
A Three-Step Computer Vision-Based Framework for Concrete Crack Detection and Dimensions Identification


Abstract
1. Introduction
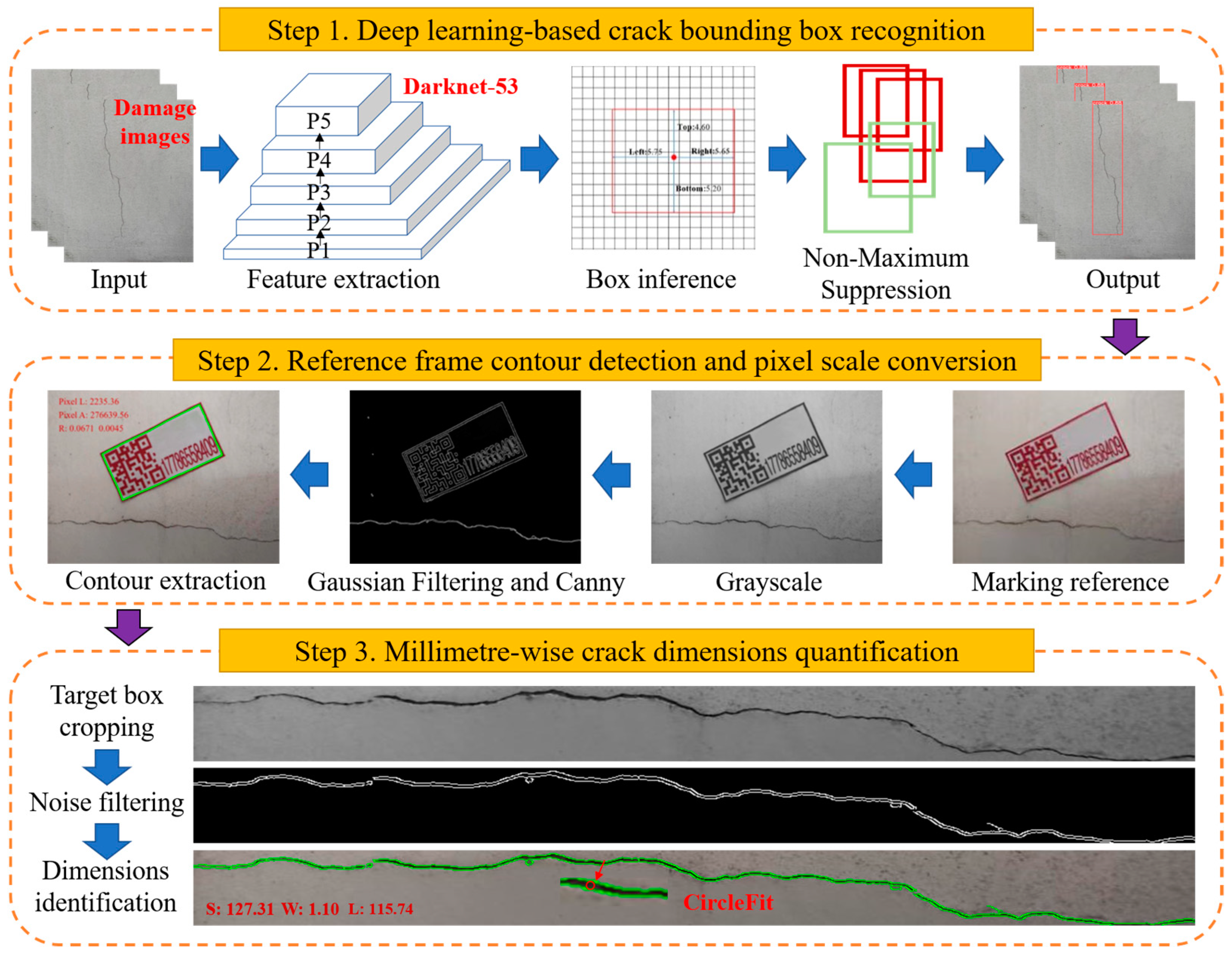
2. Methodologies
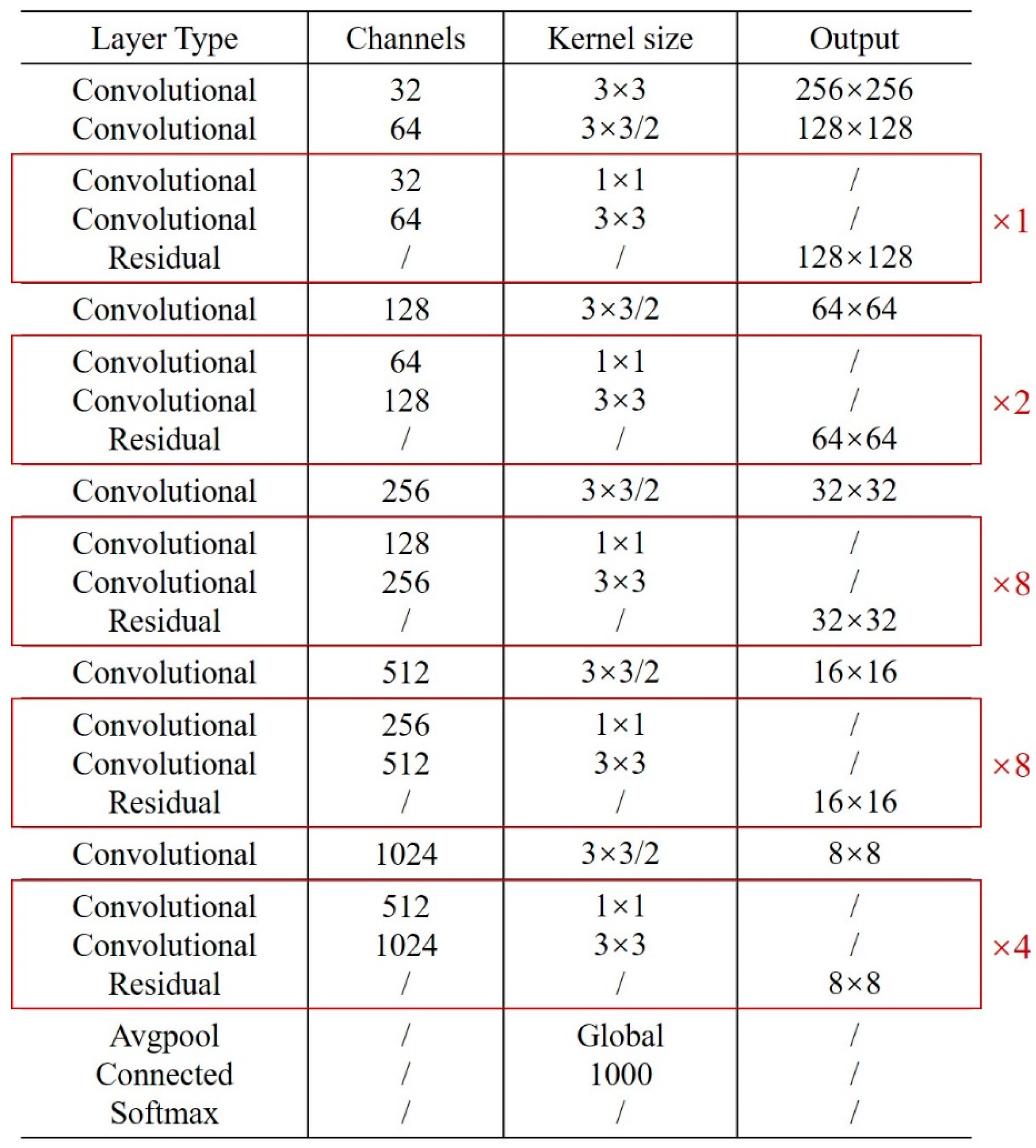
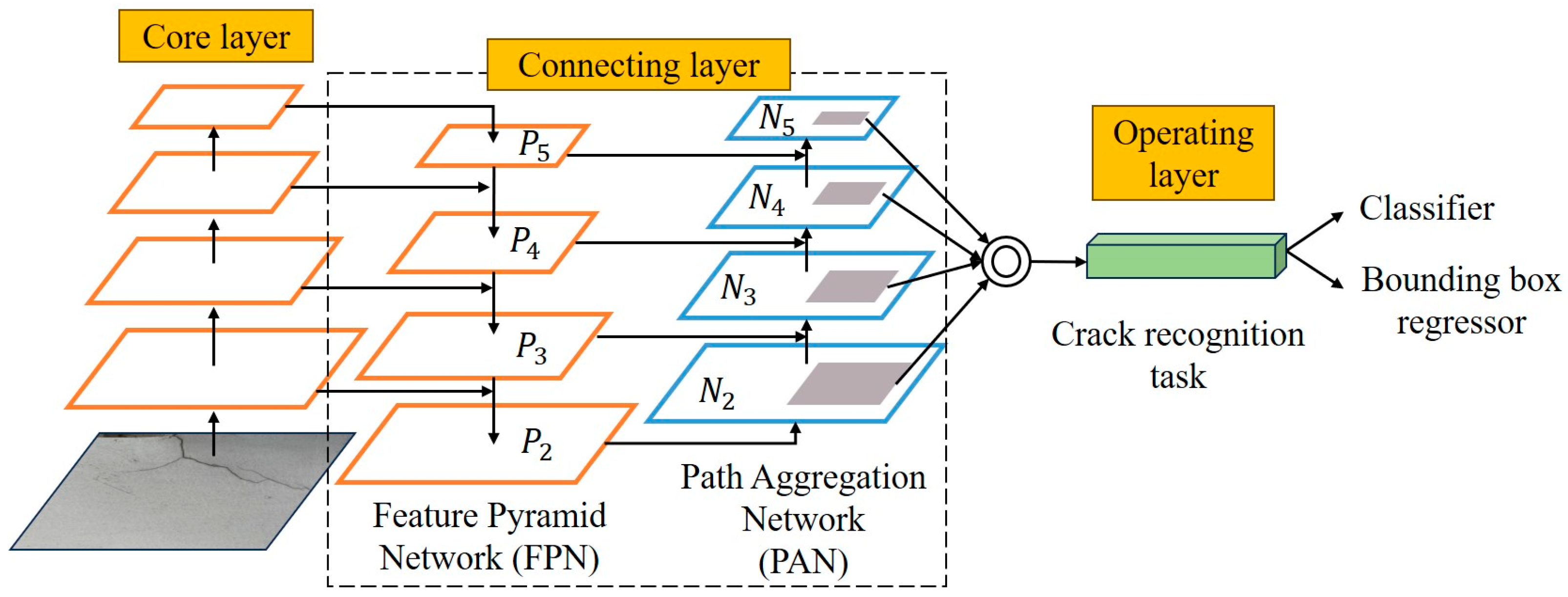
2.1. Deep Learning-Based Crack Recognition (Step One)
2.2. Fused IPTs-Based Reference Frame Contour Detection (Step Two)
2.2.1. Image Greyscaling and Filtering
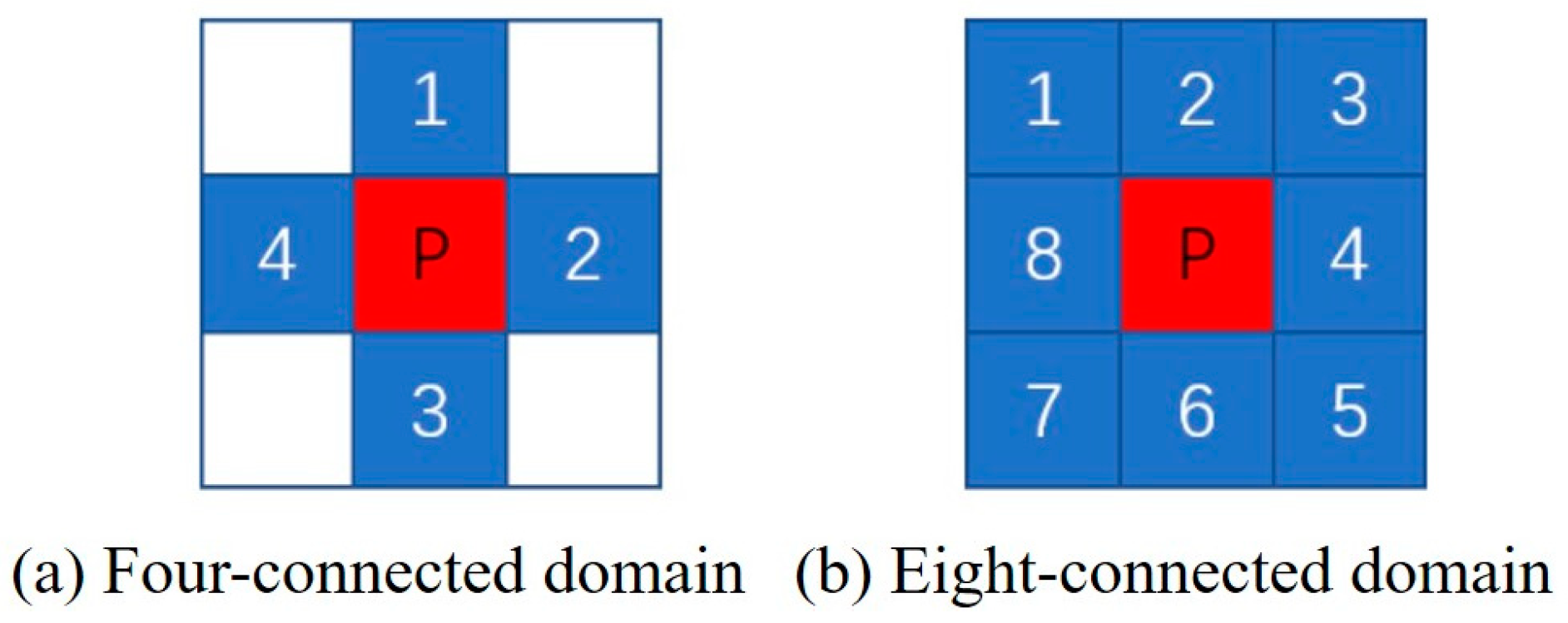
2.2.2. Reference Frame Contour Extraction and Scale Conversion
- (a)
- If fij = 0 and fi, j+1 = 1, point (i, j) is the external boundary start point; if fij ≥ 1 and fi,j+1 = 0, point (i, j) is the hole boundary start point and the number of the currently tracked boundary is updated to Bk+1.
- (b)
- According to the type of the previous boundary Bk and the current new boundary Bk+1, the parental boundary of Bk+1 can be obtained from Table 1.
- (c)
- With (i, j) as the center and (i, j + 1) as the start point, find whether there exists a 1-pixel point in the connected domain of (i, j) in a clockwise direction. If it exists, let (p1, q1) be the first 1-pixel point in a clockwise direction; otherwise, continue scanning from point (i, j + 1) until the end of the bottom-right vertex of the image.
- (d)
- With (i, j) as the center and (p1, q1) as the start point, search counter-clockwise for the existence of a 1-pixel point in the connected domain of (i, j). If it exists, let (i, j) be Bk; if it is a pixel point that has already been checked, the scanning continues from the point (i, j + 1) until it ends at the bottom right vertex of the image.
