
Comparative Evaluation of Different Multi-Agent Reinforcement Learning Mechanisms in Condenser Water System Control

Abstract
:1. Introduction
1.1. Value and Application of Reinforcement Learning (RL) Techniques in HVAC System Control
- (1)
- As stated in Ref. [11], model-based control methods’ heavy dependence on accurate system performance models is the main barrier between academic control approaches and practical engineering applications: an accurate model requires integral sensor systems, extensive manual labor, and time to build [8]; moreover, model uncertainty and inaccuracy may harm control performance [12,13].
- (2)
- Model-free reinforcement learning is a discipline that concerns the fast training of self-learning agents for games and optimal control problems [14]. Its independence from embedded models is suitable to mitigate the “model dependency” issue. The model-free nature of this technique leads to fewer pre-conditions and faster online computation, which enhance its feasibility in building control applications.
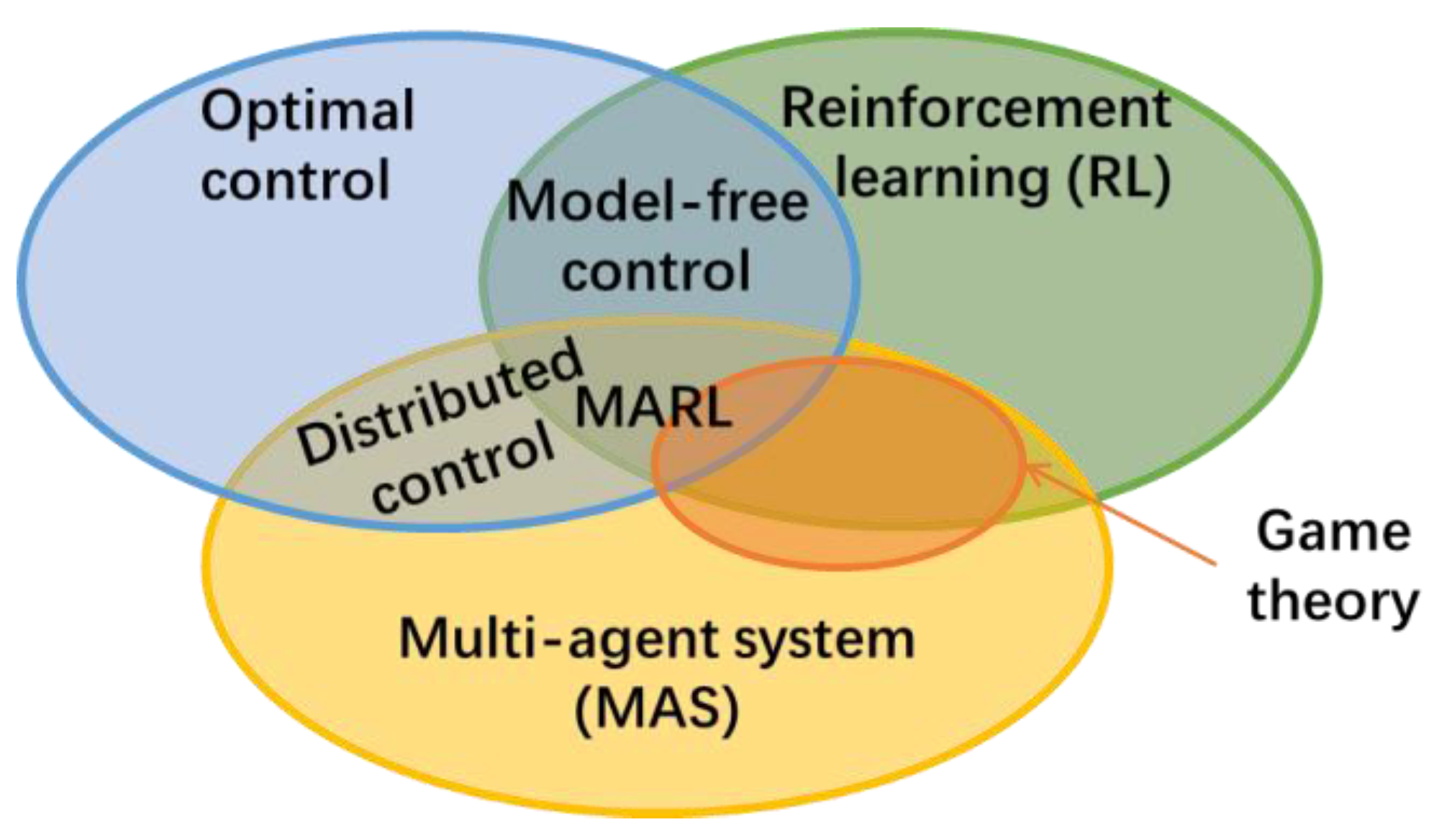
1.2. Multi-Agent Reinforcement Learning (MARL)
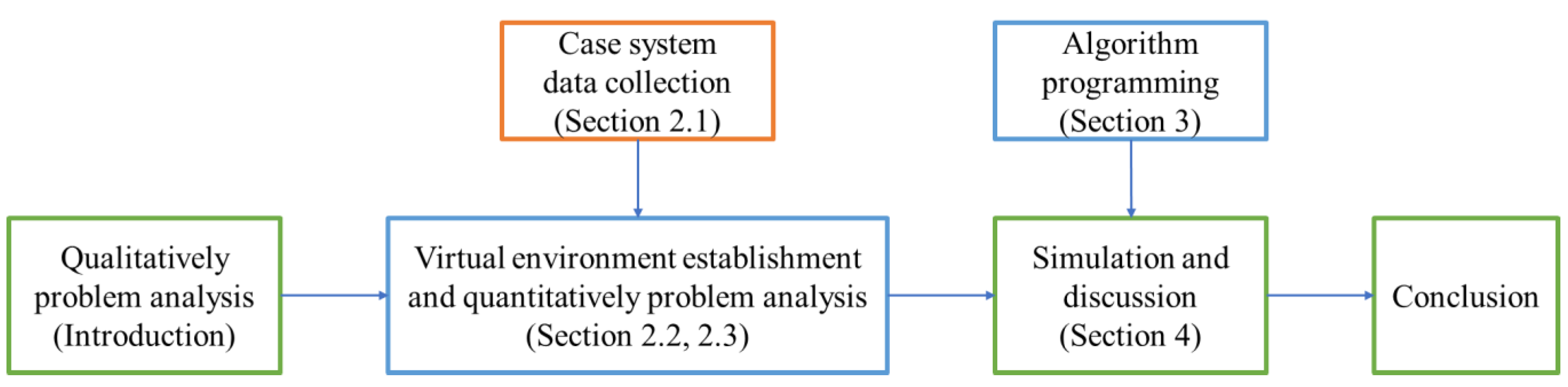
1.3. Motivation and Overall Framework of this Research
2. Virtual Environment Establishment
2.1. Case System
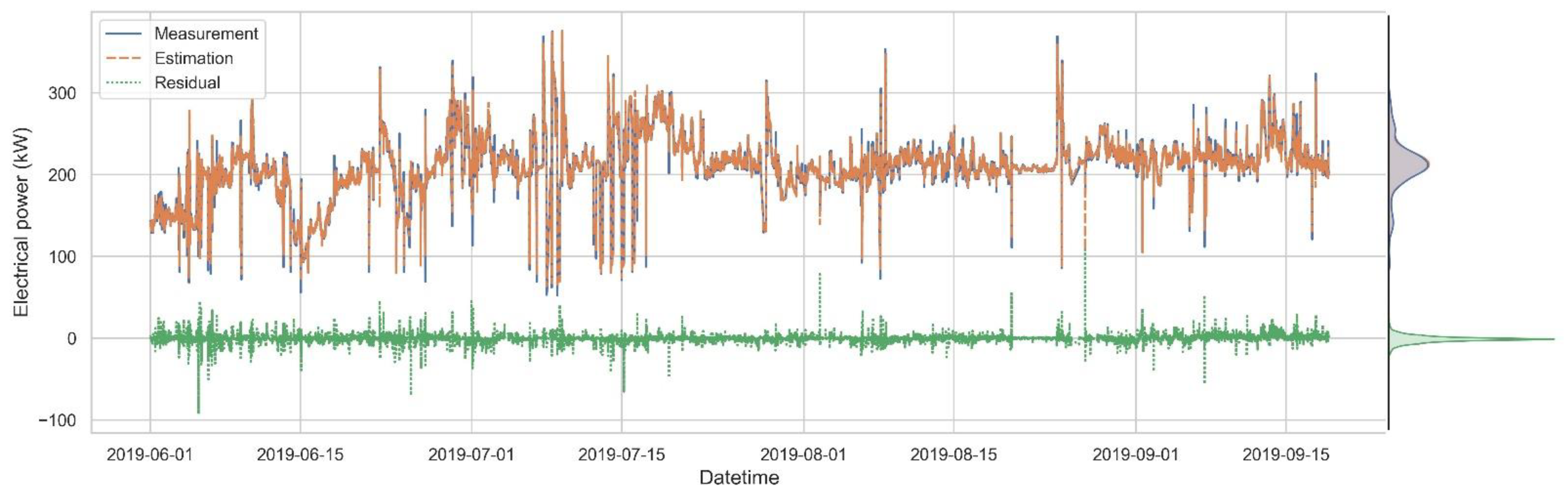
