1. Introduction
The parameters for the Mix Design of Asphalt Concrete are used to grade characteristics of aggregates and the types and percentages of bitumen used. The key methods used for mix designs of asphalt are the Marshall Method, Modified Marshall Method, Hveem Mix Design, and the Superpave Mix Design [
1,
2]. The most common methods used for mix design of asphalt are the Marshall Mix Design Method (M2DM) and Modified Marshall Mix Design Method (M3DM) as endorsed by the asphalt institute MS-02 [
3]. Marshall Stability (MS) and Marshall Flow (MF) are significant features in the Marshall Mix Design. MS is critical in the design of the wearing course. The ability to resist rutting and shoving is known as the stability of the pavement. Flow is regarded as a property that is opposite to stability. Flow determines the elasto-plastic characteristics of asphalt concrete, which is considered as the capability of asphalt concrete to adjust to the gradual movements and settlement in the subgrade without cracking [
4,
5]. The above parameters are calculated using the trial and error approach.
The tests used for the Marshall mixed design are time consuming, hectic, and need the expertise of a skilled operator to handle test equipment, with zero mathematical relation to predict the mathematical values of MF and MS. To avoid problems and make the process intelligible, easy and straightforward, many researchers have used several techniques of Artificial Intelligence (AI) to determine the values of MS and MF in the M2DM used for asphalt mixtures, which are the major output parameters.
With the advancement in the field of AI techniques, the new, accurate, and updated models for prediction of Marshall parameters have been introduced [
6,
7,
8]. Models based on AI techniques are a great way to model and predict the output parameters of complex engineering problems with high accuracy and reliability [
9,
10,
11]. A broader spectrum of work was performed relating to the development of mathematical and numerical modeling [
12,
13,
14,
15,
16,
17]. Various research studies have used ANN to predict the results of Marshall tests for dense bituminous mixtures modified with polypropylene [
8] to model the MS of asphalt concrete for changing temperatures [
18]; to model stiffness modulus, MQ and MS of HMA [
19]; to model MF, MS, indirect tensile strength, and stiffness of asphalt concrete with progressive conditions of temperature [
20]; to determine optimum bitumen content, MS and MQ of asphalt concrete mixtures; to model fluctuation in MS with asphalt content [
21]; and to model the MS of expanded clay aggregates used in light asphalt concrete [
22]. Morova et al. [
23] used ANFIS to model MS for fiber-reinforced asphalt mixtures. Serin et. al. [
24] developed models using fuzzy logic to predict MS of expanded clay aggregate used in lightweight asphalt concrete and had varied mix properties. Ozgan [
25] predicted the MS of asphalt concrete underlying various temperatures and exposure with statistical method and Fuzzy Logic (FL). Tsompanakis et al. [
26] used Multiple Additive Regression Trees to predict MS of asphalt concrete. They compared the results of MART’s model with Multilayer Perception Neural Networks (MLPNN). Nguyen et al. [
27] used SVM and hybrid AI techniques to predict the MS of stone matrix asphalt. Khuntia et al. [
28] predicted the MS of polyethylene-modified asphalt specimen with the least-square support vector machine (LS-SVM) and ANN. Ghanizadeh et al. [
29] developed a Multivariate Adaptive Regression Spline (MARS) model to predict the MF of asphalt mix based on the Marshall parameters. Azarhoosh and Pouresmaeil [
6] used Genetic Programming (GP) to model parameters of flexible pavement. Yan et al. [
30] used Support Vector Machine (SVM) to compare it with Gene Expression Programming (GEP) and Multiple Lease Square Regression (MLSL) to predict MF. MEP has been used for computing the degree of consolidation [
31] for classification of soils [
32], for forecasting compression strength of geopolymer concrete [
33], for predicting the elastic modulus of concrete [
34,
35], for predicting the compressive strength of concrete [
36,
37,
38,
39], for predicting the parameters of soil compaction [
40], and for calculating the uplift capacity of the suction caissons [
41]. However, the application of MEP to model the Marshall parameters and its performance evaluation still remains a mystery, and this research gap must be fulfilled.
Inspired by Darwin’s theory of evolution, GP [
42,
43] is an emerging subclass of Evolutionary Algorithms (EAs) [
44]. Generally, GP is a technique of machine learning that explores program space rather than data space [
42]. In the previous decade, a certain variant of GP, named Multi-Expression Programming (MEP) was proposed in which linear representation of chromosomes is used [
45]. Multiple computer programs can be encoded into a single chromosome, used to solve problems, making it the special ability of MEP. MEP technique has the ability to significantly outperform similar approaches that are based on numerical experiments. MEP can be used as an efficient substitute to the traditional GP (tree-based) approaches [
46,
47,
48].
The MS and MF of asphalt concrete have been modeled widely using the distinctive features of most common technique of AI, i.e., ANN [
6,
8,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
48,
49,
50,
51,
52,
53]. These algorithms, with their abilities to recognize patterns, result in simplified engineering problems that are complex in nature [
11,
54,
55,
56]. NN are labeled as Black-Box Algorithms (BBA) and can perform well only over a specific set of problems considered for optimization. BBA do not take into consideration any physical phenomenon or data information of the problem under evaluation [
57,
58,
59]. The majority of ANN procedures slack in a way that complex numerical expressions are created for the prediction of output parameters based on input parameters. ANN-based modeling is considered as a correlation of input parameters with that of output parameters, and the relationship in the developed models is either linear or is based on a predefined base function [
60]. Acceptable performance of ANN models is the main attraction for their application, but one of the shortcomings is the problem with generalization for traditional ANN-based models [
50]. The development of models by ANN have the potential to overfit the data. Moreover, the utmost difficult task to carry out in studies using ANN is to identify the ideal number of neurons and layers in hidden layers with a trial-and-error approach to identify optimal network architecture [
8,
51]. In the recent decade, the majority of research studies have placed their focus on GEP and NN in order to model the MS and MF, the output parameters of M2DM, although MEP has certain advantages over similar algorithms. Usually, a large database is utilized to model MS and MF of M2DM. In GP, the utilization of a genetic tree cross-over operator results in the creation of a parse tree with a large population, which in turn, leads to increased simulation time and a requirement for large memory [
42]. Additionally, the non-linear structure of GP works as a phenotype and genotype, which makes it challenging for the algorithm to devise a suitable mathematical expression needed for the desired properties. [
61]. However, the MEP’s inclusion of a linear variant enables it to easily differentiate between the phenotype and genotype of an individual [
34]. There is a threshold limit in the rate of success rate in GP, by increasing the number of genes in the chromosomes. Overfitting is likely to appear beyond the threshold, limiting the applications of the model in the construction industry [
62,
63,
64]. However, when the intricacy of the targeting model expression is undefined, which is major problem in material engineering, MEP is predominantly more beneficial, where a slight variation in input parameters has a significant impact on the output parameters [
46]. In MEP, the encoding of numerous solutions in a single chromosome and the linearity in the chromosomes allows the model to search in a broader space for the prediction of output parameters [
59,
65]. The obvious benefits of MEP over EAs mentioned above would result in the creation of more precise models in the field of pavement engineering. Despite the fact that MEP has significant advantages over other approaches, it has been hardly been utilized in civil engineering tasks, and in the field of pavement engineering, its applications are near to none in predicting the output parameters of M2DM, i.e., MF and MS, despite its obvious advantages.