- (e)
- Save the boundary topology sequence achieved from the above procedures as the extracted contours, then calculate and sort the areas of all the contours and take the largest one as the contour of the reference frame.
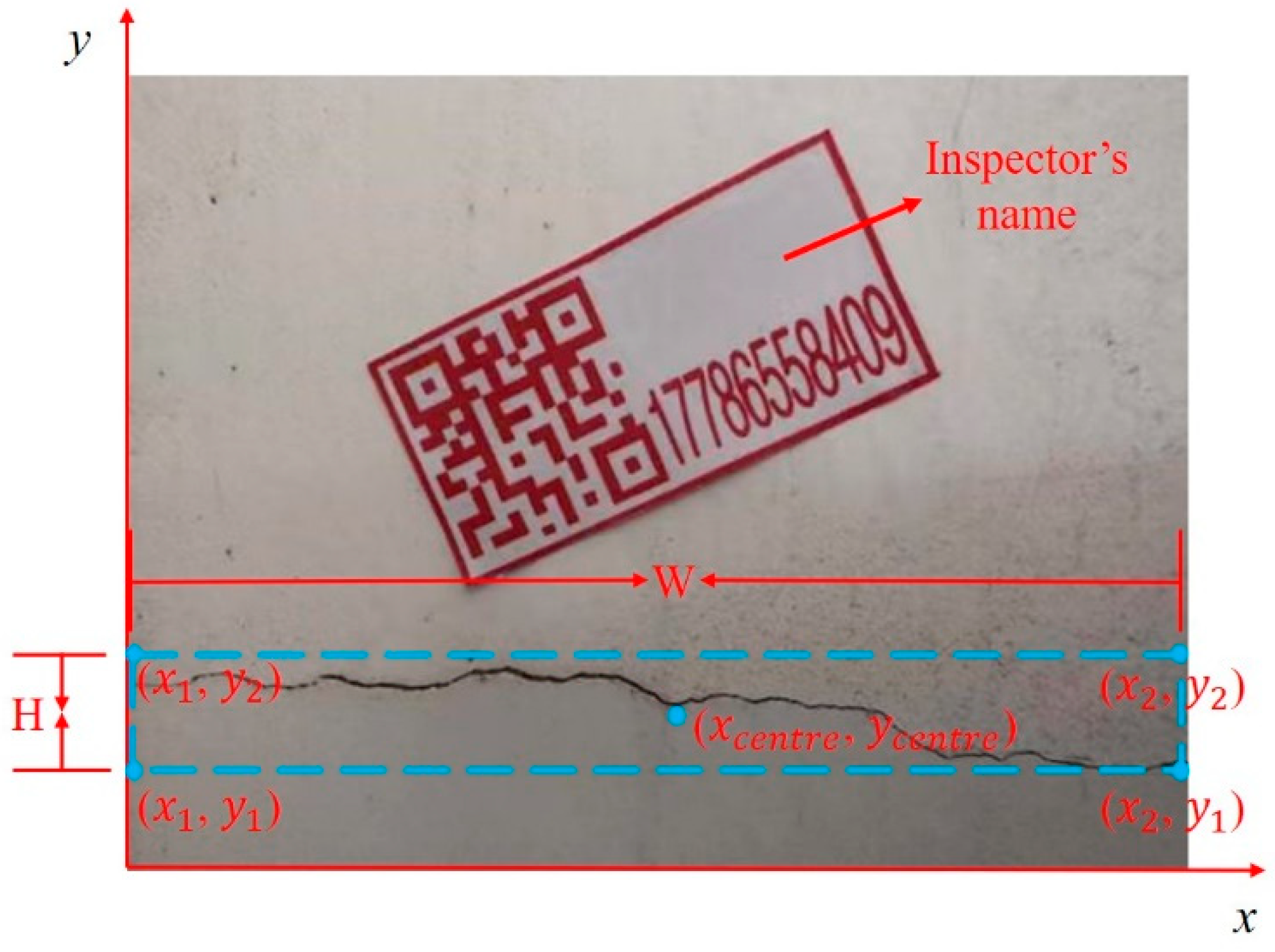
2.3. Millimeter-Wise Crack Dimensions Quantification (Step Three)
2.3.1. Target Bounding Box Cropping
2.3.2. Crack Contour Extraction and Dimensions Quantification
3. Experimental Procedures
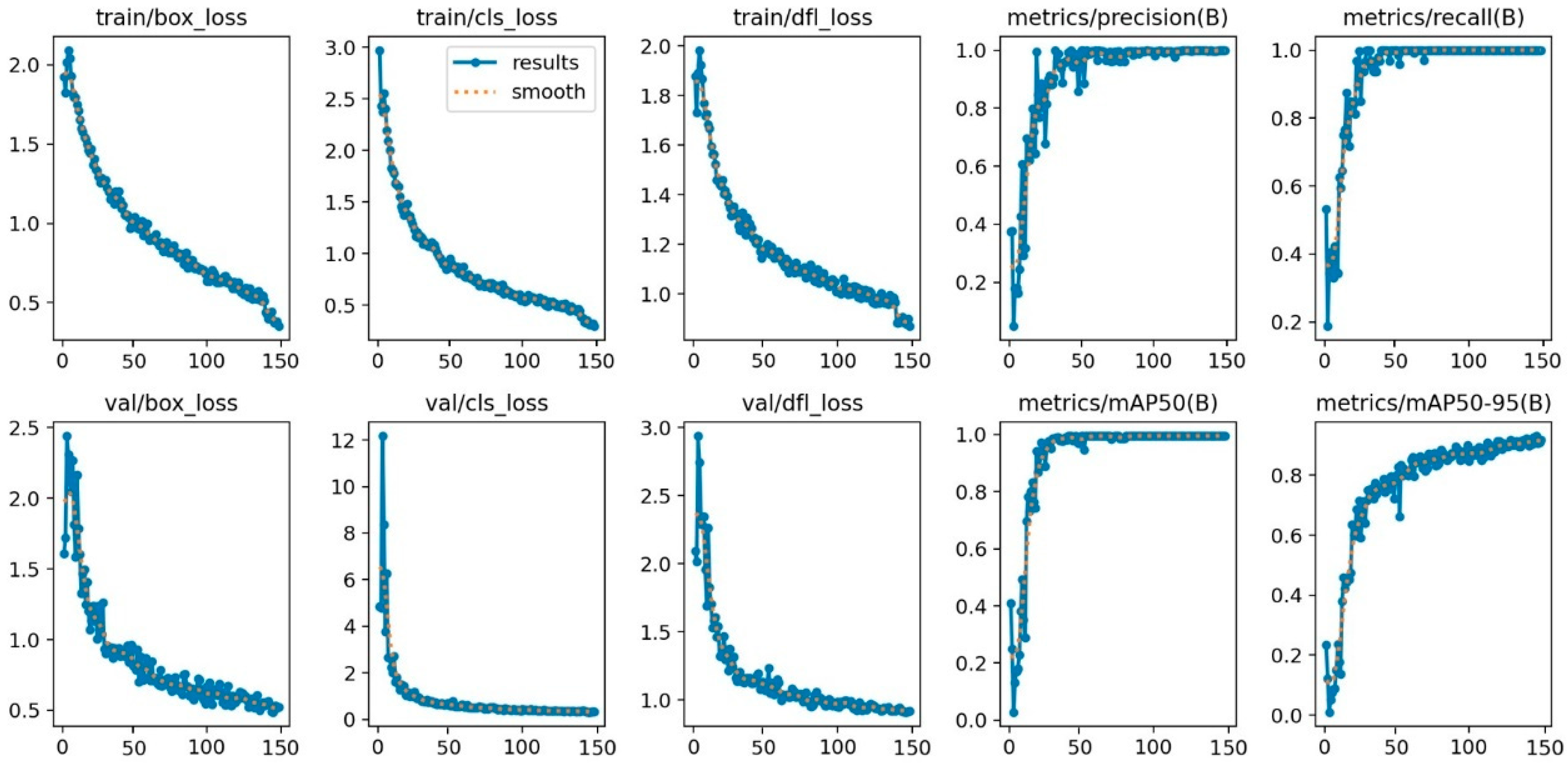
3.1. Concrete Crack Recognition Model Training
3.1.1. Setup of Image Datasets and Training Configurations
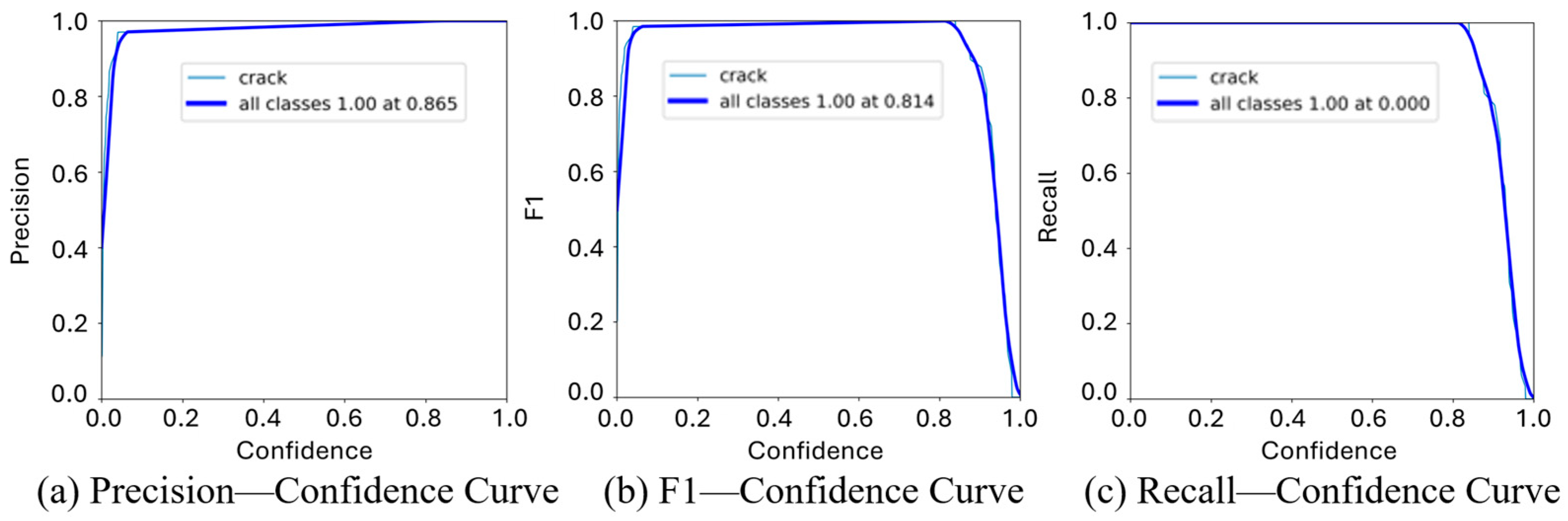
3.1.2. Indicator Analysis for Model Evaluation
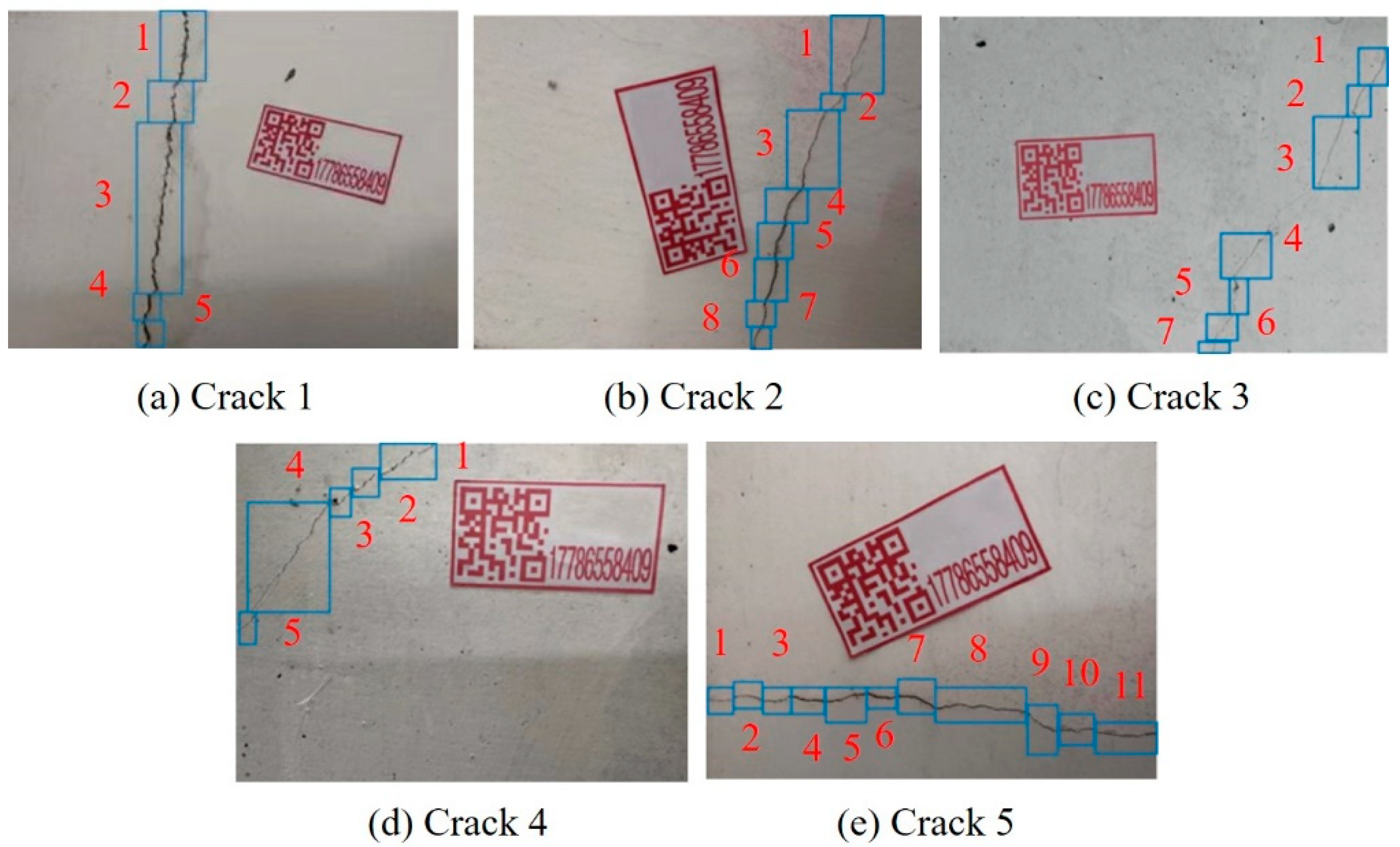
3.2. Crack Real-World Dimensions Identification
4. Result Analysis of Crack Quantification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete crack detection by multiple sequential image filtering. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Qi, Y.; Yuan, C.; Kong, Q.; Xiong, B.; Li, P. A deep learning-based vision enhancement method for UAV assisted visual inspection of concrete cracks. Smart Struct. Syst. 2021, 27, 1031–1040. [Google Scholar]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Shahrokhinasab, E.; Hosseinzadeh, N.; Monirabbasi, A.; Torkaman, S. Performance of image-based crack detection systems in concrete structures. J. Soft Comput. Civ. Eng. 2020, 4, 127–139. [Google Scholar]
- Hu, W.; Wang, W.; Ai, C.; Wang, J.; Wang, W.; Meng, X.; Liu, J.; Tao, H.; Qiu, S. Machine vision-based surface crack analysis for transportation infrastructure. Autom. Constr. 2021, 132, 103973. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Salman, M.; Mathavan, S.; Kamal, K.; Rahman, M. Pavement crack detection using the Gabor filter. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 2039–2044. [Google Scholar]
