
An Advanced Chicken Face Detection Network Based on GAN and MAE

 , , , ,
, , , ,
Abstract
:Simple Summary
Abstract
1. Introduction
- Using GAN and MAE models to augment the small volume of data in the dataset.
- We used multiple data enhancement methods to balance the dataset.
- We added feature map outcomes to three feature map results, changing the downsampling of the feature map outputs to fourfold, which provides more minor object features for subsequent feature fusion.
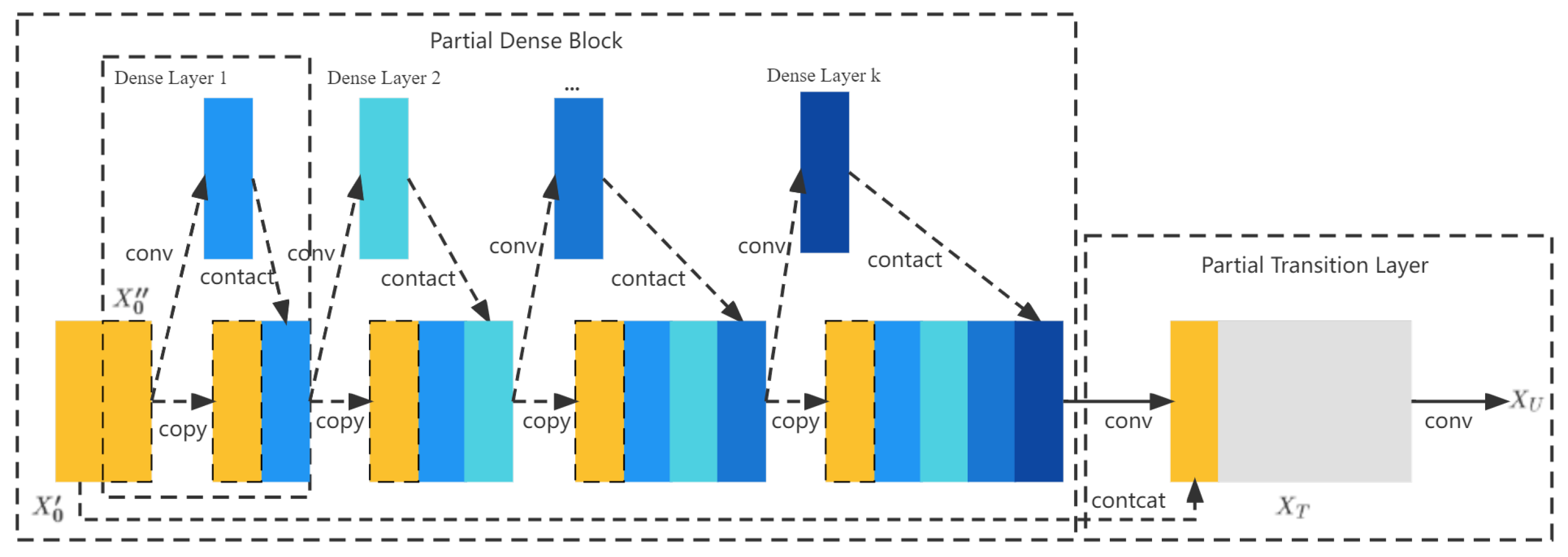
- We opted for the idea of dense connectivity, improving the feature fusion module to reuse features. The YOLO head classifier responsible for object detection can combine features from different levels of feature layers to obtain better object detection and classification results.
- We applied our model equipped with cameras and edge servers for a specific chicken coop.
- Using growth stage detection technology in livestock farms can improve the accuracy and efficiency of supervision, increasing productivity and profitability. At the same time, it reduces farming costs while following a humane and ethical approach to animal protection.
2. Related Work
- Classification.The classification task structures an image into a certain category of information, describing the image with a predefined category or instance identification code. This task is the most straightforward and primary image understanding task, and is the first one where deep learning models have broken out and achieved large-scale applications. Among all the excellent classification methods, ImageNet [16,17] is the most authoritative set of reviews. The annual ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) has spawned many excellent deep network structures [18,19], which provide the foundation for other tasks. In the application domain, face recognition [20,21], scenes, etc., can be classified as classification tasks.
- The classification task focuses on the overall image and describes the whole picture’s content. Detection [24,25,26], however, focuses on a particular target and requires both class and location information for this target [27]. In contrast to classification, object detection provides an understanding of the image’s foreground and background. We need to divide the object of interest from the background and determine the object’s description (category and location). Object detection is a fundamental task in computer vision. Image segmentation, object tracking, and keypoint detection rely on object detection.
