
Detection of Components in Korean Apartment Complexes Using Instance Segmentation


Abstract
1. Introduction
2. Related Work
2.1. Apartment Complex Plan
2.2. Image Segmentation
2.3. Trends in Architecture Using Deep Learning
3. Materials and Methods
3.1. Apartment Complex Dataset
3.1.1. Scope of Apartment Complexes
3.1.2. Composition of Apartment Complexes
3.2. Dataset and Preprocessing
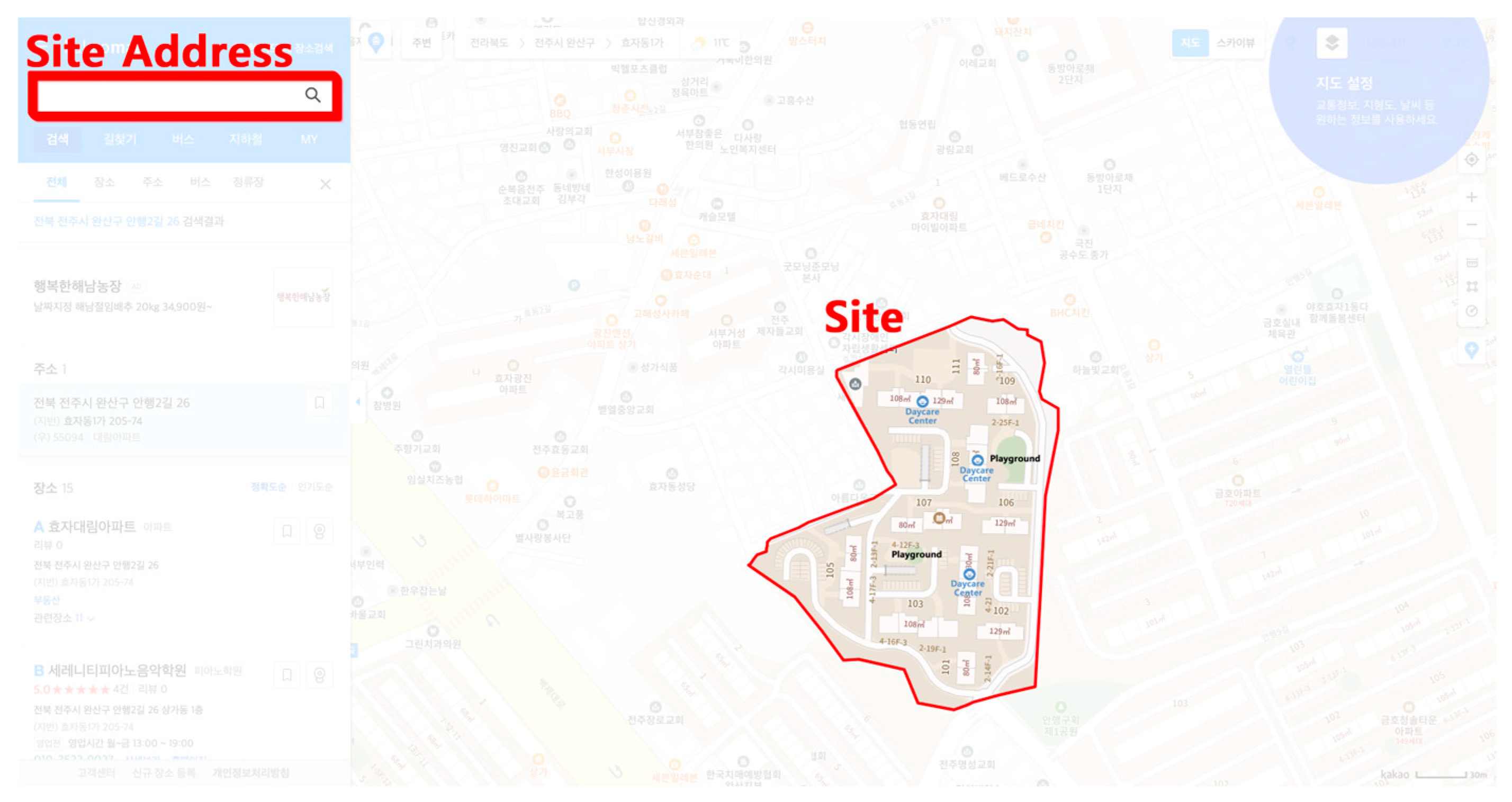
3.2.1. Image Acquisition
3.2.2. Data Annotation
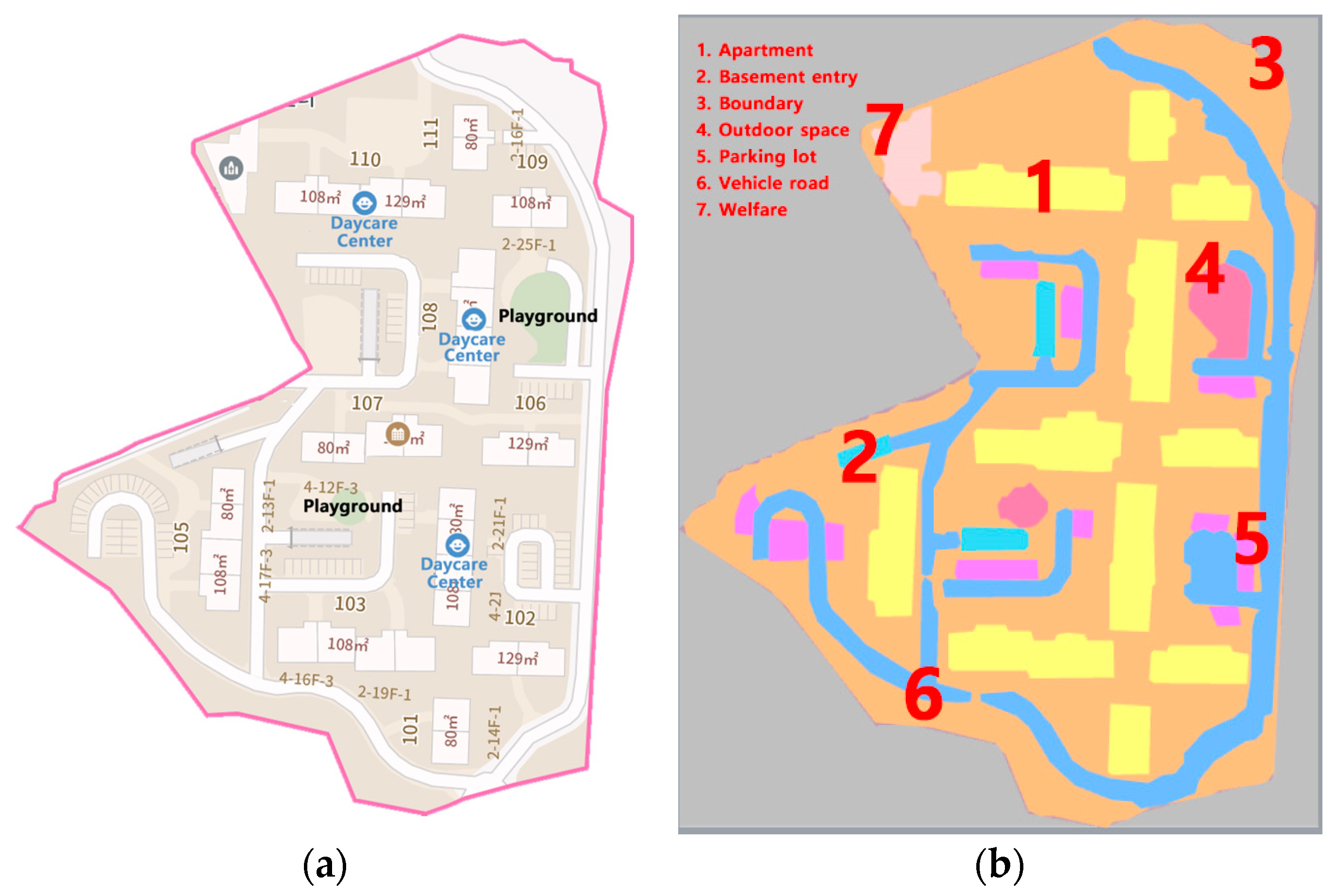
- (a)
- Label 1 represents the main buildings within the apartment complex, segmented to fit the shape;
- (b)
- Label 2 represents the basement parking entrance, connected to vehicle roads within the complex, and is indicated by hatching on the map;
- (c)
- Label 3 represents the complex boundary, which corresponds to the cadastral boundary displayed when the address is entered on the map;
- (d)
- Label 4 represents outdoor space, including playgrounds, badminton courts, exercise areas, and rest spaces;
- (e)
- Label 5 represents above-ground parking lots within the complex; these correspond to the series of rectangles on the map;
- (f)
- Label 6 represents vehicle pathways within the complex for vehicle circulation;
- (g)
- Label 7 represents welfare facilities such as daycare centers, kindergartens, senior centers, and shopping centers.