2.2. Field-Data-Based System Modeling
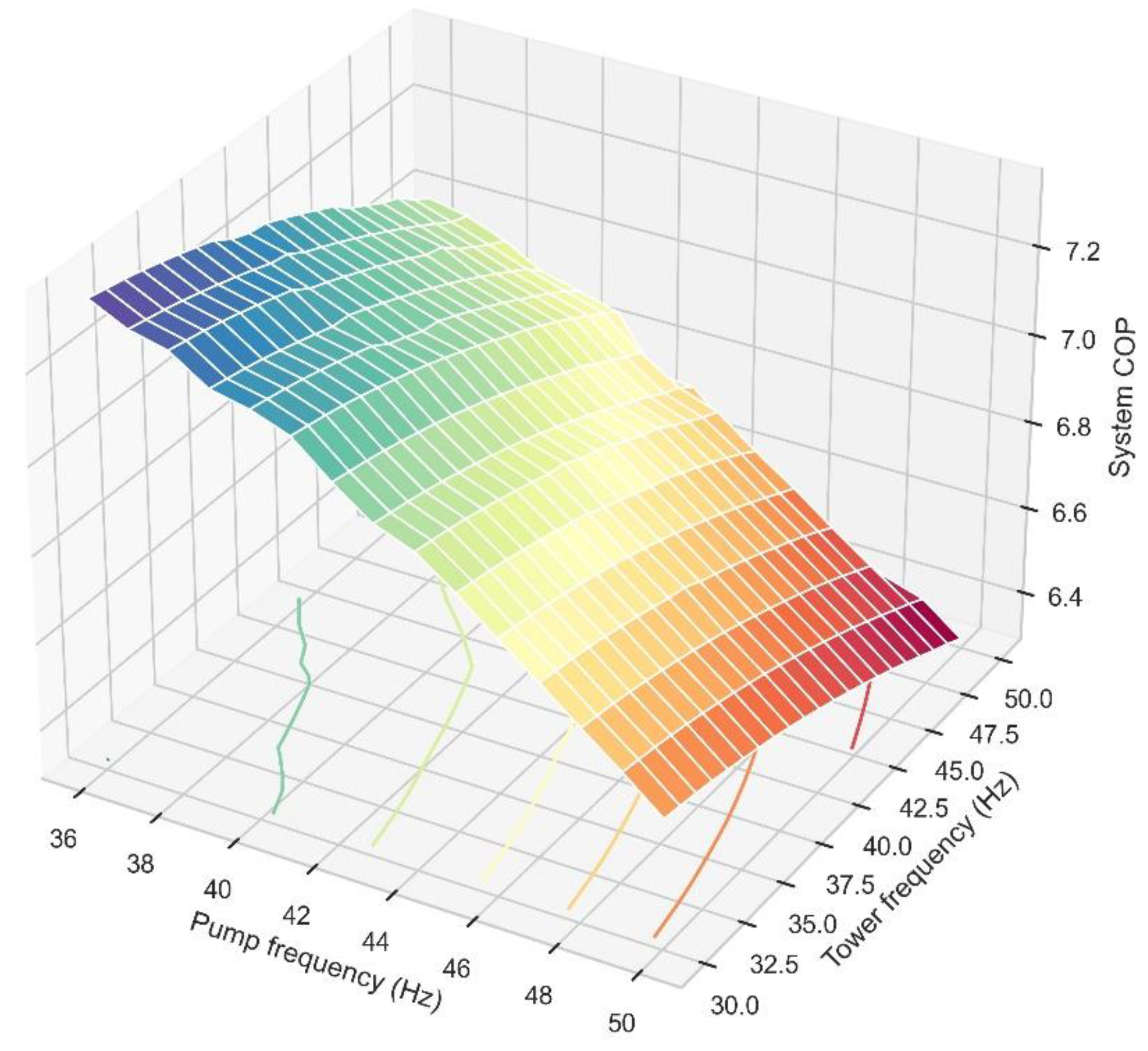
2.3. Mutual Inference between Cooling Tower Action and Condenser Water Pump Action
3. Methodology of MARL-Based Controllers
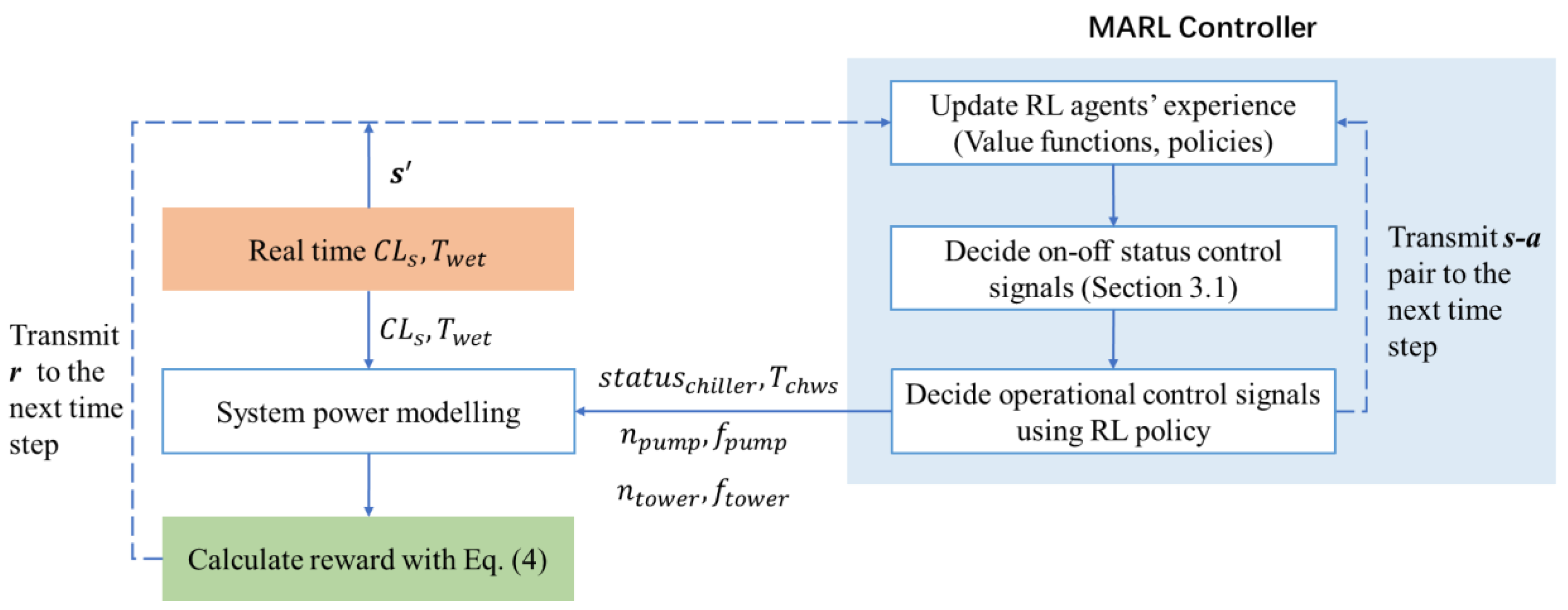
3.1. Overview
- (1)
- Input real-time and (two uncontrollable environmental variables [5]) to the virtual environment (i.e., system model) and the controller.
- (2)
- Based on the inputs, the controller decides the proper control signals, including on–off control signals and operational signals (i.e., setpoints of ).
- (3)
- Model the electrical power of the system. Calculate the system’s COP (the common reward of RL agents).
- (4)
- Turn to the next simulation time step.
- (5)
- RL agents update the experience with the last reward , last state–action () pair, and current state .
- (1)
- (2)
- In order to fully utilize the heat exchange area of cooling towers, two cooling towers operate simultaneously when the system is on.
- (3)
- Two chillers operate simultaneously when is larger than a single chiller’s maximum cooling capacity; otherwise, only Chiller 1 operates to cover the cooling demand.
- (4)
- The number of running condenser water pumps is in accordance with the number of working chillers.
- (5)
- is set to 11 °C constantly, which is close to the chillers’ nominal value.
