
A Filling Method Based on K-Singular Value Decomposition (K-SVD) for Missing and Abnormal Energy Consumption Data of Buildings


 ,
,
Abstract
:1. Introduction
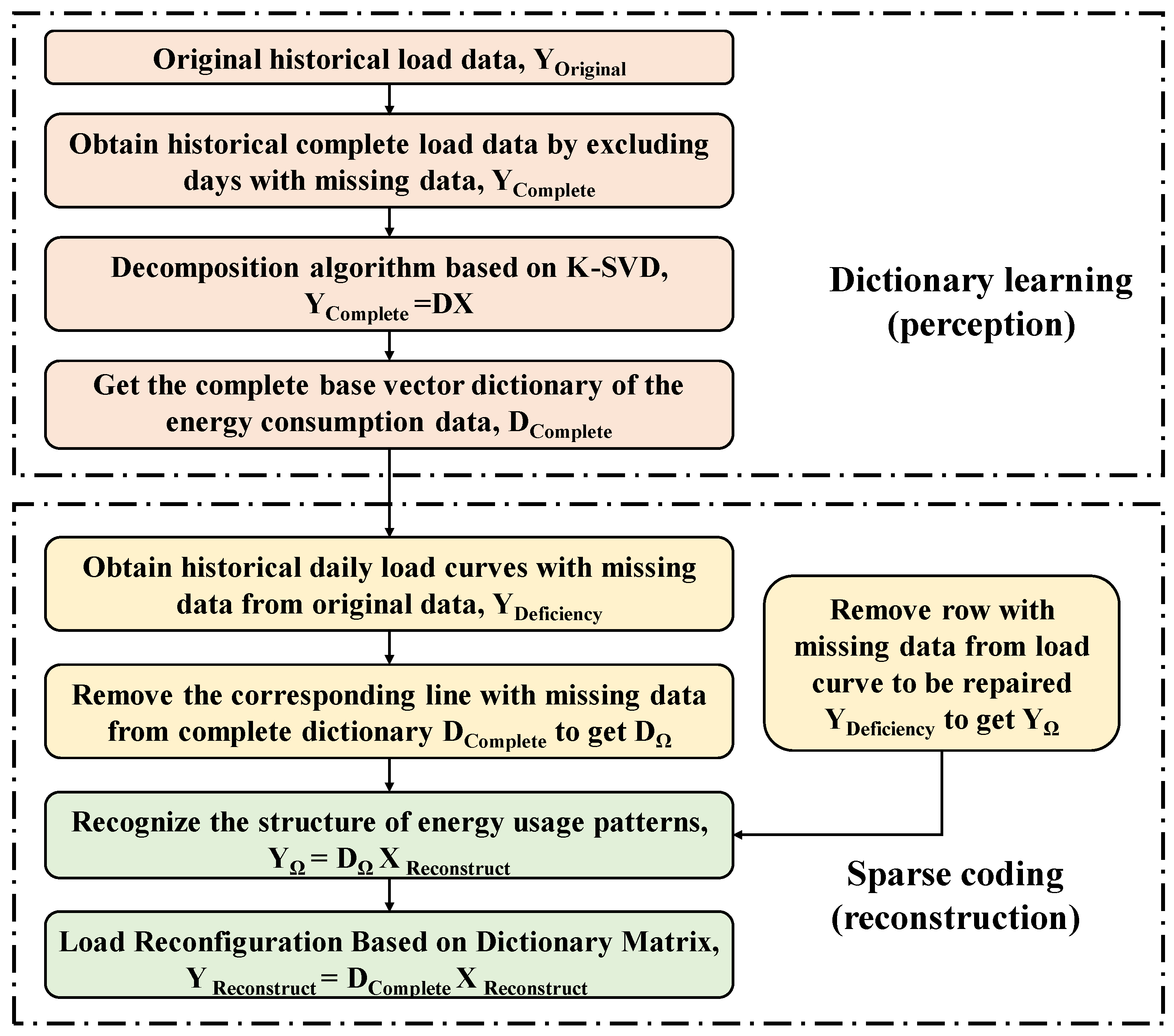
2. Missing Data Filling Method Based on K-SVD
2.1. Introduction on K-SVD
2.2. Evaluation Metrics
- (1)
- Mean Absolute Percentage Error (MAPE):
- (2)
- Coefficient of Variation of the Root Mean Square Error (CVRMSE):
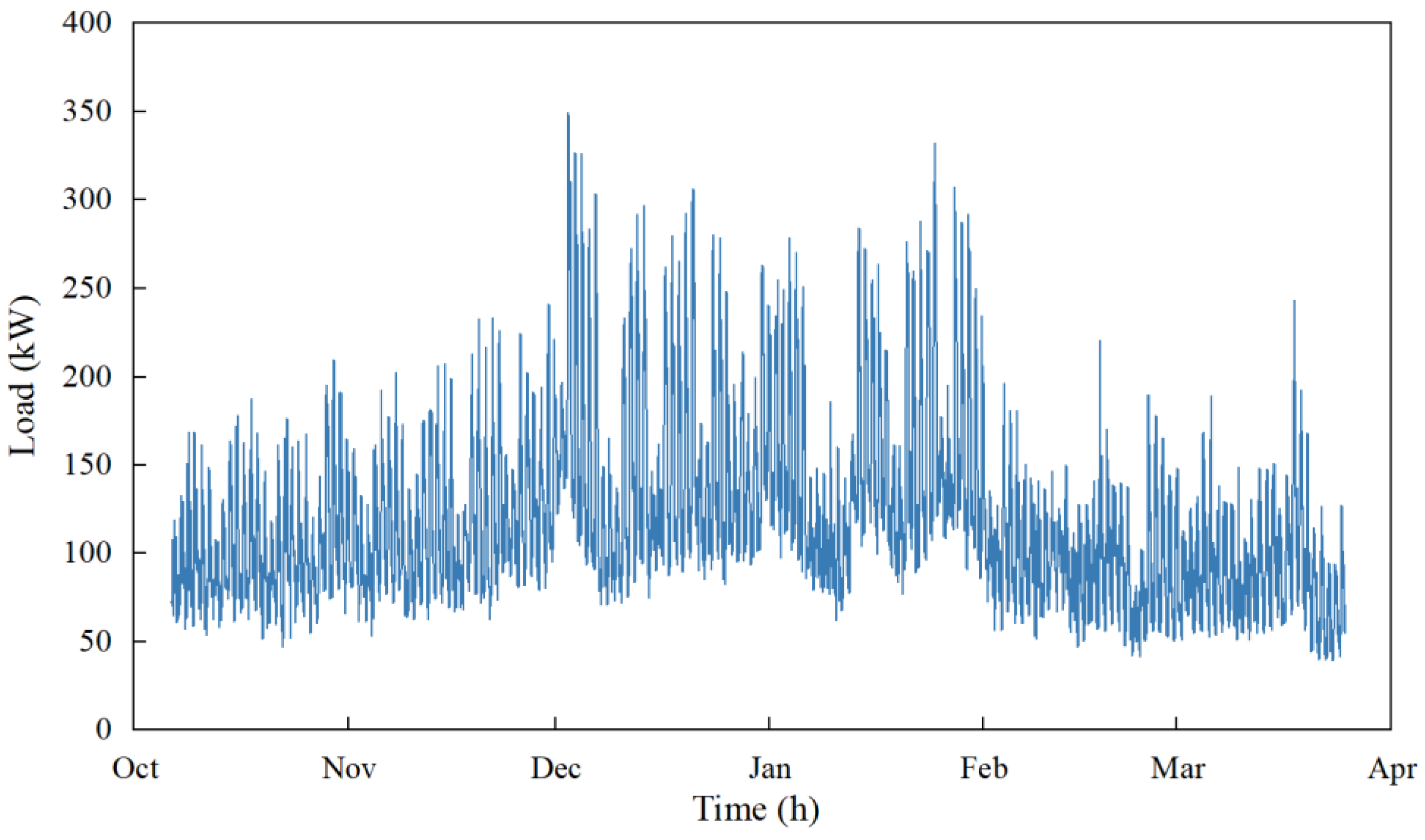
