1. Introduction
Lameness, or abnormal gait, affects 16% of dairy cows in the United States, making lameness the second most prevalent disease in dairy cattle after mastitis [
1]. Digital dermatitis (DD) is a common cause of lameness, comprising 70.9% and 36.0% of lameness cases in heifers and cows, respectively [
1]. The economic impacts of DD are
$64 to
$153 per episode due to reduced milk production, discarded milk, treatment costs, and additional labor [
2,
3]. Furthermore, premature culling obligates producers to expand their replacement heifer herd. Because heifers consume inputs without contributing to milk production, a larger replacement heifer herd inflates the economic cost [
4] and carbon footprint [
5] per unit of milk. Thus, reducing the incidence of DD and associated lameness has great potential to benefit animal welfare, the producer’s profit margin, and the environment, bolstering the three pillars of sustainability.
Heritability estimates for DD range from 0.01 to 0.4 [
6,
7,
8], indicating genetic contributions to DD susceptibility along with a strong environmental influence. Reducing DD incidence, therefore, will likely be achieved through a combination of management and genetic approaches informed by the etiology of DD. Although the etiology of DD has not been completely elucidated, multiple bacterial phylotypes belonging to the genus
Treponema are consistently found in DD lesions [
9]. Accordingly, the main environmental management method for reducing DD incidence is medicated foot baths [
10,
11], though this treatment is expensive, with estimates of ~
$42 per cow per year [
12]. Additionally, the disinfectant compounds commonly used in foot baths raise environmental and health concerns, as the primary ingredients, copper sulfate and formaldehyde, are environmental pollutants [
13] and carcinogenic [
14], respectively. To alleviate these issues and improve DD prevention, some producers emphasize feet and leg conformation scores or indices that include claw health when selecting sires and, increasingly, rely upon genetic testing for heifers. However, the low genetic correlation between conformation traits and claw health impairs efficient indirect selection against claw lesions when using selection on conformation traits [
15].
Currently, no selection index exists specifically for DD susceptibility. Targeted genetic selection against DD and associated lameness requires the identification of genomic regions influencing DD susceptibility. To find the contributing quantitative trait loci (QTL), genome-wide association studies (GWAS) have been undertaken, although the results to date have been discordant. Previous studies found significant and suggestive single nucleotide polymorphisms (SNPs) on
Bos taurus autosomes (BTAs) 1, 3, 5, 6, 8, 9, 10, 14, and 26 [
6,
16,
17,
18,
19], or no suggestive or significant SNPs [
20].
In an effort to improve upon and refine past studies, the present study used strict phenotyping, dairies with similar management practices, and a high-density SNP genotyping array to identify the associations between DD and genomic regions. We hypothesized that certain genetic markers would be associated with DD susceptibility, and that those markers would have small effects. Our results revealed multiple small-effect SNPs were associated with DD and defined QTL that contained candidate genes related to immune function and wound healing, supporting our hypothesis.
2. Materials and Methods
Four commercial dairies in the Central Valley of California, two of which had participated in our previous heritability study [
8], provided hoof trimming records and blood samples from which to generate genotypic data. All the procedures were conducted in accordance with the ethical standards set by the University of California, Davis, and approved by the Institutional Animal Care and Use Committee.
2.1. Phenotypic Data
Hoof trimming records were used to generate binary and quantitative phenotypes. Claw lesions and lameness issues were diagnosed by a single hoof trimmer servicing three of the dairies (dairies A, B, and C), and a different hoof trimmer servicing the fourth dairy (dairy D). The hoof trimmer servicing three dairies was trained by Dr. Steven Berry, a veterinarian specializing in claw lesions who offered hoof trimming training workshops to the industry and was a coauthor of our earlier paper [
8], and the other trimmer shadowed trained trimmers to standardize the diagnostics. Claw lesions were diagnosed and recorded while the cow was restrained. Claw lesion types and the foot with DD lesions were recorded into the cow’s electronic record (dairies A and D) or maintained in a hard copy format (dairies B and C). Each type of claw lesion (e.g., DD, sole ulcer, laminitis, white line disease, foot rot, etc.) and miscellaneous lameness event (e.g., rock, cut, etc.) was tallied for each cow.
