

Research on the Application and Performance Optimization of GPU Parallel Computing in Concrete Temperature Control Simulation


Abstract
:1. Introduction
2. Improved Analytical Formula for GPU Parallel Algorithms
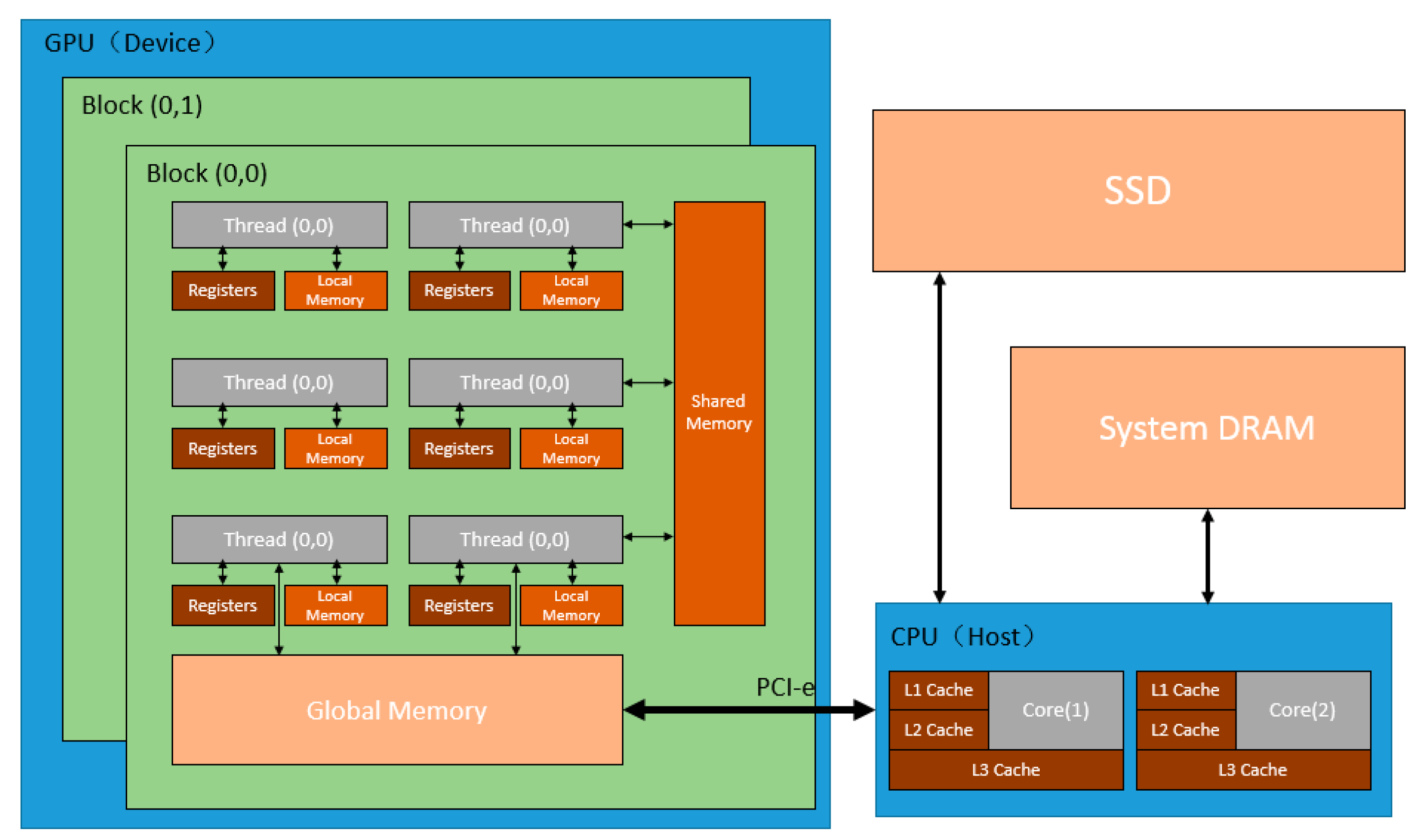
2.1. CUDA Fortran Parallel Experimental Platform
2.2. The Traditional Analytical Formula
2.3. Improved Analytical Formula
3. Research on GPU Memory Access Optimization by Using Shared Memory Results
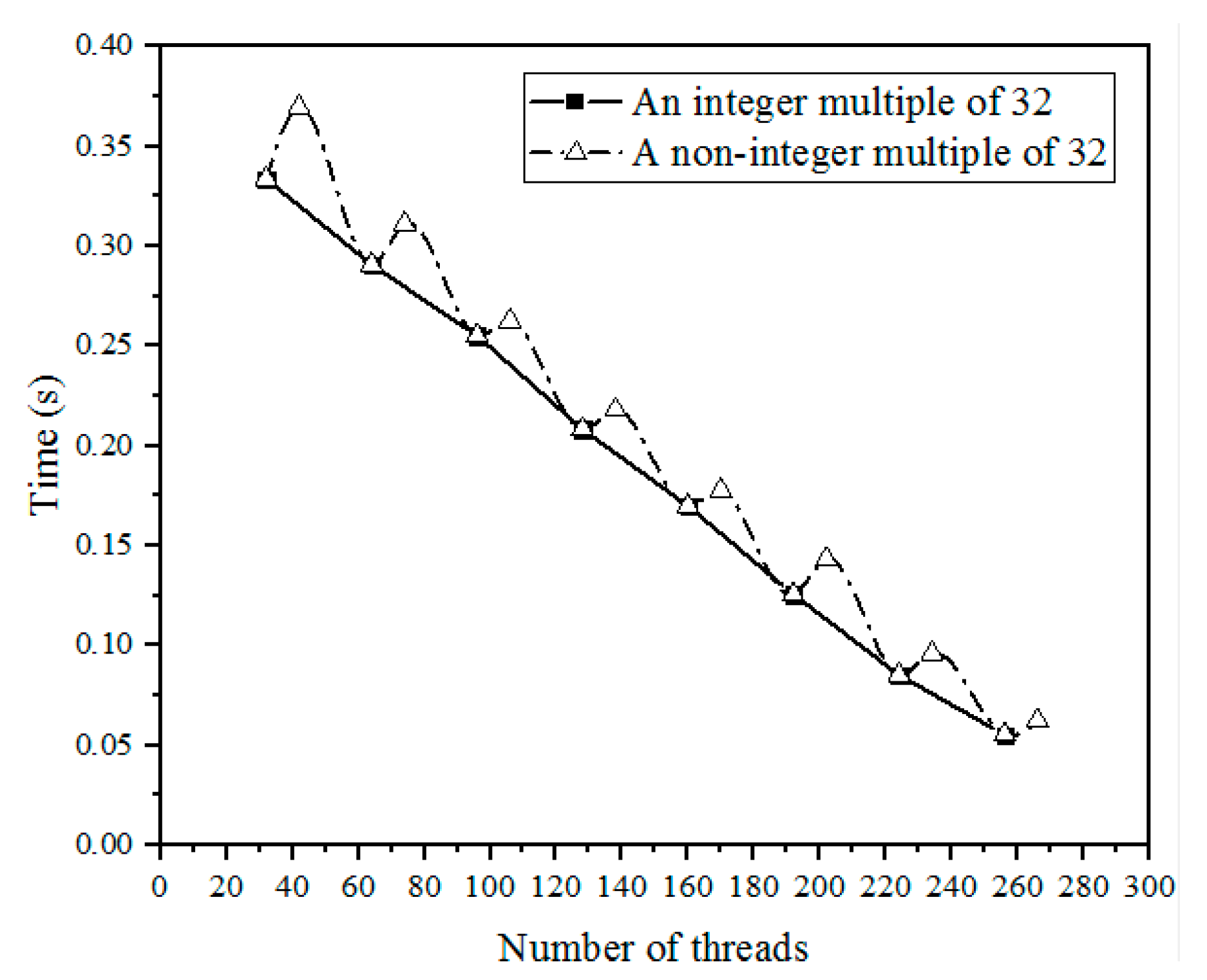
3.1. Selection of Kernel Execute Parameter
3.2. Features of Shared Memory
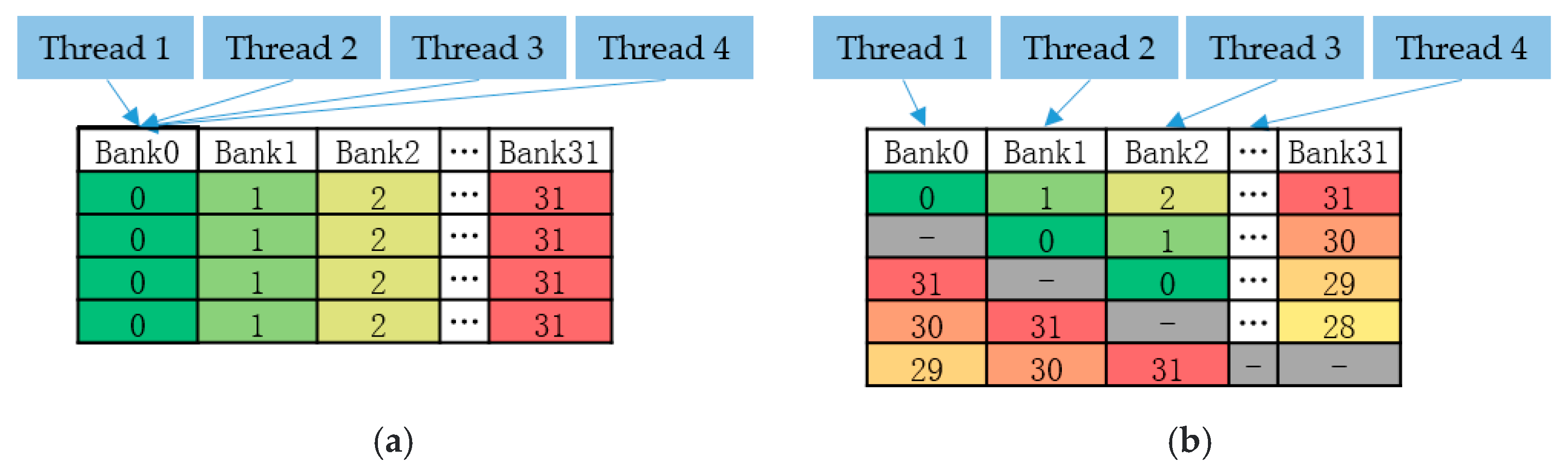
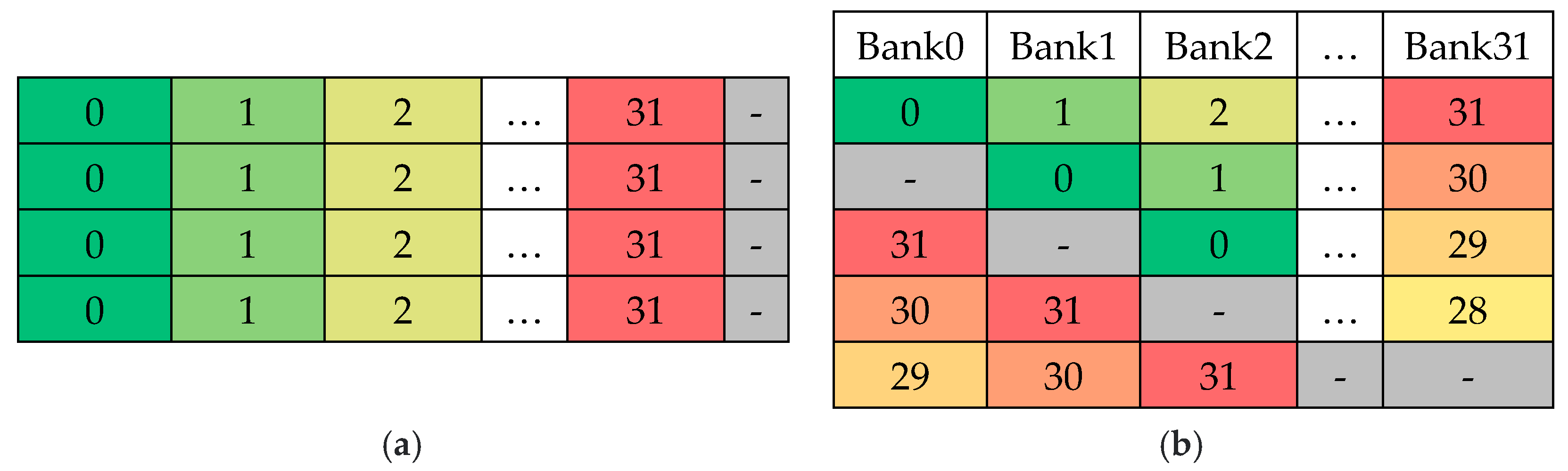
3.3. Research on Avoiding Bank Conflicts
| Listing 1. Code of shared memory. | |
| 1 2 3 4 5 6 7 8 9 | attributes (global) subroutine NoBF_Kernel (odata, idata ) real, intent (out)::odata (ny, nx) real, intent (in)::idata (nx, ny) … real, shared::tile (TILE_DIM, TILE_DIM) ! Before optimization real, shared::tile (TILE_DIM, TILE_DIM + 1) ! After optimization integer::x, y, j … end subroutine |
3.4. Time Consumption Analysis of Shared Memory
4. Research on Asynchronous Parallelism in GPU Computing
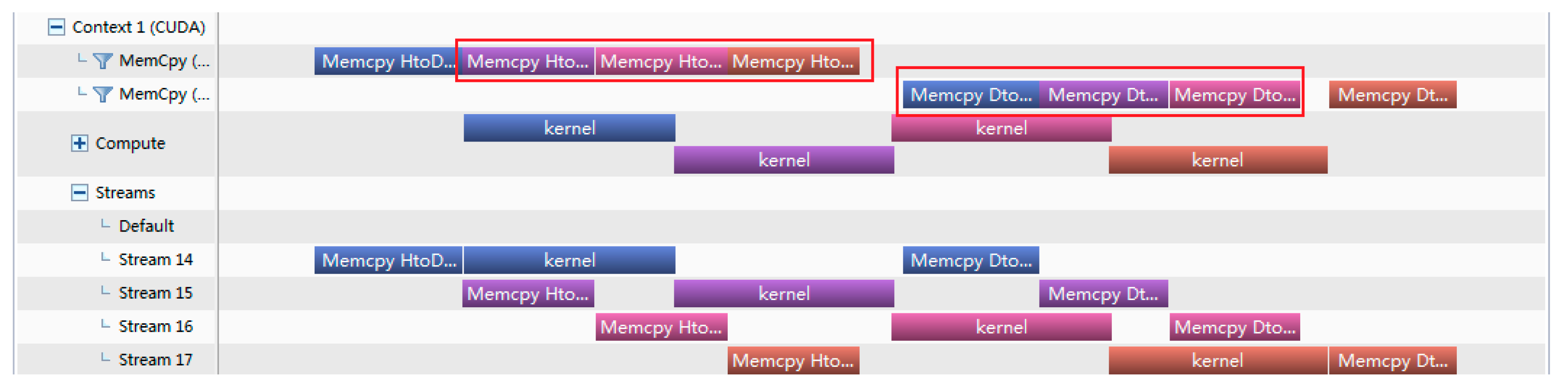
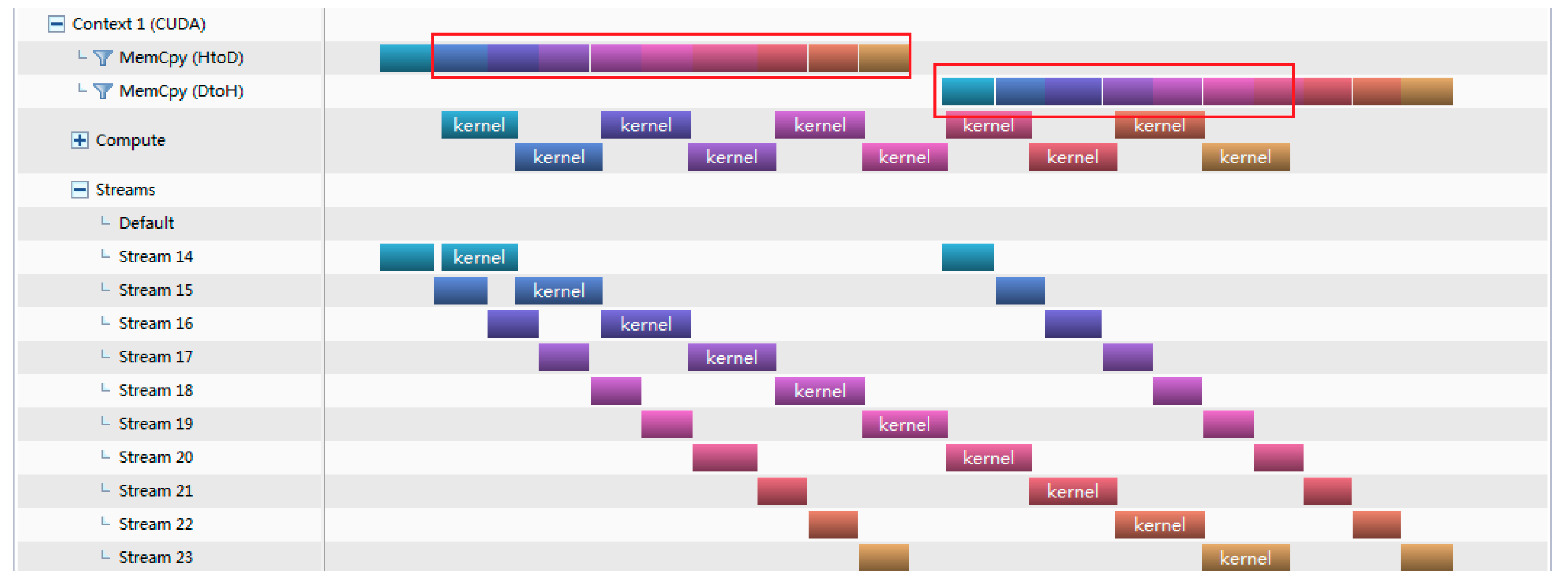
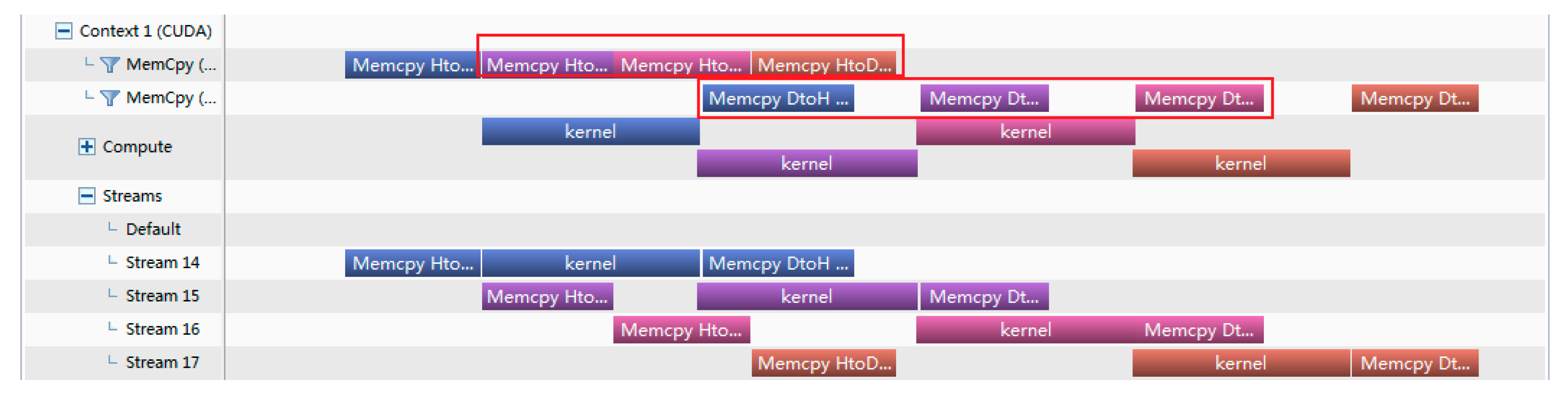
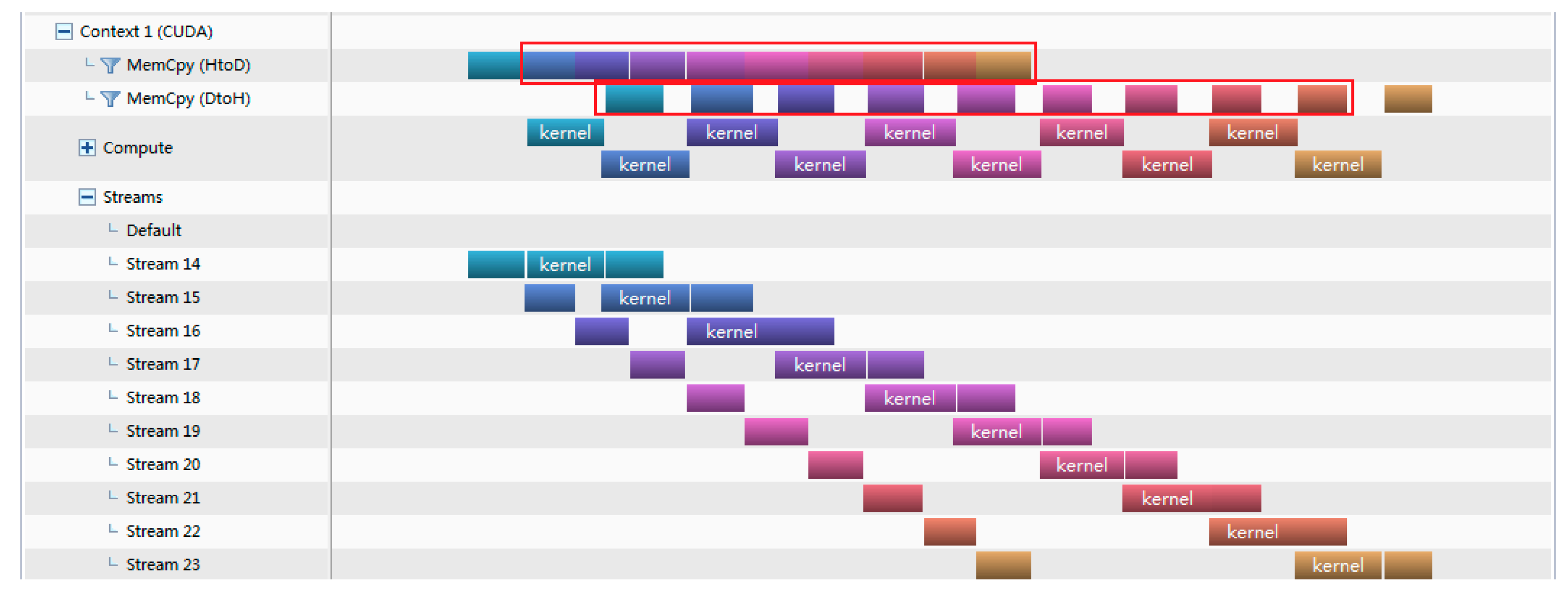
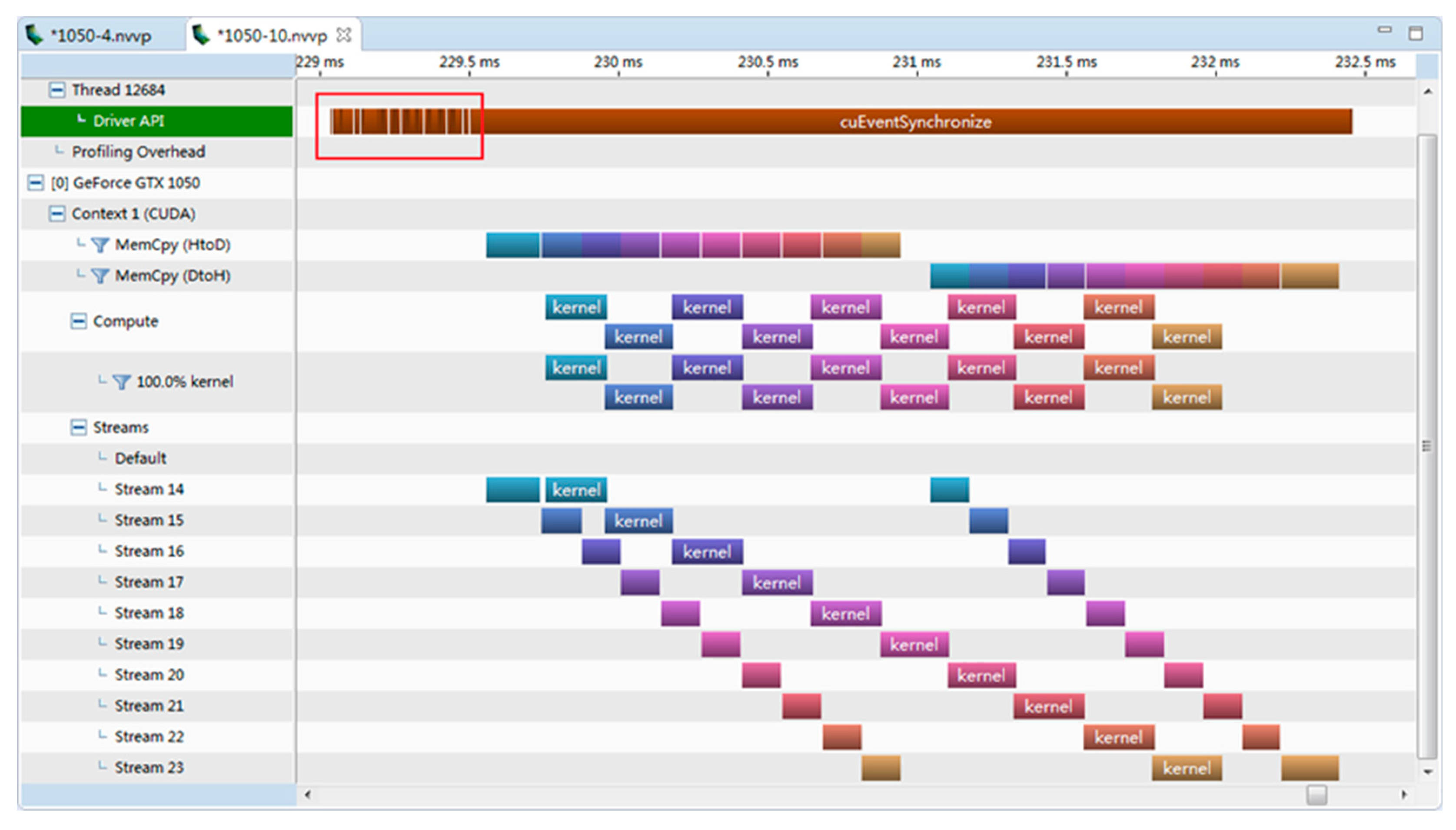
4.1. Comparison and Analysis of Different Asynchronous Parallel Methods
| Listing 2. Code of Version 1. | |
| 1 2 3 4 5 6 7 | !CPU Subroutine Call Function_1 (a) !GPU parallel Subroutine a_d = a call kernel <<<n/blockSize,blockSize>>>(a_d,0) a = a_d |
| Listing 3. Code of Version 2. | |
| 1 2 3 4 5 6 | do i = 1,nStreams offset = (i − 1)*streamSize istat = cudaMemcpyAsync(a_d(offset + 1),a(offset + 1),streamSize,stream(i)) call kernel <<<streamSize/blockSize,blockSize,0,stream(i)>>>(a_d,offset) istat = cudaMemcpyAsync(a(offset + 1),a_d(offset + 1),streamSize,stream(i)) end do |
| Listing 4. Code of Version 3. | |
| 1 2 3 4 5 6 7 8 9 10 11 12 | do i = 1,nStreams offset = (i − 1)* streamSize istat = cudaMemcpyAsync(a_d(offset + 1),a(offset + 1),streamSize,stream(i)) end do do i = 1,nStreams offset = (i − 1)* streamSize call kernel <<<streamSize/blockSize,blockSize,0,stream(i)>>>(a_d,offset) end do do i = 1,nStreams offset = (i − 1)* streamSize istat = cudaMemcpyAsync(a(offset+1),a_d(offset+1),streamSize,stream(i)) end do |
