
Indoor Temperature Control of Radiant Ceiling Cooling System Based on Deep Reinforcement Learning Method


 ,
, 
Abstract
:1. Introduction
2. Literature Review
3. Methodology
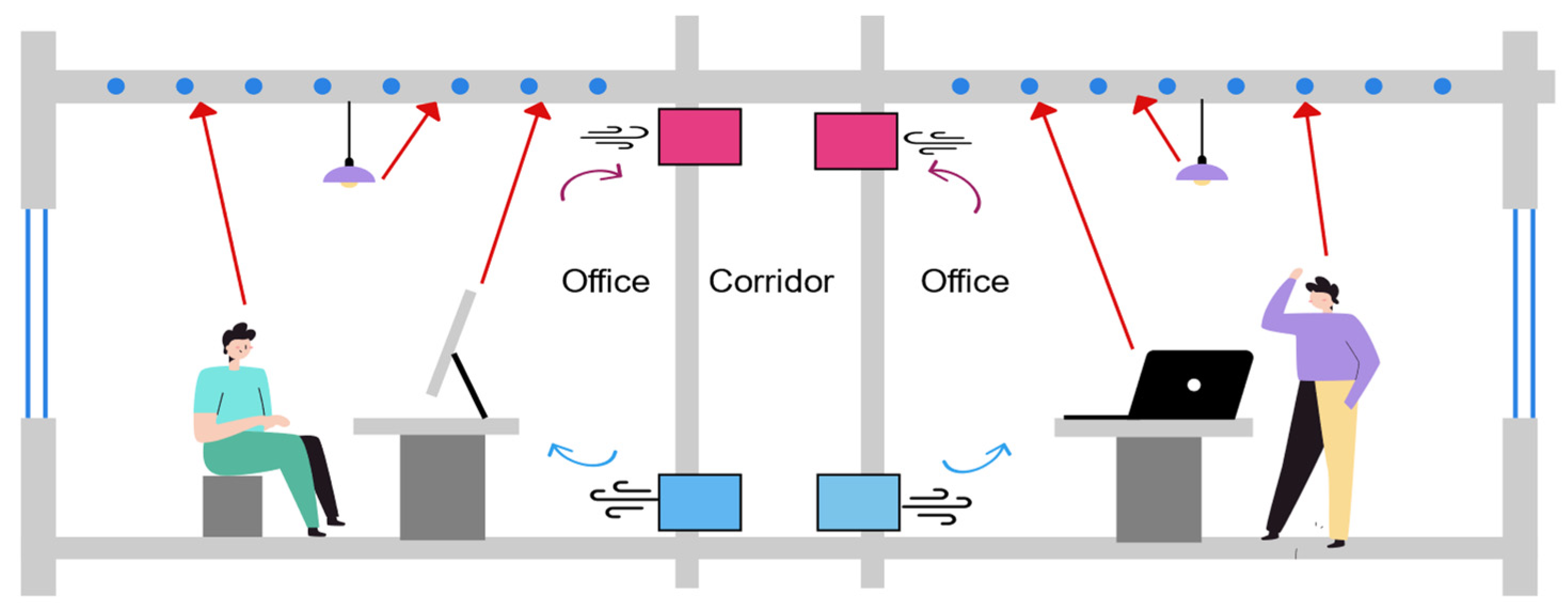
3.1. Overview
3.1.1. Simulation Environment
3.1.2. Control Methods
3.2. Physical Model of Room
3.2.1. Meteorological Data
3.2.2. Room Structure
3.2.3. Room Cooling Load
3.2.4. Radiant Panel Selection
3.3. Simulation Modeling of Traditional Control Models
3.3.1. Traditional on–off Control Model of Radiant Ceiling Cooling System
3.3.2. PID Variable Water Temperature Control Model of Radiant Ceiling Cooling System
4. Simulation Modeling of DRL Control Model
4.1. DRL Control Model of Radiant Ceiling Cooling System
4.2. Reinforcement Learning (RL) Process
4.3. Deep Learning (DL) Process
4.4. DRL Control Model Algorithm Design
- Initialize all parameters of Q network ω, Target Q* network ω* = ω, and Random-based ω. Initialize states and actions and corresponding q-value. Clear the experience playback collection M.
- Ensure the normal connection between the algorithm model and the environment, and reset the environment to the initial state.
- When the communication connection was smooth and the environment was running normally, carry out the iteration.
- (1)
- Obtain the current state quantity of environment initialization, and conduct preliminary processing to obtain the characteristic state parameter S.
- (2)
- In the Q network, take S as the input to obtain the action output of all corresponding q-values of the Q network, and the ε Greedy algorithm or ‘softmax’ selected the corresponding action ‘a’ from the current q-value (the ‘softmax’ function performed well in the simulation).
