Remaining Useful Life Prediction Based on Wear Monitoring with Multi-Attribute GAN Augmentation



Abstract
:1. Introduction
- (1)
- Considering the uncertainty induced by the oil small sample data, the multi-attribute representation architecture of indicator-attribute-state is proposed to realize the information fusion based on the probability membership, which forms the quantitative characterization of the state for RUL prediction.
- (2)
- Regarding the interaction between monitoring indicators, a multi-attribute CMC-GAN is constructed to introduce indicator mutual constraints to realize data augmentation of multi-indicator monitoring data.
- (3)
- Via stochastic process to describe the comprehensive wear state, the parameter updating strategy is proposed based on EM to realize the RUL prediction under the multi-indicator data augmentation.
2. Augmented Quantitative Characterization of Multi-Attribute Wear State
2.1. Basic Definition of Wear State Grade
- (1)
- Set of state grades: , where N is the number of state grade divisions,
- (2)
- Set of attributes of state: , , where r is the number of attributes,
- (3)
- Set of indicators of state: , , where g is the number of indicators contained in the i-th attribute.
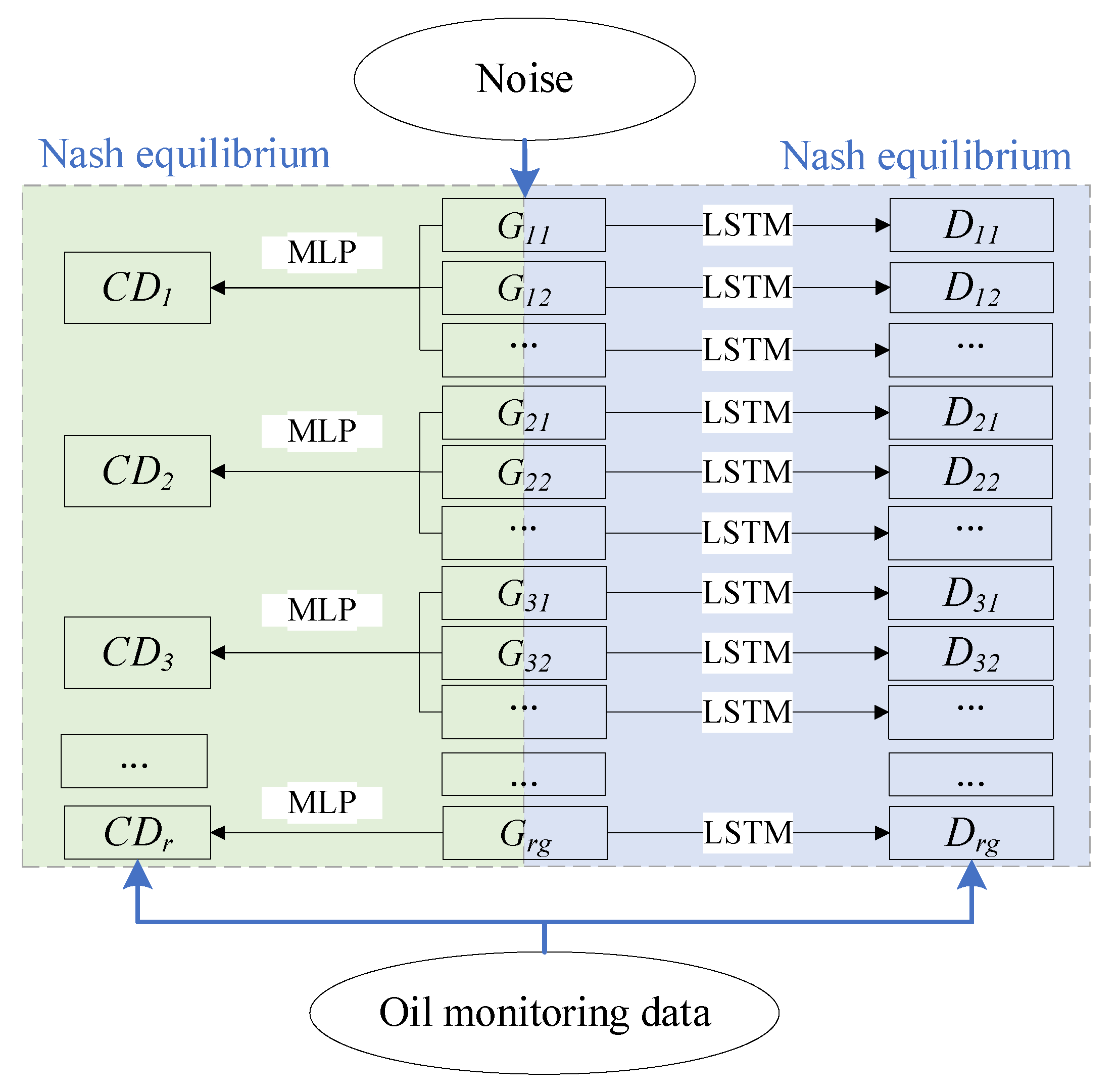
2.2. CMC-GAN Network Architecture
2.3. Quantitative Characterization of Fuzzy Membership
3. Modeling for RUL Prediction
3.1. Wear State Modelling
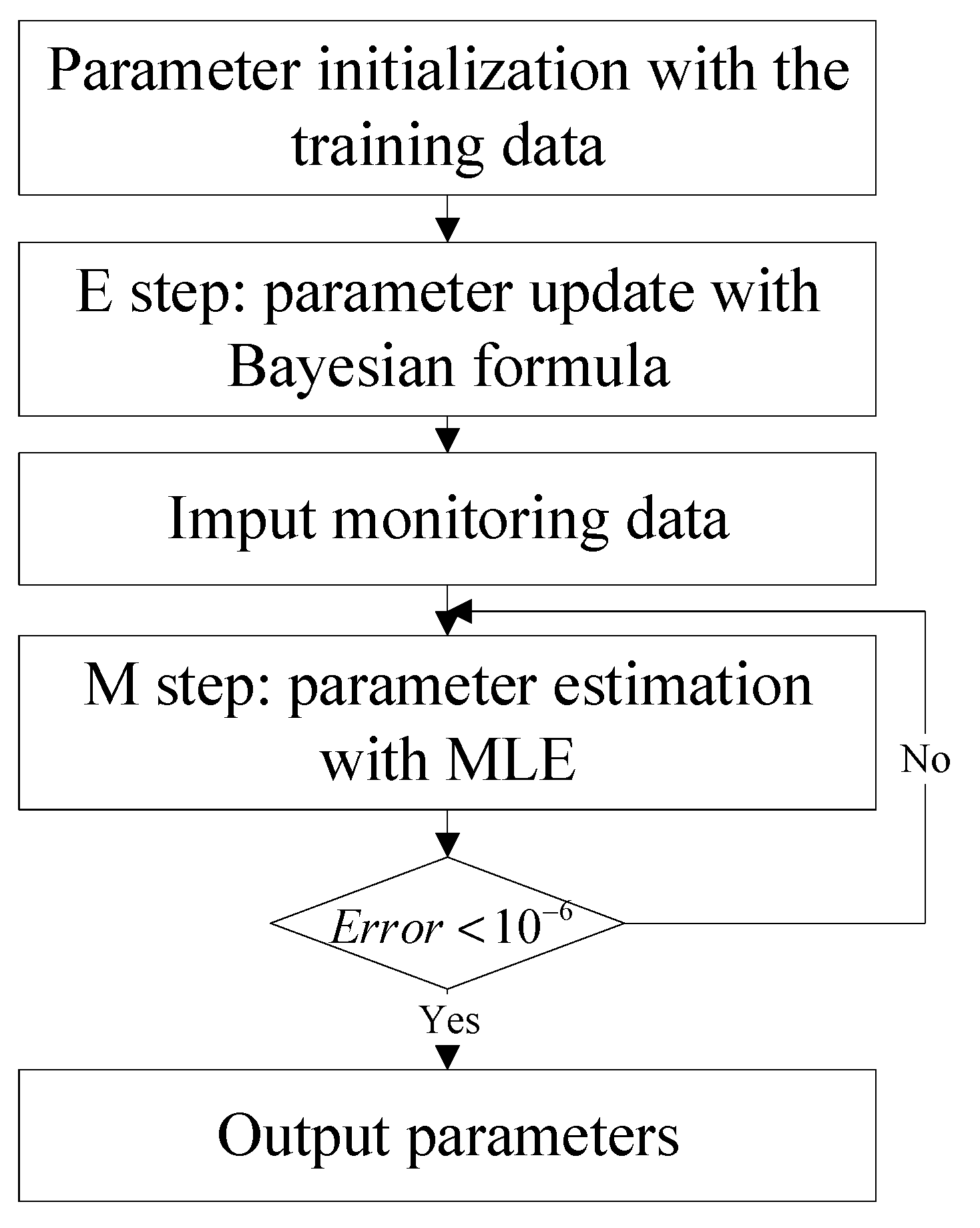
3.2. Parameter Updates
4. Case Study
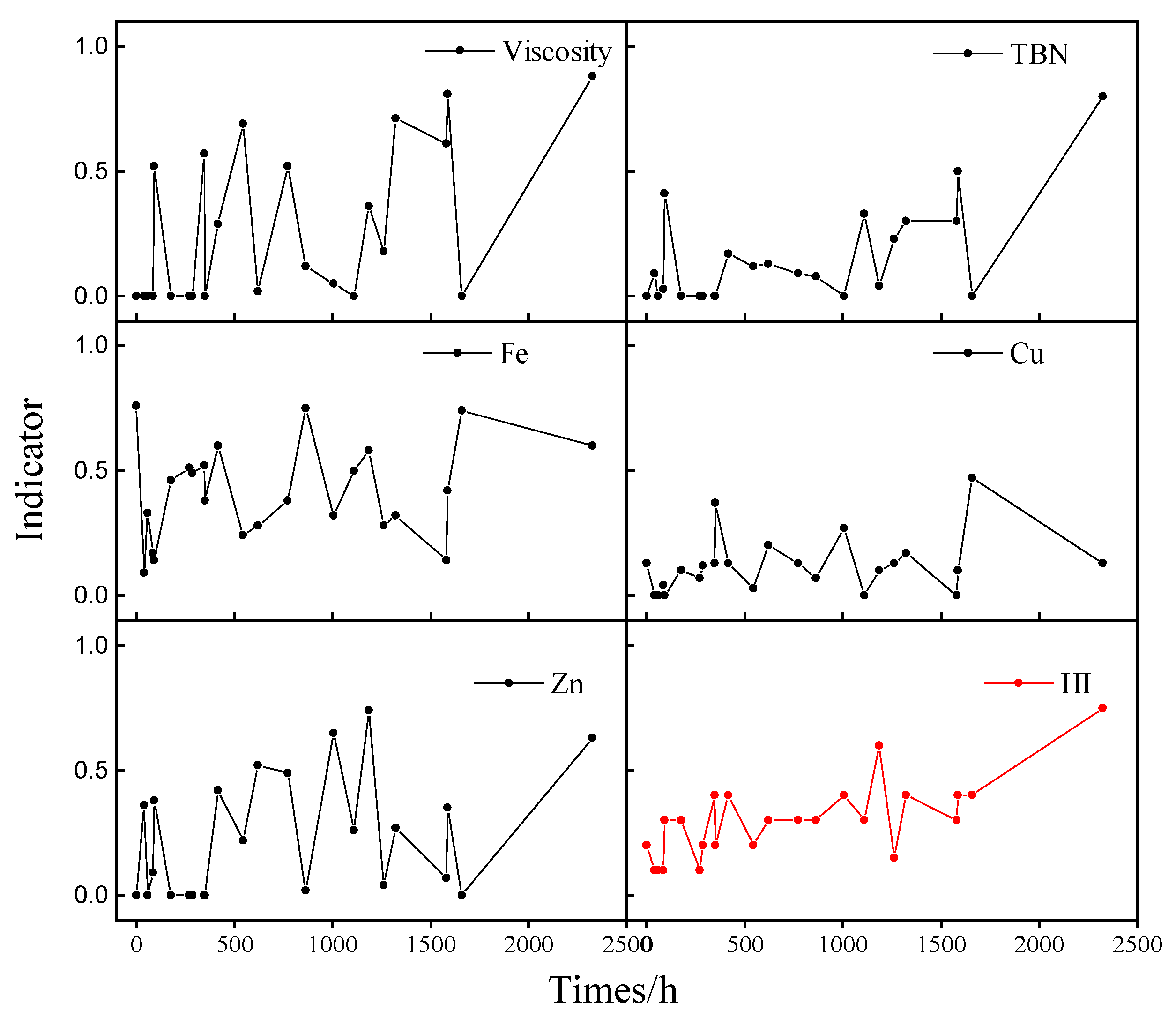
4.1. Case 1
