

Exploring the Potential of Emerging Digitainability—GPT Reasoning in Energy Management of Kindergartens

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
1.1. Subject of Research

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Ref. | Country | Study Aim | Study Outcome | Stated Concerns/Downsides |
|---|---|---|---|---|---|
| Industry | [18] | United Kingdom | To investigate how GPT can be used to reduce waste generation, improve product quality, and achieve sustainability in the textile industry. | By utilizing GPT, companies in the textile industry can improve the customer experience and make their services more efficient, cost-effective, and prompt. | Not stated. |
| [19] | United Arab Emirates | To evaluate GPT output by a pool of participants (experts); to gather feedback regarding the overall interaction experience and the quality of the GPT output. | The participants had an overall positive interaction experience and indicated the potential of such a tool in automating many preliminary and time-consuming tasks. | The response is not reliable; generic and boilerplate statements; not connected to real-time internet data. | |
| [20] | United Kingdom | To explore what users anticipate from AI; to gain insight into GPT’s applications and the potential effects they may have soon. | GPT can improve interactive learning, simplify collaborations between students and teachers, and provide a more efficient way to store and access course materials. | Privacy and data security; potential to replace human jobs. | |
| Environment and Sustainable Development | [21] | Brazil | To examine the usability of five LLM models in natural resources management decision making. | In the context of water management, it is possible to support human decisions by the use of conversational agents. | Not stated. |
| [22] | Austria | To evaluate contributions and the potential impact of AI on sustainable development in the society domain. | AI has the potential to significantly aid in achieving sustainable development goals. | Lack of transparency concerning AI decisions; bias built into the algorithms; overreliance on automated solutions rather than human intervention. | |
| [23] | Austria | To investigate the benefits of AI for digitalization, urbanization, globalization, climate change, automation and mobility, global health issues, and the aging population. | GPT-3 provides easily understandable insights into the complex and cross-sectional matters of megatrends. | AI systems can make mistakes or generate wrong output. | |
| [24] | India | To investigate how GPT can be used to spread the concept and benefits of nearly-zero-energy buildings through the academic community. | GPT can contribute to activities aimed at spreading the benefits of sustainable development. | Not stated. | |
| [25] | Germany | To investigate the political reasoning, biases, and limitations of GPT. | GPT argues for pro-environmental, left-libertarian ideology. It would impose taxes on flights, restrict rent increases, and legalize abortion. | The study examined just two political orientations, i.e., Germany’s Wahl-O-Mat and the Netherlands’s Stem Wijzer. | |
| Education | [4] | Singapore | To discuss the potentials of GPT in education and research; discuss student-facing, teacher-facing, and system-facing applications; and analyze opportunities and threats. | Despite the challenges that GPT poses for traditional assessments, it will not necessarily lead to their extinction. Instead, it will encourage educators to use AI tools to create diverse assessments that evaluate deeper understanding and critical thinking. | Academic dishonesty; superficial understanding; overreliance on chatbots. |
