
The Relationship between Urban Density and Building Energy Consumption


Abstract
:1. Introduction
2. Methodology
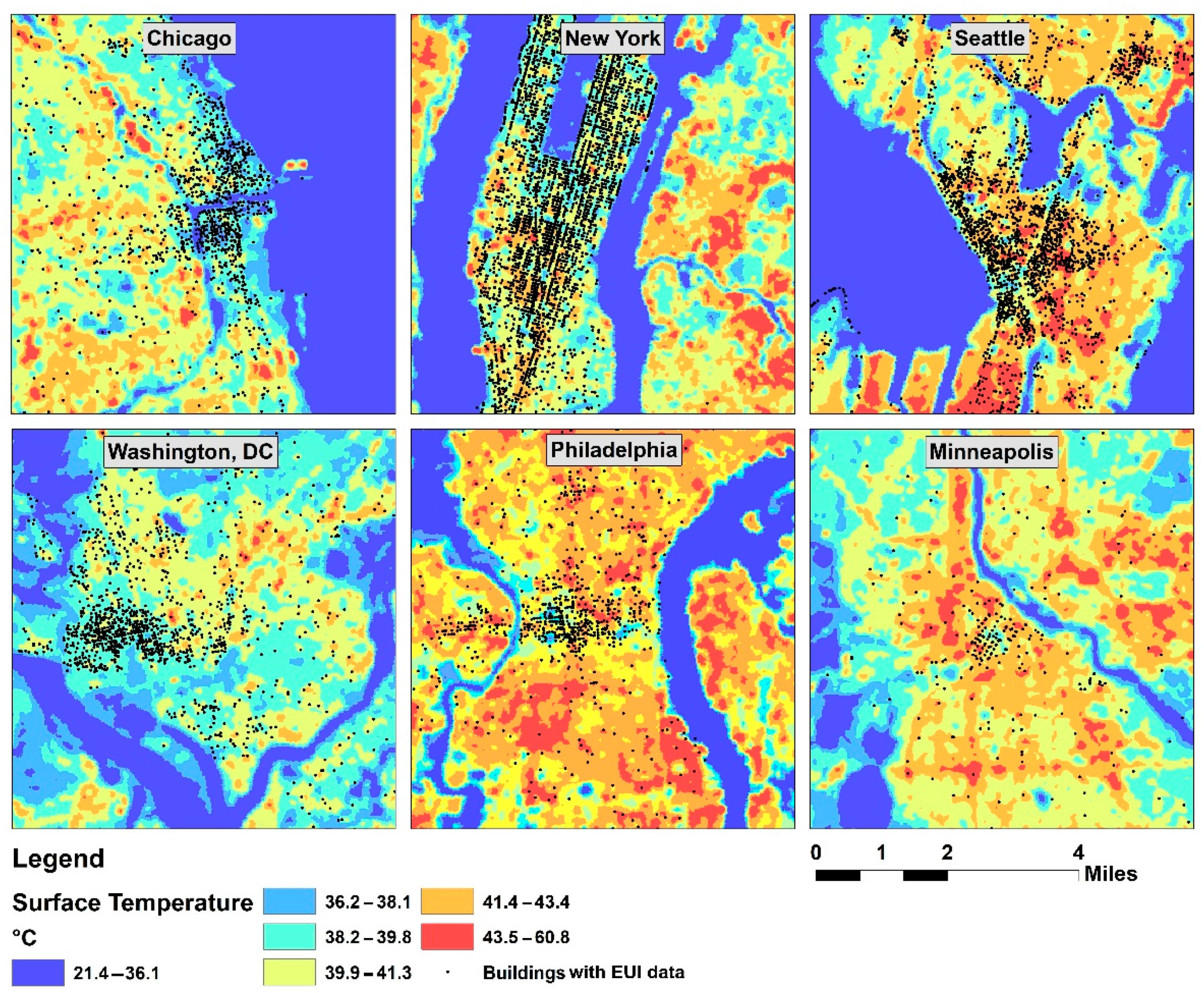
2.1. Data
2.2. Analysis
3. Regression Results
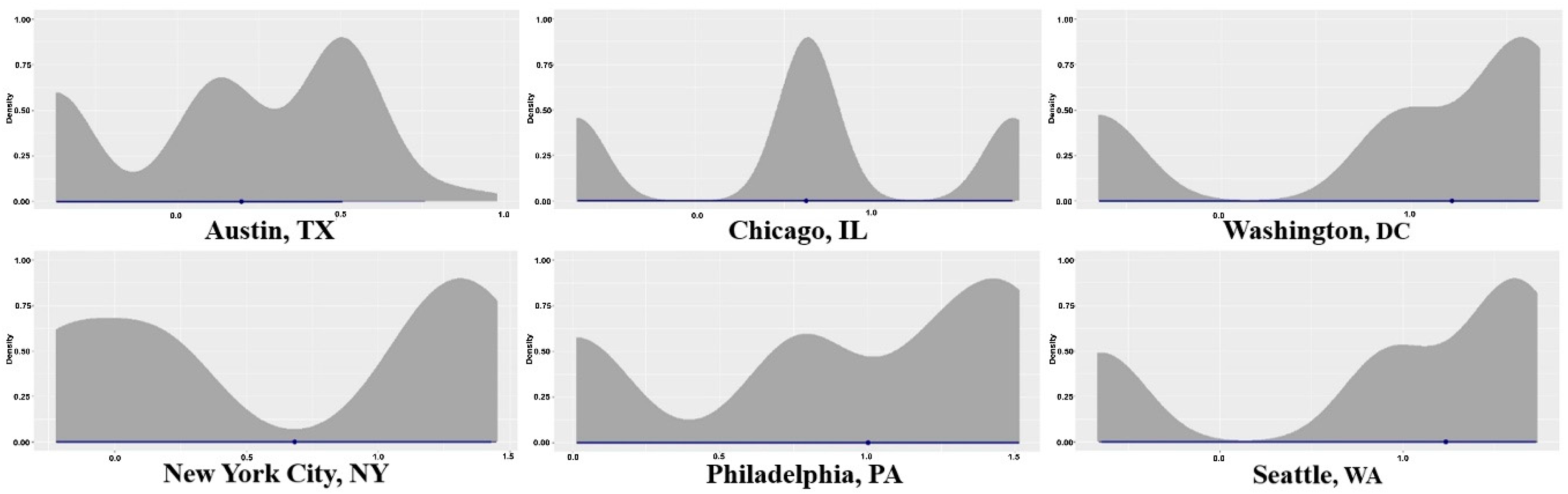
3.1. City-Specific Trends
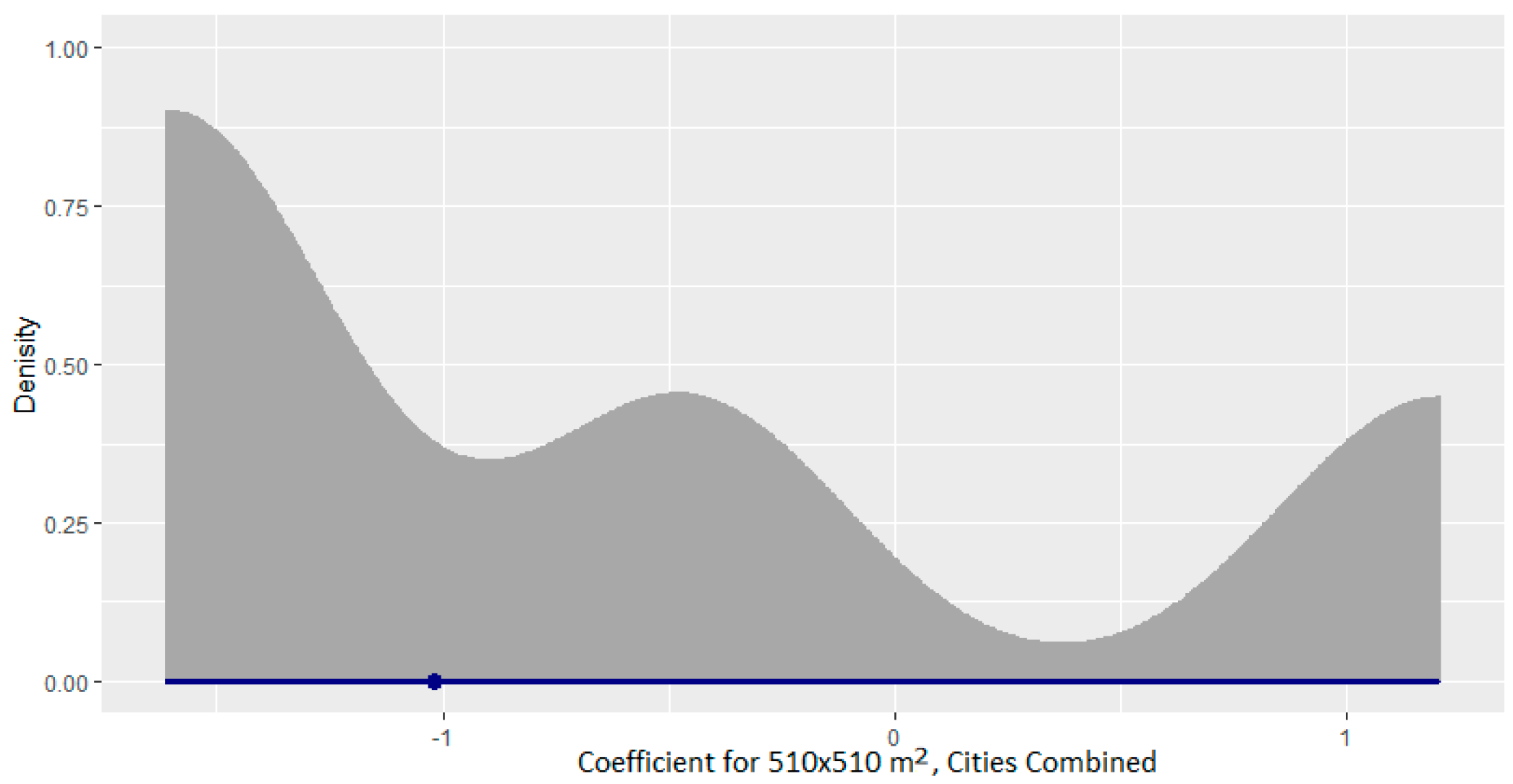
3.2. Cities Combined
3.3. The Bayesian Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mostafavi, N.; Farzinmoghadam, M.; Hoque, S.; Weil, B. Integrated Urban Metabolism Analysis Tool (IUMAT). Urban Policy Res. 2014, 32, 53–69. [Google Scholar] [CrossRef]
- United Nations Population Division World Urbanization Prospects: The 2018 Revision. Available online: https://esa.un.org/unpd/wup/ (accessed on 19 July 2018).
- Kropf, K. Urban Tissue and the Character of Towns. Urban Des. Int. 1996, 1, 247–263. [Google Scholar] [CrossRef]
- Oliveira, V. The elements of urban form. In Urban Morphology; Springer: Cham, Switzerland, 2016; pp. 7–30. [Google Scholar]
- Rode, P.; Floater, G.; Thomopoulos, N.; Docherty, J.; Schwinger, P.; Mahendra, A.; Fang, W. Accessibility in Cities: Transport and Urban Form. In Disrupting Mobility: Impacts of Sharing Economy and Innovative Transportation on Cities; Meyer, G., Shaheen, S., Eds.; Lecture Notes in Mobility; Springer International Publishing: Cham, Switzerland, 2017; pp. 239–273. ISBN 978-3-319-51602-8. [Google Scholar]