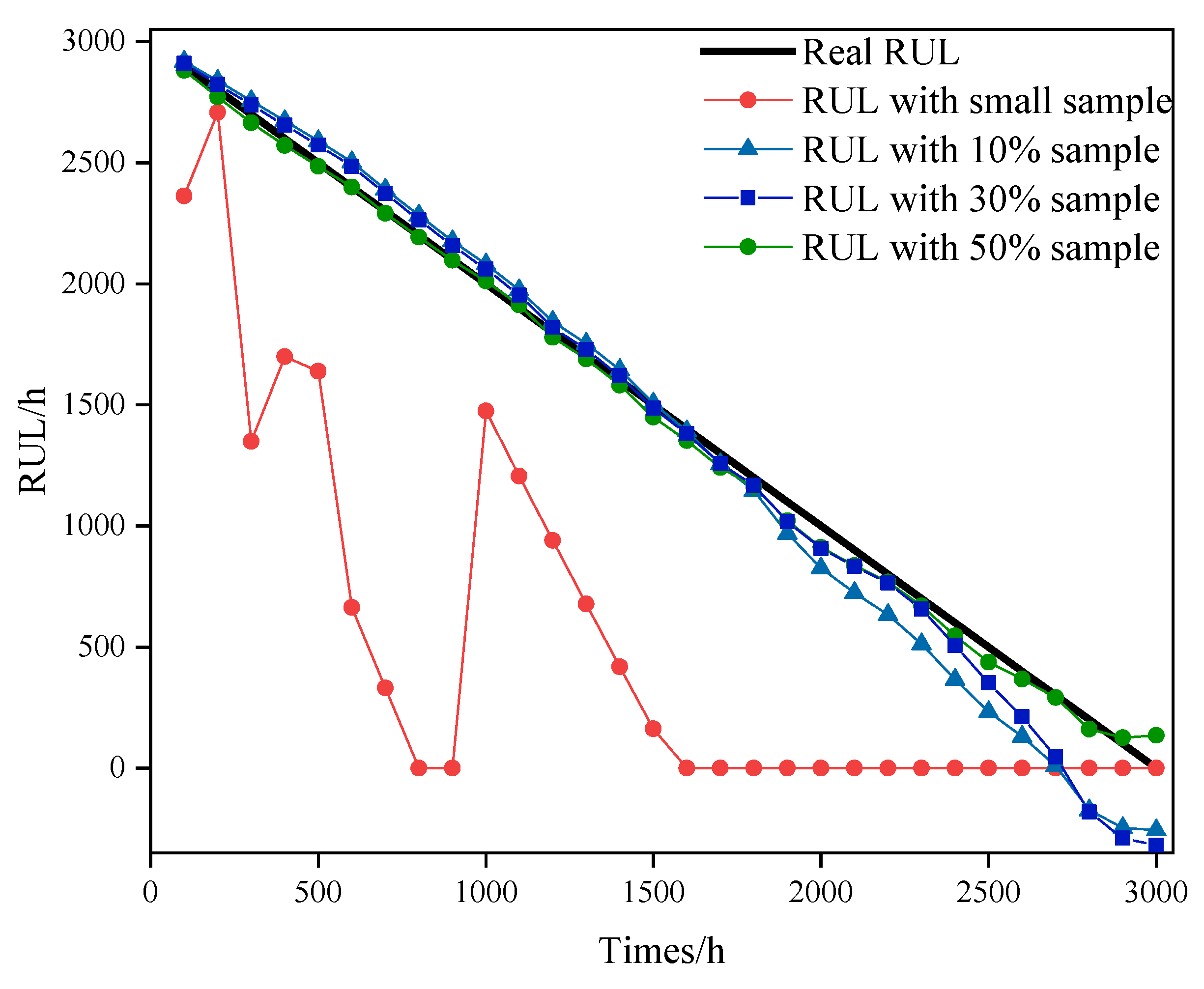
4.2. Case 2
5. Conclusions
- 1.
- CMC-GAN is adopted to achieve the augmentation of oil small-sample data and the HI indexes of joint multi-attribute quantitative characterization can comprehensively reflect the integrated wear state, guaranteeing the accuracy of RUL prediction.
- 2.
- The model is constructed based on the Wiener process with the EM algorithm for parameter update, reflecting the gradual degradation trend of the wear state, which more accurately predicts the oil RUL.
- 3.
- The proposed method shows superior performance through a real case study. It can be seen that the HI has the best monotonic trend by calculating , which provides the guarantee for RUL prediction.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pan, Y.; Han, Z.; Wu, T.; Lei, Y. Remaining Useful Life Prediction of Lubricating Oil with Small Samples. IEEE Trans. Ind. Electron. 2023, 70, 7373–7381. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Hao, M.; Wu, D. Prediction of RUL of Lubricating Oil Based on Information Entropy and SVM. Lubricants 2023, 11, 121. [Google Scholar] [CrossRef]
- Wang, S.; Tian, Y.; Hu, X.; Wang, J.; Han, J.; Liu, Y.; Wang, J.; Wang, D. Identification of Grinding Wheel Wear States Using AE Monitoring and HHT-RF Method. Wear 2025, 562–563, 205668. [Google Scholar] [CrossRef]
- Wang, Y.; E, S.; Yang, K.; Xie, B.; Lu, F. Reliability-Based Robust Design Optimization with Fourth-Moment Method for Ball Bearing Wear. Lubricants 2024, 12, 293. [Google Scholar] [CrossRef]
