An Adaptive Machine Learning Methodology Applied to Neuromarketing Analysis: Prediction of Consumer Behaviour Regarding the Key Elements of the Packaging Design of an Educational Toy

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Results
2.1. Results Interpretation from Neuromarketing Approach
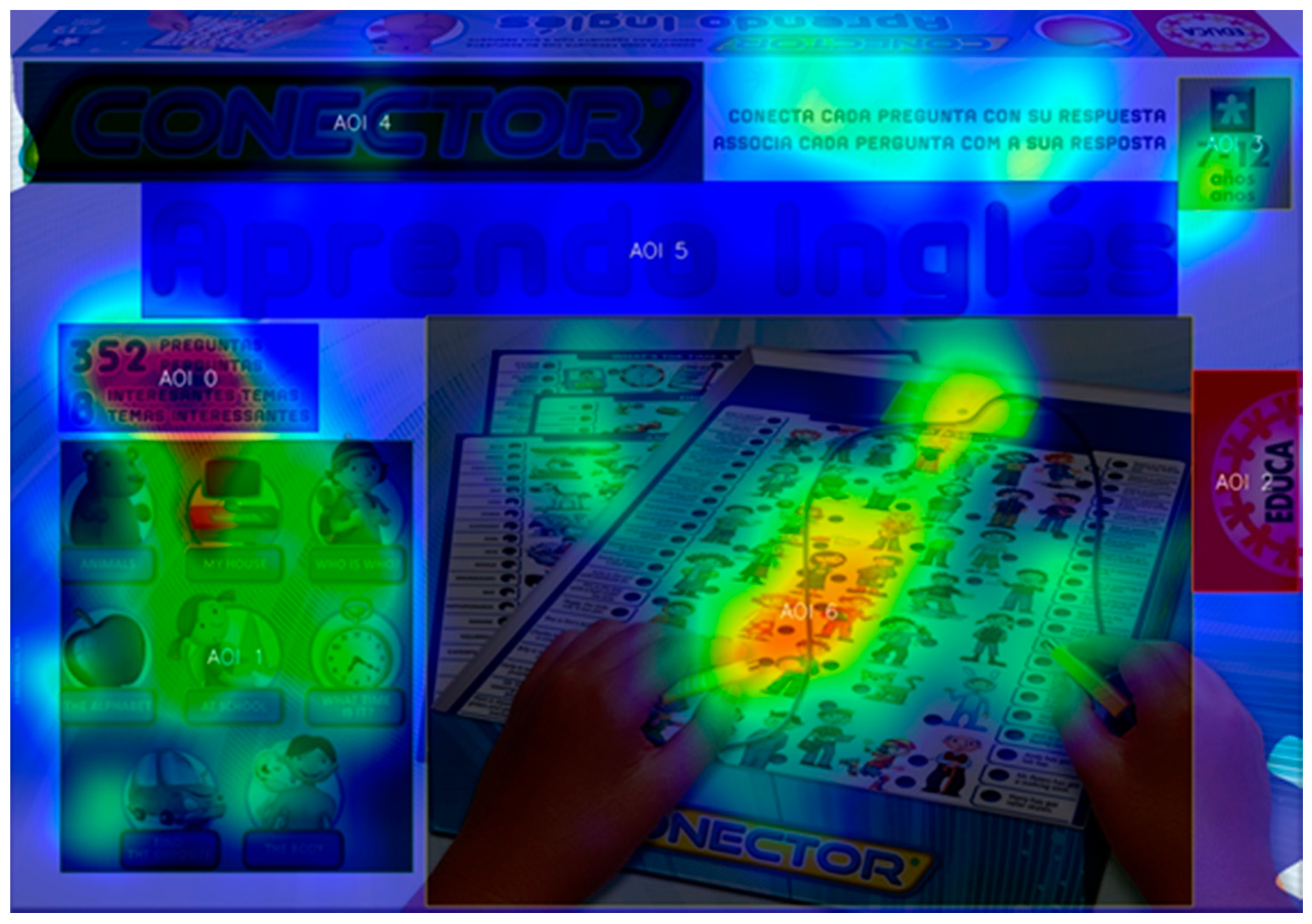
- Gaze (accumulated time displayed), 30 s;
- Size (focus representation size), 35%;
- Transparency (level of transparency of the representation), 40%.
- Gaze (accumulated time displayed), 30 s;
- Size (focus representation size), 35%;
- Transparency (level of transparency of the representation), 40%.
2.2. Computational Experiment in the Educational Toy Industry
Preprocessing Procedure
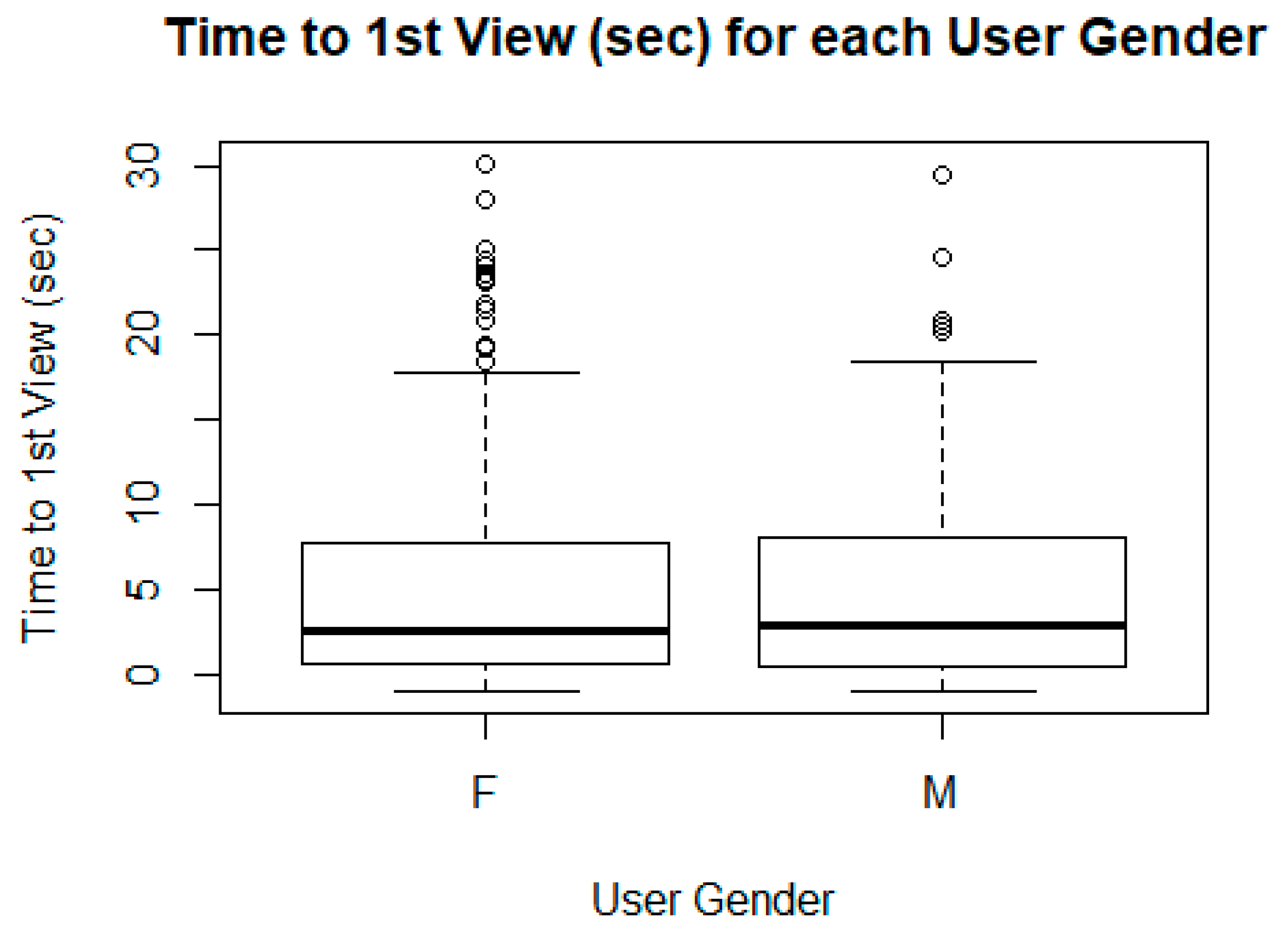
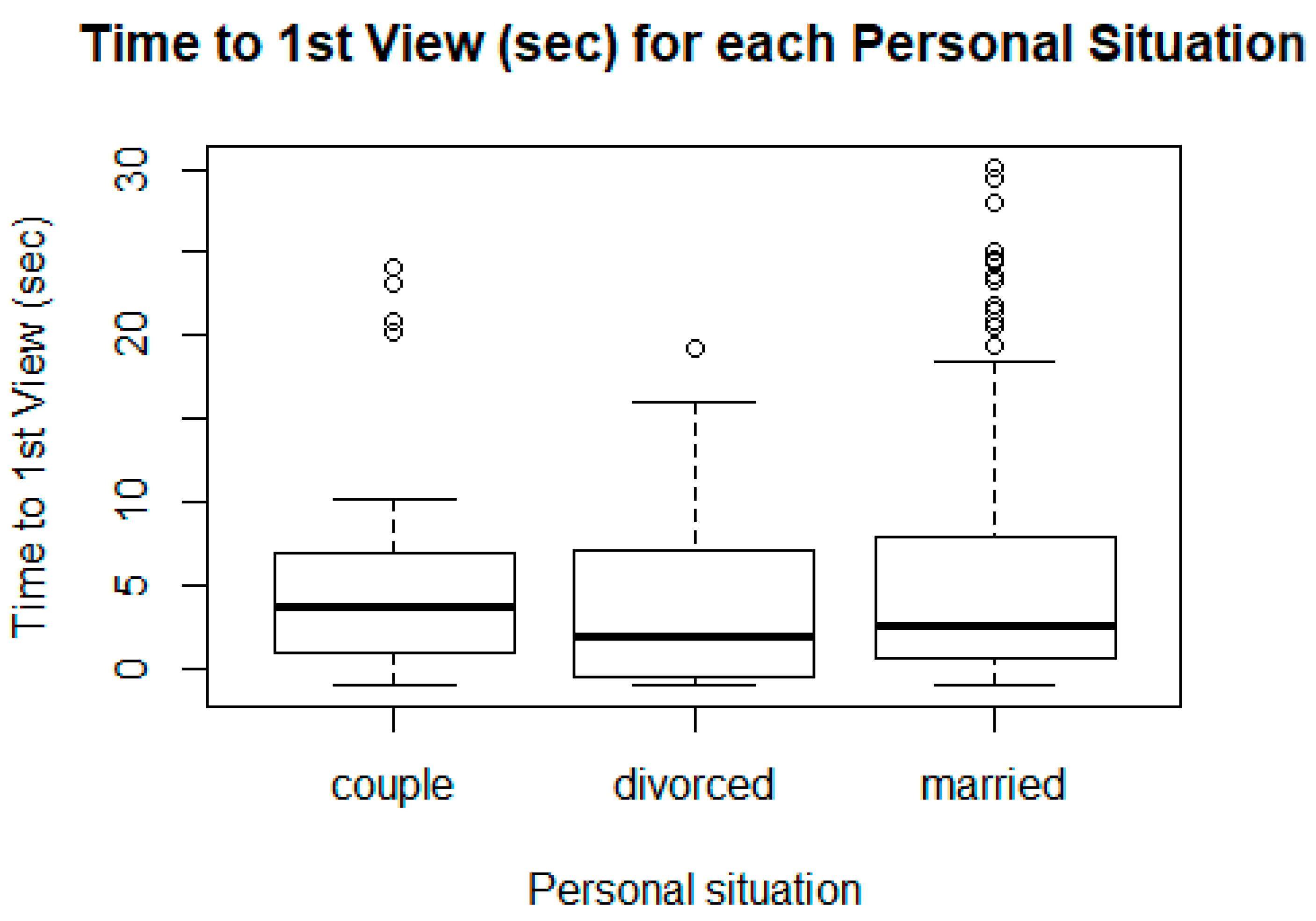
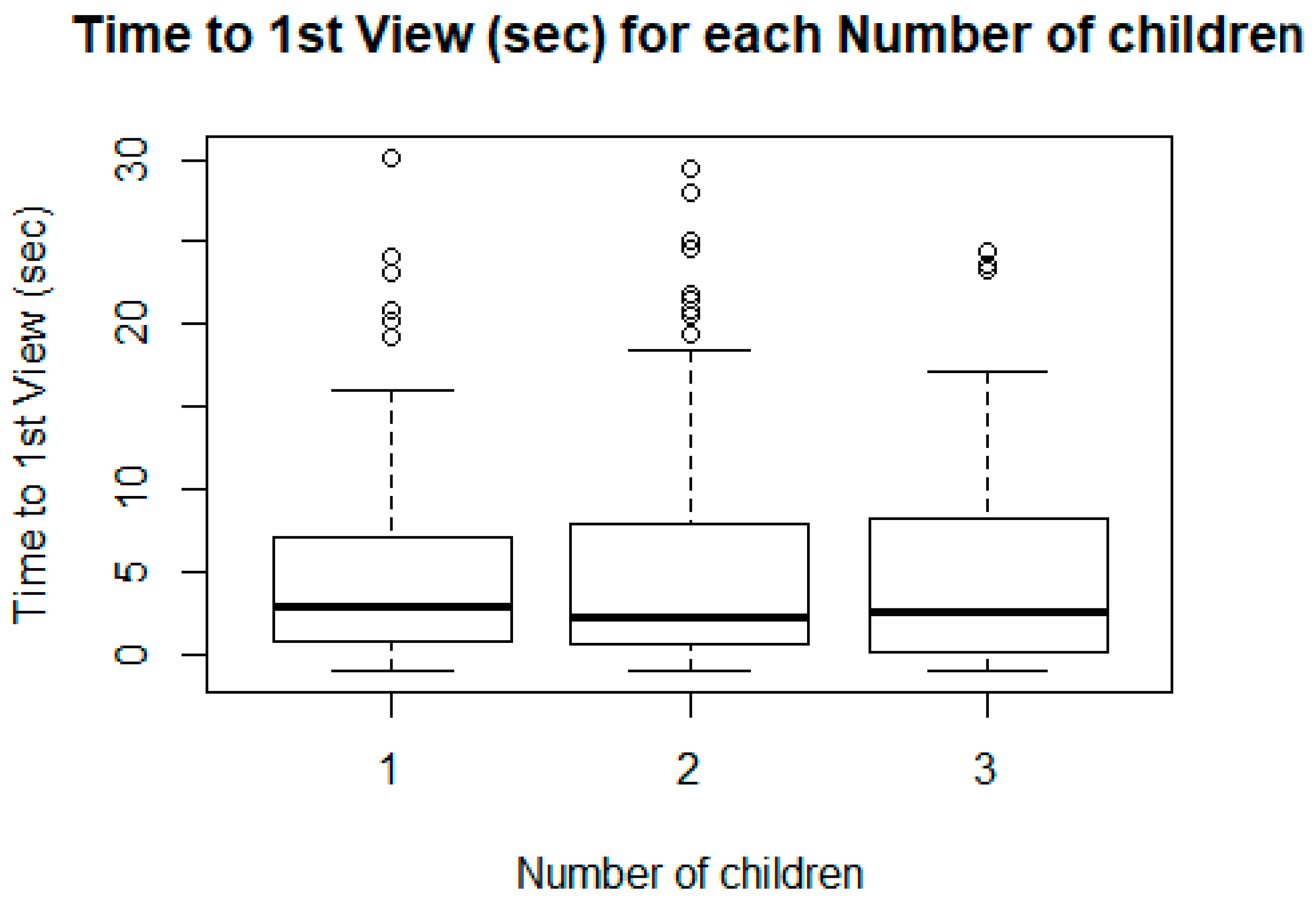
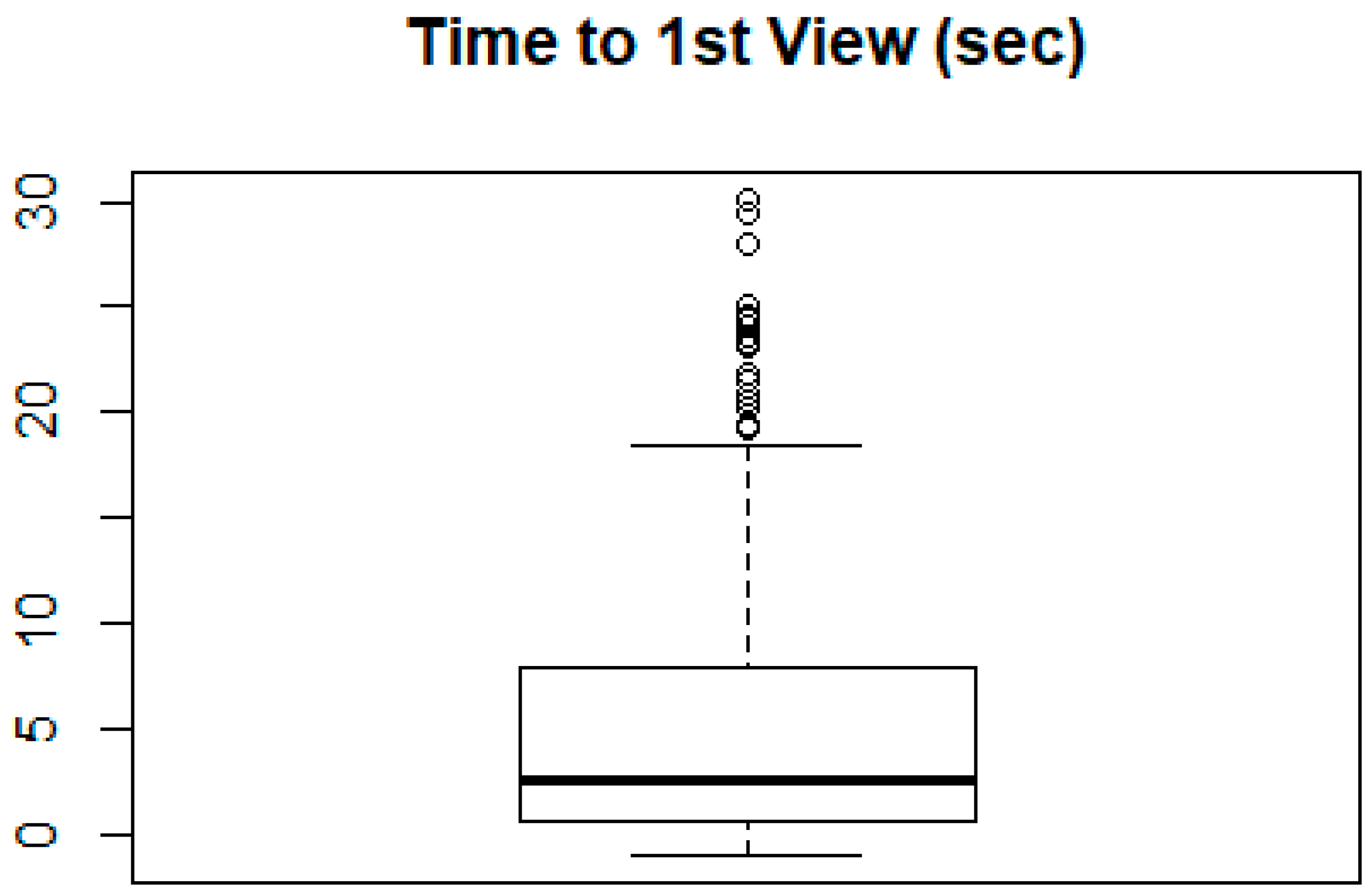
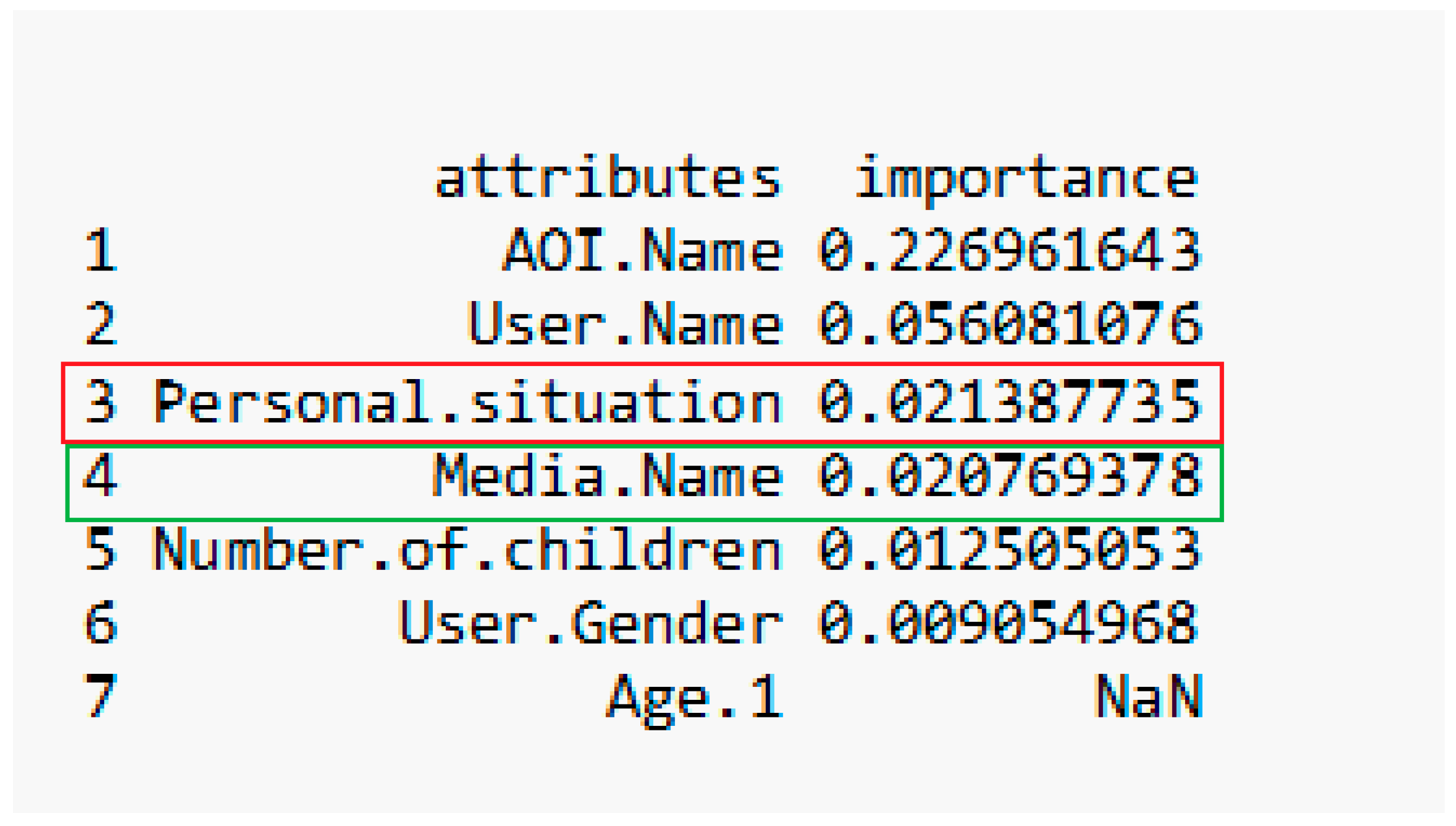
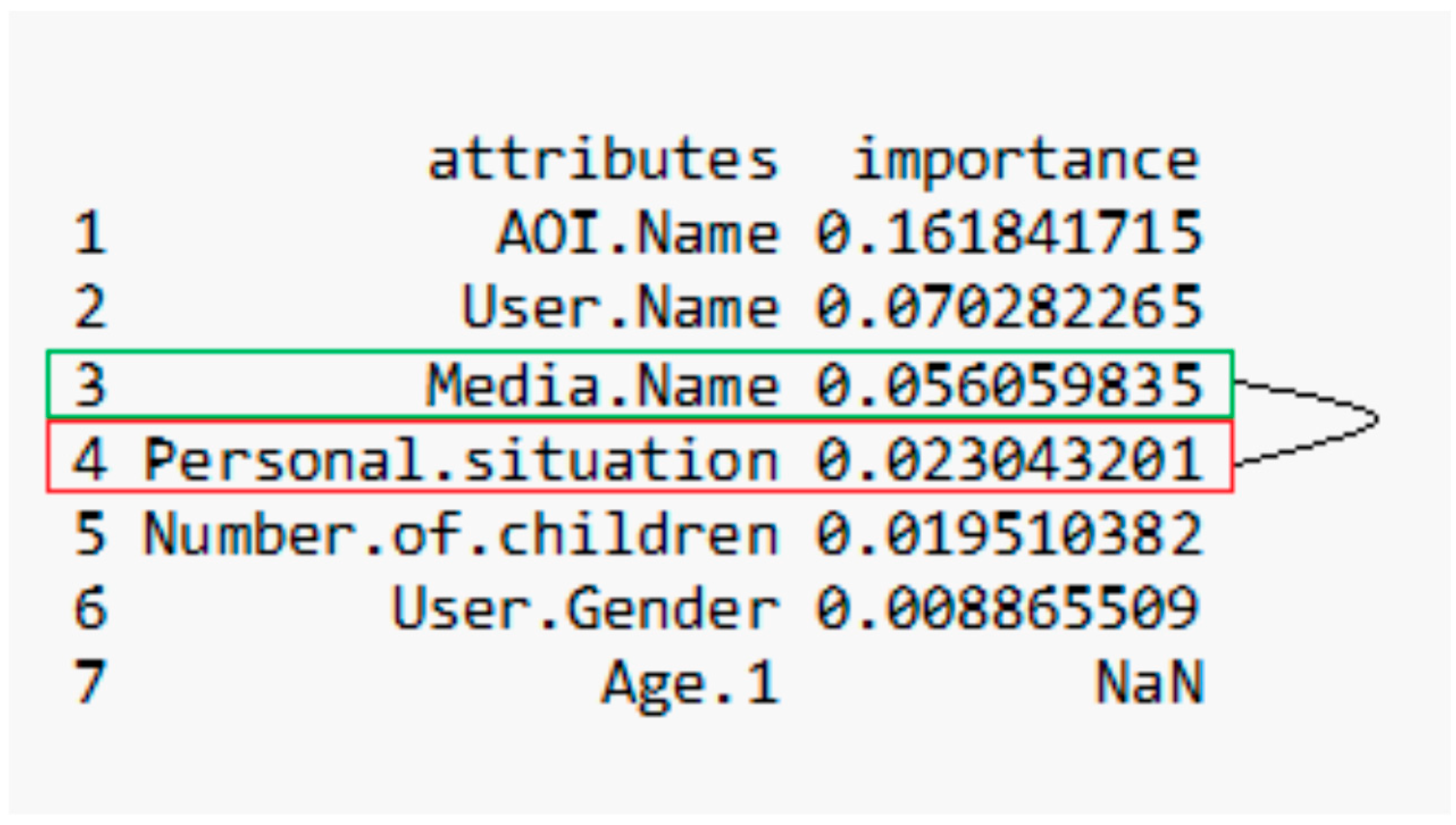
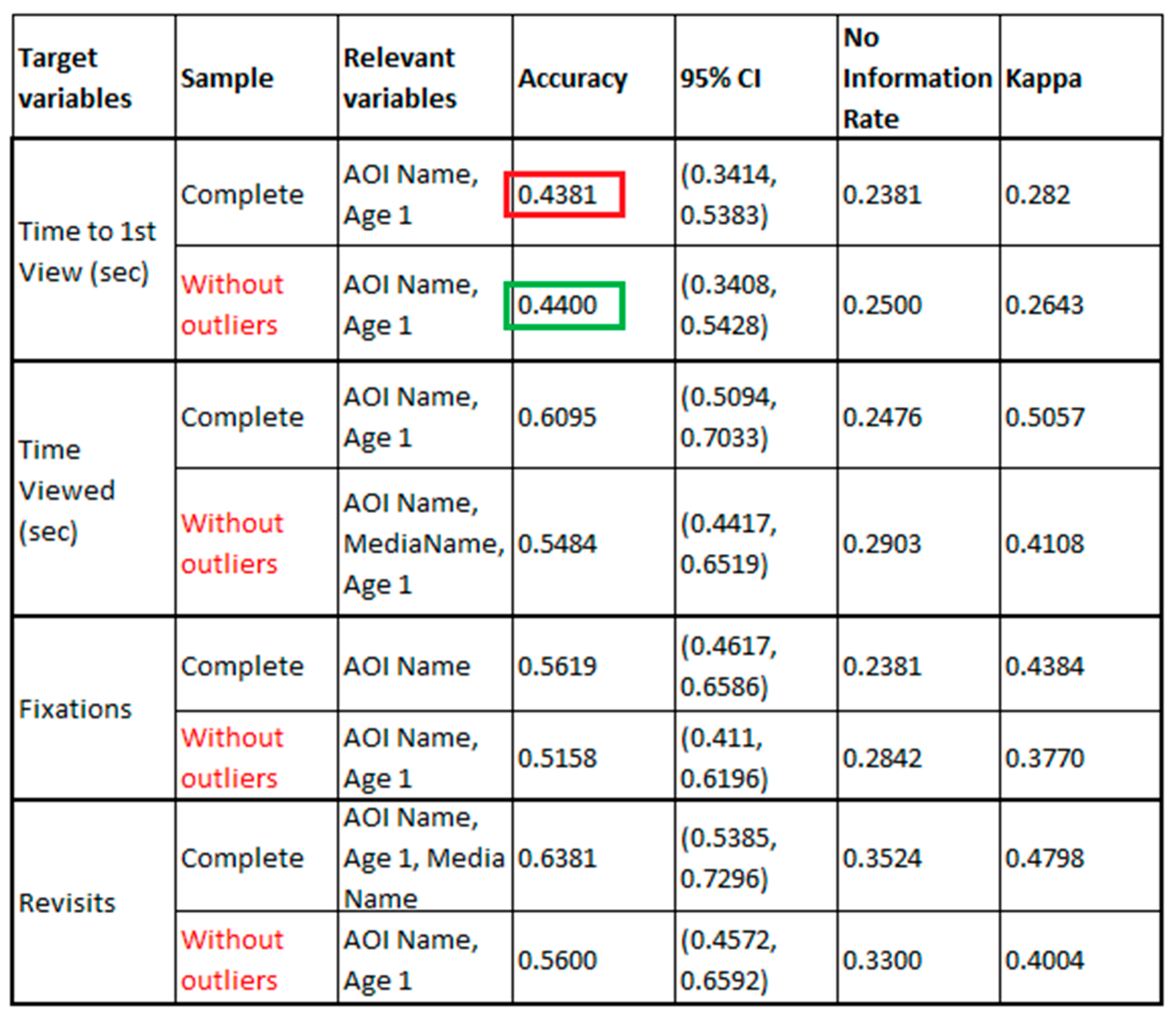
2.3. Feature Selection Depending on Target Variable
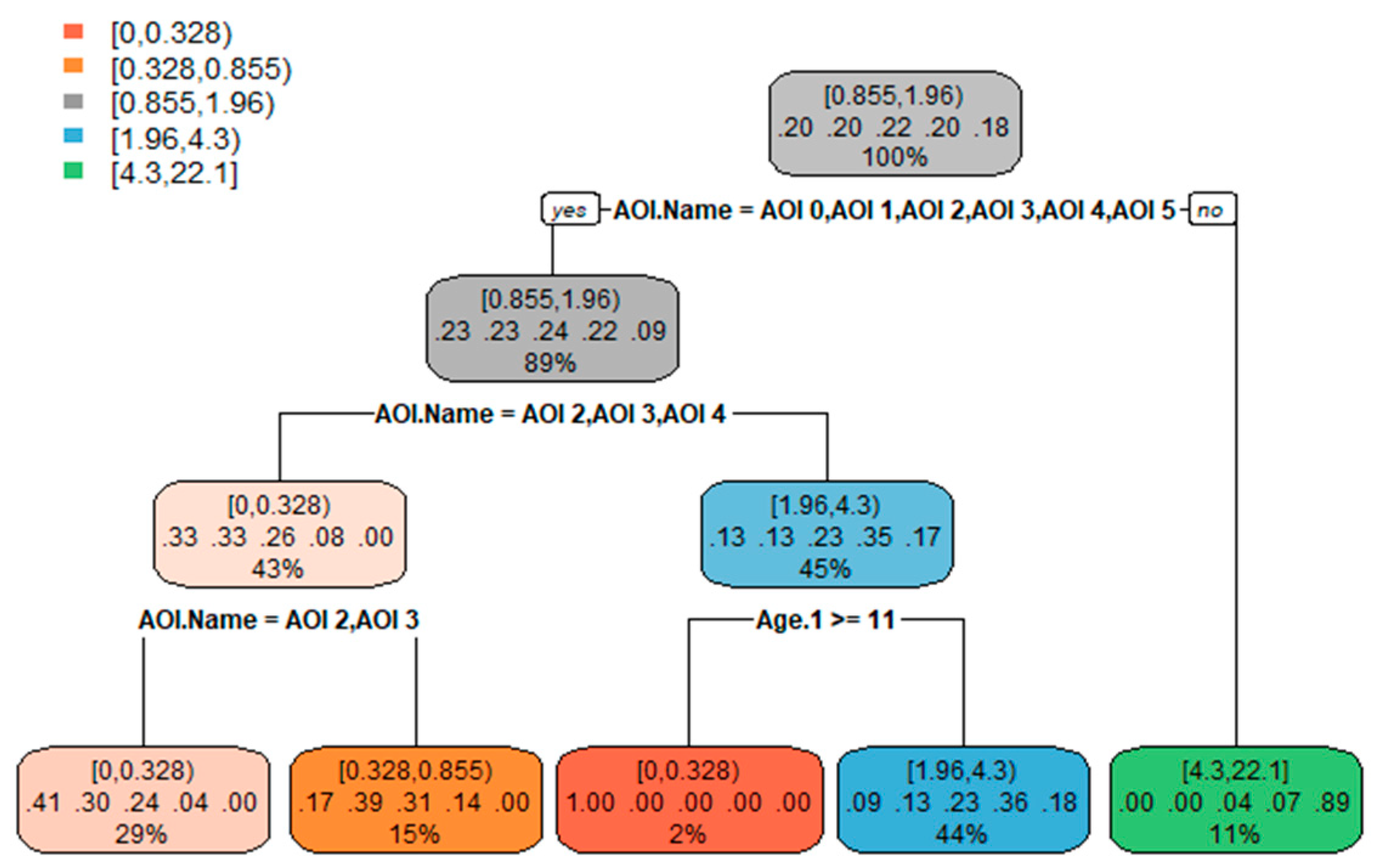
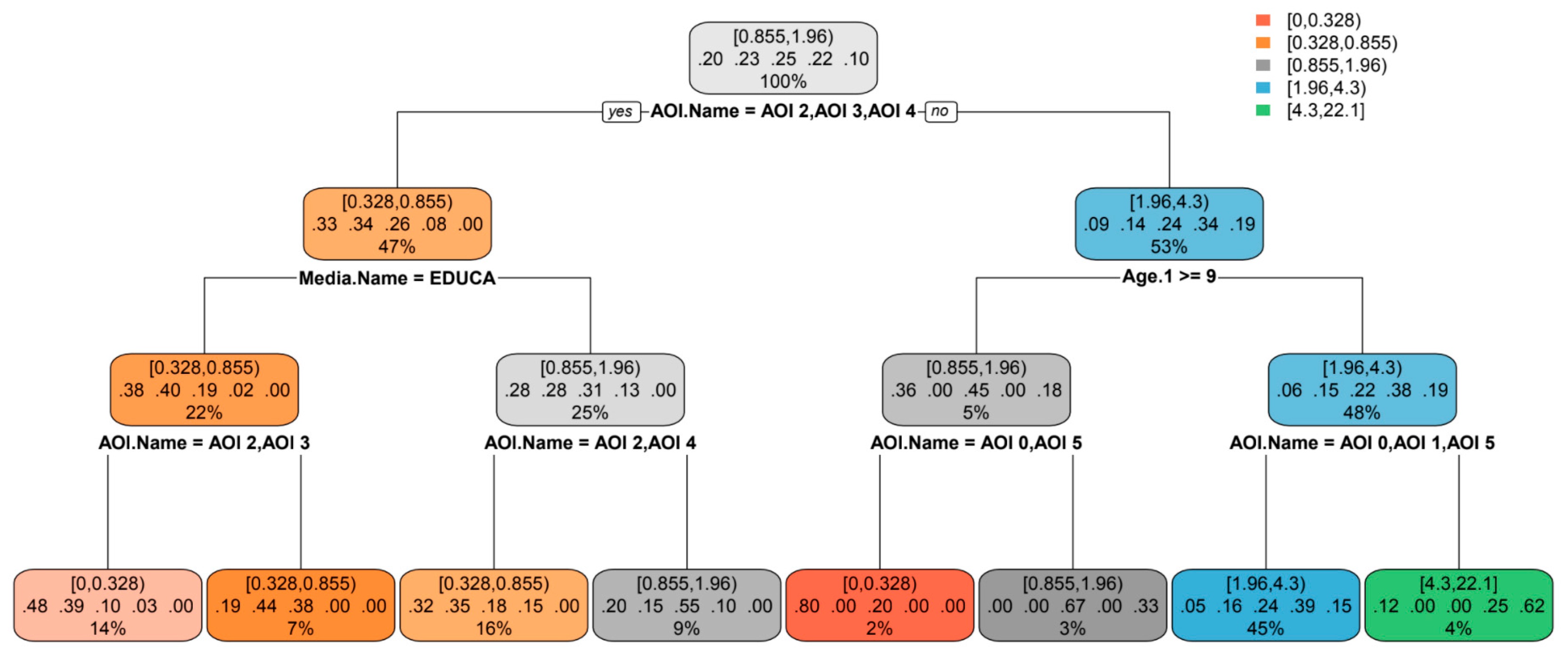
2.4. Generating Predictive Classification Models