- Bramley, G.; Power, S. Urban Form and Social Sustainability: The Role of Density and Housing Type. Environ. Plann. B Plann. Des. 2009, 36, 30–48. [Google Scholar] [CrossRef]
- Frank, L.D.; Engelke, P.O. The Built Environment and Human Activity Patterns: Exploring the Impacts of Urban Form on Public Health. J. Plan. Lit. 2001, 16, 202–218. [Google Scholar] [CrossRef]
- Larson, W.; Zhao, W. Telework: Urban Form, Energy Consumption, and Greenhouse Gas Implications. Econ. Inq. 2017, 55, 714–735. [Google Scholar] [CrossRef]
- Rickwood, P.; Glazebrook, G.; Searle, G. Urban Structure and Energy—A Review. Urban Policy Res. 2008, 26, 57–81. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Liu, X.; Zhou, C.; Hu, J.; Ou, J. Examining the Impacts of Socioeconomic Factors, Urban Form, and Transportation Networks on CO2 Emissions in China’s Megacities. Appl. Energy 2017, 185, 189–200. [Google Scholar] [CrossRef]
- Crane, R. The Influence of Urban Form on Travel: An Interpretive Review. J. Plan. Lit. 2000, 15, 3–23. [Google Scholar] [CrossRef]
- Burton, E. The Potential of the Compact City for Promoting Social Equity. Achiev. Sustain. Urban Form 2000, 19–29. [Google Scholar]
- Dieleman, F.; Wegener, M. Compact City and Urban Sprawl. Built Environ. 2004, 30, 308–323. [Google Scholar] [CrossRef] [Green Version]