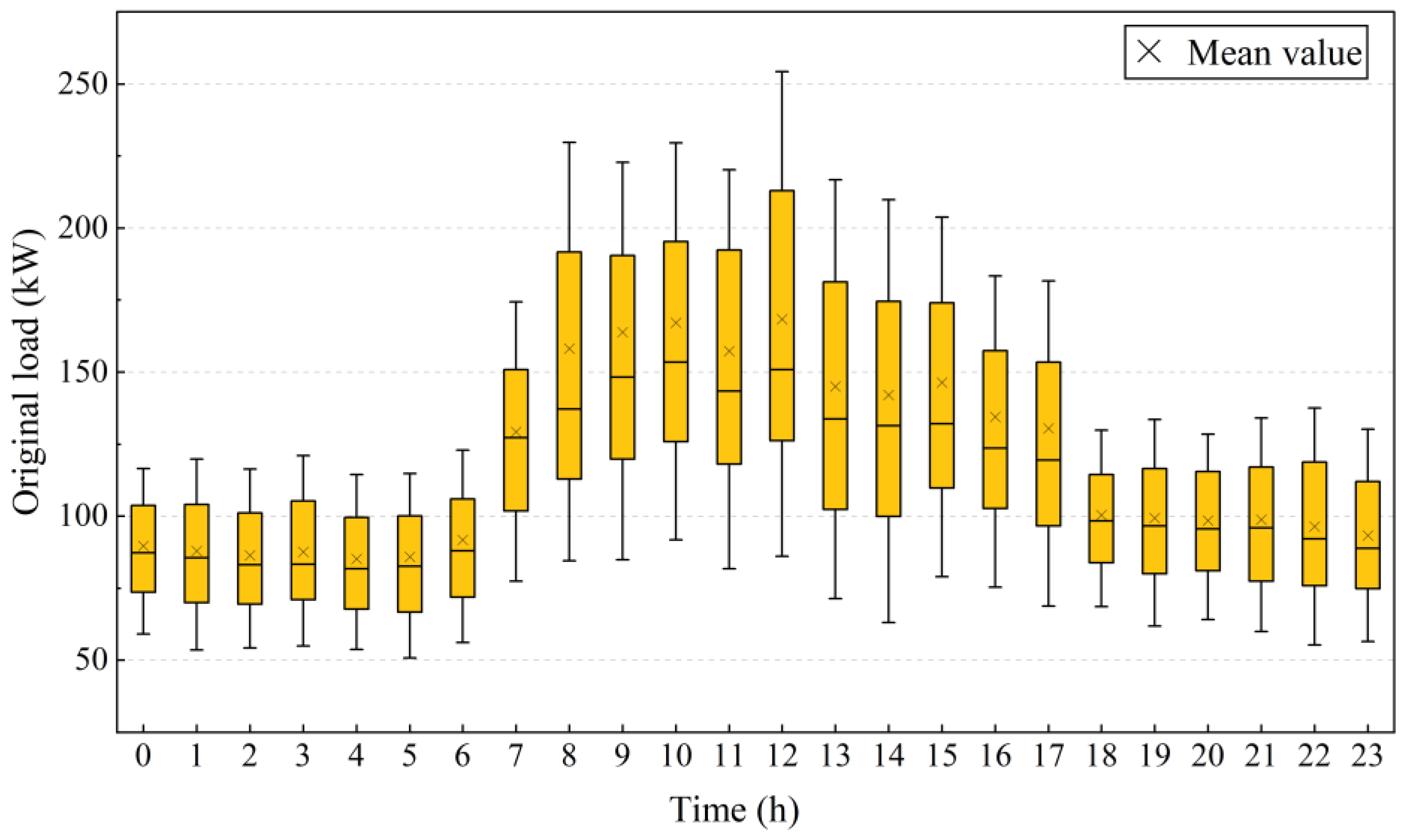
3. Energy Consumption Data of a Building and Evaluation Scenarios
- (1)
- Method 1: It is interpolated based on the linear regression of the previous two adjacent data.
- (2)
- Method 2: The missing data are estimated by assuming the linear relationship between the data before and after it.
- (3)
- Method 3: The load at the same moment of the same weekday of the previous week is utilized to fill in the missing values. It is assumed the working pattern and energy consumption would not vary significantly in two weeks.
- (4)
- Method 4: The mean value of the load data obtained by Method 3 and the load data at the previous moment of the missing data is used.
- (5)
- Method 5: It fills the data with the mean of the data obtained by Method 1 and Method 3, considering the periodic and time-series characteristics of the load data.