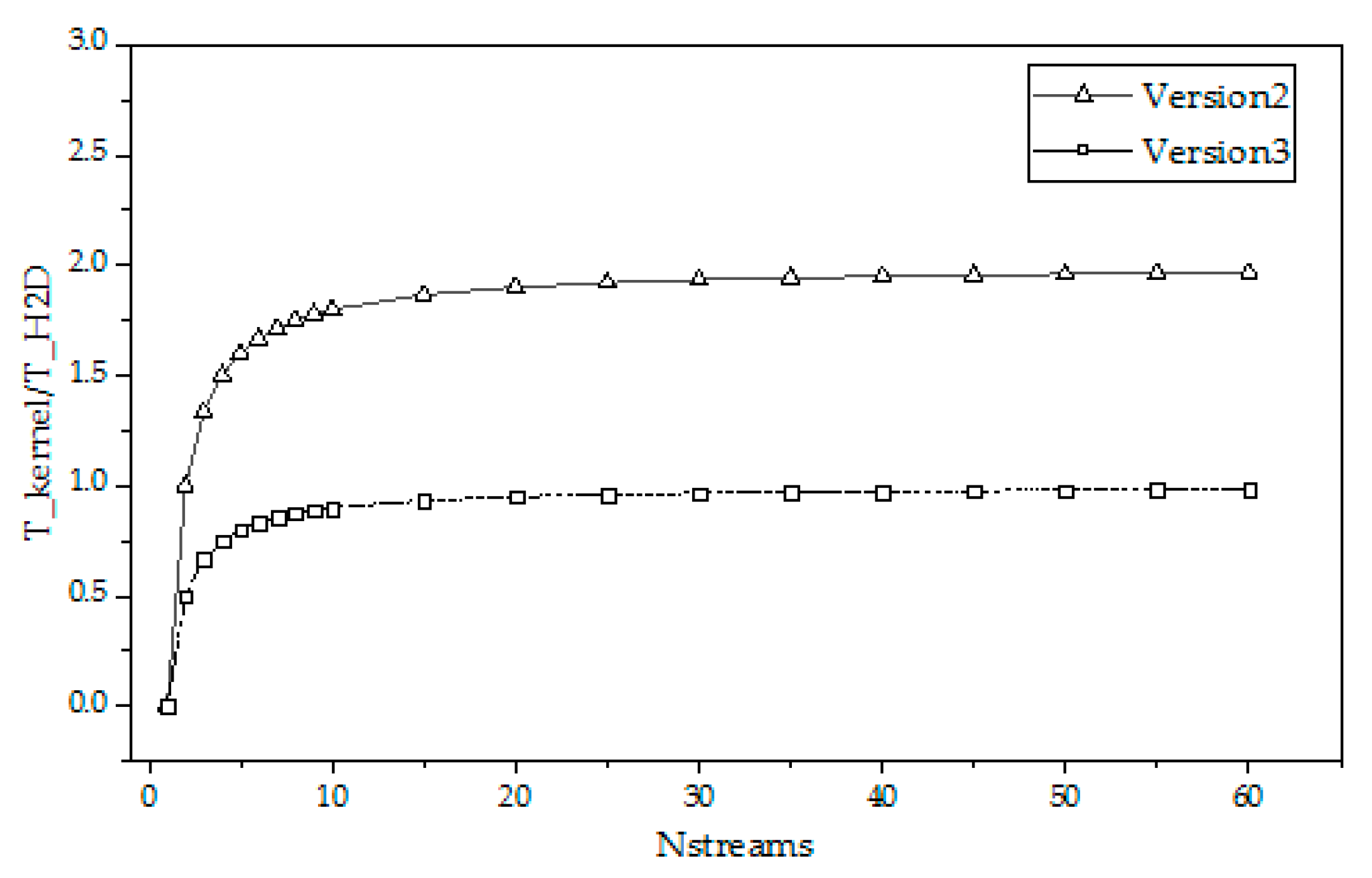
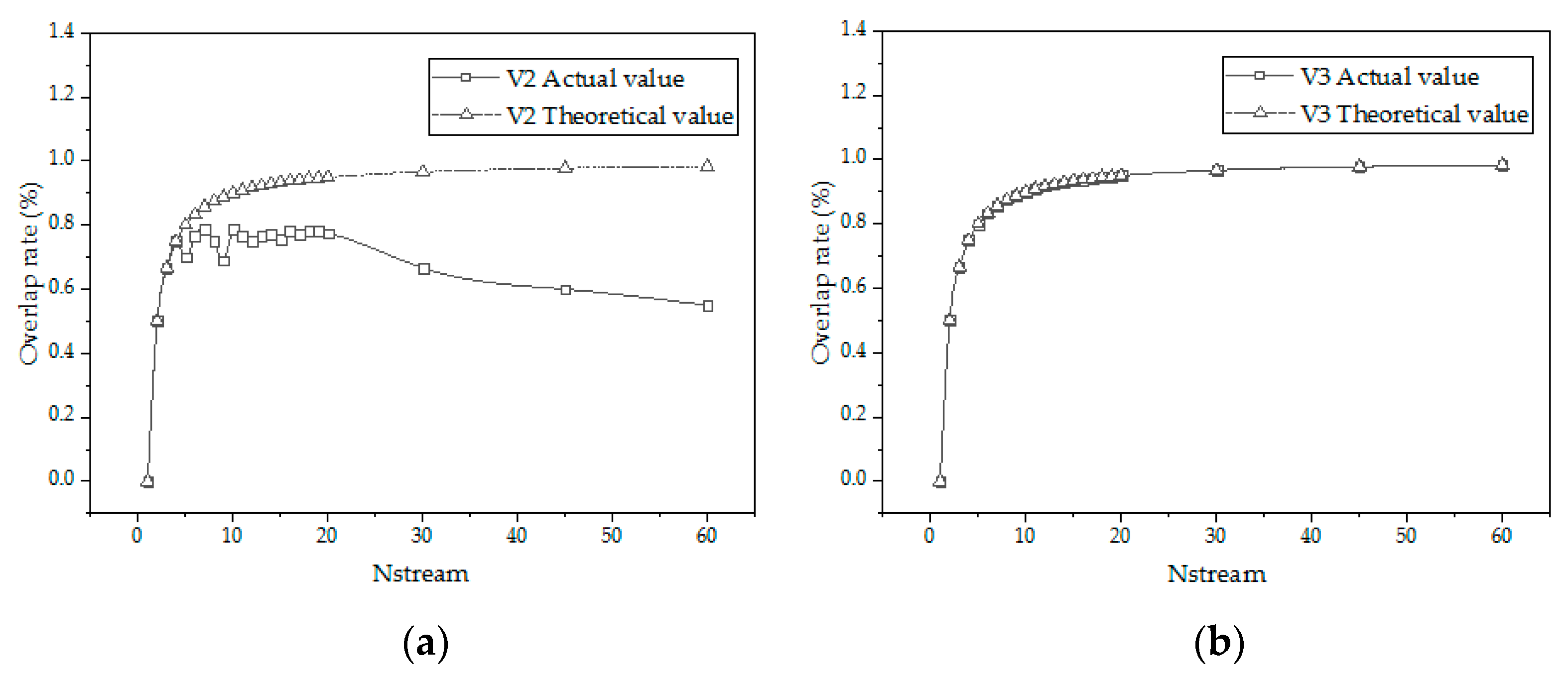
4.2. Overlap Rate Theory of Memcpy
- Overlap rate formula of Memcpy of version 2
- 2.
- Overlap rate formula of Memcpy of version 3
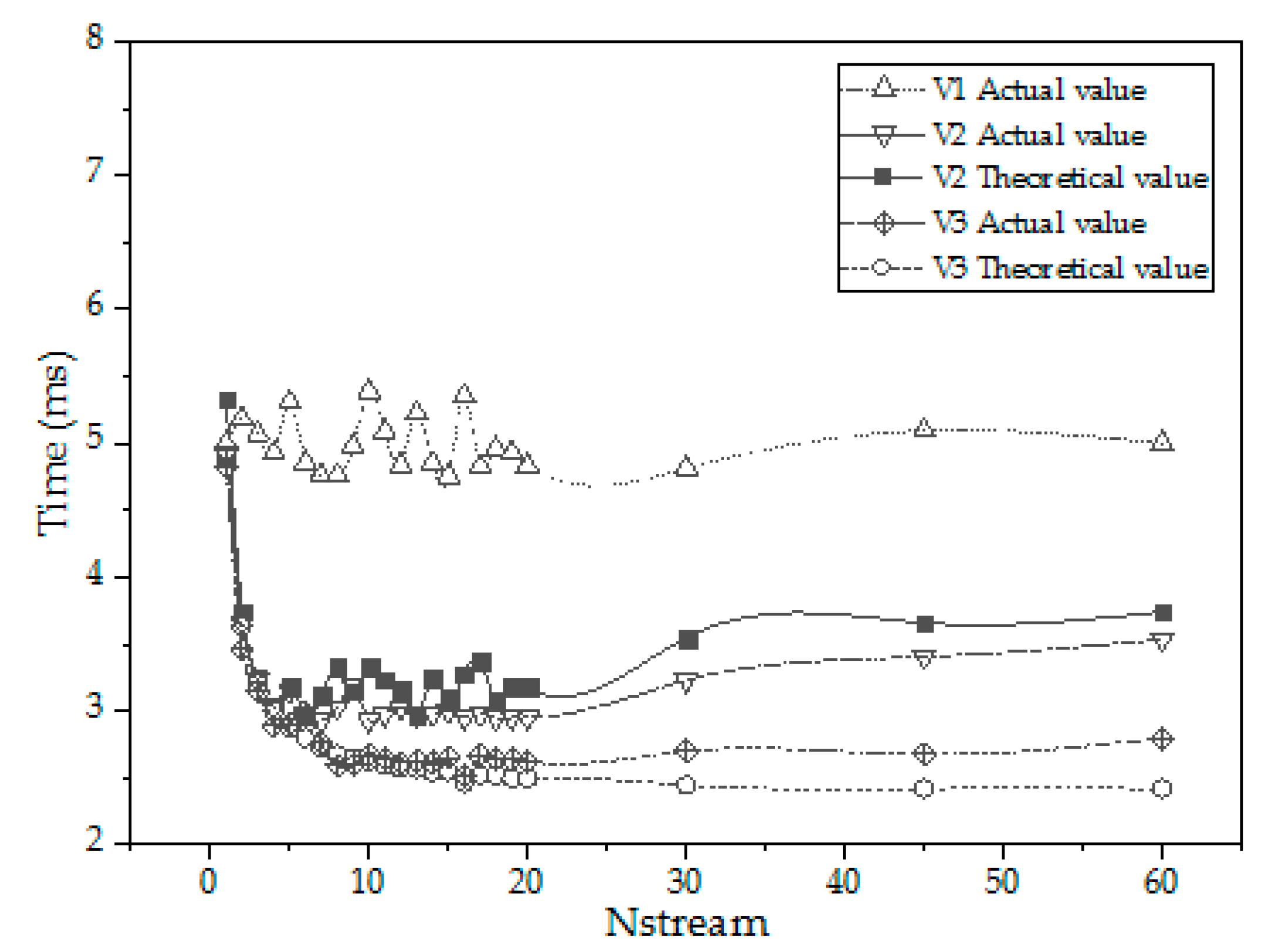
4.3. Analysis of Theoretical Operation Time and Practical Operation Time
4.4. Limitations of Parallel Algorithms
| Listing 5. Code of loop dependencies. | |
| 1 2 3 4 5 6 7 8 | do i = 1, n a(i) = a(i + 1) + c(i) end do do i = 1, n do j = 1, n a(i,j) = a(i + 1,j + 1) + c(j) end do end do |
5. Application of GPU Parallel Computing in Engineering
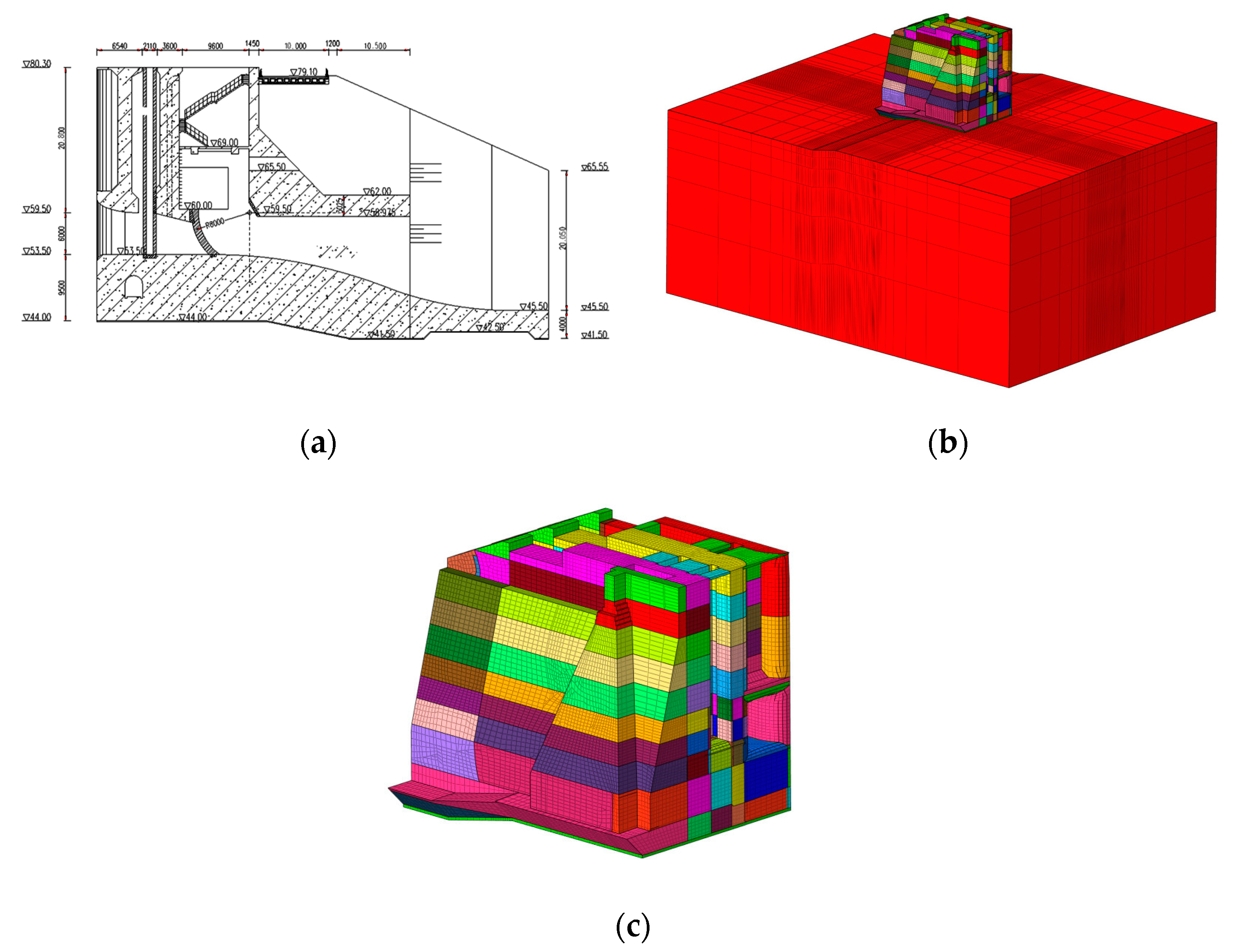
5.1. Simulation Calculation Model and Material Parameters
5.2. Experimental Platform Parameters
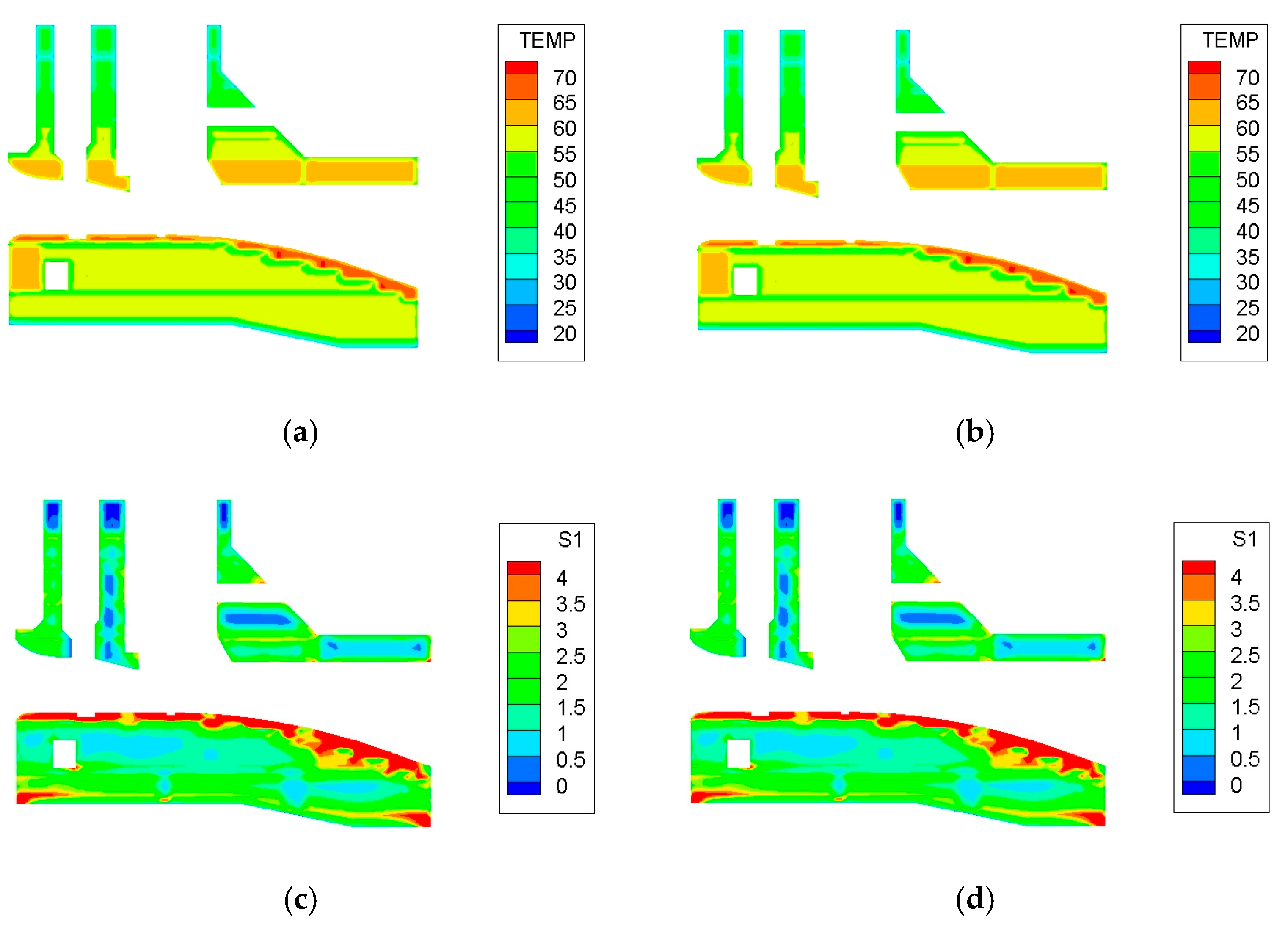
5.3. Comparison of Calculation Results
6. Conclusions
- From the improved analytical formula, GPU parallel programs should be optimized from the following aspects: Hardware level: replace the GPU with stronger performance to obtain more threads and higher clock rate. Algorithm level: modify the algorithm to increase the proportion of parallel operations, improve the running efficiency of kernel functions and overlap more data transmission time;
- The data access mode of parallel programs is optimized by using shared memory, and the problem of bank conflicts is further solved. For matrix transpose operations of finite element operations, 437.5× acceleration is achieved;
- This paper implements asynchronous parallelism on the GPU through CUDA streams, which can hide the time of data access. Overlap rate theory of Memcpy is proposed to guide the optimization of asynchronous parallel programs. For GPU kernel subroutines of matrix inner products, compared with ordinary GPU parallel programs that do not use asynchronous parallelism, it can achieve nearly twice the acceleration. Compared with serial programs, it can achieve 61.42× acceleration. Not all programs are suitable for parallelization and need to be analyzed on a case-by-case basis;
