
Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering

 ,
,
Abstract
Simple Summary
Abstract
1. Introduction
2. Materials and Method
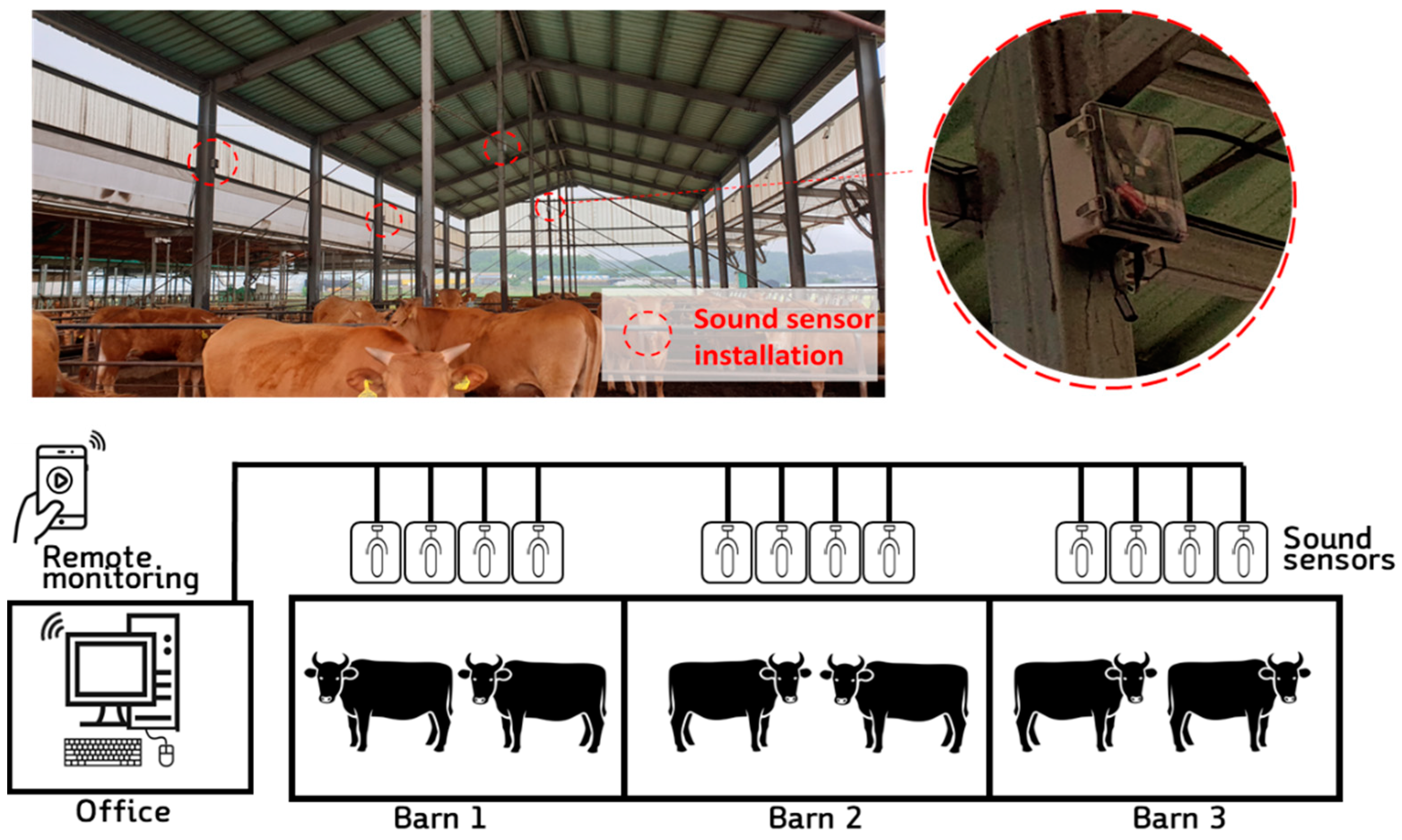
2.1. Description of On-Site Sound Monitoring System
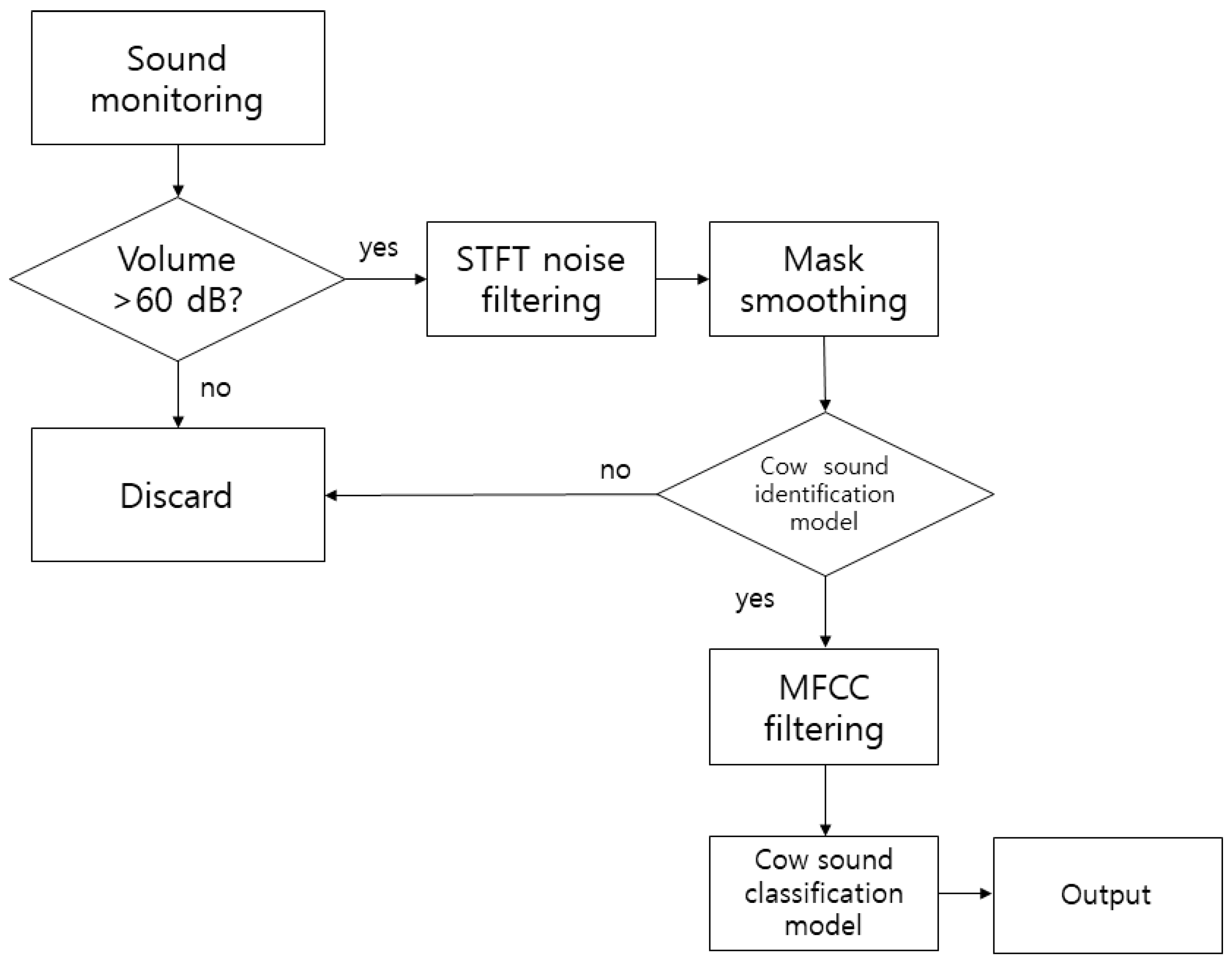
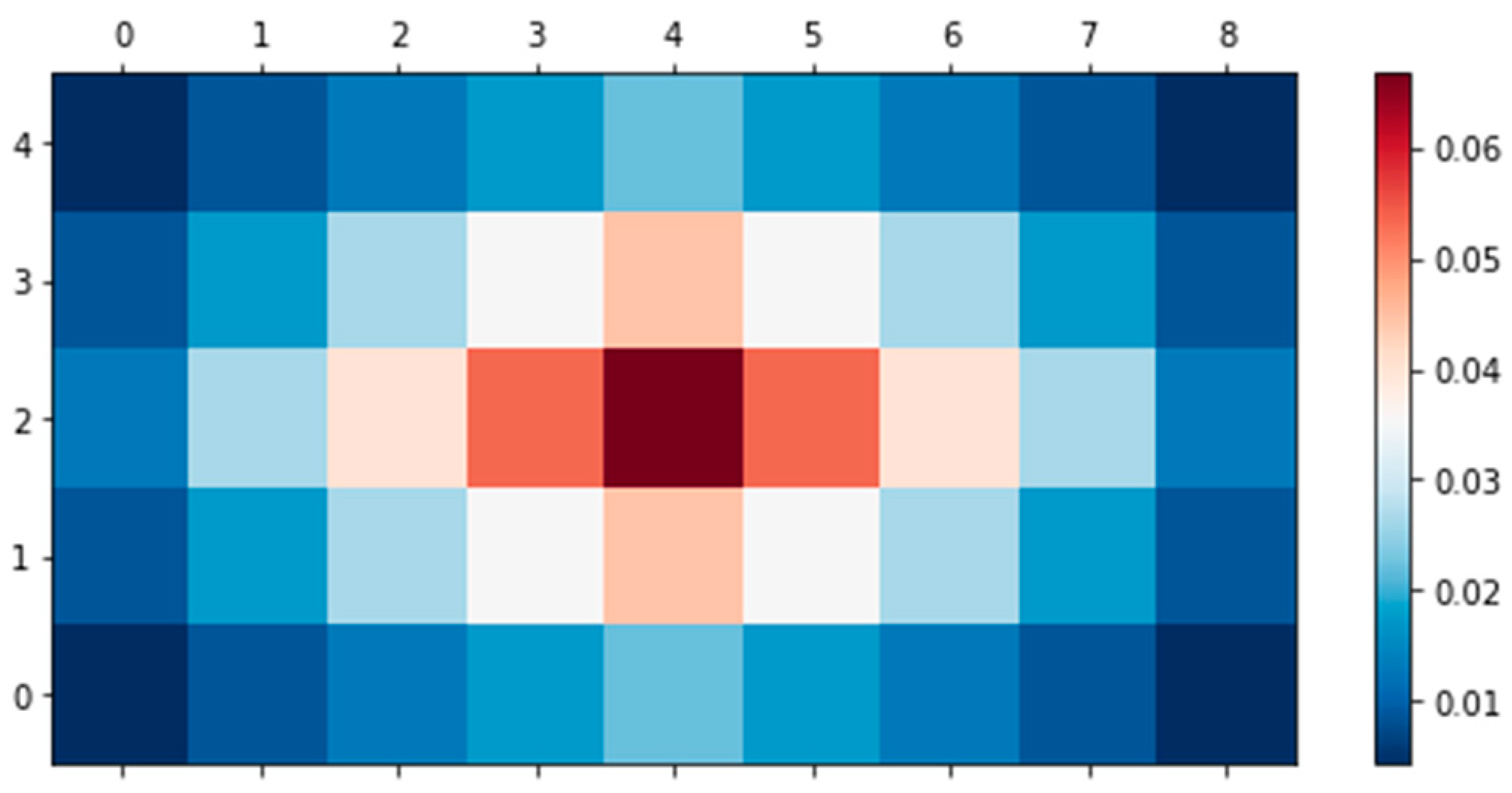
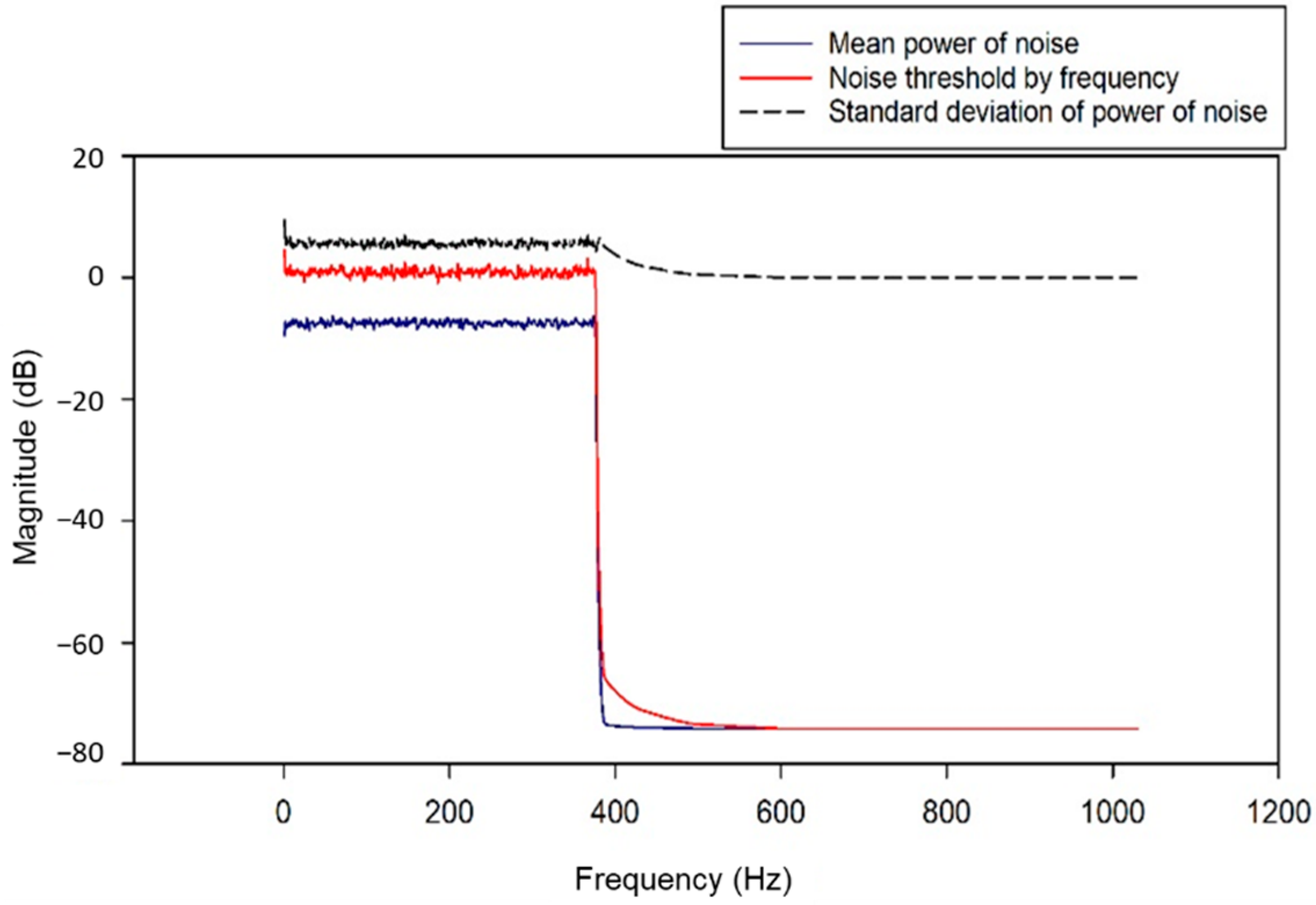
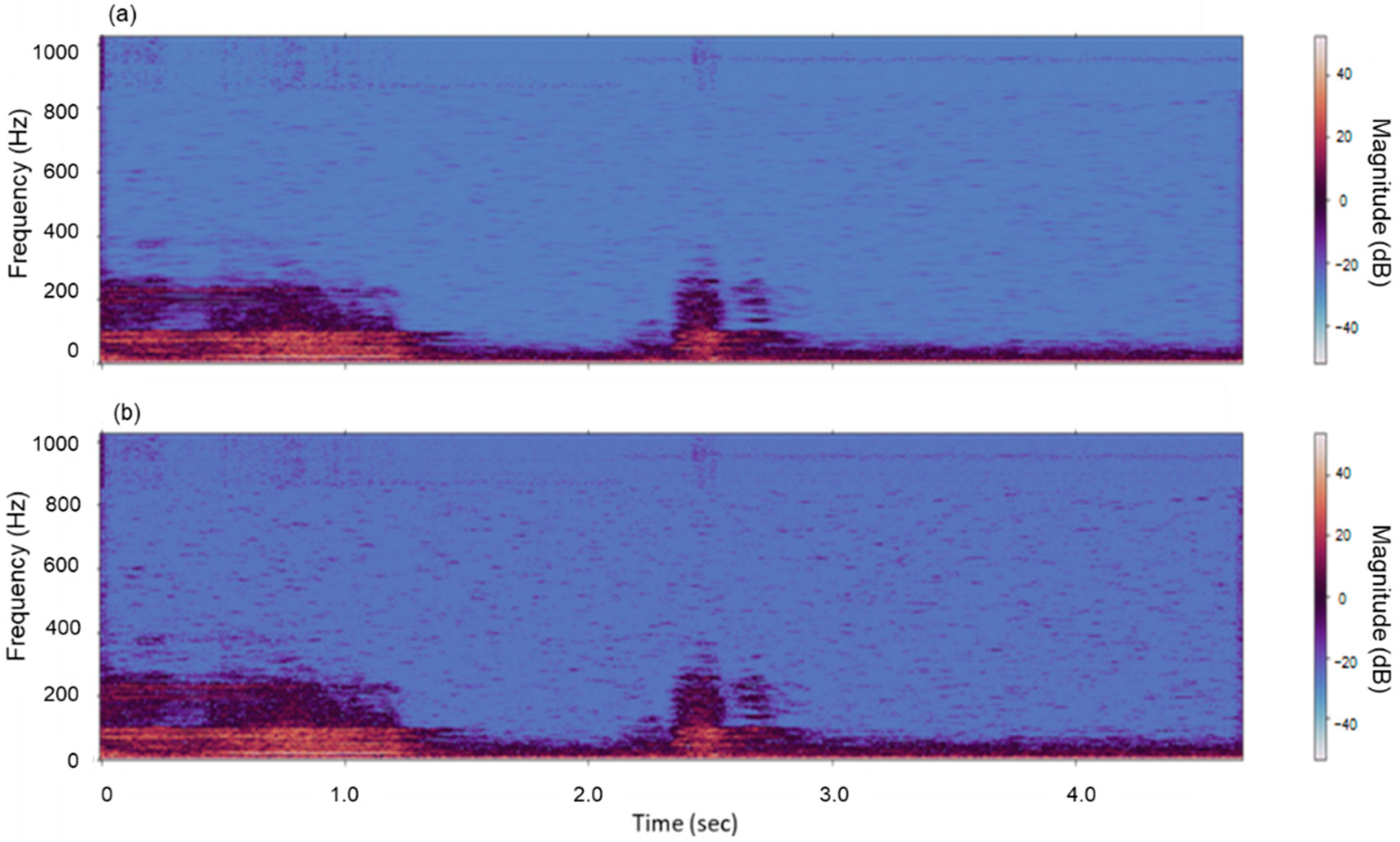
2.2. Noise Filtering Using Short-Time Fourier Transform and Mask Smoothing
