RBF was first introduced by Rolland Hardy to fit irregular topographic contours of geographical data [
20]. RBF networks are three layer feed-forward networks that are trained using a supervised training algorithm, which is shown in
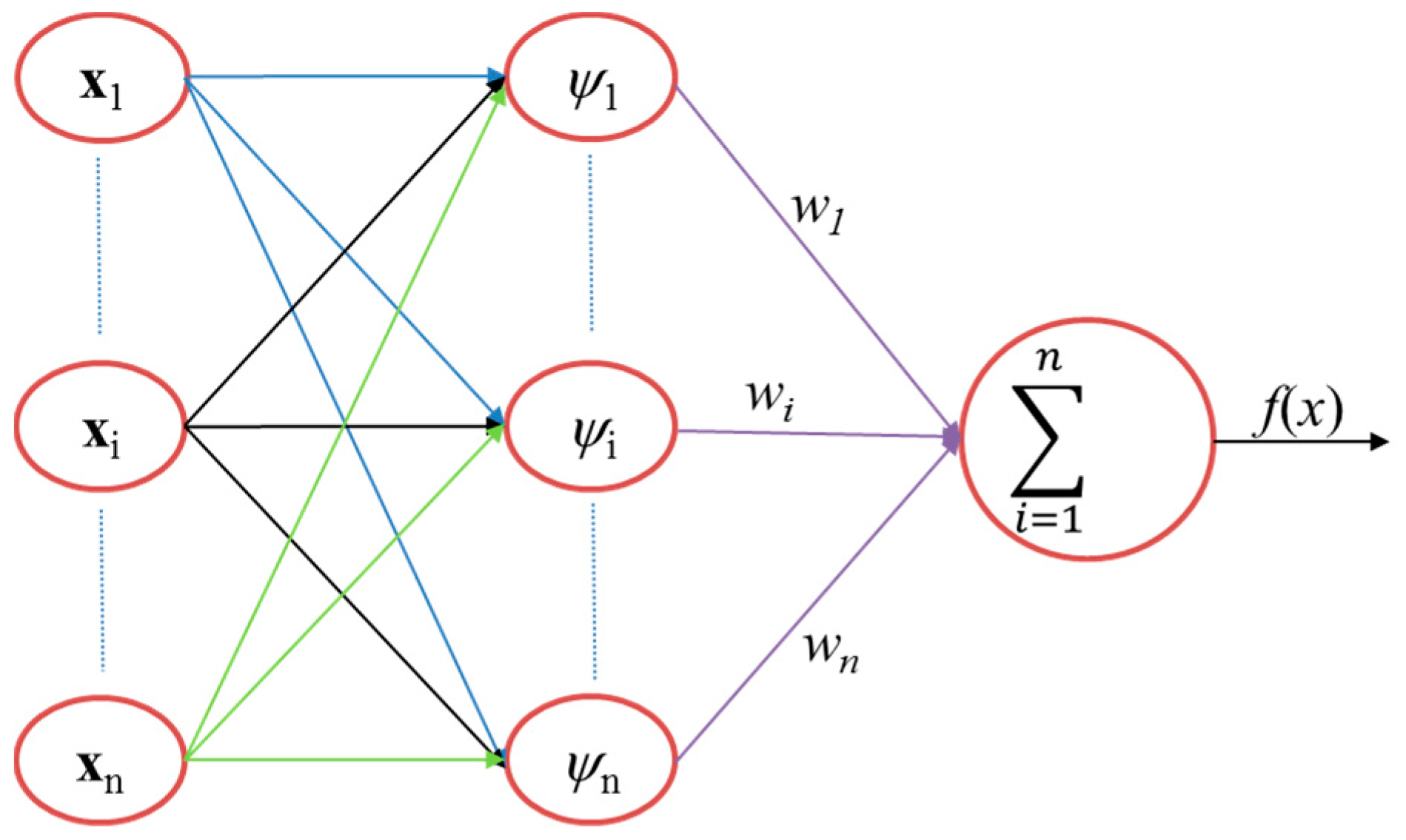
Figure 8, featuring are an input
x, hidden units
Ψ, weights
w, linear output transfer functions, and output
f(
x). To construct the fitting model using RBF, we first consider the scalar response function
f or the yielding responses
y = {
y1,
y2, …,
yn}
T which is obtained from the simulation or experimental results by employing the input training sample data of
X = {
x1,
x2, …,
xn}
T. Then, we pursue RBF approximation function
, which is given as
where
ci is the
ith of the
nc basis function centers and
Ψ denotes the
nc vector which is contained the values of the basis function
Ψ, it is evaluated at the Euclidean distances between the prediction site
x and the centers
ci of the basis functions,
wi denotes the weight of the
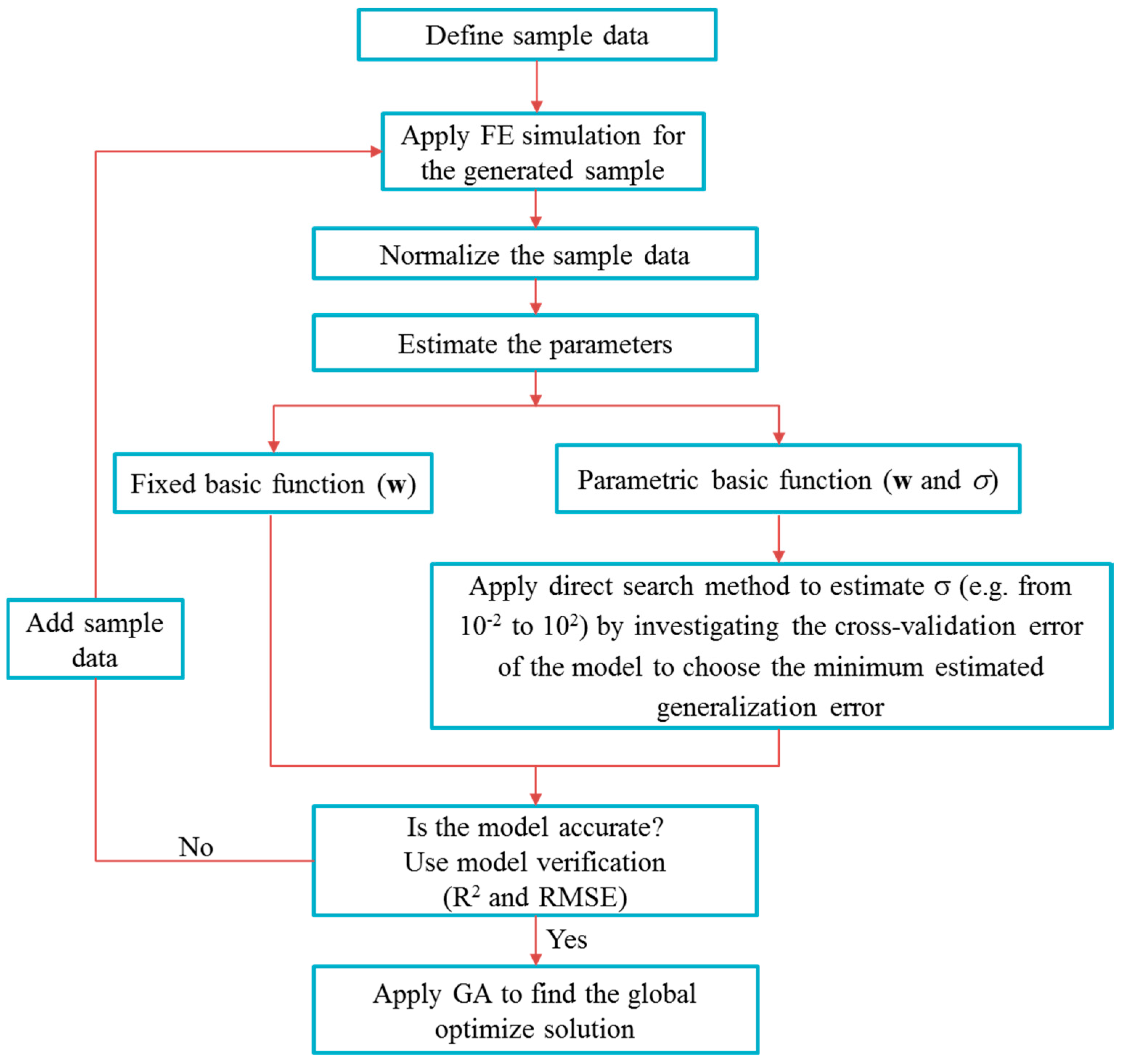