| [26] | Kenya | To explore the possibility of implementing a constructivist learning environment using chatbot technology. | Chatbot technology can contribute to education through active and social learning. | Not stated. | |
| [27] | United Kingdom | To establish an understanding of the ethics of AI applied in educational contexts. | While initial indicators suggest a lack of interest in the ethics of AI in education, the community recognizes its significance. To improve ethical engagement, discussions and frameworks are required to ensure ethical principles for meaningful real-world impact. | Uncertainties in equity, fairness, confidentiality, and anonymity. | |
| [28] | United States | (Not directly stated) Conversation was aimed to explore complex issues and propose solutions and strategies. | Not directly stated. | (Not directly stated) Limited access to external resources (references). | |
| [29] | United States | To evaluate the abstracts using an AI output detector, plagiarism detector, and blinded human reviewers trying to distinguish whether abstracts were original or generated. | Most generated abstracts were detected using the AI output detector. Blinded human reviewers correctly identified 68% of generated abstracts as being generated by GPT. | GPT writes believable scientific abstracts, though with completely generated data. | |
| [30] | India, Zambia | To understand the perceptions and opinions of academicians toward GPT by collecting and analyzing social media comments, and a survey was conducted with library and information science professionals. | While some academicians may not accept GPT-3, most are starting to accept it. | GPT reduces critical thinking and raises ethical concerns. | |
| [31] | United States | To evaluate the performance of GPT on questions within the scope of the United States Medical Licensing Examination Step 1 and Step 2 exams, as well as to analyze responses for user interpretability. | By performing at a greater than 60% threshold, the model achieved the equivalent of a passing score for a third-year medical student. | GPT training data were not up to date. | |
| [32] | China | To evaluate GPT capabilities in open-ended question answering, factual modeling, and following instructions. The study highlights the strengths and weaknesses of the bot in comparison with human experts. | Although GPT demonstrated impressive capabilities, it still cannot replace human experts. | The study findings were based on unbalanced data. | |
| [33] | Slovakia, UAE, Czech Republic | To provide an up-to-date overview of upcoming changes and advancements in the use of AI in dental education. | GPT can facilitate communication between healthcare providers and patients. | Ethical and legal implications. | |
| [34] | Germany | To assess the quality of radiology reports simplified by GPT. The evaluation was performed by 15 radiologists. | Most radiologists agreed that the simplified reports were factually correct, complete, and not potentially harmful to the patient. | Instances of incorrect statements; missed key; medical findings. | |
| Computing | [35] | China | To provide an overview of GPT, its features, benefits, and challenges. | GPT is a promising AI technology that can be used to automate conversations and generate more accurate responses. | Security and limited capabilities. |
| [36] | United States | To assist researchers and developers in enhancing future language models and chatbots. | Despite its impressive capabilities, GPT improvement is necessary for it to excel in areas such as reasoning, mathematical problem solving, and reducing bias. | Unsatisfactory context comprehension; weak math and arithmetic skills; perception of ethics and morality; difficulty using idioms. | |