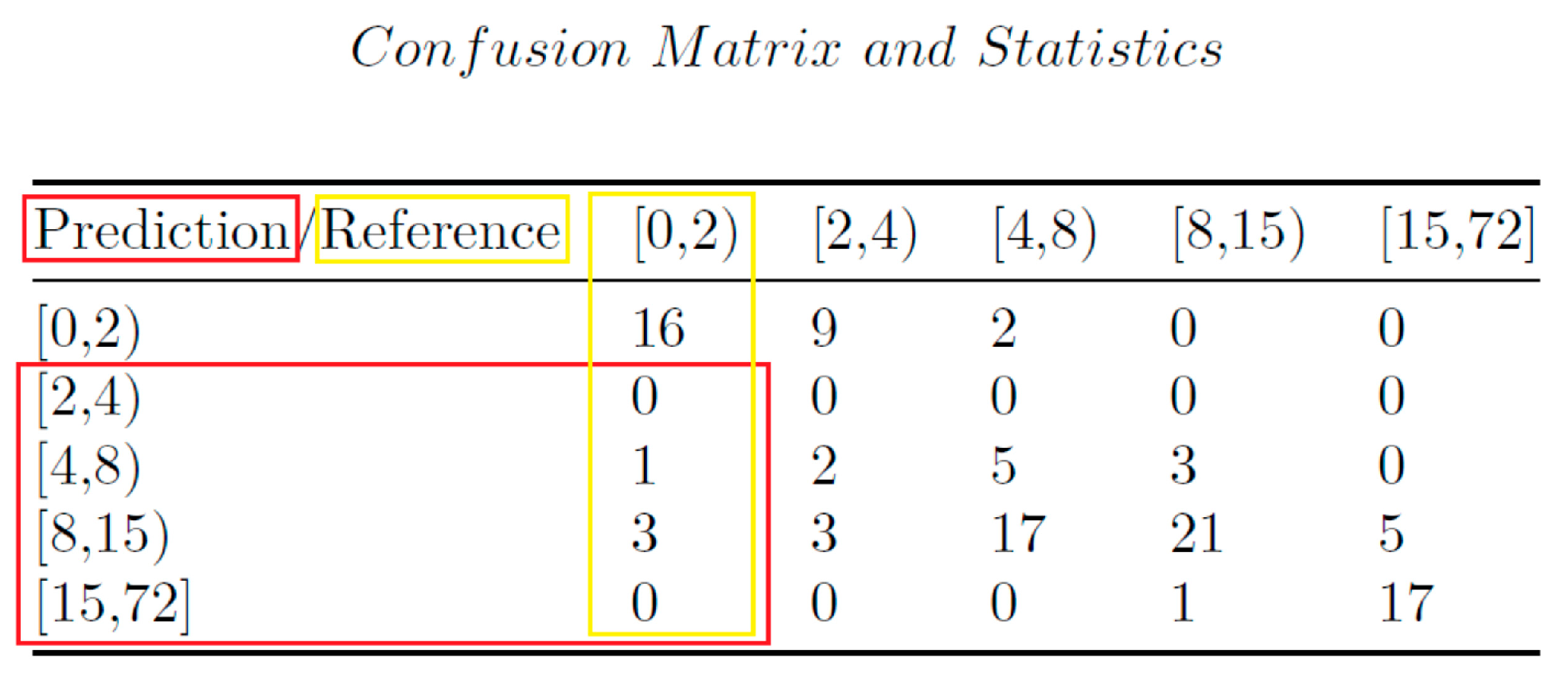
2.5. Comparison of Classification Models
3. Discussion
4. Materials and Methods
4.1. Objectives
- Analyze the attention generated by the different elements of the packaging of an educational toy (comparison with 2 similar products of competing brands) between parents;
- Analyze and segment the areas, according to social circumstance and which family member is observing;
- Determine what differences there are between parents, according to gender;
- Analyze the attention of the different elements generated in the parents, according to the purchase intention.
4.2. Research Instrument
4.3. Sample
4.4. Data Collection and Analysis
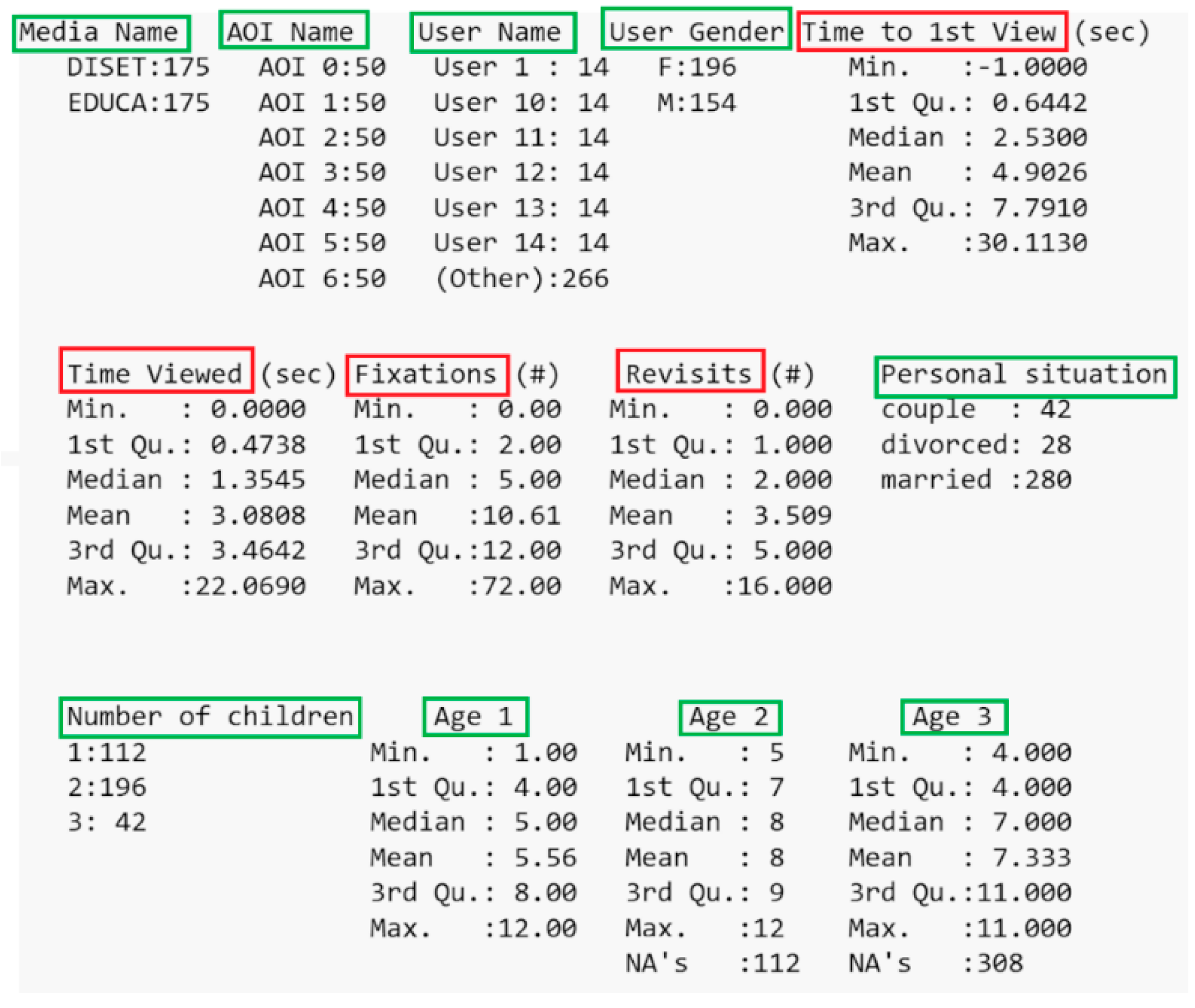
4.5. Dataset
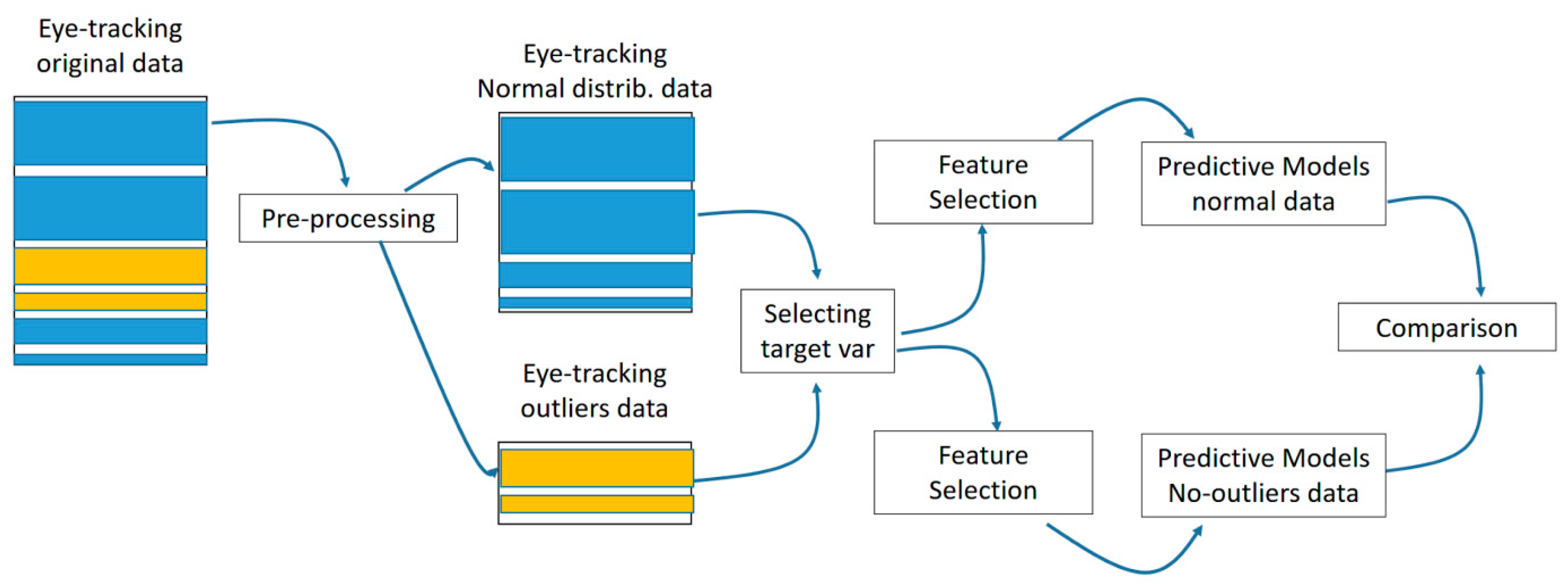
4.6. Analysis Methodology
- selection of the target variable (variable to be predicted);
- detection of the most relevant variables on the chosen target variable;
- generation of predictive models for classifying the target variable with the most influential variables in each case.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- AEFJ. 2019. Toy Image. Imagen del Juguete. Available online: https://www.aefj.es/paginas/carta-de-imagen-del-juguete (accessed on 15 November 2019).