- Morgan, I.; Liu, H.; Tormos, B.; Sala, A. Detection and Diagnosis of Incipient Faults in Heavy-Duty Diesel Engines. IEEE Trans. Ind. Electron. 2010, 57, 3522–3532. [Google Scholar] [CrossRef]
- Stein, G.J.; Randall, R.B. Vibration-Based Condition Monitoring (Industrial, Aerospace and Automotive Applications). Stroj. Cas. 2011, 62, e977668. [Google Scholar]
- Matania, O.; Bachar, L.; Bechhoefer, E.; Bortman, J. Signal Processing for the Condition-Based Maintenance of Rotating Machines via Vibration Analysis: A Tutorial. Sensors 2024, 24, 17. [Google Scholar] [CrossRef]
- Tambadou, M.S.; Chao, D.; Duan, C. Lubrication Oil Anti-Wear Property Degradation Modeling and Remaining Useful Life Estimation of the System Under Multiple Changes Operating Environment. IEEE Access 2019, 7, 96775–96786. [Google Scholar] [CrossRef]
- Wei, L.; Duan, H.; Jia, D.; Jin, Y.; Chen, S.; Liu, L.; Liu, J.; Sun, X.; Li, J. Motor oil condition evaluation based on on-board diagnostic system. Friction 2020, 8, 95–106. [Google Scholar] [CrossRef]
- Wang, W.; Hussin, B. Plant residual time modelling based on observed variables in oil samples. J. Oper. Res. Soc. 2009, 60, 789–796. [Google Scholar] [CrossRef]
- Makis, V.; Wu, J.; Gao, Y. An application of DPCA to oil data for CBM modeling. Eur. J. Oper. Res. 2006, 174, 112–123. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, X.; Liu, G.; Liu, Y. Life cycle cost analysis considering multiple dependent degradation processes and environmental influence. Reliab. Eng. Syst. Saf. 2020, 197, 106784. [Google Scholar] [CrossRef]