3.2. Division and Multiplication MARL Controllers: Policy Hill Climbing
3.3. Interaction MARL Controller: WoLF-PHC
4. Simulation Case Study and Discussion
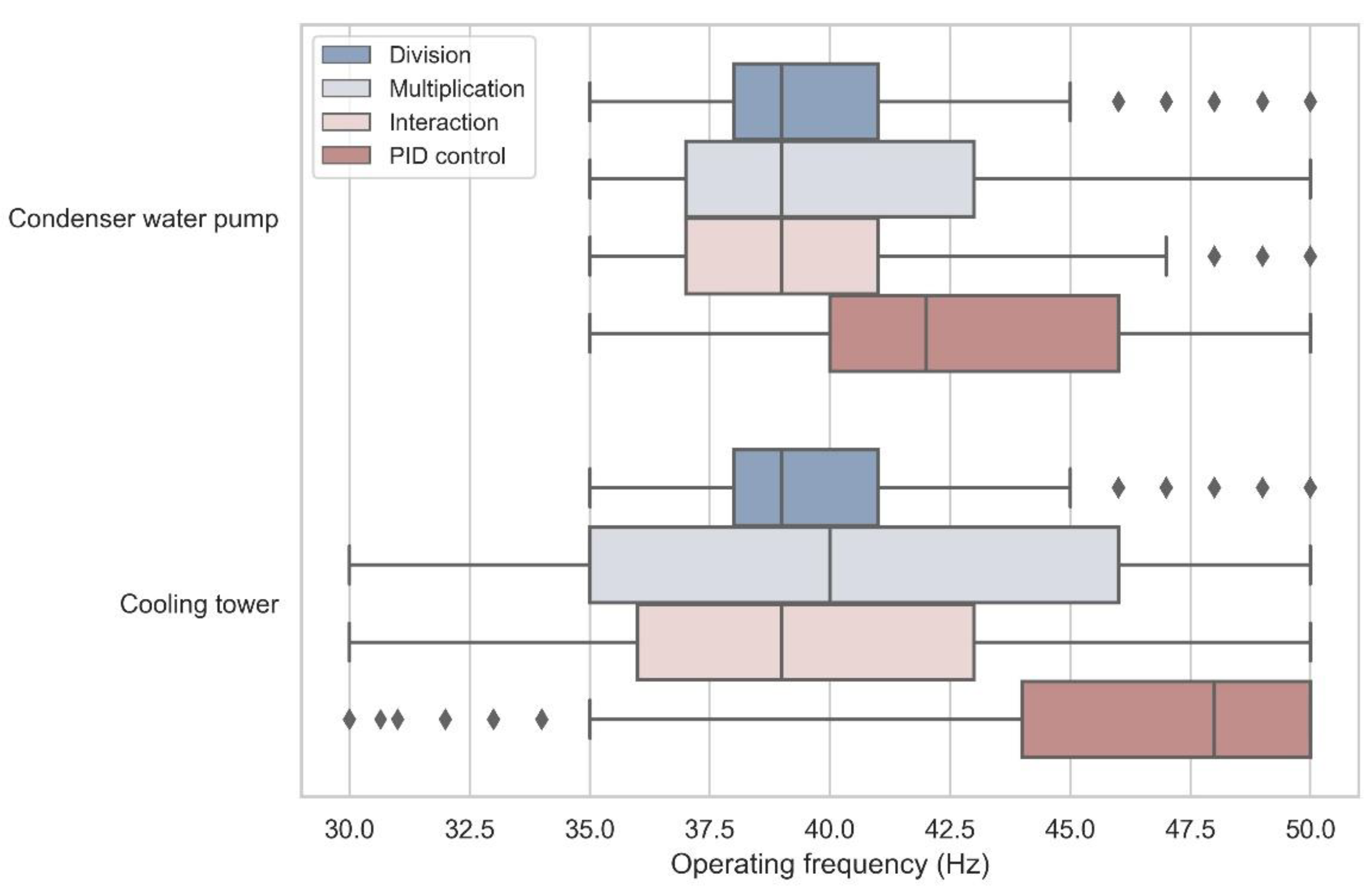
4.1. Short-Term Performance
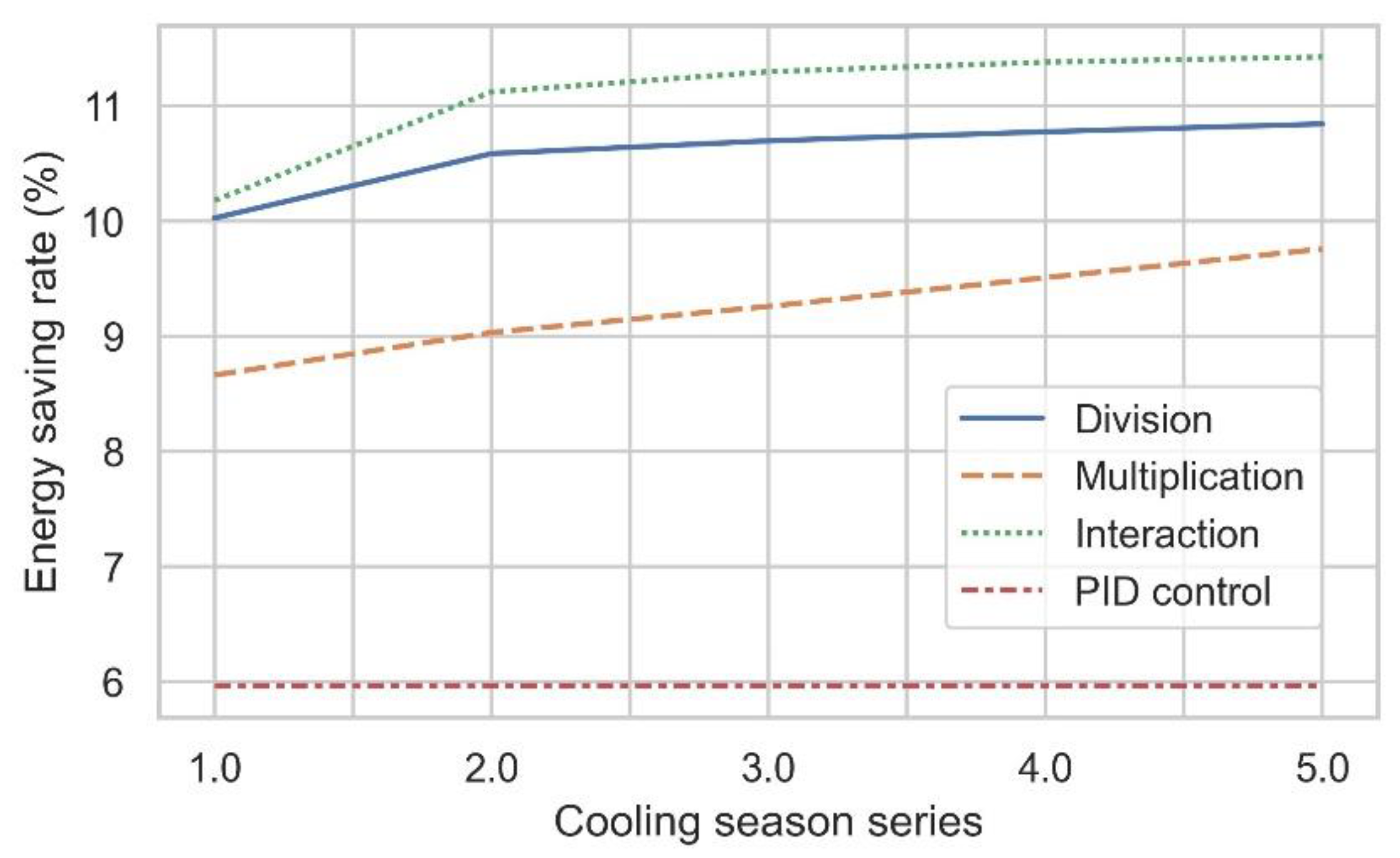
4.2. Long-Term Performance
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Klepeis, N.E.; Nelson, W.C.; Ott, W.R.; Robinson, J.P.; Tsang, A.M.; Switzer, P.; Behar, J.V.; Hern, S.C.; Engelmann, W.H. The National Human Activity Pattern Survey (NHAPS): A resource for assessing exposure to environmental pollutants. J. Expo. Sci. Environ. Epidemiol. 2001, 11, 231–252. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Hong, T. Reinforcement learning for building controls: The opportunities and challenges. Appl. Energy 2020, 269, 115036. [Google Scholar] [CrossRef]
- International Energy Agency. World Energy Statistics and Balances; Organisation for Economic Co-operation and Development: Paris, France, 1989. [Google Scholar]
- Hou, J.; Xu, P.; Lu, X.; Pang, Z.; Chu, Y.; Huang, G. Implementation of expansion planning in existing district energy system: A case study in China. Appl. Energy 2018, 211, 269–281. [Google Scholar] [CrossRef]
- Wang, S.; Ma, Z. Supervisory and Optimal Control of Building HVAC Systems: A Review. HVAC R Res. 2008, 14, 3–32. [Google Scholar] [CrossRef]
- Taylor, S.T. Fundamentals of Design and Control of Central Chilled-Water Plants; ASHRAE Learning Institute: Atlanta, GA, USA, 2017. [Google Scholar]
- Swider, D.J. A comparison of empirically based steady-state models for vapor-compression liquid chillers. Appl. Therm. Eng. 2003, 23, 539–556. [Google Scholar] [CrossRef]
- Huang, S.; Zuo, W.; Sohn, M.D. Improved cooling tower control of legacy chiller plants by optimizing the condenser water set point. Build. Environ. 2017, 111, 33–46. [Google Scholar] [CrossRef] [Green Version]
- Braun, J.E.; Diderrich, G.T. Near-optimal control of cooling towers for chilled-water systems. ASHRAE Trans. 1990, 96, 2. [Google Scholar]
- Hee Kang, W.; Yoon, Y.; Hyeon Lee, J.; Woo Song, K.; Tae Chae, Y.; Ho Lee, K. In-situ application of an ANN algorithm for optimized chilled and condenser water temperatures set-point during cooling operation. Energy Build. 2021, 233, 110666. [Google Scholar] [CrossRef]
- Qiu, S.; Li, Z.; Li, Z.; Li, J.; Long, S.; Li, X. Model-free control method based on reinforcement learning for building cooling water systems: Validation by measured data-based simulation. Energy Build. 2020, 218, 110055. [Google Scholar] [CrossRef]