- (6)
- Method 6: It fills the data with the mean of the data obtained by Method 2 and Method 3, also considering the periodic and time-series characteristics of the load data.
- (7)
- Method 7: The missing load data are filled with that at the same time of the nearest previous weekday or weekend. It is assumed that the working patterns and energy consumption do not change significantly for adjacent days of weekdays or weekends, respectively.
- Dictionary size: The dictionary size determines the complexity of the model. If the dictionary is too large, it may lead to overfitting. Conversely, if the dictionary is too small, it may lead to underfitting. Moreover, increasing the dictionary size may increase the computational complexity of the K-SVD algorithm. Thus, the influence of the dictionary size is evaluated.
- Missing continuity: It will affect the integrity of the information in the original data. Therefore, in this study, the continuity of the missing data is considered to show the advantages of the data filling method.
- Training sample size: The training sample size would affect the quality of the learned dictionary and the computational cost. Thus, the impact of the training sample size is considered and tested.
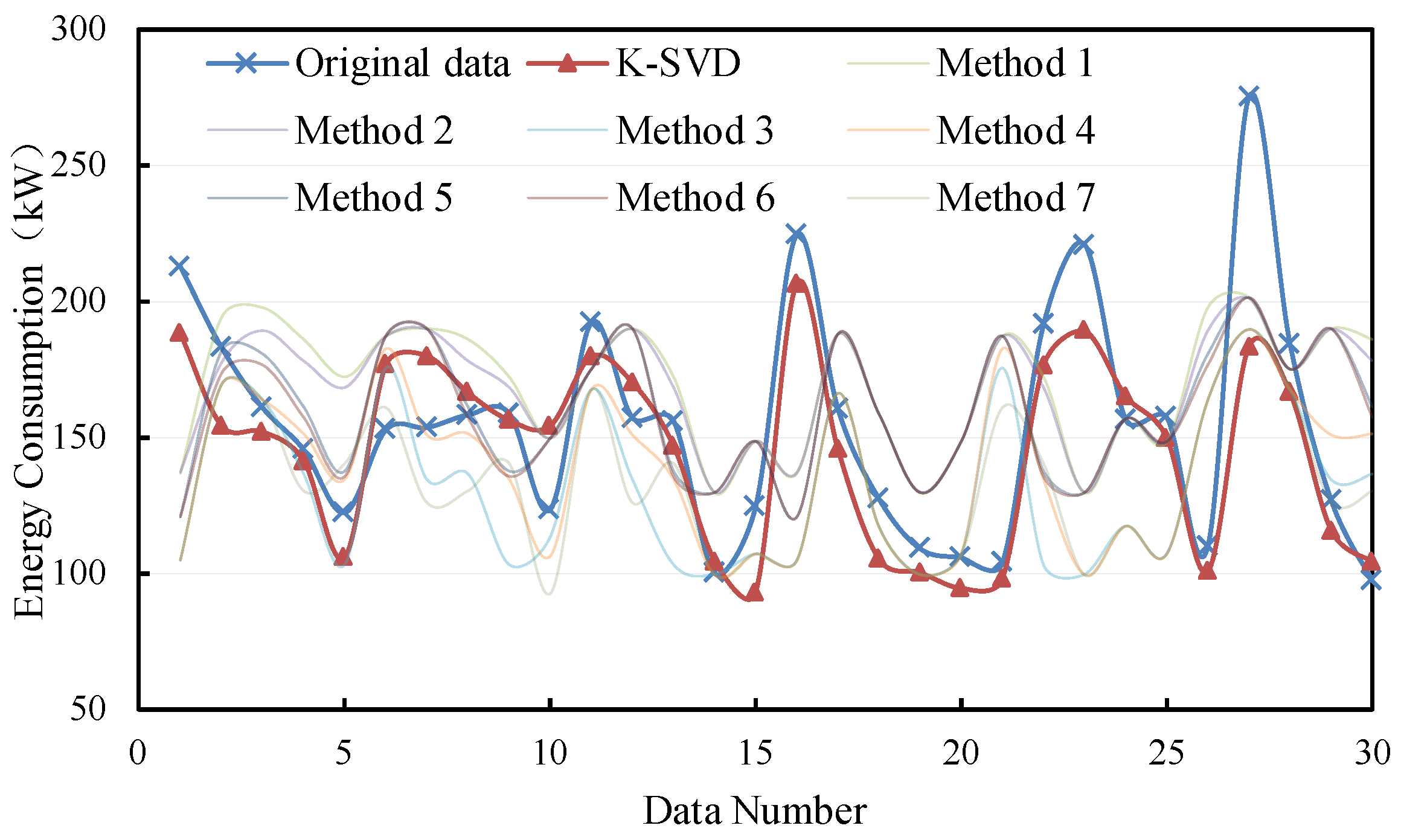
4. Result Analysis and Discussion
4.1. Impact of the Dictionary Size
4.2. Impact of the Missing Continuity
4.3. Impact of the Sample Size
5. Conclusions
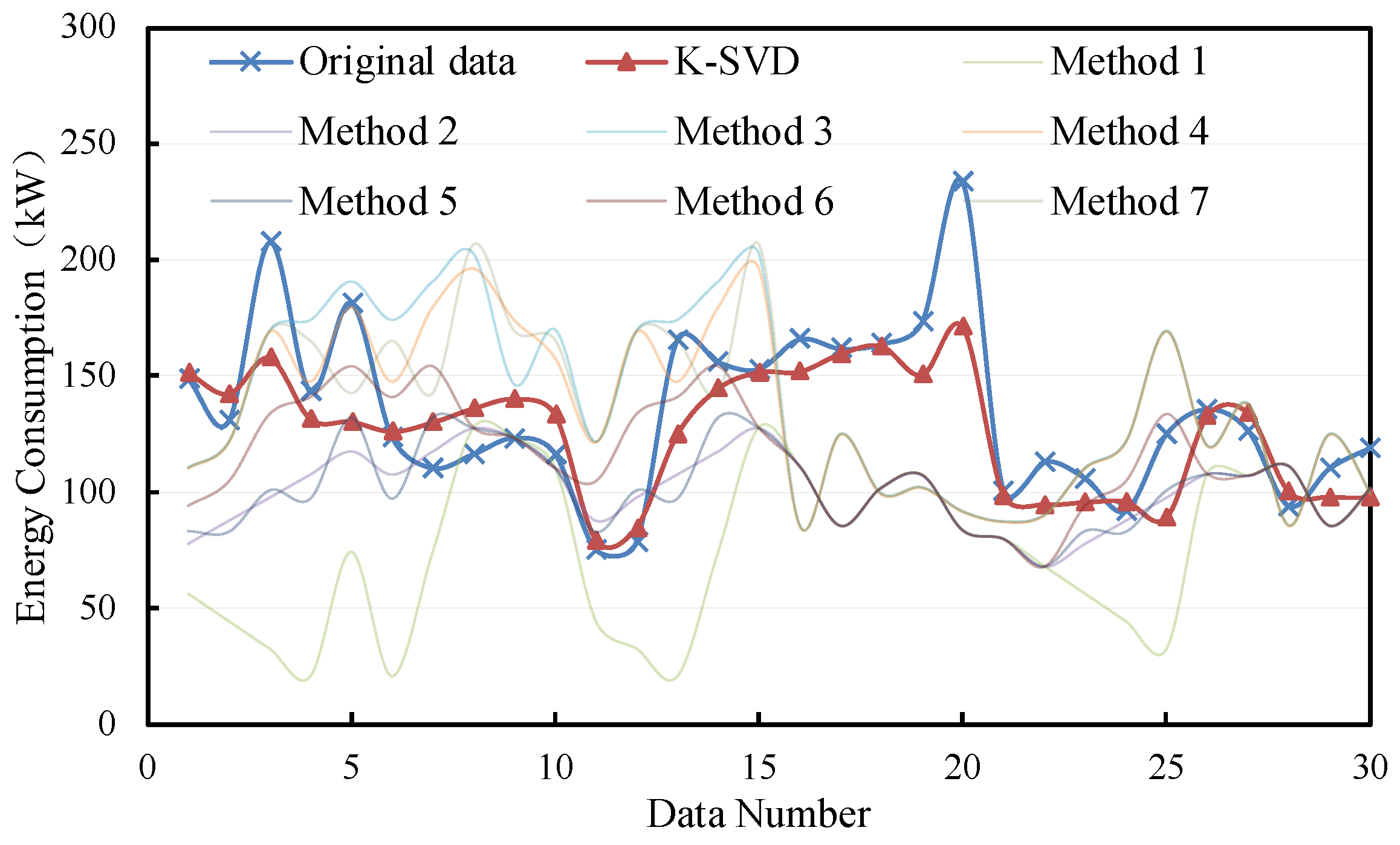
- The proposed K-SVD-based method can fill the missing energy consumption data with high accuracy. The MAPE and CVRMSE are 10.8–14.8% and 15.7–22.4%. It shows a better imputation performance compared with other traditional methods, resulting in a decrease in the MAPE and CVRMSE by 3.8–45.4% and 6.7–87.8%.