- Yamagata, Y.; Seya, H. Simulating a Future Smart City: An Integrated Land Use-Energy Model. Appl. Energy 2013, 112, 1466–1474. [Google Scholar] [CrossRef]
- Pili, S.; Grigoriadis, E.; Carlucci, M.; Clemente, M.; Salvati, L. Towards Sustainable Growth? A Multi-Criteria Assessment of (Changing) Urban Forms. Ecol. Indic. 2017, 76, 71–80. [Google Scholar] [CrossRef]
- Stevenson, M.; Thompson, J.; de Sá, T.H.; Ewing, R.; Mohan, D.; McClure, R.; Roberts, I.; Tiwari, G.; Giles-Corti, B.; Sun, X.; et al. Land Use, Transport, and Population Health: Estimating the Health Benefits of Compact Cities. Lancet 2016, 388, 2925–2935. [Google Scholar] [CrossRef] [Green Version]
- Frey, H. Designing the City: Towards a More Sustainable Urban Form; Taylor & Francis: Milton Park, Abington, 2003. [Google Scholar]
- Wolsink, M. ‘Sustainable City’ Requires ‘Recognition’—The Example of Environmental Education under Pressure from the Compact City. Land Use Policy 2016, 52, 174–180. [Google Scholar] [CrossRef]
- Neuman, M. The Compact City Fallacy. J. Plan. Educ. Res. 2005, 25, 11–26. [Google Scholar] [CrossRef]
- Holden, E.; Norland, I.T. Three Challenges for the Compact City as a Sustainable Urban Form: Household Consumption of Energy and Transport in Eight Residential Areas in the Greater Oslo Region. Urban Stud. 2005, 42, 2145–2166. [Google Scholar] [CrossRef]