In the current research study, to predict the output parameters of M2DM, i.e., MS and MF, models have been developed utilizing the MEP technique. The modeling is combined with detailed statistical analysis and external validation, in conjunction with parametric study to warrant the accuracy, precision and effectiveness of the model. The availability of reliable and consistent models will endorse the utilization of the MEP technique in the construction sector, in general, and the pavement industry specifically, as it will bypass the hectic and time-consuming experimental procedures used for M2DM. This would contribute toward the reduction of time for testing and promote the use of the MEP technique. Additionally, the current methodology for modeling will pave the way for similar and accurate complex modeling of engineering phenomena.
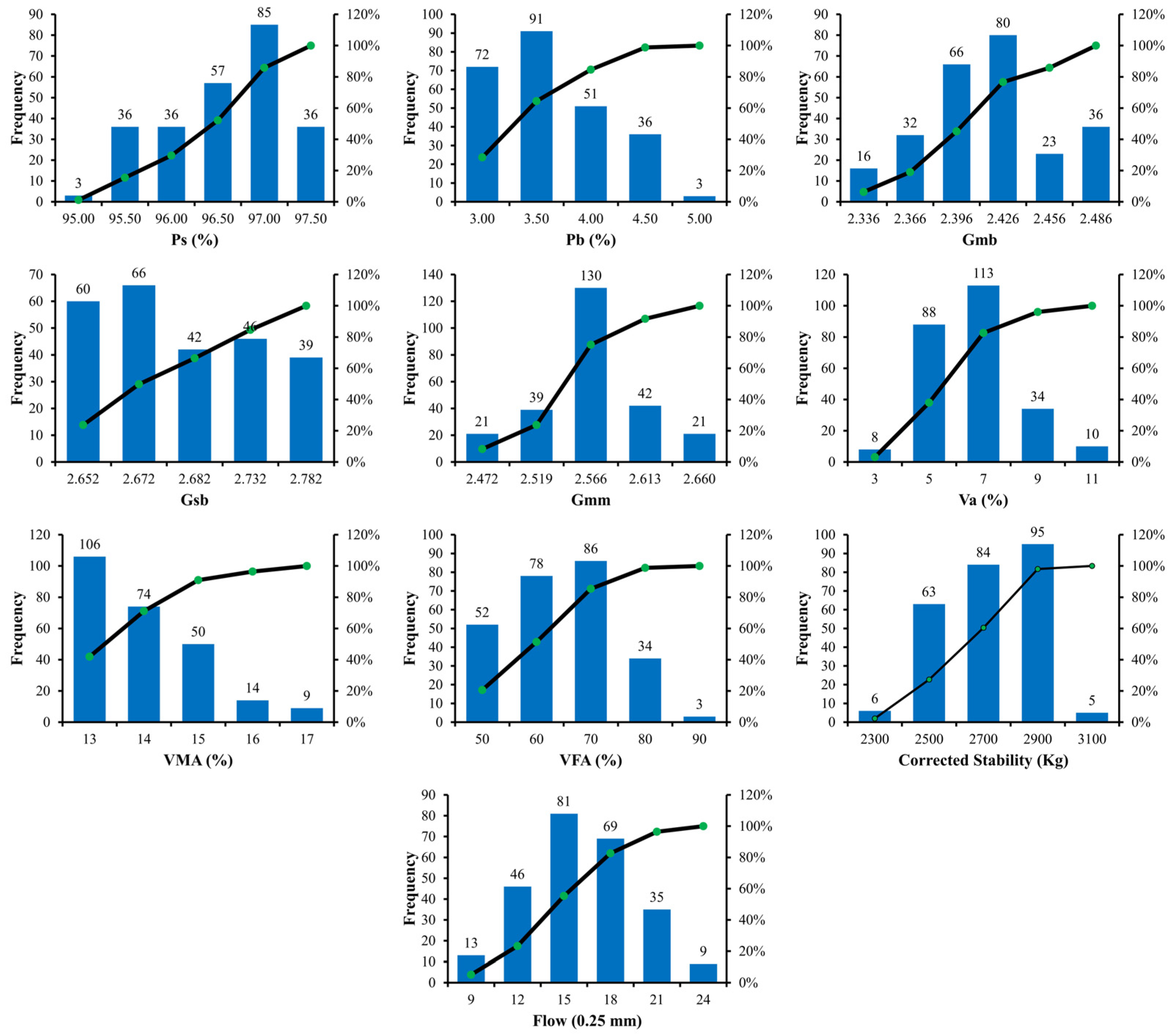
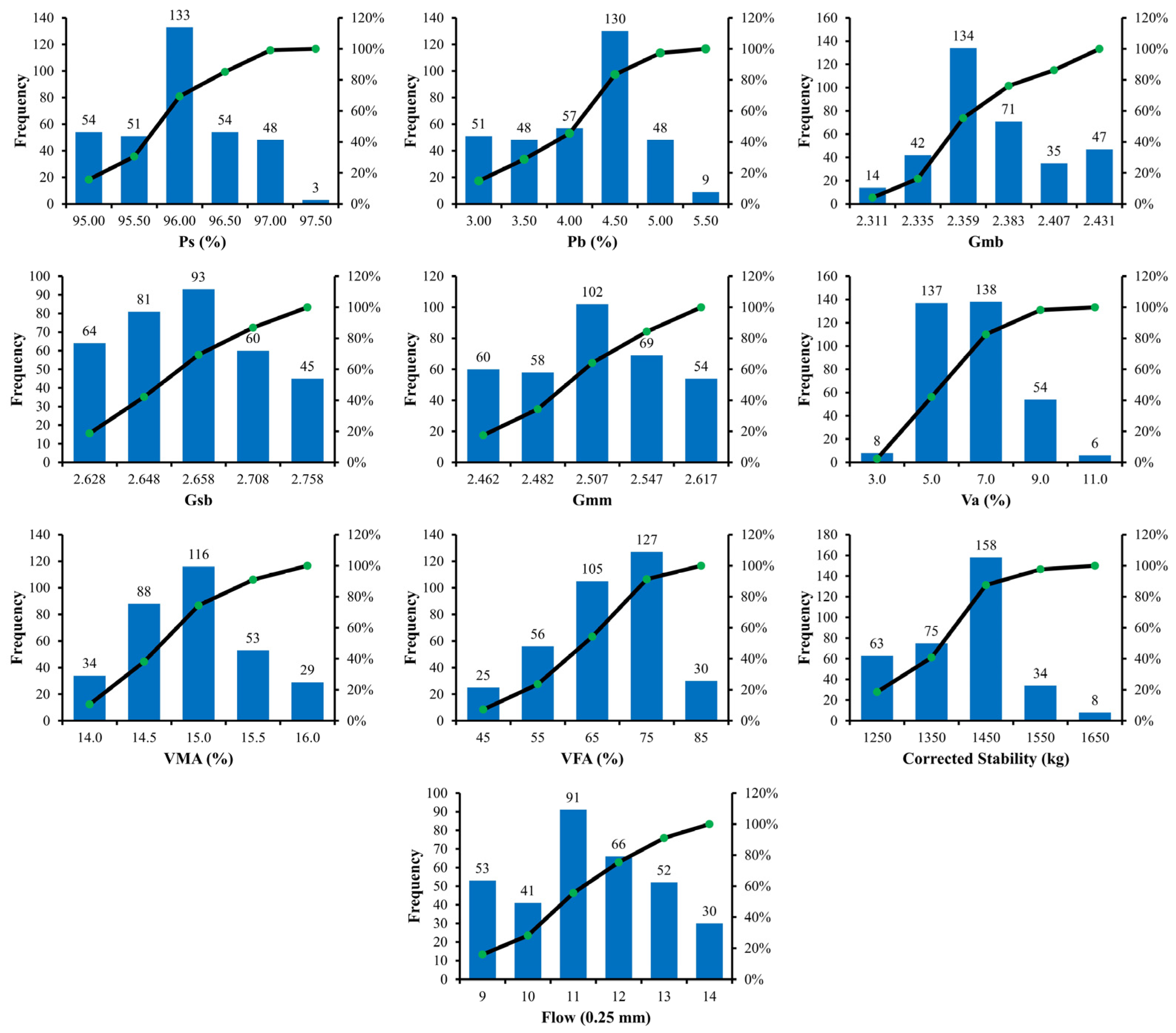
3. Model Development and Evaluation Criteria
The selection of influential input parameters for the prediction of output parameters is the starting step in the development of a model. In order to develop the model, the parameters affecting MS and MF were selected. Numerous trials were made, and the results were calculated to assess the best and simplest influencing parameters for the development of the model. The equations below are used for the calculations of MS and MF of ABC and AWC of asphalt pavements.
Several fitting input parameters are required in MEP, which need to be identified before model development for a generalized and robust model. The fitting input parameters are carefully chosen, considering the previous recommendations and the trial-and-error approach [
72]. The size of the population specifies the number of programs that are to be evolved. A model developed with large population size might be relatively accurate but it would be more complex and might take longer time to converge. Although, as size increases beyond a threshold limit, issues may arise regarding the overfitting of the model.
At the beginning, a subpopulation size of 10 and 100 generations were considered for the initiation of the project, with basic mathematical parameters, i.e., subtraction, addition, division, and multiplication. The parameters, including subpopulation and number of generations, were gradually increased in trials by addition of mathematical parameters in the models to reduce error size. The final selection of parameters for the four models, based on an acceptable error range, is shown in
Table 5.
The accuracy level that the model’s algorithm should achieve is determined by the number of generations prior to its termination. The larger the number of generations in a run, the less the statistical errors will be. Likewise, crossover and mutation rates indicate the offspring’s probability of undergoing these genetic operations. The range for the rate of crossover lies between 50–95%. Various combinations of the settings shown in