- The increase in dictionary size would not lead to better filling accuracy, so a smaller size is recommended. However, the optimal size should be checked before being applied.
- The K-SVD-based method performs better for the non-consecutive missing data compared with the consecutive missing situation. The MAPE and CVRMSE for non-consecutive missing can be lower by 0.1–4% and 5.1–6.7% compared with that for consecutive missing data. However, the filling advantage of the proposed method is stronger for consecutive missing data compared with the traditional methods.
- The proposed method can achieve a higher filling accuracy when the learning sample size is small. The accuracy of the imputation method using K-SVD, based on the data of one month, evaluated by MAPE and CVRMSE, ranges from 9.3% to 9.4% and 12% to 17.1%. It is much lower than that with a large learning sample size.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hossain, E.; Khan, I.; Un-Noor, F.; Sikander, S.S.; Sunny, M.S.H. Application of Big Data and Machine Learning in Smart Grid, and Associated Security Concerns: A Review. IEEE Access 2019, 7, 13960–13988. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, T.; Bompard, E.F. Big data analytics in smart grids: A review. Energy Inform. 2018, 1, 8. [Google Scholar] [CrossRef]
- Huang, G. Missing data filling method based on linear interpolation and lightgbm. J. Phys. Conf. Ser. 2021, 1754, 012187. [Google Scholar] [CrossRef]
- Razavi-Far, R.; Farajzadeh-Zanjani, M.; Saif, M.; Chakrabarti, S. Correlation Clustering Imputation for Diagnosing Attacks and Faults with Missing Power Grid Data. IEEE Trans. Smart Grid 2020, 11, 1453–1464. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Deng, Z.; Liu, Y.; Li, Y.; Tan, M.; An, Z. Implementation of state-wide power quality monitoring and analysis system in China. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018; pp. 1–5. [Google Scholar]
- Ge, M.; Chren, S.; Rossi, B.; Pitner, T. Data Quality Management Framework for Smart Grid Systems. In Business Information Systems, proceedings of the 22nd International Conference, BIS 2019, Seville, Spain, 26–28 June 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 299–310. [Google Scholar]
- Liu, H.; Wang, Y.; Chen, W.J. Three-step imputation of missing values in condition monitoring datasets. IET Gener. Transm. Distrib. 2020, 14, 3288–3300. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Abraham, W.T.; Russell, D.W. Missing data: A review of current methods and applications in epidemiological research. Curr. Opin. Psychiatry 2004, 17, 315–321. [Google Scholar] [CrossRef]
- Ahn, H.; Sun, K.; Kim, K.P. Comparison of Missing Data Imputation Methods in Time Series Forecasting. Comput. Mater. Contin. 2022, 70, 767–779. [Google Scholar] [CrossRef]
- Aydilek, I.B.; Arslan, A. A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inf. Sci. 2013, 233, 25–35. [Google Scholar] [CrossRef]
- Myrtveit, I.; Stensrud, E.; Olsson, U.H. Analyzing data sets with missing data: An empirical evaluation of imputation methods and likelihood-based methods. IEEE Trans. Softw. Eng. 2001, 27, 999–1013. [Google Scholar] [CrossRef]
- Khan, S.I.; Hoque, A.S.M.L. SICE: An improved missing data imputation technique. J. Big Data 2020, 7, 37. [Google Scholar] [CrossRef]
- Dasarathy, B.V. Nearest Neighbor (NN) Norms: NN Pattern CLassification Techniques. 1991. Available online: https://www.semanticscholar.org/paper/Nearest-neighbor-(NN)-norms%3A-NN-pattern-techniques-Dasarathy/0b1d3ec2e6fe49aaf8dc068b8a812e9ef3f163fa (accessed on 21 January 2024).