| [37] | United States | (Not directly stated) Highlighting potential limitations of GPT, such as its ability to generate inaccurate or meaningless content as well as raising concerns about the technology’s potential harm. | (Not directly stated) GPT has limitations. | Overreliance on AI is harmful. |
1.2. Object of Research
2. Materials and Methods
| Building Location (l) | |||||||
|---|---|---|---|---|---|---|---|
| l1 | l2 | l3 | l4 | ||||
| Vejtoften, Denmark [53] | Wolgast, Germany [54] | Graz, Austria [55] | Tver, Russia [56] | ||||
| Before Renovation | Data Label (k) | 6 | Built year | Not stated | 1973 | 1970 | Not stated |
| 5 | Heated floor area | 221 m2 | 2339 m2 | 992 m2 | 632 m2 | ||
| 4 | Number of stories | 1 | 2 | 2 | 2 | ||
| 3 | Fenestration details | Traditional double-glazed windows | Unknown | Unknown | Wooden frame windows with a total surface of 151 m2 | ||
| 2 | External walls details | With 95 mm thermal insulation (not stated what type) | Unknown | Unknown | Building brick, plastered and painted, the percent of wear makes 64% | ||
| 1 | Roof details | Pitched, with 145 mm thermal insulation (not stated what type) | Flat | Pitched | Pitched roof is on rafters and an obreshetka | ||
| Energy consumption | 167.4 kWh/m2/a | 158 kWh/m2/a | Not stated | Not stated | |||
| Upon Renovation | Data Label (j) | 5 | Modernization completed in | Before 2015 | 2009 | 2010 | Before 2014 |
| 4 | Fenestration details | Triple-glazed windows | Double glazing with insulating protection (U-value including frame 1.4) | Replacement of windows | Metaplastic-framed windows with a total surface of 151 m2 | ||
| 3 | External walls details | With 390 mm thermal insulation (not stated what type) | Exterior wall insulation with mineral wool (15 cm, U-value 0.22) | Additional thermal insulation of external walls | Not renovated | ||
| 2 | Roof details | Pitched, with 145 mm thermal insulation (not stated what type) | Roof insulation (30 cm, U-value 0.12) | Not stated | Not renovated | ||
| 1 | Additional measures | In order to reduce/remove thermal bridge effects at the uninsulated base/foundation of the building, 200 mm of insulation was added on the outside to a depth of 400 mm. | Not stated | Thermal insulation of heat pipes | Not stated | ||
| Energy consumption | 91.7 kWh/m2/a | 116 kWh/m2/a | Not stated | Not stated | |||
| Energy or CO2 savings | 45.2% | 70 t/a | 70% | 40% | |||
2.1. GPT-3.5 Deductive Reasoning Test
2.2. GPT-3.5 Inductive Reasoning Test
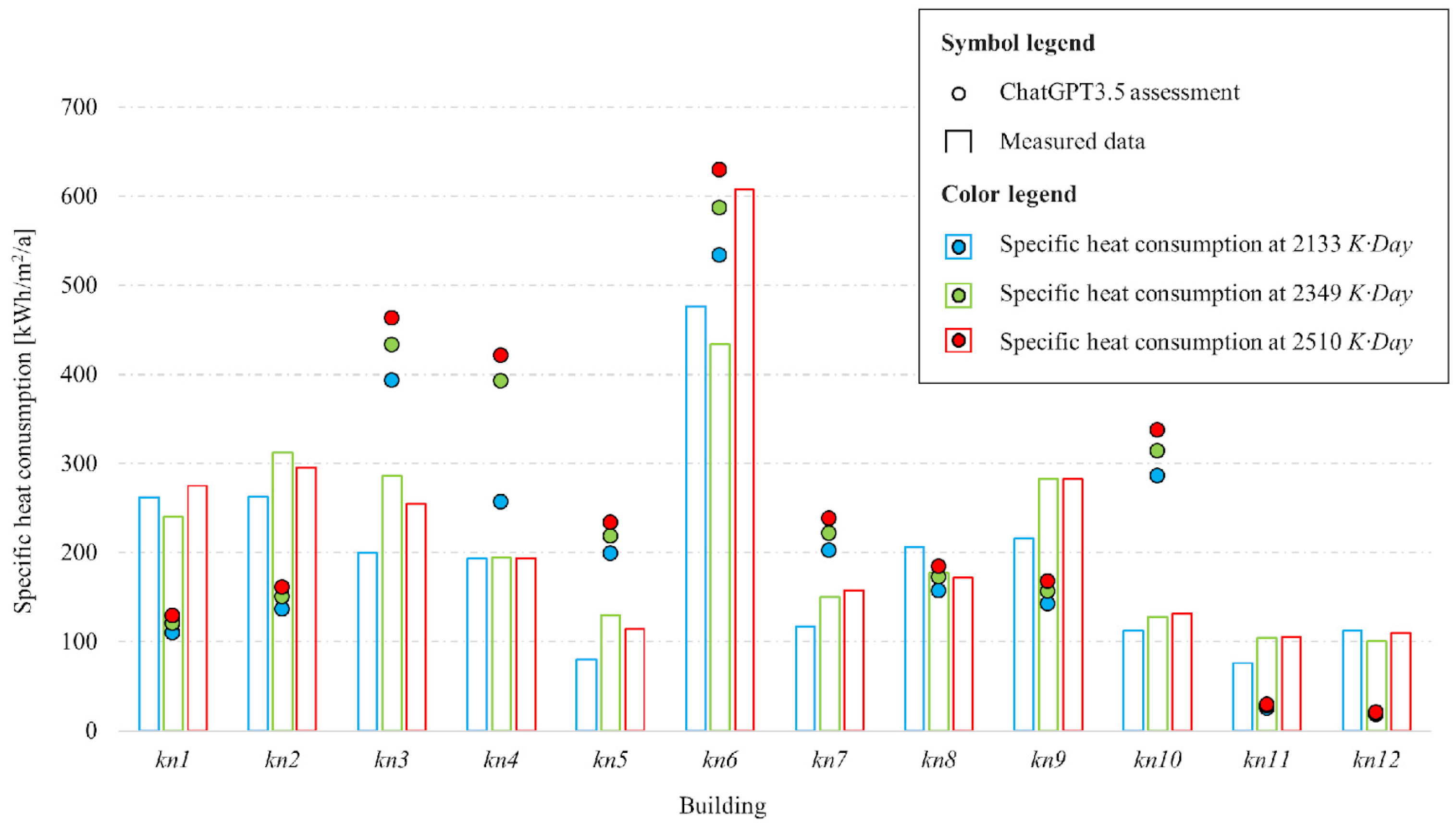
3. Results and Discussion
3.1. GPT-3.5 Deductive Reasoning Test
3.2. GPT-3.5 Inductive Reasoning Test
3.3. Study Contributions and Directions for Future Research
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
List of Abbreviations Including Units and Nomenclature
| HC | Heat consumption [kWh/a] |
| HDD | Heating degree day [K∙Day] |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error [%] |
| r | Pearson’s correlation coefficient [-] |
| R2 | Coefficient of determination [-] |
| SHC | Specific heat consumption [kWh/m2/annually] i.e., [kWh/m2/a] |
| DHS | Duration of a heating season [day] |
| a | Independent variable |
| Mean of the values of the a-variable | |
| b | Dependent variable |
| Mean of the values of the b-variable | |
| bl | Building location |
| br | Before renovation |
| D | Description |
| i | Instance |
| GPT | Generative pre-trained transformer |
| j | Day of a heating season |
| kn | Kindergarten number |
| LLM | Large Language Model |
| MLR | Multiple linear regression |
| n | Number of instances (sample size) |
| nbv | Number of visits |
| NLP | Natural language processing |