- (3)
- Execute the action ‘a’ in the current state St, and obtain the processed characteristic state vector St+1 of the new environment state and the reward r of this action.
- (4)
- Put tuples (St, a, St+1, r) into experience replay storage set M.
- (5)
- Assignment: St = St+1.
- (6)
- Randomly select n samples from the experience replay set M, and calculate the target q-value of these samples to update the Q-value estimation network.
- (7)
- (8)
- The weight value ω was modified by the loss function
5. Results
5.1. Comparison of DRL on–off with Traditional on–off Control Method
5.2. Comparison of DRL Variable Water Temperature with PID Variable Water Temperature Control Method
6. Discussion
6.1. Performance of the DRL Method
6.2. Analysis of the DRL Method
7. Summary and Future Work
7.1. Summary
7.2. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- China Association of Building Energy Efficiency. China Building Energy Consumption Research Report 2020. J. Build. Energy Effic. 2021, 49, 30–39. (In Chinese) [Google Scholar]
- Department of Energy. Buildings Energy Data Book. 2011. Available online: https://ieer.org/wp/wp-content/uploads/2012/03/DOE-2011-Buildings-Energy-DataBook-BEDB.pdf (accessed on 20 April 2021).
- EIA. Energy Consumption Survey (CBECS). 2012. Available online: http://www.eia.gov/tools/faqs/faq.cfm?id=86&t=1 (accessed on 10 April 2021).
- Oyedepo, S.O.; Fakeye, B.A. Waste heat recovery technologies: Pathway to sustainable energy development. J. Therm. Eng. 2021, 7, 324–348. [Google Scholar] [CrossRef]
- Afram, A.; Janabi-Sharifi, F. Theory and Applications of HVAC Control Systems–A Review of Model Predictive Control (MPC). Build. Environ. 2014, 72, 343–355. [Google Scholar] [CrossRef]
- Cho, S.-H.; Zaheer-Uddin, M. An Experimental Study of Multiple Parameter Switching Control for Radiant Floor Heating Systems. Energy 1999, 24, 433–444. [Google Scholar] [CrossRef]
- Song, D.; Kim, T.; Song, S.; Hwang, S.; Leigh, S.B. Performance Evaluation of a Radiant Floor Cooling System Integrated with Dehumidified Ventilation. Appl. Therm. Eng. 2008, 28, 1299–1311. [Google Scholar] [CrossRef]
- Meng, Z.Y.; Yu, G.Q.; Jin, R. Design of PID Temperature Control System Based on BP Neural Network. Appl. Mech. Mater. 2014, 602–605, 1244–1247. [Google Scholar] [CrossRef]
- Jin, A.; Wu, H.; Zhu, H.; Hua, H.; Hu, Y. Design of Temperature Control System for Infant Radiant Warmer Based on Kalman Filter-fuzzy PID. J. Phys. Conf. Ser. 2020, 1684, 12140. [Google Scholar] [CrossRef]
- Zhao, J.; Shi, L.; Li, J.; Li, H.; Han, Q. A Model Predictive Control Regulation Model for Radiant Air Conditioning System Based on Delay Time. J. Build. Eng. 2022, 62, 105343. [Google Scholar] [CrossRef]
- Zhang, D.; Huang, X.; Gao, D.; Cui, X.; Cai, N. Experimental Study on Control Performance Comparison between Model Predictive Control and Proportion-integral-derivative Control for Radiant Ceiling Cooling Integrated with Underfloor Ventilation System. Appl. Therm. Eng. 2018, 143, 130–136. [Google Scholar] [CrossRef]
- Dong, B.; Lam, K.P. A real-time model predictive control for building heating and cooling systems based on the occupancy behavior pattern detection and local weather forecasting. Build. Simul. 2014, 7, 89–106. [Google Scholar] [CrossRef]
- Pang, X.; Duarte, C.; Haves, P.; Chuang, F. Testing and Demonstration of Model Predictive Control Applied to a Radiant Slab Cooling System in a Building Test Facility. Energy Build. 2018, 172, 432–441. [Google Scholar] [CrossRef]
- Joe, J.; Karava, P. A Model Predictive Control Strategy to Optimize the Performance of Radiant Floor Heating and Cooling Systems in Office Buildings. Appl. Energy 2019, 245, 65–77. [Google Scholar] [CrossRef]