- Kapela, R.; Śniata, P.; Turkot, A.; Rybarczyk, A.; Pożarycki, A.; Rydzewski, P.; Wyczalek, M.J.; Bloch, A. Asphalt surfaced pavement cracks detection based on histograms of oriented gradients. In Proceedings of the 2015 22nd International Conference Mixed Design of Integrated Circuits & Systems (MIXDES), Toruń, Poland, 25–27 June 2015; IEEE: New York, NY, USA, 2015; pp. 579–584. [Google Scholar]
- Quintana, M.; Torres, J.; Menéndez, J.M. A simplified computer vision system for road surface inspection and maintenance. IEEE Trans. Intell. Transp. Syst. 2015, 17, 608–619. [Google Scholar] [CrossRef]
- Varadharajan, S.; Jose, S.; Sharma, K.; Wander, L.; Mertz, C. Vision for road inspection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; IEEE: New York, NY, USA, 2014; pp. 115–122. [Google Scholar]
- Fadlullah, Z.M.; Tang, F.; Mao, B.; Kato, N.; Akashi, O.; Inoue, T.; Mizutani, K. State-of-the-art deep learning: Evolving machine intelligence toward tomorrow’s intelligent network traffic control systems. IEEE Commun. Surv. Tutor. 2017, 19, 2432–2455. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Dang, J.; Shrestha, A.; Haruta, D.; Tabata, Y.; Chun, P.; Okubo, K. Site verification tests for UAV bridge inspection and damage image detection based on deep learning. In Proceedings of the 7th World Conference on Structural Control and Monitoring, Qingdao, China, 22–25 July 2018. [Google Scholar]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.-H. Crack and noncrack classification from concrete surface images using machine learning. Struct. Health Monit. 2019, 18, 725–738. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Wang, H. Pixel-wise crack detection using deep local pattern predictor for robot application. Sensors 2018, 18, 3042. [Google Scholar] [CrossRef] [PubMed]
- Da Silva, W.R.L.; de Lucena, D.S. Concrete cracks detection based on deep learning image classification. Multidiscip. Digit. Publ. Inst. Proc. 2018, 2, 489. [Google Scholar]
- Bang, S.; Park, S.; Kim, H.; Kim, H. A deep residual network with transfer learning for pixel-level road crack detection. In Proceedings of the International Symposium on Automation and Robotics in Construction, ISARC, Berlin, Germany, 20–25 July 2018; IAARC Publications: Berlin, Germany, 2018; Volume 35, pp. 1–4. [Google Scholar]
