This section explains the details of the system and the approach used for system modelling and optimization.
2.1. System Description
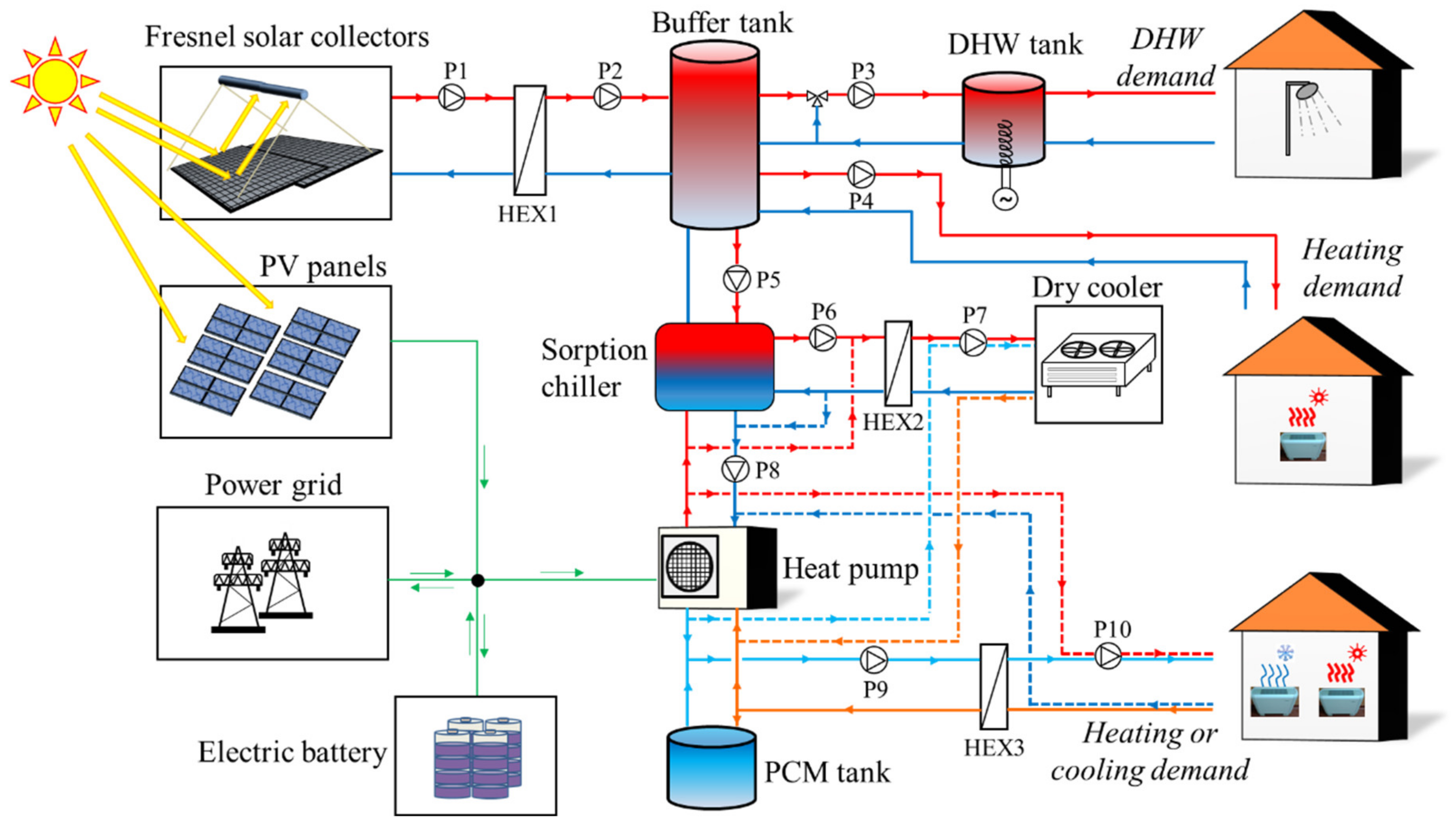
The system considered in this study (
Figure 1) was designed to ensure comfort indoor conditions and domestic hot water (DHW) in residential buildings, and specifically to reduce primary energy consumption of single-family houses located in Mediterranean climate regions. Therefore, the different system components were chosen and sized with the main purpose to meet most of the cooling demand using solar energy. To enhance the energy efficiency of the system and the share of renewable energy, it incorporates four different energy storage technologies: an electric battery connected to PV panels, a low-temperature phase change material (PCM) storage unit connected to the low-pressure side of the heat pump, a sorption chiller connected to the high-pressure side of the heat pump and a buffer water tank that stores the heat produced by the Fresnel solar collectors. The hot water stored in the buffer tank is used to drive the sorption chiller and also to contribute to heating and DHW supply.
The heat pump is fed with DC current by means of a DC-bus, which interconnects the PV panels, electric battery, heat pump and (by means of an AC/DC inverter) the power grid. Even though this type of connection enhances the complexity of the system, it also gives a high flexibility and improves the efficiency of the system by reducing the number of multiple stages of conversions from DC to AC and vice-versa.
To obtain the energy demand of the building, a single-family residential building located in Athens was considered as a reference building for Mediterranean climate regions. The building has a total surface of 100 m
2 distributed in two floors, each having a living surface area of 50 m
2, and it was assumed to be inhabited by four people. The ceiling/floor heights considered were 2.5 m/3.0 m, while the building width/depth were 6.5 m/8.0 m. The glazing ratio considered was of 20% on the south side, 10% on the north side and 12% on the east and west sides. The energy demand profile for cooling, heating and DHW of the building were obtained within the HYBUILD project [
23] activities and it is out of the scope of this paper to present the details of energy demand calculations.
2.2. Components Models and Operating Modes Description
This subsection presents the main system components mathematical models along with the associated operating modes, which were implemented in the control strategies developed for the system.
2.2.1. Fresnel Collectors
The Fresnel collectors consist of flat mirrors that can rotate around a fixed horizontal axis oriented along the north-south direction. There are only two possible operating modes of this component: mode 1 (on) and mode 2 (off). In mode 1, the orientation of the mirrors is set by a controller in such a way that they focus the incident solar radiation to the receiver that is located on top of the mirrors to heat the water in the primary circuit up to 100 °C. The heat is transferred to the buffer tank by means of a heat exchanger (HEX1) and two circulation pumps (P1 and P2) installed in the primary and secondary circuits, respectively. No heat losses were considered in HEX1 for simplicity. In mode 2, no heat is harvested by the solar collectors and pumps P1 and P2 are switched off.
When operating in mode 1, the thermal power generated by the Fresnel collectors (
, in kW) is given by Equation (1), otherwise
.
where
is the optical efficiency of the receiver,
is the mirror cleanness factor, DNI (in W/m
2) is the direct normal irradiance at the specified location [
24],
°C is the mean receiver temperature,
(in °C) is the ambient air temperature [
24],
(in m/s) is the wind speed [
24] and
m
2 is the total surface area of the solar collectors.
The values for the optical efficiency of the receiver (
) depend on the month of the year and on the geographic coordinates of the location, and were provided by the manufacturer within HYBUILD activities [
22].
The overall electricity consumption of Fresnel collectors is the sum of the consumption of the circulation pumps P1 (34 W) and P2 (34 W), when the Fresnel collectors operate in mode 1, otherwise the electricity consumption of this component is zero.
2.2.2. PV Panels
The PV panels were assumed to face south and have a tilt angle of 30° with respect to the horizontal plane. The net power generated by the PV panels (
, in kW) is given by Equation (2):
where
[
25] is the efficiency of the
PV system,
(in W/m
2) is the plan of array (
POA) irradiance at the specified location and
m
2 is the PV panels surface area. The efficiency of auxiliary components related to the
PV system (DC/DC converter, connections, etc.) was assumed to be accounted for in
.
The value of the solar irradiance incident to the PV surface (
, in W/m
2) is the sum of three contributions, as shown in Equation (3):
where
(in W/m
2) is the POA beam component,
(in W/m
2) is the POA ground-reflected component and
(in W/m
2) is the POA sky-diffuse component.
The three contributions shown in the right-hand member of Equation (3) were obtained using Pysolar library [
26] and Reindl model [
27,
28,
29], and assuming an albedo of 0.2.
2.2.3. Heat Pump and PCM Tank
The heat pump (HP) is one of the core components of the system and it is mainly used to provide space cooling, although it can also provide space heating. On the one hand, the low-pressure circuit of the HP is connected to an innovative type of PCM tank, which can at the same time act as the evaporator of the heat pump. The main purpose of the PCM tank is to store the surplus of coolness produced by the HP during periods of low cooling demand and high PV production, when the electric battery is already completely charged. On the other hand, the high-pressure circuit of the HP (condenser) is connected, by means of a hydraulic loop, to the evaporator of a sorption chiller, so that the heat rejected by the HP condenser is absorbed by the evaporator of the sorption chiller. The objective of this connection is to increase the efficiency (EER) of the HP and reduce therefore the overall electricity consumption of the heat pump.
As shown in
Figure 1, the hydraulic connections allow the HP and PCM tank to operate in different modes, either for cooling or heating purposes, as summarized in
Table 1.
The PCM tank consists of a compact three-fluids (refrigerant-PCM-water) heat exchanger, in which PCM is placed in an array of parallel channels containing aluminum fins, sandwiched between refrigerant and water channels in an alternating sequence. This configuration allows for efficient heat transfer between the three fluids in the same container, also made of aluminum, which allows for easy charging and discharging of the PCM, as well as direct heat transfer between the supply and demand circuits. An amount of 160 kg of the commercial RT4 PCM, which is a paraffin that melts around 5 °C, was considered in the PCM tank. A complete description of the HP and PCM tank model can be found in [
30]. A slightly improved model for the PCM tank was used in this study to also consider the sensible contribution to the overall energy stored in the PCM tank, as well as energy losses to the ambient. The updated relation between the charging level of the PCM tank (
, in kJ) and the PCM temperature (
, in °C) at time
t is shown in Equation (4):
Regardless the operating mode, the change in the energy stored in the PCM tank at time
t is calculated from the charging level at the previous time slot (
, in kJ) and the net rate of coolness transfer to the PCM in the time interval
(in seconds), as shown in Equation (5):
where
(in kW) is the rate of coolness transfer to the PCM and
(in kW) are the coolness losses from the PCM tank to the ambient air at temperature
(in °C). The thermal resistance of the PCM tank (
) was estimated to be equal to 424.5 K/kW.
