
Advancing Interior Design with AI: Controllable Stable Diffusion for Panoramic Image Generation


Abstract
1. Introduction
1.1. Background and Motivation
1.2. Problem Statement and Objectives
2. Literature Review
2.1. Architectural Design
2.2. Stable Diffusion Model
2.3. LoRA Fine-Tuning
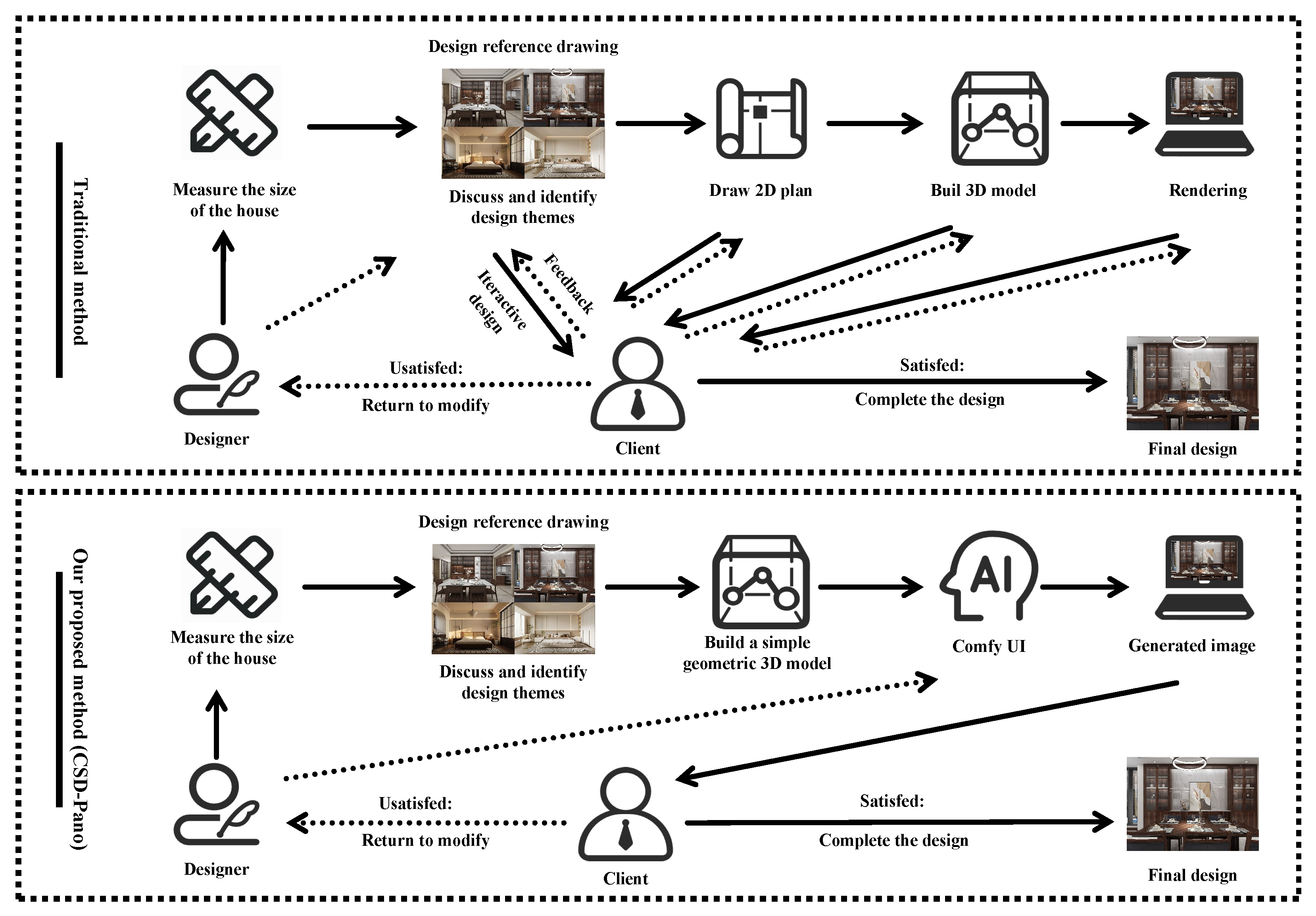
3. Methodology
3.1. Research Framework
3.2. Collect Building Datasets
3.3. Structural Controller
3.4. Style Controller
3.5. Panoramic Loss Function
4. Experiments and Results
4.1. Experimental Settings
4.2. PSD-4
4.3. Subjective Assessment
4.4. Objective Assessment
4.5. Ablation Study on CSD-Pano Framework
4.6. The Diversity of Generated Designs
4.7. Generate Design Details
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, S.; Zhou, P.; Xiong, Y.; Ma, C.; Wu, D.; Lu, W. Strategies for Driving the Future of Educational Building Design in Terms of Indoor Thermal Environments: A Comprehensive Review of Methods and Optimization. Buildings 2025, 15, 816. [Google Scholar] [CrossRef]
- Emad, S.; Aboulnaga, M.; Wanas, A.; Abouaiana, A. The Role of Artificial Intelligence in Developing the Tall Buildings of Tomorrow. Buildings 2025, 15, 749. [Google Scholar] [CrossRef]
- Thampanichwat, C.; Wongvorachan, T.; Sirisakdi, L.; Somngam, P.; Petlai, T.; Singkham, S.; Bhutdhakomut, B.; Jinjantarawong, N. The Architectural Language of Biophilic Design After Architects Use Text-to-Image AI. Buildings 2025, 15, 662. [Google Scholar] [CrossRef]
- Song, Y.; Wang, S. A Survey and Research on the Use of Artificial Intelligence by Chinese Design-College Students. Buildings 2024, 14, 2957. [Google Scholar] [CrossRef]
- Gür, M.; Çorakbaş, F.K.; Atar, İ.S.; Çelik, M.G.; Maşat, İ.; Şahin, C. Communicating AI for Architectural and Interior Design: Reinterpreting Traditional Iznik Tile Compositions through AI Software for Contemporary Spaces. Buildings 2024, 14, 2916. [Google Scholar] [CrossRef]