- AIJU. 2019. AIJU 3.0 Guide: (Juego y Juguete. Guía AIJU 3.0). AIJU Instituto Tecnológico de Producto Infantil y de Ocio. Available online: www.guiaaiju.com (accessed on 15 November 2019).
- Alm, Cecilia Ovesdotter, Dan Roth, and Richard Sproat. 2005. Emotions from text: Machine learning for text-based emotion prediction. Paper presented at Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, October 6–8. [Google Scholar]
- American Marketing Asociation. 2013. Packaging. Available online: https://www.ama.org/ (accessed on 15 November 2019).
- Añaños-Carrasco, Elena J. C. 2015. Eyetracker technology in elderly people: How integrated television content is paid attention to and processed. Comunicar 23: 75–83. [Google Scholar] [CrossRef]
- Ariely, Dan, and Gregory S. Berns. 2010. Neuromarketing: The hope and hype of neuroimaging in business. Nature Reviews Neuroscience 11: 284–92. [Google Scholar] [CrossRef] [PubMed]
- Bloch, Peter H. 1995. Seeking the ideal form: Product design and consumer response. Journal of Marketing 59: 16–29. [Google Scholar] [CrossRef]
- Breiman, Leo, Jerome H. Friedman, Charles J. Stone, and Richard A. Olshen. 1984. Classification and Regression Trees. Boca Raton: CRC Press. [Google Scholar]