- Özcan, M.M.; Kutbay, U. Improving Predictive Maintenance Performance in Limited Data Environment with CGAN. In Proceedings of the 2024 9th International Conference on Computer Science and Engineering (UBMK), Antalya, Turkiye, 26–28 October 2024; pp. 1–6. [Google Scholar] [CrossRef]
- He, X.; Ding, C.; Qiao, F.; Shi, J. An Incremental Remaining Useful Life Prediction Method Based on Wasserstein GAN and Knowledge Distillation. In Proceedings of the 2024 IEEE International Conference on Systems, Man and Cybernetics (SMC), Kuching, Malaysia, 7–10 October 2024; pp. 3857–3862. [Google Scholar] [CrossRef]
- Urban, A.; Zhe, J. A microsensor array for diesel engine lubricant monitoring using deep learning with stochastic global optimization. Sens. Actuators A Phys. 2022, 343, 113671. [Google Scholar] [CrossRef]
- Wang, W.; Hussin, B.; Jefferis, T. A case study of condition based maintenance modelling based upon the oil analysis data of marine diesel engines using stochastic filtering. Int. J. Prod. Econ. 2012, 136, 84–92. [Google Scholar] [CrossRef]
- Vališ, D.; Žák, L.; Pokora, O.; Lánský, P. Perspective analysis outcomes of selected tribodiagnostic data used as input for condition based maintenance. Reliab. Eng. Syst. Saf. 2016, 145, 231–242. [Google Scholar] [CrossRef]
- Vališ, D.; Forbelská, M.; Vintr, Z.; La, Q.T.; Leuchter, J. Perspective estimation of light emitting diode reliability measures based on multiply accelerated long run stress testing backed up by stochastic diffusion process. Measurement 2023, 206, 112222. [Google Scholar] [CrossRef]