The rate of coolness transfer to the PCM (
) depends on the operating mode. When operating in cooling mode 1, the entire energy (coolness) generated by the HP (
, in kW) [
30] is transferred to the PCM, so that
. In cooling mode 2, the PCM is discharged by the heat transfer fluid (HTF) of the building cooling circuit, and it was assumed to be equal (in absolute value) to the cooling demand, i.e.,
. In cooling mode 3, an energy balance is needed to determine the net rate of coolness transferred to the PCM because, on the one hand, the PCM is cooled down by the refrigerant and, on the other hand, it is heated up by the HTF. Therefore, in cooling mode 3, the PCM tank can actually be charging or discharging, depending on the charge level and the cooling demand. In cooling mode 4, the heat pump operates with the standard evaporator and the PCM tank is by-passed, and the same occurs when the heat pump operates in the heating mode. Therefore,
in cooling mode 4 and in heating mode.
When the heat pump operates in heating mode, the sorption chiller is always off. The heat required by the building is taken from the ambient air through the dry cooler by activating pump P7 and by-passing HEX2, and it is delivered to the building heating loop connected to the condenser of the heat pump by activating P10 and by-passing HEX3.
Once the charging level of the PCM tank at time slot t (
) is calculated, the PCM temperature and the water temperature at condenser outlet (
) can be updated. Moreover, the electricity consumption of the compressor of the heat pump (
), as well as the electricity consumption of all auxiliary equipment (pumps, dry cooler, fan-coils), can be calculated by taking into account what components are active in each operating mode according to
Table 1. Only the compressor of the heat pump is driven by the DC-bus, while all other equipment uses electricity directly from the grid.
2.2.4. Sorption Chiller
The sorption chiller consists of two adsorbers based on a silica gel/water system, which switch periodically between adsorption and desorption operation in counter phase, a condenser and an evaporator. There are only two possible operating modes for the sorption chiller: mode 1 in which the sorption chiller is on and mode 2 in which it is off. In mode 1, the adsorption cycle is activated thanks to the hot water provided by the buffer tank. To work properly, the temperature of the hot water provided by the buffer tank () should lie between 65 °C and 95 °C. At the evaporator side of the sorption chiller, heat is taken from the condenser of the HP. The waste heat produced by the sorption chiller is drained by the dry cooler to the ambient air at temperature .
The thermal coefficient of performance () of the sorption chiller is defined as , where (in kW) is the cooling power (heat taken from the condenser of the HP) and (in kW) is the thermal power extracted from the buffer tank. Experimental tests performed in the lab showed that can be considered constant and equal to 0.55 for a large range of operating conditions.
The cooling power of the sorption module (
) is a function of the water temperature at the evaporator inlet (
, in °C), the water temperature that returns from the dry cooler (
, in °C) and the water temperature that returns from the buffer tank (
, in °C) [
31], as shown in Equation (6):
The return water temperature from the dry cooler () was assumed to be 5 K above the ambient temperature, i.e., . The water temperature at the evaporator inlet () was assumed to be equal to the water temperature at the outlet of the condenser of the HP evaluated at the previous time slot, i.e., .
Therefore, the thermal power extracted from the buffer tank (
) can be calculated according to Equation (7) [
31]:
Water temperature at the outlet of the adsorption module (
, in °C) can be obtained using an energy balance as shown in Equation (8):
where
kg/s is the mass flow rate of the water in the loop that connects the buffer tank with the sorption chiller and
kJ/(kg·K) is the specific heat capacity of the water.
Finally, the water temperature at the evaporator outlet (
, in °C) can be obtained using an energy balance as shown in Equation (9):
where
kg/s is the mass flow rate of the water in the loop that connects the condenser of the HP with the evaporator of the sorption chiller.
In mode 2, the sorption chiller is off and the following values were assumed for the main variables related to the sorption chiller: , , and , where (in °C) is the temperature of the water at the top part of the buffer tank at the previous time slot.
The overall electricity consumption of the sorption chiller in mode 1 is the sum of the electricity consumption of the dry cooler, pumps P5–P8 and the actuators of the hydraulic system and controller (around 200 W). In mode 2, the electricity consumption of the sorption chiller is zero. The electricity needed to feed the sorption module is taken from the grid.
2.2.5. Dry Cooler
The dry cooler switches on whenever there is a need to reject heat from the system to the ambient air, i.e., when the sorption chiller and/or the heat pump are on. The electricity consumption of the dry cooler (
, in kW) depends on the part load of the dry cooler (
) and it is given in Equation (10) [
32]:
The part load (
) is defined as the actual thermal power to be rejected or absorbed by the dry cooler divided by its nominal thermal power (40 kW), i.e.,
. The actual thermal power (
, in kW) depends on the operating modes of both the sorption chiller and the HP, as shown in Equation (11):
where
(in kW) is the rate of heat rejected by the HP condenser and
(in kW) is the heat absorbed by the dry cooler from the ambient air.
2.2.6. DHW Tank
The DHW tank is used in the system to store a sufficient amount of hot water able to meet the DHW demand of the building at any moment. Therefore, the water stored in the tank should always be kept above a minimum temperature level. To achieve it, the DHW tank should be heated with hot water from the buffer tank. An electric heater can also be used as a backup in case the temperature in the buffer tank is not high enough to be able to charge the DHW tank. In case the water temperature inside the DHW tank lies within the required temperature range, no heat is provided to the DHW tank. This means that there are three possible operating modes for the DHW tank: mode 1, in which the DHW tank is heated by the buffer tank, mode 2, in which it is heated by the electric heater and mode 3, when no heat is provided to the DHW tank.
In mode 1, pump P3 is activated to circulate hot water from the top part of the buffer tank to heat the DHW tank. This mode can be activated whenever the temperature inside the DHW tank (, in °C) is below a lower threshold () and the temperature of the water at the top part of the buffer tank (, in °C) is above a given threshold (). The DHW tank is heated by the water from the buffer tank until the water temperature inside the DHW reaches the upper threshold of the set-point temperature () or the buffer tank temperature is lower than the required threshold (), whichever occurs first. The value considered for the set-point temperature of the DHW tank is °C.
Mode 2 is activated when the temperature inside the DHW tank is below the set-point range () and the DHW tank is heated by the electric heater (instead of the buffer tank). Similar to mode 1, the electric heater is switched off when the water temperature reaches the upper threshold of the set-point temperature (). In mode 3, water temperature inside the DHW tank lies within the required temperature range (), so no heat is supplied to the DHW tank, although heat can be discharged from the DHW tank to meet the demand.
In all three modes, the temperature distribution inside the tank is considered homogeneous, and it can be calculated at any time
t by means of an energy balance given in Equation (12):
where
and
for DHW mode
respectively,
(in kW) is the heat extracted from the buffer tank,
kW is the thermal power supplied by the electric heater,
(in kW) is the DHW demand,
(in kW) are the heat losses from the DHW tank to the ambient air,
kg is the mass of the water inside the DHW tank and
(in °C) is the temperature of the water inside the DHW tank calculated in the previous time slot.
The heat extracted from the buffer tank (
) depends on the temperature inside the DHW tank (
) as shown in Equation (13):
where
kg/s is the water mass flow rate (displaced by pump P3) in the loop that charges the DHW tank and
°C is the set-point of water temperature at the DHW tank inlet.
Heat losses from the DHW tank to the ambient air (
) are calculated using Equation (14):
where
K/kW is the overall thermal resistance of the DHW tank.
The electricity consumption of the DHW tank from the grid is associated to the circulating pump P3 (only in mode 1) and the electric heater (only in mode 2). There is no electricity consumption in mode 3.