- The Fortran finite element program for temperature and stress fields of concrete is reconstructed and optimized in parallel. The GPU parallelization of the program plays a role in improving computational efficiency while ensuring the computational accuracy.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CUDA | Compute Unified Device Architecture |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| H2D | Host to Device |
| D2H | Device to Host |
| Dg/Db | Dim of Girde/ Dim of Block |
| Memcpy | Memory Copy |
References
- Aniskin, N.; Nguyen, T.C. Influence factors on the temperature field in a mass concrete. E3S Web Conf. 2019, 97, 05021. [Google Scholar] [CrossRef]
- Briffaut, M.; Benboudjema, F.; Torrenti, J.M. Numerical analysis of the thermal active restrained shrinkage ring test to study the early age behavior of massive concrete structures. Eng. Struct. 2011, 33, 1390–1401. [Google Scholar] [CrossRef]
- Silva, C.M.; Castro, L.M. Hybrid-mixed stress model for the nonlinear analysis of concrete structures. Comput. Struct. 2005, 83, 2381–2394. [Google Scholar] [CrossRef]
- Yuan, M.; Qiang, S.; Xu, Y. Research on Cracking Mechanism of Early-Age Restrained Concrete under High-Temperature and Low-Humidity Environment. Materials 2021, 14, 4084. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.B.; Qiang, S.; Sun, X. Dynamic Simulation Analysis of Temperature Field and Thermal Stress of Concrete Gravity Dam during Construction Period. Appl. Mech. Mater. 2011, 90–93, 2677–2681. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, Y.; Yang, P. Analysis on the causes of crack formation and the methods of temperature control and crack prevention during construction of super-high arch dams. J. Hydroelectr. Eng. 2010, 29, 45–51. [Google Scholar] [CrossRef]
- Yin, T.; Li, Q.; Hu, Y.; Yu, S.; Liang, G. Coupled Thermo-Hydro-Mechanical Analysis of Valley Narrowing Deformation of High Arch Dam: A Case Study of the Xiluodu Project in China. Appl. Sci. 2020, 10, 524. [Google Scholar] [CrossRef]
- Zheng, X.; Shen, Z.; Wang, Z.; Qiang, S.; Yuan, M. Improvement and Verification of One-Dimensional Numerical Algorithm for Reservoir Water Temperature at the Front of Dams. Appl. Sci. 2022, 12, 5870. [Google Scholar] [CrossRef]