- Pan, Y.; Wu, T.; Jing, Y.; Han, Z.; Lei, Y. Remaining useful life prediction of lubrication oil by integrating multi-source knowledge and multi-indicator data. Mech. Syst. Signal Process. 2023, 191, 110174. [Google Scholar] [CrossRef]
- Pan, Y.; Jing, Y.; Wu, T.; Kong, X. Knowledge-based data augmentation of small samples for oil condition prediction. Reliab. Eng. Syst. Saf. 2022, 217, 108114. [Google Scholar] [CrossRef]
- Hönig, V.; Procházka, P.; Obergruber, M.; Kučerová, V.; Mejstřík, P.; Macků, J.; Bouček, J. Determination of Tractor Engine Oil Change Interval Based on Material Properties. Materials 2020, 13, 5403. [Google Scholar] [CrossRef]
- Pan, Y.; Wu, T.; Jing, Y.; Wang, P. Multiattribute Modeling for Oil Condition Assessment Considering Uncertainties. IEEE Trans. Instrum. Meas. 2022, 71, 3509908. [Google Scholar] [CrossRef]
- Xu, F.; Yang, S.; Liang, B. Interval set-membership estimation for continuous linear systems. Int. J. Robust Nonlinear Control. 2020, 30, 5305–5321. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Process |
|---|---|
| Step 1 | Apply LSTM to construct generators and discriminators of GAN networks; |
| Step 2 | Take a random noise vector as the input of generator, which maps through a fully connected layer (Linear layer) to the target data space to output the final data sequence, the loss function is selected as the binary cross entropy loss; |
