
Machine Learning Methods for the Prediction of the Inclusion Content of Clean Steel Fabricated by Electric Arc Furnace and Rolling

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Cold Heading Steel: Properties and Fabrication
- In the EAF, steel scrap, direct reduced iron and hot briquetted iron are melted by means of high-current electric arcs to obtain liquid steel with the required chemistry and temperature. Lime and dolomite are included in the EAF to promote the formation of slag, which favors the refining of steel and reduces heat losses. Molten steel is poured into the transportation ladle where ferroalloys and additives are added to form a new slag layer.
- The so-called secondary metallurgy occurs in the LF; there, the final chemical composition and the temperature of the steel are adjusted. Deoxidizers, slag formers and other alloying agents are added for the refining. Molten steel is stirred by means of a stream of argon to homogenize the temperature and composition and to promote the flotation of NMIs within the slag. The chemistry of steel and slag, different temperatures and the amounts of fluxes and argon injected are monitored in the LF stage.
- During CC, liquid steel is poured from the ladle into the tundish (a small distributer that controls the flow rates and feeds the mold) provoking the solidification of steel in the form of billets. Chemical compositions and temperatures make up the parameters recorded at this stage.
- Rods are obtained from billets through HR. The steel is passed through several pairs of rolls to reduce the thickness, the final cross-section being typically between 5 and 30 mm in diameter. To facilitate the process, the temperature of steel during forming is above the recrystallization temperature. Rods are coiled after HR.
2.2. The K-Index as a Measure of the Degree of Purity
2.3. Machine Learning Methods
2.3.1. Scope of the Analysis
2.3.2. Collecting Data
2.3.3. Data Preprocessing
- Outliers and meaningless values were removed from the dataset. Data outliers can mislead the training process resulting in longer training times and less accurate models. z-score is a common procedure to detect and remove outliers. The z-score indicates how many standard deviations a data point is from the sample’s mean. In this research, outliers were defined as data points beyond |z| > 3.0.
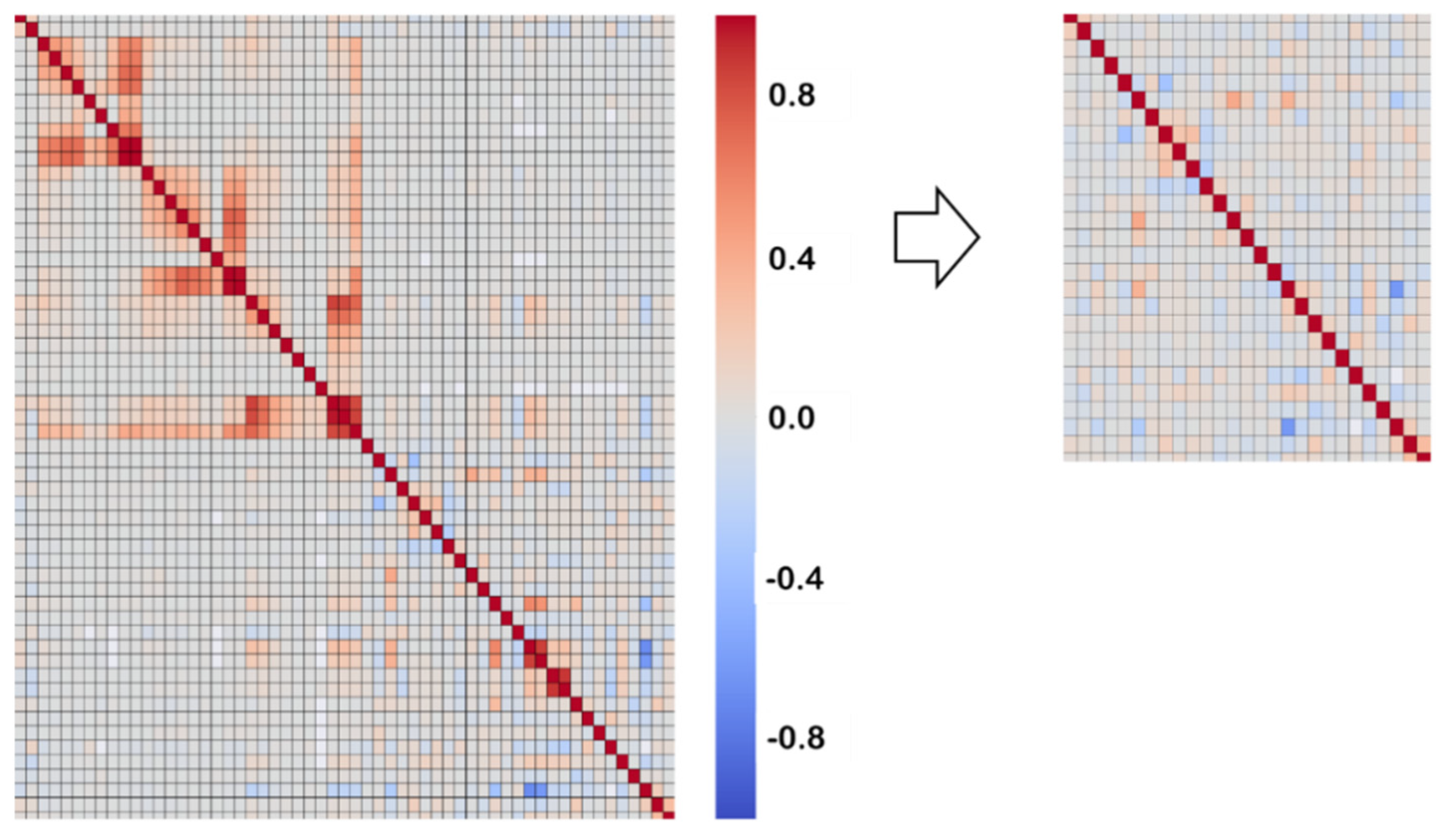
- Multicollinearity is potentially harmful for the performance of the model and may reduce its statistical significance. More importantly, it makes it difficult to determine the importance of a feature to the target variable. The Pearson’s correlation matrix of the dataset was obtained and one of the features of every couple with a correlation coefficient exceeding (in absolute value) 0.60 was removed (this selection was supported with engineering judgement). The final number of features was 37. Figure 1 shows the heatmaps of the original (left) and final (right) correlation matrices showing the reduction in the number of features as well as the removal of highly correlated ones (these matrices only include the numeric features).