- Butler, Michael J. R. 2008. Neuromarketing and the perception of knowledge. Journal of Consumer Behaviour 7: 415–19. [Google Scholar] [CrossRef]
- Calver, G. 2004. What is Packaging Design. Mies: Rotovision. [Google Scholar]
- Chapelle, Olivier, Vladimir Vapnik, Olivier Bousquet, and Sayan Mukherjee. 2002. Choosing multiple parameters for support vector machines. Machine Learning 46: 131–59. [Google Scholar] [CrossRef]
- Chapman, Pete, and Julian Clinton. 1999. Julian Clinton (SPSS), Randy Kerber (NCR), Thomas Khabaza (SPSS), Thomas Reinartz (Daimler Chrysler), Colin Shearer (SPSS) and Rüdiger Wirth (Daimler Chrysler). Available online: https://www.coursehero.com/file/14884931/CRISP-DM-Process-Model-User-Guide/ (accessed on 15 November 2019).
- Cuesta-Cambra, Ubaldo, Nino-Gonzalez José Ignacio, and José Rodriguez-Terceno. 2017. The Cognitive Processing of an Educational App with Electroencephalogram and “Eye Tracking”. Comunicar 52: 41–50. [Google Scholar] [CrossRef]
- Dernoncourt, David, Blaise Hanczar, and Jean-Daniel Zucker. 2014. Analysis of feature selection stability on high dimension and small sample data. Computational Statistics & Data Analysis 71: 681–93. [Google Scholar]