2.2.7. Buffer Tank
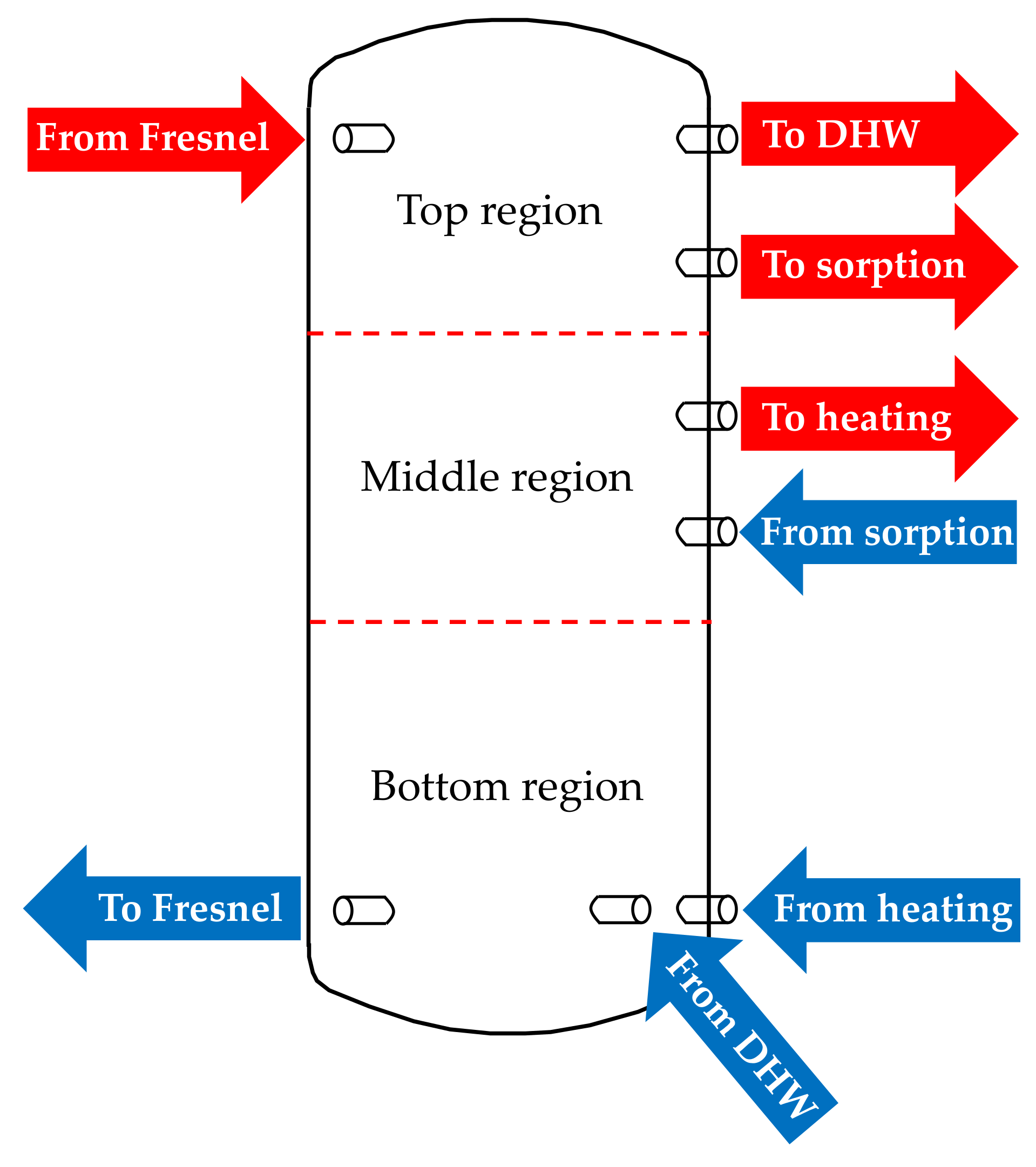
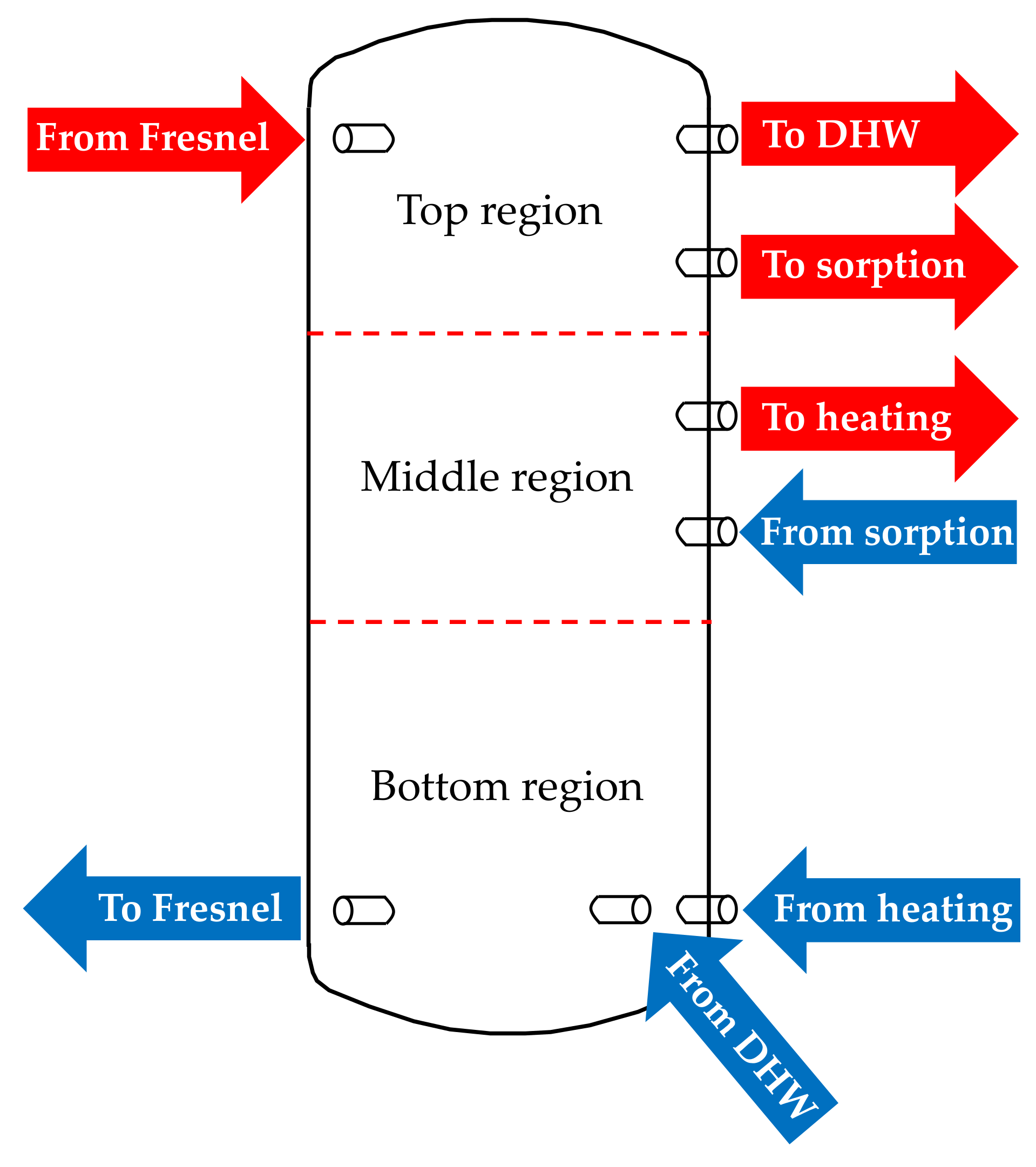
The buffer tank is modelled considering three different regions (volumes) and assuming a uniform water temperature distribution inside each volume (
Figure 2) [
33,
34]. The temperature of the buffer tank at time slot
t is calculated by applying an energy balance to each of the three different volumes of the tank. Heat transfer by conduction or natural convection between two adjacent regions is neglected and the only heat transfer mechanism considered is through mass transfer. The buffer tank charging is assumed to be done with hot water at constant inlet temperature of 95 °C coming from the Fresnel solar field. The heat generated by the solar collectors (
, in kW) is transferred to the buffer tank by means of a heat exchanger placed between the solar field loop and the buffer tank loop (HEX1 in
Figure 1). Heat losses between the solar field and the buffer tank were neglected for simplicity. The mass flow rate of the water in the buffer tank loop (
, in kg/s) is variable to maintain a constant water temperature at the buffer tank inlet.
For the top region, the energy balance is shown in Equation (15):
where
= 800 kg is the mass of the water inside the buffer tank,
= 0.3 is the mass fraction of the top part of the buffer tank,
= 95 °C is the inlet temperature of the water flow coming from the Fresnel collectors,
(in °C) and
(in °C) are the temperatures of water at the top and middle parts of the buffer tank in the previous time slot, respectively, and
is the time step (in seconds). If sorption module is off,
= 0. The sorption module is automatically switched off when
65 °C and it may be switched on again when
68 °C (if the high-level controller decides it is best to do it, and whenever the heat pump is working in one of the cooling modes 1, 3 or 4).
The mass flow rate of the loop that connects the buffer tank with the solar field (
, in kg/s) is given by Equation (16):
where
(in °C) is the water temperature at the bottom part of the buffer tank evaluated at the previous time slot. When the water temperature at the top of the buffer tank reaches 94 °C during charging, the solar field is switched off and the charging of the buffer tank stops (
= 0) until the water temperature at the top of the buffer tank decreases to 90 °C, when it may be switched on again if
0.
The water mass flow rate at the buffer tank outlet towards the DHW tank charging circuit (
, in kg/s) is given by Equation (17):
where
(in °C) is the temperature inside the DHW tank at the previous time slot. Equation (17) only applies if the DHW tank works in mode 1 (charging with heat supplied from the buffer tank), otherwise
= 0.
Heat losses from the top part of the buffer tank to the ambient air depend on the thermal resistance of this part of the tank (
, in K/kW), which can be calculated using Equation (18):
where
= 430.3 K/kW is the overall thermal resistance of the buffer tank,
= 4.095 m
2 is the surface area of the buffer tank edge (lateral surface area) and
= 0.62 m
2 is the surface area of the base of the buffer tank.
For the middle part of the buffer tank, the energy balance is shown in Equation (19):
where
= 0.63 kg/s is the mass flow rate of the building heating loop (circulated by pump P4),
= 0.3 is the mass fraction of the middle part of the buffer tank and
(in °C) is the temperature of the water returning from the adsorption module. If there is no heating demand (
= 0) or heat is provided to the building by the heat pump working in heating mode,
= 0.
Heat losses from the middle part of the buffer tank to the ambient air depend on the thermal resistance of this part of the tank (
, in K/kW), which can be calculated using Equation (20):
For the bottom region of the buffer tank, the energy balance equation is shown in Equation (21):
where
= 0.4 is the mass fraction of the bottom part of the buffer tank.
When the heating demand is satisfied by the buffer tank, water temperature returning from the building (
, in °C) depends on the heating demand of the building (
, in kW) and it is calculated according to Equation (22):
Otherwise, when there is no heating demand from the building (= 0) or heat is provided by the heat pump working in heating mode, = 0 and (as an alternative to Equation (22)). In case that water temperature at the middle part of the buffer tank is below 45 °C ( 45 °C), heat cannot be delivered to the building from the buffer tank, therefore pump P4 switches off (= 0).
Heat losses from the bottom part of the buffer tank to the ambient air depend on the thermal resistance of this part of the tank (
, in K/kW), which can be calculated using Equation (23):
The overall electricity consumption associated to the buffer tank only consists of the electricity consumption of pump P4 (34 W) when the heating demand of the building is higher than zero and this demand is met by the buffer tank (0) and not by the heat pump working in heating mode.