ith basis function. In a previous study, different basis functions are suggested, which is used in RBF, some of the basis functions are stated as follow under categories of fixed and parametric basis functions:
As we have seen from the formulation equation, the weight
w parameters are unknown, in addition, for parametric basis functions, the variance (width) σ is also unknown. The estimation of the weight parameters can be found through the interpolation of
The above equation is linear in terms of the weights
w of the basis function; however, the predictor
y can express highly nonlinear. To obtain a unique solution, the system in Equation (6) has to be square; this means that
nc should be equal to
n. For simplification, the bases coincide with the data points, which means
ci =
xi, for
i = 1, 2, …,
n, this leads us to the equation of
where
Ψ is also called as
Gram matrix and it is defined as
,
i =
j = 1, 2, …,
n. From Equation (7) we can estimate the weight value as
However, if the responses
y = {
y1,
y2, …,
yn}
T are corrupted by noise, using the above equation may affect the prediction model that to fit the observed data. The noise effect should be considered in the model. To solve this kind of problem, Poggio and Girosi [
21] introduced using a regularization parameter λ as model flexibility can control the noise effect on the prediction model. It is also recommended that λ value should be adequately small, such as λ = 1.0 × 10
−3. This will add to the diagonal matrix of
Ψ. So the weight estimation value will be in the form of
where
Ψ, and λ
I are given as follows:
To estimate the sigma value the previous studies proposed different methods, for instance, Nakayama, et al. [
22] proposed
, where
n denotes the number of sampling point,
m denotes the number of process parameters, and
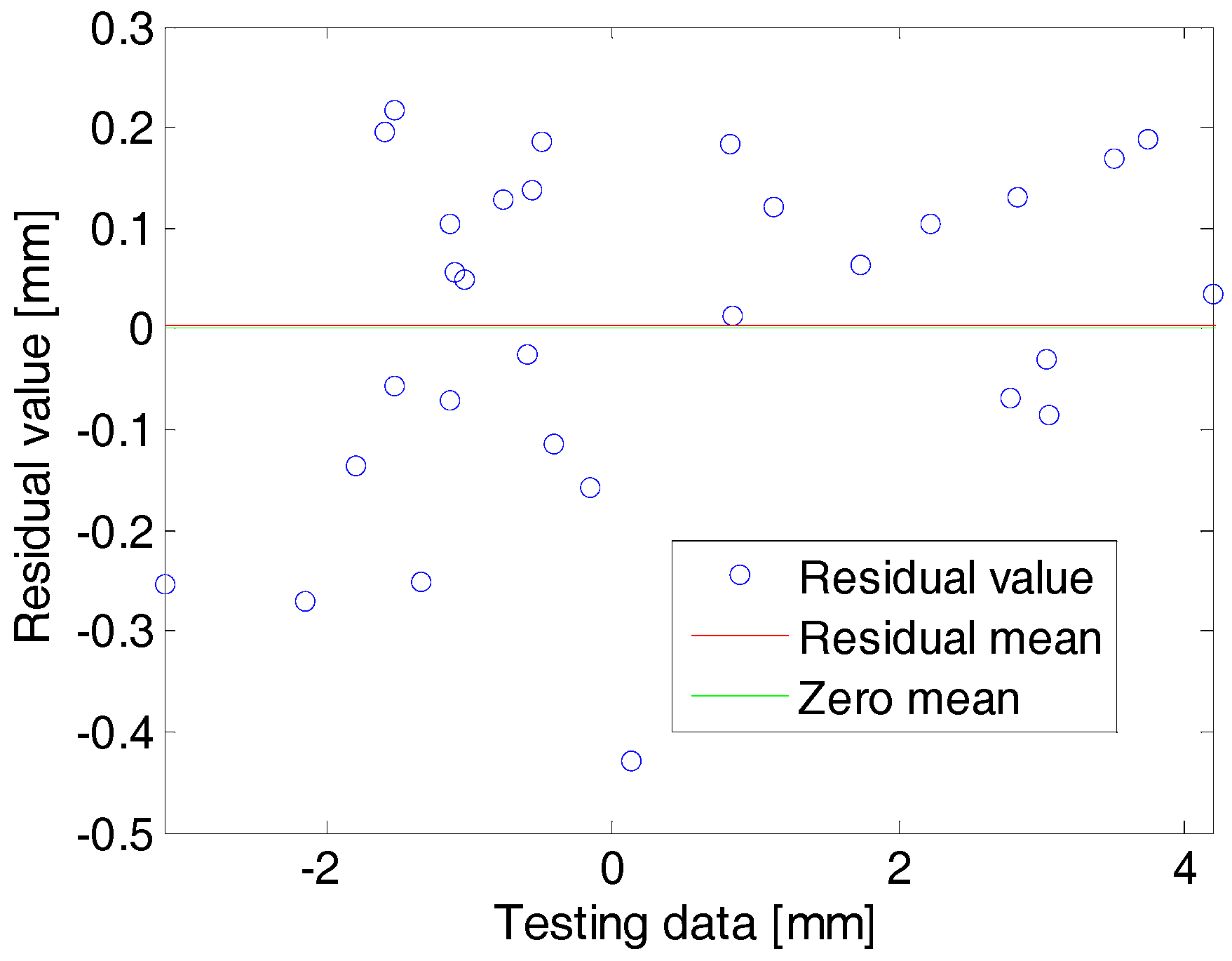
dmax is denotes the maximum distance among the sampling point. Whereas, the accurate estimation of the sigma parameters will allow for us to reduce the generalization (estimated) error of the prediction model, so, this study used the direct search method by investigating the model accuracy using the cross-validation error for each sigma value. Cross-validation is a model verification method, which is used to assess the results of a statistical analysis to simplify the independent data set. Here, the study investigates the model by removing some data from the training sample data and evaluating each sigma value for every removed data and finally we chosen the best sigma value, which has a minimum model cross-validation error. The cross-validation function is given as:
where
q is the number of the removed data from the training sample (subsets of the training sample),
, and
is the true and prediction response value at the
ith removed training sample, respectively. If
q is equal to the number of training sample data
n, the cross-validation error is a nearly balanced estimator of the exact risk. Nevertheless, because of the
n subsets being similar to each other the leave-one-out measure variance can be quite high. Hastie et al. [
23] proposed a desirable value of
q such as
q = 5 or
q = 10, it is depends on the total number of sample data. In general, using less number of the training sample subsets
q means reducing the cross-validation process computational cost by reducing the total number of the fitted model.