2.3. Deep Neural Network Models for Classification
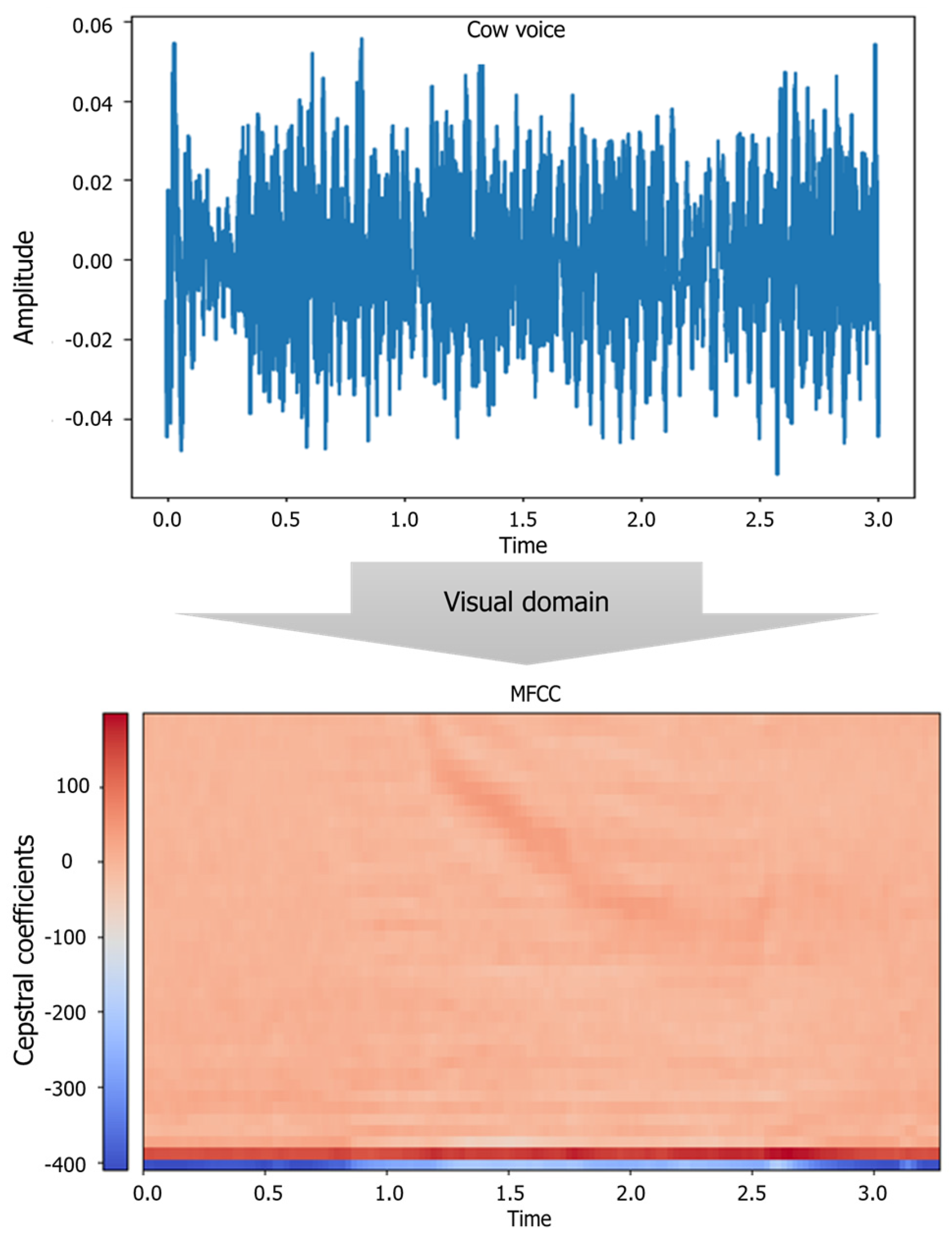
2.3.1. Audio Data Conversion Using Mel-Frequency Cepstral Coefficients
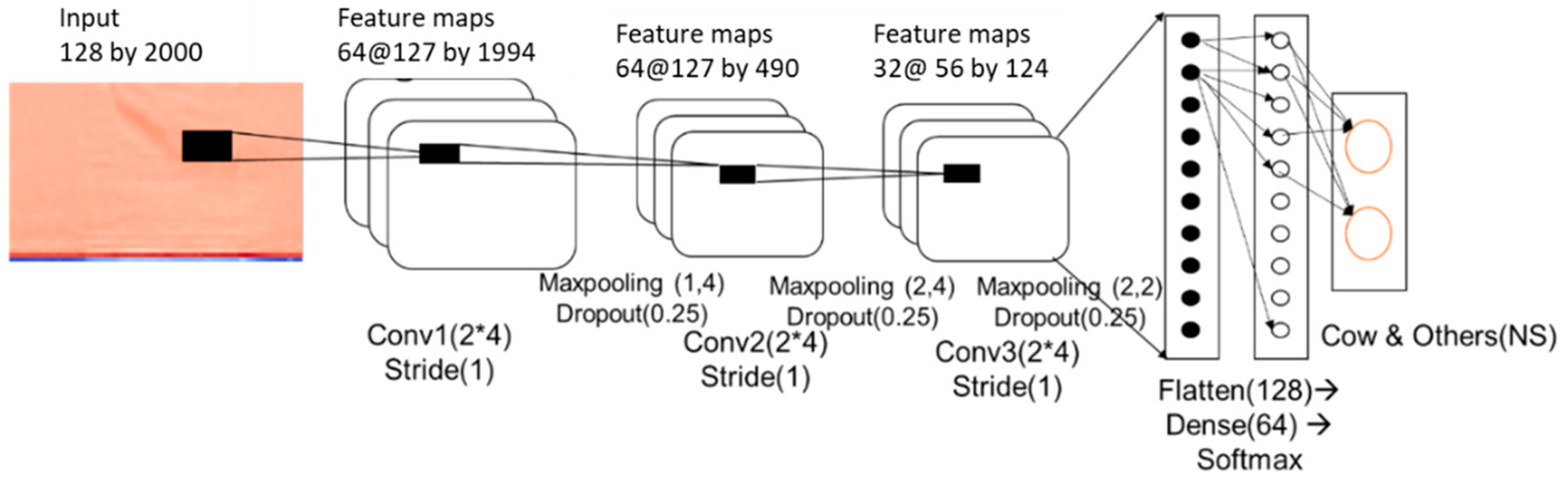
2.3.2. CNN Model for Removing External Sounds
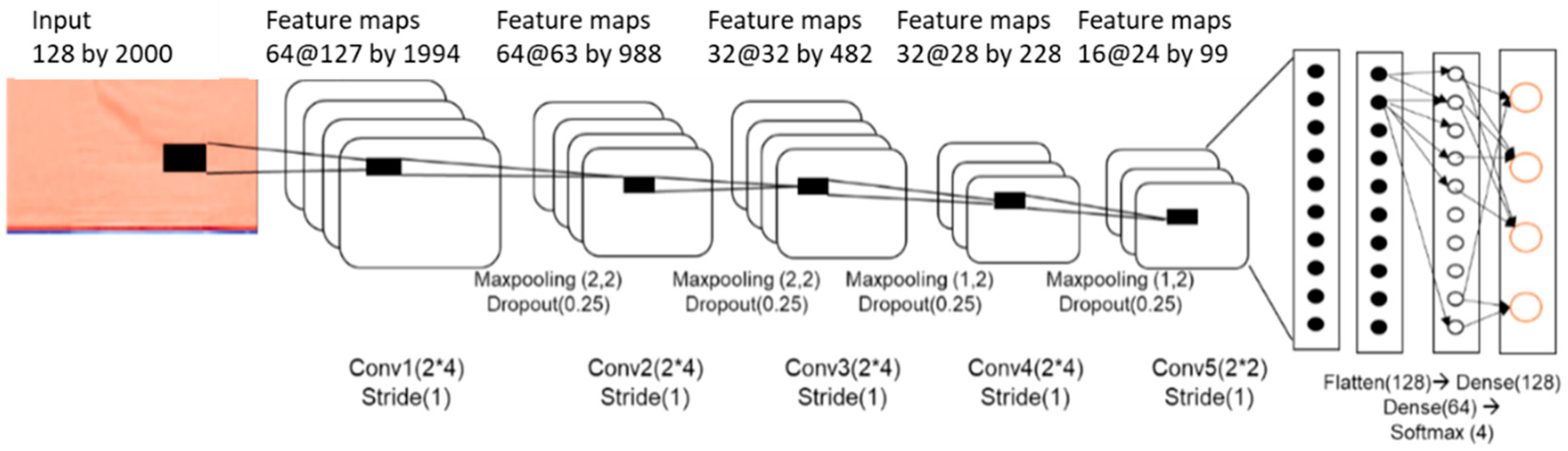
2.3.3. CNN Model for Cattle Behavioral Voice Classification
- Estrus call: the sound of cattle estrus call was collected from 130 Korean cattle breeding cattle (aged 12 to 40 months). This corresponds to the sound produced by individual cows, identified as estrous cows, which are cows that have succeeded in conceiving through artificial insemination. At this time, the vocals produced by the cow through the voice were recorded each voice datum was collected. The proportion of primiparous cattle vocalizing individuals tended to be higher than that of multiparous cattle.
- Food anticipating call: the cattle were in a situation where the feeding time was delayed by up to 3 h (by more than 1 h for 30 Korean calves aged 6 to 8 months). At this time, the acquired sounds were collected and labeled as “Food anticipating call”.
- Cough sound: A recording device was installed in an area with the coughing cows and the recorded files were analyzed. The cough voices were collected under expert judgment at the point of the cow coughing.
- Normal call: The calls were not classified in these three cases and were classified into one class and labeled as “normal call.”