| Q | Question |
| SLR | Simple linear regression |
| ted | Thermal envelope detail |
| y | True value of an instance |
| Predicted value of an instance | |
| Mean value of a sample |
Appendix A
| Building: kn10 | ||
|---|---|---|
| Month | HDD | nv |
| I | 612 | 2778 |
| II | 338 | 3953 |
| III | 365 | 4356 |
| IV | 120 | 4316 |
| X | 159 | 3984 |
| XI | 326 | 4633 |
| XII | 582 | 4031 |
| I | 658 | 2159 |
| II | 485 | 3643 |
| III | 220 | 4558 |
| IV | 230 | 4328 |
| X | 102 | 2877 |
| XI | 295 | 4918 |
| XII | 418 | 4114 |
Appendix B
| Building: kn7 | ||
|---|---|---|
| Month | HDD | nv |
| II | 289 | 2557 |
| III | 369 | 2830 |
| IV | 113 | 2626 |
| X | 217 | 2189 |
| XI | 538 | 2830 |
| XII | 618 | 2404 |
| I | 683 | 1733 |
| II | 366 | 2320 |
| III | 238 | 2518 |
| IV | 205 | 2731 |
| X | 127 | 824 |
| XI | 297 | 2162 |
References
- Renn, O. How Sustainable Is the Digital World? Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- Dunning, S.B. Saeculum. In Oxford Classical Dictionary; Oxford University Press: Oxford, UK, 2017. [Google Scholar] [CrossRef]
- Knell, M. The Digital Revolution and Digitalized Network Society. Rev. Evol. Polit. Econ. 2021, 2, 9–25. [Google Scholar] [CrossRef]
- Rudolph, J.; Tan, S.; Tan, S. ChatGPT: Bullshit Spewer or the End of Traditional Assessments in Higher Education? J. Appl. Learn. Teach. 2023, 6, 342–363. [Google Scholar] [CrossRef]
- Đukić, P. Just Transition of the Energy Sector in Serbia—Reforms Sustainability in Face of a New Global Crisis. Energ. Ekon. Ekol. 2022, XXIV, 53–62. [Google Scholar] [CrossRef]
- Cvetanović, A.; Jovičić, M.; Bošković, G.; Jovičić, N. Implementation of Circular Economy and Lean Approaches for a More Competitive and Sustainable Industry. In Proceedings of the 14th International Quality Conference, Kragujevac, Serbia, 24–27 May 2023; Faculty of Engineering, University of Kragujevac: Kragujevac, Serbia, 2023; pp. 1719–1729, ISBN 978-86-6335-104-2. [Google Scholar]
- Goh, H.H.; Vinuesa, R. Regulating Artificial-Intelligence Applications to Achieve the Sustainable Development Goals. Discov. Sustain. 2021, 2, 3–8. [Google Scholar] [CrossRef]
- Lichtenthaler, U. Digitainability: The Combined Effects of the Megatrends Digitalization and Sustainability. J. Innov. Manag. 2021, 9, 64–80. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. An Overview of Chatbot Technology. In Artificial Intelligence Applications and Innovations, Proceedings of the 6th IFIP WG 12.5 International Conference, AIAI 2020, Neos Marmaras, Greece, 5–7 June 2020; IFIP Advances in Information and Communication Technology; Springer International Publishing: Cham, Switzerland, 2020; Volume 584, pp. 373–383. [Google Scholar] [CrossRef]
- Weizenbaum, J. ELIZA—A Computer Program for the Study of Natural Language Communication between Man and Machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Gordon, C. ChatGPT Is the Fastest Growing App in the History of Web Applications. Available online: https://www.forbes.com/sites/cindygordon/2023/02/02/chatgpt-is-the-fastest-growing-ap-in-the-history-of-web-applications/?sh=2055a15a678c (accessed on 10 May 2024).
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural Language Processing: An Introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef]
- OpenAI. Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 12 May 2024).
- Common Crawl—Open Repository of Web Crawl Data. Available online: https://commoncrawl.org/ (accessed on 27 January 2024).
- WebText Background—OpenWebText2. Available online: https://openwebtext2.readthedocs.io/en/latest/background/ (accessed on 27 January 2024).
- Wikipedia. Available online: https://www.wikipedia.org/ (accessed on 27 January 2024).