Both hoof trimmers utilized similar criteria for defining instances of DD in the cattle to reduce the phenotypic classification variability; specifically, DD was recorded for cows with raised, inflamed lesions on the skin above the heel of the foot or above the interdigital space on the front of the foot. Routine hoof trimming varied by dairy: cows were trimmed at the beginning and middle of lactation, during dry off, and when exhibiting altered gait (dairy A); during dry off and when exhibiting altered gait (dairy B and C); and only when exhibiting altered gait (dairy D). Cases were defined as cows who had exhibited at least one DD lesion, whereas controls had no DD or other lameness records and were 6.5 years of age or older to avoid misphenotyping younger cows who had insufficient time to develop lameness events. Cows may have multiple bouts of DD over their lifetime and, in some cases, the first instance of DD may have occurred before the cows were in milk (i.e., as heifers). Because DD lesions typically last for four to six months [
21,
22], we defined independent DD lesion episodes as those that were separated by at least six months. Cows with two or more independent DD episodes were considered recurrent cases. Digital dermatitis records that were less than six months apart were considered repeated records of one persistent DD episode. Digital dermatitis was analyzed as a binary phenotype to identify loci influencing general susceptibility to DD and as a quantitative phenotype calculated as the total number of independent DD lesions a cow had divided by the total number of hoof trimming records to standardize the number of lesions by the number of hoof trimming records for each cow. Consequently, the quantitative phenotype for a control cow was zero. Digital dermatitis was also analyzed as a recurrent phenotype (cases with ≥2 DD episodes vs. controls) to identify the loci contributing to reoccurring DD episodes.
2.2. Genome-Wide Association and Linear Mixed Model Analyses