3. Results
3.1. Noise Filter and Mask Smoothing Results
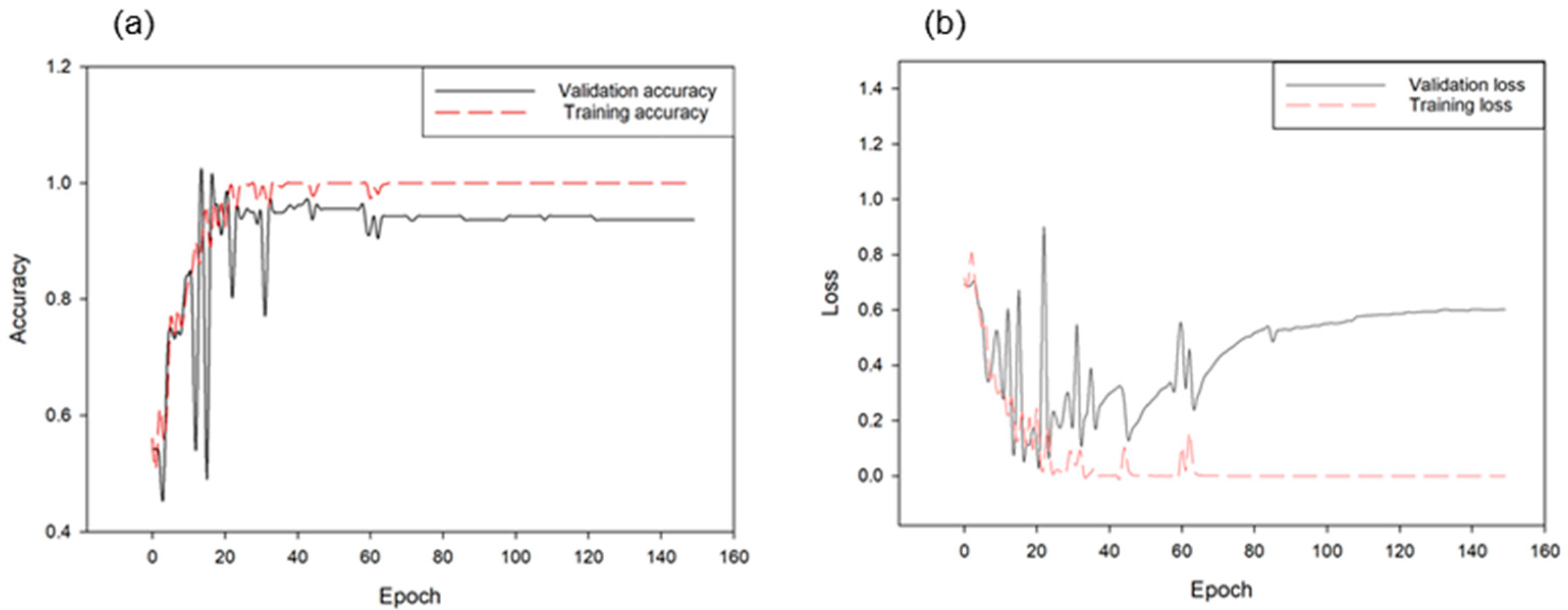
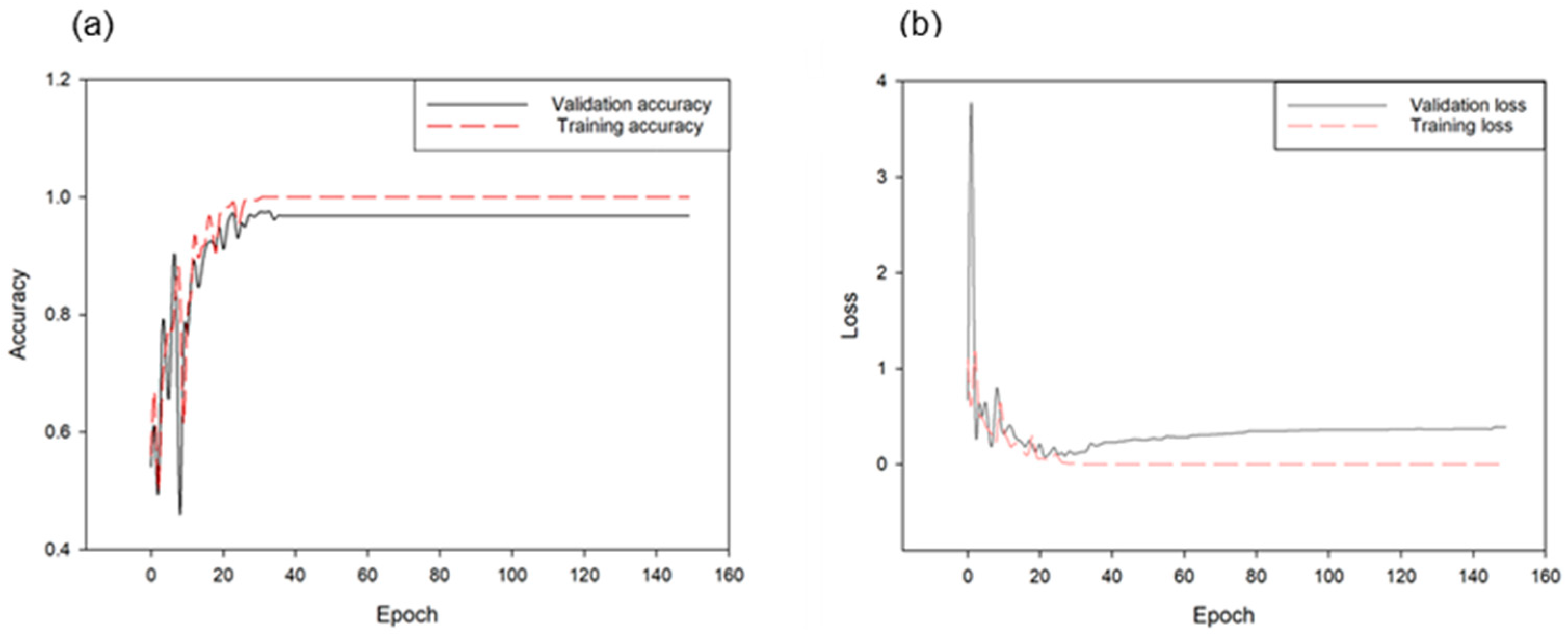
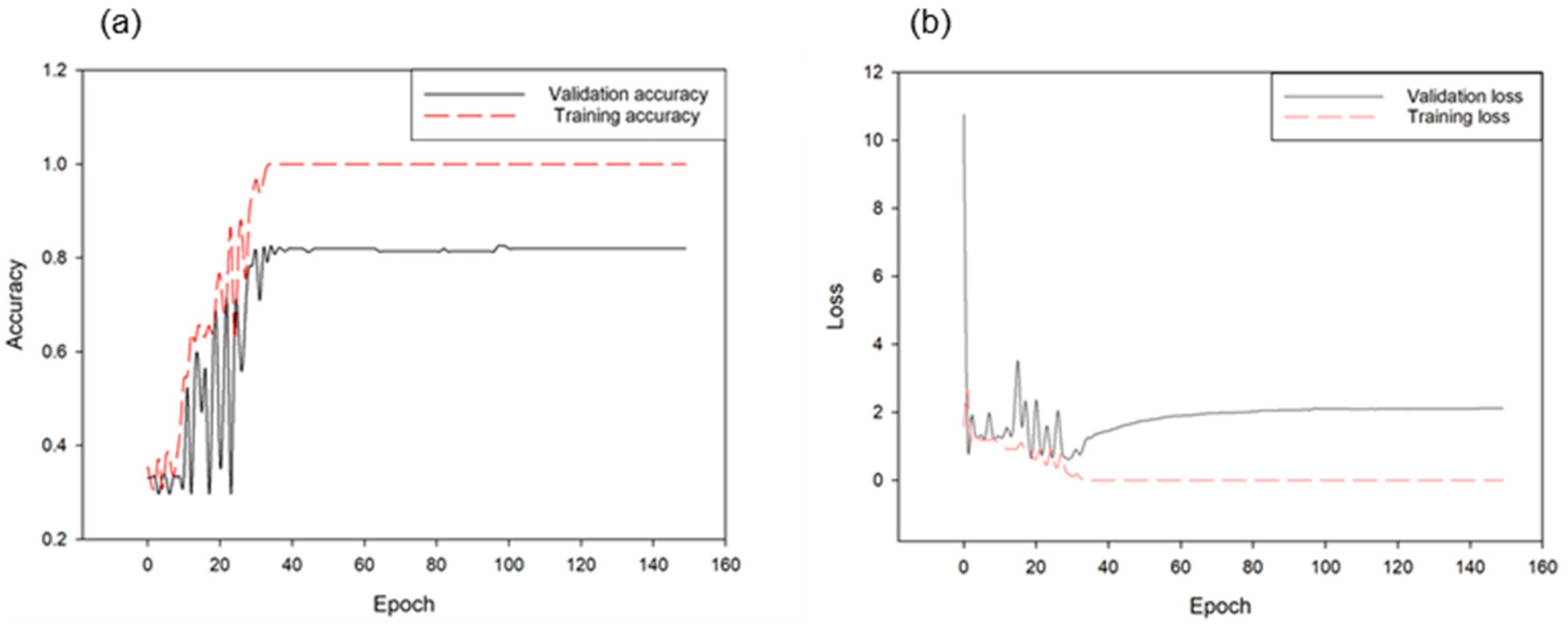
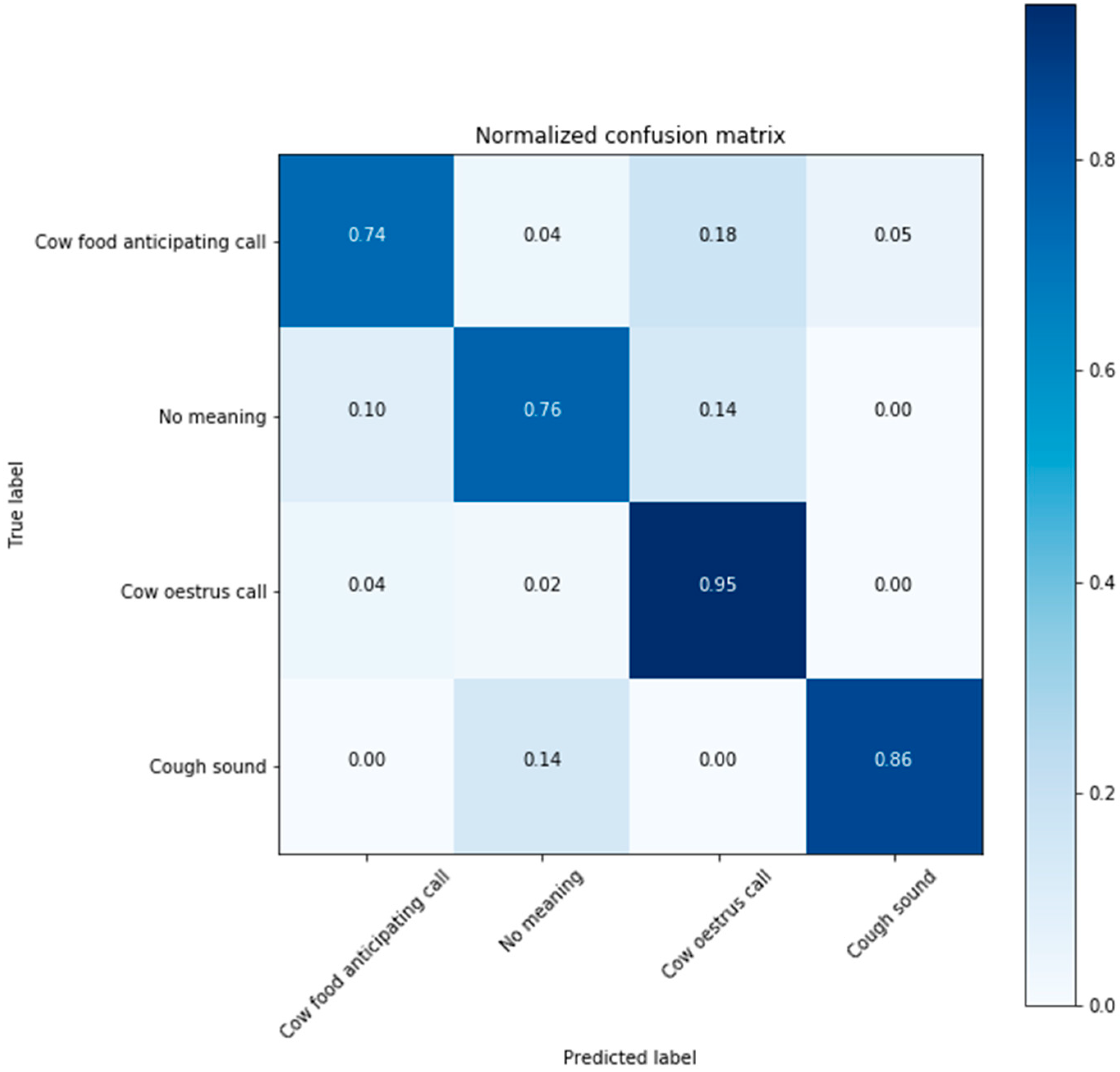
3.2. Deep Neural Network Classification Performance
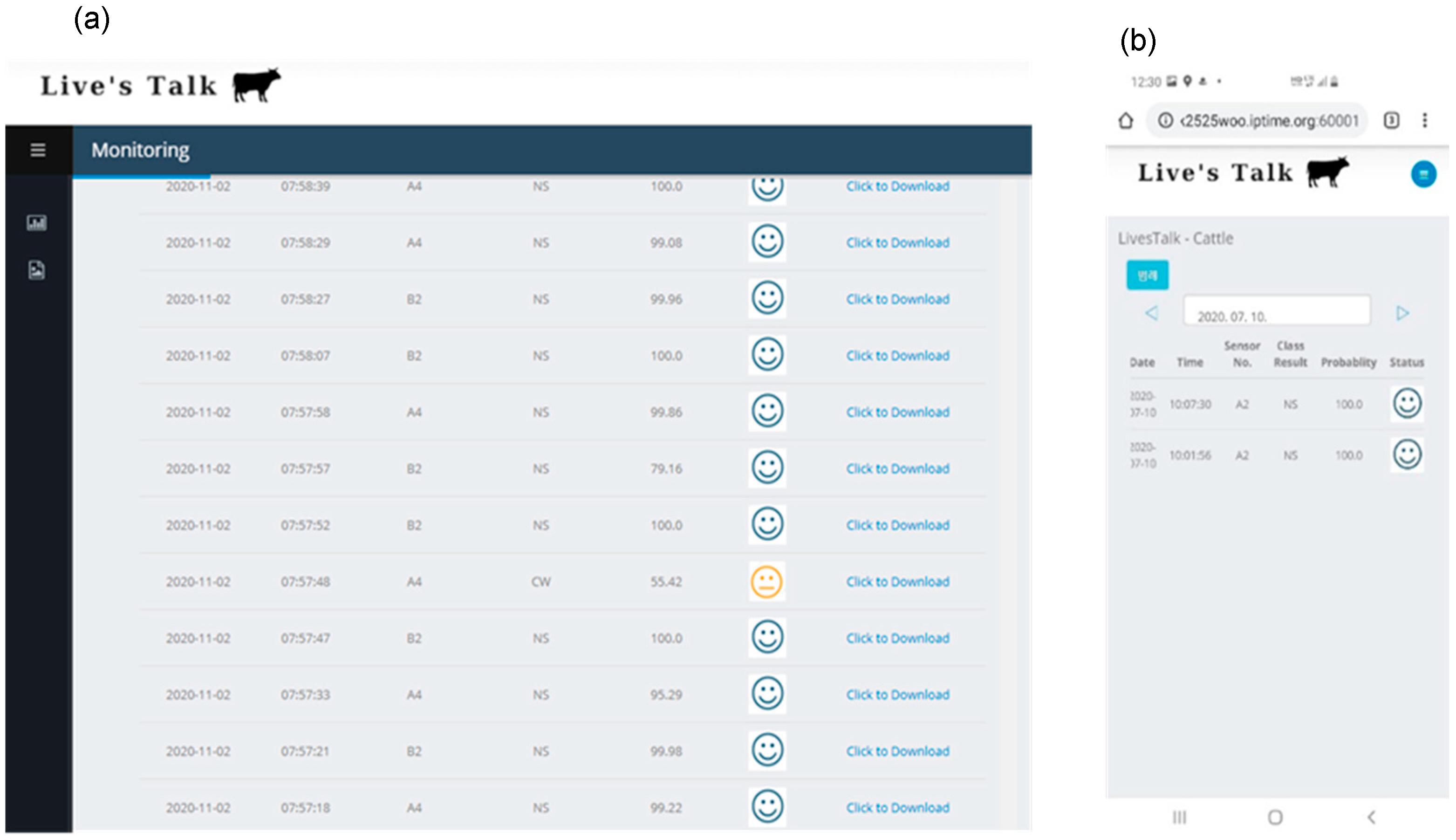
3.3. Developed Web-Based Sound Information Monitoring System
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Nasirahmadi, A.; Edwards, S.A.; Sturm, B. Implementation of machine vision for detecting behaviour of cattle and pigs. Livest. Sci. 2017, 202, 25–38. [Google Scholar] [CrossRef]
- Meen, G.H.; Schellekens, M.A.; Slegers, M.H.M.; Leenders, N.L.G.; Kooij, E.V.E.-V.D.; Noldus, L.P.J.J. Sound analysis in dairy cattle vocalisation as a potential welfare monitor. Comput. Electron. Agric. 2015, 118, 111–115. [Google Scholar] [CrossRef]
- Ikeda, Y.; Ishii, Y. Recognition of two psychological conditions of a single cow by her voice. Comput. Electron. Agric. 2008, 62, 67–72. [Google Scholar] [CrossRef]
- Riede, T.; Tembrock, G.; Herzel, H.; Brunnberg, L. Vocalization as an indicator for disorders in mammals. J. Acoust. Soc. Am. 1997, 102, 3179. [Google Scholar] [CrossRef]
- Yeon, S.C.; Jeon, J.H.; Houpt, K.A.; Chang, H.H.; Lee, H.C.; Lee, H.J. Acoustic features of vocalizations of Korean native cows (Bos taurus coreanea) in two different conditions. Appl. Anim. Behav. Sci. 2006, 101, 1–9. [Google Scholar] [CrossRef]
- Kiley, M. The vocalizations of ungulates, their causation and function. Zeitschrift Tierpsychologie 2010, 31, 171–222. [Google Scholar] [CrossRef]
- Watts, J.M.; Stookey, J.M. Vocal behaviour in cattle: The animal’s commentary on its biological processes and welfare. Appl. Anim. Behav. Sci. 2000, 67, 15–33. [Google Scholar] [CrossRef]
- Watts, J.M.; Stookey, J.M. The propensity of cattle to vocalise during handling and isolation is affected by phenotype. Appl. Anim. Behav. Sci. 2001, 74, 81–95. [Google Scholar] [CrossRef]
- Röttgen, V.; Becker, F.; Tuchscherer, A.; Wrenzycki, C.; Düpjan, S.; Schön, P.C.; Puppe, B. Vocalization as an indicator of estrus climax in Holstein heifers during natural estrus and superovulation. J. Dairy Sci. 2018, 101, 2383–2394. [Google Scholar] [CrossRef]
- Bishop, J.C.; Falzon, G.; Trotter, M.; Kwan, P.; Meek, P.D. Sound Analysis and Detection, and the Potential for Precision Livestock Farming-A Sheep Vocalization Case Study. In Proceedings of the 1st Asian-Australasian Conference on Precision Pastures and Livestock Farming, Hamilton, New Zealand, 16–18 October 2017; pp. 1–7. [Google Scholar]
- De Moura, D.J.; Silva, W.; Nääs, I.D.A.; Tolón, Y.; Lima, K.; Vale, M. Real time computer stress monitoring of piglets using vocalization analysis. Comput. Electron. Agric. 2008, 64, 11–18. [Google Scholar] [CrossRef]
- Fontana, I.; Tullo, E.; Butterworth, A.; Guarino, M. Broiler vocalisation to predict the growth. In Proceedings of the Measuring Behavior, Wageningen, The Netherlands, 27–29 August 2014; pp. 27–29. [Google Scholar]
- McLoughlin, M.P.; Stewart, R.; McElligott, A.G. Automated bioacoustics: Methods in ecology and conservation and their potential for animal welfare monitoring. J. R. Soc. Interface 2019, 16. [Google Scholar] [CrossRef] [PubMed]
- Sheng, H.; Zhang, S.; Zuo, L.; Duan, G.; Zhang, H.; Okinda, C.; Shen, M.; Chen, K.; Lu, M.; Norton, T. Construction of sheep forage intake estimation models based on sound analysis. Biosyst. Eng. 2020, 192, 144–158. [Google Scholar] [CrossRef]
