
A New Pest Detection Method Based on Improved YOLOv5m



Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
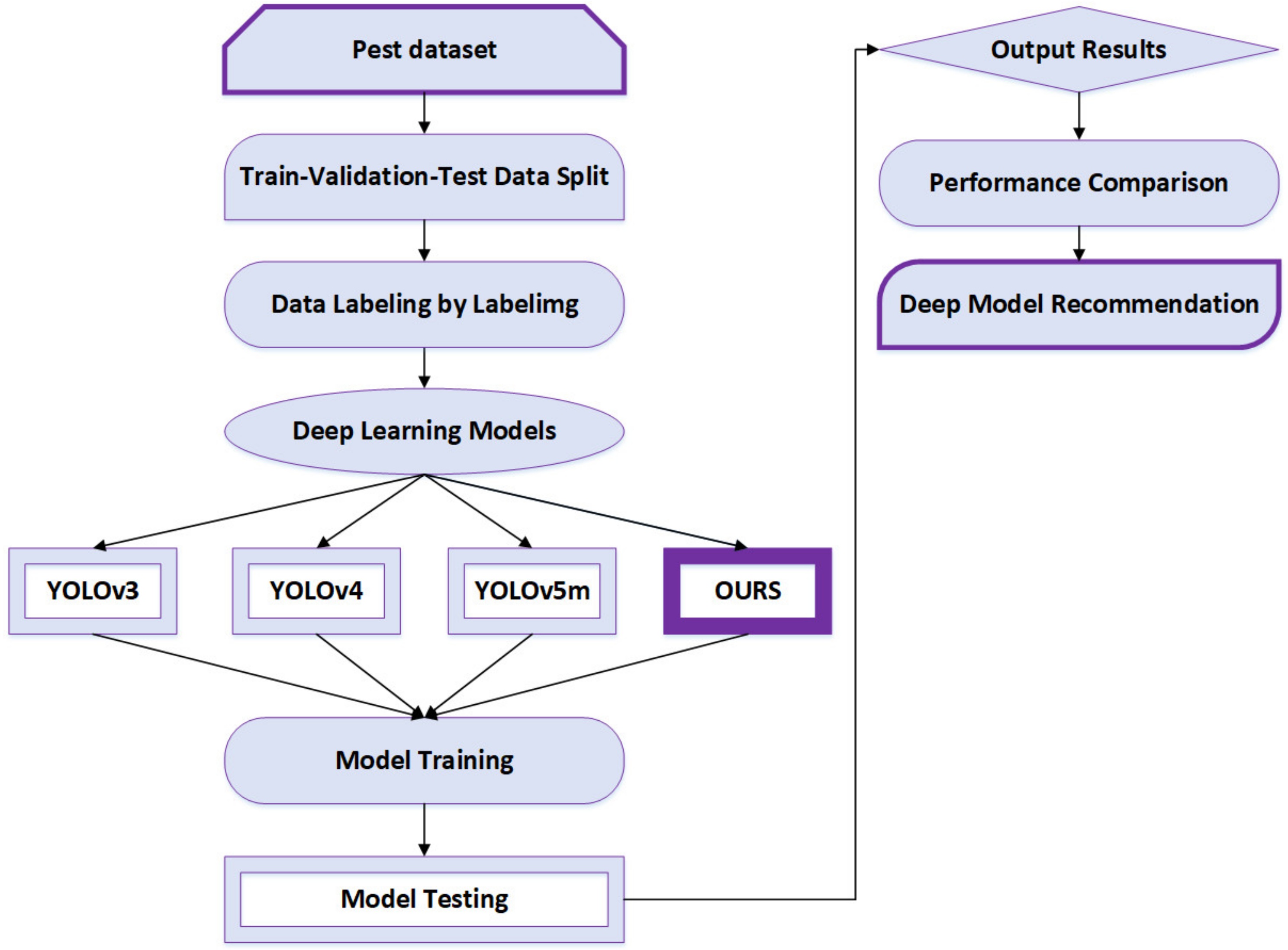
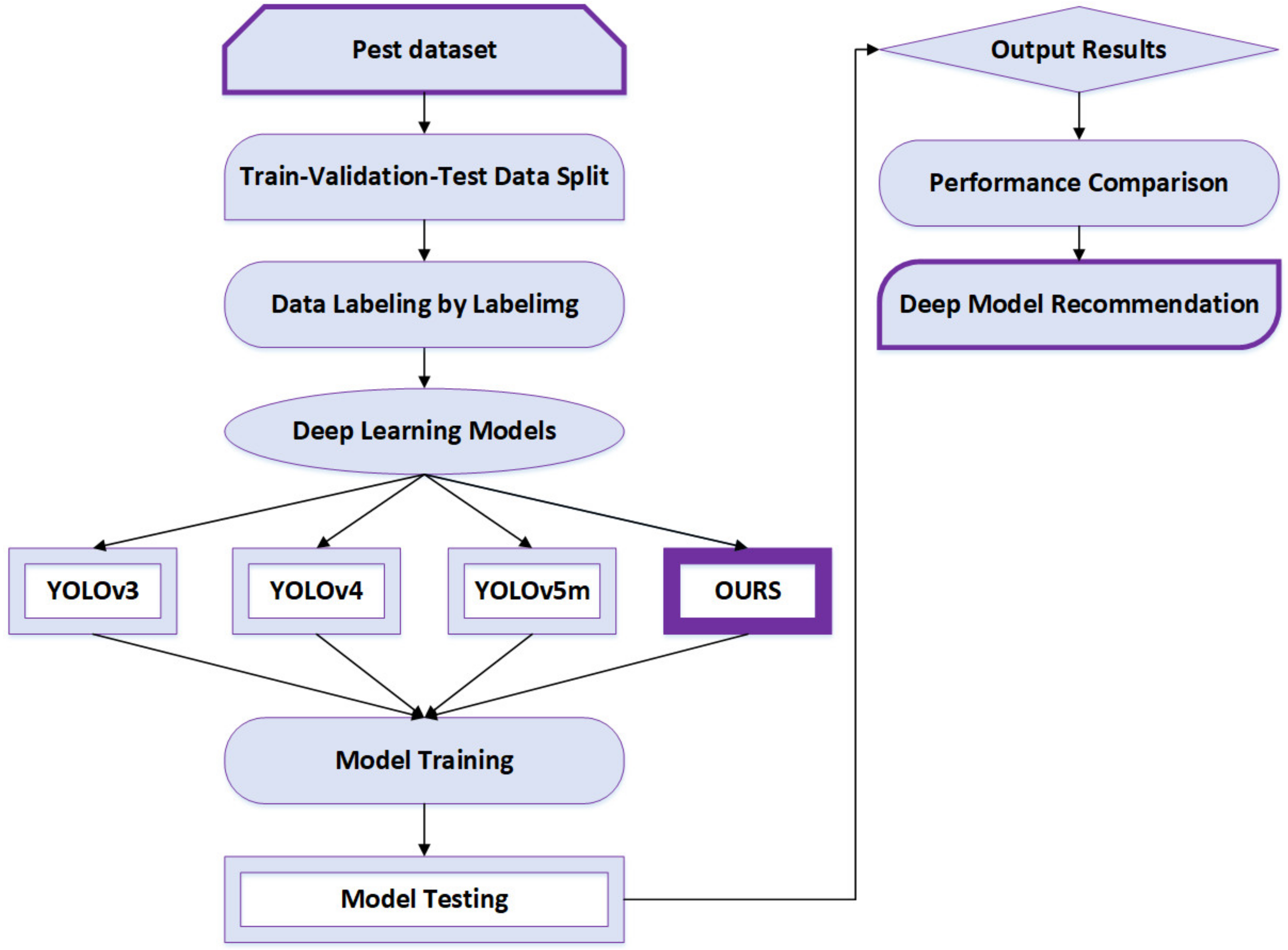
2.1. Overview
2.2. Pest Dataset
2.3. Model Design
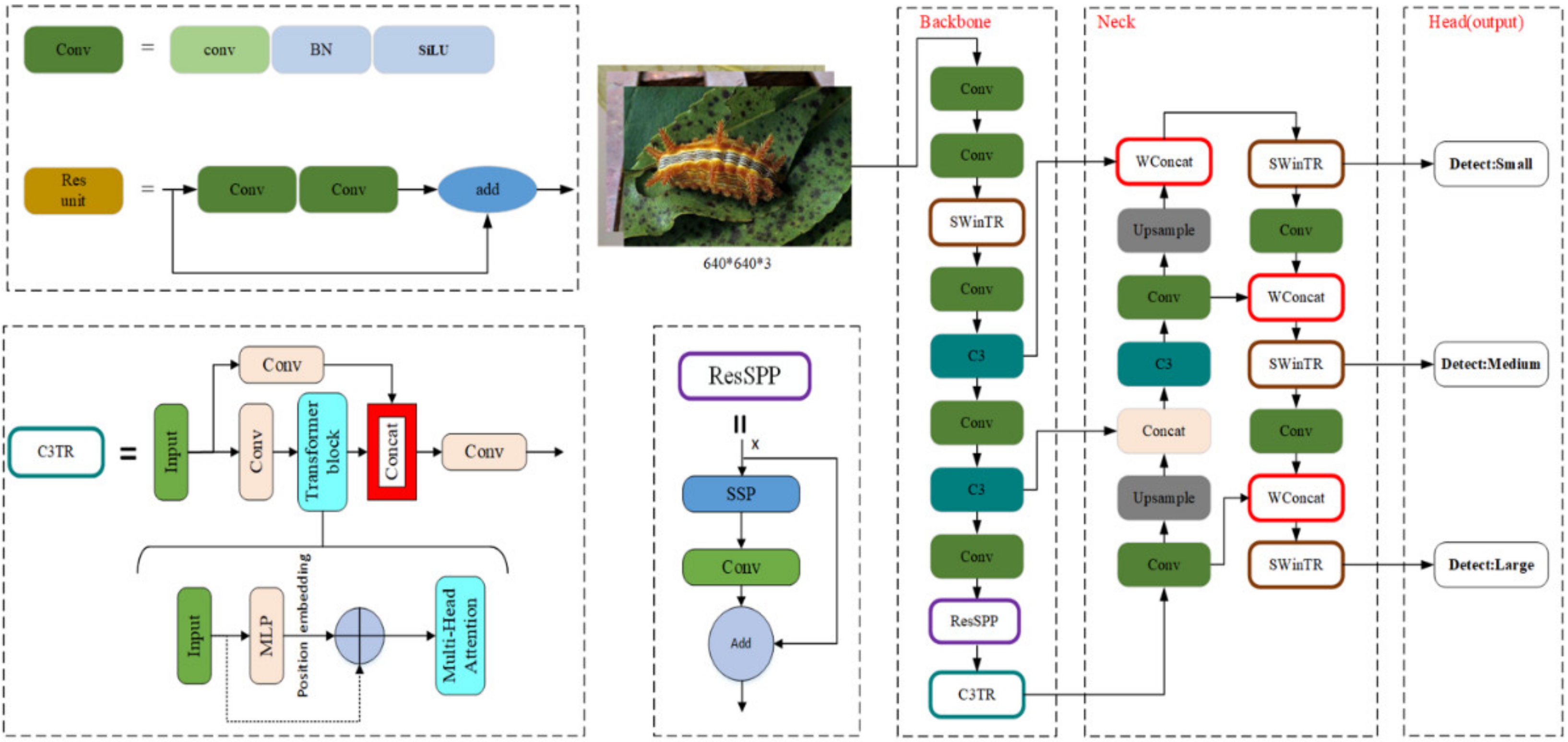
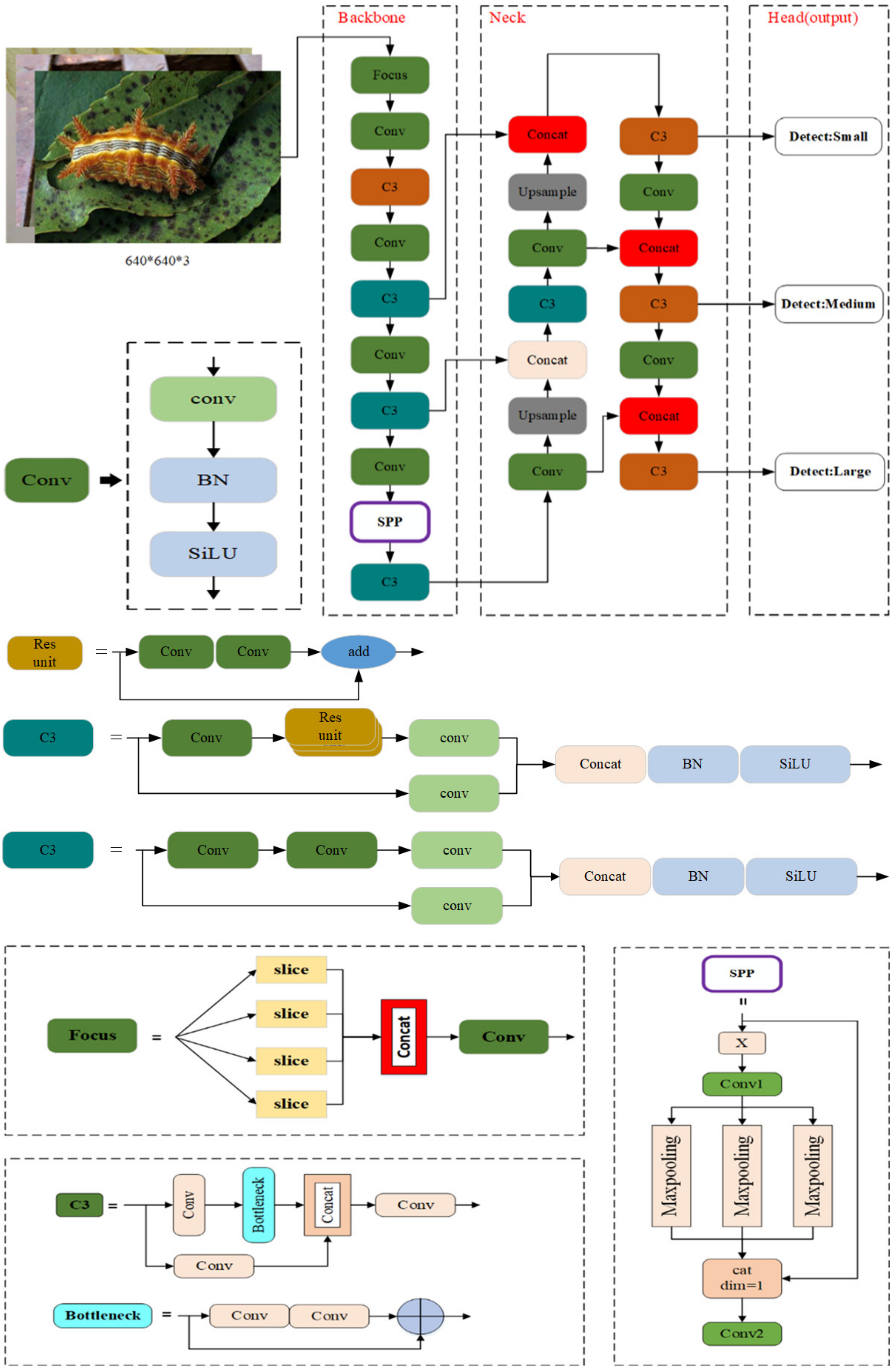
2.3.1. The Structure of YOLOv5m Model
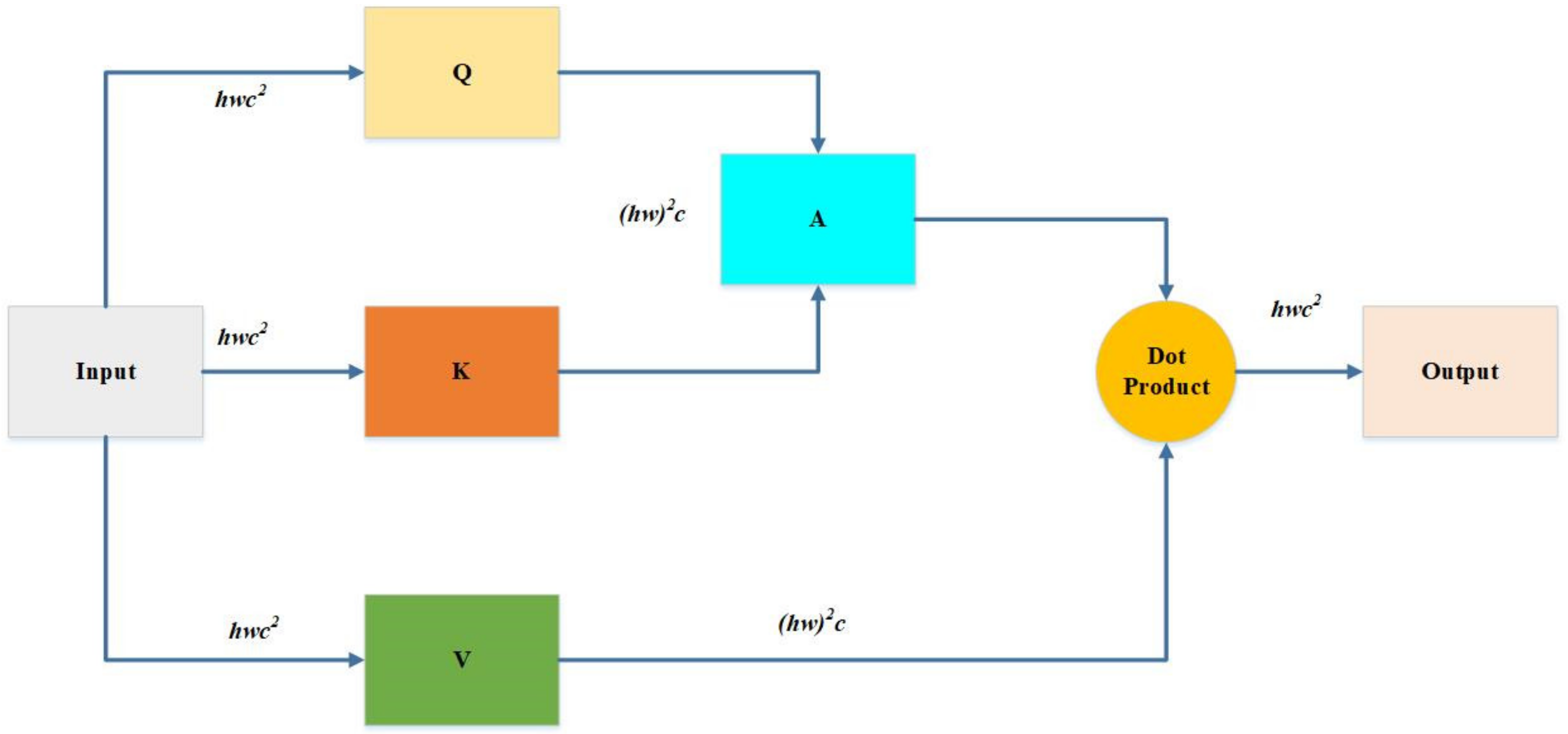
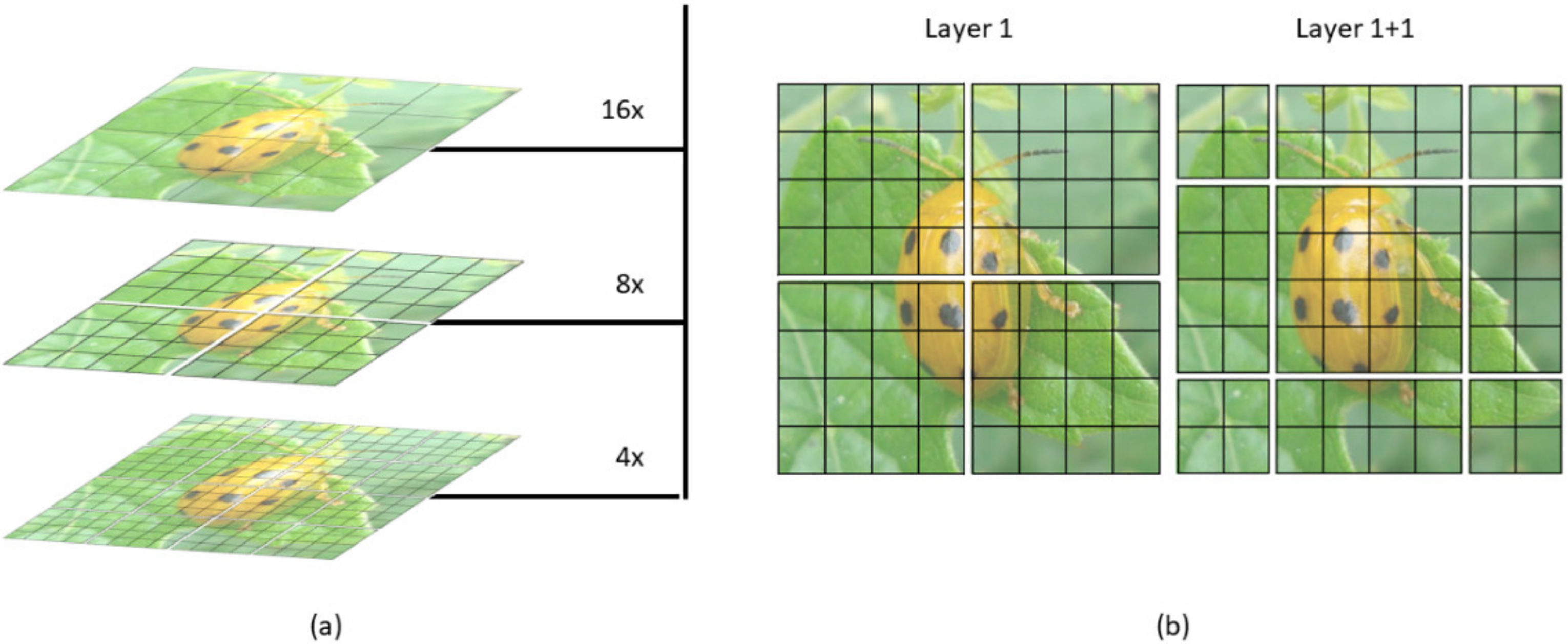
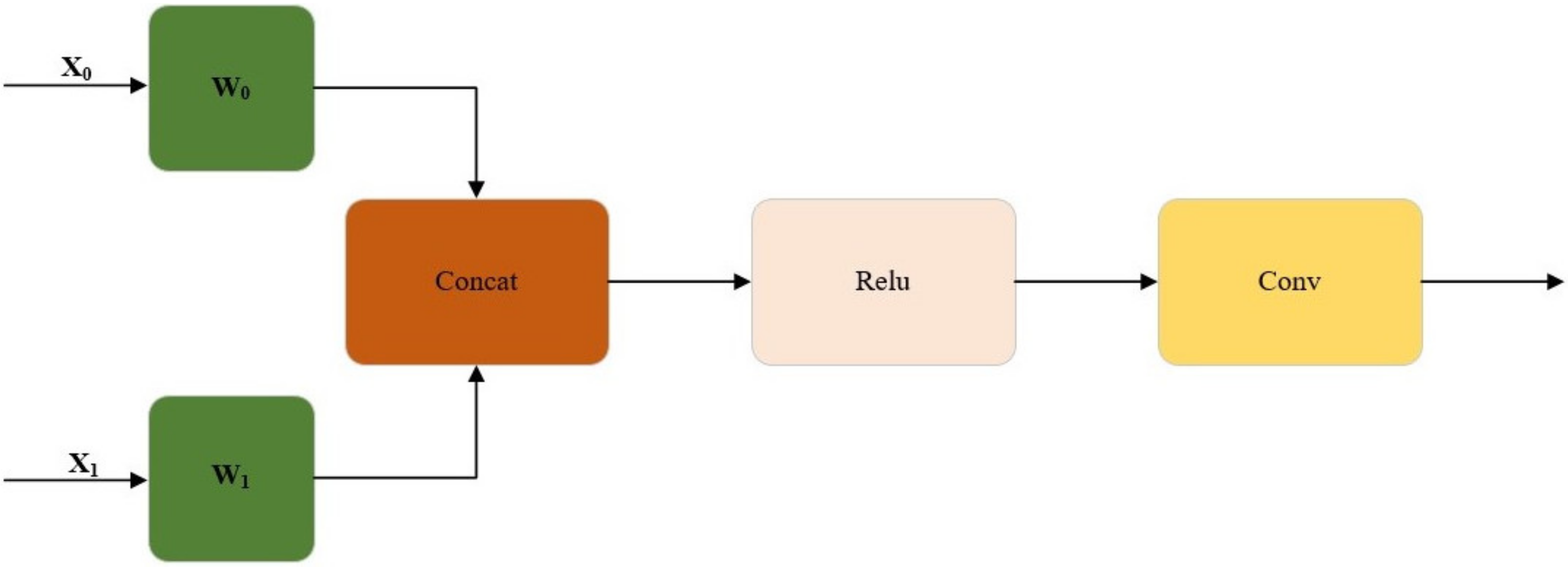
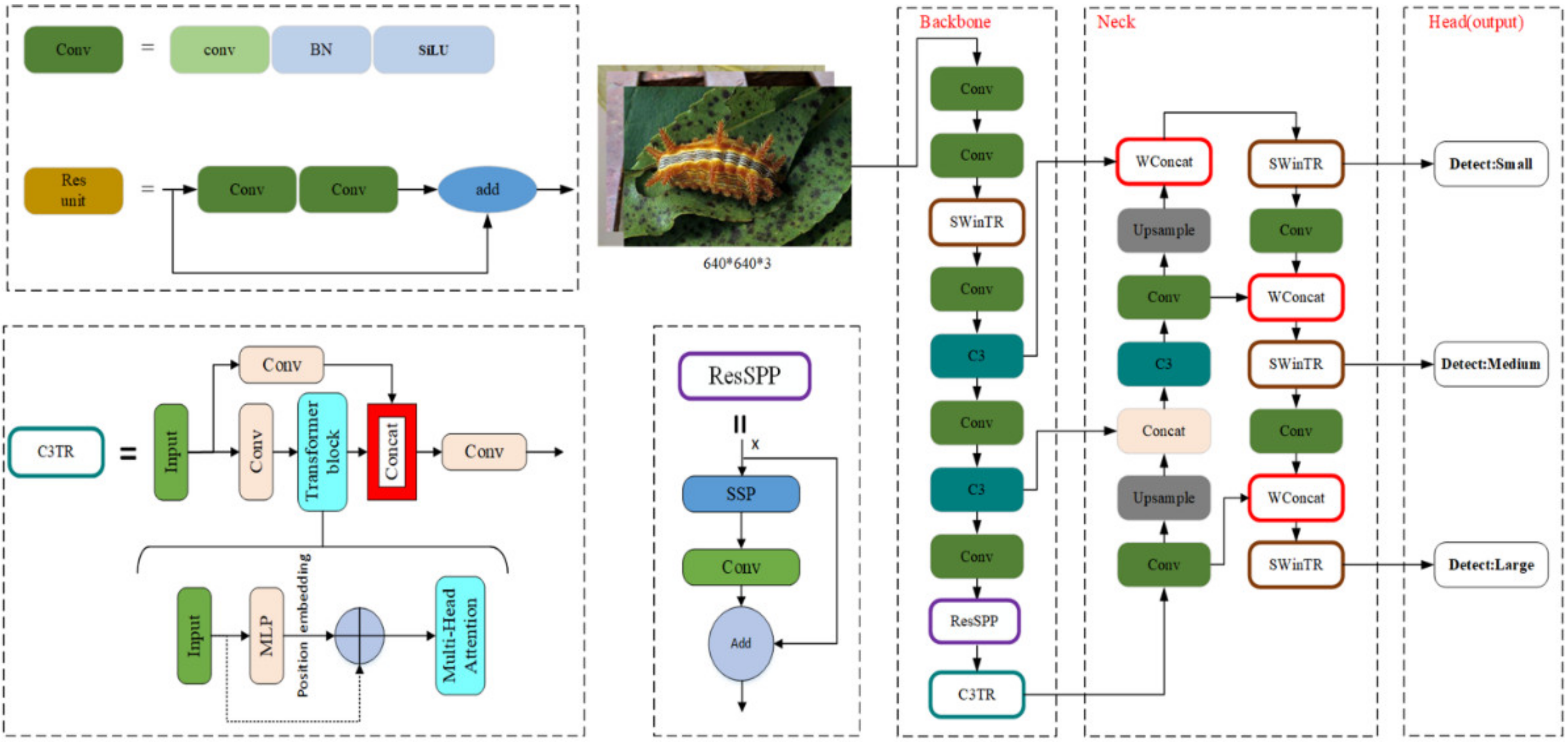
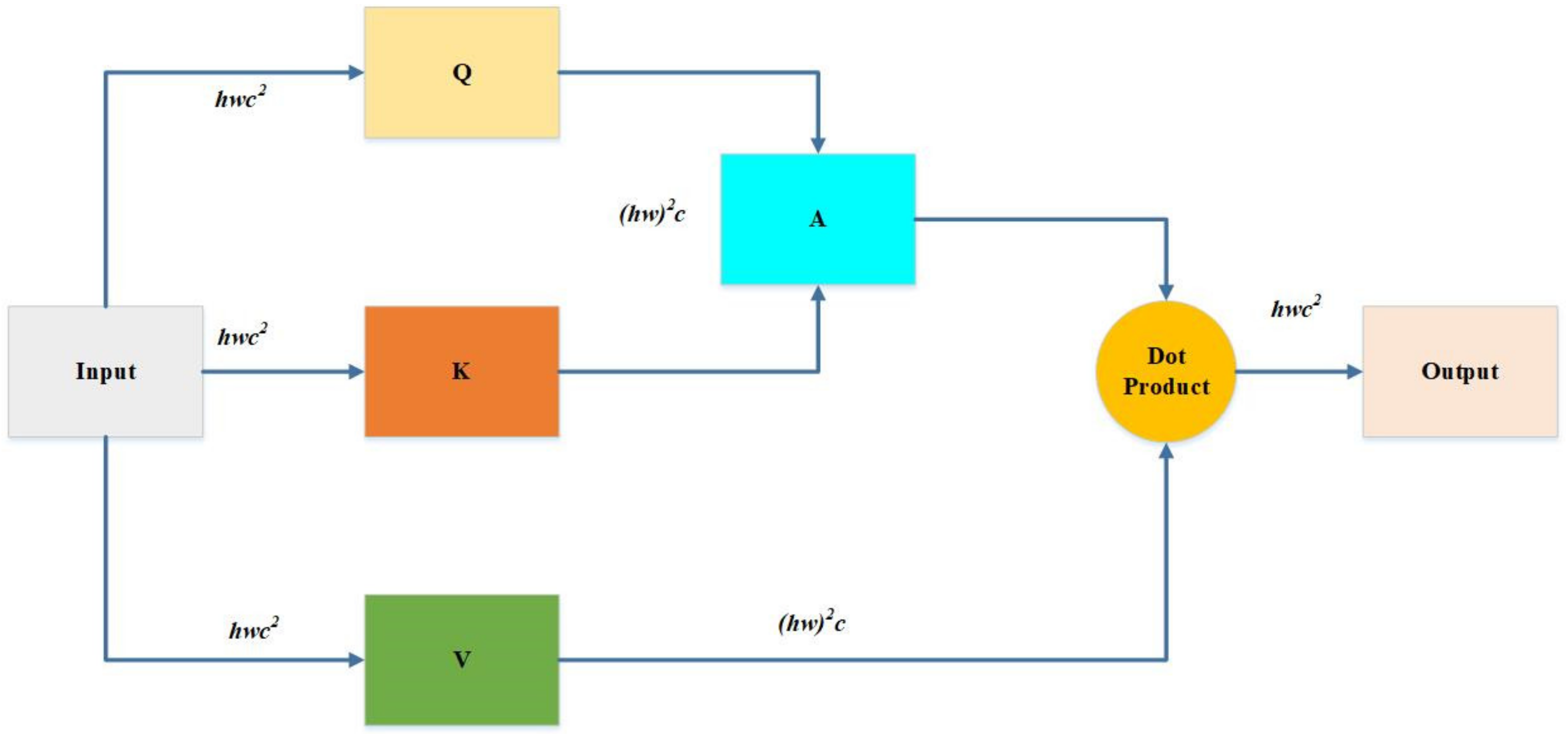
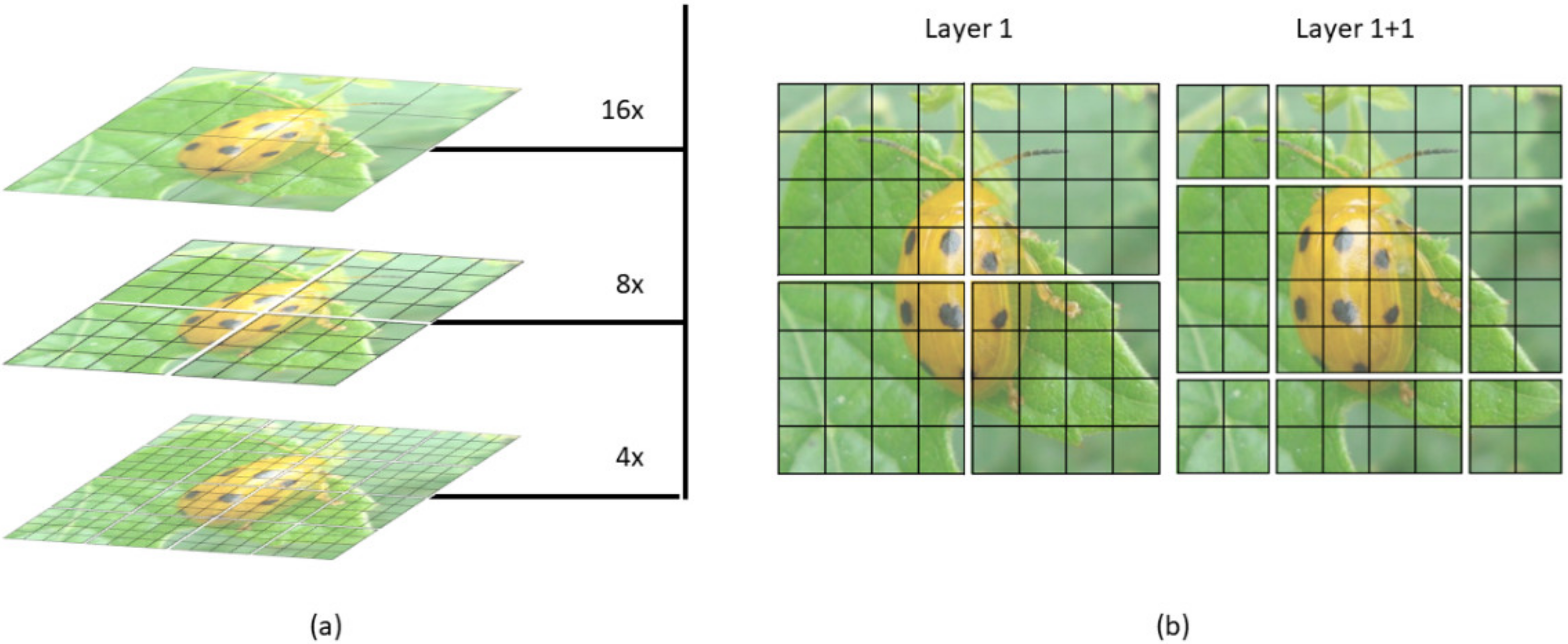
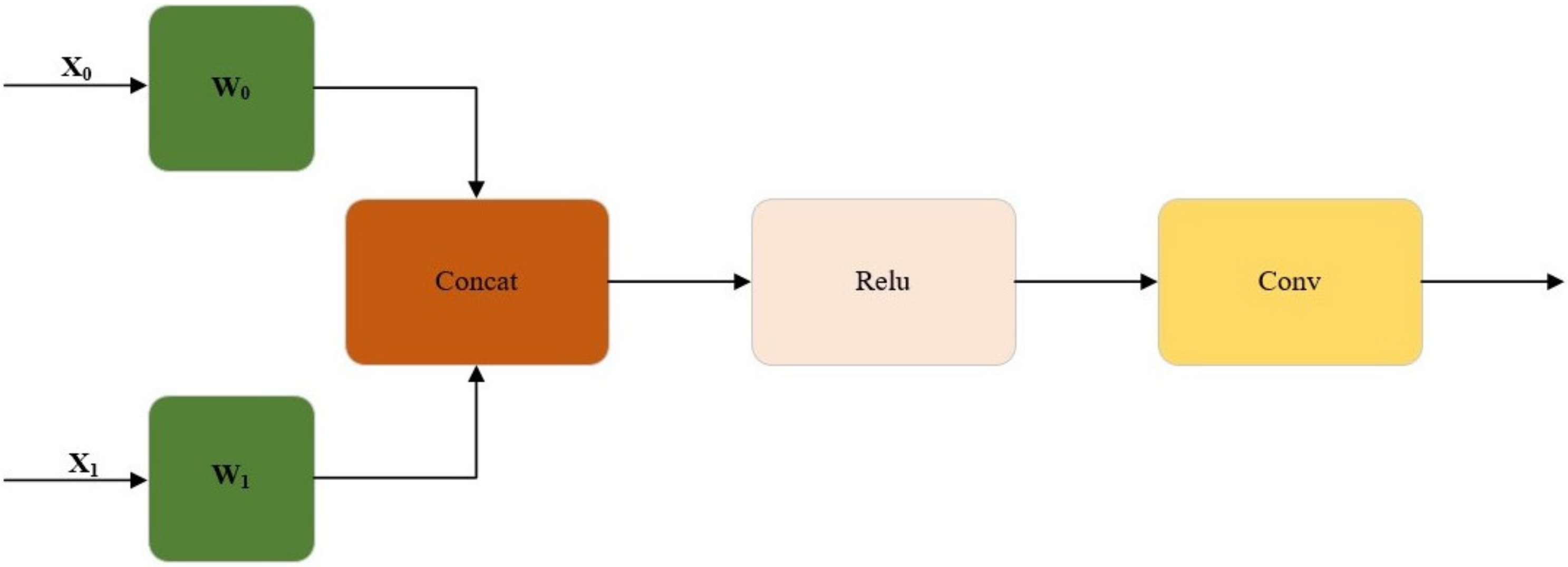
2.3.2. The Method of Improved YOLOv5m Model
3. Experimental Results and Analyses
3.1. Experimental Setting
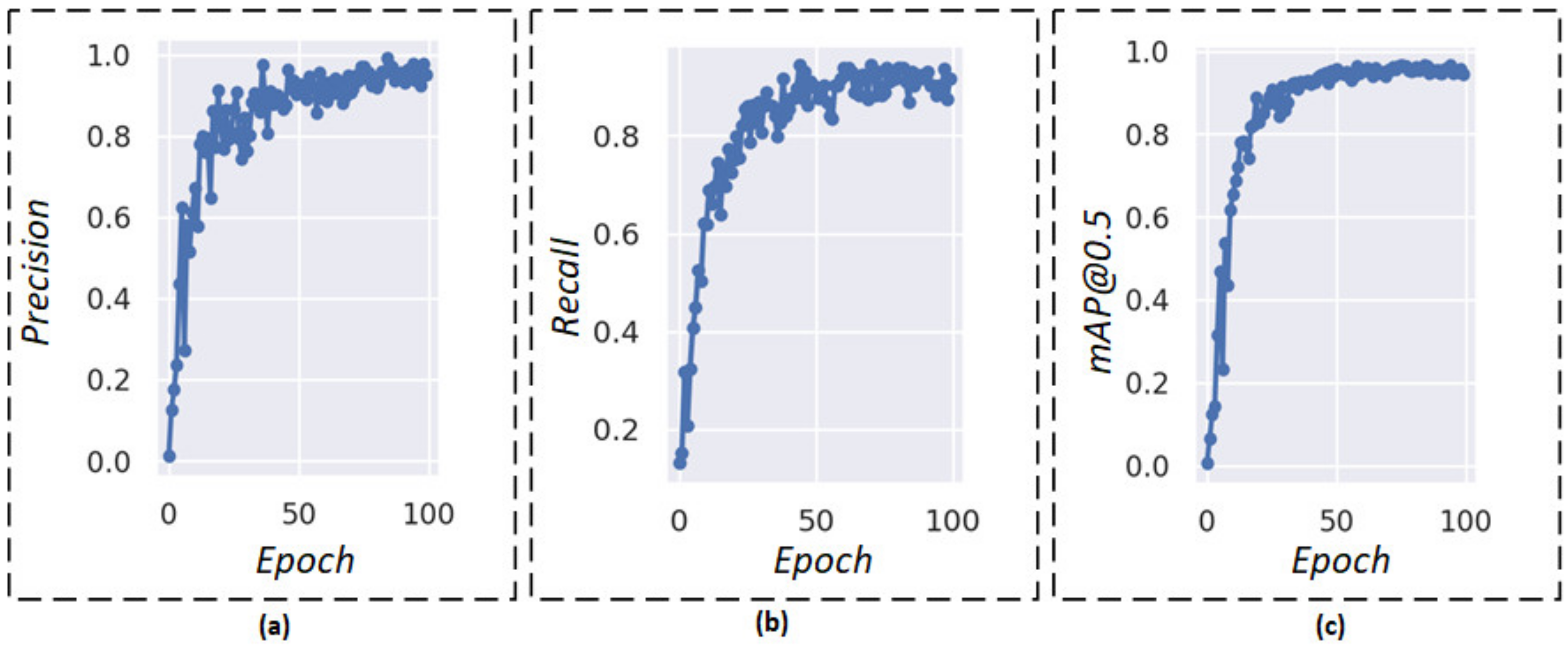
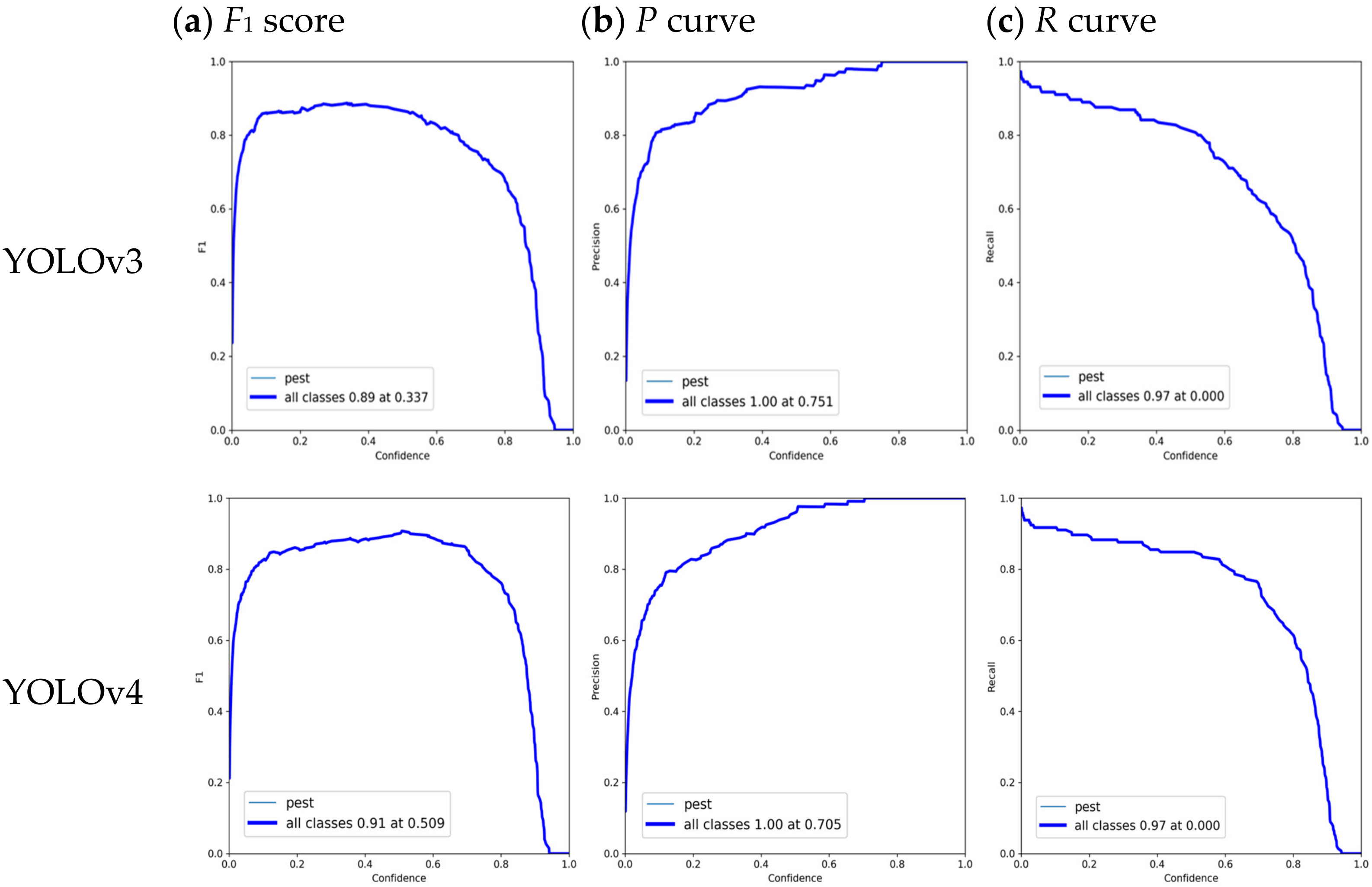
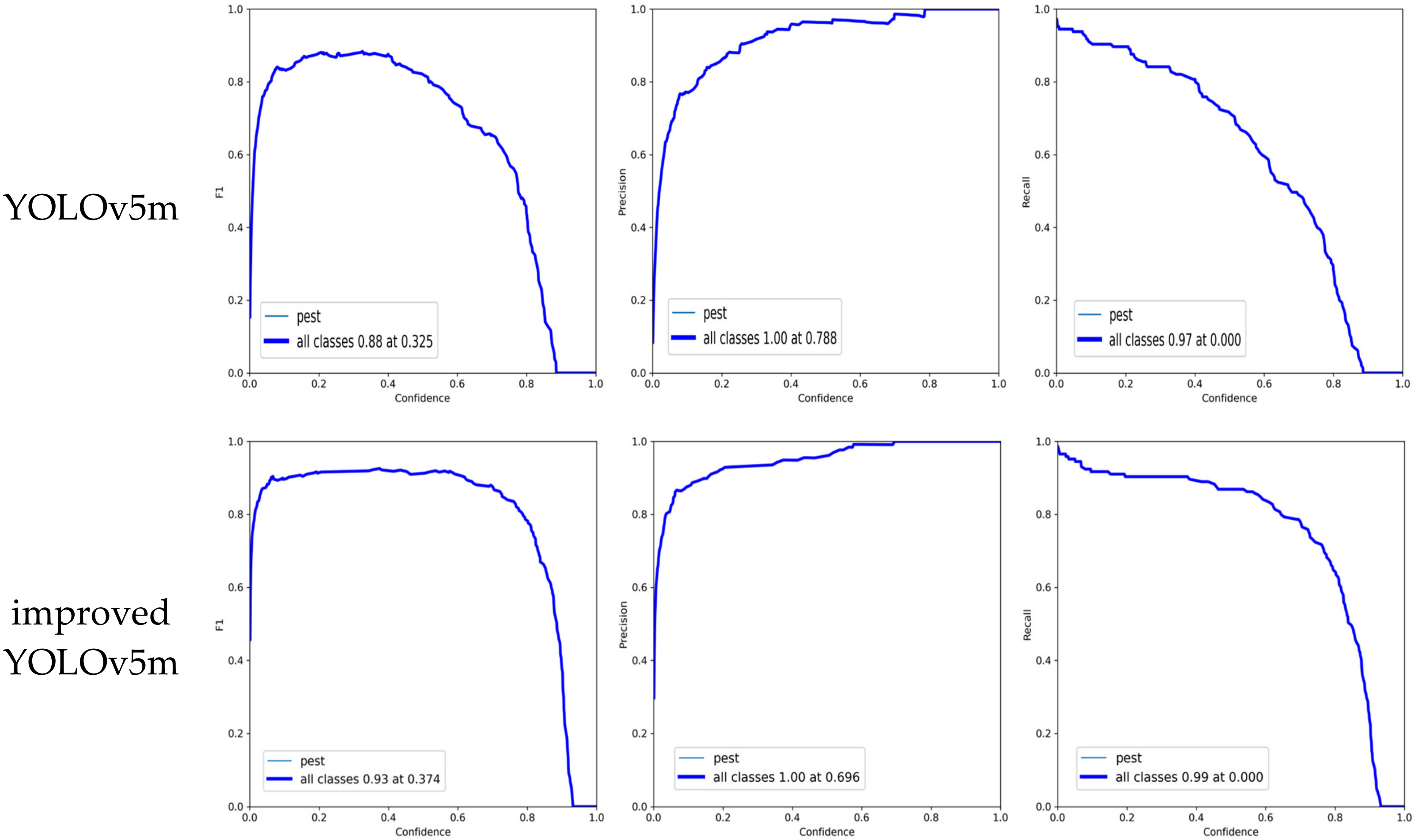
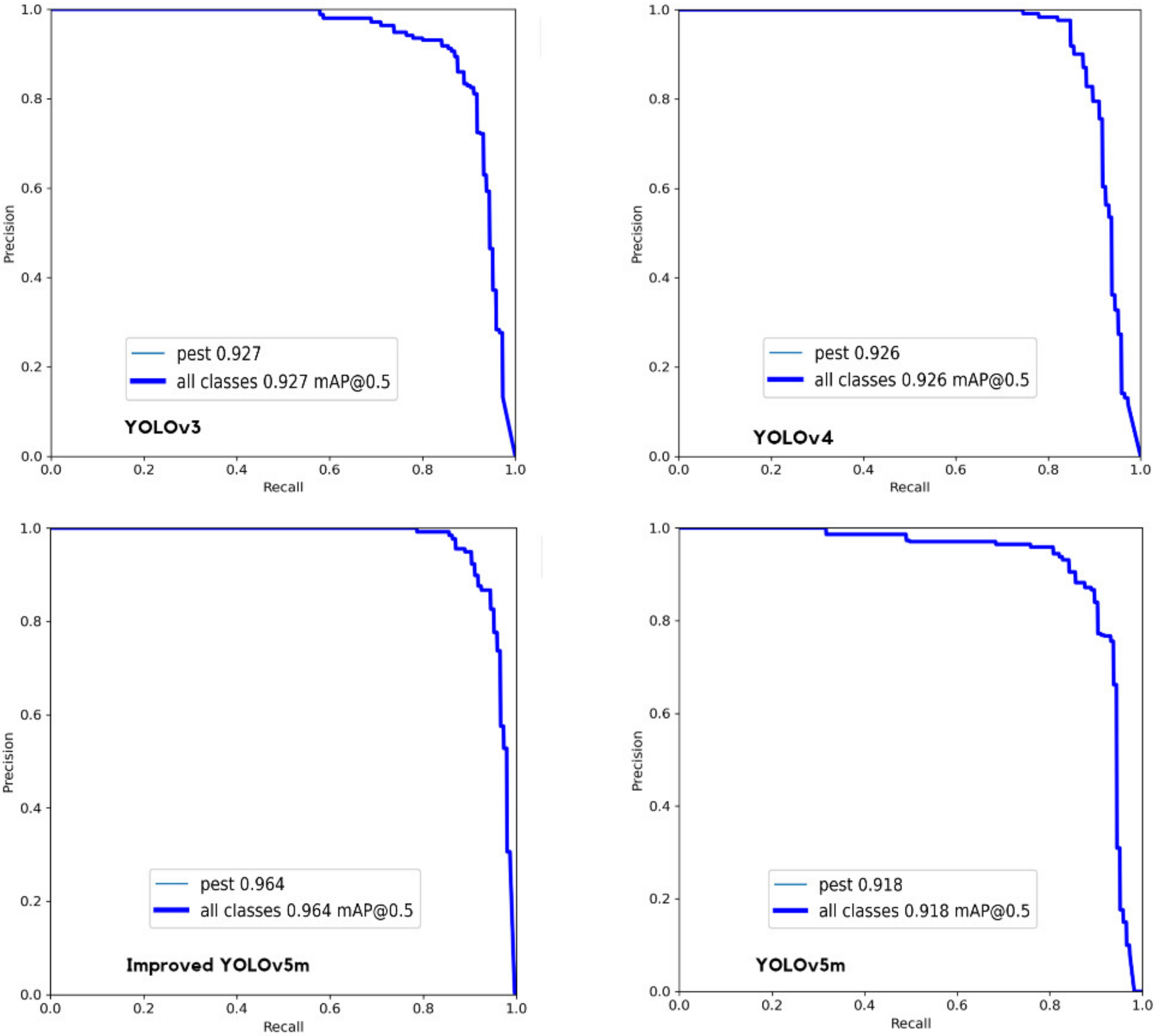
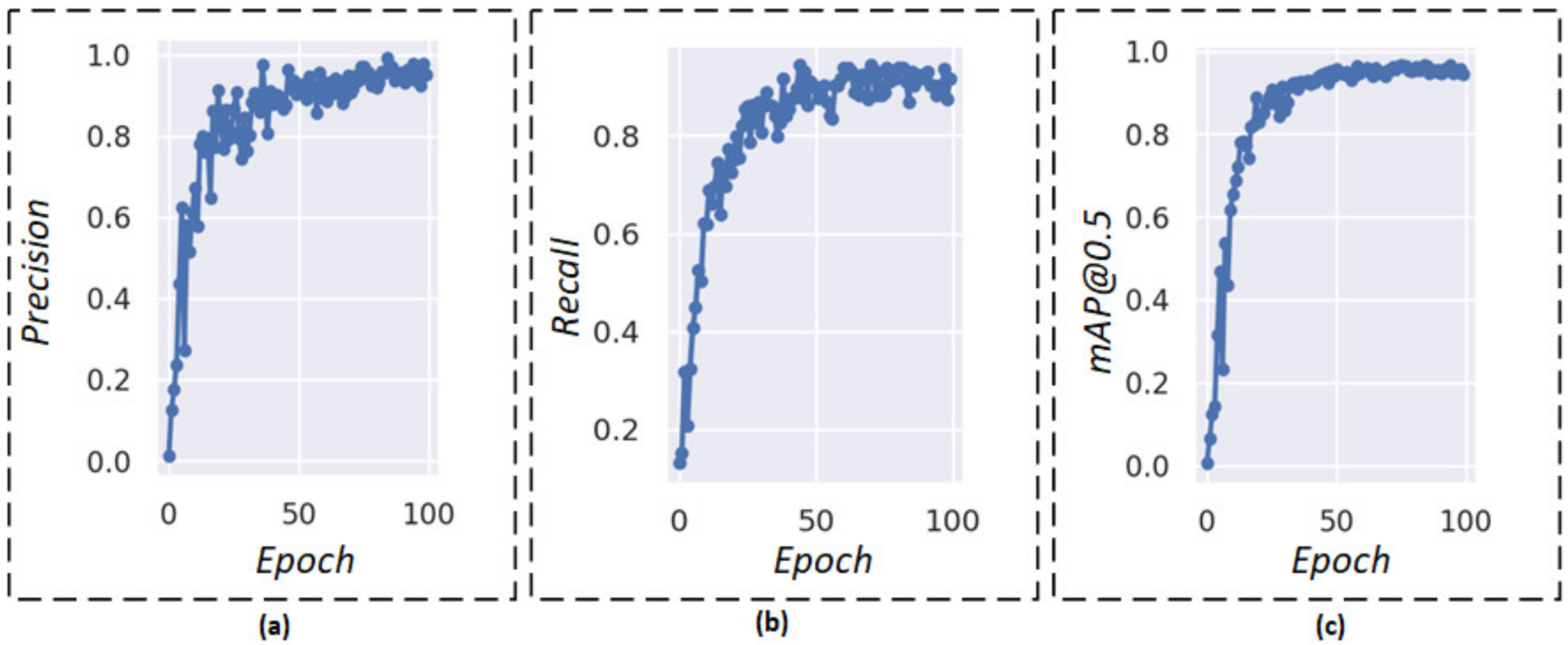
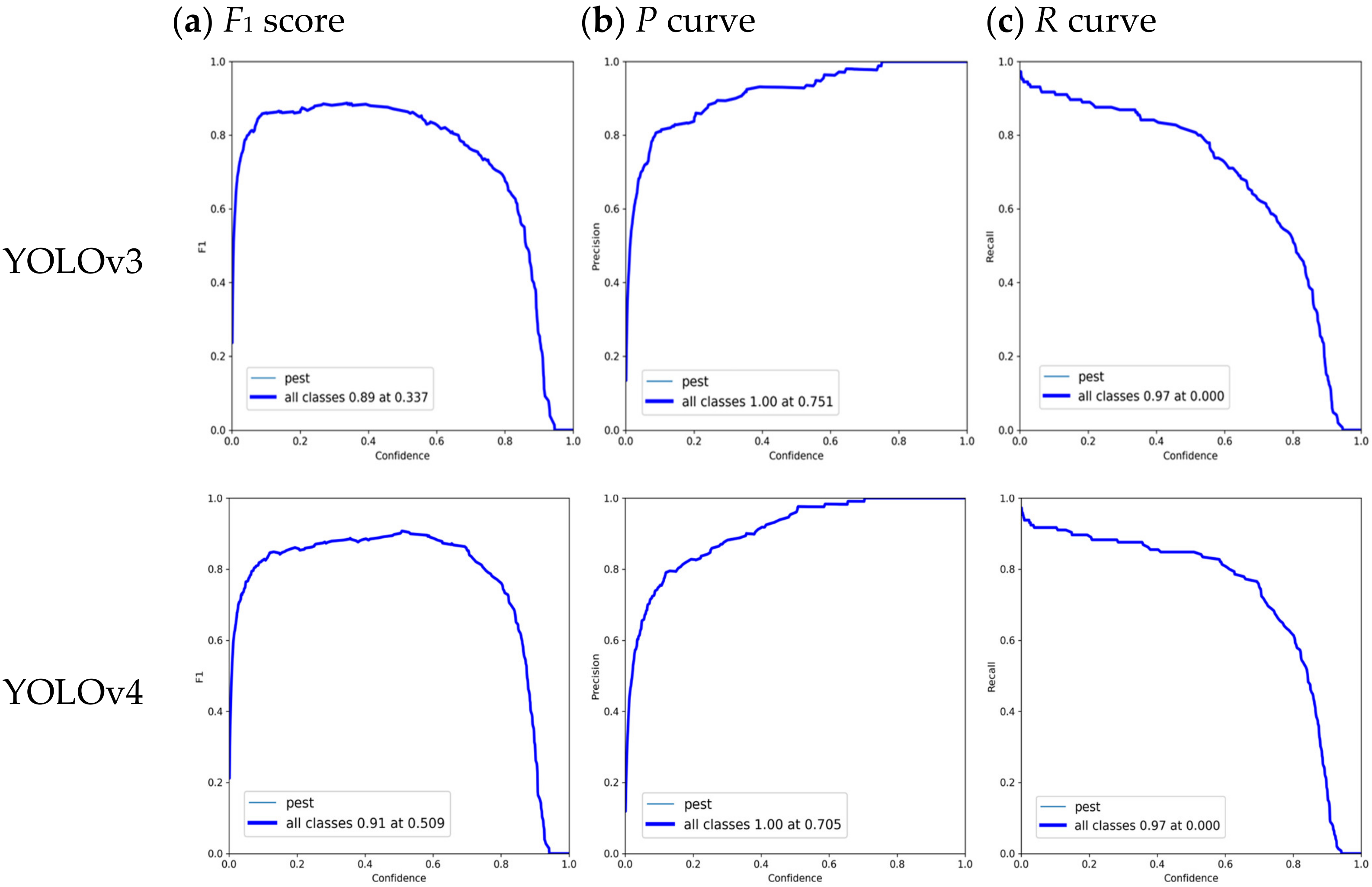
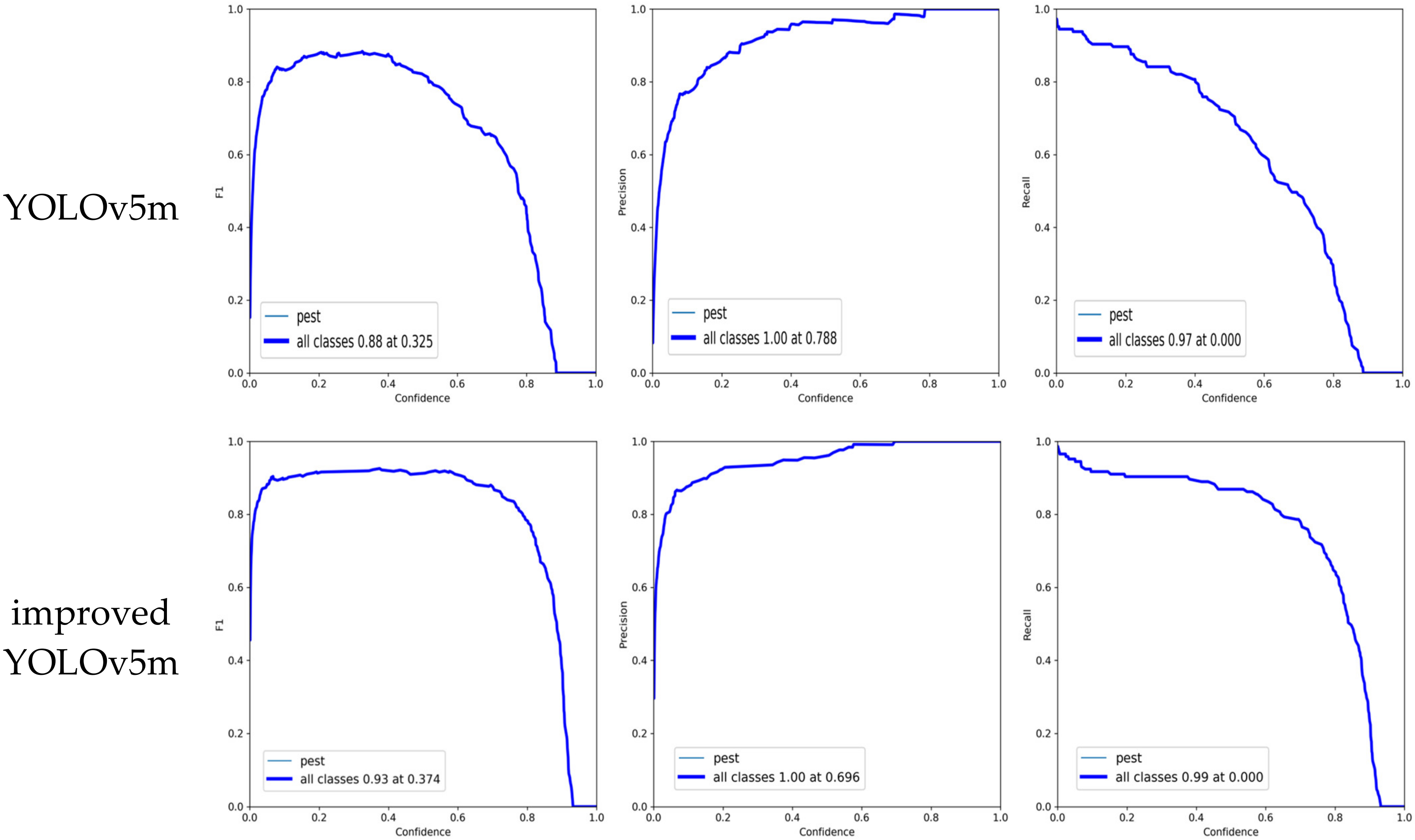
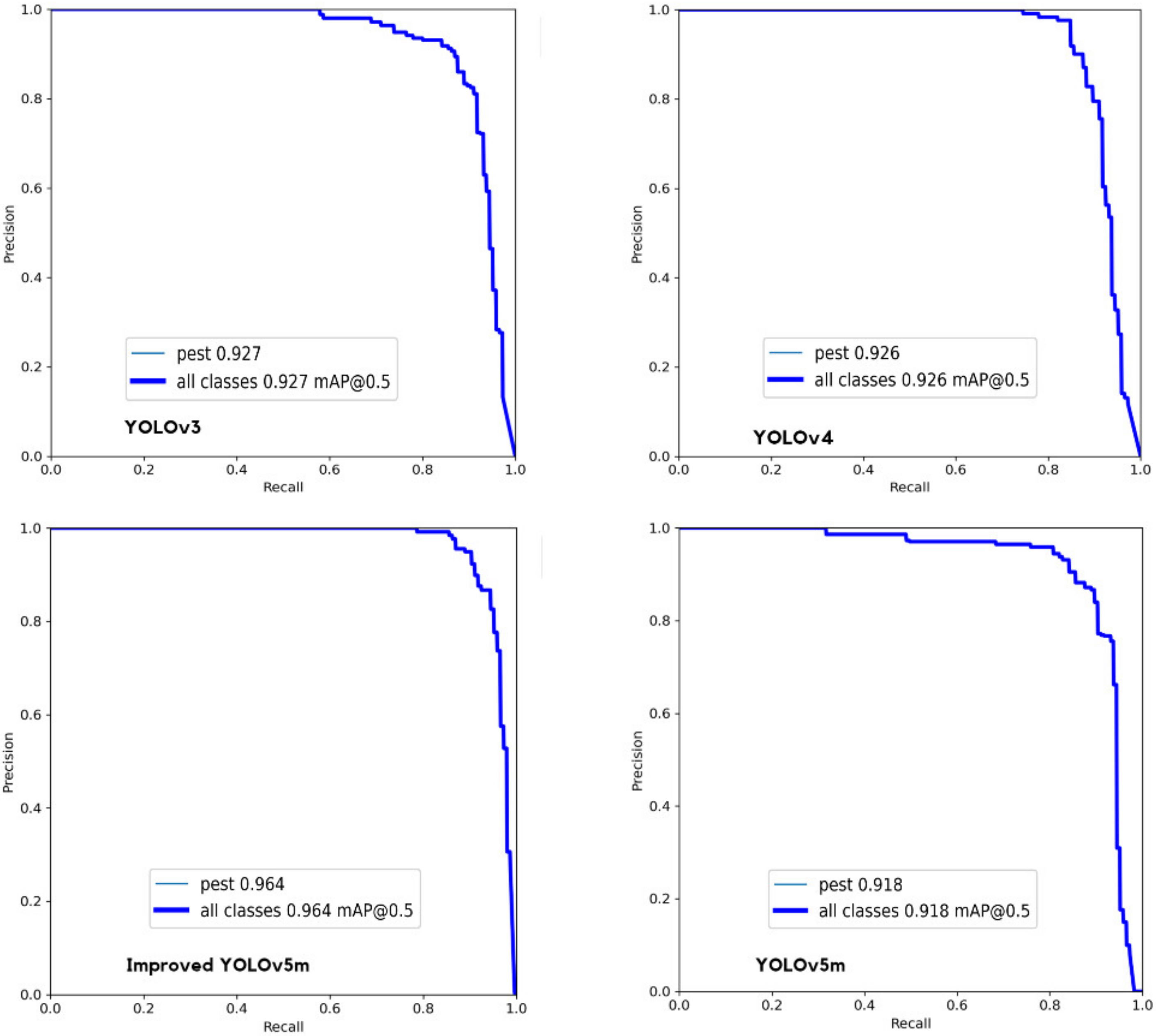
3.2. Performance Evaluation
3.3. Results and Discussion
4. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fernandez, R.M.; Petek, M.; Gerasymenko, I.; Jutersek, M.; Baebler, S.; Kallam, K.; Gimenez, E.M.; Gondolf, J.; Nordmann, A.; Gruden, K.; et al. Insect Pest Management in the Age of Synthetic Biology. Plant Biotechnol. J. 2022, 20, 25–36. [Google Scholar] [CrossRef] [PubMed]
- Albanese, A.; Nardello, M.; Brunelli, D. Automated Pest Detection with DNN on the Edge for Precision Agriculture. IEEE J. Em. Sel. Top. C. 2021, 11, 458–467. [Google Scholar] [CrossRef]
- Mekha, J.; Parthasarathy, V. An Automated Pest Identification and Classification in Crops Using Artificial Intelligence-A State-of-Art-Review. Autom. Control. Comput. 2022, 56, 283–290. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Plant Diseases and Pests Detection Based on Deep Learning: A Review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef] [PubMed]
- Turkoglu, M.; Yanikoglu, B.; Hanbay, D. PlantDiseaseNet: Convolutional neural network ensemble for plant disease and pest detection. Signal. Image. Video. P. 2022, 16, 301–309. [Google Scholar] [CrossRef]
- Waheed, H.; Zafar, N.; Akram, W.; Manzoor, A.; Gani, A.; Ulislam, S. Deep Learning Based Disease, Pest Pattern and Nutritional Deficiency Detection System for “Zingiberaceae” Crop. Agriculture 2022, 12, 742. [Google Scholar] [CrossRef]