| Step 3 | The input of the discriminator is a sequence of real data and a sequence of data generated by the generator, which is mapped to a single output node through multiple LSTM fully connected layers, using a binary cross-entropy loss to assure that the prediction of the real data is close to 1, and the prediction of the generated data is close to 0; |
| Step 4 | The central discriminator receives the fusion of time series generated by all channel generators as a multivariate time series, which is structured as a Linear layer, a LeakyReLU activation function and a Dropout layer; |
| Step 5 | Import the simulation sample sequence and train the objective function optimization based on Equation (4) until finish training, ; |
| Step 6 | Apply Equations (13)–(16) to estimate the trajectory parameters for the control guided model, and obtain the model temporal parameter set ; |
| Step 7 | Substitute the updated parameter expectations into Equation (17) to obtain the trajectory tracking data. |
| Number | RUL | Real Data of Fe | 10% Predicted Data of Fe | 30% Predicted Data of Fe | 50% Predicted Data of Fe |
|---|---|---|---|---|---|
| h | ppm | ppm | ppm | ppm | |
| 1 | 290 | 15.40 | 12.61 | 13.87 | 18.27 |
| 2 | 280 | 15.95 | 12.86 | 13.98 | 18.25 |
| 3 | 270 | 16.33 | 13.32 | 14.24 | 18.25 |
| 4 | 260 | 17.08 | 13.96 | 14.69 | 18.32 |
| 5 | 250 | 17.95 | 14.73 | 15.32 | 18.49 |
| 6 | 240 | 18.79 | 15.59 | 16.12 | 18.80 |
| 7 | 230 | 18.98 | 16.54 | 17.04 | 19.24 |
| 8 | 220 | 19.59 | 17.55 | 18.03 | 19.77 |
| 9 | 210 | 20.33 | 18.59 | 19.04 | 20.39 |
| 10 | 200 | 21.32 | 19.60 | 20.04 | 21.08 |
| 11 | 190 | 22.08 | 20.57 | 21.00 | 21.84 |
| 12 | 180 | 22.31 | 21.50 | 21.95 | 22.69 |