- Ntalampiras, S. On Acoustic Monitoring of Farm Environments. In Programmieren für Ingenieure und Naturwissenschaftler; Springer: Berlin/Heidelberg, Germany, 2019; pp. 53–63. [Google Scholar]
- Sahidullah, M.; Saha, G. Design, analysis and experimental evaluation of block based transformation in MFCC computation for speaker recognition. Speech Commun. 2012, 54, 543–565. [Google Scholar] [CrossRef]
- Khunarsa, P.; Mahawan, J.; Nakjai, P.; Onkhum, N. Nondestructive determination of maturity of the monthong durian by mel-frequency cepstral coefficients (MFCCs) and neural network. Appl. Mech. Mater. 2016, 855, 75–81. [Google Scholar] [CrossRef]
- Devi, I.; Singh, P.; Lathwal, S.S.; Dudi, K.; Singh, Y.; Ruhil, A.P.; Kumar, A.; Dash, S.; Malhotra, R. Threshold values of acoustic features to assess estrous cycle phases in water buffaloes (Bubalus bubalis). Appl. Anim. Behav. Sci. 2019, 219, 104838. [Google Scholar] [CrossRef]
- Chung, Y.; Lee, J.; Oh, S.; Park, D.; Chang, H.H.; Park, D. Automatic detection of cow’s oestrus in audio surveillance system. Asian Australas. J. Anim. Sci. 2013, 26, 1030–1037. [Google Scholar] [CrossRef]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef]
- Sainburg, T.; Thielk, M.; Gentner, T.Q. Finding, visualizing, and quantifying latent structure across diverse animal vocal repertoires. PLoS Comput. Biol. 2020, 16, e1008228. [Google Scholar] [CrossRef]
- Sasmaz, E.; Tek, F.B. Animal Sound Classification Using A Convolutional Neural Network. In Proceedings of the 3rd International Conference on Computer Science and Engineering (UBMK), Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; pp. 625–629. [Google Scholar]
- Chen, H.-M.; Huang, C.-J.; Chen, Y.-J.; Chen, C.-Y.; Chien, S.-Y. An intelligent nocturnal animal vocalization recognition system. Int. J. Comput. Commun. Eng. 2015, 4, 39–45. [Google Scholar] [CrossRef]
- Sauvé, C.C.; Beauplet, G.; Hammill, M.O.; Charrier, I. Mother–pup vocal recognition in harbour seals: Influence of maternal behaviour, pup voice and habitat sound properties. Anim. Behav. 2015, 105, 109–120. [Google Scholar] [CrossRef]
- Oikarinen, T.; Srinivasan, K.; Meisner, O.; Hyman, J.B.; Parmar, S.; Fanucci-Kiss, A.; DeSimone, R.; Landman, R.; Feng, G. Deep convolutional network for animal sound classification and source attribution using dual audio recordings. J. Acoust. Soc. Am. 2019, 145, 654–662. [Google Scholar] [CrossRef] [PubMed]
- Khamparia, A.; Gupta, D.; Nguyen, G.N.; Khanna, A.; Pandey, B.; Tiwari, P. Sound classification using convolutional neural network and tensor deep stacking network. IEEE Access 2019, 7, 7717–7727. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Paci, M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef]
- Xie, J.; Zhu, M. Handcrafted features and late fusion with deep learning for bird sound classification. Ecol. Inform. 2019, 52, 74–81. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, X.; Yao, L.; Xue, W.; Wei, B. A multi-view CNN-based acoustic classification system for automatic animal species identification. Ad Hoc Netw. 2020, 102, 102115. [Google Scholar] [CrossRef]
- Bishop, J.C.; Falzon, G.; Trotter, M.; Kwan, P.; Meek, P.D. Livestock vocalisation classification in farm soundscapes. Comput. Electron. Agric. 2019, 162, 531–542. [Google Scholar] [CrossRef]
- Mead-Hunter, R.; A Selvey, L.; Rumchev, K.B.; Netto, K.; Mullins, B.J. Noise exposure on mixed grain and livestock farms in Western Australia. Ann. Work. Expo. Heal. 2018, 63, 305–315. [Google Scholar] [CrossRef]
