1 × 1 | (None, 20, 80) |
| 6 | FC1 | Fully connected | 80 × 1 | (None, 20, 80) |
| 7 | D1 | Dropout | / | (None, 20, 80) |
| 8 | MHA | Multi-Head Attention | / | (None, 20, 80) |
| 9 | FC2 | Fully connected | 80 × 1 | (None, 20, 80) |
| 10 | FC3 | Fully connected | 80 × 1 | (None, 20, 80) |
| 11 | D2 | Dropout | / | (None, 20, 80) |
| 12 | GRU | Gated recurrent units | / | (None, 80) |
| 13 | D3 | Dropout | / | (None, 80) |
| 14 | FC4 | Fully connected | 1 × 1 | (None, 1) |
| Working Condition | Rotation Speed | Load | Dataset | Sample Number | Bearing Lifetime | Division |
|---|---|---|---|---|---|---|
| 1 | 1800 rpm | 4000 N | Bearing 1-1 | 2803 | 7 h 47 m | training |
| Bearing 1-2 | 871 | 2 h 25 m | training | |||
| Bearing 1-3 | 1802 | 5 h 10 s | testing | |||
| Bearing 1-4 | 1139 | 3 h 9 m 40 s | testing | |||
| Bearing 1-5 | 2302 | 6 h 23 m 30 s | testing | |||
| Bearing 1-6 | 2302 | 6 h 23 m 29 s | testing | |||
| Bearing 1-7 | 1502 | 4 h 10 m 11 s | testing | |||
| 2 | 1650 rpm | 4200 N | Bearing 2-1 | 911 | 2 h 31 m 40 s | training |
| Bearing 2-2 | 797 | 2 h 12 m 40 s | training | |||
| Bearing 2-3 | 1202 | 3 h 20 m 10 s | testing | |||
| Bearing 2-4 | 612 | 1 h 41 m 50 s | testing | |||
| Bearing 2-5 | 2002 | 5 h 33 m 30 s | testing | |||
| Bearing 2-6 | 572 | 1 h 35 m 10 s | testing | |||
| Bearing 2-7 | 172 | 28 m 30 s | testing | |||
| 3 | 1500 rpm | 5000 N | Bearing 3-1 | 515 | 1 h 25 m 40 s | training |
| Bearing 3-2 | 1637 | 4 h 32 m 40 s | training | |||
| Bearing 3-3 | 352 | 58 m 30 s | testing |
| Working Condition | Rotation Speed | Load | Dataset | Sample Number | Bearing Lifetime | Division |
|---|---|---|---|---|---|---|
| 1 | 2100 rpm | 12,000 N | Bearing 1-1 | 123 | 2 h 3 m | training |
| Bearing 1-2 | 161 | 2 h 41 m | training | |||
| Bearing 1-3 | 158 | 2 h 38 m | testing | |||
| Bearing 1-4 | 122 | 2 h 2 m | testing | |||
| Bearing 1-5 | 52 | 52 m | testing | |||
| 2 | 2250 rpm | 11,000 N | Bearing 2-1 | 491 | 8 h 11 m | training |
| Bearing 2-2 | 161 | 2 h 41 m | training | |||
| Bearing 2-3 | 533 | 8 h 53 m | testing | |||
| Bearing 2-4 | 42 | 42 m | testing | |||
| Bearing 2-5 | 339 | 5 h 39 m | testing | |||
| 3 | 2400 rpm | 10,000 N | Bearing 3-1 | 2538 | 42 h 18 m | training |
| Bearing 3-2 | 2496 | 41 h 36 m | training | |||
| Bearing 3-3 | 371 | 6 h 11 m | testing | |||
| Bearing 3-4 | 1515 | 25 h 15 m | testing | |||
| Bearing 3-5 | 114 | 1 h 54 m | testing |