- Alto, V. Modern Generative AI with ChatGPT and OpenAI Models; Packt Publishing Ltd.: Birmingham, UK, 2023; ISBN 9781805123330. [Google Scholar]
- Rathore, B. Future of Textile: Sustainable Manufacturing & Prediction via ChatGPT. Eduzone 2023, 12, 52–62. [Google Scholar] [CrossRef]
- Prieto, S.A.; Mengiste, E.T.; Soto, B.G. Investigating the Use of ChatGPT for the Scheduling of Construction Projects. Buildings 2023, 13, 857. [Google Scholar] [CrossRef]
- Rathore, D.B. Future of AI & Generation Alpha: ChatGPT beyond Boundaries. Eduzone 2023, 12, 63–68. [Google Scholar] [CrossRef]
- Alves, B.C.; Freitas, L.A.; Aguiar, M.S. Chatbot as Support to Decision-Making in the Context of Natural Resource Management. In Proceedings of the 2021: Workshop de Computação Aplicada à Gestão do Meio Ambiente e Recursos Naturais, Online, 18–23 July 2021; pp. 29–38. [Google Scholar] [CrossRef]
- Jungwirth, D.; Haluza, D. Artificial Intelligence and the Sustainable Development Goals: An Exploratory Study in the Context of the Society Domain. J. Softw. Eng. Appl. 2023, 16, 91–112. [Google Scholar] [CrossRef]
- Jungwirth, D.; Haluza, D. Artificial Intelligence and Ten Societal Megatrends: An Exploratory Study Using GPT-3. Systems 2023, 11, 120. [Google Scholar] [CrossRef]
- Rani, P.S.; Rani, K.R.; Daram, S.B.; Angadi, R.V. Is It Feasible to Reduce Academic Stress in Net-Zero Energy Buildings? Reaction from ChatGPT. Ann. Biomed. Eng. 2023, 51, 2654–2656. [Google Scholar] [CrossRef]
- Hartmann, J.; Schwenzow, J.; Witte, M. The Political Ideology of Conversational AI: Converging Evidence on ChatGPT’s pro-Environmental, Left-Libertarian Orientation. arXiv 2023, arXiv:2301.01768. [Google Scholar] [CrossRef]
- Bii, P. Chatbot Technology: A Possible Means of Unlocking Student Potential to Learn How to Learn. Educ. Res. 2013, 4, 218–221, ISSN: 2141-5161. [Google Scholar]
- Holmes, W.; Porayska-Pomsta, K.; Holstein, K.; Sutherland, E.; Baker, T.; Shum, S.B.; Santos, O.C.; Rodrigo, M.T.; Cukurova, M.; Bittencourt, I.I.; et al. Ethics of AI in Education: Towards a Community-Wide Framework. Int. J. Artif. Intell. Educ. 2022, 32, 504–526. [Google Scholar] [CrossRef]
- King, M.R. A Conversation on Artificial Intelligence, Chatbots, and Plagiarism in Higher Education. Cell. Mol. Bioeng. 2023, 16, 1–2. [Google Scholar] [CrossRef]
- Gao, C.A.; Howard, F.M.; Markov, N.S.; Dyer, E.C.; Ramesh, S.; Luo, Y.; Pearson, A.T. Comparing Scientific Abstracts Generated by ChatGPT to Real Abstracts with Detectors and Blinded Human Reviewers. NPJ Digit. Med. 2023, 6, 75. [Google Scholar] [CrossRef]
- Subaveerapandiyan, A.; Vinoth, A.; Tiwary, N. Netizens, Academicians and Information Professionals’ Opinions About AI with Special Reference to ChatGPT. Libr. Philos. Pract. 2023, 1–16. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef] [PubMed]
- Guo, B.; Zhang, X.; Wang, Z.; Jiang, M.; Nie, J.; Ding, Y.; Yue, J.; Wu, Y. How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection. arXiv 2023, arXiv:2301.07597. [Google Scholar] [CrossRef]
- Thurzo, A.; Strunga, M.; Urban, R.; Surovková, J.; Afrashtehfar, K.I. Impact of Artificial Intelligence on Dental Education: A Review and Guide for Curriculum Update. Educ. Sci. 2023, 13, 150. [Google Scholar] [CrossRef]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stuber, A.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.; Ricke, J.; et al. ChatGPT Makes Medicine Easy to Swallow: An Exploratory Case Study on Simplified Radiology Reports. arXiv 2022, arXiv:2212.14882. [Google Scholar] [CrossRef]
- Deng, J.; Lin, Y. The Benefits and Challenges of ChatGPT: An Overview. Front. Comput. Intell. Syst. 2022, 2, 81–83. [Google Scholar] [CrossRef]
- Borji, A. A Categorical Archive of ChatGPT Failures. arXiv 2023, arXiv:2302.03494. [Google Scholar] [CrossRef]
- Markus, G.; Davis, E. GPT-3, Bloviator: OpenAI’s Language Generator Has No Idea What It’s Talking About|MIT Technology Review. Available online: https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/ (accessed on 27 June 2024).