- Kaza, N. Urban Form and Transportation Energy Consumption. Energy Policy 2020, 136, 111049. [Google Scholar] [CrossRef]
- Liu, C.; Shen, Q. An Empirical Analysis of the Influence of Urban Form on Household Travel and Energy Consumption. Comput. Environ. Urban Syst. 2011, 35, 347–357. [Google Scholar] [CrossRef]
- Mindali, O.; Raveh, A.; Salomon, I. Urban Density and Energy Consumption: A New Look at Old Statistics. Transp. Res. Part A Policy Pract. 2004, 38, 143–162. [Google Scholar] [CrossRef]
- Næss, P. Residential Location Affects Travel Behavior—but How and Why? The Case of Copenhagen Metropolitan Area. Prog. Plan. 2005, 2, 167–257. [Google Scholar] [CrossRef]
- Yang, X.; Peng, L.L.H.; Jiang, Z.; Chen, Y.; Yao, L.; He, Y.; Xu, T. Impact of Urban Heat Island on Energy Demand in Buildings: Local Climate Zones in Nanjing. Appl. Energy 2020, 260, 114279. [Google Scholar] [CrossRef]
- Ewing, R.; Rong, F. The Impact of Urban Form on U.S. Residential Energy Use. Hous. Policy Debate 2008, 19, 1–30. [Google Scholar] [CrossRef]
- Wang, M.; Elgowainy, A.; Benavides, P.T.; Burnham, A.; Cai, H.; Dai, Q.; Hawkins, T.R.; Kelly, J.C.; Kwon, H.; Lee, D.-Y.; et al. Argonne GREET Publication: Summary of Expansions and Updates in GREET® 2018; Sysetms Assessment Group, Energy Systems Division; Argonne National Laboratory: Argonne, IL, USA, 2018; p. 32.