- Chang, X.; Liu, X.; Wei, B. Temperature simulation of RCC gravity dam during construction considering solar radiation. Eng. J. Wuhan Univ. 2006, 39, 26–29. [Google Scholar] [CrossRef]
- Nishat, A.M.; Mohamad, S.J. Efficient CPU Core Usage and Balanced Bandwidth Distribution using Smart Adaptive Arbitration. Indian J. Sci. Technol. 2016, 9, S1. [Google Scholar] [CrossRef]
- Lastovetsky, A.; Manumachu, R.R. Energy-Efficient Parallel Computing: Challenges to Scaling. Information 2023, 14, 248. [Google Scholar] [CrossRef]
- Mao, R.J.; Huang, L.S.; Xu, D.J.; Chen, G.L. Joint optimization scheduling algorithm and parallel implementation of group Base in Middle and upper reaches of Huaihe River. Small Microcomput. Syst. 2000, 21, 5. [Google Scholar]
- Jia, M. Master-slave Parallel Mind Evolutionary Computation Based on MPI. J. North Univ. China Nat. Sci. Ed. 2007, 4, 66–69. [Google Scholar]
- Wu, W.; Wang, X. Multi-Core CPU Parallel Power Flow Computation in AC/DC System Considering DC Control. Electr. Power Compon. Syst. 2017, 45, 990–1000. [Google Scholar] [CrossRef]
- Bocci, A.; CMS Collaboration. CMS High Level Trigger performance comparison on CPUs and GPUs. J. Phys. Conf. Ser. 2023, 2438, 012016. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, L.; Guo, H.; Zheng, Y.; Ma, S.; Chen, Y. Inference-Optimized High-Performance Photoelectric Target Detection Based on GPU Framework. Photonics 2023, 10, 459. [Google Scholar] [CrossRef]
- Misbah, M.; Christopher, D.C.; Robert, B.R. Enabling Parallel Simulation of Large-Scale HPC Network Systems. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 87–100. [Google Scholar] [CrossRef]
- Xu, W.; Jia, M.; Guo, W.; Wang, W.; Zhang, B.; Liu, Z.; Jiang, J. GPU-based discrete element model of realistic non-convex aggregates: Mesoscopic insights into ITZ volume fraction and diffusivity of concrete. Cem. Concr. Res. 2023, 164, 107048. [Google Scholar] [CrossRef]