- Yeum, C.M.; Dyke, S.J.; Ramirez, J. Visual data classification in post-event building reconnaissance. Eng. Struct. 2018, 155, 16–24. [Google Scholar] [CrossRef]
- Elshafey, A.A.; Dawood, N.; Marzouk, H.; Haddara, M. Crack width in concrete using artificial neural networks. Eng. Struct. 2013, 52, 676–686. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Practical image measurement of crack width for real concrete structure. Electron. Commun. Jpn. 2009, 92, 1–12. [Google Scholar] [CrossRef]
- Cho, H.; Yoon, H.-J.; Jung, J.-Y. Image-based crack detection using crack width transform (CWT) algorithm. IEEE Access 2018, 6, 60100–60114. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack detection and comparison study based on faster R-CNN and mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Attard, L.; Debono, C.J.; Valentino, G.; Di Castro, M.; Masi, A.; Scibile, L. Automatic crack detection using mask R-CNN. In Proceedings of the 2019 11th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 23–25 September 2019; IEEE: New York, NY, USA, 2019; pp. 152–157. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Nie, M.; Wang, C. Pavement Crack Detection based on yolo v3. In Proceedings of the 2019 2nd International Conference on Safety Produce Informatization (IICSPI), Chongqing, China, 28–30 November 2019; IEEE: Chengdu, China, 2019; pp. 327–330. [Google Scholar]
- Zhang, Y.; Huang, J.; Cai, F. On Bridge Surface Crack Detection Based on an Improved YOLO v3 Algorithm. IFAC-PapersOnLine 2020, 53, 8205–8210. [Google Scholar] [CrossRef]
- Park, S.E.; Eem, S.-H.; Jeon, H. Concrete crack detection and quantification using deep learning and structured light. Constr. Build. Mater. 2020, 252, 119096. [Google Scholar] [CrossRef]
- Shan, B.; Zheng, S.; Ou, J. A stereovision-based crack width detection approach for concrete surface assessment. KSCE J. Civ. Eng. 2016, 20, 803–812. [Google Scholar] [CrossRef]