- O’Malley, C.; Piroozfarb, P.A.; Farr, E.R.; Gates, J. An Investigation into Minimizing Urban Heat Island (UHI) Effects: A UK Perspective. Energy Procedia 2014, 62, 72–80. [Google Scholar] [CrossRef] [Green Version]
- Valladares-Rendón, L.G.; Schmid, G.; Lo, S.-L. Review on Energy Savings by Solar Control Techniques and Optimal Building Orientation for the Strategic Placement of Façade Shading Systems. Energy Build. 2017, 140, 458–479. [Google Scholar] [CrossRef]
- Gros, A.; Bozonnet, E.; Inard, C. Cool Materials Impact at District Scale—Coupling Building Energy and Microclimate Models. Sustain. Cities Soc. 2014, 13, 254–266. [Google Scholar] [CrossRef]
- Roman, K.K.; O’Brien, T.; Alvey, J.B.; Woo, O. Simulating the Effects of Cool Roof and PCM (Phase Change Materials) Based Roof to Mitigate UHI (Urban Heat Island) in Prominent US Cities. Energy 2016, 96, 103–117. [Google Scholar] [CrossRef]
- Lee, H.; Mayer, H.; Chen, L. Contribution of Trees and Grasslands to the Mitigation of Human Heat Stress in a Residential District of Freiburg, Southwest Germany. Landsc. Urban Plan. 2016, 148, 37–50. [Google Scholar] [CrossRef]
- Pisello, A.L.; Taylor, J.E.; Xu, X.; Cotana, F. Inter-Building Effect: Simulating the Impact of a Network of Buildings on the Accuracy of Building Energy Performance Predictions. Build. Environ. 2012, 58, 37–45. [Google Scholar] [CrossRef]
- Han, Y.; Taylor, J.E.; Pisello, A.L. Exploring Mutual Shading and Mutual Reflection Inter-Building Effects on Building Energy Performance. Appl. Energy 2017, 185, 1556–1564. [Google Scholar] [CrossRef] [Green Version]
- Adolphe, L. A Simplified Model of Urban Morphology: Application to an Analysis of the Environmental Performance of Cities. Environ. Plann. B Plann. Des. 2001, 28, 183–200. [Google Scholar] [CrossRef]
- Steemers, K. Energy and the City: Density, Buildings and Transport. Energy Build. 2003, 35, 3–14. [Google Scholar] [CrossRef]
- Ratti, C.; Baker, N.; Steemers, K. Energy Consumption and Urban Texture. Energy Build. 2005, 37, 762–776. [Google Scholar] [CrossRef]
- Krüger, E.; Pearlmutter, D.; Rasia, F. Evaluating the Impact of Canyon Geometry and Orientation on Cooling Loads in a High-Mass Building in a Hot Dry Environment. Appl. Energy 2010, 87, 2068–2078. [Google Scholar] [CrossRef]
- Ali-Toudert, F. Energy Efficiency of Urban Buildings: Significance of Urban Geometry, Building Construction and Climate Conditions. In Proceedings of the Seventh International Conference on Urban Climate, Yokohama, Japan, 29 June–3 July 2009; Volume 29. [Google Scholar]
- Strømann-Andersen, J.; Sattrup, P.A. The Urban Canyon and Building Energy Use: Urban Density versus Daylight and Passive Solar Gains. Energy Build. 2011, 43, 2011–2020. [Google Scholar] [CrossRef]
- Wong, N.H.; Jusuf, S.K.; Syafii, N.I.; Chen, Y.; Hajadi, N.; Sathyanarayanan, H.; Manickavasagam, Y.V. Evaluation of the Impact of the Surrounding Urban Morphology on Building Energy Consumption. Sol. Energy 2011, 85, 57–71. [Google Scholar] [CrossRef]
- Futcher, J.A.; Mills, G. The Role of Urban Form as an Energy Management Parameter. Energy Policy 2013, 53, 218–228. [Google Scholar] [CrossRef]