2.2.8. DC-Bus
The heat pump is driven by DC through a connection to the DC-bus. Electricity can be taken either from the PV panels and/or from the battery, depending on the PV production and the state of charge of the battery. Furthermore, in case that the power supplied by the battery and the PV panels is not enough to feed the heat pump, electricity can also be provided by the power grid through an AC/DC converter (not shown in
Figure 1). Conversely, when the PV production is high and the battery is fully charged, surplus electricity can be delivered to the grid. The power generated by the PV panels (
, in kW) was assumed to be always less than the maximum charging power of the battery (
) and the maximum discharging power of the battery (
) was assumed to be always higher than the power demanded by the HP (
).
Three different operating modes were considered for the DC-bus, focusing on the control strategy of the battery, as summarized in
Table 2. Two thresholds,
(in %) and
(in %), were used to drive the DC-bus in one of the three possible operating modes.
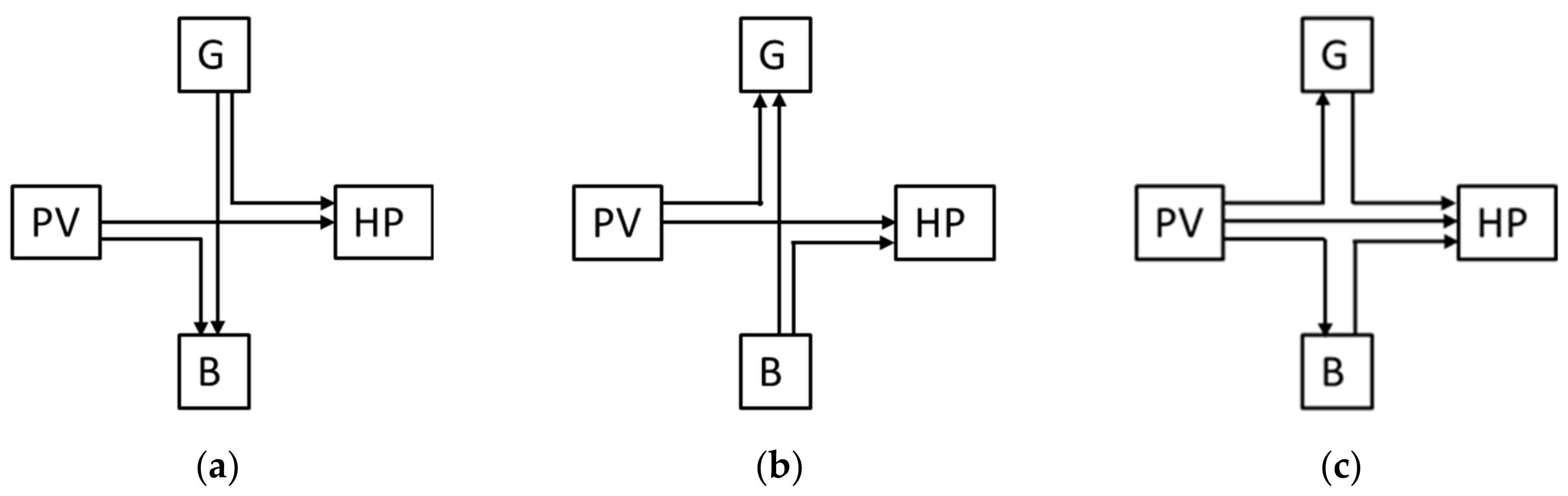
Charging mode (mode 1) takes place if , where is the lower charging level allowed for the battery, (in %) is the state of charge of the battery and (in %) is a threshold below which the battery is automatically charged (i.e., when ). In this mode, the battery charges at a constant maximum rate ( kW) until , after which the battery switches to buffer mode.
In charging mode, the power required by the heat pump (HP) can only be taken from the PV and/or from the grid (G), but not from the battery (
Figure 3a).
The equations that describe the different energy streams in charging mode are shown in the set of Equation (24):
where
(in kW) is the power supplied to the HP from the PV panels,
(in kW) is the power supplied to the battery from the PV panels,
(in kW) is the power required from the grid to charge the battery at maximum power,
is the power required from the grid to feed the HP,
is the power coming from the PV panels that is delivered to the grid and
is the power supplied to the HP from the battery. The power exchanged between X and Y, where X and Y may refer to PV (PV panels), HP (heat pump), G (power grid) or B (battery), is assumed to be positive (
) if energy is incoming to X from Y (
).
Discharging mode (mode 2) takes place if
, where
(in %) is a threshold above which the battery automatically discharges (i.e., when
) and
is the upper threshold allowed for the charging level of the battery. In this mode, the battery is discharging at the maximum rate (
kW) towards both the HP and the grid (
Figure 3b) until
, after which the battery switches to buffer mode.
The equations that describe the different energy streams in discharging mode are shown in the set of Equation (25):
Buffer mode (mode 3) takes place if . Whenever the optimizer decides to switch to the buffer mode, the following values are assigned: and . In this way, the battery will be forced to switch to buffer mode whatever the value of is.
In mode 3, the battery acts as a buffer, meaning that it charges if there is a surplus of electricity production from the PV panels or it discharges if the HP requires more power than is produced by the PV panels (
Figure 3c). In this mode, there is no interaction between the battery and the grid, i.e., the battery cannot charge from the grid, neither can it deliver electricity to the grid.
The equations that describe the different energy streams in buffer mode are shown in the set of Equation (26):
In this mode, the total power supplied to the grid (G) can be negative, positive or zero, depending on the relation between PV production and HP consumption. The total power supplied to the battery (B) can be positive if there is a surplus of PV generation, negative when the power demand of the HP cannot be met only from the PV panels, or zero, when the absolute difference between PV production and HP consumption is less than 400 W ().
For all operating modes, the state of charge of the battery at time instant
t (
) is given by Equation (27):
where
is the state of charge of the battery at the previous time slot,
is the efficiency of battery charging/discharging process,
kWh is the maximum storage capacity of the battery and
(in seconds) is the time step of the simulation. For the sake of simplicity, the value of the efficiency of battery charging/discharging process (
) was assumed to depend on the sign of B:
if
(battery is charging) and
if
(battery is discharging).
2.2.9. Summary of the Main Model Parameters
The main model parameters considered for the training/testing scenarios that will be explained later are summarized below:
Surface of the Fresnel solar collectors: 60 m2.
PV panels surface: 20.9 m2.
PV panels orientation: 0° (south).
PV panels inclination: 30°.
PCM tank storage capacity: kJ (12 kWh).
DHW tank capacity: 250 L.
DHW electric heater power: 2 kW.
Buffer tank capacity: 800 L.
Battery energy storage capacity: 7.3 kWh.
Maximum battery charging/discharging power: 3 kW.
2.3. DRL Control Description
2.3.1. General Description
Reinforcement learning is a class of solution methods that optimizes a numerical reward by interaction with the environment [
9], in which a learning agent takes actions that drive the environment to new states, provoking some reward being observed by the agent. It is in this context that Markov decision processes (MDP) provide a useful mathematical framework to solve the problem of learning from interaction to optimize a given goal [
35]. In a finite and discrete MDP, the environment is represented at each time step as a state. Based on this state, the agent, according to a given policy, decides to execute an action, obtaining a reward from the environment and moving it to the next state. Considering stochastic environments, one can think on state-transition probabilities that characterize the MDP. Furthermore, as each transition gives a reward, each state may be associated to a state-value function that represents all the expected MDP rewards given a state. These representations are the basis for the Bellman optimality equations [
36], which must be solved to achieve an optimal solution for the problem.
Expressing the MDP abstraction more formally, and considering a discrete time MDP with time step t = 0, 1, 2, …, the MDP consists of:
A set of states that represents the environment, being the environment state at time t.
A set of actions that can be taken by the agent, being the action taken at time t from the subset of available actions at state , .
A numerical reward for the new visited state, that will depend on its trajectory: …, .
Assuming that the system dynamics is Markovian, random variables
and
will only depend on its previous values, with a probability distribution,
which characterizes the system, defined as in Equation (28):
An agent policy, , which determines the chosen action at a given state. Defined as a probability, results in the probability of choosing action from state .