- Wang, J.; Kuang, C.; Ou, L.; Zhang, Q.; Qin, R.; Fan, J.; Zou, Q. A Simple Model for a Fast Forewarning System of Brown Tide in the Coastal Waters of Qinhuangdao in the Bohai Sea, China. Appl. Sci. 2022, 12, 6477. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, J.; Li, T. Dam-Break Flows: Comparison between Flow-3D, MIKE 3 FM, and Analytical Solutions with Experimental Data. Appl. Sci. 2018, 8, 2456. [Google Scholar] [CrossRef]
- Umeda, H.; Hanawa, T.; Shoji, M. Performance Benchmark of FMO Calculation with GPU-Accelerated Fock Matrix Preparation Routine. J. Comput. Chem. Jpn. 2015, 13, 323–324. [Google Scholar] [CrossRef]
- Umeda, H.; Hanawa, T.; Shoji, M. GPU-accelerated FMO Calculation with OpenFMO: Four-Center Inter-Fragment Coulomb Interaction. J. Comput. Chem. Jpn. 2015, 14, 69–70. [Google Scholar] [CrossRef]
- Mcgraw, T.; Nadar, M. Stochastic DT-MRI Connectivity Mapping on the GPU. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1504–1511. [Google Scholar] [CrossRef]
- Qin, A.; Xu, J.; Feng, Q. Fast 3D medical image rigid registration Technology based on GPU. Ication Res. Comput. 2010, 3, 1198–1200. [Google Scholar] [CrossRef]
- Ishida, J.; Aranami, K.; Kawano, K.; Matsubayashi, K.; Kitamura, Y.; Muroi, C. ASUCA: The JMA Operational Non-hydrostatic Model. J. Meteorol. Soc. Japan Ser. II 2022, 100, 825–846. [Google Scholar] [CrossRef]
- Liu, G.F.; Liu, Q.; Li, B.; Tong, X.L.; Liu, H. GPU/CPU co-processing parallel computation for seismic data processing in oil and gas exploration. Prog. Geophys. 2009, 24, 1671–1678. [Google Scholar] [CrossRef]
- Novalbos, M.; Gonzalez, J.; Otaduy, M.A.; Sanchez, A. On-Board Multi-GPU Molecular Dynamics. In Euro-Par 2013 Parallel Processing; Wolf, F., Mohr, B., Mey, D., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8097, pp. 862–873. [Google Scholar] [CrossRef]
- Liang, B.; Wang, S.; Huang, Y.; Liu, Y.; Ma, L. F-LSTM: FPGA-Based Heterogeneous Computing Framework for Deploying LSTM-Based Algorithms. Electronics 2023, 12, 1139. [Google Scholar] [CrossRef]
- Wen, C.; Ou, J.; Jinyuan, A.J. GPGPU-based Smoothed Particle Hydrodynamic Fluid Simulation. J. Comput.-Aided Des. Comput. Graph. 2010, 22, 406–411. [Google Scholar] [CrossRef]
- Lin, S.Z.; Zhi, Q. A Jacobi_PCG solver for sparse linear systems on multi-GPU cluster. J. Supercomput. 2016, 73, 433–454. [Google Scholar] [CrossRef]