- Ahn, Y.; Sohn, D.-W. The Effect of Neighbourhood-Level Urban Form on Residential Building Energy Use: A GIS-Based Model Using Building Energy Benchmarking Data in Seattle. Energy Build. 2019, 196, 124–133. [Google Scholar] [CrossRef]
- Williams, K. Spatial Planning, Urban Form and Sustainable Transport; Routledge: Milton Park, Abingdon, 2017; ISBN 978-1-351-89872-0. [Google Scholar]
- Güneralp, B.; Zhou, Y.; Ürge-Vorsatz, D.; Gupta, M.; Yu, S.; Patel, P.L.; Fragkias, M.; Li, X.; Seto, K.C. Global Scenarios of Urban Density and Its Impacts on Building Energy Use through 2050. Proc. Natl. Acad. Sci. USA 2017, 114, 8945–8950. [Google Scholar] [CrossRef] [Green Version]
- Aschwanden, G.D.P.A.; Haegler, S.; Bosché, F.; Van Gool, L.; Schmitt, G. Empiric Design Evaluation in Urban Planning. Autom. Constr. 2011, 20, 299–310. [Google Scholar] [CrossRef]
- Raimbault, J.; Perret, J. Generating Urban Morphologies at Large Scales; MIT Press: Cambridge, MA, USA, 2019; pp. 179–186. [Google Scholar]
- Heris, M.P. Evaluating Metropolitan Spatial Development: A Method for Identifying Settlement Types and Depicting Growth Patterns. Reg. Stud. Reg. Sci. 2017, 4, 7–25. [Google Scholar] [CrossRef] [Green Version]
- Ward, M.D.; Gleditsch, K.S. Spatial Regression Models; SAGE Publications: Thousand Oaks, CA, USA, 2018; ISBN 978-1-5443-2882-9. [Google Scholar]
- Bivand, R.S.; Pebesma, E.J.; Gómez-Rubio, V.; Pebesma, E.J. Applied Spatial Data Analysis with R, 2nd ed.; Springer: New York, NY, USA, 2013; Volume 747248717. [Google Scholar]
- Chen, Y. Spatial Autocorrelation Approaches to Testing Residuals from Least Squares Regression. PLoS ONE 2016, 11, e0146865. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- CRAN Brms: Bayesian Regression Models Using ‘Stan’. J. Intell. 2020, 8, 5.
- Bürkner, P.-C. Advanced Bayesian Multilevel Modeling with the R Package Brms. R. J. 2018, 10, 395–411. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Austin, TX | NYC, NY | Philadelphia, PA | Seattle, WA | Chicago, IL | Washington, DC | Minneapolis, MN | |
|---|---|---|---|---|---|---|---|
| Hotel | 22 (7%) | 164 (4%) | 38 (3%) | 75 (2%) | 45 (3%) | 71 (6%) | 13 (5%) |
| Multi-use | 19 (6%) | 114 (4%) | |||||
| Warehouse | 42 (14%) | ||||||
| Office | 81 (27%) | 837 (18%) | 153 (13%) | 375 (12%) | 239 (14%) | 398 (32%) | 66 (27%) |
| Retail | 98 (32%) | ||||||
| Residential | 3245 (70%) | 320 (28%) | 1649 (55%) | 694 (40%) | 458 (36%) | 1 (0%) | |
| College | 27 (2%) | 66 (4%) | 15 (1%) | ||||
| School | 176 (15%) | 134 (4%) | 320 (19%) | 117 (9%) | |||
| Parking | 33 (13%) | ||||||
| Other | 41 (14%) | 388 (8%) | 425 (37%) | 671 (22%) | 363 (21%) | 615 (49%) | 133 (54%) |
| City | Model Type | Urban Form Impact | Selected Window |
|---|---|---|---|
| Austin, TX | Linear | Yes | 1950 × 1950 m2 |
| Chicago, IL | Hierarchical | Yes | 270 × 270 m2 |
| Washington, DC | Hierarchical | Yes | 1950 × 1950 m2 |
| Minneapolis, MN | Linear | No | n/a |
| New York City, NY | Hierarchical | Yes | 390 × 390 m2 |