Table 5 were tested on the data sample, and the optimum set of combinations was chosen based on the model’s overall performance attributes, which are shown in
Table 5. Overfitting of the data is one of major challenges in AI-based modeling. The model’s efficiency is high, when using the original data, however, the efficiency reduces considerably when unseen data is used. To avoid this issue, it is recommended that the training model be tested on a testing or unseen dataset [
73,
74]. Consequently, the entire dataset was randomly divided into sets of training, validation and testing. In modeling, datasets of training and validation were processed. The validation model was then tested on the testing dataset, which was not included in the development of the model. The data distribution of all three datasets was assured to be consistent. For the current research study, 70%, 15%, and 15% of the data were used as training, testing, and validation, respectively. On all three datasets, the final developed models outperformed the competition. MEPX v 2021.08.05.0-beta, a commercially available computing tool, was used to implement the MEP algorithm.
The algorithm begins by creating a population of the most possible solutions. The process of the algorithm is iterative, and with each generation, it arrives closer to the solution. Within the solution population, each generation’s fitness is assessed. The algorithm of MEP continues to advance until the function for pre-specified fitness, such as root mean squared error (RMSE) or R, remains unchanged. For each trained model, the objective function (OF) was also assessed in this research study because it reflects the influence of R, RMSE and frequency of data points to quantify the overall efficiency. If the results of the model for all datasets, i.e., training, validation, and testing, are not accurate, the process is repeated, increasing the size and number of subpopulations incrementally. After that, the model is finalized based on the minimum value OF. It was determined that certain models performed better on the dataset of training than on the testing set, indicating overfitting of the proposed model, which ought to be avoided. The number of generations it takes for a model to evolve has an in impact on the mode’s accuracy. A model would keep evolving indefinitely in these types of algorithms due to induction of additional variables into the system. All the models in this research study were terminated at 1000 generations. Furthermore, an ideal model should meet the criteria for several performance indicators, as elaborated in the following discussion.