| 13 | 170 | 23.43 | 22.47 | 22.93 | 23.62 |
| 14 | 160 | 24.30 | 23.52 | 23.96 | 24.62 |
| 15 | 150 | 24.83 | 24.72 | 25.07 | 25.67 |
| 16 | 140 | 25.94 | 26.06 | 26.26 | 26.71 |
| 17 | 130 | 26.78 | 27.48 | 27.45 | 27.72 |
| 18 | 120 | 28.10 | 28.94 | 28.59 | 28.67 |
| 19 | 110 | 28.40 | 30.36 | 29.62 | 29.58 |
| 20 | 100 | 29.20 | 31.74 | 30.57 | 30.49 |
| 21 | 90 | 30.54 | 33.10 | 31.51 | 31.45 |
| 22 | 80 | 32.04 | 34.47 | 32.56 | 32.49 |
| 23 | 70 | 33.18 | 35.88 | 33.81 | 33.62 |
| 24 | 60 | 34.04 | 37.35 | 35.37 | 34.82 |
| 25 | 50 | 35.16 | 38.92 | 37.25 | 36.03 |
| 26 | 40 | 36.75 | 40.57 | 39.42 | 37.20 |
| 27 | 30 | 38.14 | 42.24 | 41.72 | 38.27 |
| 28 | 20 | 38.65 | 43.80 | 43.91 | 39.19 |
| 29 | 10 | 40.24 | 45.04 | 45.65 | 39.88 |
| 30 | 0 | 42.14 | 45.74 | 46.62 | 40.24 |
| Indicator | Viscosity | TBN | Fe | Cu | Zn | HI |
|---|---|---|---|---|---|---|
| 0.45 | 0.82 | 0.35 | 0.30 | 0.65 | 0.85 |
| Indicator Type | Data Processing | Test-1 | Test-2 | Test-3 | Test-4 |
|---|---|---|---|---|---|
| Fusion method | FIS fusion | 0.7134 | 0.3356 | 0.4802 | 0.4372 |
| Selection fusion | 0.3589 | 0.7188 | 0.2729 | 0.4852 | |
| CMC-GAN | 0.9765 | 0.9343 | 0.9927 | 0.9215 | |
| Single indicator | Viscosity | 0.2617 | 0.4441 | 0.3321 | 0.4263 |
| TBN | 0.3112 | 0.5493 | 0.1608 | 0.6980 | |
| Fe | 0.3778 | 0.6299 | 0.6336 | 0.3588 | |
| Zn | 0.3290 | 0.4403 | 0.6983 | 0.3289 |
| Times/h | Real RUL/h | Predicted RUL with HI/h | Predicted RUL with Viscosity/h | Predicted RUL with TBN/h | Predicted RUL with Fe/h | Predicted RUL with Zn/h |