- Image segmentation includes semantic segmentation, instance segmentation, and panoptic segmentation [30,31]. Semantic segmentation [32,33] segments all objects in an image (including the background), but cannot distinguish between different individuals for the same category. Instance segmentation [34] is an extension of the detection task, which needs to describe the object’s contour (more detailed than the detection frame). Panoptic segmentation [35] is based on instance segmentation and can segment the background objects. Segmentation is a pixel-level description of an image that gives significance to each pixel class (instance) and is suitable for scenarios that require a high level of understanding, such as the segmentation of roads and non-roads for unmanned vehicles.
3. Materials and Methods
3.1. Dataset Analysis
3.2. Data Augmentation
3.2.1. CutMix
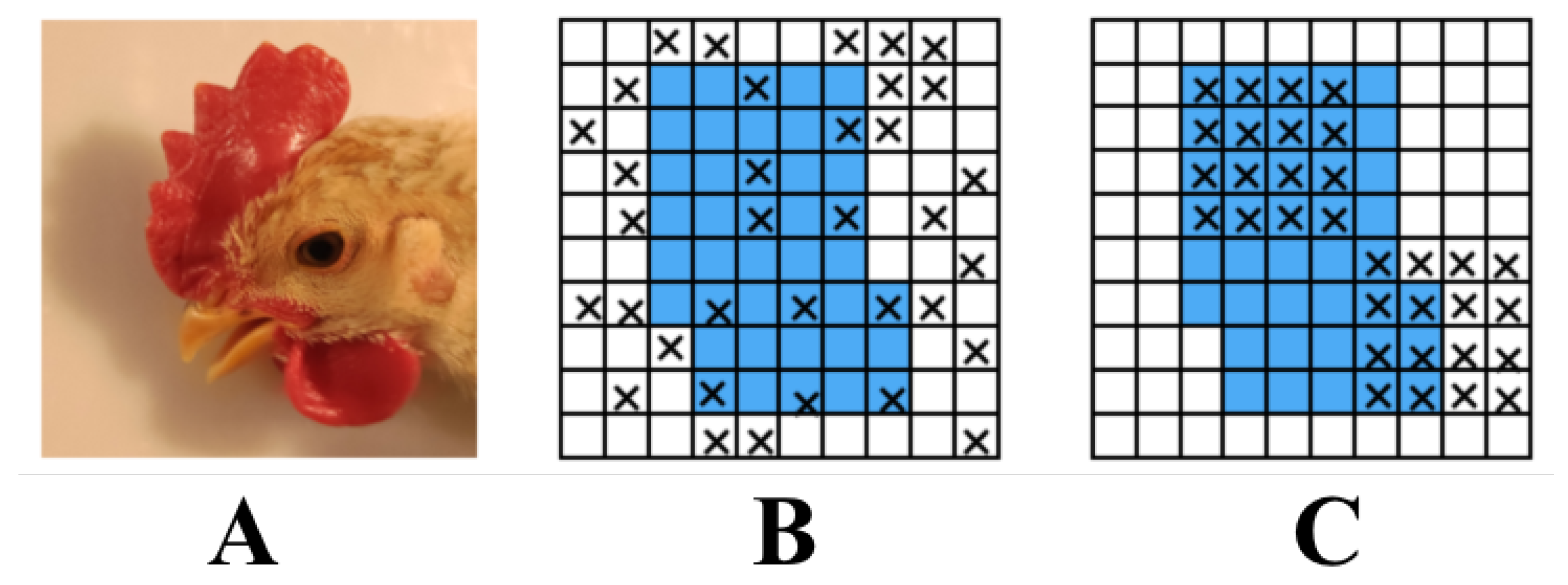
3.2.2. DropBlock Regularization
3.2.3. Modified Label Smoothing
- Inability to guarantee the model’s generalizability, which tends to cause overfitting.
- The probabilities of one and zero encourage the widest possible gap between the category to which they belong and the other categories, which is difficult to accommodate as known by the gradient being bounded. It can cause the model to place too much confidence in the predicted categories.
3.3. Augmentation Networks
3.3.1. Generative Adversarial Networks
- Determine the target identification object.
- Make a dataset M of target objects (the dataset M is relatively small).
- Collect a large amount of public data N of similar objects in other environments through methods such as Baidu platform.
- Model training. Train N to a data distribution of similar style to M by GANs model.
- Add to M.
3.3.2. Masked Autoencoders
3.4. Core Detection Network
3.4.1. CSPDarknet53
- Larger network input resolution—for detecting small objects.
- Deeper network layers—able to cover a larger receptive field area.
- More parameters—better detection of different-sized objects within the same image.