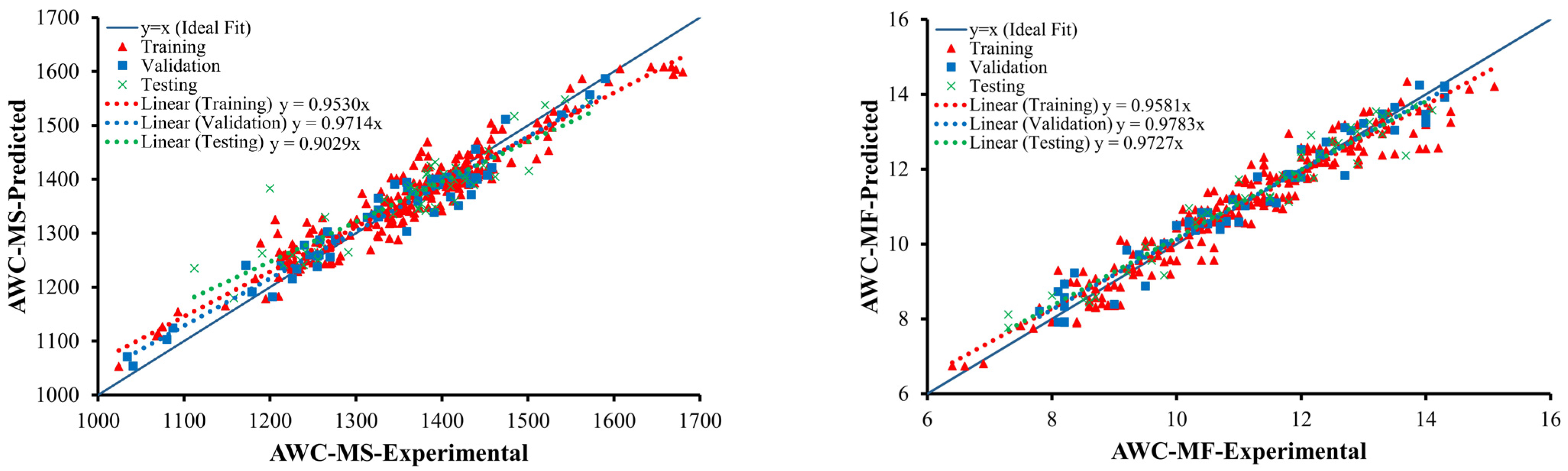
The effectiveness of the models was assessed by calculating several statistical error metrics. These statistical errors included for the assessment of the models were R, mean absolute error (MAE), RMSE, relative squared error (RSE), relative root mean square error (RRMSE), and the performance index (ρ). Moreover, another strategy to prevent the model’s overfitting was to choose an optimal model by reducing the value of OF, as advocated by Azim et al. [
69], which is referred to as the fitness function. These statistical measures have the following Expressions (1)–(7):
where p
i, x
i,
and
, denote the ith predicted, experimental, mean predicted and mean experimental values, respectively, and the symbol n denotes the total number of values in the dataset used for the development of the models. The training and testing sets are denoted by abbreviations T and TE, respectively. An accurate model has a high R value, while the statistical errors are low. R has been recommended by the researchers to assess the linear dependency among input and output parameters [
75], with a value greater than 0.8 indicating a decent correlation between experimental and predicted values [
41,
76]. Due to the insensitivity of R with the division and multiplication of outputs with a constant, it could not be considered solely as a measure for overall model efficiency. The average magnitude of errors can be measured using MAE and RMSE. Both parameters, however, have their own implication. In RMSE, errors are squared before average is estimated, giving larger errors more weight. A high RMSE value indicates that the amount of high-error predictions is significantly more than the expected and should be excluded. MAE, however, gives large errors a low weight and is always smaller than RMSE. Likewise, Despotovic et al., (2016) recommended that a model is considered to be outstanding if RRMSE values are between 0 and 0.10 and fair if the value is between 0.11 and 0.20 [
77]. The range of values for OF and ρ is 0–infinity. If the values of ρ and OF are less than 0.2, the model can be considered as good [
66]. While using OF, it considers three factors at the same time, i.e., R and RRMSE with relative percentage of data in various datasets (training and testing). As a result, a low value of OF indicates that the model’s overall performance is superior. As stated previously, numerous trial runs were carried out, and the models with the lowest values of OF stated in this research study. Additionally, the validation of developed models was also carried out using criteria suggested by various researchers, which are described in
Table 6.