Genomic DNA was extracted from whole blood samples using the QIAGEN QIAamp DNA Blood Mini Kit (QIAGEN Inc., Valencia, CA, USA) and quantified using the NanoDrop (ND-2000 v3.2.1) spectrophotometer (Thermo Scientific, Wilmington, DE, USA). DNA samples were genotyped on the BovineHD BeadChip (777962 SNPs, Illumina Inc., San Diego, CA, USA) by GeneSeek (Lincoln, NE, USA). Raw and processed microarray data were submitted to the NCBI Gene Expression Omnibus database (GEO series record GSE159157). Illumina’s GenCall algorithm was used to call genotypes.
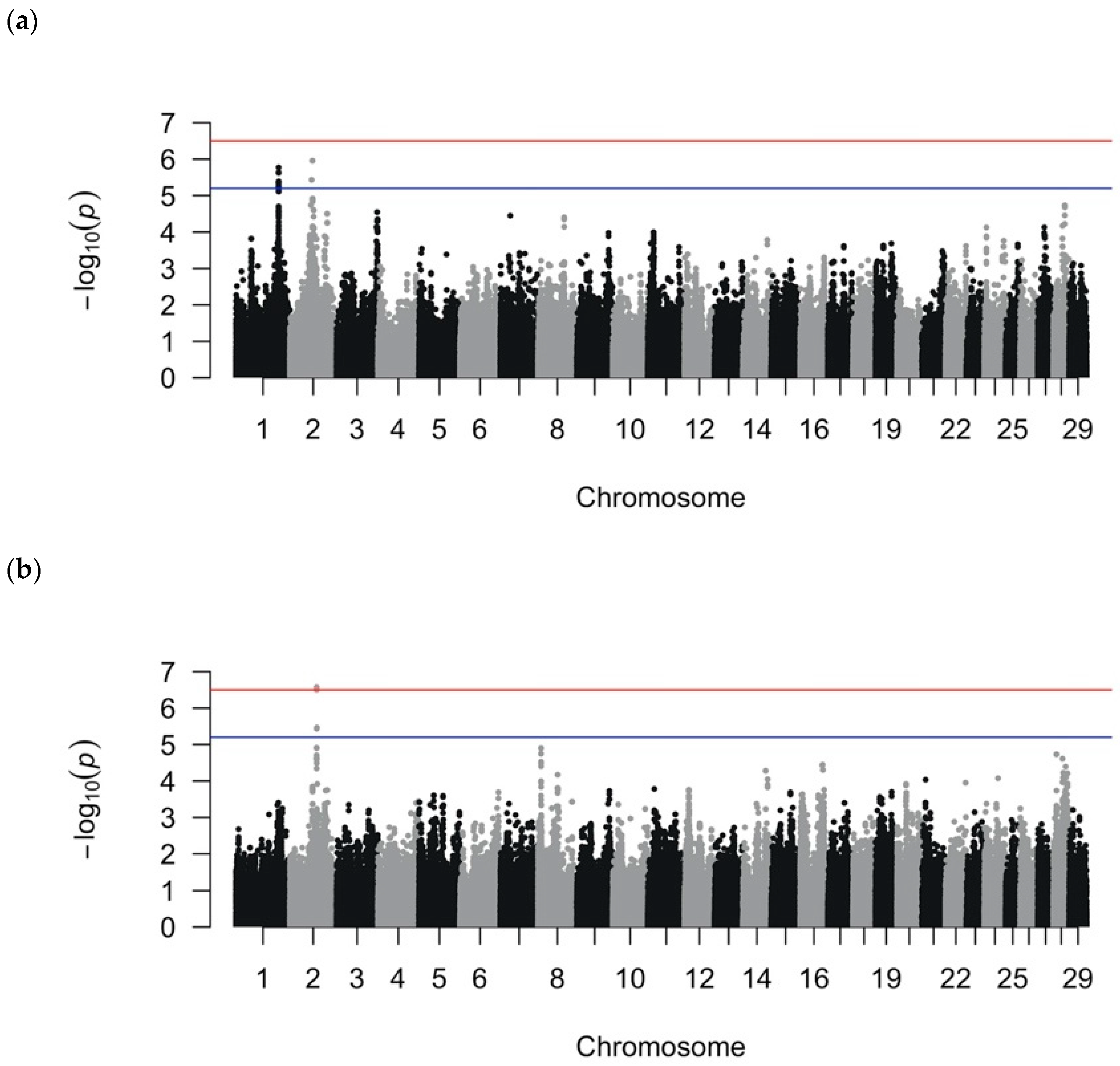
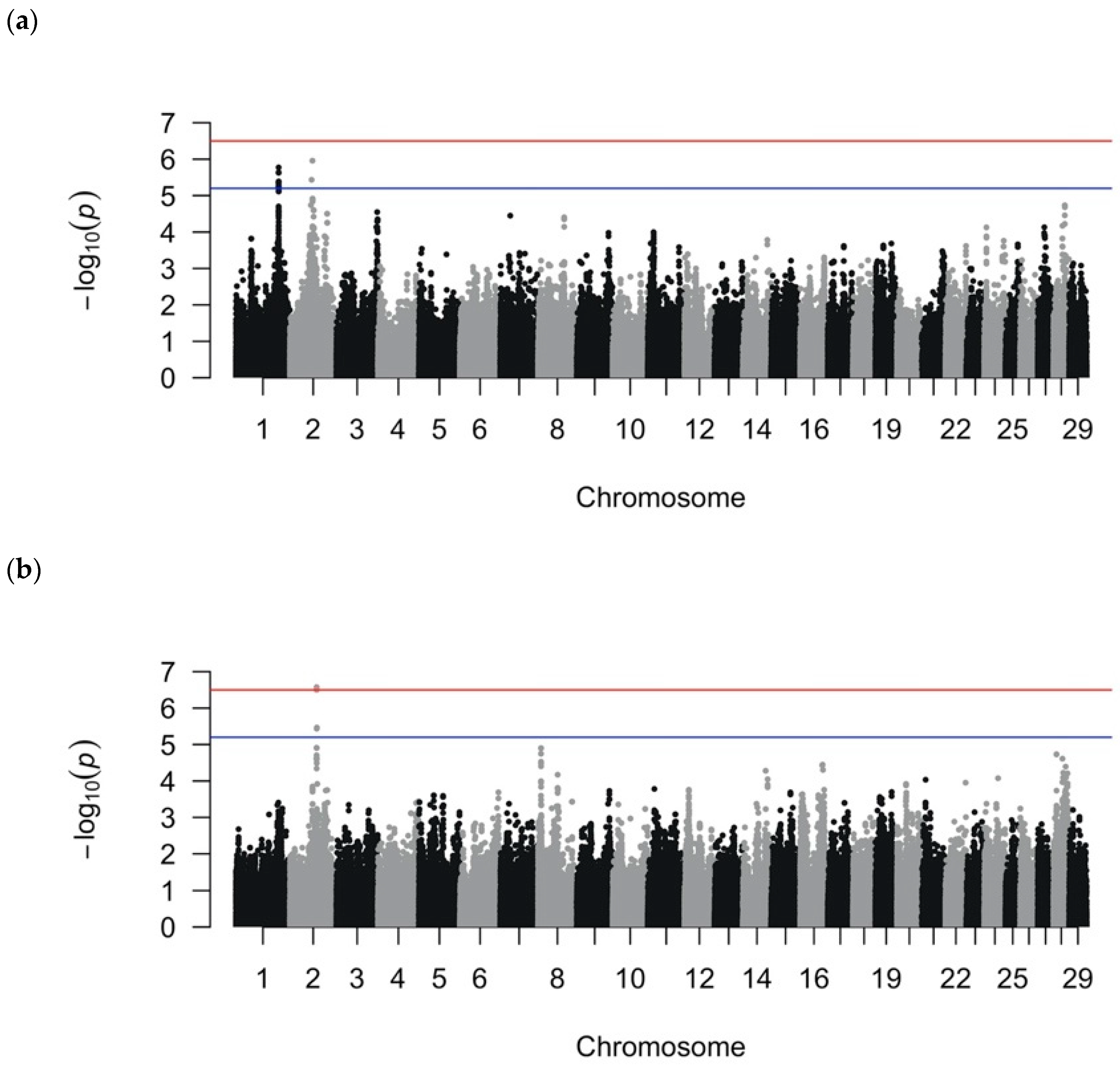
GWAS were performed using the binary, quantitative, and recurrent phenotypes using the SNP coordinates from the ARS-UCD1.2 map (accessed August 2020 from the National Animal Genome Research Project’s Cattle Genome Analysis Data Repository (
https://www.animalgenome.org/repository/cattle/UMC_bovine_coordinates/), version last modified 11 September 2018). The quality filtering of SNP genotypes was performed using PLINK 1.9 [
23,
24] to remove from further analysis any cows having less than 5% of all SNPs genotyped and SNPs missing genotypes in more than 5% of the cows. SNPs with a minor allele frequency of less than 0.05 were removed to exclude rare variants, and SNPs that deviated significantly from the Hardy–Weinberg equilibrium (
p < 1 × 10
−6) in controls were removed to exclude systematic genotyping errors.
Family structure is extremely prevalent in the dairy population from breeding elite bulls to hundreds to tens of thousands of cows. To visualize the genetic similarity among cows at this initial dairy, a multi-dimensional scaling (MDS) analysis was performed and the first two dimensions were plotted. The GWA analyses were performed using the genetic analysis program Genome-wide Complex Trait Analysis (GCTA) [
25] to fit a linear mixed model (LMM) that tests for the association of SNP genotypes with binary and quantitative DD phenotypes. An LMM was selected for its ability to incorporate a genetic relatedness matrix to correct for familial relatedness and population structure. Linear mixed models are designed for quantitative phenotypes, as LMMs assume that phenotypes are normally distributed; however, LMMs have also been routinely used to analyze binary traits [