- Retief, F.; Bond, A.; Pope, J.; Morrison-Saunders, A.; King, N. Global Megatrends and Their Implications for Environmental Assessment Practice. Environ. Impact Assess. Rev. 2016, 61, 52–60. [Google Scholar] [CrossRef]
- Talan, T.; Kalinkara, Y. The Role of Artificial Intelligence in Higher Education: ChatGPT Assessment for Anatomy Course. Int. J. Manag. Inf. Syst. Comput. Sci. 2023, 7, 32–40. [Google Scholar] [CrossRef]
- Salvagno, M.; Taccone, F.S.; Gerli, A.G. Can Artificial Intelligence Help for Scientific Writing? Crit. Care 2023, 27, 75. [Google Scholar] [CrossRef]
- Li, L.; Ma, Z.; Fan, L.; Lee, S.; Yu, H.; Hemphill, L. ChatGPT in Education: A Discourse Analysis of Worries and Concerns on Social Media. Educ. Inf. Technol. 2024, 29, 10729–10762. [Google Scholar] [CrossRef]
- The Government Offices of Sweden. Lund Declaration on Maximising the Benefits of Research Data. Available online: https://www.government.se/information-material/2023/06/lund-declaration-on-maximising-the-benefits-of-research-data/ (accessed on 27 June 2024).
- European Commission. The Rome Declaration. Available online: https://ec.europa.eu/commission/presscorner/detail/en/STATEMENT_17_767 (accessed on 27 June 2024).
- Jurišević, N. System for Monitoring and Targeting of Energy and Water Consumption in Public Buildings, University of Kragujevac, Kragujevac, Serbia 2021. Available online: https://nardus.mpn.gov.rs/handle/123456789/18681?locale-attribute=en (accessed on 30 June 2024).
- Bećirović, S.P.; Vasić, M. Methodology and Results of Serbian Energy-Efficiency Refurbishment Project. Energy Build. 2013, 62, 258–267. [Google Scholar] [CrossRef]
- European Commission. Renovation Wave. Available online: https://energy.ec.europa.eu/topics/energy-efficiency/energy-efficient-buildings/renovation-wave_en (accessed on 30 June 2024).
- Jurišević, N.; Gordić, D.; Vukićević, A. Assessment of Predictive Models for the Estimation of Heat Consumption in Kindergartens. Therm. Sci. 2022, 26, 503–516. [Google Scholar] [CrossRef]
- Jurišević, N.M.; Gordić, D.R.; Vukašinović, V.; Vukicevic, A.M. Assessment of Predictive Models for Estimation of Water Consumption in Public Preschool Buildings. J. Eng. Res. 2021, 10, 98–111. [Google Scholar] [CrossRef]
- Capozzoli, A.; Grassi, D.; Causone, F. Estimation Models of Heating Energy Consumption in Schools for Local Authorities Planning. Energy Build. 2015, 105, 302–313. [Google Scholar] [CrossRef]
- Beusker, E.; Stoy, C.; Pollalis, S.N. Estimation Model and Benchmarks for Heating Energy Consumption of Schools and Sport Facilities in Germany. Build. Environ. 2012, 49, 324–335. [Google Scholar] [CrossRef]
- Garrido, A.; Hardy, L. Análisis y Evaluación de las Relaciones Entre el Agua y la Energía en España; Realigraf, S.A.: Madrid, Spain, 2010; Volume 6, ISBN 9788496655232. [Google Scholar]
- Aranda, A.; Ferreira, G.; Mainar-Toledo, M.D.; Scarpellini, S.; Llera Sastresa, E. Multiple Regression Models to Predict the Annual Energy Consumption in the Spanish Banking Sector. Energy Build. 2012, 49, 380–387. [Google Scholar] [CrossRef]
- Rose, J.; Thomsen, K.E. Energy Saving Potential in Retrofitting of Non-Residential Buildings in Denmark. Energy Procedia 2015, 78, 1009–1014. [Google Scholar] [CrossRef]
- Power, A.; Zulaf, M. Cutting Carbon Costs: Learning from Germany’s Energy Saving Program; London School of Economics: London, UK, 2011. [Google Scholar]
- Bleyl-androschin, J.W.; Schinnerl, D. Comprehensive Refurbishment of Buildings Through Energy Performance Contracting a Guide for Building Owners and ESCos Including Good Practice Examples; Graz Energy Agency: Graz, Austria, 2010; ISBN 4315861524340. [Google Scholar]
- Vatin, N.I.; Nemova, D.V.; Kazimirova, A.S.; Gureev, K.N. Increase of Energy Efficiency of the Building of Kindergarten. Adv. Mater. Res. 2014, 953–954, 1537–1544. [Google Scholar] [CrossRef]
- Playground—OpenAI API. Available online: https://platform.openai.com/playground (accessed on 20 September 2024).