- Kalita, J.C.; Upadhyaya, P.; Gupta, M.M. GPU accelerated flow computation by the streamfunction-velocity (ψ-ν) formulation. In AIP Conference Proceedings; AIP Publishing: Melville, NY, USA, 2015; Volume 1648. [Google Scholar] [CrossRef]
- Thi, K.T.; Huong, N.T.M.; Huy, N.D.Q.; Tai, P.A.; Hong, S.; Quan, T.M.; Bay, N.T.; Jeong, W.-K.; Phung, N.K. Assessment of the Impact of Sand Mining on Bottom Morphology in the Mekong River in An Giang Province, Vietnam, Using a Hydro-Morphological Model with GPU Computing. Water 2020, 12, 2912. [Google Scholar] [CrossRef]
- Nesti, A.; Mediero, L.; Garrote, L. Probabilistic calibration of the distributed hydrological model RIBS ied to real-time flood forecasting: The Harod river basin case study (Israel). Egu General Assembly 2010, 12, 8028. [Google Scholar] [CrossRef]
- Schneider, R.; Lewerentz, L.; Lüskow, K.; Marschall, M.; Kemnitz, S. Statistical Analysis of Table-Tennis Ball Trajectories. Appl. Sci. 2018, 8, 2595. [Google Scholar] [CrossRef]
- Lee, T.L. Prediction of Storm Surge and Surge Deviation Using a Neural Network. J. Coast. Res. 2008, 24, 76–82. [Google Scholar] [CrossRef]
- Fonseca, R.B.; Gonçalves, M.; Guedes Soares, C. Comparing the Performance of Spectral Wave Models for Coastal Areas. J. Coast. Res. 2017, 33, 331–346. [Google Scholar] [CrossRef]
- Ganesh, R.; Gopaul, N. A predictive outlook of coastal erosion on a log-spiral bay (trinidad) by wave and sediment transport modelling. J. Coast. Res. 2013, 65, 488–493. [Google Scholar] [CrossRef]
- Zhu, Z.Y.; Qiang, S.; Liu, M.Z. Cracking Mechanism of RCC Dam Surface and Prevention Method. Adv. Mater. Res. 2011, 295–297, 2092–2096. [Google Scholar] [CrossRef]
- Zakonnova, A.V.; Litvinov, A.S. Analysis of Relation of Water Temperature in the Rubinsk Reservoir with Income of Solar Radiation. Hydrobiol. J. 2017, 53, 77–86. [Google Scholar] [CrossRef]
- Windisch, D.; Kaever, C.; Juckeland, G.; Bieberle, A. Parallel Algorithm for Connected-Component Analysis Using CUDA. Algorithms 2023, 16, 80. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | GPU | Compute Capability | Total Global (MiB) | Bus Width | Clock Rate | Processors | SM | Memory Copy | Rate (Gib/s) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | GTX1050 | 6.1 | 2048 | 128 bits | 1455 MHz | 640 | 5 | H2D | 11.33 |