- Enax, Laura, Bernd Weber, Maren Ahlers, Ulrike Kaiser, Katharina Diethelm, Dominik Holtkamp, Ulya Faupel, Hartmut H. Holzműller, and Mathilde Kersting. 2015. Food packaging cues influence taste perception and increase effort provision for a recommended snack product in children. Frontiers in Psychology 6: 882. [Google Scholar] [CrossRef]
- ESOMAR. 2017. ESOMAR. Available online: https://www.esomar.org/ (accessed on 15 November 2019).
- Espinosa, Cruz R. J. Y. G. 2018. The Educational Toy Guide (Guía El Juguete Educativo), 2nd ed. Cruz Roja Juventud. Available online: https://www.cruzrojajuventud.org/ (accessed on 15 November 2019).
- Goodall, Paul, Richard Sharpe, and Andrew West. 2019. A data-driven simulation to support remanufacturing operations. Computers in Industry 105: 48–60. [Google Scholar] [CrossRef]
- Goto, Nobuhiko, Xue Li Lim, Dexter Shee, Aya Hatano, Kok Wei Khong, Luciano Grüdtner Buratto, Motoki Watabe, and Alexandre Schaefer. 2019. Can brain waves really tell if a product will be purchased? Inferring consumer preferences from single-item brain potentials. Frontiers in Integrative Neuroscience 13: 19. [Google Scholar] [CrossRef]