6. Conclusions
This research study utilizes MEP, an innovative AI technique in the area of pavement engineering to develop predictive models for MS and MF of M2DM for the ABC and AWC of flexible pavements. For this reason, wide and comprehensive datasets were produced from various projects in Pakistan. The researchers developed high-precision models, and the following are the main conclusions of this research study:
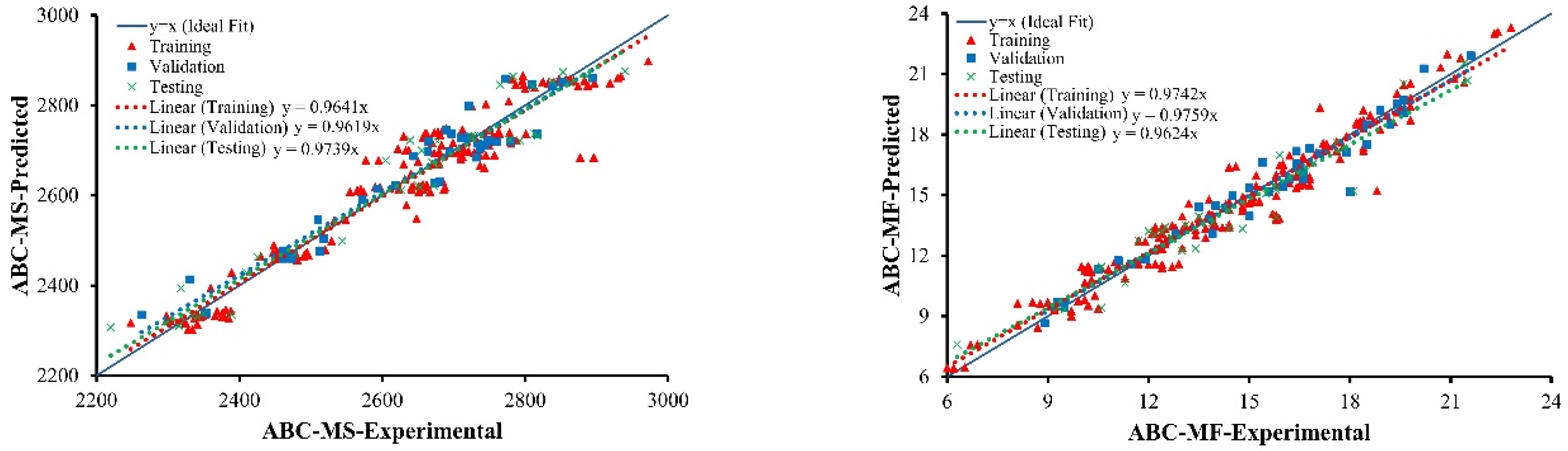
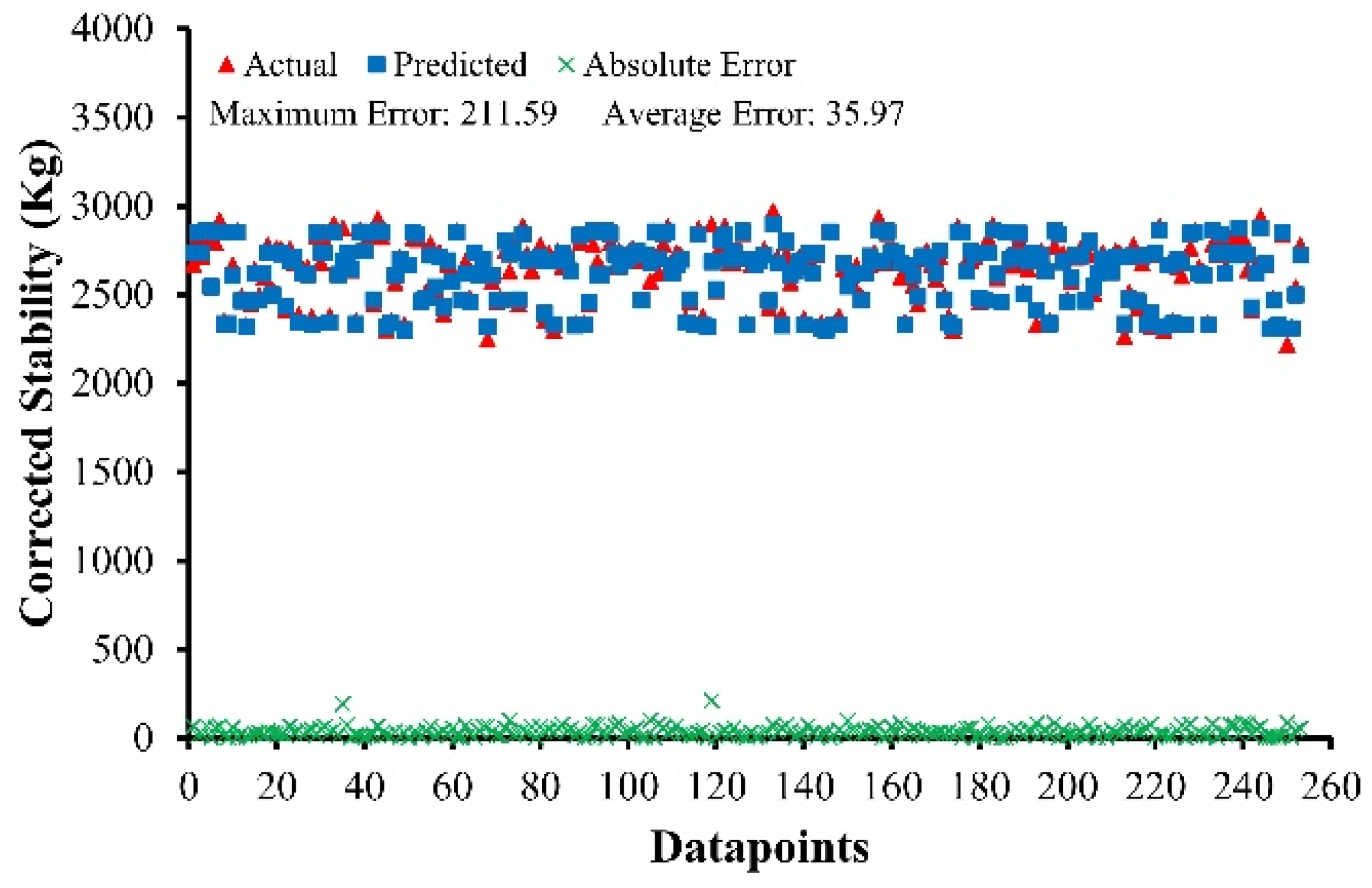
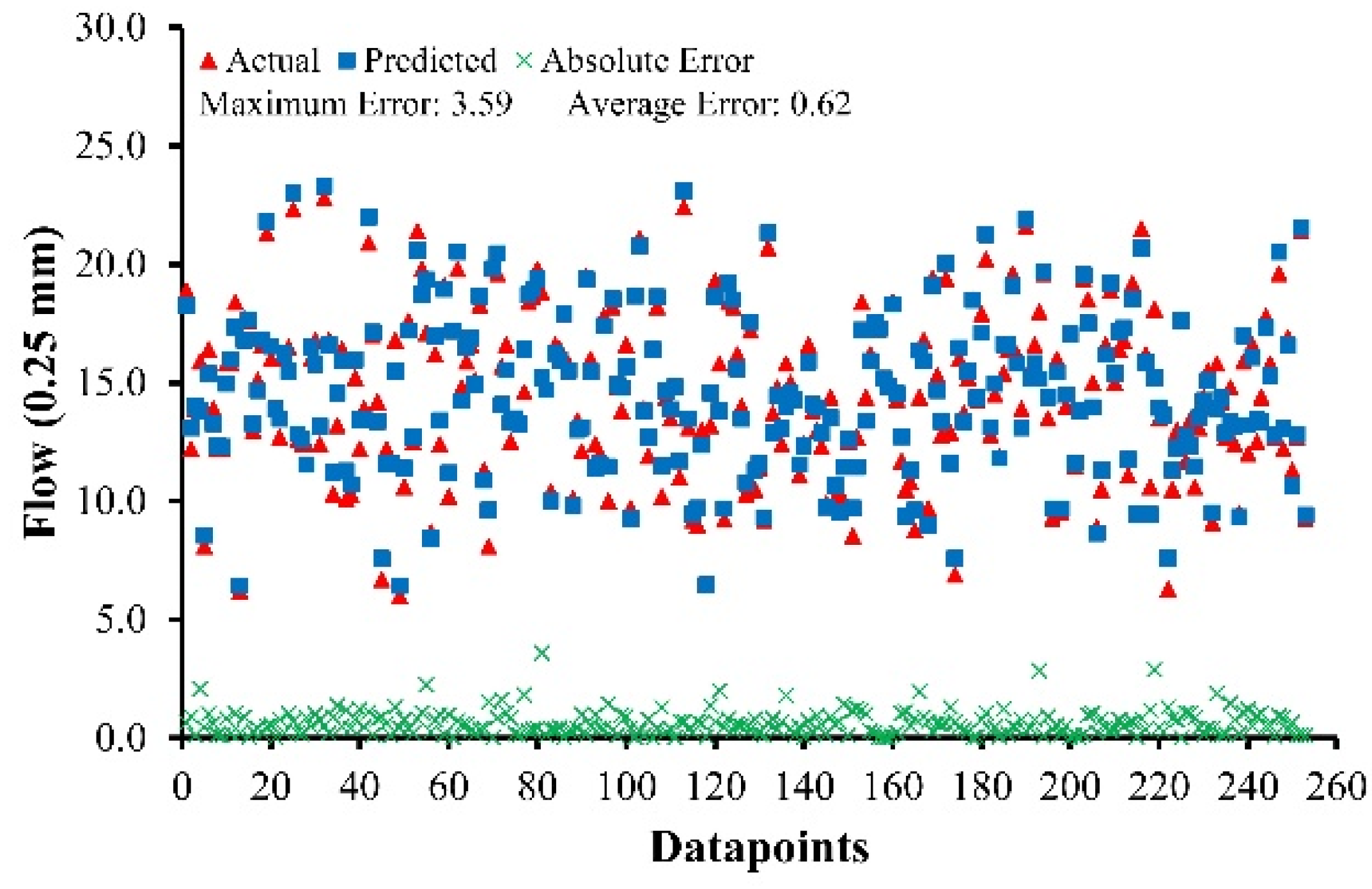
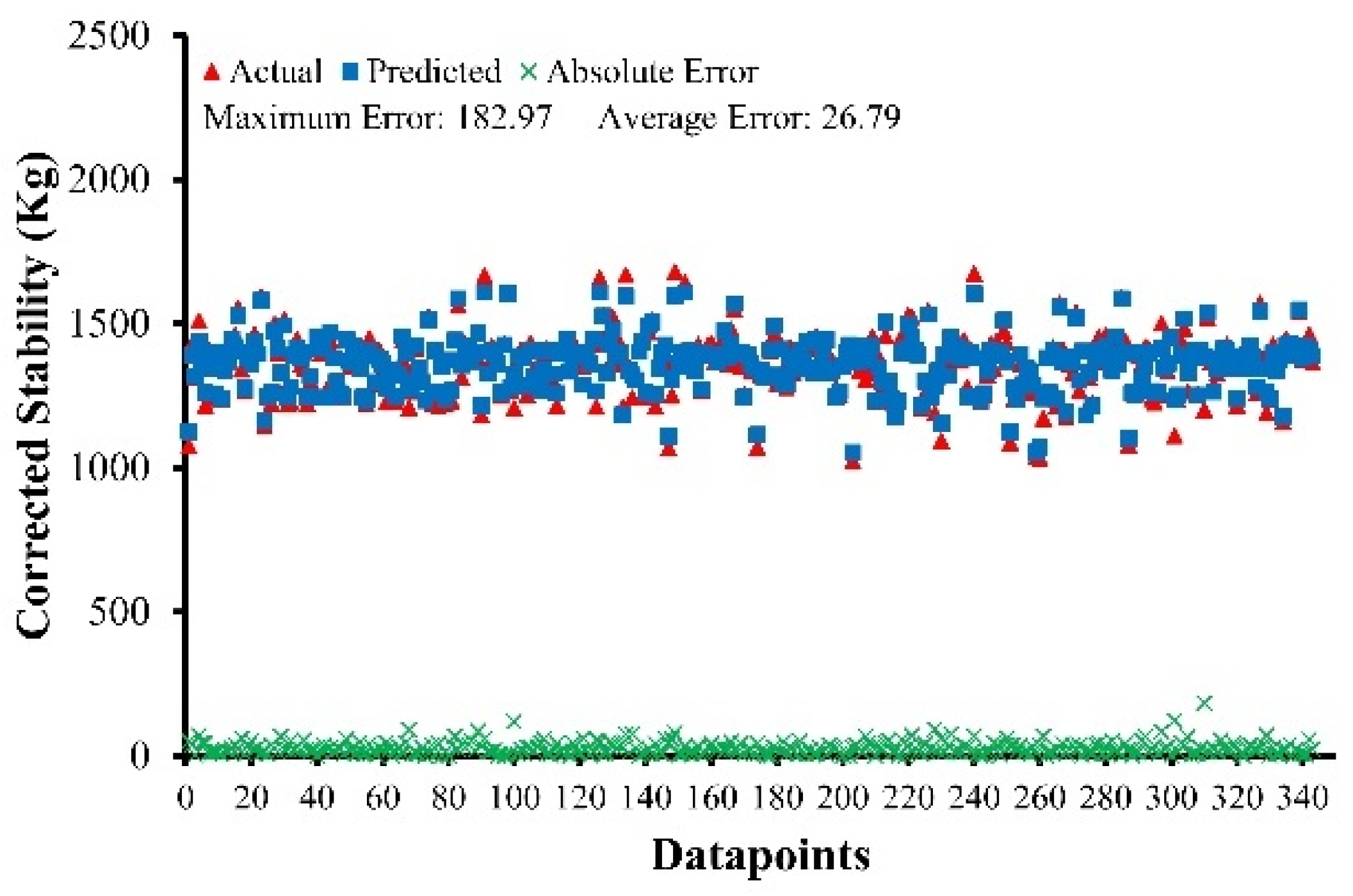
The developed models have produced results that are consistent with the experimental data and function equally well for unknown data.