26,
27]. A genetic relatedness matrix was computed and included along with farm as a covariate in the LMM. When fitting the LMM for each SNP, the LMM included the chromosome of the candidate SNP being tested. To reduce false positive associations due to multiple testing across many loci without being overly stringent, the effective number of independent SNPs (M
e) after linkage disequilibrium (LD) pruning was determined using the Genetic Type I error calculator (GEC) and used as the denominator for Bonferroni-corrected thresholds [
28]. Significant SNPs were defined as those with
p < 0.05/M
e, whereas suggestive SNPs were defined as having
p < 1/M
e [
29]. To calculate the genomic inflation factors (λ
GC), chi-squared test statistics were first generated from association
p-values, and the median of the resulting chi-squared distribution was divided by the median of the expected chi-squared distribution. Quantile-quantile plots (qqplots) and Manhattan plots were plotted in R [
30] using the package qqman [
31].
2.3. Random Forest Analysis
Random forest (RF) analysis was performed as an additional method for identifying SNPs that appeared to importantly contribute to disease phenotypes. Random forests do not make any assumptions about the inheritance model (additive, dominant, recessive) and are able to test multiple SNPs jointly for association with phenotype. Additionally, the RF approach is unaffected by an uneven farm distribution of cases and controls because RF builds decision trees and estimates the importance of each feature by the frequency it appears in the decision trees, rather than estimating parameters for a model. Consequently, RFs avoid estimating parameters for which there are no data. These properties make RFs well equipped to identify structure within complex genetic architectures like DD susceptibility. Specifically, RF can accommodate data despite uneven sampling across farms, in which contributing SNPs may have different modes of inheritance and where epistasis is likely prevalent.