- Adewale, B.A.; Ene, V.O.; Ogunbayo, B.F.; Aigbavboa, C.O. A Systematic Review of the Applications of AI in a Sustainable Building’s Lifecycle. Buildings 2024, 14, 2137. [Google Scholar] [CrossRef]
- Wang, Y.T.; Liang, C.; Huai, N.; Chen, J.; Zhang, C.J. A Survey of Personalized Interior Design. Comput. Graph. Forum 2023, 42, e14844. [Google Scholar] [CrossRef]
- Delgado, J.M.D.; Oyedele, L.; Ajayi, A.; Akanbi, L.; Akinade, O.; Bilal, M.; Owolabi, H. Robotics and automated systems in construction: Understanding industry-specific challenges for adoption. J. Build. Eng. 2019, 26, 100868. [Google Scholar] [CrossRef]
- Wang, D.; Li, J.; Ge, Z.; Han, J. A computational approach to generate design with specific style. In Proceedings of the Design Society: 23rd International Conference on Engineering Design (ICED21), Gothenburg, Sweden, 16–20 August 2021; Volume 1, pp. 21–30. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, T. Personalized Interiors at Scale: Leveraging AI for Efficient and Customizable Design Solutions. arXiv 2024, arXiv:2405.19188. [Google Scholar]
- Sinha, M.; Fukey, L.N. Sustainable Interior Designing in the 21st Century—A Review. ECS Trans. 2022, 107, 6801–6823. [Google Scholar] [CrossRef]
- Chen, L.; Wang, P.; Dong, H.; Shi, F.; Han, J.; Guo, Y.; Childs, P.R.N.; Xiao, J.; Wu, C. An artificial intelligence based data-driven approach for design ideation. J. Vis. Commun. Image Represent. 2019, 61, 10–22. [Google Scholar] [CrossRef]
- Le, M.-H.; Chu, C.-B.; Le, K.-D.; Nguyen, T.V.; Tran, M.-T.; Le, T.-N. VIDES: Virtual Interior Design via Natural Language and Visual Guidance. In Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Brisbane, Australia, 17–21 October 2023; IEEE: Brisbane, Australia, 2023; pp. 689–694. [Google Scholar]
- Chen, J.; Shao, Z.; Hu, B. Generating Interior Design from Text: A New Diffusion Model-Based Method for Efficient Creative Design. Buildings 2023, 13, 1861. [Google Scholar] [CrossRef]