- Standardization/feature scaling of a dataset is mandatory for some ML algorithms and advisable for others. Some regressors or classifiers, such as K-Nearest Neighbors or Support Vector Machines (see Section 2.3.4), calculate the distance in the feature’s hyperspace between instances; this distance is governed by the features with the broadest values. For this reason, the range of all features must be normalized so that each one contributes approximately proportionately to the final distance. For other algorithms, such as Multi-Layer Perceptron (see Section 2.3.4), scaling is not compulsory but recommended because gradient descent converges much faster with feature scaling. In this study, features were scaled though the StandardScaler provided by Scikit-Learn [30,31] which standardizes the features by removing the mean and scaling to unit variance.
- Missing data: Imputation is the process of replacing the missing values of the dataset by an educated guess. To avoid removing rows or columns, imputation was carried out by means of the KNNImputer provided by Scikit-Learn [32] in which missing values are estimated using the K-Nearest Neighbors algorithm (see Section 2.3.4).
2.3.4. ML Algorithms
- Logistic Regression (LR) [36] is considered as a baseline algorithm for binary classification. LR measures the relationship between the dependent variable and the independent variables using the sigmoid/logistic function (which is determined through a Maximum Likelihood Method). The logistic function returns the probability of every observation to belong to class 1. This real value in the interval (0, 1) is transformed into either 0 or 1 using a threshold value.
- In K-Nearest Neighbors (KNN) [37], classification or regression is conducted for a new observation by summarizing the output variable of the “K” closest observations (the neighbors) with weights that can be either uniform or proportional to the inverse of the distance from the query point. The simplest method to determine the closeness to neighbor instances is to use the Euclidean distance. The performance of KNN may fail in problems with a large number of input variables (curse of dimensionality).
- Support Vector Machine (SVM) was originally designed as a classifier [38] but may also be used for regression and feature selection. In classification, SVM determines the optimal separating hyperplane between linearly separable classes maximizing the margin, which is defined as the distance between the hyperplane and the closest points on both sides (classes). Many datasets are highly nonlinear but can be linearly separated after being nonlinearly mapped into a higher dimensional space [39]. This mapping gives rise to the kernel, which is selected by the user in a trial and error procedure on the test set.
- A Decision Tree (DT) is a non-parametric supervised learning method used for classification and regression [40]. Classification and Regression Trees were introduced in 1984 by Breiman et al. [41]. It is a flowchart-like structure in which each internal node represents a split based on a feature. The split with the highest information gain will be taken as the first split and the process will continue until all children nodes are pure, or until there is no information gain. “Gini” and “entropy” are common metrics to decide the best split. Leaf nodes (final nodes) represent the class labels. The main advantage of DTs is that the resulting model can easily be visualized and understood by non-experts. In addition, the DT may provide the feature importance, which is a score between 0 and 1 for each feature to rate how important each feature is for the decision a tree makes. The main downside is that they tend to overfit and provide poor generalization performance. In such cases, pruning methods can be implemented to control the complexity of Decision Trees.
- Ensemble algorithms [42] combine multiple “weak classifiers” into a single “strong classifier”. A weak classifier is a classifier that performs slightly better than random guessing. Ensemble algorithms are classified into bagging-based and boosting-based, which are respectively designed to reduce variance and bias. Random Forest (RF) is a widely used bagging algorithm based on classification trees (weak learner). In RFs, each tree in the ensemble is built from a sample drawn with replacement (i.e., a bootstrap sample) from the training set. In addition, instead of using all the features, a random subset of features is selected, further randomizing the tree. AdaBoost (AB), which stands for adaptive boosting, is the most widely used form of boosting algorithm. In this case, weak learners are trained sequentially, each one trying to correct its predecessor. In AB, the weak learners are usually Decision Trees with a single split, called decision stumps. Gradient Boosting (GB) is another ensemble algorithm, very similar to AB, which works by adding predictors sequentially to a set, each correcting its predecessor.