- Ebrahimi, M.A.; Khoshtaghaza, M.H.; Minaei, S.; Jamshidi, B. Vision-Based Pest Detection Based on SVM Classification Method. Comput. Electron. Agric. 2017, 137, 52–58. [Google Scholar] [CrossRef]
- Kasinathan, T.; Singaraju, D.; Uyyala, S.R. Insect Classification and Detection in Field Crops Using Modern Machine Learning Techniques. Inf. Process. Agric. 2021, 8, 446–457. [Google Scholar] [CrossRef]
- Domingues, T.; Brandao, T.; Ferreira, J.C. Machine Learning for Detection and Prediction of Crop Diseases and Pests: A Comprehensive Survey. Agriculture 2022, 12, 1350. [Google Scholar] [CrossRef]
- Feng, F.; Dong, H.; Zhang, Y.; Zhang, Y.; Li, B. MS-ALN: Multiscale Attention Learning Network for Pest Recognition. IEEE Access 2022, 10, 40888–40898. [Google Scholar] [CrossRef]
- Gutierrez, A.; Ansuategi, A.; Susperregi, L.; Tubio, C.; Rankic, I.; Lenza, L. A Benchmarking of Learning Strategies for Pest Detection and Identification on Tomato Plants for Autonomous Scouting Robots Using Internal Databases. J. Sens. 2019, 2019, 5219471. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Yang, Z.; Lv, J.; Zheng, T.; Li, M.; Sun, C. Detection of Small-Sized Insects in Sticky Trapping Images Using Spectral Residual Model and Machine Learning. Front. Plant. Sci. 2022, 13, 915543. [Google Scholar] [CrossRef]
- Wang, K.; Chen, K.; Du, H.; Liu, S.; Xu, J.; Zhao, J.; Chen, H.; Liu, Y.; Liu, Y. New Image Dataset and New Negative Sample Judgment Method for Crop Pest Recognition Based on Deep Learning Models. Ecol. Inform. 2022, 69, 101620. [Google Scholar] [CrossRef]
- Lima, M.C.F.; de Almeida Leandro, M.E.D.; Valero, C.; Coronel, L.C.P.; Bazzo, C.O.G. Automatic Detection and Monitoring of Insect Pests—A Review. Agriculture 2020, 10, 161. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In European Conference on Computer Vision; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lyu, Z.; Jin, H.; Zhen, T.; Sun, F.; Xu, H. Small Object Recognition Algorithm of Grain Pests Based on SSD Feature Fusion. IEEE Access 2021, 9, 43202–43213. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6517–6525. [Google Scholar]
- Balarammurthy, C.; Hashmi, M.F.; Muhammad, G.; Alqahtani, S.A. YOLOv2PD: An Efficient Pedestrian Detection Algorithm Using Improved YOLOv2 Model. Comput. Mater. Contin. 2021, 69, 3015–3031. [Google Scholar]