- Zhu, N.; Shan, K.; Wang, S.; Sun, Y. An optimal control strategy with enhanced robustness for air-conditioning systems considering model and measurement uncertainties. Energy Build. 2013, 67, 540–550. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Huang, G. Chiller sequencing control with enhanced robustness for energy efficient operation. Energy Build. 2009, 41, 1246–1255. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G.; Bach, F. Reinforcement Learning: An Introduction; A Bradford Book; The MIT Press: Cambridge, MA, USA; London, UK, 2018. [Google Scholar]
- Deng, X.; Zhang, Y.; Zhang, Y.; Qi, H. Towards optimal HVAC control in non-stationary building environments combining active change detection and deep reinforcement learning. Build. Environ. 2022, 211, 108680. [Google Scholar] [CrossRef]
- Qiu, S.; Li, Z.; Fan, D.; He, R.; Dai, X.; Li, Z. Chilled water temperature resetting using model-free reinforcement learning: Engineering application. Energy Build. 2022, 255, 111694. [Google Scholar] [CrossRef]
- Tao, J.Y.; Li, D.S. Cooperative Strategy Learning in Multi-Agent Environment with Continuous State Space. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 2107–2111. [Google Scholar]
- Buşoniu, L.; Babuška, R.; De Schutter, B. Multi-agent Reinforcement Learning: An Overview. In Innovations in Multi-Agent Systems and Applications—1; Srinivasan, D., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 183–221. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Bowling, M.; Veloso, M. Multiagent learning using a variable learning rate. Artif. Intell. 2002, 136, 215–250. [Google Scholar] [CrossRef] [Green Version]
- Oroojlooyjadid, A.; Hajinezhad, D. A Review of Cooperative Multi-Agent Deep Reinforcement Learning. arXiv 2019, arXiv:1908.03963. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Cohen, W.W., Hirsh, H., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1994; pp. 157–163. [Google Scholar] [CrossRef] [Green Version]
- Shiyao, L.; Yiqun, P.; Qiujian, W.; Zhizhong, H. A non-cooperative game-based distributed optimization method for chiller plant control. Build. Simul. 2022, 15, 1015–1034. [Google Scholar] [CrossRef]
- Schwartz, H.M. Multi-Agent Machine Learning: A Reinforcement Approach; Wiley Publishing: New York, NY, USA, 2014. [Google Scholar]
- Zhang, K.; Yang, Z.; Baar, T. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms. arXiv 2019, arXiv:1911.10635. [Google Scholar]
- Weiss, G.; Dillenbourg, P. What Is "Multi" in Multiagent Learning? Collaborative Learning: Cognitive and Computational Approaches; Pergamon Press: Amsterdam, The Netherland, 1999. [Google Scholar]
- Tesauro, G. Extending Q-Learning to General Adaptive Multi-Agent Systems. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA; London, UK, 2003. [Google Scholar]
- Matignon, L.; Laurent, G.J.; Le Fort-Piat, N. Independent reinforcement learners in cooperative Markov games: A survey regarding coordination problems. Knowl. Eng. Rev. 2012, 27, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Tan, M. Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents. In Proceedings of the Tenth International Conference, University of Massachusetts, Amherst, MA, USA, 27–29 June 1993; pp. 330–337. [Google Scholar]