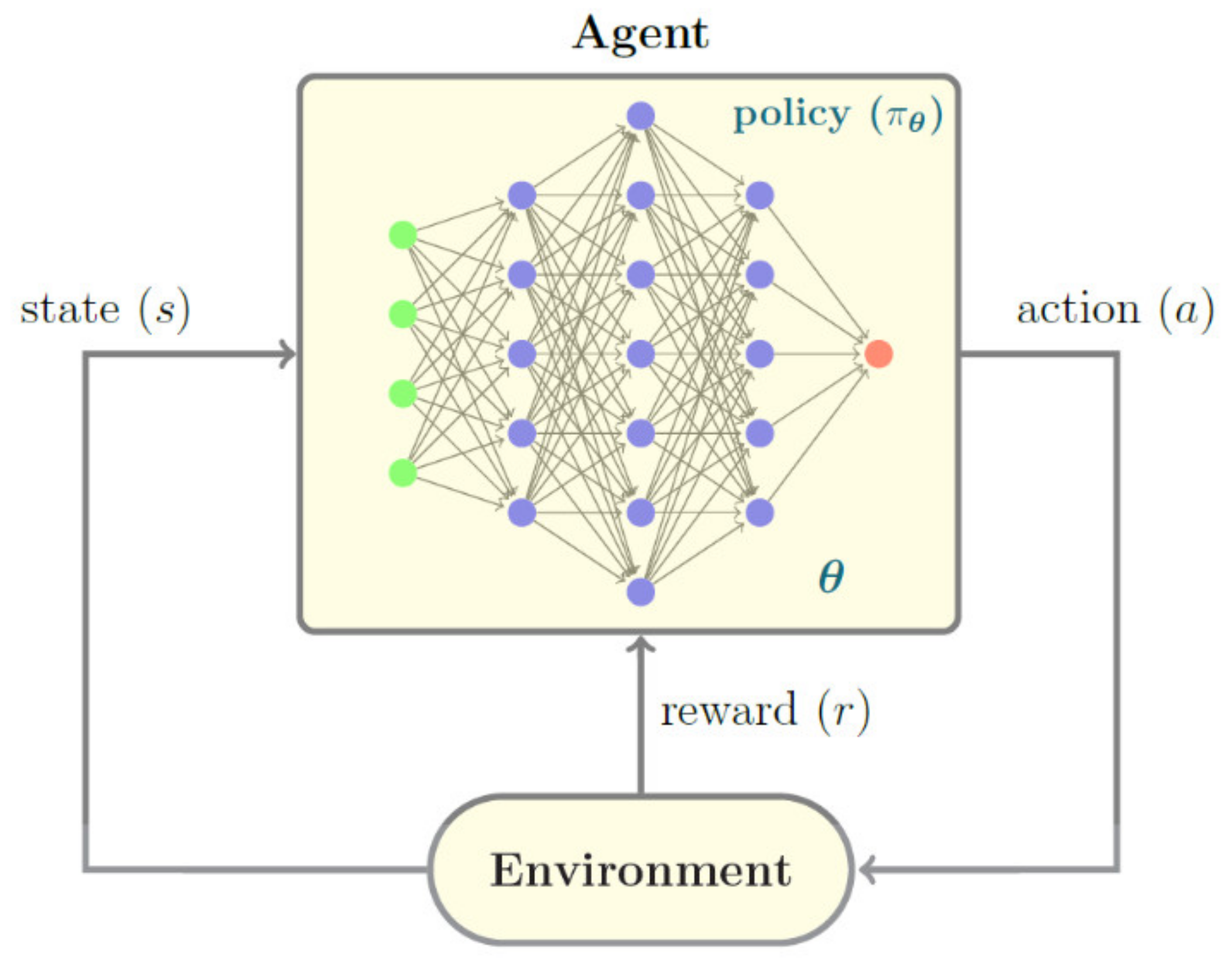
Figure 4 shows a typical RL paradigm representation. In this case, policy
depends on a set of parameters
that represents the neural network weights to be discussed later.
The cumulative reward at a given time slot can be defined as in Equation (29):
where
is the final time step and
is a discount rate that determines the worthiness of future rewards. Equation (29) helps to define the concept of the value of being at a state for a given policy given in Equation (30):
and using Equation (28), Equation (30) becomes the Bellman equations for
, shown in Equation (31):
for all
.
Solving a RL problem implies to find an optimal policy (
) that solves the state-value function defined in Equation (32):
and derives from Equations (28), (29) and (32), the Bellman optimality equations as in Equation (33):
The solution of Equation (33) provides the best action , in terms of future rewards, from a given state . Once solved for every possible state, it gives the optimal policy,, because the probabilities are known.
It is at this point that the whole family of reinforcement learning algorithms is created, trying to solve these optimality equations by different means. Resolution techniques based on dynamic programming (DP) may solve the problem, i.e., find an optimal solution, by iteratively finding the state-values, , but these methods suffer from the so-called curse of dimensionality, because the number of states grows exponentially with the number of state variables. Such a curse is tackled by Monte-Carlo (MC) methods by sampling values of the state-values through experience, by interaction with the model. Even with a partial knowledge of those state-value functions, good MC algorithms converge to acceptable solutions. Even more, if those MC methods are combined with DP ideas, such as update regularly the estimated values, a new family of algorithms arises, called temporal-difference (TD) learning, such as Sarsa , Q-Learning or TD , proving to be highly efficient methods for a lot of optimal control problems.
Even the improvement of new RL methods, large and complex problems may require an enormous amount of computational power, particularly when the number of states is large, during the learning phase. Under this scenario, the ground-breaking concept of deep reinforcement learning (DRL) [
13,
37] appears to change the rules of the game, scaling up RL to space state dimensions previously intractable. DRL deals efficiently with the curse of dimensionality by using neural networks as substituting parts of traditional value tables, obtaining approximations of the optimal value functions trained by their corresponding neural network backpropagation mechanisms. The emergence of specialized libraries as TensorFlow [