Various performance measures such as R, RRMSE, RSE, RMSE, MAE were used to assess the reliability and correction of the developed models. Furthermore, OF and ρ showed highly generalization capability of the developed models, with the issue of overfitting effectively addressed. The results of the statistical parameters validated the accuracy of the proposed MEP developed models.
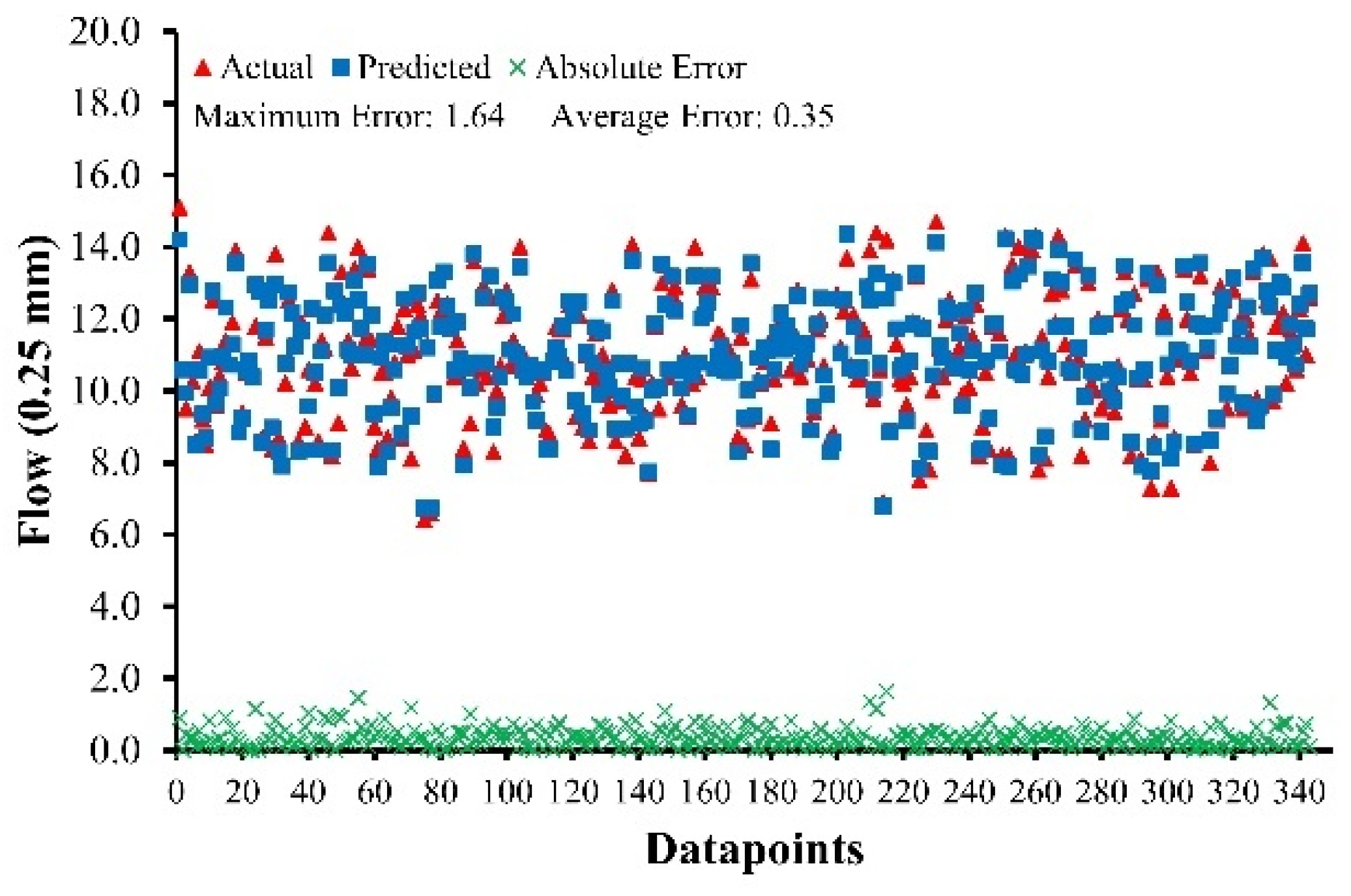
The value of R lies in between 0.90 and 0.98 for MS and MF of ABC and AWC. MAE ranges from 24.64 to 36.94 kg for MS of ABC and AWC, while it ranges from 0.31 (0.25 mm) to 0.71 (0.25 mm) for MF of ABC and AWC.
The developed models also met a number of external validation criteria taken from the literature.