- Yang, L.; Nagy, Z.; Goffin, P.; Schlueter, A. Reinforcement learning for optimal control of low exergy buildings. Appl. Energy 2015, 156, 577–586. [Google Scholar] [CrossRef]
- Sen, S.; Sekaran, M.; Hale, J. Learning to coordinate without sharing information. In Proceedings of the Twelfth AAAI National Conference on Artificial Intelligence, Seattle, DC, USA, 31 July–4 August 1994; pp. 426–431. [Google Scholar]
- Usunier, N.; Synnaeve, G.; Lin, Z.; Chintala, S. Episodic Exploration for Deep Deterministic Policies: An Application to StarCraft Micromanagement Tasks. arXiv 2016, arXiv:1609.02993. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 1, 2825–2830. [Google Scholar]
- ASHRAE Standards Committee. ASHRAE Guideline 14, Measurement of Energy, Demand and Water Savings; ASHRAE: Atlanta, GA, USA, 2014. [Google Scholar]
- Pang, Z.; Xu, P.; O’Neill, Z.; Gu, J.; Qiu, S.; Lu, X.; Li, X. Application of mobile positioning occupancy data for building energy simulation: An engineering case study. Build. Environ. 2018, 141, 1–15. [Google Scholar] [CrossRef]
- Ardakani, A.J.; Ardakani, F.F.; Hosseinian, S.H. A novel approach for optimal chiller loading using particle swarm optimization. Energy Build. 2008, 40, 2177–2187. [Google Scholar] [CrossRef]
- Lee, W.; Lin, L. Optimal chiller loading by particle swarm algorithm for reducing energy consumption. Appl. Therm. Eng. 2009, 29, 1730–1734. [Google Scholar] [CrossRef]
- Chang, Y.C.; Lin, J.K.; Chuang, M.H. Optimal chiller loading by genetic algorithm for reducing energy consumption. Energy Build. 2005, 37, 147–155. [Google Scholar] [CrossRef]
- Xi, L.; Yu, T.; Yang, B.; Zhang, X. A novel multi-agent decentralized win or learn fast policy hill-climbing with eligibility trace algorithm for smart generation control of interconnected complex power grids. Energy Convers. Manag. 2015, 103, 82–93. [Google Scholar] [CrossRef]
- Xi, L.; Chen, J.; Huang, Y.; Xu, Y.; Liu, L.; Zhou, Y.; Li, Y. Smart generation control based on multi-agent reinforcement learning with the idea of the time tunnel. Energy 2018, 153, 977–987. [Google Scholar] [CrossRef]
- Littman, M.L. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar]
- Yuan, X.; Dong, L.; Sun, C. Solver–Critic: A Reinforcement Learning Method for Discrete-Time-Constrained-Input Systems. IEEE Trans. Cybern. 2021, 51, 5619–5630. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment | Number | Characteristics |
|---|---|---|
| Screw chiller | 2 | Cooling capacity = 1060 kW, power = 159.7 kW |
| Condenser water pump | 2 + 1 (one auxiliary) | Power = 14.7 kW, flowrate = 240 m3/h Head: 20 m, variable speed |