- Xu, Y.; Ni, Y. Research on Missing Data Imputation Based on Conditional Variational Autoencoder. In Proceedings of the International Conference on Computer Information Science and Artificial Intelligence (CISAI), Kunming, China, 17–19 September 2021; pp. 726–730. [Google Scholar]
- Zou, D.; Xiang, Y.; Zhou, T.; Peng, Q.; Dai, W.; Hong, Z.; Shi, Y.; Wang, S.; Yin, J.; Quan, H. Outlier detection and data filling based on KNN and LOF for power transformer operation data classification. Energy Rep. 2023, 9, 698–711. [Google Scholar] [CrossRef]
- Jadhav, A.; Pramod, D.; Ramanathan, K. Comparison of Performance of Data Imputation Methods for Numeric Dataset. Appl. Artif. Intell. 2019, 33, 913–933. [Google Scholar] [CrossRef]
- Xiong, Z.; Guo, H.; Wu, Y. Review of Missing Data Processing Methods. Comput. Eng. Appl. 2021, 57, 27–38. [Google Scholar]
- Domagk, M.; Zyabkina, O.; Meyer, J.; Schegner, P. Trend identification in power quality measurements. In Proceedings of the Australasian Universities Power Engineering Conference (AUPEC), Orlando, FL, USA, 27–30 September 2015; pp. 1–6. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Kiran, P.M.; Rao, A.; Ratnamala, B. An Efficient Approach for Filling Incomplete Data. Int. J. Comput. Appl. 2012. [Google Scholar]
- Carpenter, J.R.; Bartlett, J.W.; Morris, T.P.; Wood, A.M.; Quartagno, M.; Kenward, M.G. Multiple Imputation and Its Application; John Wiley & Sons: Hoboken, NJ, USA, 2023. [Google Scholar]
- Breiman, L.J.M.L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Tang, F.; Ishwaran, H. Random Forest Missing Data Algorithms. Stat. Anal. Data Min. ASA Data Sci. J. 2017, 10, 363–377. [Google Scholar] [CrossRef]
- Amritkar, R.E.; Kumar, P.P. Interpolation of missing data using nonlinear and chaotic system analysis. J. Geophys. Res. Atmos. 1995, 100, 3149–3154. [Google Scholar] [CrossRef]
- Hong, S.; Sun, Y.; Li, H.; Lynn, H.S. Influence of parallel computing strategies of iterative imputation of missing data: A case study on missForest. arXiv 2020, arXiv:2004.11195. [Google Scholar]
- Stekhoven, D.J.; Bühlmann, P.J.B. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2011, 28, 112–118. [Google Scholar] [CrossRef]
- Pan, R.; Yang, T.; Cao, J.; Lu, K.; Zhang, Z. Missing data imputation by K nearest neighbours based on grey relational structure and mutual information. Appl. Intell. 2015, 43, 614–632. [Google Scholar] [CrossRef]
- Zhang, C.; Kai, J.; Feng, H.; Yang, T. The Nearest Neighbor Algorithm of Filling Missing Data Based on Cluster Analysis. Appl. Mech. Mater. 2013, 347–350, 2324–2328. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, J.; Zhao, K. A locally weighted KNN algorithm based on eigenvector of SVM. Int. J. Wirel. Mob. Comput. 2020, 19, 256–266. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, L.; Pei, S.; Yu, Z.; Chen, Y.; Liu, X.; Du, J.; Xiong, N. KNN-BLOCK DBSCAN: Fast Clustering for Large-Scale Data. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 3939–3953. [Google Scholar] [CrossRef]
- Hammad Alharbi, H.; Kimura, M. Missing Data Imputation Using Data Generated By GAN. In Proceedings of the the 3rd International Conference on Computing and Big Data, Taichung, Taiwan, 5–7 August 2020. [Google Scholar]
- Mao, X.; Wong, R.K.; Chen, S. Matrix Completion under Low-Rank Missing Mechanism. Stat. Sin. 2018, 31, 2005–2030. [Google Scholar] [CrossRef]