After converting quality-filtered binary PLINK files into VCF files split by chromosome in PLINK 1.9 [
24,
32], all the missing genotypes were imputed using BEAGLE 5.1 [
33] because the RF analysis cannot handle missing genotypes. The resulting VCF files were converted back to binary PLINK files, which were LD-pruned using a threshold of R
2 ≥ 0.90 to avoid diluting the importance of SNPs in strong LD during the RF analysis [
34] and recoded to additive and dominant component files suitable for importing into R. The additive component (i.e., genotypes coded as 0/1/2 minor alleles) was used as input for the RF analysis in R using the caret package [
30,
35]. For binary and quantitative phenotypes, RF analysis was implemented with all genome-wide SNPs in one run to estimate the relative importance of explainers, comprised of SNP genotypes and farm. For both runs, the same random sample of two thirds of the cows was used to train the model and calculate variables of importance for each explainer. The RF run for each phenotype built 500 decision trees that included three values of
mtry, the number of predictors considered at each node of the tree. The value of
mtry that yielded the most accurate model was used as the final model. The most important explainer was assigned an importance variable of 100, and the other explainers were assigned importance variables relative to the most important explainer (e.g., an explainer with an importance of 50 is 50% as important as the most important explainer). To assess the accuracy of the final model, the remaining third of cows was used as the test population, using the explainers and their relative importance to predict phenotype.
After evaluating the model accuracy using the test population, a threshold of importance was determined by ranking and plotting the SNPs the RF identified as important for each chromosome in a scree plot and finding the rank of the second-order point of inflection using the d2uik option in the inflection package in R [
36,
37]. SNPs ranking equally as or more important than this threshold were considered important and included in further analyses.
2.4. Bayesian Regression to Assess Model Predictability and Validation
To assess the collective predictive ability of the top SNPs identified in the LMM and RF analyses, the top SNPs from each analysis (i.e., significant and suggestive SNPs from LMM analyses, important SNPs from RF analyses) were tested for association with phenotype using Bayesian regression. Bayesian regression was selected because of its ability to fit multiple SNPs simultaneously while also recognizing that the majority of SNPs have small effects on DD susceptibility [
20,
38], that some SNPs are likely correlated due to LD, and that not all farms contributed controls to the analyses. Additionally, Bayesian regression enables the thorough evaluation of model fit through leave-one-out (LOO) validation and posterior predictive checking (PPC), the latter of which is a uniquely Bayesian feature.
Suggestive and significant SNPs from the LMM GWAS and important SNPs from the RF analysis were used as predictors along with farm in each Bayesian regression model. Similar to the RF analyses, SNP genotypes were coded as 0/1/2 minor alleles. A Bayesian regression model was fitted for each combination of GWAS method (LMM and RF) and phenotype (binary and quantitative), such that four models were fitted: LMM-binary and RF-binary were fitted using a Bayesian logistic regression model, and LMM-quantitative and RF-quantitative were fitted using a Bayesian generalized linear model for continuous data. Susceptibility to DD appears to be complex and the majority of SNP effects are likely to be small [
20,
38]. To reflect this distribution of SNP effects, a normal prior with a small-scale N (0,1) was used for the distribution of predictors for all four models. Each of the four models was fitted by sampling from the posterior distribution using the Hamiltonian Monte Carlo algorithm, a Markov chain Monte Carlo (MCMC) algorithm, using the rstanarm package in R [
39]. Four parallel chains sampled the posterior distribution, and each chain was run for 10,000 iterations with a warmup of 2500 iterations, keeping every 25th iteration to avoid autocorrelation.