- Yuan, C.; Xiong, B.; Li, X.; Sang, X.; Kong, Q. A novel intelligent inspection robot with deep stereo vision for three-dimensional concrete damage detection and quantification. Struct. Health Monit. 2022, 21, 788–802. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Safie, S.I.; Kamal, N.S.A.; Yusof, E.M.M.; Tohid, M.Z.-W.M.; Jaafar, N.H. Comparison of SqueezeNet and DarkNet-53 based YOLO-V3 Performance for Beehive Intelligent Monitoring System. In Proceedings of the 2023 IEEE 13th Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 20–21 May 2023; IEEE: New York, NY, USA, 2023; pp. 62–65. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Ito, K.; Xiong, K. Gaussian filters for nonlinear filtering problems. IEEE Trans. Autom. Control. 2000, 45, 910–927. [Google Scholar] [CrossRef]
- Samanta, S.; Pal, M. Fuzzy Threshold Graphs. CiiT Int. J. Fuzzy Syst. 2011, 3, 360–364. [Google Scholar]
- Manuaba, P.; Indah, K.A.T. The object detection system of balinese script on traditional Balinese manuscript with findcontours method. Matrix J. Manaj. Teknol. Dan Inform. 2021, 11, 177–184. [Google Scholar] [CrossRef]
- Gervasi, O.; Caprini, L.; Maccherani, G. Virtual exhibitions on the web: From a 2d map to the virtual world. In Proceedings of the Computational Science and Its Applications. ICCSA 2013: 13th International Conference, Ho Chi Minh City, Vietnam, 24–27 June 2013; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2013; pp. 708–722. [Google Scholar]
- Illingworth, J.; Kittler, J. A Survey of the Hough Transform. Comput. Vis. Graph. Image Process. 1988, 44, 30. [Google Scholar] [CrossRef]
- Özgenel, Ç.F. Concrete Crack Images for Classification, Version 2. 2019. Available online: https://data.mendeley.com/datasets/5y9wdsg2zt/2 (accessed on 23 June 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Boundaries | Interpretation |
|---|---|
| External boundary | Let S1 be a 1-connected domain and S2 be a 0-connected domain, the boundary between S2 and S1 is the external boundary when S2 directly surrounds S1. |
| Hole Boundary | Let S1 be a 1-connected domain and S2 be a 0-connected domain, the boundary between S1 and S2 is a hole boundary when S1 directly surrounds S2. |