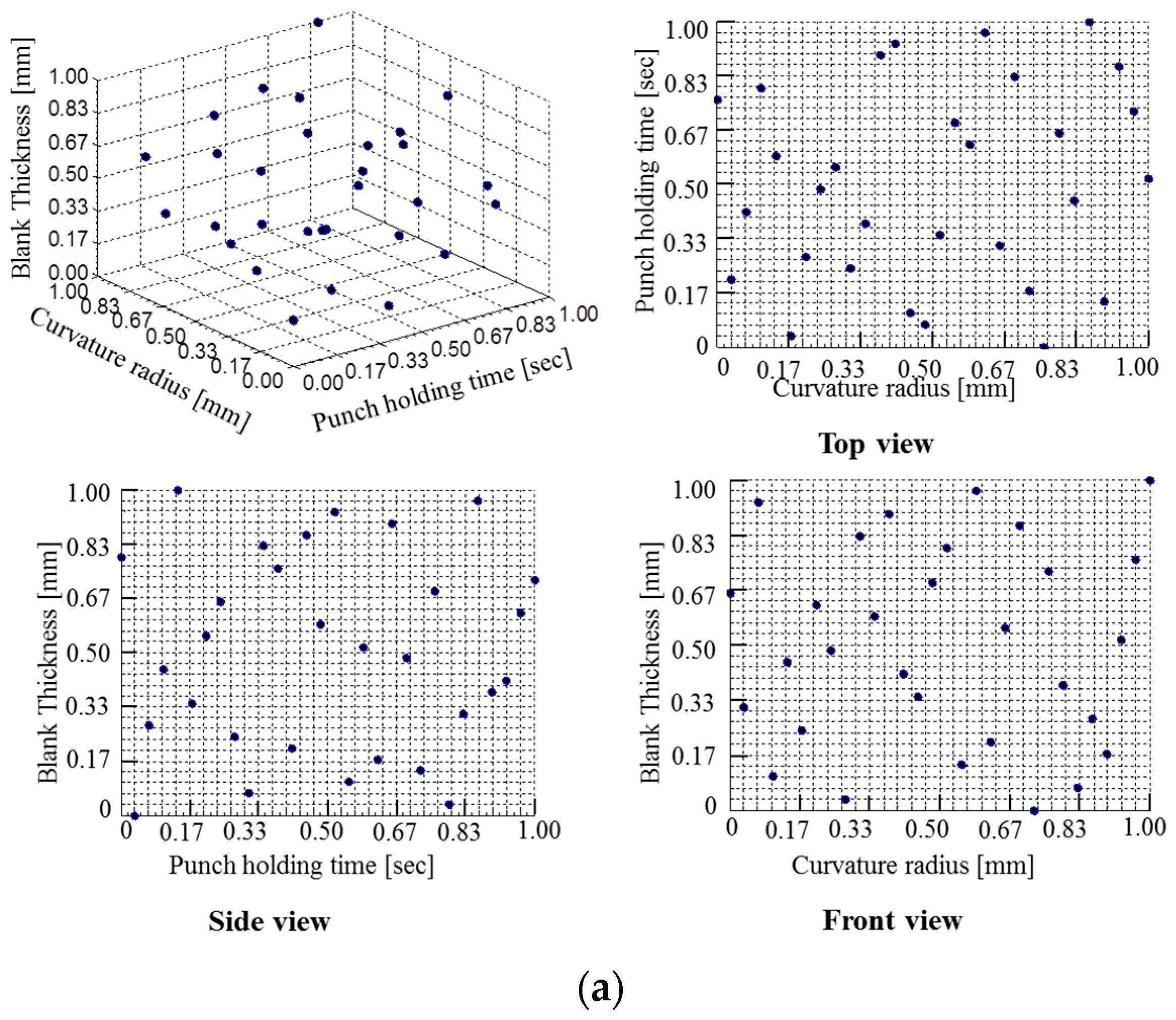
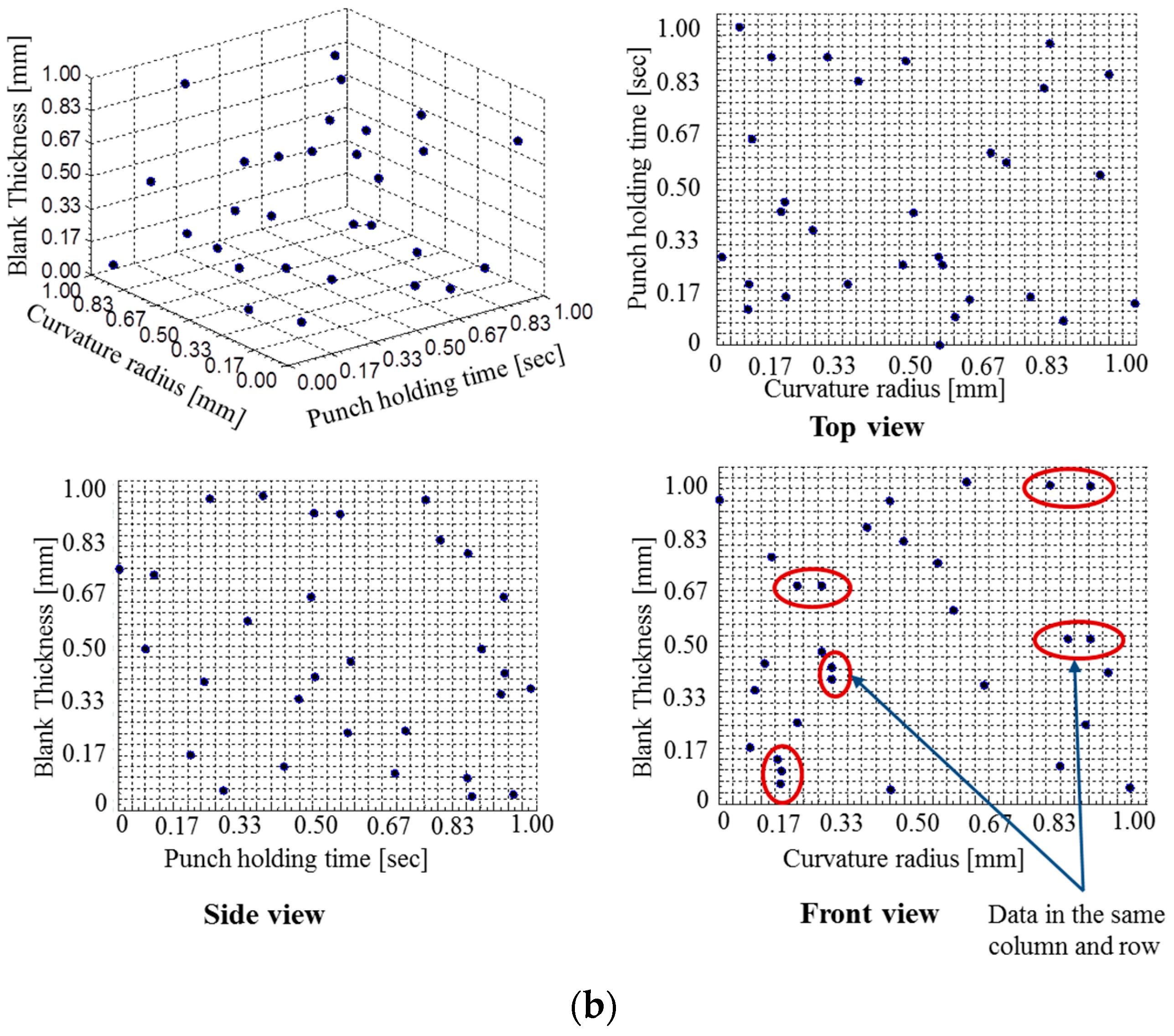
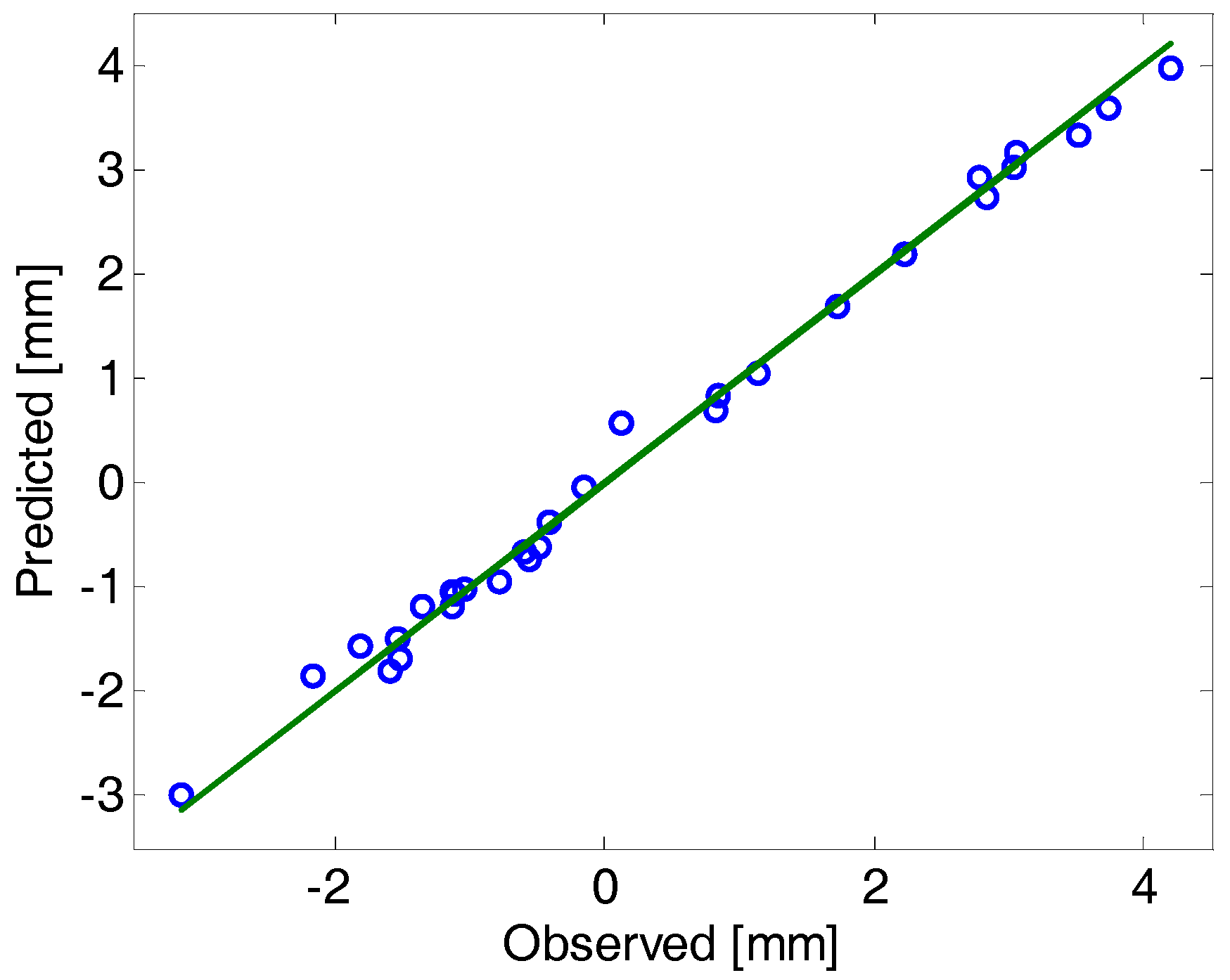
Here, the study used 30 numbers of samples, so we chose
q is equal to 5 and the σ value is searched in between 10
−2 and 10
2. The algorithm is written in MATLAB and the σ value found as 1.6103. In addition, the obtained weight
w value also listed in
Table 3.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