- Taulli, T. Generative AI; Apress: New York, NY, USA, 2023; ISBN 9781484293690. [Google Scholar]
- Sammut, C.; Webb, G.I. (Eds.) Mean Absolute Error (MAE). In Encyclopedia of Machine Learning and Data Mining; Springer: Boston, MA, USA, 2017; p. 806. [Google Scholar] [CrossRef]
- Swamidass, P.M. (Ed.) Mean Absolute Percentage Error (MAPE). In Encyclopedia of Production and Manufacturing Management; Springer: New York, NY, USA, 2006; p. 462. ISBN 9781402006128. [Google Scholar]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Coefficient of Determination R-Squared Is More Informative than SMAPE, MAE, MAPE, MSE and RMSE in Regression Analysis Evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]



| Dataset | Number of Tokens | Training Mix |
|---|---|---|
| Common Crawl (filtered) | 490 billion | 60% |
| WebText2 | 19 billion | 22% |
| Books1 | 12 billion | 8% |
| Books2 | 55 billion | 8% |
| Wikipedia | 3 billion | 3% |
| Building Thermal Envelope Details (i) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| Built Year | Number of Floors | External Walls Gross Area | Heated Floor Area | Gross Heated Volume | Gross Glazing Area | External Walls U-Value | Glazing Elements U-Value | Ceiling U-Value | Roof Type | ||
| [-] | [-] | [m2] | [m2] | [m3] | [m2] | [W/m2K] | [W/m2K] | [W/m2K] | [-] | ||
| Kindergarten No (kn) | 1 | 1947 | 3 | 468 | 484 | 1382 | 92 | 1.38 | 4.01 | 0.37 | Flat |
| 2 | 1948 | 1 | 740 | 452 | 1429 | 98 | 1.28 | 3.68 | 1.75 | Pitched | |
| 3 | 1968 | 2 | 1121 | 862 | 2888 | 548 | 0.5 | 1.59 | 0.52 | Flat | |
| 4 | 1973 | 2 | 738 | 860 | 2580 | 236 | 1.38 | 3.6 | 0.25 | Flat | |
| 5 | 1974 | 3 | 1036 | 1174 | 3745 | 270 | 0.46 | 3.21 | 0.35 | Pitched | |
| 6 | 1974 | 1 | 764 | 1370 | 4482 | 499 | 2.0 | 4.26 | 1.4 | Pitched | |
| 7 | 1974 | 2 | 1942 | 537 | 5199 | 453 | 0.46 | 3.52 | 0.34 | Pitched | |
| 8 | 1974 | 2 | 685 | 807 | 2598 | 273 | 1.16 | 2.88 | 1.4 | Pitched | |
| 9 | 1980 | 2 | 2708 | 1321 | 4057 | 461 | 1.38 | 3.52 | 1.53 | Pitched | |
| 10 | 1982 | 2 | 2480 | 2379 | 7636 | 755 | 0.34 | 3.11 | 0.34 | Pitched | |
| 11 | 2008 | 1 | 311 | 387 | 1136 | 68 | 0.16 | 2.71 | 0.35 | Pitched | |
| 12 | 2010 | 1 | 230 | 464 | 1508 | 80 | 0.16 | 2.9 | 0.35 | Pitched | |
| GPT Parameters | Parameter Value | Parameter Role [17,58] |
|---|---|---|
| Model | “gpt-3.5-turbo” | A deep learning model that generates text employing a neural network. |