38] did the rest, by allowing parallelization across multiple CPUs or GPUs and permitting in this way to train huge neural networks able to cope the structure of complex systems in affordable running times.
2.3.2. Policy Gradient Algorithms
The above-mentioned RL algorithms based the resolution of the Bellman optimality equations on the learned value of the selected actions. Instead, policy gradient methods base their learning on a parameterized policy that selects the actions without the knowledge of a value function. Generically, one can consider a set of parameters that usualy correspond to the weights of a neural network. By doing so, one can rephrase the policy function as .
At this point, Equation (30) may work as an objective function,
. Effectively, one can define the objective as in Equation (34):
i.e., the expected cumulative reward from
. According to the policy gradient theorem [
39], whenever the policy was differentiable with respect to
, the gradient of the cost function obeys the proportionality shown in Equation (35):
Considering that Equation (35) can be instantiated at each time slot and that parameters
are time-dependent, one can apply any gradient descent algorithm to compute
as in Equation (36):
being
a learning rate constant. Equation (36) is the fundamental idea that supports a new family of RL algorithms called REINFORCE [
40]. As noted, REINFORCE is a MC-like algorithm because it can be implemented by sampling the environment, getting from it the cumulative reward and the logarithm of the policy gradient, presenting good convergence properties for small enough values of the learning parameter. The existence of gradient descent optimizers based on neural networks, as well as the existing softmax layers did the rest to allow efficient REINFORCE implementations.
2.3.3. HYBUILD Control Model
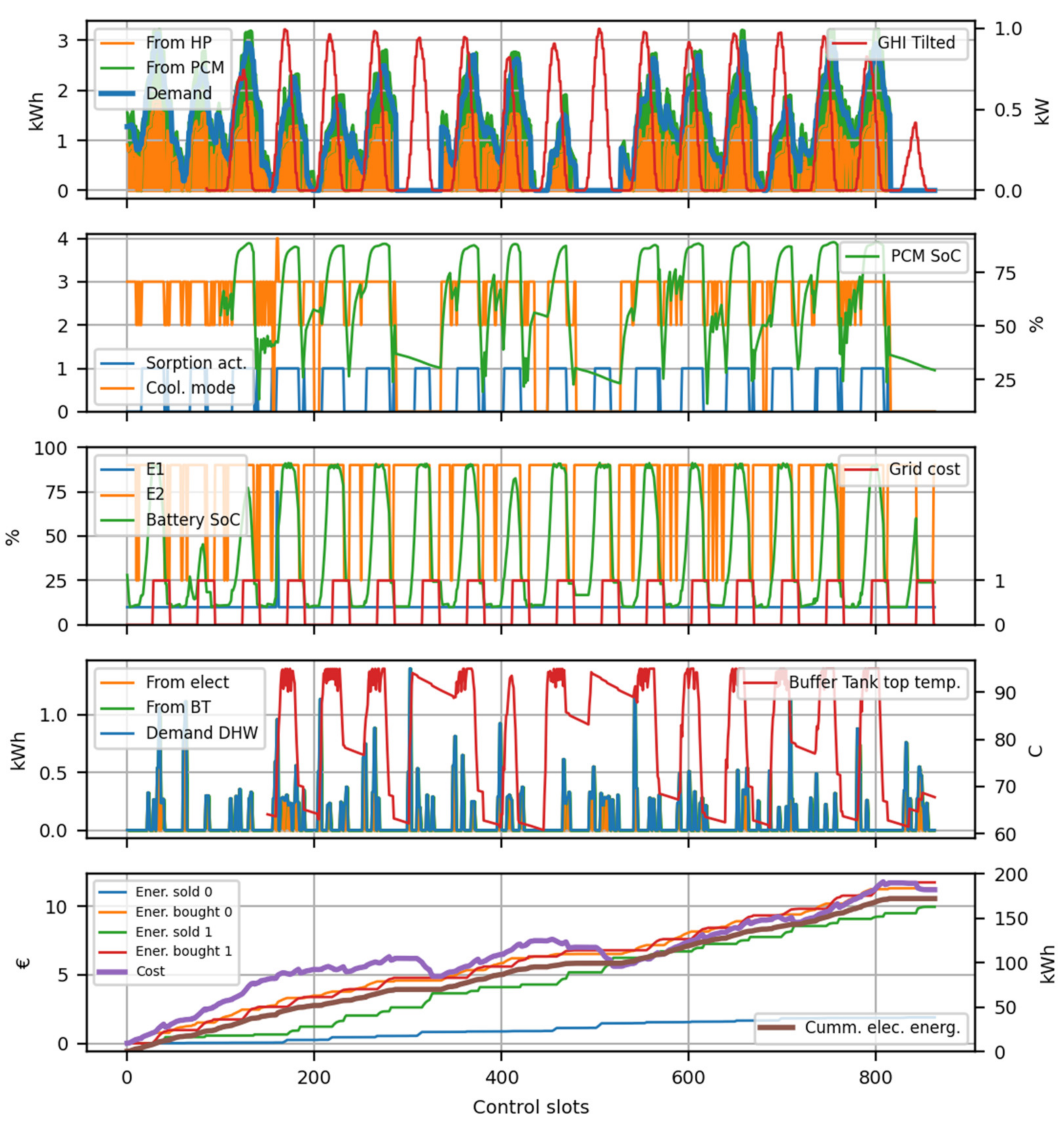
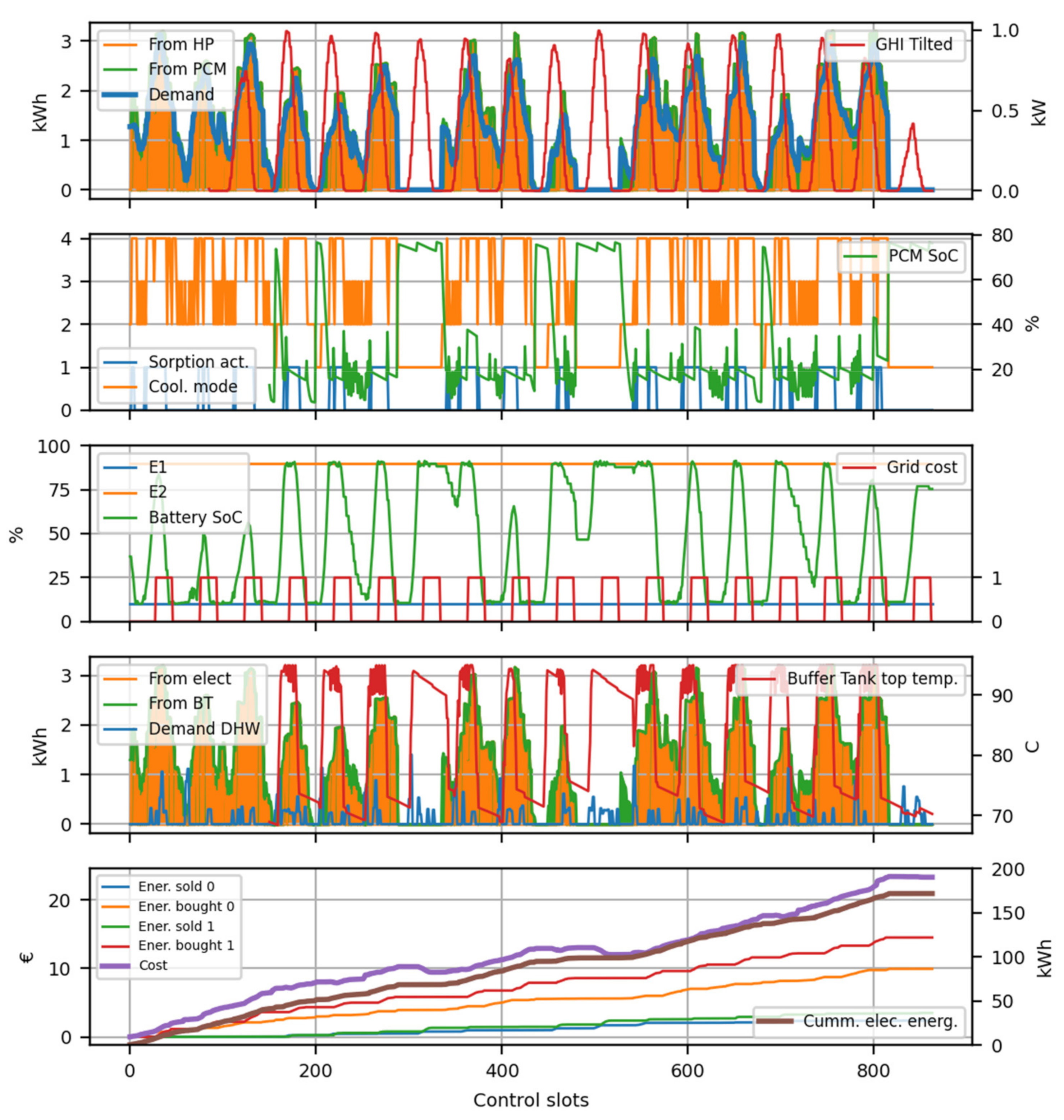
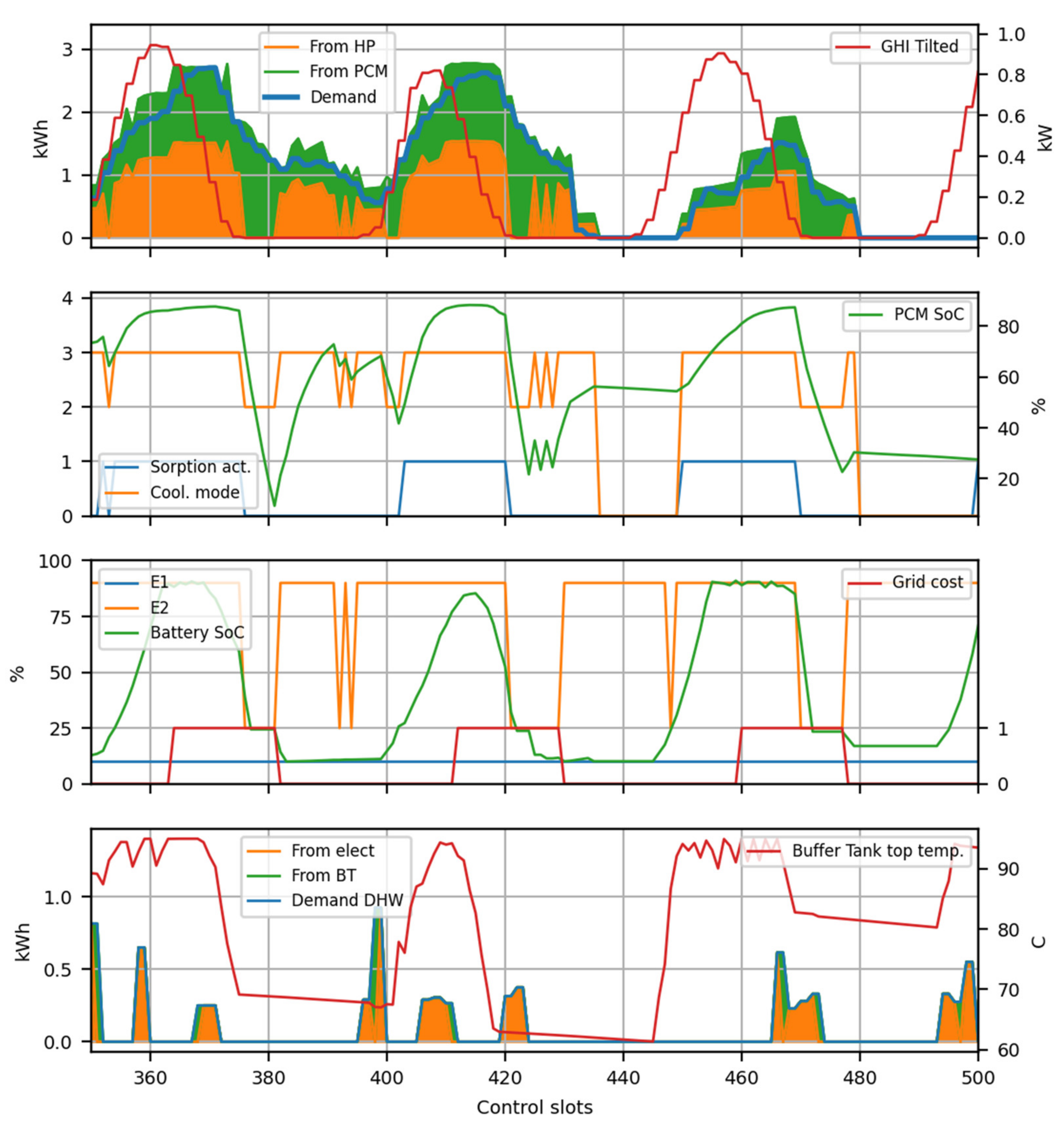
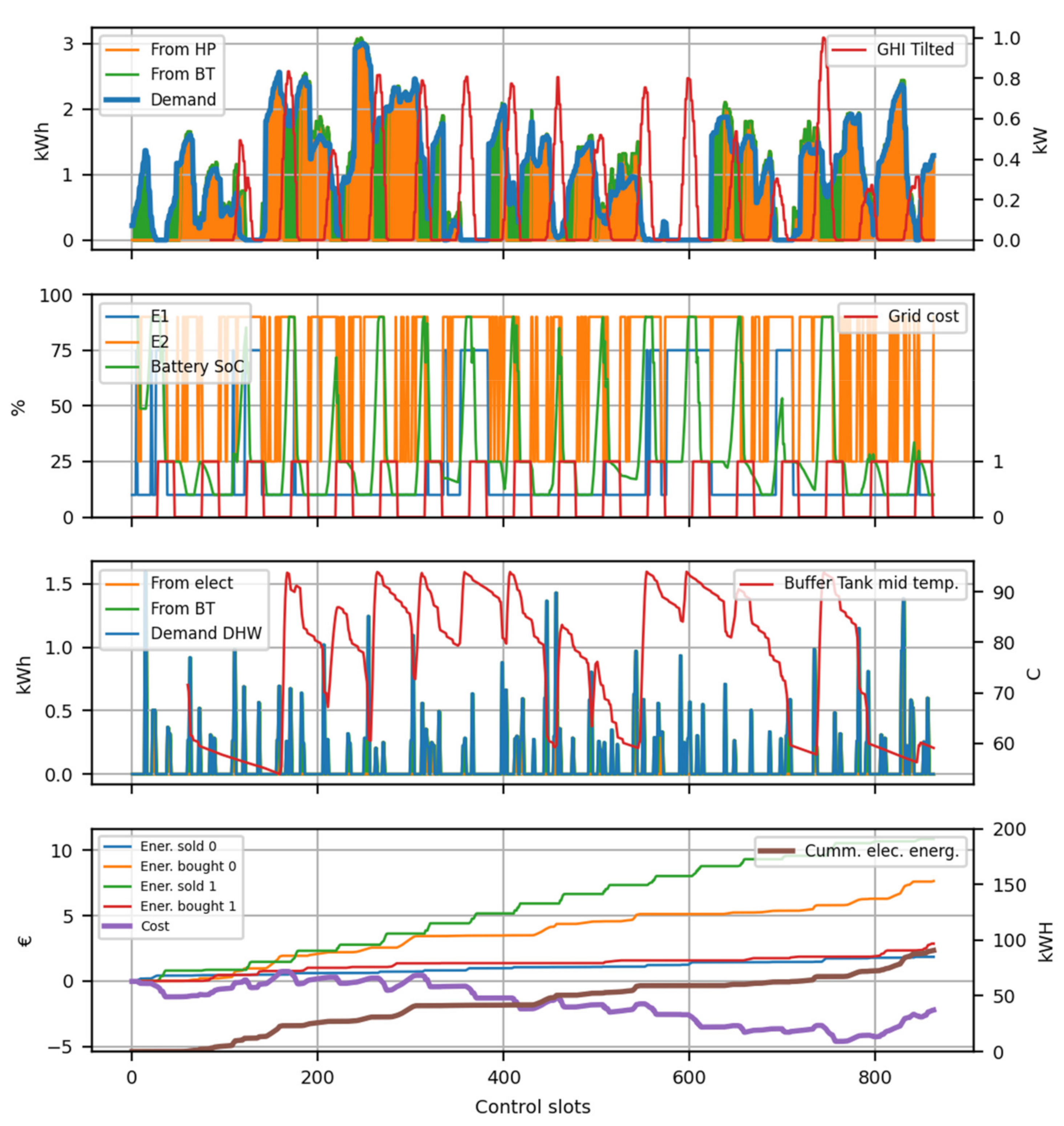
The HYBUILD control is based on a REINFORCE algorithm with no baseline. HYBUILD system model operates at two differently slotted time scales. First, a finer slot is considered in order to numerically compute the HYBUILD system behavior (3 min are typically considered). This smaller time slot is only considered for inner model operations and it is not relevant for control purposes. Second, a larger slot () is used to manage the control system (15 and 30 min were considered). Within time slot, any action decided by the control system is invariant until reaching any subsystem limit. As an example, if during a given slot one decides to charge the heat pump/PCM tank subsystem, the charging process will not stop unless the maximum state of charge was reached. Similarly, the input system variables for the control system are considered invariant in .