- Li, W.; Zhu, T.; Li, X.; Dong, J.; Liu, J. Recommending Advanced Deep Learning Models for Efficient Insect Pest Detection. Agriculture 2022, 12, 1065. [Google Scholar] [CrossRef]
- Amrani, A.; Sohel, F.; Diepeveen, D.; Murray, D.; Jones, M.G.K. Insect Detection from Imagery Using YOLOv3-Based Adaptive Feature Fusion Convolution Network. Crop Pasture Sci. 2022. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Tomato Diseases and Pests Detection Based on Improved Yolo V3 Convolutional Neural Network. Front. Plant Sci. 2020, 11, 898. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X.; Miao, W.; Liu, G. Tomato Pest Recognition Algorithm Based on Improved YOLOv4. Front. Plant Sci. 2022, 13, 1894. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yang, G.; Liu, Y.; Wang, C.; Yin, Y. An Improved YOLO Network for Unopened Cotton Boll Detection in the Field. J. Intell. Fuzzy Syst. 2022, 42, 2193–2206. [Google Scholar] [CrossRef]
- Li, S.; Feng, Z.; Yang, B.; Li, H.; Liao, F.; Gao, Y.; Liu, S.; Tang, J.; Yao, Q. An Intelligent Monitoring System of Diseases and Pests on Rice Canopy. Front. Plant Sci. 2022, 13, 972286. [Google Scholar] [CrossRef] [PubMed]