| Temperature (ranging from 0 to 1) | 1 | Determines the randomness of the response. The more closely the temperature approaches 0, the less erratic the result will be. |
| Maximum length (ranging from 0 to 2048) | 200 | Caps a number of tokens that are allowed for a response. This varies according to the type of model. |
| Stop sequences (user input) | - | Makes responses end at the desired point, such as the end of a sentence or list. |
| Top probabilities/Top P (ranging from 0 to 1) | 1 | Controls which tokens the model will consider when generating a response. Setting this to 0.9 will consider the top 90% most likely of all possible tokens. |
| Frequency penalty (ranging from 0 to 1) | 0 | Controls the repetition of the same tokens in the generated response. The higher the penalty, the lower the probability of seeing the same tokens more than once in the same response. |
| Presence penalty (ranging from 0 to 2) | 0 | Reduces the chance of repeating any token that has appeared in the text. It is stricter than the frequency penalty, so it increases the likelihood of introducing new topics in a response. |
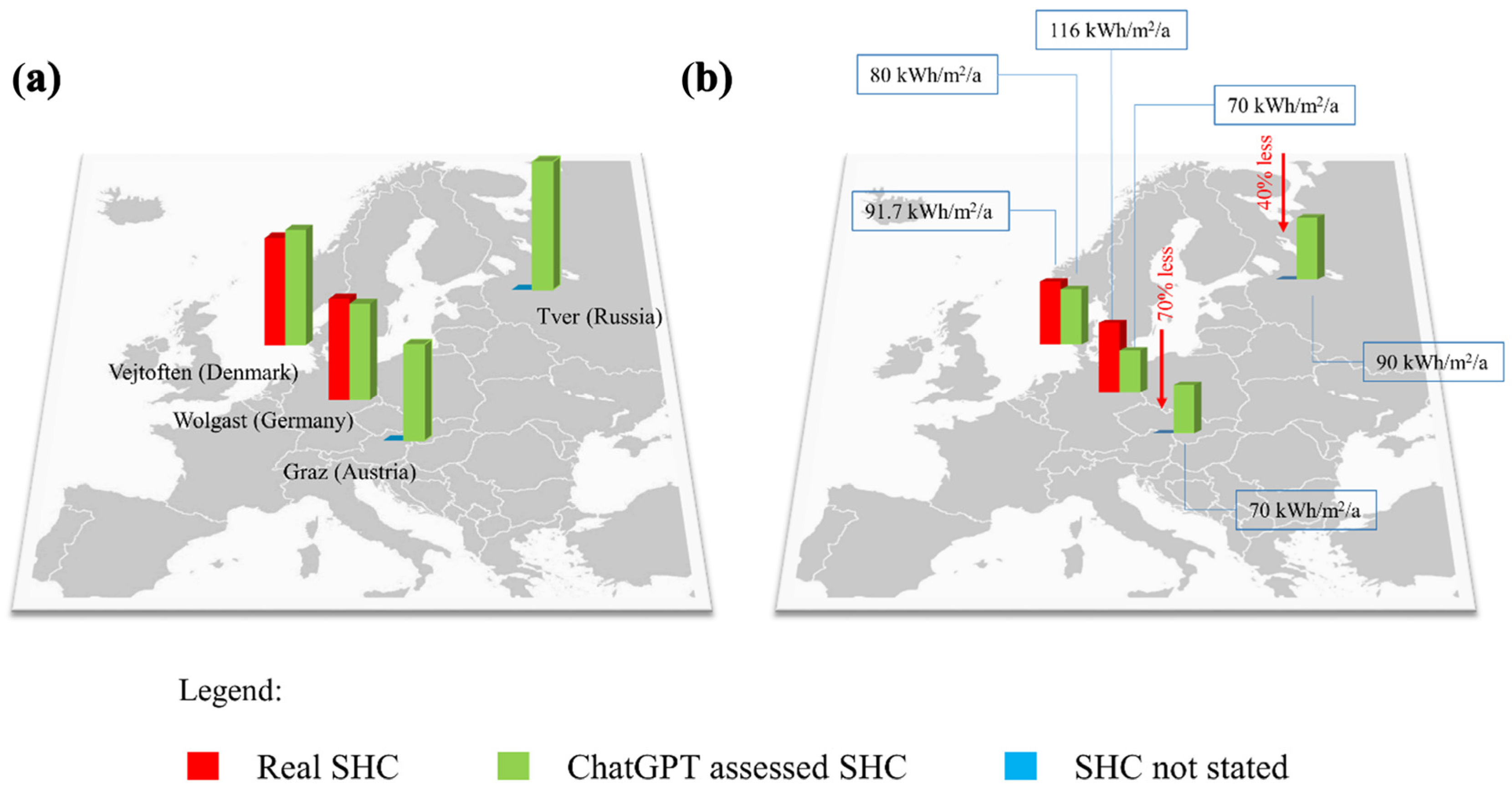
| Vejtofen (Denmark) | Wolgast (Germany) | Graz (Austria) | Tver (Russia) | |
|---|---|---|---|---|
| Real SHC [kWh/m2/a] | 167.4 | 158 | Not stated | Not stated |
| GPT-assessed SHC [kWh/m2/a] | 180 | 150 | 150 | 200 |
| Real SHC savings [%] | 49% | 23% | 70% | 40% |
| GPT-assessed SHC savings [%] | 55% | 53% | 53% | 55% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jurišević, N.; Gordić, D.; Nikolić, D.; Nešović, A.; Kowalik, R. Exploring the Potential of Emerging Digitainability—GPT Reasoning in Energy Management of Kindergartens. Buildings 2024, 14, 4038. https://doi.org/10.3390/buildings14124038
Jurišević N, Gordić D, Nikolić D, Nešović A, Kowalik R. Exploring the Potential of Emerging Digitainability—GPT Reasoning in Energy Management of Kindergartens. Buildings. 2024; 14(12):4038. https://doi.org/10.3390/buildings14124038
Chicago/Turabian StyleJurišević, Nebojša, Dušan Gordić, Danijela Nikolić, Aleksandar Nešović, and Robert Kowalik. 2024. "Exploring the Potential of Emerging Digitainability—GPT Reasoning in Energy Management of Kindergartens" Buildings 14, no. 12: 4038. https://doi.org/10.3390/buildings14124038
APA StyleJurišević, N., Gordić, D., Nikolić, D., Nešović, A., & Kowalik, R. (2024). Exploring the Potential of Emerging Digitainability—GPT Reasoning in Energy Management of Kindergartens. Buildings, 14(12), 4038. https://doi.org/10.3390/buildings14124038