- An Artificial Neural Network (ANN) [43] contains a large number of neurons/nodes arranged in layers. A Multi-Layer Perceptron (MLP) contains one or more hidden layers (apart from one input and one output layers). The nodes of consecutive layers are connected and these connections have weights associated with them. In a feedforward network, the information moves in one direction from the input nodes, through the hidden nodes to the output nodes. The output of every neuron is obtained by applying an activation function to the linear combination of inputs (weights) to the neuron; sigmoid, tanh and Rectified Linear Unit (ReLu) are the most widely used activation functions. MLPs are trained through the backpropagation algorithm. Gradient descent, Newton, conjugate gradient and Levenberg–Marquardt are different algorithms used to train an ANN.
2.3.5. Training and Testing the Model on Data
2.3.6. Evaluation Scores for Classification
2.3.7. Relevance of Features: Feature Importance and Permutation Importance
2.3.8. Partial Dependence Plots
3. Results
3.1. Description of the Distribution of the K3 Index
3.2. Classification of Observations
3.2.1. Comparison of the Performance of the ML Models
3.2.2. Importance of the Features
3.2.3. Partial Dependence Plots
4. Discussion
- The variable “diameter”, i.e., the final diameter of the rod after rolling, stands out as a very important feature in Figure 5. At first sight, this result is unexpected because it is not truly a manufacturing parameter and it may seem peculiar that the final diameter of the bar influences the inclusion content. However, it is possible to outline two explanations, mechanistically grounded, to understand the possible influence of the diameter. First of all, it is necessary to consider that the rolling of the steel is a plastic deformation process in which the bar is longitudinally stretched and, simultaneously, transversally shortened. As a matter of fact, the volume of metals remains constant [22,52] during plastic deformation; this is a consequence of the fact that the mechanism justifying plastic deformation at the microstructural level corresponds to the displacement of dislocations [53]. Figure 7 shows a simplistic diagram showing the influence of the rolling process on the length, “L”, and diameter, “D”, of the bar. Two situations, represented with subscripts 1 and 2, are sketched. The box in dotted lines in Figure 7 represents the area examined with the optical microscope to quantify the number of non-metallic inclusions. The condition of constant volume is expressed in Equation (7). The number of inclusions per unit surface, “n”, present in a longitudinal section, is expressed in Equation (8). Introducing the condition of constant volume, it is obtained that n is proportional to the diameter (or, equivalently, inversely proportional to the square root of the length). Therefore, based on this simplified geometric model, there must be a positive correlation between the diameter and the inclusion cleanliness (or, in other words, the K3 index). There is, however, another phenomenon that can contribute to explaining the influence of the diameter. It has been reported, see Vasconcellos et al. [5], that when steels are deformed (during rolling, for example), depending on temperature and inclusion composition, NMIs may deform or crack (or display a mixed behavior). Holappa and Wijk [2] distinguish four types of behaviors: (i) Alumina inclusions, which are hard and brittle, are typically broken up into fragments. (ii) Silicates and manganese sulfides are ductile and deform in a similar way to the steel matrix. (iii) Calcium-aluminate inclusions display very limited deformation and can lead to the formation of cavities after a very demanding rolling. (iv) Complex multiphase inclusions have a hard core surrounded by a deformable phase. Therefore, they show a ductile behavior at low degrees of deformation and prolonged ends at higher deformations. This classification exemplifies the intrinsic difficulties in capturing the complexities of the inclusion content on a simple index. In addition, when an NMI is broken during rolling, the size of the resulting fragments may be lower than the detection limit of the K3 method. Then, the lower the diameter, the smaller the final sizes and, therefore, the lower the value of the K3 index. This rationale is consistent with the results represented in the PDPs; thus, it is observed that the smaller the final diameter, the lower the probability of obtaining a high value of K3. This effect tends to attenuate for large diameters (more than one standard deviation beyond the mean), which also agrees with the argument sketched above.
- During casting, the content of consecutive LFs is poured into the tundish. The tundish is a small refractory distributer placed over the mold that receives the steel from the LF [54]. The tundish is in charge of matching the flow rate of liquid steel into the mold with the speed of the strands out of the mold, which is a key aspect of continuous casting. The content of consecutive LFs is poured into the tundish and the feature “sequence” expresses the number of the corresponding LF. Casting is expected to be a continuous process; nevertheless, casting transitions occur at the start of a sequence, during LF exchanges or at the end of casting [55]. NMIs are often generated during transitions [56] because during these non-steady state casting periods, slag entrainment and air absorption are more likely, inducing reoxidation. For example, it has been reported [57] that the presence of slivers (line defects that appear on the surface of the finished product, resulting from NMIs near the surface of the slab) at the beginning of the first heat is five times higher than at the middle of the first heat and over 15 times that for successive heats. Moreover, Zhang and Thomas [55] have shown that the first heat has more total oxygen than the intermediate heats, which facilitates reoxidation. The results represented in Figure 6 reveal a marked influence of the variable sequence in agreement with the previous explanation. Specifically, the probability of belonging to class 1 is larger for the first LFs but it attenuates as sequence increases.