- Guo, Q.; Wang, C.; Xiao, D.; Huang, Q. Automatic Monitoring of Flying Vegetable Insect Pests Using an RGB Camera and YOLO-SIP Detector. Precis. Agric. 2022. [Google Scholar] [CrossRef]
- Li, D.; Ahmed, F.; Wu, N.; Sethi, A.I. YOLO-JD: A Deep Learning Network for Jute Diseases and Pests Detection from Images. Plants 2022, 11, 937. [Google Scholar] [CrossRef]
- Chen, J.-W.; Lin, W.-J.; Cheng, H.-J.; Hung, C.-L.; Lin, C.-Y.; Chen, S.-P. A Smartphone-Based Application for Scale Pest Detection Using Multiple-Object Detection Methods. Electronics 2021, 10, 372. [Google Scholar] [CrossRef]
- Guo, M.; Cai, J.; Liu, Z.; Mu, T.J.; Martin, R.; Hu, S. PCT: Point cloud transformer. Comput. Visual Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Yan, C.; Hao, Y.; Li, L.; Yin, J.; Liu, A.; Mao, Z.; Chen, Z.; Gao, X. Task-Adaptive Attention for Image Captioning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 43–51. [Google Scholar] [CrossRef]
- Li, Y.; Xiang, Y.; Guo, H.; Liu, P.; Liu, C. Swin Transformer Combined with Convolution Neural Network for Surface Defect Detection. Machines 2022, 10, 1083. [Google Scholar] [CrossRef]