- Liu, S.; Li, Z.; Teng, Y.; Dai, L. A Dynamic Simulation Study on the Sustainability of Prefabricated Buildings. Sustain. Cities Soc. 2022, 77, 103551. [Google Scholar] [CrossRef]
- Luo, L.; Mao, C.; Shen, L.; Li, Z. Risk Factors Affecting Practitioners’ Attitudes Toward the Implementation of an Industrialized Building System: A Case Study from China. Eng. Constr. Archit. Manag. 2015, 22, 622–643. [Google Scholar] [CrossRef]
- Gao, H.; Koch, C.; Wu, Y. Building information modelling based building energy modelling: A review. Appl. Energy 2019, 238, 320–343. [Google Scholar] [CrossRef]
- Zikirov, M.C.; Qosimova, S.F.; Qosimov, L.M. Direction of Modern Design Activities. Asian J. Multidimens. Res. (AJMR) 2021, 10, 11–18. [Google Scholar] [CrossRef]
- Idi, D.B.; Khaidzir, K.A.B.M. Concept of Creativity and Innovation in Architectural Design Process. Int. J. Innov. Manag. Technol. 2015, 6, 16. Available online: https://www.ijimt.org/vol6/566-A10041.pdf (accessed on 16 March 2025). [CrossRef]
- Borji, A. Generated Faces in the Wild: Quantitative Comparison of Stable Diffusion, Midjourney, and DALL-E 2. arXiv 2022, arXiv:2210.00586. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, C.; Zhang, M.; Kweon, I.S.; Kim, J. Text-to-image Diffusion Models in Generative AI: A Survey. arXiv 2023, arXiv:2303.07909. [Google Scholar]
- Chang, L.W.; Bao, W.; Hou, Q.; Jiang, C.; Zheng, N.; Zhong, Y.; Zhang, X.; Song, Z.; Yao, C.; Jiang, Z.; et al. FLUX: Fast Software-Based Communication Overlap on GPUs Through Kernel Fusion. arXiv 2024, arXiv:2406.06858. [Google Scholar]
- Cheng, S.I.; Chen, Y.J.; Chiu, W.C.; Tseng, H.Y.; Lee, H.Y. Adaptively-Realistic Image Generation from Stroke and Sketch with Diffusion Model. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 4054–4062. Available online: https://openaccess.thecvf.com/content/WACV2023/html/Cheng_Adaptively-Realistic_Image_Generation_From_Stroke_and_Sketch_With_Diffusion_Model_WACV_2023_paper.html (accessed on 16 March 2025).