| D2H | 11.32 | ||||||||
| 2 | GTX1070 | 6.1 | 4096 | 256 bits | 1759 MHz | 1920 | 15 | H2D | 11.96 |
| D2H | 11.73 | ||||||||
| 3 | RTX3080 | 8.6 | 4096 | 256 bits | 1770 MHz | 8960 | 70 | H2D | 23.97 |
| D2H | 23.71 |
| Blocks | Threads/Block | Bandwidth (GB/s) | Blocks | Threads/Block | Bandwidth (GB/s) |
|---|---|---|---|---|---|
| 64 | 32 | 67.52 | 8 | 256 | 90.83 |
| 32 | 64 | 87.69 | 4 | 512 | 89.23 |
| 16 | 128 | 89.76 | 2 | 1024 | 79.32 |
| Memory | Sphere of Action | Life Cycle | Speed Ordering | Control |
|---|---|---|---|---|
| Register | Thread | kernel | 1 | System |
| L1/L2 Cache | SM | kernel | 2 | System |
| Shared Memory | Block | kernel | 2 | User |
| Local Memory | Thread | kernel | 2 | User |
| Global Memory | Gride | Program | 3 | User |
| Graphics Card | Version | ||||
|---|---|---|---|---|---|
| Replication | Replication (Shared Memory) | Transposition | Transposition (Shared Memory) | Transposition (Non-Bank Conflict) | |
| Time (ms) | |||||
| Inteli7-6700 | 4974.03 | - | - | - | - |
| GTX 1050 | 91.23 | 88.31 | 336.38 | 180.26 | 89.24 |
| GTX 1070 | 44.86 | 42.12 | 102.37 | 54.29 | 41.64 |
| RTX 3080 | 12.61 | 11.41 | 40.93 | 16.04 | 11.37 |
| Accelerate rate | |||||
| GTX 1050 | 54.52 | 56.32 | 14.79 | 27.59 | 55.74 |
| GTX 1070 | 110.88 | 118.09 | 48.59 | 91.62 | 119.45 |
| RTX 3080 | 394.45 | 435.94 | 121.53 | 310.10 | 437.47 |
| Bandwidth (GB/s) | |||||
| GTX 1050 | 85.64 | 88.47 | 23.23 | 43.34 | 87.54 |
| GTX 1070 | 174.39 | 185.45 | 76.31 | 143.93 | 187.61 |
| RTX 3080 | 619.62 | 864.82 | 190.89 | 487.07 | 687.09 |
| Version | Time (ms) | Accelerate Rate | Cumulative Accelerate Rate |
|---|---|---|---|
| Serial | 148.63 | 1 | 1 |
| V1 | 4.83 | 30.77 | 30.77 |
| V2 | 2.92 | 1.65 | 50.90 |
| V3 | 2.42 | 2.00 | 61.42 |
| Category | Thermal Convection (kJ/m·h °C) | Specific Heat (kJ/(kg·°C)) | Thermal Diffusivity (m2/h) | Linear Expansion Coefficient (×10−6/°C) | Poisson Ratio | Density (kg/m3) | Final Elasticity Modulus (GPa) | Final Value of Autogenous Volume Deformation (×10−6) | Final Value of Adiabatic Temperature Rise (°C) |