|---|---|---|---|---|---|---|
| 1500 | 2200 | 1747 | 3188 | 2992 | 3082 | 2086 |
| 2000 | 1700 | 1673 | 1573 | 2475 | 678 | 1884 |
| 1700 | 2000 | 1699 | 697 | 1649 | 1474 | 1378 |
| 2200 | 1500 | 1631 | 2116 | 2962 | 162 | 2207 |
| 400 | 3300 | 4017 | 3708 | 4323 | 3290 | 4750 |
| 2500 | 1200 | 1727 | 909 | 2034 | 0 | 3378 |
| 1600 | 2100 | 1805 | 3018 | 3192 | 0 | 2455 |
| 700 | 3000 | 3138 | 3367 | 3709 | 1931 | 4960 |
| 1000 | 2700 | 2940 | 1957 | 2711 | 1350 | 4814 |
| 3100 | 600 | 764 | 0 | 1663 | 0 | 2208 |
| Score | 0.3837 | 0.2096 | 0.1550 | 0.2127 | 0.1499 | |
| Std (Error%) | 20.46 | 48.39 | 54.86 | 47.66 | 91.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Pan, Y.; Lan, B.; Wang, H.; Huang, H. Remaining Useful Life Prediction Based on Wear Monitoring with Multi-Attribute GAN Augmentation. Lubricants 2025, 13, 145. https://doi.org/10.3390/lubricants13040145
Zhu X, Pan Y, Lan B, Wang H, Huang H. Remaining Useful Life Prediction Based on Wear Monitoring with Multi-Attribute GAN Augmentation. Lubricants. 2025; 13(4):145. https://doi.org/10.3390/lubricants13040145
Chicago/Turabian StyleZhu, Xiaojun, Yan Pan, Bin Lan, He Wang, and Huixin Huang. 2025. "Remaining Useful Life Prediction Based on Wear Monitoring with Multi-Attribute GAN Augmentation" Lubricants 13, no. 4: 145. https://doi.org/10.3390/lubricants13040145
APA StyleZhu, X., Pan, Y., Lan, B., Wang, H., & Huang, H. (2025). Remaining Useful Life Prediction Based on Wear Monitoring with Multi-Attribute GAN Augmentation. Lubricants, 13(4), 145. https://doi.org/10.3390/lubricants13040145