- Chen, Q.; Li, N. Model Predictive Control for Energy-efficient Optimization of Radiant Ceiling Cooling Systems. Build. Environ. 2021, 205, 108272. [Google Scholar] [CrossRef]
- Liu, Q.; Zhai, J.; Zhang, Z.; Zhong, S.; Zhou, Q.; Zhang, P.; Xu, J. A summary of deep reinforcement learning. J. Comput. Sci. 2018, 41, 1–27. (In Chinese) [Google Scholar]
- Albert, B.; May, M.; Zadrozny, B.; Gavalda, R.; Pedreschi, D.; Bonchi, F.; Cardoso, J.; Spiliopoulou, M. Autonomous HVAC Control, A Reinforcement Learning Approach. In Machine Learning and Knowledge Discovery in Databases; Lecture Notes in Computer Science; Springer International AG: Cham, Switzerland, 2015; Volume 9286, pp. 3–19. [Google Scholar]
- Li, B.; Xia, L. A Multi-grid Reinforcement Learning Method for Energy Conservation and Comfort of HVAC in Buildings. In Proceedings of the 2015 IEEE International Conference on Automation Science and Engineering (CASE), Gothenburg, Sweden, 24–28 August 2015; pp. 444–449. [Google Scholar]
- Zenger, A.; Schmidt, J.; Krödel, M. Towards the Intelligent Home: Using Reinforcement-Learning for Optimal Heating Control. In KI 2013: Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2013; pp. 304–307. [Google Scholar]
- Zhang, Z.; Chong, A.; Pan, Y. A Deep Reinforcement Learning Approach to Using Whole Building Energy Model for HVAC Optimal Control. In Proceedings of the 2018 Building Performance Modeling Conference, Chicago, IL, USA, 26–28 September 2018. [Google Scholar]
- Wei, T.; Wang, Y.; Zhu, Q. Deep Reinforcement Learning for Building HVAC Control. In Proceedings of the 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017. [Google Scholar]
- Blad, C.; Koch, S.; Ganeswarathas, S.; Kallesøe, C.S.; Bøgh, S. Control of HVAC-systems with Slow Thermodynamic Using Reinforcement Learning–ScienceDirect. In Proceedings of the 29th International Conference on Flexible Automation and Intelligent Manufacturing (FAIM2019), Limerick, Ireland, 24–28 June 2019. [Google Scholar]
- Ding, Z.; Pan, Y.; Xie, J.; Wang, W.; Huang, Z. Application of reinforcement learning algorithm in air-conditioning system operation optimization. J. Build. Energy Effic. 2020, 48, 14–20. (In Chinese) [Google Scholar]
- GB 55015-2021; General Code for Energy Efficiency and Renewable Energy Application in Buildings. National Standard of China; China Architecture & Building Press: Beijing, China, 2021.
- GB 50189-2015; Design Standard for Energy Efficiency of Public Buildings. National Standard of China; China Architecture & Building Press: Beijing, China, 2015.
- Gao, G.; Li, J.; Wen, Y. DeepComfort: Energy-Efficient Thermal Comfort Control in Buildings Via Reinforcement Learning. IEEE Internet Things J. 2020, 7, 8472–8484. [Google Scholar] [CrossRef]
- Jiang, Z.; Risbeck, M.J.; Ramamurti, V.; Murugesan, S.; Amores, J.; Zhang, C.; Lee, Y.M.; Drees, K.H. Building HVAC control with reinforcement learning for reduction of energy cost and demand charge. Energy Build. 2021, 239, 110833. [Google Scholar] [CrossRef]
- Liu, L.; Fu, L.; Jiang, Y. An On-off Regulation Method by Predicting the Valve On-time Ratio in District Heating System. Build. Simul. 2015, 8, 665–672. [Google Scholar] [CrossRef]
- Janprom, K.; Permpoonsinsup, W.; Wangnipparnto, S. Intelligent Tuning of PID Using Metaheuristic Optimization for Temperature and Relative Humidity Control of Comfortable Rooms. J. Control Sci. Eng. 2020, 2020, 2596549. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | External Wall HTC (W/(m2·K)) | External Window HTC (W/(m2·K)) | External Window SHGC |
|---|---|---|---|
| Beijing | 0.485 | 1.51 | 0.37 |
| Shanghai | 0.745 | 2.14 | 0.23 |
| Guangzhou | 1.346 | 2.36 | 0.29 |
| Region | Room Orientation | Room Area (m2) | Cooling Load (W) | Time of Cooling Load (h) | Cooling Load per Area (W/m2) |
|---|---|---|---|---|---|