- Feature “billet sequence” has also been identified as relevant. Steel flows from the tundish through a submerged entry nozzle into one or several molds; in this case, the material was fabricated in a six-strand bow-type caster. Therefore, the main function of the tundish is not only to be a steel reservoir between the ladle and the mold, but to distribute the liquid into the six molds (giving rise to six strands/lines). Steel emerges horizontally in the form of a solid steel strand. At this point, it is cut to length using automatic gas burners to produce billets. The index that defines the position of the slab in each strand/line corresponds to the feature billet sequence. As can be seen in Figure 6, best results for billet sequence are obtained when this variable is in the range of mean ± standard deviation (between −1 and +1 in the PDP). This result reflects that the inclusion cleanliness of the central billets coming from the same LF is slightly superior to that of the initial and final billets. This matches with the fact that a steady condition leads to better cleanliness than an unsteady one (start and end of the ladle).
- The task of the tundish is of special importance during ladle change and the processes that take place in the tundish deserve some consideration in order to understand the role played by the temperature (“tundish_temperature”) and weight (“tundish_weight”). The tundish, like the ladle, is in fact a metallurgical reactor where interactions between the molten steel, the slag, the refractory phases and the atmosphere occur. Regarding temperature, the performance of the tundish is associated with a good thermal insulation of the molten steel, the prevention of reactions with the atmosphere and the absorption of NMIs. Thermal insulation is best achieved with a solid powder layer, while preventing the reaction with the atmosphere and promoting the absorption of nonmetallic inclusions requires the presence of a liquid layer. If the temperature of the tundish is very low, the viscosity of the tundish flux will be too high and its ability to absorb inclusions will be reduced. Conversely, an excessively low viscosity is not recommended because the flux may be drawn down into the mold, producing the contamination of the steel after solidification [58]. The change of ladle makes the process discontinuous. Thus, the temperature of the steel coming from the new ladle is higher than the melt in the tundish from the previous ladle. This temperature difference may affect the flow phenomena in the tundish because convection makes hotter steel ascend in the tundish whereas colder steel descends to the bottom [59]. The influence of the feature tundish_temperature is clearly seen in the corresponding PDP; see Figure 6, where the probability of belonging to the class above the median may be reduced by more than 5% by using above mean values.
- The tundish weight, in turn, acts as a proxy to estimate the steel level in the tundish. During casting operation, some ladle slag can be drawn by vortex formation into the tundish as the metal level in the ladle decreases. Some of this entrained slag may be carried over into the mold generating defects in the final product. From flotation considerations, there may also be a higher content of inclusions in the last portion of steel to leave the ladle [56]. Moreover, near the end of a ladle, slag may enter the tundish, due in part to the vortex formed in the liquid steel near the ladle exit. This phenomenon requires some steel to be kept in the ladle upon closing [55]. Therefore, it is important to establish the range of steel levels in the tundish that prevent incurring any of these situations. In recent years, numerical modeling has gained importance as a method for determining the fields of fluid flow in the tundish (residence time distribution, velocity profile, temperature distribution, NMIs distribution, etc.) [59]. In general, high residence times and avoidance of short circuits and cold spots of liquid steel are highly appreciated targets and these can be estimated numerically. The PDP in Figure 6 shows that when the tundish weight is very low, the K3 index tends to display larger values, which agrees with the previous rationale.
- The origin of macro- and microinclusions is different. Macroinclusions are typically formed due to reoxidation, ladle slag carryover, slag emulsification, refractory erosion, etc. Microinclusions are typically deoxidation products [59]. The free surface of the melt in the tundish is usually covered by synthetic slag intentionally added, keeping air away from the steel to avoid reoxidation and heat losses from the melt; the feature “slag_bags” represents the number of units used for this purpose. Another important function of the covering slag is the reception of the inclusions from the steel melt. Therefore, it has a key role in the inclusion cleanliness of the final product. Shielding is improved in this process by pouring steel by means of refractory tubes that are immersed in the steel through the slag layer [54]. Emulsification, i.e., the dispersion of slag into the steel as droplets, should be minimized [59]. Rice husk ash (RHA) has historically been the first element to be employed as a tundish covering material due to its availability and low cost. Rice husk is the film that covers rice grains and is commonly used as a biofuel; RHA is the residual of this process, which is formed by silica (~80% wt.) and carbon (5–10% wt.), and is considered an excellent option for its low bulk density and efficiency in preventing heat loss of the molten steel in the tundish [60]. The feature “rice_bags” refers to the amount of RHA employed to thermally isolate the molten material given that, as explained above, an adequate temperature is crucial for the cleanliness of the final product. Figure 6 proves that the higher the number of rice_bags the better the K3 index. Even though this result agrees with the previous argument, it should be treated with caution since, in general, rice bags are usually added at the beginning of each sequence and, as a consequence, there is presumably a correlation between both variables. In fact, this has been observed (the Pearson’s correlation coefficient between the features sequence and rice_bags is 0.598). Something similar occurs with the variable slag_bags. Moreover, recent developments [61] suggest that rice husk is harmful to steel cleanliness due to the steel reoxidation by the silica present in rice husk ash.