| Parental Boundary | Let S1 and S3 be 1-connected domains and S2 be a 0-connected domain; let the boundary between S1 and S2 be B1 and the boundary between S2 and S3 be B2 when S2 is directly around S1 and S3 is directly around S2, then B2 is the parental boundary of B1. |
| Crack No. | Length/Pixel | Area/Pixel | Length Conversion Scale | Area Conversion Scale |
|---|---|---|---|---|
| 1 | 782.51 | 6084.90 | 0.2001 | 0.0404 |
| 2 | 719.55 | 6182.03 | 0.1468 | 0.0217 |
| 3 | 828.32 | 2053.18 | 0.1988 | 0.0393 |
| 4 | 644.34 | 3126.55 | 0.1342 | 0.0177 |
| 5 | 899.63 | 7034.25 | 0.1338 | 0.0181 |
| Crack No. | Quantitative Length/mm | Quantitative Area/mm2 | Maximum Width/mm | True Length/mm | True Width/mm | Length Error/% | Width Error/% |
|---|---|---|---|---|---|---|---|
| 1 | 156.58 | 245.83 | 1.77 | 167.50 | 1.83 | 6.52 | 3.28 |
| 2 | 105.63 | 134.15 | 1.47 | 112.25 | 1.52 | 5.90 | 3.29 |
| 3 | 164.67 | 80.69 | 0.70 | 155.90 | 0.65 | 5.63 | 7.69 |
| 4 | 86.47 | 55.34 | 0.84 | 82.60 | 0.78 | 4.69 | 7.33 |
| 5 | 120.37 | 127.32 | 1.26 | 124.05 | 1.30 | 2.97 | 3.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Y.; Ding, Z.; Luo, Y.; Ma, Z. A Three-Step Computer Vision-Based Framework for Concrete Crack Detection and Dimensions Identification. Buildings 2024, 14, 2360. https://doi.org/10.3390/buildings14082360
Qi Y, Ding Z, Luo Y, Ma Z. A Three-Step Computer Vision-Based Framework for Concrete Crack Detection and Dimensions Identification. Buildings. 2024; 14(8):2360. https://doi.org/10.3390/buildings14082360
Chicago/Turabian StyleQi, Yanzhi, Zhi Ding, Yaozhi Luo, and Zhi Ma. 2024. "A Three-Step Computer Vision-Based Framework for Concrete Crack Detection and Dimensions Identification" Buildings 14, no. 8: 2360. https://doi.org/10.3390/buildings14082360
APA StyleQi, Y., Ding, Z., Luo, Y., & Ma, Z. (2024). A Three-Step Computer Vision-Based Framework for Concrete Crack Detection and Dimensions Identification. Buildings, 14(8), 2360. https://doi.org/10.3390/buildings14082360