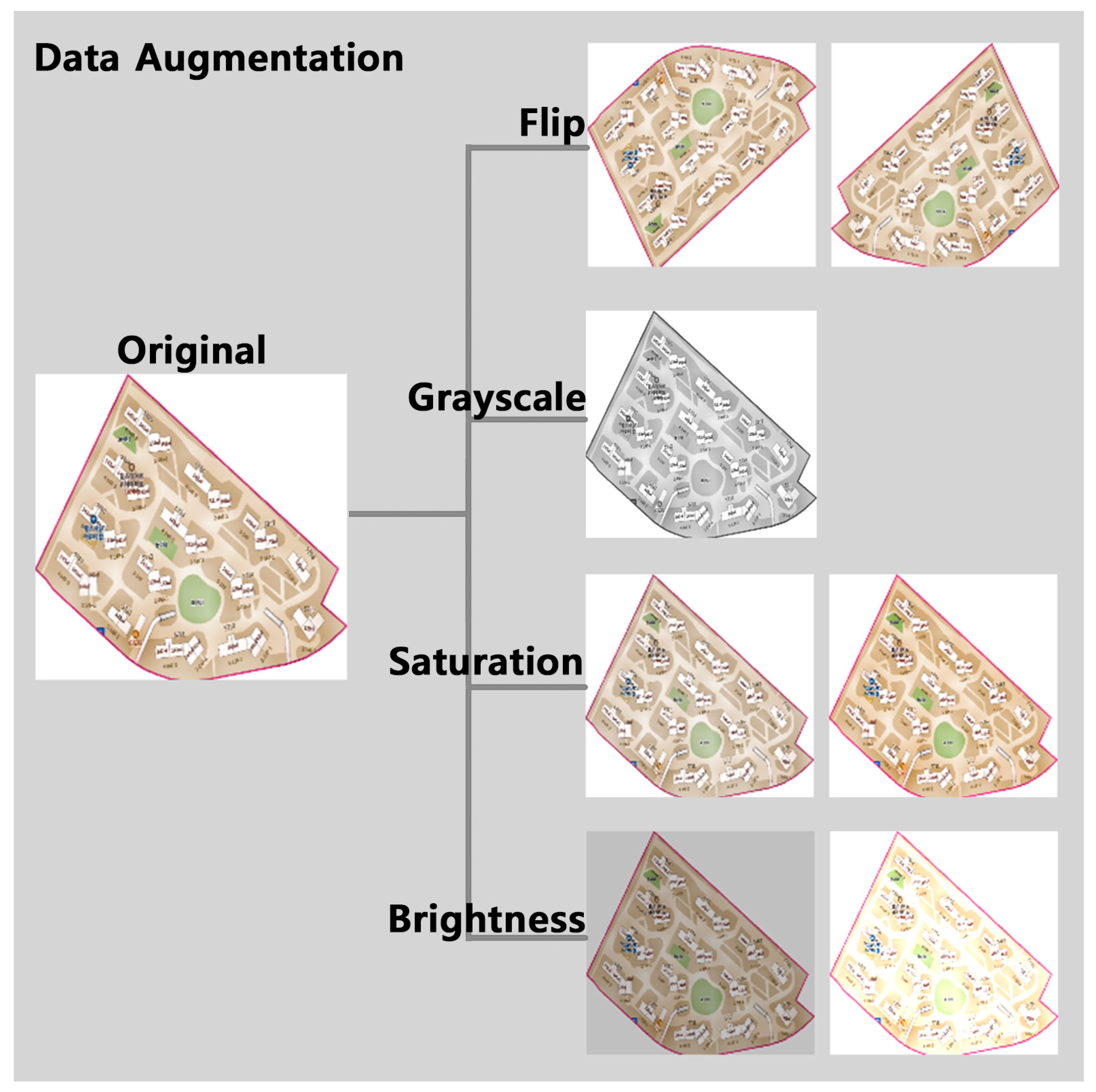
3.2.3. Data Augmentation
3.3. Research Methods
3.3.1. Comparison with YOLO Segmentation Models
3.3.2. YOLOv8 Model
4. Model Training and Evaluation
4.1. Model Training and Validation
4.2. Evaluation
4.2.1. Evaluation Matrix
4.2.2. Testing Results
5. Results and Discussion
6. Conclusions
6.1. Summary
6.2. Limitations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kang, B.S.; Kang, I.H.; Park, G.J.; Park, I.S.; Park, C.S.; Baek, H.S.; Lee, G.I. History of Korean Apartment Housing Planning; Land and Housing Research Institute: Seoul, Republic of Korea, 1999. [Google Scholar]
- Kang, B.S.; Kang, I.H.; Park, G.J.; Park, I.S. Housing Design; Land and Housing Research Institute: Seoul, Republic of Korea, 2010. [Google Scholar]
- Byun, N.; Choi, J. A typology of Korean housing units: In search of spatial configuration. J. Asian Archit. Build. Eng. 2016, 15, 41–48. [Google Scholar] [CrossRef]
- Park, T.D. A Study on the Composition of Outdoor Spaces for Community Formation within Apartment Complexes. Master’s Thesis, Seoul National University of Science and Technology, Seoul, Republic of Korea, 2006. [Google Scholar]
- Ryu, S.-M.; Hyun, C.-Y. Analysis of spatial structure for outdoor space according to the changes of pedestrian environment in the apartment complex by period. KIEAE J. 2023, 23, 77–83. [Google Scholar] [CrossRef]
- Song, H.M.; Kang, B.S.; Yoon, S.B.; Hwang, S.E. An analysis of resident satisfaction based on types of external spaces in apartment. KIEAE J. 2023, 23, 23–32. [Google Scholar] [CrossRef]
- Royal Institute of British Architects (RIBA). RIBA AI Report 2024; Royal Institute of British Architects (RIBA): London, UK, 2023. [Google Scholar]
- Jang, S.C.; Kim, C.Y. A Study on the Characteristics of Planning and Design of External Environment in Apartment House. Urban Des. 2022, 21, 5–18. [Google Scholar]