| Beijing | South-facing | 18.8 | 1286.3 | 6422 | 68.3 |
| North-facing | 18.8 | 973.5 | 4816 | 51.8 | |
| Shanghai | South-facing | 18.8 | 1061.5 | 5990 | 56.5 |
| North-facing | 18.8 | 980.8 | 5128 | 52.2 | |
| Guangzhou | South-facing | 18.8 | 1104.1 | 6255 | 58.7 |
| North-facing | 18.8 | 1054.8 | 4600 | 56.1 |
| Region | Room Orientation | Cooling Load (W) | Inlet Water Temperature (°C) | Water Flow Rate (kg/h) | Pipe Space (mm) | Pipe Diameter (mm) | Average Water Temperature (°C) | Cooling Capacity (W) | Laying Area (m2) | Laying Percentage (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| Beijing | South-facing | 1163.3 | 17 | 450 | 100 | 20 | 18 | 1174.5 | 14.5 | 77.1 |
| North-facing | 850.5 | 17 | 350 | 100 | 20 | 18 | 866.7 | 10.7 | 56.9 | |
| Shanghai | South-facing | 938.5 | 17 | 450 | 100 | 20 | 18 | 939.6 | 11.6 | 61.7 |
| North-facing | 857.8 | 17 | 350 | 100 | 20 | 18 | 858.6 | 10.6 | 56.4 | |
| Guangzhou | South-facing | 981.1 | 17 | 450 | 100 | 20 | 18 | 996.3 | 12.3 | 65.4 |
| North-facing | 931.8 | 17 | 350 | 100 | 20 | 18 | 947.7 | 11.7 | 62.2 |
| Region | Room Orientation | Proportionality Coefficient | Integration Time/min | Differential Time/min |
|---|---|---|---|---|
| Beijing | South-facing | 4.0 | 40 | 5 |
| North-facing | 4.0 | 35 | 5 | |
| Shanghai | South-facing | 3.5 | 45 | 10 |
| North-facing | 3.5 | 45 | 10 | |
| Guangzhou | South-facing | 3.0 | 40 | 5 |
| North-facing | 3.5 | 40 | 5 |
| Parameter Name | Value | Parameter Name | Value |
|---|---|---|---|
| Experience playback capacity M | 3000 | Rewardeddiscount factor γ | 0.9 |
| Small batch N | 160 | Greedy exploration factor ε | 0.5 |
| Number of neurons h | 30 | Learning rate lr | 0.1 |
| Target temperature T | 26 | Control step Δt | 1 h |
| Positive Evaluation | Negative Evaluation | Energy Conservation Considerations | Strategy Summary |
|---|---|---|---|
| |Δt| < 0.8 °C |Δt| < |Δt′| Δt > Δt′ (Δt < 0 °C) Δt > Δt′ (0 °C < Δt < 0.8 °C) 0 °C < Δt | |Δt| > 0.8 °C Δt < Δt′ (Δt < 0 °C) Δt < Δt′ (0 °C < Δt < 0.8 °C) Δt < −0.2 °C | Negative rewards will be given when the indoor temperature is lower than 25.8 °C. When Δt is greater than 0, it will be allowed to continue to increase within the temperature control range, and additional rewards will be given | Reduce the range of allowable temperature fluctuation, and add more temperature criteria for reducing energy consumption |
| Region | Room Orientation | Compare to on–off Control Method | Compare to PID Control Method | ||
|---|---|---|---|---|---|
| Temperature Control Effect | Energy Consumption | Temperature Control Effect | Energy Consumption | ||
| Beijing | South-facing | +11.2% | −100.3 MJ | +2.8% | −55.5 MJ |
| North-facing | +3.1% | −129.2 MJ | +7.5% | −30.2 MJ | |
| Shanghai | South-facing | +7.4% | −70.5 MJ | +7.6% | −246.4 MJ |
| North-facing | +5.4% | −90.5 MJ | +7.1% | −6.5 MJ | |
| Guangzhou | South-facing | +14.6% | −77.7 MJ | +6.1% | −3.2 MJ |
| North-facing | +8.2% | −139.8 MJ | +2.4% | −5.2 MJ | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, M.; Wu, X.; Xu, J.; Liu, J.; Li, Z.; Gao, J.; Tian, Z. Indoor Temperature Control of Radiant Ceiling Cooling System Based on Deep Reinforcement Learning Method. Buildings 2023, 13, 2281. https://doi.org/10.3390/buildings13092281
Tang M, Wu X, Xu J, Liu J, Li Z, Gao J, Tian Z. Indoor Temperature Control of Radiant Ceiling Cooling System Based on Deep Reinforcement Learning Method. Buildings. 2023; 13(9):2281. https://doi.org/10.3390/buildings13092281
Chicago/Turabian StyleTang, Mingwu, Xiaozhou Wu, Jianyi Xu, Jiying Liu, Zhengwei Li, Jie Gao, and Zhen Tian. 2023. "Indoor Temperature Control of Radiant Ceiling Cooling System Based on Deep Reinforcement Learning Method" Buildings 13, no. 9: 2281. https://doi.org/10.3390/buildings13092281