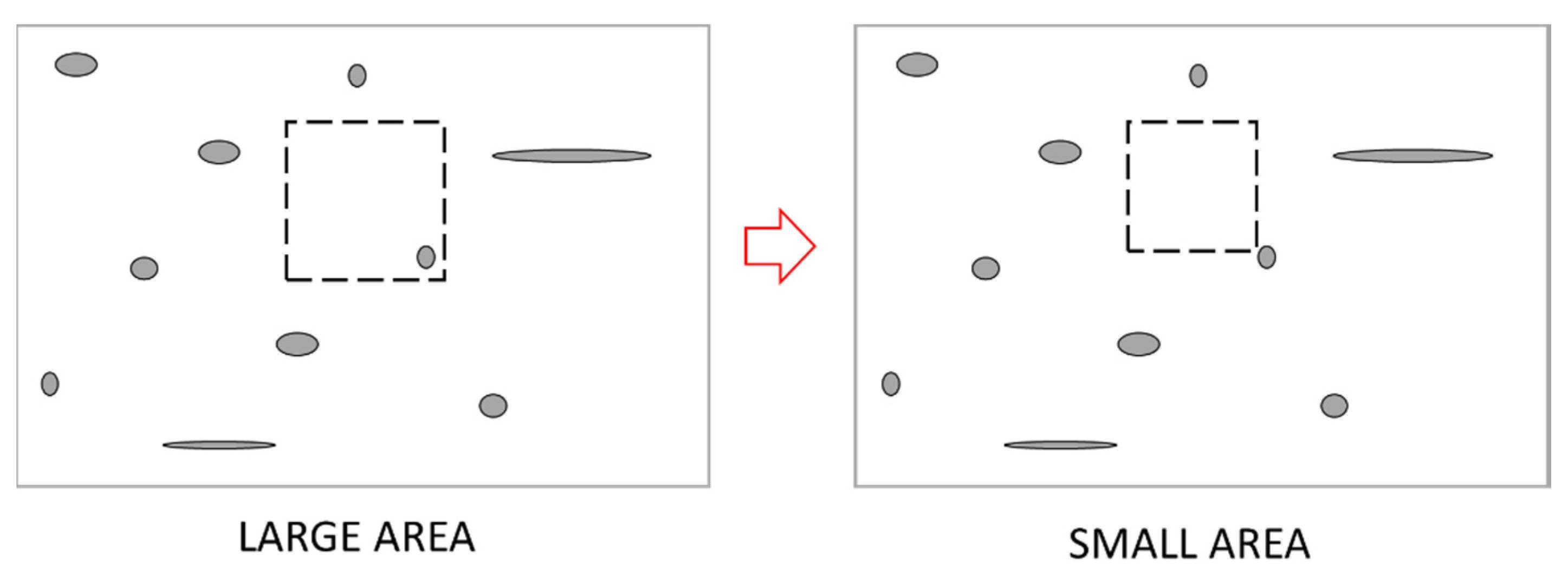
- The variable “area” represents the size of the surface scanned in each microscopic observation to detect inclusions. Its nominal value is 100 mm2, however, in practice it presents some variability. Given that, as indicated in Section 2.2, the result of the K3 index is normalized (its value is expressed for an area of 1000 mm2), it may be striking that this variable has some influence on the cleanliness. However, a positive correlation is observed in Figure 6, between this feature and the probability of yielding high values of the K3 index. To interpret this result, it is necessary to consider that the last revision of the K3 DIN 50602 [9] test standard was drawn up in 1985 and that, since then, the quality of steels has improved substantially, particularly with regards to their inclusionary content. With the steel analyzed in this study, it is very common to obtain K3 = 0 or a very low value, see Figure 2. Therefore, the “edge effects”, sketched in Figure 8, may be playing a role in the value of the K3 index. In this example, a small increase in the inspection area leads to the addition of one inclusion that otherwise would have been ignored. Logically, this effect diminishes as the inspection area increases.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vasconcellos Da Costa E Silva, A.L. Non-metallic inclusions in steels-Origin and control. J. Mater. Res. Technol. 2018, 7, 283–299. [Google Scholar] [CrossRef]
- Holappa, L.; Wijk, O. Chapter 1.7-Inclusion Engineering. In Treatise on Process Metallurgy. Volume 3: Industrial Processes; Elsevier Ltd.: Amsterdam, The Netherlands, 2014; pp. 347–372. ISBN 978-0-08-096988-6. [Google Scholar]
- Murakami, Y. Metal Fatigue: Effect of Small Defects and Nonmetallic Inclusions; Elsevier Science Ltd.: Amsterdam, The Netherlands, 2002; ISBN 0-08-044064-9. [Google Scholar]
- Atkinson, H.V.; Shi, G. Characterization of inclusions in clean steels: A review including the statistics of extremes methods. Prog. Mater. Sci. 2003, 48, 457–520. [Google Scholar] [CrossRef]
- Da Costa E Silva, A.L.V. The effects of non-metallic inclusions on properties relevant to the performance of steel in structural and mechanical applications. J. Mater. Res. Technol. 2019, 8, 2408–2422. [Google Scholar] [CrossRef]
- Reis, B.H.; Bielefeldt, W.V.; Vilela, A.C.F. Absorption of non-metallic inclusions by steelmaking slags-A review. J. Mater. Res. Technol. 2014, 3, 179–185. [Google Scholar] [CrossRef] [Green Version]
- ASTM E45-18a. Standard Test Methods for Determining the Inclusion Content of Steel. Book of Standards Volume: 03.01; ASTM: West Conshohocken, PA, USA, 2018. [Google Scholar]
- EN 10247. Micrographic Examination of the Non-Metallic Inclusion Content of Steels Using Standard Pictures; Committe Europeen de Normalisation: Brussels, Belgium, 2017. [Google Scholar]
- DIN 50602. Metallographic Examination; Microscopic Examination of Special Steels Using Standard Diagrams to Assess the Content of Non-Metallic Inclusions; Deutsches Institut fur Normung E.V. (DIN): Berlin, Germany, 1985; p. 13. [Google Scholar]
- ISO 4967:2013 Steel. Steel—Determination of Content of Non-Metallic Inclusions—Micrographic Method Using Standard Diagrams; ISO, International Organization for Standardization: Geneva, Switzerland, 2020; p. 39. [Google Scholar]
- Oeters, F. Metallurgy of Steelmaking; Verlag Stahleisen: Dusseldorf, Germany, 1994; ISBN 0387510400. [Google Scholar]
- Turkdogan, E. Principles of Steelmaking; Institute of Materials: London, UK, 1996. [Google Scholar]