| Philadelphia, PA | Hierarchical | Yes | 510 × 510 m2 |
| Seattle, WA | Hierarchical | Yes | 1590 × 1590 m2 |
| Moran’s I | p-Value | |
|---|---|---|
| Austin, TX | 0.38 | 0.02 |
| Chicago, IL | 0.07 | <0.001 |
| Washington, DC | 0.00 | 0.47 |
| Minneapolis, MN | NA | n/a |
| New York City, NY | 0.17 | <0.001 |
| Philadelphia, PA | 0.06 | <0.001 |
| Seattle, WA | 0.03 | <0.001 |
| Austin | Chicago | DC | NYC | Philadelphia | Seattle | |
|---|---|---|---|---|---|---|
| Area of building coverage | 0.00% | |||||
| Tree-covered area | 0.24% | 0.00% | ||||
| Impervious area | n/a | 0.06% | n/a | |||
| Morphological density | −7.39% | 19.15% | ||||
| Housing density per hectare | n/a | |||||
| Building count per hectare | −0.14% | 2.38% | −1.14% |
| Estimate | Standard Error | z Value | Pr (>|z|) | |
|---|---|---|---|---|
| Intercept | 3.692 | 0.068 | 54.622 | <0.001 |
| Philadelphia dummy | −0.026 | 0.032 | −0.810 | 0.418 |
| New York City dummy | 0.282 | 0.026 | 11.005 | <0.001 |
| Chicago dummy | 0.428 | 0.027 | 15.943 | <0.001 |
| Residential (1 = yes) | −0.167 | 0.015 | −10.821 | <0.001 |
| Office (1 = yes) | −0.001 | 0.019 | −0.031 | 0.975 |
| Warehouse (1 = yes) | −0.900 | 0.038 | −23.384 | <0.001 |
| Worship center (1 = yes) | −0.460 | 0.061 | −7.532 | <0.001 |
| Hospital (1 = yes) | 0.870 | 0.067 | 13.017 | <0.001 |
| Hotel (1 = yes) | 0.331 | 0.042 | 7.879 | <0.001 |
| Property value (USD 1000) | 0.000 | 0.000 | −1.873 | 0.061 |
| Area (1000 ft2) | 0.000 | 0.000 | 1.640 | 0.101 |
| Percentage of residential neighbors | −0.004 | 0.031 | −0.123 | 0.902 |
| Tree-cover area | 0.000 | 0.000 | 3.056 | 0.002 |
| Impervious area | 0.000 | 0.000 | 2.222 | 0.026 |
| Area of building coverage | 0.000 | 0.000 | 0.284 | 0.776 |
| Morphological density category (1 = 5) | 0.038 | 0.021 | 1.829 | 0.067 |
| Building count per hectare | −0.005 | 0.001 | −3.795 | <0.001 |
| Housing density per hectare | 0.001 | 0.000 | 3.541 | <0.001 |
| Cooling degree days (CDD) | 0.0002 | 0.000 | 9.384 | <0.001 |
| Confidence Interval | |||||
|---|---|---|---|---|---|
| Estimate | Standard Error | Lower Limit | Upper Limit | ||
| Intercept | 3.9 | 0.2 | 3.54 | 4.29 | 1.13 |
| Morphological density category | 0.05 | 0.01 | 0.02 | 0.06 | 1.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mostafavi, N.; Heris, M.P.; Gándara, F.; Hoque, S. The Relationship between Urban Density and Building Energy Consumption. Buildings 2021, 11, 455. https://doi.org/10.3390/buildings11100455
Mostafavi N, Heris MP, Gándara F, Hoque S. The Relationship between Urban Density and Building Energy Consumption. Buildings. 2021; 11(10):455. https://doi.org/10.3390/buildings11100455
Chicago/Turabian StyleMostafavi, Nariman, Mehdi Pourpeikari Heris, Fernanda Gándara, and Simi Hoque. 2021. "The Relationship between Urban Density and Building Energy Consumption" Buildings 11, no. 10: 455. https://doi.org/10.3390/buildings11100455
APA StyleMostafavi, N., Heris, M. P., Gándara, F., & Hoque, S. (2021). The Relationship between Urban Density and Building Energy Consumption. Buildings, 11(10), 455. https://doi.org/10.3390/buildings11100455