|---|---|---|---|---|---|---|---|---|---|
| BASE | 13.62 | 0.716 | 0.0076 | 8.0 | 0.240 | 2500 | 35.5 | — | — |
| C15 | 3.32 | 1.290 | 0.0011 | 8.0 | 0.167 | 2305 | 22.0 | 50 | 30.0 |
| C30 | 4.13 | 0.989 | 0.0017 | 8.7 | 0.167 | 2329 | 30.0 | 100 | 54.5 |
| C35 | 4.43 | 0.958 | 0.0019 | 9.0 | 0.167 | 2340 | 35.0 | 107 | 61.0 |
| Operating System | Processor | Primary Frequency | Number of Cores | SM | Memory | Memory Copy (GiB/s) | |
|---|---|---|---|---|---|---|---|
| H2D | D2H | ||||||
| Windows10-64 bit | Intel i7-12700K | 3.6 GHz | 20 | - | 16 G | - | |
| RTX3080 | 1.73 GHz | 8960 | 70 | 10 G | 23.97 | 23.71 | |
| Compiling Environment | Visual Studio 2010 | https://learn.microsoft.com/ | |||||
| Compiler | PGI Visual Fortran | https://www.pgroup.com/index.htm | |||||
| Tool Kit | CUDA Toolkit 10.0 | https://developer.nvidia.com/ | |||||
| cuDNN | https://developer.nvidia.com/rdp | ||||||
| Type of Computation | Computing Time (s) | Accelerate Rate |
|---|---|---|
| CPU serial | 7693 | — |
| CPU parallel | 5107 | 1.51 |
| GPU parallel | 2741 | 2.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Jin, J.; Wang, Y.; Yuan, M.; Qiang, S. Research on the Application and Performance Optimization of GPU Parallel Computing in Concrete Temperature Control Simulation. Buildings 2023, 13, 2657. https://doi.org/10.3390/buildings13102657
Zheng X, Jin J, Wang Y, Yuan M, Qiang S. Research on the Application and Performance Optimization of GPU Parallel Computing in Concrete Temperature Control Simulation. Buildings. 2023; 13(10):2657. https://doi.org/10.3390/buildings13102657
Chicago/Turabian StyleZheng, Xuerui, Jiping Jin, Yajun Wang, Min Yuan, and Sheng Qiang. 2023. "Research on the Application and Performance Optimization of GPU Parallel Computing in Concrete Temperature Control Simulation" Buildings 13, no. 10: 2657. https://doi.org/10.3390/buildings13102657
APA StyleZheng, X., Jin, J., Wang, Y., Yuan, M., & Qiang, S. (2023). Research on the Application and Performance Optimization of GPU Parallel Computing in Concrete Temperature Control Simulation. Buildings, 13(10), 2657. https://doi.org/10.3390/buildings13102657