- Shao, Z.; Chen, J.; Zeng, H.; Hu, W.; Xu, Q.; Zhang, Y. A new approach to interior design: Generating creative interior design videos of various design styles from indoor texture-free 3D models. Buildings 2024, 14, 1528. [Google Scholar] [CrossRef]
- Li, C.; Zhang, T.; Du, X.; Zhang, Y.; Xie, H. Generative AI for Architectural Design: A Literature Review. arXiv 2024, arXiv:2404.01335. [Google Scholar]
- Ashour, M.; Mahdiyar, A.; Haron, S.H. A comprehensive review of deterrents to the practice of sustainable interior architecture and design. Sustainability 2021, 13, 10403. [Google Scholar] [CrossRef]
- Colenberg, S.; Jylhä, T. Identifying interior design strategies for healthy workplaces—A literature review. J. Corp. Real Estate 2021, 24, 173–189. [Google Scholar] [CrossRef]
- Ibadullaev, I.R.; Atoshov, S.B. The Effects of Colors on the Human Mind in Interior Design. Indones. J. Innov. Stud. 2019, 7, 27. [Google Scholar] [CrossRef]
- Bettaieb, D.M.; Alsabban, R. Emerging living styles post-COVID-19: Housing flexibility as a fundamental requirement for apartments in Jeddah. Archnet-IJAR Int. J. Archit. Res. 2021, 15, 28–50. [Google Scholar] [CrossRef]
- Park, B.H.; Hyun, K.H. Analysis of pairings of colors and materials of furnishings in interior design with a data-driven framework. J. Comput. Des. Eng. 2022, 9, 2419–2438. [Google Scholar] [CrossRef]
- Chen, J.; Shao, Z.; Cen, C.; Li, J. HyNet: A novel hybrid deep learning approach for efficient interior design texture retrieval. Multimed. Tools Appl. 2024, 83, 28125–28145. [Google Scholar] [CrossRef]
- Bao, Z.; Laovisutthichai, V.; Tan, T.; Wang, Q.; Lu, W. Design for manufacture and assembly (DfMA) enablers for offsite interior design and construction. Build. Res. Inf. 2021, 50, 325–338. [Google Scholar] [CrossRef]
- Chen, J.; Wang, D.; Shao, Z.; Zhang, X.; Ruan, M.; Li, H.; Li, J. Using Artificial Intelligence to Generate Master-Quality Architectural Designs from Text Descriptions. Buildings 2023, 13, 2285. [Google Scholar] [CrossRef]
- Chen, J.; Shao, Z.; Zhu, H.; Chen, Y.; Li, Y.; Zeng, Z.; Yang, Y.; Wu, J.; Hu, B. Sustainable interior design: A new approach to intelligent design and automated manufacturing based on Grasshopper. Comput. Ind. Eng. 2023, 183, 109509. [Google Scholar] [CrossRef]
- Abd Hamid, B.A.; Taib, M.Z.; Razak, A.A.; Embi, M.R. Building Information Modelling: Challenges and Barriers in Implement of BIM for Interior Design Industry in Malaysia. IOP Conf. Ser. Earth Environ. Sci. 2018, 140, 012002. [Google Scholar] [CrossRef]
- Shen, F.; Wang, C.; Gao, J.; Guo, Q.; Dang, J.; Tang, J.; Chua, T.-S. Long-Term TalkingFace Generation via Motion-Prior Conditional Diffusion Model. arXiv 2025, arXiv:2502.09533. [Google Scholar]
- Shen, F.; Tang, J. IMAGPose: A Unified Conditional Framework for Pose-Guided Person Generation. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 10–15 December 2024; Available online: https://proceedings.neurips.cc/paper_files/paper/2024/file/0bd32794b26cfc99214b89313764da8e-Paper-Conference.pdf (accessed on 16 March 2025).
- Shen, F.; Jiang, X.; He, X.; Ye, H.; Wang, C.; Du, X.; Li, Z.; Tang, J. IMAGDressing-v1: Customizable Virtual Dressing. arXiv 2024, arXiv:2407.12705. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. Available online: https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html (accessed on 16 March 2025).