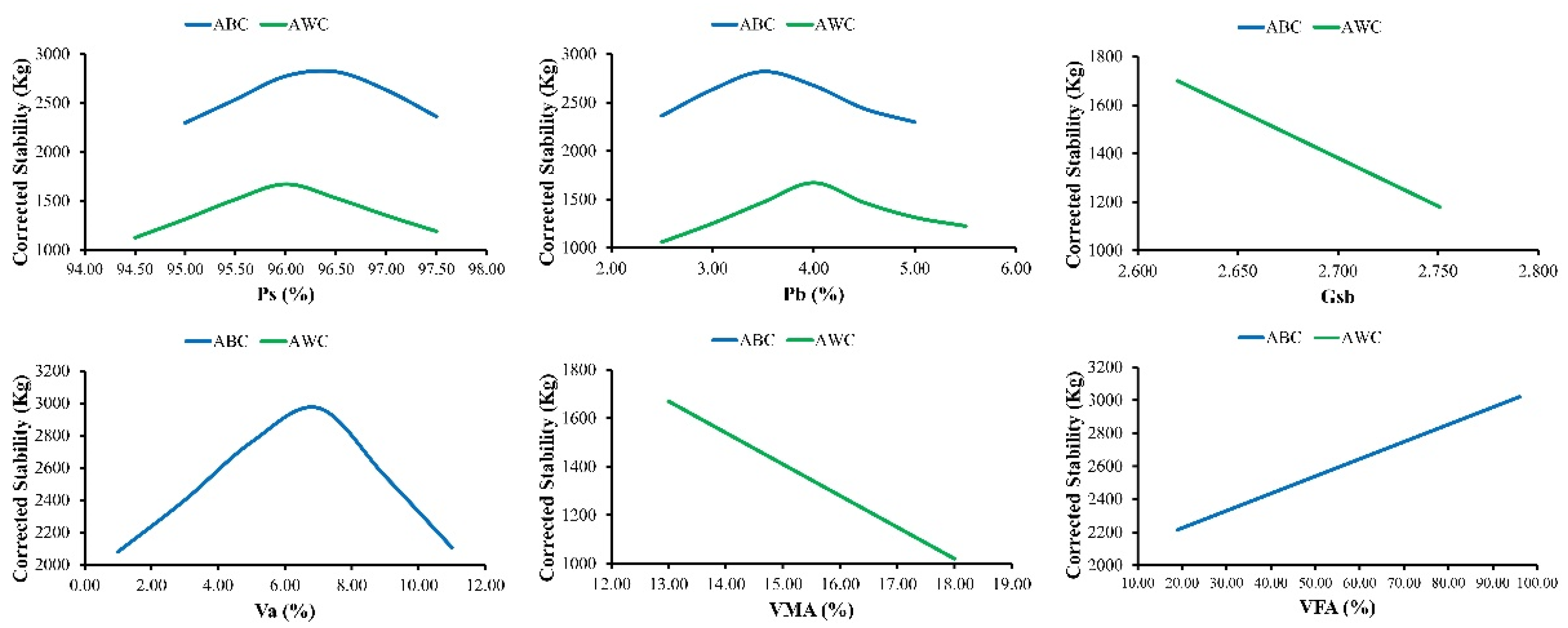
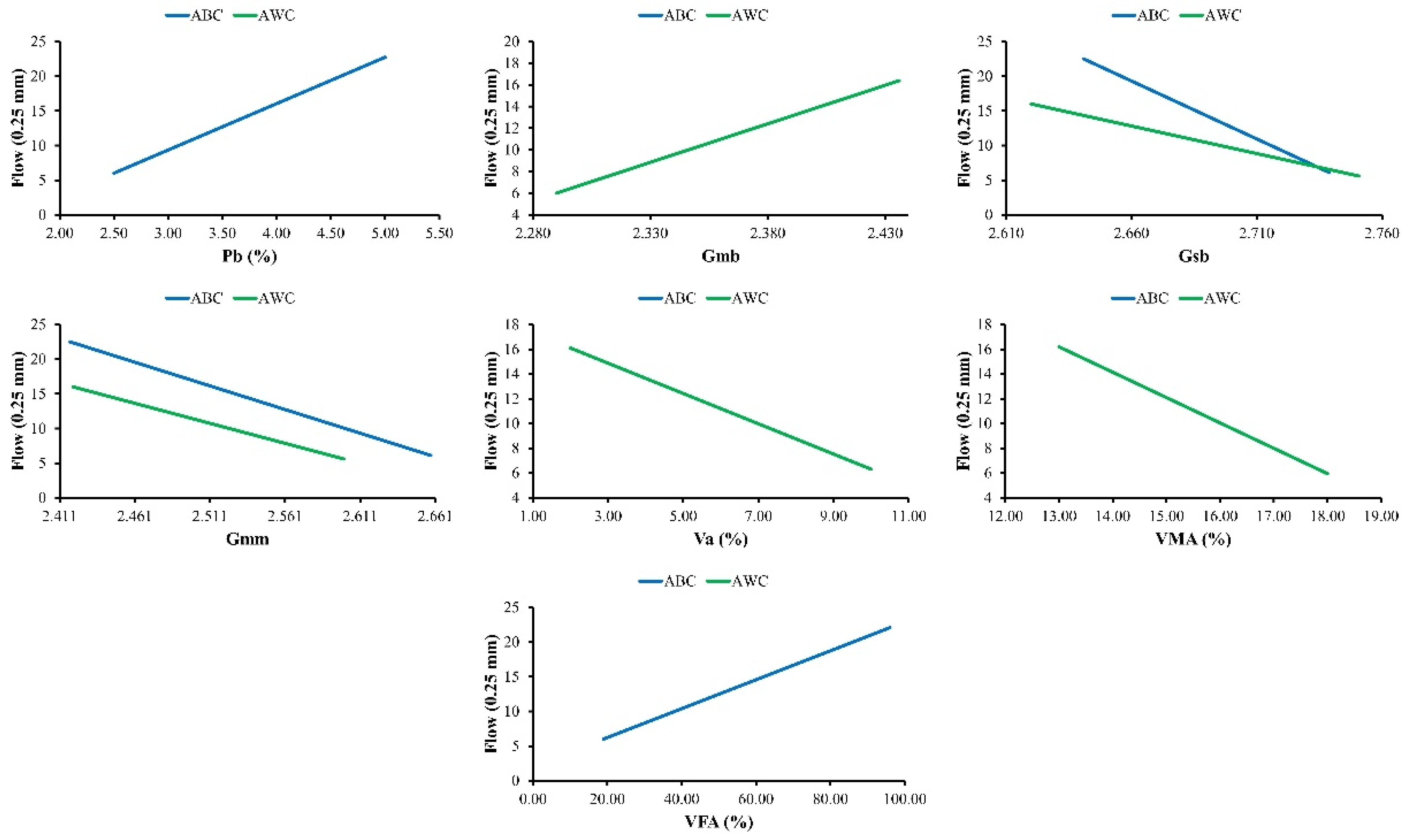
The models developed have successfully incorporated input parameters and have the capability to predict the trends of MS and MF for flexible pavements, as revealed from the parametric study.
It is convincing from the modeling approach being proposed, i.e., MEP in conjunction with validation parameters, that MEP can be utilized for predicting the Marshall parameters.
It is suggested that different AI techniques such as SVM, Ensemble random forest regression, eXtreme gradient boosting (XGBoost), GEP, and ANFIS should be used to predict MS and MF and should then be compared to each other to see which AI technique is more efficient in predicting MS and MF.
It is recommended that bitumen with different penetration grades such as 85/100 and 45/50 be tested on AI-based Marshall parameter modeling.
The most influential parameter in M2DM is the grading of aggregates, whereas the impact of grading on M2DM has to be discussed by various researchers. Hence, finding the influence of different types of grading on Marshall parameters using various AI methods is also recommended.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}