- Green, A.C.; Clark, C.E.; Lomax, S.; Favaro, L.; Reby, D. Context-related variation in the peripartum vocalisations and phonatory behaviours of Holstein-Friesian dairy cows. Appl. Anim. Behav. Sci. 2020, 231, 105089. [Google Scholar] [CrossRef]
- Chedad, A.; Moshou, D.; Aerts, J.M.; Van Hirtum, A.; Ramon, H.; Berckmans, D. AP—animal production technology: Recognition system for pig cough based on probabilistic neural networks. J. Agric. Eng. Res. 2001, 79, 449–457. [Google Scholar] [CrossRef]
- Magron, P.; Badeau, R.; David, B. Model-based STFT phase recovery for audio source separation. IEEE ACM Trans. Audio Speech Lang. Process. 2018, 26, 1095–1105. [Google Scholar] [CrossRef]
- Guo, M.; Kuenzle, B. Obtaining Narrow Transition Region in STFT Domain Processing Using Subband Filters. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 970–974. [Google Scholar]
- Allen, J. Short term spectral analysis, synthesis, and modification by discrete Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1977, 25, 235–238. [Google Scholar] [CrossRef]
- Sejdić, E.; Djurović, I.; Jiang, J. Time–frequency feature representation using energy concentration: An overview of recent advances. Digit. Signal. Process. 2009, 19, 153–183. [Google Scholar] [CrossRef]
- Heffner, H.E. Auditory awareness. Appl. Anim. Behav. Sci. 1998, 57, 259–268. [Google Scholar] [CrossRef]
- Xu, M.; Duan, L.-Y.; Cai, J.; Chia, L.-T.; Xu, C.; Tian, Q. HMM-Based Audio Keyword Generation. In Mining Data for Financial Applications; Springer: Berlin/Heidelberg, Germany, 2004; pp. 566–574. [Google Scholar]
- Soto-Murillo, M.A.; Villagrana Bañuelos, K.E.; Rodriguez-Ruiz, J.G.; Salinas-González, J.D.; Galván-Tejada, C.E.; Gamboa-Rosales, H.; Galván-Tejada, J.I. Classification of Heart Health by LPC and MFCC Coefficients and Statistical Features. In VIII Latin American Conference on Biomedical Engineering and XLII National Conference on Biomedical Engineering; Díaz, G.C.A., González, C.C., Leber, L.E., Vélez, H.A., Puente, N.P., Flores, D.-L., Andrade, A.O., Galván, H.A., Martínez, F., García, R., Eds.; Springer: Cham, Switzerland, 2020; pp. 104–112. [Google Scholar]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef] [PubMed]
- Kemal, A.; Kiliçarslan, S. Performance Analysis of Optimization Algorithms on Stacked Autoencoder. In Proceedings of the 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 11–13 October 2019; pp. 1–4. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Yazan, E.; Talu, M.F. Comparison of the Stochastic Gradient Descent Based Optimization Techniques. In Proceedings of the International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 1–5. [Google Scholar]
- Demir, F.; Abdullah, D.A.; Sengur, A. A new deep CNN model for environmental sound classification. IEEE Access 2020, 8, 66529–66537. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, L.; Lu, Z.; Xu, K. Large-Scale Whale Call Classification Using Deep Convolutional Neural Network Architectures. In Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Qingdao, China, 14–16 September 2018; pp. 1–5. [Google Scholar]
- Sprengel, E.; Jaggi, M.; Kilcher, Y.; Hofmann, T. Audio Based Bird Species Identification Using Deep Learning Techniques; ETH Zürich: Zürich, Switzerland, 2016. [Google Scholar]