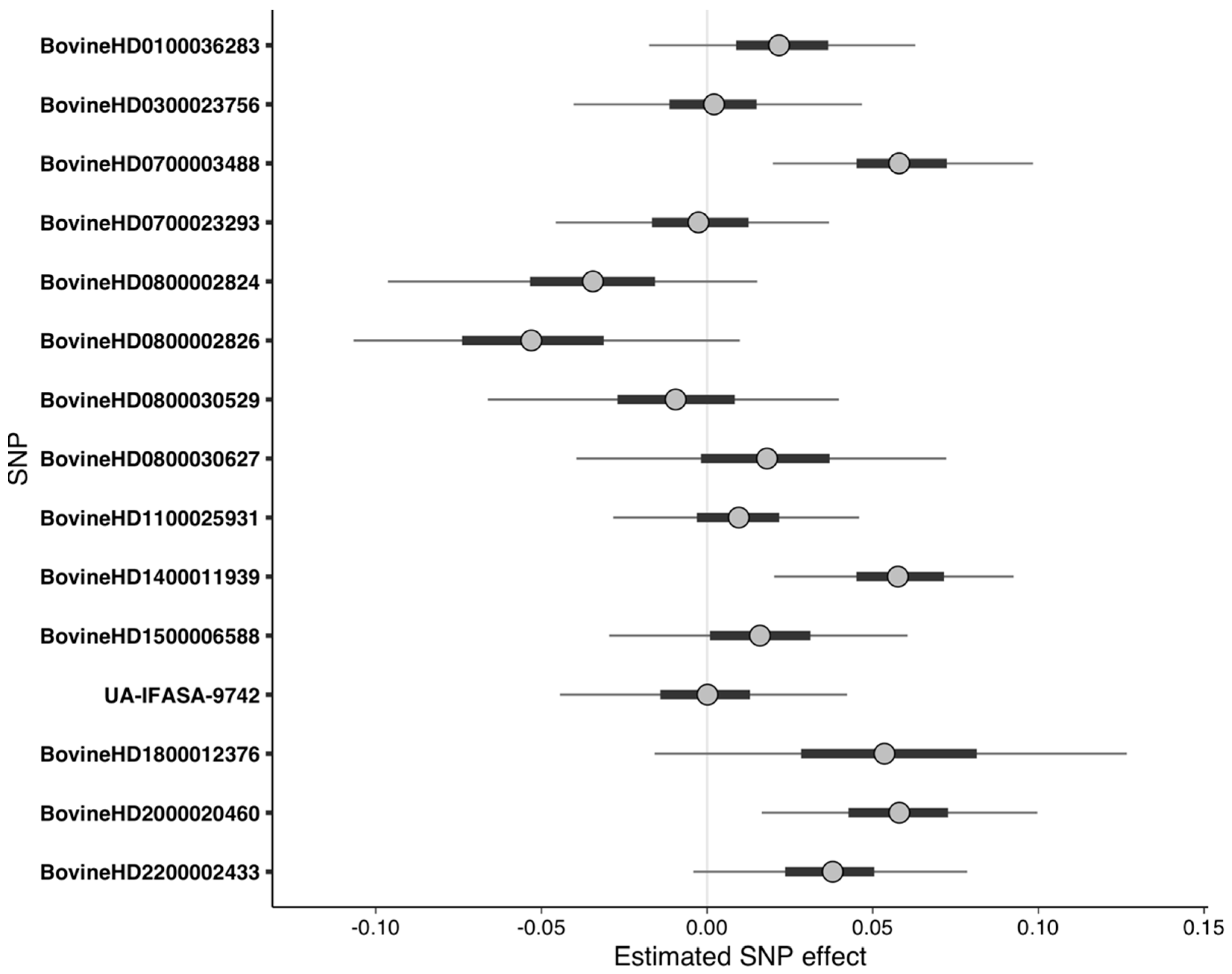
Unlike frequentist regression, which would output a point estimate of each SNP effect, Bayesian regression outputted a distribution of where the true value of each SNP effects fell, defined by the Bayesian uncertainty interval (UI). SNPs with 95% UIs that did not include zero were considered significantly associated with DD susceptibility. For each significant SNP, the probability of disease given a genotype at the significant SNP (coded as 0/1/2 minor alleles) and a 0 genotype at all other SNPs was calculated using the median of SNP effect estimates as point estimates in the inverse logit equation using the R package arm [
40]. Diagnostic and Bayesian UI plots for the posterior medians of SNP effects were plotted using the bayesplot package. Leave one out cross validation was performed using the loo package [
41,
42] in R to predict the phenotype of each cow using the SNP effects estimated from all other cows. The reliability of prediction was assessed using the Pareto
k diagnostic values outputted from the LOO analysis. Posterior predictive checking (PPC) from the bayesplot package [
43] was used to assess the goodness of fit of the model. Posterior predictive checking assessed how well the estimated predictor effects were able to simulate phenotypes with a similar distribution to that of the observed phenotypes.