| Metric | Bearing 1-3 | Bearing 1-4 | Bearing 1-5 | Bearing 1-6 | Bearing 1-7 | Bearing 2-3 | Bearing 2-4 | Bearing 2-5 | Bearing 2-6 | Bearing 2-7 | Bearing 3-3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | SACGNet | 0.010 | 0.053 | 0.039 | 0.042 | 0.012 | 0.017 | 0.042 | 0.066 | 0.042 | 0.061 | 0.078 |
| NoAttention | 0.203 | 0.138 | 0.212 | 0.193 | 0.223 | 0.049 | 0.063 | 0.064 | 0.061 | 0.062 | 0.162 | |
| NoConv1d | 0.055 | 0.099 | 0.160 | 0.060 | 0.069 | 0.162 | 0.110 | 0.161 | 0.129 | 0.076 | 0.095 | |
| RMSE | SACGNet | 0.101 | 0.230 | 0.197 | 0.205 | 0.108 | 0.131 | 0.204 | 0.202 | 0.205 | 0.397 | 0.280 |
| NoAttention | 0.451 | 0.372 | 0.461 | 0.439 | 0.472 | 0.220 | 0.250 | 0.253 | 0.246 | 0.249 | 0.403 | |
| NoConv1d | 0.236 | 0.314 | 0.401 | 0.245 | 0.263 | 0.403 | 0.332 | 0.402 | 0.359 | 0.276 | 0.309 | |
| MAE | SACGNet | 0.041 | 0.157 | 0.077 | 0.079 | 0.022 | 0.033 | 0.081 | 0.071 | 0.083 | 0.220 | 0.161 |
| NoAttention | 0.373 | 0.304 | 0.382 | 0.359 | 0.394 | 0.201 | 0.148 | 0.225 | 0.167 | 0.096 | 0.368 | |
| NoConv1d | 0.216 | 0.215 | 0.273 | 0.203 | 0.256 | 0.387 | 0.271 | 0.375 | 0.303 | 0.178 | 0.205 | |
| MAPE | SACGNet | 1.300 | 1.461 | 5.800 | 2.707 | 2.526 | 13.290 | 14.128 | 15.778 | 48.944 | 188.952 | 11.879 |
| NoAttention | 26.616 | 3.542 | 64.021 | 38.050 | 86.298 | 89.249 | 33.654 | 47.493 | 83.542 | 11.724 | 22.317 | |
| NoConv1d | 16.809 | 2.627 | 33.060 | 19.339 | 47.315 | 175.061 | 62.932 | 77.439 | 140.799 | 78.596 | 15.225 |
| Metric | Bearing 1-3 | Bearing 1-4 | Bearing 1-5 | Bearing 2-3 | Bearing 2-4 | Bearing 2-5 | Bearing 3-3 | Bearing 3-4 | Bearing 3-5 | |
|---|---|---|---|---|---|---|---|---|---|---|
| MSE | SACGNet | 0.022 | 0.028 | 0.129 | 0.102 | 0.261 | 0.116 | 0.134 | 0.037 | 0.249 |
| NoAttention | 0.071 | 0.045 | 0.151 | 0.099 | 0.238 | 0.189 | 0.150 | 0.050 | 0.252 | |
| NoConv1d | 0.282 | 0.141 | 0.150 | 0.262 | 0.292 | 0.122 | 0.147 | 0.093 | 0.254 | |
| RMSE | SACGNet | 0.147 | 0.166 | 0.360 | 0.320 | 0.511 | 0.341 | 0.369 | 0.193 | 0.500 |
| NoAttention | 0.266 | 0.212 | 0.388 | 0.315 | 0.488 | 0.435 | 0.387 | 0.223 | 0.502 | |
| NoConv1d | 0.531 | 0.376 | 0.387 | 0.512 | 0.540 | 0.350 | 0.383 | 0.304 | 0.504 | |
| MAE | SACGNet | 0.117 | 0.088 | 0.206 | 0.307 | 0.428 | 0.249 | 0.256 | 0.069 | 0.447 |
| NoAttention | 0.229 | 0.137 | 0.198 | 0.301 | 0.400 | 0.333 | 0.276 | 0.098 | 0.450 | |
| NoConv1d | 0.447 | 0.274 | 0.194 | 0.479 | 0.462 | 0.297 | 0.294 | 0.211 | 0.447 | |
| MAPE | SACGNet | 12.904 | 0.714 | 3.217 | 12.090 | 0.862 | 8.714 | 17.105 | 31.240 | 1.251 |
| NoAttention | 39.583 | 1.903 | 0.798 | 12.442 | 0.750 | 8.626 | 19.341 | 53.358 | 1.286 | |
| NoConv1d | 84.217 | 4.435 | 0.568 | 19.283 | 0.998 | 9.188 | 33.756 | 172.834 | 1.314 |