- Hino, M.; Ito, K. (Eds.) Thermodynamic Data for Steelmaking; Tohoku University Press: Sendai, Japan, 2010; ISBN 9784861631290. [Google Scholar]
- Park, J.H.; Lee, S.-B.; Kim, D.S. Inclusion control of ferritic stainless steel by aluminum deoxidation and calcium treatment. Metall. Mater. Trans. B 2005, 36, 67–73. [Google Scholar] [CrossRef]
- Kang, Y.B.; Lee, H.G. Inclusions chemistry for Mn/Si deoxidized steels: Thermo-dynamic predictions and experimental confirmations. ISIJ Int. 2004, 44, 1006–1015. [Google Scholar] [CrossRef] [Green Version]
- Riboud, P.V.; Gatellier, C.; Gaye, H.; Pontoire, J.N.; Rocabois, P. Examples of physical chemistry approach to high quality steel processing. ISIJ Int. 1996, 36, 22–25. [Google Scholar] [CrossRef]
- Pfeiler, C.; Wu, M.; Ludwig, A. Influence of argon gas bubbles and non-metallic inclusions on the flow behavior in steel continuous casting. Mater. Sci. Eng. A 2005, 413–414, 115–120. [Google Scholar] [CrossRef]
- Choudhary, S.K.; Ghosh, A. Mathematical Model for Prediction of Composition of Inclusions Formed during Solidification of Liquid Steel. ISIJ Int. 2009, 49, 1819–1827. [Google Scholar] [CrossRef] [Green Version]
- Robinson, E. Bringing Machine Learning to Nonmetallic Inclusions in Steelmaking. Ind. Heat. 2019, 34–45. Available online: https://www.industrialheating.com/articles/95278-bringing-machine-learning-to-nonmetallic-inclusions-in-steelmaking (accessed on 20 May 2021).
- Webler, B. Machine Learning for Nonmetallic Inclusions. Ind. Heat. 2019, 66–71. Available online: https://www.industrialheating.com/articles/95293-machine-learning-for-nonmetallic-inclusions (accessed on 20 May 2021).
- EN 10221. Surface Quality Classes for Hot-Rolled Bars and Rods-Technical Delivery Conditions; Committe Europeen de Normalisation: Brussels, Belgium, 1995. [Google Scholar]
- Callister, W.D. Materials Science and Engineering; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2010; ISBN 978-0470505861. [Google Scholar]
- Gasik, M. (Ed.) Handbook of Ferroalloys: Theory and Technology, 1st ed.; Butterworth-Heinemann: Oxford, UK, 2013; ISBN 978-0080977539. [Google Scholar]
- Wente, E.F.; Nutting, J.; Wondris, E.F. Steel. Available online: https://www.britannica.com/technology/steel (accessed on 20 May 2021).
- Ruiz, E.; Cuartas, M.; Ferreno, D.; Romero, L.; Arroyo, V.; Gutierrez-Solana, F. Optimization of the Fabrication of Cold Drawn Steel Wire Through Classification and Clustering Machine Learning Algorithms. IEEE Access 2019. [Google Scholar] [CrossRef]
- Pant, A. Workflow of a Machine Learning Project. Available online: https://towardsdatascience.com/workflow-of-a-machine-learning-project-ec1dba419b94 (accessed on 8 June 2020).
- Introduction to Data Preprocessing in Machine Learning. Available online: https://towardsdatascience.com/introduction-to-data-preprocessing-in-machine-learning-a9fa83a5dc9d (accessed on 9 June 2020).
- Geron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow; O’Reilly Media, Inc.: Newton, MA, USA, 2017; ISBN 978-1491962299. [Google Scholar]
- Guido, S.; Müller, A. Introduction to Machine Learning with Python. A Guide for Data Scientists; O’Reilly Media, Inc.: Newton, MA, USA, 2016; ISBN 978-1449369415. [Google Scholar]
- sklearn.preprocessing.StandardScaler. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html#sklearn-preprocessing-standardscaler (accessed on 24 October 2019).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M. Scikit-learn. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- sklearn.impute.KNNImputer. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.impute.KNNImputer.html (accessed on 8 June 2020).