- Seo, H.; Raut, A.D.; Chen, C.; Zhang, C. Multi-label classification and automatic damage detection of masonry heritage building through CNN analysis of infrared thermal imaging. Remote Sens. 2023, 15, 2517. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. arXiv 2015, arXiv:1506.02640. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Salvador, A.; Bellver, M.; Campos, V.; Baradad, M.; Marques, F.; Torres, J.; Giro-i-Nieto, X. Recurrent neural networks for semantic instance segmentation. arXiv 2017, arXiv:1712.00617. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- COCO. Common Objects in Context. 2019. Available online: https://cocodataset.org/#home (accessed on 8 January 2020).
- Sapkota, R.; Ahmed, D.; Karkee, M. Comparing YOLOv8 and Mask RCNN for object segmentation in complex orchard environments. Qeios 2023. [Google Scholar] [CrossRef]
- Ameli, Z.; Nesheli, S.J.; Landis, E.N. Deep learning-based steel bridge corrosion segmentation and condition rating using Mask RCNN and YOLOv8. Infrastructures 2023, 9, 3. [Google Scholar] [CrossRef]
- Dumitriu, A.; Tatui, F.; Miron, F.; Ionescu, R.T.; Timofte, R. Rip current segmentation: A novel benchmark and YOLOv8 baseline results. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 1261–1271. [Google Scholar] [CrossRef]
- Ahn, E.S. Deep Learning Based Spatial Analysis Method for Korean Apartment Unit Plans. Doctoral Thesis, Seoul National University, Seoul, Republic of Korea, 2021. [Google Scholar]
- Choo, S.Y.; Seo, J.H.; Park, H.J.; Ku, H.M.; Lee, J.K.; Kim, K.T.; Park, S.H.; Kim, J.S.; Song, J.Y.; Lee, S.H.; et al. AI-Based Architectural Design Automation Technology Development; Korea Agency for Infrastructure Technology Advancement: Seoul, Republic of Korea, 2020. [Google Scholar]
- K-apt. Available online: http://www.k-apt.go.kr/cmmn/main.do (accessed on 23 October 2023).
- Kakaomap. Available online: https://map.kakao.com/ (accessed on 23 October 2023).
- Google Maps. Available online: https://www.google.com/maps/?hl=ko (accessed on 23 October 2023).
- Yoon, S.-B.; Hwang, S.-E.; Kang, B.S.; Lee, J.H. An analysis of South Korean apartment complex types by period using deep learning. Buildings 2024, 14, 776. [Google Scholar] [CrossRef]
- Roboflow. Available online: https://roboflow.com/ (accessed on 20 December 2023).