- Brisco, R.; Hay, L.; Dhami, S. Exploring the Role of Text-to-Image AI in Concept Generation. Proc. Des. Soc. 2023, 3, 1835–1844. [Google Scholar] [CrossRef]
- Yang, B.; Gu, S.; Zhang, B.; Zhang, T.; Chen, X.; Sun, X.; Chen, D.; Wen, F. Paint by Example: Exemplar-Based Image Editing with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18381–18391. Available online: https://openaccess.thecvf.com/content/CVPR2023/html/Yang_Paint_by_Example_Exemplar-Based_Image_Editing_With_Diffusion_Models_CVPR_2023_paper.html (accessed on 16 March 2025).
- Shen, F.; Ye, H.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models. arXiv 2023, arXiv:2310.06313. [Google Scholar]
- Vartiainen, H.; Tedre, M. Using artificial intelligence in craft education: Crafting with text-to-image generative models. Digit. Creat. 2023, 34, 1–21. [Google Scholar] [CrossRef]
- Shamsian, A.; Navon, A.; Fetaya, E.; Chechik, G. Personalized Federated Learning Using Hypernetworks. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 9489–9502. Available online: https://proceedings.mlr.press/v139/shamsian21a.html (accessed on 16 March 2025).
- Lee, J.; Cho, K.; Kiela, D. Countering Language Drift via Visual Grounding. arXiv 2019, arXiv:1909.04499. [Google Scholar]
- Voynov, A.; Aberman, K.; Cohen-Or, D. Sketch-Guided Text-to-Image Diffusion Models. In Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023; Association for Computing Machinery: New York, NY, USA, 2023; Volume 139, pp. 8162–8171. [Google Scholar] [CrossRef]
- Li, Y.; Liu, H.; Wu, Q.; Mu, F.; Yang, J.; Gao, J.; Li, C.; Lee, Y.J. GLIGEN: Open-Set Grounded Text-to-Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 22511–22521. Available online: https://openaccess.thecvf.com/content/CVPR2023/html/Li_GLIGEN_Open-Set_Grounded_Text-to-Image_Generation_CVPR_2023_paper.html (accessed on 16 March 2025).
- Zhang, L.; Rao, A.; Agrawala, M. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 3836–3847. Available online: https://openaccess.thecvf.com/content/ICCV2023/papers/Zhang_Adding_Conditional_Control_to_Text-to-Image_Diffusion_Models_ICCV_2023_paper.pdf (accessed on 16 March 2025).
- Kawar, B.; Zada, S.; Lang, O.; Tov, O.; Chang, H.; Dekel, T.; Mosseri, I.; Irani, M. Imagic: Text-Based Real Image Editing with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 6007–6017. Available online: https://openaccess.thecvf.com/content/CVPR2023/papers/Kawar_Imagic_Text-Based_Real_Image_Editing_With_Diffusion_Models_CVPR_2023_paper.pdf (accessed on 16 March 2025).
- Otani, M.; Togashi, R.; Sawai, Y.; Ishigami, R.; Nakashima, Y.; Rahtu, E.; Heikkilä, J.; Satoh, S. Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 14277–14286. Available online: https://openaccess.thecvf.com/content/CVPR2023/html/Otani_Toward_Verifiable_and_Reproducible_Human_Evaluation_for_Text-to-Image_Generation_CVPR_2023_paper.html (accessed on 16 March 2025).
- Shen, F.; Ye, H.; Liu, S.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Boosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models. arXiv 2024, arXiv:2407.02482. [Google Scholar] [CrossRef]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022; pp. 1–15. [Google Scholar]
- Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A.H.; Chechik, G.; Cohen-Or, D. An Image is Worth One Word: Personalizing Text-to-Image Generation Using Textual Inversion. arXiv 2022, arXiv:2208.01618. [Google Scholar]
- Gao, B.; Ren, J.; Shen, F.; Wei, M.; Huang, Z. Exploring Warping-Guided Features via Adaptive Latent Diffusion Model for Virtual Try-On. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME), Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. arXiv 2022, arXiv:2208.12242. [Google Scholar]
- Ye, H.; Zhang, J.; Liu, S.; Han, X.; Yang, W. IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models. arXiv 2023, arXiv:2308.06721. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009; Available online: https://web.stanford.edu/~hastie/ElemStatLearn/ (accessed on 16 March 2025).