- Sklearn.Preprocessing.LabelEncoder—Scikit-Learn 0.23.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html (accessed on 9 June 2020).
- Sklearn.Preprocessing.OneHotEncoder—Scikit-Learn 0.23.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html (accessed on 9 June 2020).
- No Free Lunch Theorem-Wikipedia. Available online: https://en.wikipedia.org/wiki/No_free_lunch_theorem (accessed on 10 June 2020).
- Cramer, J.S. The Origins of Logistic Regression. Tinbergen Inst. Working Paper 2002. [Google Scholar] [CrossRef] [Green Version]
- Nilsson, N.J. Learning Machines: Foundations of Trainable Pattern-Classifying Systems; McGraw-Hill Companies: New York, NY, USA, 1965; ISBN 978-0070465701. [Google Scholar]
- Vapnik, V.; Chervonenkis, A. A note on one class of perceptrons. Autom. Remote. Control. 1964, 25, 61–68. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. Proc. Fifth Annu. Work. Comput. Learn. Theory 1992, 144–152. [Google Scholar] [CrossRef]
- Yadav, P. Decision Tree in Machine Learning. Available online: https://towardsdatascience.com/decision-tree-in-machine-learning-e380942a4c96 (accessed on 16 June 2020).
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; Chapman and Hall/CRC: London, UK, 1984; ISBN 978-0412048418. [Google Scholar]
- Schapire, R.E. The Strength of Weak Learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Hebb, D. The Organization of Behavior; Wiley: New York, NY, USA, 1949; ISBN 978-1-135-63190-1. [Google Scholar]
- sklearn.model_selection.KFold. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html#sklearn-model-selection-kfold (accessed on 24 October 2019).
- sklearn.model_selection.GridSearchCV. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html (accessed on 24 October 2019).
- Permutation Importance vs. Random Forest Feature Importance (MDI). Available online: https://scikit-learn.org/dev/auto_examples/inspection/plot_permutation_importance.html#sphx-glr-auto-examples-inspection-plot-permutation-importance-py (accessed on 20 May 2021).
- Feature Importances with Forests of Trees. Available online: https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html (accessed on 24 October 2019).
- Dubey, A. Feature Selection Using Random Forest. Available online: https://towardsdatascience.com/feature-selection-using-random-forest-26d7b747597f (accessed on 16 June 2020).
- Parr, T.; Turgutlu, K.; Csiszar, C.; Howard, J. Beware Default Random Forest Importances. Available online: https://explained.ai/rf-importance/ (accessed on 10 October 2020).
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Molnar, C. Interpretable Machine Learning, 1st ed.; Molnar, C., Ed.; LeanPub: Victoria, BC, Canada, 2019; ISBN 9780244768522. [Google Scholar]
- Ashby, M.F. Materials Selection in Mechanical Design; Butterworth-Heinemann: Oxford, UK, 2004; ISBN 978-0750661683. [Google Scholar]
- Schoeck, G. Dislocation Theory of Plasticity of Metals. In Advances in Applied Mechanics Volume 4; Elsevier Ltd.: Amsterdam, The Netherlands, 1956; pp. 229–279. [Google Scholar]
- Nutting, J.; Wondris, E.F. Steel. In Encyclopædia Britannica; Encyclopædia Britannica, Inc: Chicago, IL, USA, 1768. [Google Scholar]