- Hakim, Adam, and Dino Levy. 2019. A gateway to consumers’ minds: Achievements, caveats, and prospects of electroencephalography-based prediction in neuromarketing. Wiley Interdisciplinary Reviews Cognitive Science 10: e1485. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, Douglas M. 1980. Identification of Outliers. Berlin: Springer, vol. 11. [Google Scholar]
- Innerscope. 2017. Innerscope. Available online: http://www.nielsen.com/us/en/solutions/capabilities/consumer-neuroscience.html (accessed on 15 November 2019).
- John, George H. 1995. Robust Decision Trees: Removing Outliers from Databases. Available online: https://www.aaai.org/Papers/KDD/1995/KDD95-044.pdf (accessed on 15 November 2019).
- Jones, Candace, Mark Lorenzen, and Jonathan Sapsed. 2015. Creative Industries. In The Oxford Handbook of Creative Industries. New York: Oxford University Press, p. 1. [Google Scholar]
- Juarez, David, Victoria Tur-Viñes, and Ana Mengual. 2020. Neuromarketing Applied to Educational Toy Packaging. Frontiers in Psychology 11: 2077. [Google Scholar] [CrossRef]
- Kahneman, Daniel. 2002. Daniel Kahneman. Available online: https://kahneman.socialpsychology.org/ (accessed on 15 November 2019).