- Wang, W.; Wang, X.; Xue, C. Aesthetics Evaluation Method of Chinese Characters Based on Region Segmentation and Pixel Calculation. In Intelligent Human Systems Integration (IHSI 2023): Integrating People and Intelligent Systems; Ahram, T., Karwowski, W., Di Bucchianico, P., Taiar, R., Casarotto, L., Costa, P., Eds.; AHFE International: Orlando, FL, USA, 2023; Volume 69, pp. 1234–1243. [Google Scholar] [CrossRef]
- Wang, L.; Xue, C. A Simple and Automatic Typesetting Method Based on BM Value of Interface Aesthetics and Genetic Algorithm. In Advances in Usability, User Experience, Wearable and Assistive Technology: Proceedings of the AHFE 2021 Virtual Conferences on Usability and User Experience, Human Factors and Wearable Technologies, Human Factors in Virtual Environments and Game Design, and Human Factors and Assistive Technology; Ahram, T., Karwowski, W., Di Bucchianico, P., Taiar, R., Casarotto, L., Costa, P., Eds.; Springer: Cham, Switzerland, 2021; Volume 69, pp. 931–938. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021), Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. Available online: https://proceedings.mlr.press/v139/radford21a.html (accessed on 16 March 2025).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. Available online: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 16 March 2025). [CrossRef]




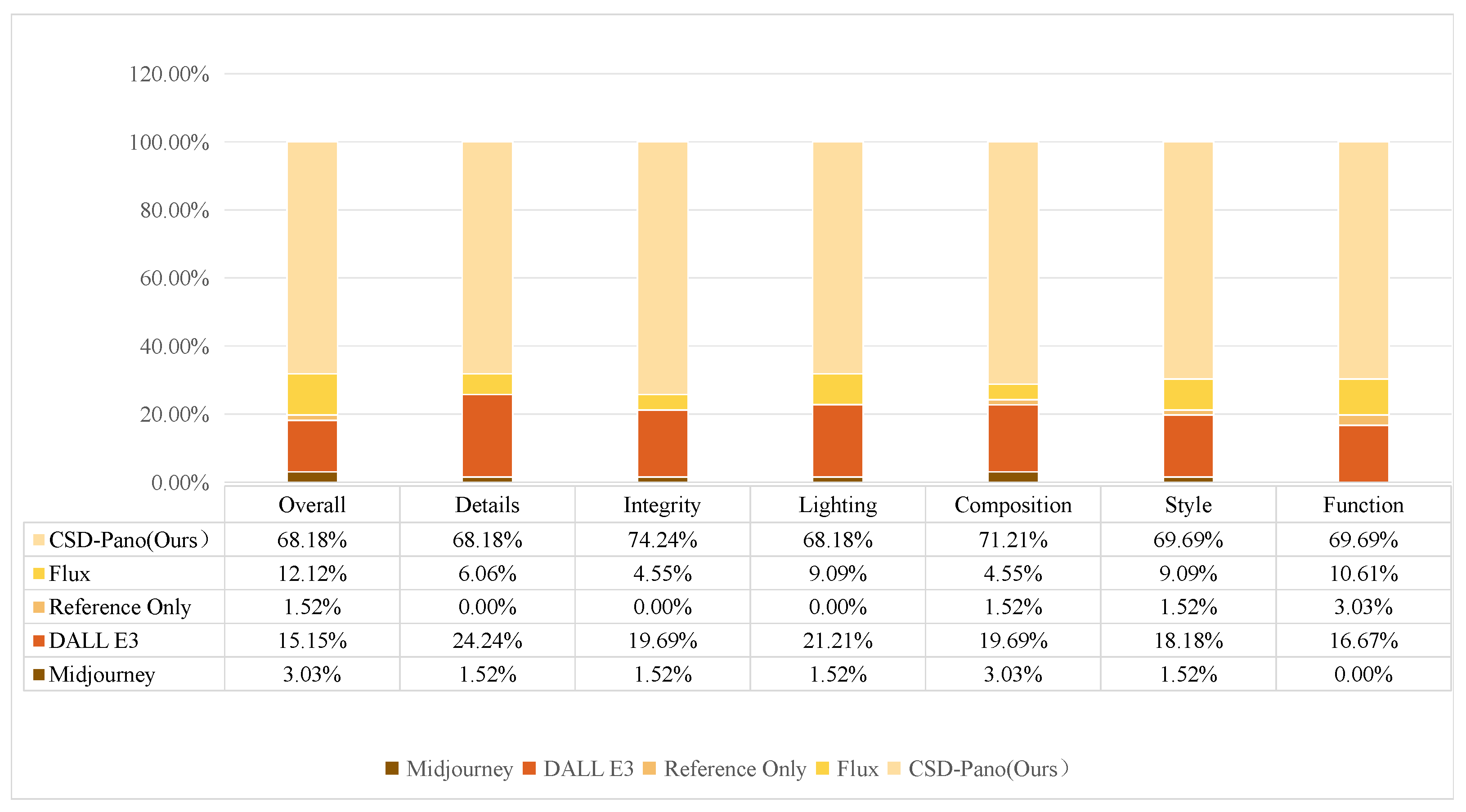




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| American Style | European Style | Modern Style | Neoclassical Style | New Chinese Style | |
|---|---|---|---|---|---|