- Nanni, L.; Costa, Y.M.G.; Aguiar, R.L.; Mangolin, R.B.; Brahnam, S.; Silla, C.N. Ensemble of convolutional neural networks to improve animal audio classification. EURASIP J. Audio Speech Music Process. 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Lucio, D.R.; Maldonado, Y.; da Costa, G. Bird Species Classification Using Spectrograms. In Proceedings of the 2015 Latin American Computing Conference (CLEI), Arequipa, Peru, 19–23 October 2015; pp. 1–11. [Google Scholar]
- Zhao, Z.; Zhang, S.-H.; Xu, Z.-Y.; Bellisario, K.; Dai, N.-H.; Omrani, H.; Pijanowski, B.C. Automated bird acoustic event detection and robust species classification. Ecol. Inform. 2017, 39, 99–108. [Google Scholar] [CrossRef]
- Huang, J.; Wang, W.; Zhang, T. Method for detecting avian influenza disease of chickens based on sound analysis. Biosyst. Eng. 2019, 180, 16–24. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, T.; Cuan, K.; Fang, C. An intelligent method for detecting poultry eating behaviour based on vocalization signals. Comput. Electron. Agric. 2021, 180, 105884. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Classification Results | Actual Results | |
|---|---|---|
| True | False | |
| True | True positive (TP) | False positive (FP) |
| False | False negative (FN) | True negative (TN) |
| Index | Value | Sample Quantity |
|---|---|---|
| 0 | Estrus call | 207 |
| 1 | Cattle food anticipating call | 178 |
| 2 | Cough sound | 56 |
| 3 | Normal call | 456 |
| Without Noise Filtering | With Noise Filtering | |
|---|---|---|
| True positive | 140 | 141 |
| False positive | 12 | 11 |
| True negative | 189 | 199 |
| False negative | 19 | 10 |
| True recognition rate (%) | 92.10 | 92.76 |
| False recognition rate (%) | 90.86 | 95.21 |
| Accuracy, (%) | 91.38 | 94.18 |
| Animals or Dataset | Classification Target | Approach | Descriptor | Accuracy (%) |
|---|---|---|---|---|
| BIRD [49] | Forty-six species | Handcrafted features with SVM | BSIF | 88.8 |
| WHALE [48] | Whale identification | Deep learning | CNN | 97.8 |
| BIRDZ [50] | Eleven bird species | Vgg-19 | 96.6 | |
| Cow [19] | Oestrus detection | Ensembles of deep learning | Fus_Spec + Fus_Scatter + CNN | 98.7 |
| Sheep, cattle, dogs [30] | Classification between three animals’ vocal | MFCC with SVM | Correlation-based Feature Selection | Over 94 accuracy |
| Chicken [51] | Avian-influenza detection | MFCC with SVM | Discrete wavelet transform | At least 95.78 (cattle) |
| Chicken [52] | Eating behavior | Deep learning | PV-net | 96.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, D.-H.; Kim, N.Y.; Moon, S.H.; Jhin, C.; Kim, H.-J.; Yang, J.-S.; Kim, H.S.; Lee, T.S.; Lee, J.Y.; Park, S.H. Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering. Animals 2021, 11, 357. https://doi.org/10.3390/ani11020357
Jung D-H, Kim NY, Moon SH, Jhin C, Kim H-J, Yang J-S, Kim HS, Lee TS, Lee JY, Park SH. Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering. Animals. 2021; 11(2):357. https://doi.org/10.3390/ani11020357
Chicago/Turabian StyleJung, Dae-Hyun, Na Yeon Kim, Sang Ho Moon, Changho Jhin, Hak-Jin Kim, Jung-Seok Yang, Hyoung Seok Kim, Taek Sung Lee, Ju Young Lee, and Soo Hyun Park. 2021. "Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering" Animals 11, no. 2: 357. https://doi.org/10.3390/ani11020357
APA StyleJung, D.-H., Kim, N. Y., Moon, S. H., Jhin, C., Kim, H.-J., Yang, J.-S., Kim, H. S., Lee, T. S., Lee, J. Y., & Park, S. H. (2021). Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering. Animals, 11(2), 357. https://doi.org/10.3390/ani11020357