| Metric | Bearing 1-3 | Bearing 1-4 | Bearing 1-5 | Bearing 1-6 | Bearing 1-7 | Bearing 2-3 | Bearing 2-4 | Bearing 2-5 | Bearing 2-6 | Bearing 2-7 | Bearing 3-3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | SACGNet | 0.010 | 0.053 | 0.039 | 0.042 | 0.012 | 0.017 | 0.042 | 0.066 | 0.042 | 0.061 | 0.078 |
| CNN | 0.276 | 0.236 | 0.361 | 0.339 | 0.401 | 0.017 | 0.044 | 0.033 | 0.049 | 0.063 | 0.159 | |
| RNN | 0.087 | 0.079 | 0.191 | 0.167 | 0.089 | 0.098 | 0.107 | 0.102 | 0.106 | 0.052 | 0.080 | |
| LSTM | 0.051 | 0.154 | 0.099 | 0.088 | 0.100 | 0.134 | 0.126 | 0.080 | 0.129 | 0.153 | 0.232 | |
| GRU | 0.156 | 0.130 | 0.220 | 0.212 | 0.122 | 0.047 | 0.173 | 0.074 | 0.150 | 0.621 | 0.255 | |
| RMSE | SACGNet | 0.101 | 0.230 | 0.197 | 0.205 | 0.108 | 0.131 | 0.204 | 0.202 | 0.205 | 0.397 | 0.280 |
| CNN | 0.526 | 0.486 | 0.601 | 0.583 | 0.633 | 0.132 | 0.209 | 0.182 | 0.221 | 0.250 | 0.399 | |
| RNN | 0.295 | 0.282 | 0.437 | 0.409 | 0.299 | 0.313 | 0.327 | 0.319 | 0.326 | 0.229 | 0.282 | |
| LSTM | 0.227 | 0.393 | 0.315 | 0.296 | 0.317 | 0.366 | 0.354 | 0.283 | 0.360 | 0.392 | 0.482 | |
| GRU | 0.395 | 0.360 | 0.469 | 0.461 | 0.350 | 0.216 | 0.416 | 0.272 | 0.387 | 0.788 | 0.505 | |
| MAE | SACGNet | 0.041 | 0.157 | 0.077 | 0.079 | 0.022 | 0.033 | 0.081 | 0.071 | 0.083 | 0.220 | 0.161 |
| CNN | 0.431 | 0.401 | 0.492 | 0.473 | 0.529 | 0.079 | 0.121 | 0.127 | 0.129 | 0.094 | 0.361 | |
| RNN | 0.272 | 0.230 | 0.405 | 0.371 | 0.277 | 0.305 | 0.297 | 0.307 | 0.302 | 0.137 | 0.208 | |
| LSTM | 0.082 | 0.270 | 0.294 | 0.275 | 0.308 | 0.352 | 0.185 | 0.219 | 0.215 | 0.369 | 0.376 | |
| GRU | 0.378 | 0.315 | 0.449 | 0.282 | 0.337 | 0.163 | 0.250 | 0.167 | 0.220 | 0.744 | 0.433 | |
| MAPE | SACGNet | 1.300 | 1.461 | 5.800 | 2.707 | 2.526 | 13.290 | 14.128 | 15.778 | 48.944 | 188.952 | 11.879 |
| CNN | 34.128 | 4.702 | 84.794 | 68.833 | 116.331 | 34.082 | 26.482 | 26.338 | 66.653 | 10.532 | 21.550 | |
| RNN | 20.391 | 2.999 | 64.366 | 51.722 | 58.369 | 135.458 | 77.727 | 63.910 | 132.203 | 33.092 | 14.056 | |
| LSTM | 4.084 | 3.941 | 46.745 | 34.372 | 64.918 | 157.411 | 43.524 | 45.461 | 107.898 | 160.438 | 25.883 | |
| GRU | 28.107 | 4.765 | 52.206 | 52.417 | 70.271 | 72.181 | 63.668 | 35.833 | 110.955 | 364.585 | 28.784 |
| Metric | Bearing 1-3 | Bearing 1-4 | Bearing 1-5 | Bearing 2-3 | Bearing 2-4 | Bearing 2-5 | Bearing 3-3 | Bearing 3-4 | Bearing 3-5 | |
|---|---|---|---|---|---|---|---|---|---|---|
| MSE | SACGNet | 0.022 | 0.028 | 0.129 | 0.102 | 0.261 | 0.116 | 0.134 | 0.037 | 0.249 |