| Kitchen | 7 | 6 | 17 | 12 | 10 |
| Bedroom | 25 | 17 | 25 | 6 | 26 |
| Living room | 22 | 18 | 20 | 20 | 17 |
| Bathroom | 6 | 5 | 24 | 6 | 5 |
| Method | SSIM ↑ | LPIPS ↓ | CLIP-T ↑ |
|---|---|---|---|
| Midjourney | ✗ | ✗ | 0.310 |
| DALL E3 | ✗ | ✗ | 0.301 |
| Reference Only | 0.895 | 0.696 | 0.294 |
| Flux | 0.862 | 0.674 | 0.277 |
| CSD-Pano (Ours) | 0.910 | 0.658 | 0.274 |
| Method | SSIM ↑ | LPIPS ↓ | CLIP-T ↑ |
|---|---|---|---|
| Baseline | 0.840 | 0.734 | 0.295 |
| w/o PLC | 0.901 | 0.660 | 0.275 |
| w/o SC | 0.879 | 0.707 | 0.280 |
| w/o STC | 0.896 | 0.689 | 0.288 |
| CSD-Pano (full) | 0.910 | 0.658 | 0.274 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Wang, C.; Liu, L.; Dong, S.; Zhao, Y. Advancing Interior Design with AI: Controllable Stable Diffusion for Panoramic Image Generation. Buildings 2025, 15, 1391. https://doi.org/10.3390/buildings15081391
Yang W, Wang C, Liu L, Dong S, Zhao Y. Advancing Interior Design with AI: Controllable Stable Diffusion for Panoramic Image Generation. Buildings. 2025; 15(8):1391. https://doi.org/10.3390/buildings15081391
Chicago/Turabian StyleYang, Wanggong, Congcong Wang, Luxiang Liu, Shuying Dong, and Yifei Zhao. 2025. "Advancing Interior Design with AI: Controllable Stable Diffusion for Panoramic Image Generation" Buildings 15, no. 8: 1391. https://doi.org/10.3390/buildings15081391
APA StyleYang, W., Wang, C., Liu, L., Dong, S., & Zhao, Y. (2025). Advancing Interior Design with AI: Controllable Stable Diffusion for Panoramic Image Generation. Buildings, 15(8), 1391. https://doi.org/10.3390/buildings15081391