- Zhang, L.; Thomas, B.G. Inclusions in continuous casting of steel. In Proceedings of the XXIV National Steelmaking Symposium, Morelia, Mich, Mexico, 26–28 November 2003; pp. 138–183. [Google Scholar]
- Miki, Y.; Thomas, B.G. Modeling of inclusion removal in a tundish. Metall. Mater. Trans. B 1999, 30, 639–654. [Google Scholar] [CrossRef]
- Uehara, H.; Osanai, H.; Hasunuma, J.; Hara, K.; Nakagawa, T.; Yoshida, M.; Yuhara, S. Continuous casting technology of hot cycle operations of tundish for clean steel slabs*. Rev. Met. Paris 1998, 95, 1273–1286. [Google Scholar] [CrossRef]
- Yang, Y.D.; McLean, A. Chapter 3.1-Some Metallurgical Considerations Pertaining to the Development of Steel Quality. In Treatise on Process Metallurgy Volume 2: Process Phenomena; Elsevier Ltd.: Amsterdam, The Netherlands, 2014; pp. 251–282. ISBN 978-0-08-096988-6. [Google Scholar]
- Louhenkilpi, S. Chapter 1.8-Continuous Casting of Steel. In Treatise on Process Metallurgy: Industrial Processes; Seetharaman, S., Ed.; Elsevier Ltd.: Amsterdam, The Netherlands, 2014; pp. 373–434. ISBN 978-0-08-096988-6. [Google Scholar]
- Carli, R.; Moro, A.D.; Righi, C. Tundish Covering Materials Manufacturing: Real Technology in Tundish Metallurgy. In Proceedings of the 6th European Conference on Continuous Casting, Riccione, Italy, 3–6 June 2008. [Google Scholar]
- Kim, T.S.; Chung, Y.; Holappa, L.; Park, J.H. Effect of Rice Husk Ash Insulation Powder on the Reoxidation Behavior of Molten Steel in Continuous Casting Tundish. Metall. Mater. Trans. B Process. Metall. Mater. Process. Sci. 2017, 48, 1736–1747. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LR | KNN | DT | RF | AB | GB | SVC | MLP | |
|---|---|---|---|---|---|---|---|---|
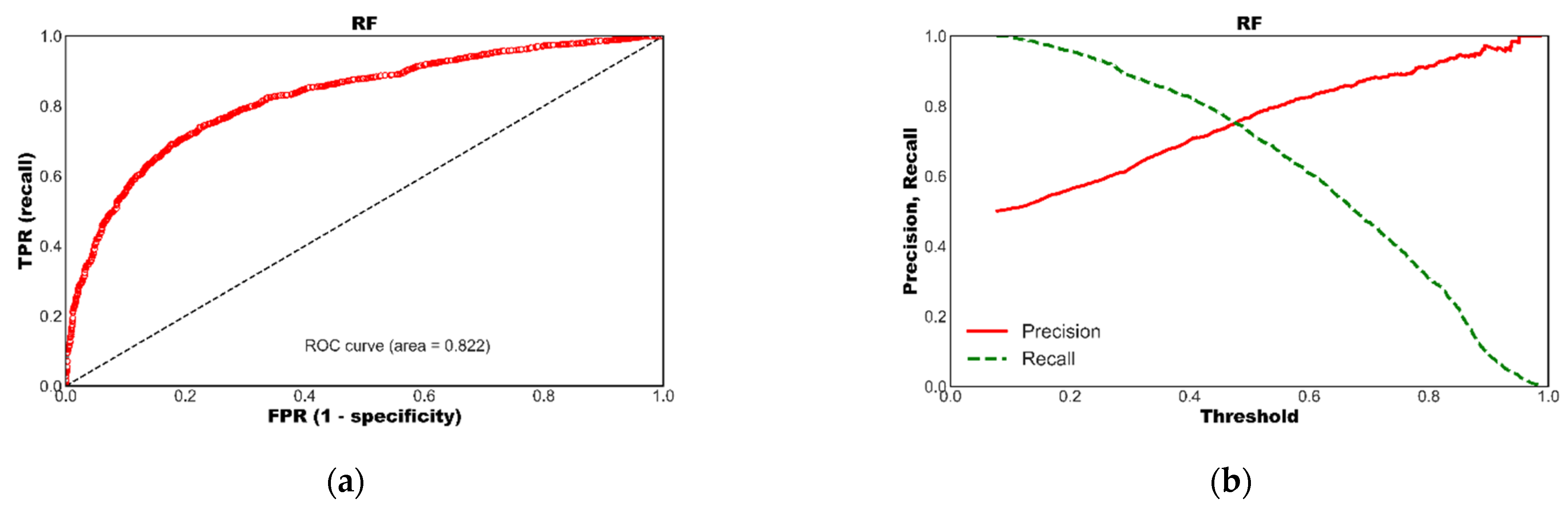
| AUC | 0.655 | 0.797 | 0.742 | 0.822 | 0.742 | 0.807 | 0.769 | 0.767 |
| Accuracy | 0.619 | 0.737 | 0.691 | 0.747 | 0.680 | 0.743 | 0.710 | 0.712 |
| Precision | 0.610 | 0.735 | 0.741 | 0.749 | 0.669 | 0.742 | 0.719 | 0.707 |
| Recall | 0.568 | 0.706 | 0.540 | 0.709 | 0.658 | 0.712 | 0.648 | 0.681 |
| F1 | 0.588 | 0.720 | 0.626 | 0.728 | 0.663 | 0.726 | 0.682 | 0.694 |
| AP | 0.634 | 0.772 | 0.709 | 0.820 | 0.736 | 0.804 | 0.751 | 0.752 |
| Predicted | ||
|---|---|---|
| Actual | False | True |
| False | 1332 | 373 |
| True | 466 | 1222 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz, E.; Ferreño, D.; Cuartas, M.; Lloret, L.; Ruiz del Árbol, P.M.; López, A.; Esteve, F.; Gutiérrez-Solana, F. Machine Learning Methods for the Prediction of the Inclusion Content of Clean Steel Fabricated by Electric Arc Furnace and Rolling. Metals 2021, 11, 914. https://doi.org/10.3390/met11060914
Ruiz E, Ferreño D, Cuartas M, Lloret L, Ruiz del Árbol PM, López A, Esteve F, Gutiérrez-Solana F. Machine Learning Methods for the Prediction of the Inclusion Content of Clean Steel Fabricated by Electric Arc Furnace and Rolling. Metals. 2021; 11(6):914. https://doi.org/10.3390/met11060914
Chicago/Turabian StyleRuiz, Estela, Diego Ferreño, Miguel Cuartas, Lara Lloret, Pablo M. Ruiz del Árbol, Ana López, Francesc Esteve, and Federico Gutiérrez-Solana. 2021. "Machine Learning Methods for the Prediction of the Inclusion Content of Clean Steel Fabricated by Electric Arc Furnace and Rolling" Metals 11, no. 6: 914. https://doi.org/10.3390/met11060914