HYBUILD control model for the Mediterranean system may be defined for cooling or heating purposes, but the heating model can be considered as a subset of the cooling model because heating operations for the Mediterranean system are much simpler. Actually, heating mode bypasses the PCM tank and sorption subsystems, resulting in only one operating mode for the heat pump subsystem.
The state vector () is an 8-dimensional vector in cooling mode (7-dimensional in heating mode) with the following components:
Thermal energy demand for cooling/heating in the current time slot ().
Thermal energy demand for domestic hot water (DHW) in the current time slot ().
Ambient temperature ().
Energy cost for electric demand in the current time slot ().
Charge level of the PCM tank subsystem, (
), as explained in
Section 2.2.3. Not used in heating mode.
Buffer tank top temperature, (
), as explained in
Section 2.2.7.
Battery state of charge in the DC-bus subsystem (
), as explained in
Section 2.2.8. being
the corresponding time and all of them were standard normalized according to their ranges.
Choosing thermal energy demand as input, instead of temperature set-points, allow to decouple the model from building thermal mass dynamics, providing more consistency to the Markovian assumption. In this sense, considering the control process as an MDP results is a valid assumption as long as the heating/cooling subsystem models, detailed in
Section 2.2, are time-depending on only previous time slots. As a counter effect, an on-site control implementation will require to model the building dynamics based on the temperature set-points in order to predict the thermal demand. In this sense, the models used in this study are based on reinforcement learning that accurately provide the thermal demand for a particular building under different weather conditions and set-points.
The set of actions () that guide the control can be defined as , where is the set of cooling/heating operating modes, is the set of activation modes for the sorption subsystem and is the set of battery modes in the DC-bus subsystem. As only the set differs for the cooling and the heating models, one can differentiate the set of actions accordingly: and .
According to the operating modes defined in
Table 1,
and
because the sorption subsystem may be on or off. For the heating modes, as sorption and heat pump/PCM tank subsystems are bypassed, only one operating mode is considered, being
.
Concerning the actions related to the DC-bus subsystem, as detailed in
Section 2.2.8, the high-level control may determine the
and
thresholds that define the area of DC-bus operation, as well as the maximum charging/discharging power when operating in charge/discharge areas. As the control model presented here only deals with discrete values, the DC-bus control operations were simplified according the following rules:
Charging/discharging power is set to a fixed value, namely 3 kW.
If from the high-level control the DC-bus is forced to operate in charging, buffer or discharging mode, the pair of values is set to three fixed levels: (75, 90), (10, 90) and (10, 25), respectively, as a percentage of the battery state of charge, .
Following these assumptions,, which corresponds to charging, buffer and discharging modes, respectively.
Finally, considering that during cooling mode 2 (all cooling energy is supplied by the PCM tank) the sorption chiller is in mode 0, the set of possible actions are:
and
= 21.
In heating mode, considering that the sorption chiller is always off, it follows that:
and
= 3.
It should be noted that all the cases where cooling/heating mode is 0 may be omitted because:
If there is some energy demand, cooling/heating mode 0 is not an option.
Otherwise, any cooling/heating mode will perform as mode 0 inside .
In other words, mode 0 is adopted when energy demand is null.
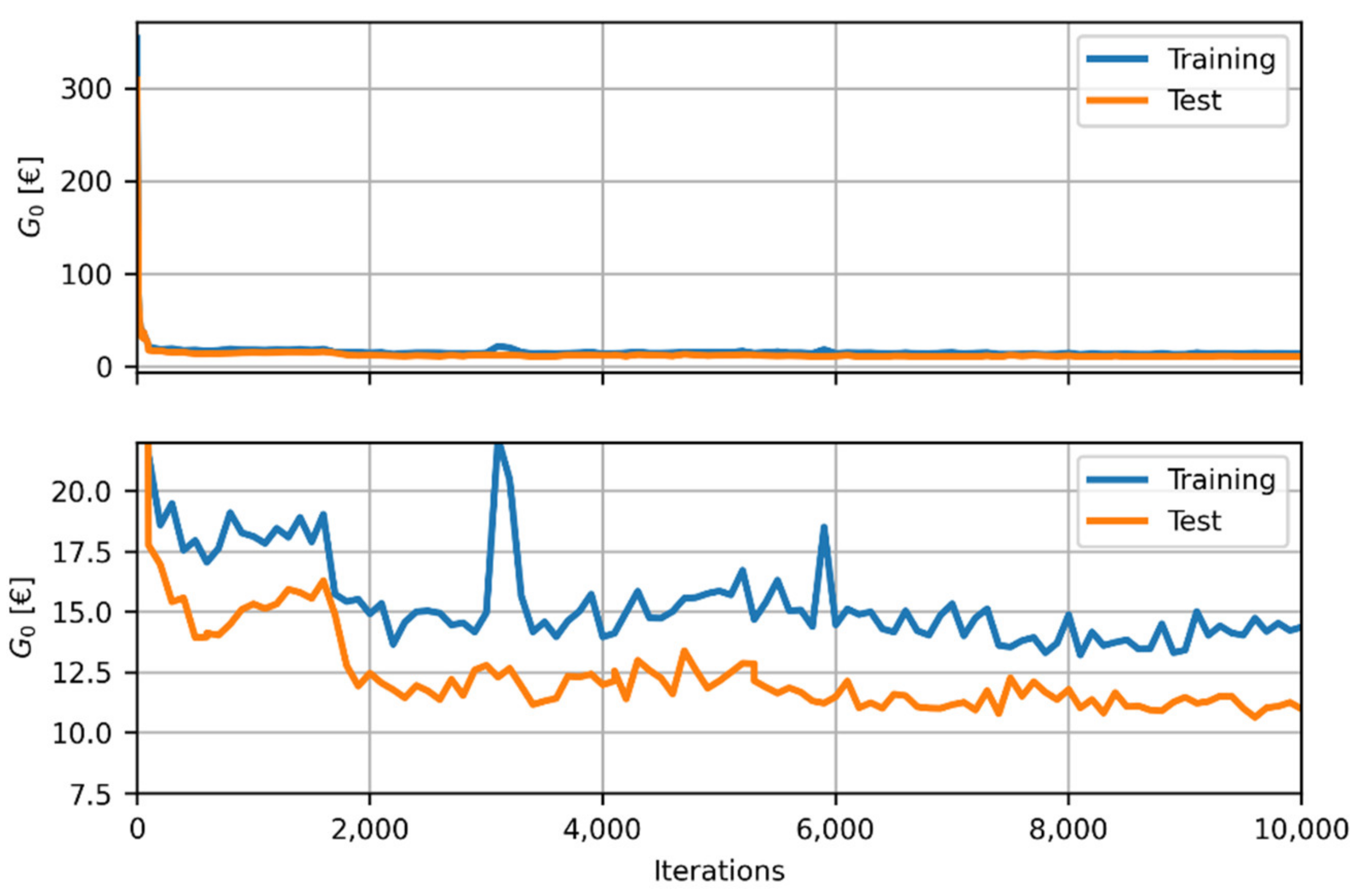
For the purpose of this study, a policy gradient REINFORCE algorithm was implemented, with two three-layer fully-connected neural networks of sizes and for heating and cooling, respectively, with the following characteristics:
= 7 and = 8 are the number of inputs, defined by the system state dimension. Their values are standard normalized with their corresponding ranges.
and are the hidden layer sizes for heating and cooling modes, respectively. They use to be much larger than the size of inputs and outputs. Actually, the number of hidden layers, their size, the type activation functions, as well as other parameters will be adjusted in a future study by hyper-parameter setting analysis, being out of the scope of this paper. The values = 100 and = 1,000 were adopted here, with exponential linear unit activation functions and a dropout rate of 0.8.
= 3 and = 21 are the number of outputs corresponding to the cardinality of the actions set. Outputs represent softmax of logits and the corresponding action is taken as a multinomial of the logarithm of outputs.
Learning rate, = 0.0005.
Discount rate, = 0.99.
The neural network was trained minimizing the cross entropy of the multinomial outputs using an Adam stochastic optimizer [
41]. Under this scenario, one objective function was defined regarding an economic reward related to the cost associated to the system operation.
2.3.4. Minimum Cost Control Policy
In order to derive control policies focused on minimizing the cost of operation, the cumulative reward
used in Equation (36) and in Equation (29) should be calculated considering the reward function
defined in Equation (37):
where:
is the electrical energy bought from the grid in slot , either to feed the DC-bus or other equipment, such as the electric resistance of the DHW tank.
is the electrical energy sold to the grid in slot . A discount factor of 0.5 was considered.
is the thermal energy provided by the heat pump subsystem for cooling/heating in slot .
is the thermal energy provided by the PCM tank for cooling/heating in slot .
is the cost assumed for a non-covered demand. A value much higher than the energy cost is used.