- Lamb, Charles W. 2008. Marketing, 9th ed. Boston: Thomsom Learning Inc. [Google Scholar]
- Lawrence, Thomas B., and Nelson Phillips. 2002. Understanding cultural industries. Journal of Management Inquiry 11: 430–41. [Google Scholar] [CrossRef]
- Lawrence, Kate, Ruth Campbell, and David Skuse. 2015. Age, gender, and puberty influence the development of facial emotion recognition. Frontiers in Psychology 6: 761. [Google Scholar] [CrossRef] [PubMed]
- Li, Zhe, Yi Wang, and Kesheng Wang. 2019. A deep learning driven method for fault classification and degradation assessment in mechanical equipment. Computers in Industry 104: 1–10. [Google Scholar] [CrossRef]
- Libert, Arno, and Marc Van Hulle. 2019. Predicting Premature Video Skipping and Viewer Interest from EEG Recordings. Entropy 21: 1014. [Google Scholar] [CrossRef]
- Liu, Jiang B., and Jun Han. 2002. A Practical Knowledge Discovery Process for Distributed Data Mining. Paper presented at ISCA Conference on Intelligent Systems, Boston, MA, USA, July 18–20. [Google Scholar]
- Lučić, Andrea, Marina Dabić, and John Finley. 2019. Lučić, Andrea, Marina Dabić, and John Finley. 2019. Marketing innovation and up-and-coming product and process innovation. International Journal of Entrepreneurship and Small Business 37: 434–48. [Google Scholar] [CrossRef]
- Luévano Torres, Hector A. 2013. Toy packaging design and its relationship to gender stereotypes (El diseño de empaque del juguete y su relación con los estereotipos de género). UNAM Revista Digital Universitaria 14: 7. [Google Scholar]
- Maas, Cora J.M., and Joop Hox. 2005. Sufficient sample sizes for multilevel modeling. Methodology European Journal of Research Methods for the Behavioral and Social Sciences 1: 86–92. [Google Scholar] [CrossRef]
- Mañas-Viniegra, Luis, Patricia Núñez-Gómez, and Victoria Tur-Viñes. 2020. Neuromarketing as a strategic tool for predicting how Instagramers have an influence on the personal identity of adolescents and young people in Spain. Heliyon 6: e03578. [Google Scholar] [CrossRef]
- Marín-Marín, José Antonio, Jesús López-Belmonte, Juan-Miguel Fernández-Campoy, and José-María Romero-Rodríguez. 2019. Big data in education. A bibliometric review. Social Sciences 8: 223. [Google Scholar] [CrossRef]
- Martínez-Sanz, Raquel. 2012. Estrategia comunicativa digital en el museo. El Profesional de la Información 21: 391–95. [Google Scholar] [CrossRef]
- Mengual-Recuerda, Ana, Victoria Tur-Viñes, and David Juárez-Varón. 2020. Neuromarketing in Haute Cuisine Gastronomic Experiences. Frontiers in Psychology 11: 1772. [Google Scholar] [CrossRef] [PubMed]
- Morillo, Luis M. S., Juan Antonio Alvarez-Garcia, Luis Gonzalez-Abril, and Juan A. Ortega. 2016. Discrete classification technique applied to TV advertisements liking recognition system based on low-cost EEG headsets. BioMedical Engineering 15: 75. [Google Scholar] [CrossRef] [PubMed]
- Nancarrow, Clive, Len Tiu Wright, and Ian Brace. 1998. Gaining competitive advantage from packaging and labelling in marketing communications. British Food Journal, 100. Available online: https://www.emerald.com/insight/content/doi/10.1108/00070709810204101/full/html (accessed on 15 November 2019).
- Ohme, Rafal, Michal Matukin, and Beata Pacula-Lesniak. 2011. Biometric measures for interactive advertising research. Journal of Interactive Advertising 11: 60–72. [Google Scholar] [CrossRef]
- Peres-Neto, Pedro R., Donald A. Jackson, and Keith M. Somers. 2005. How many principal components? Stopping rules for determining the number of non-trivial axes revisited. Computational Statistics & Data Analysis 49: 974–97. [Google Scholar]
- Peris-Ortiz, Marta, Mayer Rainiero Cabrera-Flores, and Arturo Serrano-Santoyo. 2018. Cultural and Creative Industries: A Path to Entrepreneurship and Innovation. Berlin: Springer. [Google Scholar]
- Pierdicca, Roberto, Marina Paolanti, Simona Naspetti, and Serena Mandolesi. 2018. User-centered predictive model for improving cultural heritage augmented reality applications: An HMM-based approach for eye-tracking data. Journal of Imaging 4: 101. [Google Scholar] [CrossRef]
- Provost, Foster, and Tom Fawcett. 2013. Data science and its relationship to big data and data-driven decision making. Data Science for Business 1: 51–59. [Google Scholar] [CrossRef]
- Quinlan, J. Ross. 1986. Induction of decision trees. Machine Learning 1: S1–106. [Google Scholar] [CrossRef]
- Quinlan, J. R. 2014. C4.5: Programs for Machine Learning. Amsterdam: Elsevier. [Google Scholar]
- Rabasa, Alex, and Ciara Heavin. 2020. An Introduction to Data Science and Its Applications. In Data Science and Productivity Analytics. Berlin: Springer, pp. 57–81. [Google Scholar]
- Radac, Mircea-Bogdan, and Radu-Emil Precup. 2015. Optimal behaviour prediction using a primitive-based data-driven model-free iterative learning control approach. Computers in Industry 74: 95–109. [Google Scholar] [CrossRef]
- Reimann, Martin, Oliver Schilke, Bernd Weber, Carolin Neuhaus, and Judith Zaichkowsky. 2011. Functional magnetic resonance imaging in consumer research: A review and application. Psychology & Marketing 28: 608–37. [Google Scholar]
- Repository, C. 2020. Package ‘MachineLearning’. Available online: https://cran.r-project.org/ (accessed on 15 November 2019).
- Ruiz-Palmero, Julio Ruiz, Ernesto Colomo-Magaña, José Manuel Ríos-Ariza, and Melchor Gómez-García. 2020. Big data in education: Perception of training advisors on its use in the educational system. Social Sciences 9: 53. [Google Scholar] [CrossRef]
- Rundh, Bo. 2009. Packaging design: Creating competitive advantage with product packaging. British Food Journal 111: 988–1002. [Google Scholar] [CrossRef]
- Silva, Emmanuel Sirimal, Hossein Hassani, Dag Øivind Madsen, and Liz Gee. 2019. Googling fashion: Forecasting fashion consumer behaviour using Google Trends. Social Sciences 8: 111. [Google Scholar] [CrossRef]
- Soluciones-Packaging. 2016. El Packaging En Los Juguetes. Available online: http://solucionespackaging.com/author/soluciones-packaging/ (accessed on 15 November 2019).