- Jin, W. Research on User Electricity Behavior Analysis and Electricity Optimization Strategy Based on Electricity Big Data. Master’s Thesis, ZhengJiang University, Zhejiang University Library, Hangzhou, China, 2021. [Google Scholar]
- Bryt, O.; Elad, M. Compression of facial images using the K-SVD algorithm. J. Vis. Commun. Image Represent. 2008, 19, 270–282. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- He, H.; Li, H.; Huang, Y.; Huang, J.; Li, P. A novel efficient camera calibration approach based on K-SVD sparse dictionary learning. Measurement 2020, 159, 107798. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Rubinstein, R.; Zibulevsky, M.; Elad, M. Efficient Implementation of the K-SVD Algorithm using Batch Orthogonal Matching Pursuit. CS Technion 2008, 40. [Google Scholar]
- Mallat, S.G.; Zhifeng, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems Computers, Materials & Continua, Pacific Grove, CA, USA, 1–3 November 1993; Volume 41, pp. 40–44. [Google Scholar]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery From Random Measurements Via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Missing Type | Evaluation Metric | K-SVD | Method 1 | Method 2 | Method 3 | Method 4 | Method 5 | Method 6 | Method 7 |
|---|---|---|---|---|---|---|---|---|---|
| Consecutive | MAPE | 14.8% | 42.9% | 24.9% | 17.8% | 16.9% | 25.3% | 20.6% | 15.3% |
| CVRMSE | 22.4% | 57.9% | 35.1% | 22.4% | 20.9% | 35.4% | 29.3% | 18.5% | |
| Non-Consecutive | MAPE | 10.8% | 20.2% | 19.5% | 17.4% | 13.4% | 17.5% | 17.7% | 15.8% |
| CVRMSE | 15.7% | 22.4% | 21.7% | 25.1% | 21.1% | 20.6% | 20.8% | 23.9% |
| Sample Size | Missing Type | Evaluation Metric | K-SVD | Method 1 | Method 2 | Method 3 | Method 4 | Method 5 | Method 6 | Method 7 |
|---|---|---|---|---|---|---|---|---|---|---|
| month | Consecutive | MAPE | 9.4% | 74.9% | 20.9% | 22.8% | 21.3% | 40.3% | 19.8% | 19.7% |
| CVRMSE | 17.1% | 121.2% | 26.7% | 32.1% | 30.2% | 59.7% | 26.2% | 25.3% | ||
| Non-Consecutive | MAPE | 9.3% | 16.7% | 16.7% | 18.6% | 18.7% | 16.7% | 16.7% | 13.1% | |
| CVRMSE | 12.0% | 21.1% | 21.1% | 23.1% | 23.3% | 21.1% | 21.1% | 18.7% | ||
| Half year | Consecutive | MAPE | 29.5% | 28.2% | 28.2% | 30.5% | 30.9% | 28.6% | 28.6% | 31.2% |
| CVRMSE | 33.4% | 39.1% | 39.1% | 47.9% | 48.6% | 40.4% | 40.4% | 49.6% | ||
| Non-Consecutive | MAPE | 24.0% | 24.9% | 26.5% | 26.8% | 25.9% | 24.6% | 26.6% | 27.7% | |
| CVRMSE | 29.0% | 36.5% | 42.0% | 40.5% | 39.3% | 38.3% | 42.2% | 35.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, L.; Liu, M.; Ling, Z.; Gang, W.; Zhang, C.; Zhang, Y.; Hao, X. A Filling Method Based on K-Singular Value Decomposition (K-SVD) for Missing and Abnormal Energy Consumption Data of Buildings. Buildings 2024, 14, 696. https://doi.org/10.3390/buildings14030696
Su L, Liu M, Ling Z, Gang W, Zhang C, Zhang Y, Hao X. A Filling Method Based on K-Singular Value Decomposition (K-SVD) for Missing and Abnormal Energy Consumption Data of Buildings. Buildings. 2024; 14(3):696. https://doi.org/10.3390/buildings14030696
Chicago/Turabian StyleSu, Lihong, Manjia Liu, Zaixun Ling, Wenjie Gang, Chong Zhang, Ying Zhang, and Xiuxia Hao. 2024. "A Filling Method Based on K-Singular Value Decomposition (K-SVD) for Missing and Abnormal Energy Consumption Data of Buildings" Buildings 14, no. 3: 696. https://doi.org/10.3390/buildings14030696