| CNN | 0.024 | 0.036 | 0.151 | 0.060 | 0.276 | 0.190 | 0.161 | 0.041 | 0.255 | |
| RNN | 0.297 | 0.122 | 0.139 | 0.127 | 0.292 | 0.984 | 0.141 | 0.084 | 0.225 | |
| LSTM | 0.276 | 0.136 | 0.150 | 0.276 | 0.292 | 0.260 | 0.615 | 0.097 | 0.147 | |
| GRU | 0.276 | 0.144 | 0.150 | 0.123 | 0.292 | 0.107 | 0.170 | 0.331 | 0.236 | |
| RMSE | SACGNet | 0.147 | 0.166 | 0.360 | 0.320 | 0.511 | 0.341 | 0.369 | 0.193 | 0.500 |
| CNN | 0.154 | 0.191 | 0.389 | 0.244 | 0.525 | 0.436 | 0.401 | 0.203 | 0.505 | |
| RNN | 0.545 | 0.349 | 0.373 | 0.357 | 0.540 | 0.314 | 0.375 | 0.290 | 0.474 | |
| LSTM | 0.525 | 0.368 | 0.387 | 0.525 | 0.540 | 0.510 | 0.784 | 0.312 | 0.384 | |
| GRU | 0.526 | 0.380 | 0.387 | 0.351 | 0.540 | 0.331 | 0.413 | 0.575 | 0.486 | |
| MAE | SACGNet | 0.117 | 0.088 | 0.206 | 0.307 | 0.428 | 0.249 | 0.256 | 0.069 | 0.447 |
| CNN | 0.134 | 0.093 | 0.200 | 0.228 | 0.444 | 0.333 | 0.297 | 0.077 | 0.454 | |
| RNN | 0.469 | 0.249 | 0.194 | 0.332 | 0.462 | 0.231 | 0.311 | 0.252 | 0.421 | |
| LSTM | 0.442 | 0.280 | 0.194 | 0.520 | 0.462 | 0.457 | 0.730 | 0.135 | 0.297 | |
| GRU | 0.446 | 0.290 | 0.194 | 0.334 | 0.462 | 0.246 | 0.368 | 0.563 | 0.433 | |
| MAPE | SACGNet | 12.904 | 0.714 | 3.217 | 12.090 | 0.862 | 8.714 | 17.105 | 31.240 | 1.251 |
| CNN | 17.219 | 0.762 | 0.922 | 8.611 | 0.929 | 8.883 | 21.782 | 34.925 | 1.292 | |
| RNN | 85.029 | 4.089 | 1.628 | 14.217 | 0.998 | 8.480 | 29.475 | 184.134 | 1.257 | |
| LSTM | 84.945 | 4.599 | 0.568 | 19.232 | 0.998 | 15.022 | 90.756 | 77.418 | 1.546 | |
| GRU | 85.115 | 4.736 | 0.568 | 14.007 | 0.998 | 8.644 | 42.677 | 425.427 | 1.258 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Duan, S.; Chen, W.; Wang, D.; Fan, Y. SACGNet: A Remaining Useful Life Prediction of Bearing with Self-Attention Augmented Convolution GRU Network. Lubricants 2022, 10, 21. https://doi.org/10.3390/lubricants10020021
Xu J, Duan S, Chen W, Wang D, Fan Y. SACGNet: A Remaining Useful Life Prediction of Bearing with Self-Attention Augmented Convolution GRU Network. Lubricants. 2022; 10(2):21. https://doi.org/10.3390/lubricants10020021
Chicago/Turabian StyleXu, Juan, Shiyu Duan, Weiwei Chen, Dongfeng Wang, and Yuqi Fan. 2022. "SACGNet: A Remaining Useful Life Prediction of Bearing with Self-Attention Augmented Convolution GRU Network" Lubricants 10, no. 2: 21. https://doi.org/10.3390/lubricants10020021
APA StyleXu, J., Duan, S., Chen, W., Wang, D., & Fan, Y. (2022). SACGNet: A Remaining Useful Life Prediction of Bearing with Self-Attention Augmented Convolution GRU Network. Lubricants, 10(2), 21. https://doi.org/10.3390/lubricants10020021