- Stark, Lawrence, Gerhard Vossius, and Laurence R. Young. 1962. Predictive control of eye tracking movements. IRE Transactions on Human Factors in Electronics 2: 52–57. [Google Scholar] [CrossRef]
- Starks, Katryna. 2014. Cognitive behavioral game design: A unified model for designing serious games. Frontiers in Psychology 5: 28. [Google Scholar] [CrossRef]
- Svanes, Erik, Mie Vold, Hanne Møller, and Marit Kvalvåg Pettersen. 2010. Sustainable packaging design: A holistic methodology for packaging design. Packaging Technology and Science 23: 161–75. [Google Scholar] [CrossRef]
- Taqwa, Tryono, Adang Suhendra, Matrissya Hermita, and Astie Darmayantie. 2015. Implementation of Naïve Bayes method for product purchasing decision using neural impulse actuator in neuromarketing. Paper presented by 2015 International Conference on Information & Communication Technology and Systems (ICTS), Surabaya, Indonesia, September 16. [Google Scholar]
- Thuethongchai, Nopsaran, Tatri Taiphapoon, Achara Chandrachai, and Sipat Triukose. 2020. Adopt big-data analytics to explore and exploit the new value for service innovation. Social Sciences 9: 29. [Google Scholar] [CrossRef]
- Tur-Viñes, Victoria, Irene Ramos-Soler, and María Costa Ferrer. 2014. Comunicación Silenciosa: Estudio Comparativo Internacional de Envases de Juguetes. Questiones Publicitarias 19: 35–50. [Google Scholar] [CrossRef]
- Ungureanu, Florina, Robert Gabriel Lupu, Adrian Cadar, and Adrian Prodan. 2017. Neuromarketing and Visual Attention Study Using Eye Tracking Techniques. Paper presented at 2017 21st International Conference on System Theory,Control and Computing, Sinaia, Romania, October 19–21; pp. 553–57. [Google Scholar]
- Velasco, Carlos, Alejandro Salgado-Montejo, Fernando Marmolejo-Ramos, and Charles Spence. 2014. Predictive packaging design: Tasting shapes, typefaces, names, and sounds. Food Quality and Preference 34: 88–95. [Google Scholar] [CrossRef]
- Vellido, Alfredo, José David Martín-Guerrero, and Paulo J. Lisboa. 2012. Making Machine Learning Models Interpretable. Paper presented at ESANN, 20th European Symposium on Artificial Neural Networks, Bruges, Belgium, April 25–27. [Google Scholar]
- Victor, Vijay, Jose Thoppan, Robert Jeyakumar Nathan, and Fekete Farkas Maria. 2018. Factors influencing consumer behavior and prospective purchase decisions in a dynamic pricing environment-an exploratory factor analysis approach. Social Sciences 7: 153. [Google Scholar] [CrossRef]
- Vilchis, Luz del Carmen. 2008. Metodología del Diseño: Fundamentos Teóricos, 4th ed. Mexico: Claves Latinoamericanas. [Google Scholar]
- Wang, Junfeng, Qing Chang, Guoxian Xiao, Nan Wang, and Shiqi Li. 2011. Data driven production modeling and simulation of complex automobile general assembly plant. Computers in Industry 62: 765–75. [Google Scholar] [CrossRef]
- Wei, Zhen, Chao Wu, Xiaoyi Wang, Akara Supratak, Pan Wang, and Yike Guo. 2018. Using Support Vector Machine on EEG for Advertisement Impact Assessment. Frontiers in Neuroscience 12: 76. [Google Scholar] [CrossRef] [PubMed]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
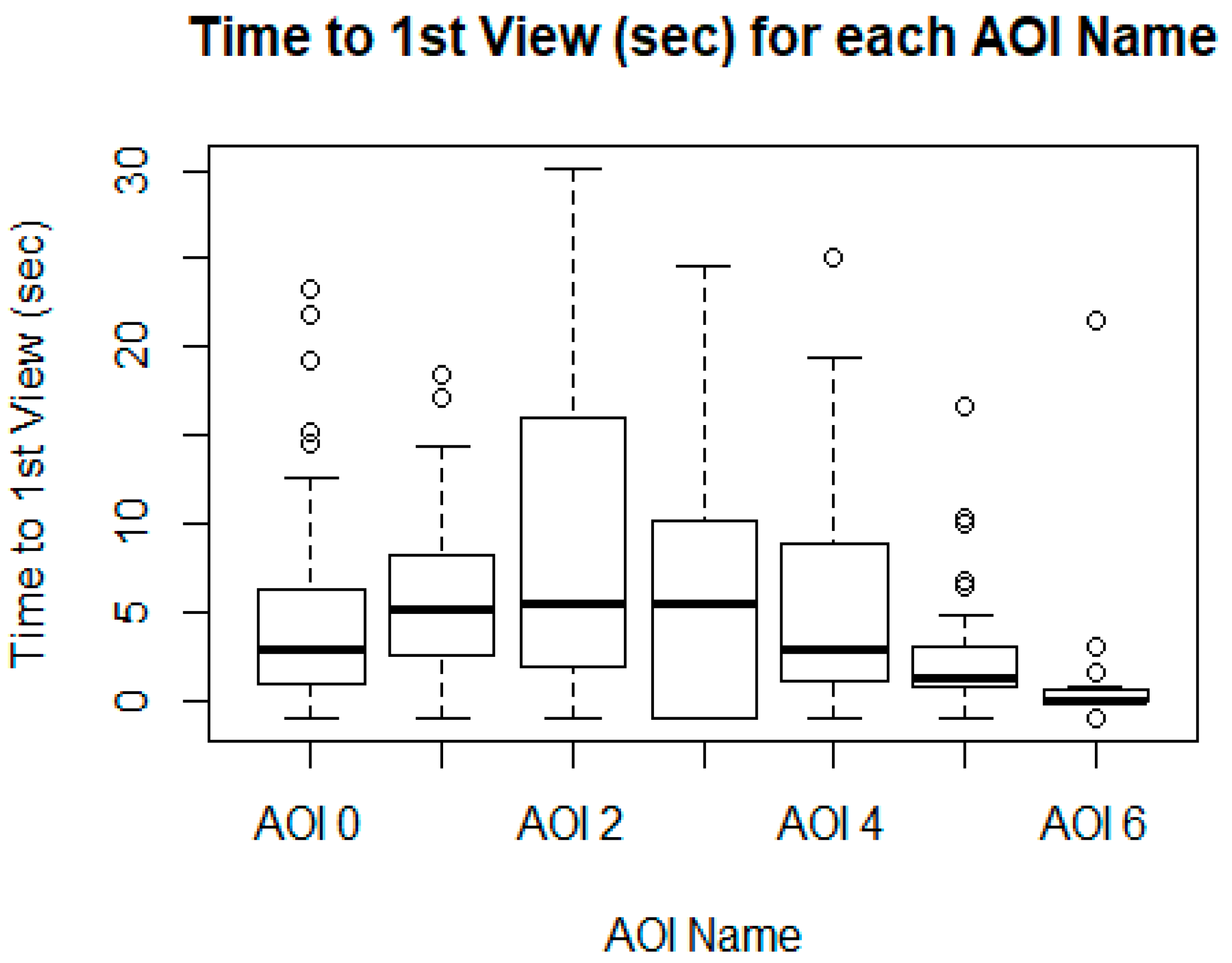
| AOI Name | AOI Start (s) | AOI Duration (sec—U = User Controlled) | Viewers (#) | Total Viewers (#) | Ave Time to 1st View (s) | Ave Time Viewed (s) | Ave Time Viewed (%) | Ave Fixations (#) | Revisitors (#) |
|---|---|---|---|---|---|---|---|---|---|
| AOI 0 | 0 | 30 | 22 | 25 | 7.63 | 1.79 | 5.97 | 6.09 | 20 |
| AOI 1 | 0 | 30 | 24 | 25 | 5.67 | 5.04 | 16.80 | 15.17 | 24 |
| AOI 2 | 0 | 30 | 22 | 25 | 12.82 | 0.44 | 1.47 | 2.18 | 9 |
| AOI 3 | 0 | 30 | 14 | 25 | 9.30 | 0.68 | 2.26 | 2.78 | 9 |
| AOI 4 | 0 | 30 | 23 | 25 | 5.49 | 0.73 | 2.45 | 4.39 | 18 |
| AOI 5 | 0 | 30 | 23 | 25 | 2.68 | 1.99 | 6.66 | 10.48 | 23 |
| AOI 6 | 0 | 30 | 24 | 25 | 1.05 | 7.85 | 26.17 | 25.54 | 24 |
| AOI Name | AOI Start (sec) | AOI Duration (sec—U = User Controlled) | Viewers (#) | Total Viewers (#) | Ave Time to 1st View (s) | Ave Time Viewed (s) | Ave Time Viewed (%) | Ave Fixations (#) | Revisitors (#) |
|---|---|---|---|---|---|---|---|---|---|
| AOI 0 | 0 | 30 | 23 | 25 | 3.22 | 3.82 | 12.75 | 11.69 | 23 |
| AOI 1 | 0 | 30 | 25 | 25 | 6.50 | 2.08 | 6.94 | 6.04 | 22 |
| AOI 2 | 0 | 30 | 18 | 25 | 9.04 | 0.59 | 1.96 | 2.94 | 14 |
| AOI 3 | 0 | 30 | 22 | 25 | 9.68 | 1.24 | 4.12 | 3.77 | 15 |
| AOI 4 | 0 | 30 | 23 | 25 | 6.38 | 1.24 | 4.14 | 6.04 | 20 |
| AOI 5 | 0 | 30 | 23 | 25 | 2.42 | 1.56 | 5.20 | 7.69 | 23 |
| AOI 6 | 0 | 30 | 25 | 25 | 0.42 | 16.21 | 54.03 | 52.08 | 25 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juárez-Varón, D.; Tur-Viñes, V.; Rabasa-Dolado, A.; Polotskaya, K. An Adaptive Machine Learning Methodology Applied to Neuromarketing Analysis: Prediction of Consumer Behaviour Regarding the Key Elements of the Packaging Design of an Educational Toy. Soc. Sci. 2020, 9, 162. https://doi.org/10.3390/socsci9090162
Juárez-Varón D, Tur-Viñes V, Rabasa-Dolado A, Polotskaya K. An Adaptive Machine Learning Methodology Applied to Neuromarketing Analysis: Prediction of Consumer Behaviour Regarding the Key Elements of the Packaging Design of an Educational Toy. Social Sciences. 2020; 9(9):162. https://doi.org/10.3390/socsci9090162
Chicago/Turabian StyleJuárez-Varón, David, Victoria Tur-Viñes, Alejandro Rabasa-Dolado, and Kristina Polotskaya. 2020. "An Adaptive Machine Learning Methodology Applied to Neuromarketing Analysis: Prediction of Consumer Behaviour Regarding the Key Elements of the Packaging Design of an Educational Toy" Social Sciences 9, no. 9: 162. https://doi.org/10.3390/socsci9090162
APA StyleJuárez-Varón, D., Tur-Viñes, V., Rabasa-Dolado, A., & Polotskaya, K. (2020). An Adaptive Machine Learning Methodology Applied to Neuromarketing Analysis: Prediction of Consumer Behaviour Regarding the Key Elements of the Packaging Design of an Educational Toy. Social Sciences, 9(9), 162. https://doi.org/10.3390/socsci9090162