- Gao, L.; Zhang, J.; Yang, C.; Zhou, Y. Cas-VSwin Transformer: A Variant Swin Transformer for Surface-defect Detection. Comput. Ind. 2022, 140, 103689. [Google Scholar] [CrossRef]
- Zhang, S.G.; Zhang, F.; Ding, Y.; Li, Y. Swin-YOLOv5: Research and Application of Fire and Smoke Detection Algorithm Based on YOLOv5. Comput. Intell. Neurosci. 2022, 2022, 6081680. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Full Name |
|---|---|
| YOLO | YOU ONLY LOOK ONCE |
| SiLU | Sigmoid-Weighted Linear Units |
| SWinTR | SWin Transformer |
| C3TR | Transformer |
| Wconcat | Weight concat |
| MLP | Multi-Layer Perceptron’s |
| SPP | Spatial Pyramid Pooling |
| SVM | Support Vector Machine |
| KNN | K-nearest neighbor |
| Faster RCNN | Faster region with the convolutional neural network |
| SSD | Single shot multi-box detector |
| DPD | Diseases and Pests Detection |
| AFF | Adaptive feature fusion |
| SIP | Small Insect Pests |
| JD | Detecting jute diseases |
| CCD | Charge-coupled device |
| mAP | Mean Average Precision |
| AP | Average Precision |
| MSA | Multi-head Self-Attention Mechanism |
| W-MSA | Window-based Multi-head Self-Attention Mechanism |
| ReLU | Rectified Linear Unit |
| P | Precision |
| R | Recall |
| IoU | Intersection over Union |