Note that is not part of the objective function because it is assumed that DHW requirements will always be fulfilled by the backup electric heater.
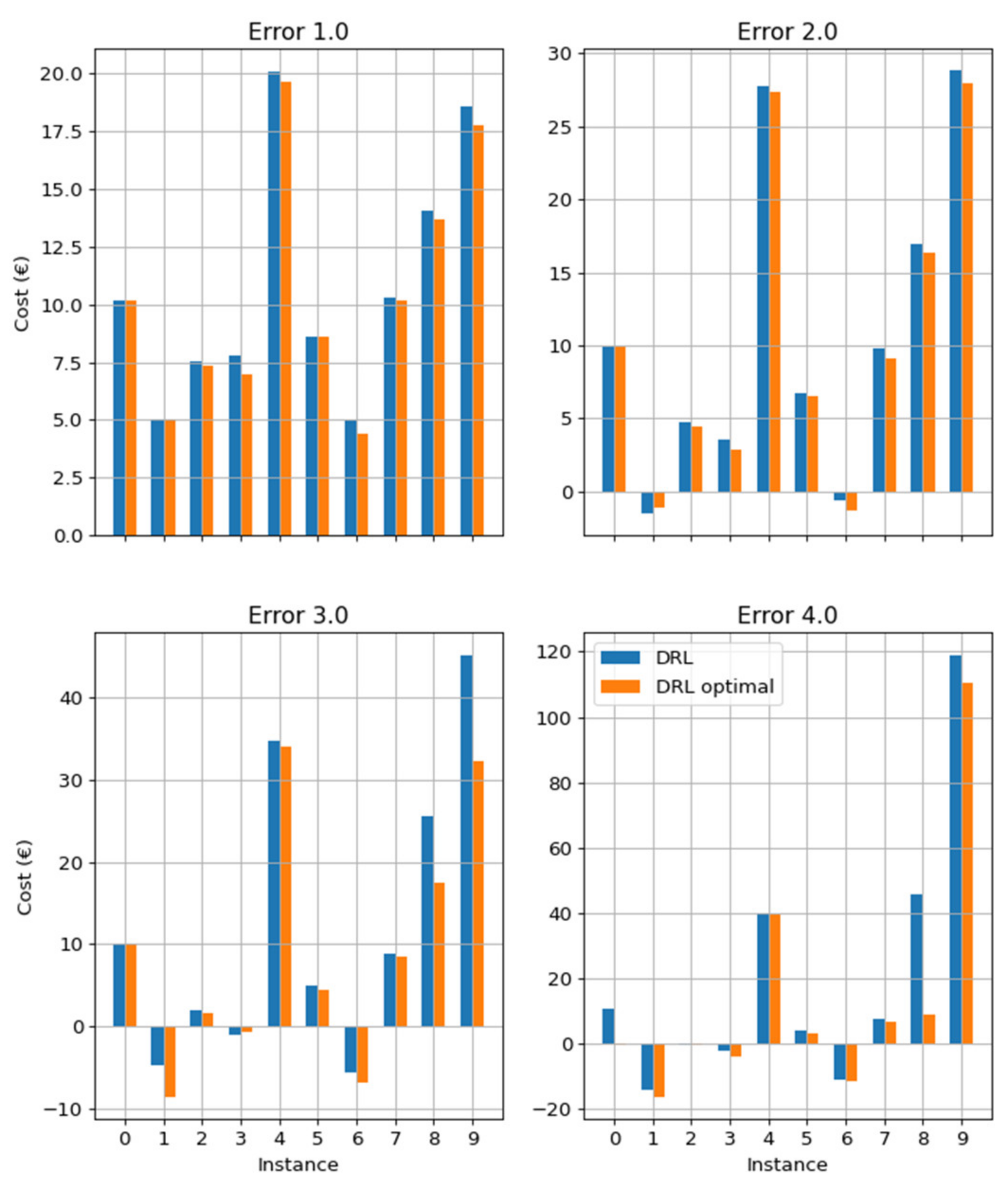
2.3.5. Rule-Based Control Policies
With the objective to evaluate the DRL control policy goodness, a simple rule-based control (RBC) policy for the cooling season was also implemented, which can be simplified for heating mode. The RBC policy is based on its own thresholds and can be described as follows:
Battery mode—charging, buffer or discharging—is determined by two battery state of charge thresholds ( and ) and the grid cost ().
Cooling mode 1 (PCM tank charging) is set if there is no cooling demand. Otherwise, cooling mode 2 (PCM tank discharging) is set if PCM energy () is larger than a threshold factor () times the cooling demand (). Otherwise, cooling mode 3 (simultaneous PCM tank charging and cooling supply to the building) or 4 (cooling supply using the standard HP evaporator) is set according to the energy stored in the PCM tank in relation to the PCM energy threshold ().
Sorption chiller mode is set depending on the buffer tank temperature threshold () in comparison to the buffer tank temperature at the top region ().
The details on both cooling and heating RBC policies are shown in
Appendix A. In both RBC policies, a hyper-parameter optimization was applied in order to determine the optimal thresholds. Hyperopt python library [
42] was used employing an adaptive Tree Parzen Estimator algorithm with 400 runs over the same training test set.
2.3.6. Implementation Aspects
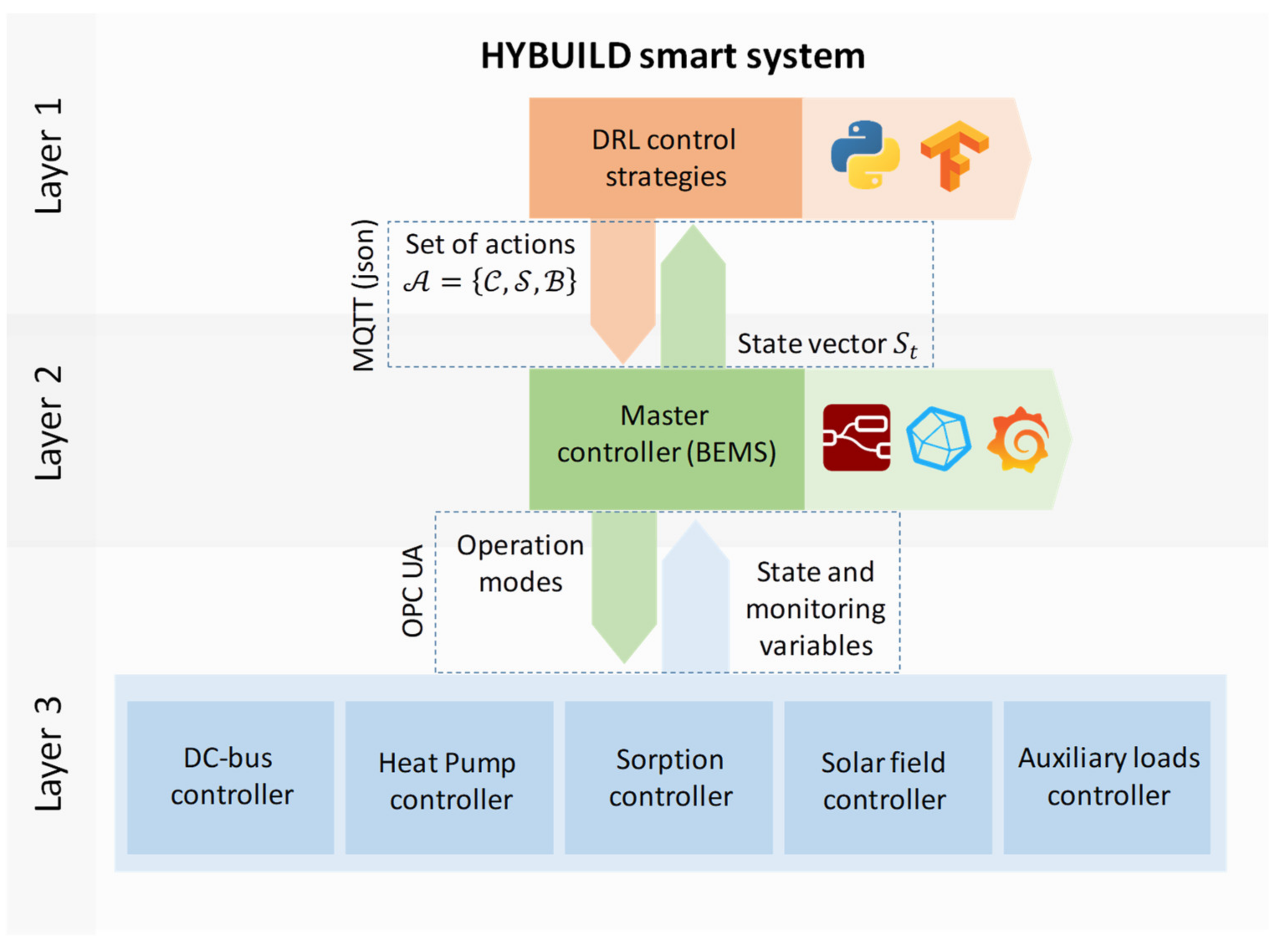
Figure 5 shows the structure designed for the implementation of the HYBUILD con-trol system. It is divided into three layers. Layer 3 is composed of the low-level controllers for each subsystem. It operates directly over the system components, including all sensors, actuators and low-level security protocols. Layer 2 is composed of the Supervisory Con-trol And Data Acquisition (SCADA) system. It monitors the system parameters, sends the state vector to layer 1 and executes the set of actions set by layer 1. Layer 1 is composed of the DRL control algorithm described in this paper. The communication between layers 1 and is done using MQTT(json) and the communication between layers 2 and 3 is performed using the OPC-UA communication protocol.
The HYBUILD control model was written in Python 3 [
43]. Furthermore, Tensorflow libraries were used in control models [
38]. The availability of a lite version of Tensorflow libraries makes suitable this implementation for light hardware or micro-controller environments that may be required for control scenarios in real time.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}