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Wang, S.; Yang, Y.; Wu, Z.; Qian, Y.; Yu, K. Data augmentation using deep generative models for embedding based speaker recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2598–2609. [Google Scholar] [CrossRef]
- Myung, H.-J.; Song, J.-W. Deep learning-based poultry object detection algorithm. J. Digit. Content Soc. 2022, 23, 1323–1330. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv8. Available online: https://docs.ultralytics.com/ko/models/yolov8/#overview (accessed on 21 December 2023).
- Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 21 December 2023).
- Harkal, S. Image Classification with YOLOv8, Medium. Available online: https://sidharkal.medium.com/image-classification-with-yolov8-40a14fe8e4bc (accessed on 21 December 2023).
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Increase in val/seg_loss and val/dfl_loss (Segmentation), Issue #2136, Ultralytics/Ultralytics, GitHub. Available online: https://github.com/ultralytics/ultralytics/issues/2136 (accessed on 21 December 2023).
- Padilla, R.; Netto, S.L.; Da Silva, E.A.B. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques Used | Value |
|---|---|
| Flipping | Horizontal, vertical |
| Grayscale | 25% of images |
| Saturation | Between −25% and +25% |
| Brightness | Between −25% and +25% |
| No. | Model | Parameters (Millions) | GFLOPs | Inference Time (ms) | Precision | Recall | mAP@0.5 | mAP @0.5:0.95 |
|---|---|---|---|---|---|---|---|---|
| 1 | YOLOv5 | 7.4 | 26.0 | 11.9 | 0.817 | 0.772 | 0.783 | 0.534 |
| 2 | YOLOv7 | 37.9 | 142.7 | 31.0 | 0.831 | 0.792 | 0.803 | 0.573 |
| 3 | YOLOv8 | 11.8 | 42.5 | 17.1 | 0.825 | 0.814 | 0.832 | 0.623 |
| Image size: 640 × 640; learning: 0.01; momentum: 0.937; decay: 0.0005; batch: 8; epoch: 10 | ||||||||
| No. | Class | Box | Mask | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | mAP@0.5 | mAP@ 0.5:0.95 | Precision | Recall | mAP@0.5 | mAP@ 0.5:0.95 | ||
| 1 | Apartment | 0.947 | 0.950 | 0.964 | 0.930 | 0.952 | 0.955 | 0.970 | 0.886 |
| 2 | Basement entry | 0.844 | 0.917 | 0.879 | 0.722 | 0.840 | 0.914 | 0.876 | 0.637 |
| 3 | Boundary | 0.984 | 0.981 | 0.980 | 0.968 | 0.961 | 0.958 | 0.942 | 0.713 |
| 4 | Outdoor space | 0.914 | 0.867 | 0.895 | 0.836 | 0.917 | 0.870 | 0.904 | 0.780 |
| 5 | Parking lot | 0.833 | 0.867 | 0.846 | 0.667 | 0.834 | 0.868 | 0.849 | 0.589 |
| 6 | Vehicle road | 0.646 | 0.547 | 0.553 | 0.391 | 0.634 | 0.536 | 0.526 | 0.297 |
| 7 | Welfare | 0.751 | 0.660 | 0.744 | 0.601 | 0.757 | 0.666 | 0.750 | 0.530 |
| All | 0.845 | 0.827 | 0.837 | 0.731 | 0.842 | 0.824 | 0.831 | 0.633 | |
| Image size: 640 × 640; learning: 0.01; momentum: 0.937; decay: 0.0005; batch: 16, epoch: 100 | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, S.-B.; Hwang, S.-E.; Kang, B.S. Detection of Components in Korean Apartment Complexes Using Instance Segmentation. Buildings 2024, 14, 2306. https://doi.org/10.3390/buildings14082306
Yoon S-B, Hwang S-E, Kang BS. Detection of Components in Korean Apartment Complexes Using Instance Segmentation. Buildings. 2024; 14(8):2306. https://doi.org/10.3390/buildings14082306
Chicago/Turabian StyleYoon, Sung-Bin, Sung-Eun Hwang, and Boo Seong Kang. 2024. "Detection of Components in Korean Apartment Complexes Using Instance Segmentation" Buildings 14, no. 8: 2306. https://doi.org/10.3390/buildings14082306
APA StyleYoon, S.-B., Hwang, S.-E., & Kang, B. S. (2024). Detection of Components in Korean Apartment Complexes Using Instance Segmentation. Buildings, 14(8), 2306. https://doi.org/10.3390/buildings14082306