2.5. Defining and Annotating QTL Regions
For the significant and suggestive SNPs identified in the LMM analyses and the important SNPs identified in the RF analyses, the QTL boundaries and regions were defined and annotated. Because SNPs are more likely to be in LD with causal variants than be causal themselves, the linkage disequilibrium in the regions flanking these top SNPs was used to define the boundaries of QTL, per the methods used in previous GWAS studies [
44,
45]. Specifically, SNPs within 5 Mb of significant and suggestive SNPs that were also in LD (r
2 ≥ 0.5) were considered as belonging to the same QTL. The SNPs furthest upstream and downstream that were in LD with the target suggestive or significant SNP defined the boundaries of the QTL. Overlapping QTL were combined into one QTL. QTL from the LMM and RF analyses were compared to discern whether the two analyses found the same QTL. QTL regions that were identified in both LMM and RF analyses were explored for candidate genes. Additionally, QTL defined by SNPs that were significant in the Bayesian regression analyses were also explored for candidate genes. Candidate genes were defined as genes falling in QTL regions identified in both LMM and RF analyses or in QTL defined by SNPs that were significant in Bayesian regression and were functionally relevant to DD etiology.
To annotate the QTL regions, the genomic regions search in FAANGMine v1.1 [
46] using the ARS_UCD1.2 assembly was implemented to find genes within the QTL regions. The RefSeq identifiers of genes within the QTL were used in a gene ontology and pathway enrichment analysis in FAANGMine to discern whether the genes belonged to higher-order functions and pathways related to DD etiology. For the gene ontology and pathway enrichment analyses, the Benjamini Hochberg test correction was used to correct for multiple testing, and all the RefSeq genes in
B. taurus were used as the background population. To identify the functions of individual genes, protein coding genes in QTL defined by SNPs that were significant in two analyses (i.e., LMM, RF, and/or Bayesian regression) were searched in the Mouse Genome Informatics batch query database (
http://www.informatics.jax.org/batch) using the mammalian phenotype option [
47].
4. Discussion
The genetic component of DD susceptibility is highly complex and heterogeneous [
20,
38], as demonstrated by the numerous and varied QTL detected in previous studies [
6,
16,
17,
18,
19,
20]. We sought to further identify the QTL contributing to DD susceptibility using a high-density SNP array and LMM and RF analytical approaches on well-phenotyped DD cases and controls. The LMM GWAS and RF analyses revealed suggestive, significant, and important SNPs that defined QTL regions in binary, quantitative, and recurrent DD phenotypes. The LMM GWAS using recurrent DD cases vs. controls indicated that the recurrent DD cases were contributing to the significance of association in the LMM-binary GWAS on BTA1 and BTA2, but not in the LMM-quantitative GWAS. Bayesian regression allowed for an intuitive estimate of SNP effects and the robust evaluation of model fit through the LOO and PPC analyses, providing additional distinctions of informative and noninformative SNPs among the top SNPs. QTL regions were explored for candidate genes if the QTL was defined by the top SNPs (i.e., significant or suggestive SNPs from LMM analyses or important SNPs in RF analyses) that were also significant in Bayesian regression or were top SNPs in both LMM and RF analyses. That is, nine QTL were investigated further (
Table 6).
Within these QTL regions, we identified likely candidate genes based on their relevance to DD etiology. DD is associated with Treponema bacteria invading the dermis and epidermis, likely through hair follicles, and results in a raised erosive lesion [
21,
49]. The infection elicits a strong initial activation of the innate immune response [
50] that is then attenuated by the treponemes [
51], leading to prolonged inflammation and a delayed adaptive immune response [
52]. Within the adaptive immune response, the antibody-mediated immune response is mainly responsible for defending the host against extracellular pathogens [
53], such as treponemes. After the immune response, the skin then attempts to heal the wound, a process that is also impaired by treponemes [
51]. As such, changes in the sequence or expression of genes related to maintaining epidermal integrity, immune response, or wound repair could affect a cow’s DD susceptibility and the persistence of a DD lesion. Previous work has indicated that genes related to these three functions were dysregulated in DD lesions [
18,
51]. Therefore, we considered candidate genes as those with associated phenotypes, as determined by MGI, that pertained to these functions and fell within the six QTL regions, resulting in six candidate genes:
CXCR4,
MGAT5,
CACNA1A,
TERT,
SLC9A3, and
AHRR (
Table 6,
Table S2). All six candidate genes were related to immune function, and
TERT was also associated with skin hyperplasia and wound healing (
Table S2). Similarly, we defined functionally relevant gene ontologies and pathways as those related to these three functions. The QTL on BTA18 contained 16 zinc finger genes that were part of the herpes simplex virus 1 infection pathway, implying an immune function of these genes that could also play a role in DD infection (
Table 6).