| Cooling tower | 2 | Power = 7.5 kW, flowrate = 260 m3/h, variable speed |
| Variable | Description | Unit |
|---|---|---|
| Real-time overall system electrical power | kW | |
| System cooling load | kW | |
| Ambient wet-bulb temperature | °C | |
| Common frequency of running condenser water pump(s) | Hz | |
| Current working number of condenser water pumps | ||
| Working frequency of running cooling tower(s) | Hz | |
| Current working number of cooling towers | ||
| Temperature of supplied chilled water | °C | |
| Current working status of chillers: 1—only Chiller 1 is running, 2—only Chiller 2 is running, 3—both chillers are running, 0—no chiller is running |
| Training Set | Testing Set | |
|---|---|---|
| CV(RMSE) | 1.48% | 3.76% |
| R2 | 0.99 | 0.95 |
| Off-line initialization: For the tower agent and pump agent (footnote i refers to the ith agent), formulate their action spaces and common state spaces in the same way as Division. For each agent, initialize all values to 0, initialize all values to , and initialize all values to . The number of each state’s occurrence is recorded by , and it is initialized to 0. |
Online decision-making procedure in every time step:
|
|
|
| Case | Controller Algorithm | Tower Agent Action | Pump Agent Action | Parameters | State | Reward |
|---|---|---|---|---|---|---|
| #1 | Baseline | 50 Hz | 50 Hz | / | / | / |
| #2 | PHC (Division) | 30–50 Hz | 35–50 Hz | α = 0.7 γ = 0.01 δ = 0.03 | Twet CLs | System COP |
| #3 | PHC (Multiplication) | Jointed actions such as (pump 50 Hz, tower 30 Hz) | ||||
| #4 | WoLF-PHC (Interaction) | 30–50 Hz | 35–50 Hz | |||
| #5 | PID feedback control | Approach at 2.5 °C | Condenser water ΔT at 3.3 °C | / | / | / |
| Cases | Total System Energy Consumption over One Cooling Season (kWh) | Energy-Saving Ratio Compared to Baseline (%) |
|---|---|---|
| #1 Baseline | 543,979 | 0.00 |
| #2 Division | 489,450 | 10.02 |
| #3 Multiplication | 496,869 | 8.66 |
| #4 Interaction | 488,621 | 10.18 |
| #5 PID feedback | 529,933 | 5.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, S.; Li, Z.; Li, Z.; Wu, Q. Comparative Evaluation of Different Multi-Agent Reinforcement Learning Mechanisms in Condenser Water System Control. Buildings 2022, 12, 1092. https://doi.org/10.3390/buildings12081092
Qiu S, Li Z, Li Z, Wu Q. Comparative Evaluation of Different Multi-Agent Reinforcement Learning Mechanisms in Condenser Water System Control. Buildings. 2022; 12(8):1092. https://doi.org/10.3390/buildings12081092
Chicago/Turabian StyleQiu, Shunian, Zhenhai Li, Zhengwei Li, and Qian Wu. 2022. "Comparative Evaluation of Different Multi-Agent Reinforcement Learning Mechanisms in Condenser Water System Control" Buildings 12, no. 8: 1092. https://doi.org/10.3390/buildings12081092