| Parameter | Value |
|---|---|
| Iterations | 100 |
| Batch size | 10 |
| Picture size | 640 × 640 |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Model | Precision% | Recall% | mAP@0.5% | F1 Score% | Model Size/MB |
|---|---|---|---|---|---|
| YOLOv3 | 85.03 | 86.2 | 89.7 | 85.61 | 100 |
| YOLOv4 | 87.83 | 89.63 | 91.87 | 88.72 | 117 |
| YOLOv5m | 88 | 86.9 | 90.35 | 87.44 | 40.4 |
| Ours | 95.7 | 93.1 | 96.4 | 94.38 | 38.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, M.; Dorjoy, M.M.H.; Miao, H.; Zhang, S. A New Pest Detection Method Based on Improved YOLOv5m. Insects 2023, 14, 54. https://doi.org/10.3390/insects14010054
Dai M, Dorjoy MMH, Miao H, Zhang S. A New Pest Detection Method Based on Improved YOLOv5m. Insects. 2023; 14(1):54. https://doi.org/10.3390/insects14010054
Chicago/Turabian StyleDai, Min, Md Mehedi Hassan Dorjoy, Hong Miao, and Shanwen Zhang. 2023. "A New Pest Detection Method Based on Improved YOLOv5m" Insects 14, no. 1: 54. https://doi.org/10.3390/insects14010054
APA StyleDai, M., Dorjoy, M. M. H., Miao, H., & Zhang, S. (2023). A New Pest Detection Method Based on Improved YOLOv5m. Insects, 14(1), 54. https://doi.org/10.3390/insects14010054