A limitation of the study is the small sample size. Minimizing phenotypic variation and increasing sample size are both methods to improve the detection of small-effect SNPs, but often pursuing one of these approaches comes at the expense of the other—for example, in this study, large sample size. Our strict phenotypic criteria also caused the controls to be from only two dairies, which was partially accounted for in the LMM analyses by including a covariate term. While the uneven sampling of dairies can be problematic in frequentist methods such as LMM, those issues were avoided in RF analyses and Bayesian estimation because these models account for parameters that did not exist (e.g., a control cow from Farm B or C). Furthermore, the SNPs that defined the QTL regions containing promising candidate genes were significant, suggestive, or important in the LMM and RF analyses, some of which also had nonzero effect sizes estimated from Bayesian regression despite the small sample size. For the quantitative phenotypes, a larger sample size might have more normally distributed phenotypes that the model expects, thereby improving the efficiency of MCMC sampling and more accurate SNP effect estimates. Although the sample size of this study was limited due to our intentionally reducing phenotypic variation, which may have prevented the detection of additional small SNP effects, the sample size was sufficient to very accurately predict the phenotype within the original population. Future replication studies are necessary to determine how well the SNP effects estimated in this study population can be extrapolated to larger populations in different geographical regions and other dairies.
In addition to minimizing phenotyping variation, our GWAS used high-density SNP genotyping to increase the resolution of QTL detection. Previous studies [
16,
17,
20,
38,
54] had larger sample sizes than our study, achieved by using dairies across multiple geographic regions and various lower-density SNP panels (maximum 76 K SNPs). The lower-resolution SNP panels in those studies may have prevented the detection of smaller linkage disequilibrium blocks (<20 kb) in Holstein cattle [
55] and contributed to the inconsistency of genomic regions detected. Although two previous studies found associated loci on BTA1, for one study the suggestive SNPs were in a different region [
6], while the other study did not provide SNP coordinates to permit comparisons [
16]. Similarly, other GWASs also detected the associated SNPs on BTA3 [
17,
19] and BTA14 [
6], but in different regions. Other GWASs did not detect SNPs on the same chromosomes as our GWAS [
54] or did not detect any suggestive or significant SNPs [
20]. The published GWASs with smaller sample sizes using the high-density SNP array were able to find SNPs associated for other traits in Holstein cattle, including digital cushion thickness [
56], mastitis resistance [
57], and fat deposition [
58]. Our study using tightly controlled cases and controls was the first to use high-density SNP genotypes in a GWAS for DD susceptibility for improved resolution and the first to find significant and suggestive SNPs on BTA2, 7, 18, and 20 in regions containing likely candidate genes or genes in relevant pathways. The multiplicity of associated chromosomal regions supports that the genetic component of DD susceptibility is heterogeneous and highly complex, such that different combinations of loci with small effects contribute to DD susceptibility, as suggested by previous authors [
20,
38]. The complex genetic architecture of DD susceptibility likely reflects multiple physiological systems (e.g., immune system, hair morphology, skin matrix remodeling) interacting in the etiology of DD.
The lack of congruence in the genomic regions associated with DD across published studies and the small effect sizes of those QTLs identified further supports that, in addition to many low-impact loci, non-genetic factors strongly influence DD susceptibility. The ranking of farm as the most important predictor in the RF analyses supports the concept that farm management (e.g., hoof trimming regimen, methods of preventing and treating DD) plays a significant role in reducing DD prevalence. Employing genetic selection in combination with environmental management will likely further reduce DD prevalence.






{kind=link}
{kind=link}
{kind=link}
{kind=link}