3.4.2. Spatial Pyramid Pooling Structure
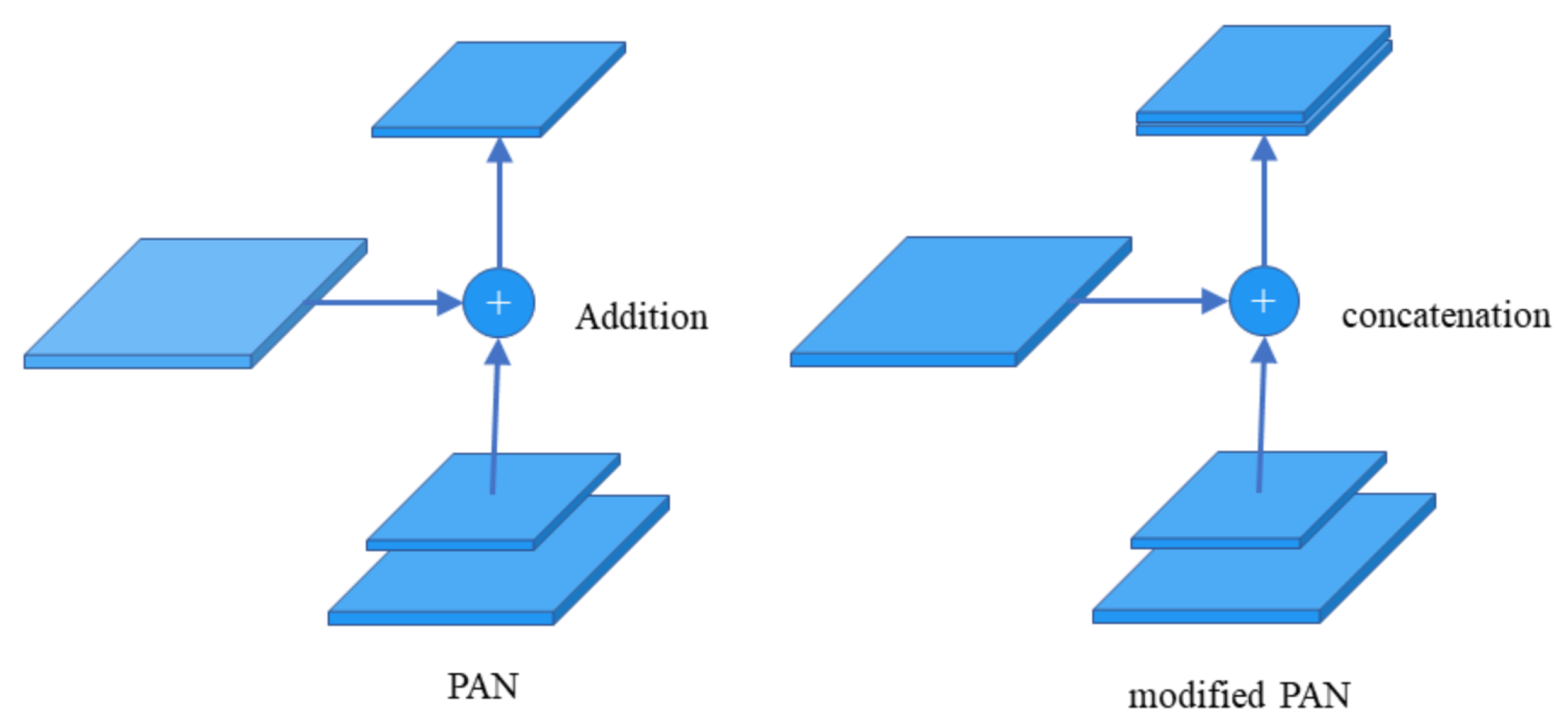
3.4.3. Path Aggregation Network Structure
3.5. Experiments
3.5.1. Experiment Settings
3.5.2. Model Evaluation Metrics
4. Results and Discussion
4.1. Validation Results
4.2. Detection Outcomes
Application for Downstream Tasks
4.3. Discussion
4.3.1. Ablation Experiments for Various Data Augmentation Methods
4.3.2. Ablation Experiments for Various Data Augmentation Methods
4.3.3. Future Work
5. Conclusions
- We augmented the limited-scale dataset by employing the GAN and MAE models. Compared with the baseline method without data augmentation, our GAN-MAE augmentation method increased the F1 and mAP from 0.87 and 0.75 to 0.91 and 0.84, respectively.
- We solved the imbalance between different classes of the dataset using multiple data enhancement methods.
- We added feature map outputs to three feature map outputs of this algorithm, thus changing the eightfold downsampling of the feature map outputs to fourfold downsampling, which provides more small object features for subsequent feature fusion.
- The feature fusion module was improved based on the idea of dense connectivity to achieve feature reuse. The YOLO head classifier responsible for object detection can combine features from different levels of feature layers to obtain better object detection and classification results.
- Our model achieved the most exceptional performance in the contrast experiments, with 0.91 F1, 0.84 mAP, and 37 FPS, which are well over those of the two-stage models and EfficientDet.
- We deployed our camera and edge server for a specific chicken coop, and applied our model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mullins, I.L.; Truman, C.M.; Campler, M.R.; Bewley, J.M.; Costa, J.H. Validation of a commercial automated body condition scoring system on a commercial dairy farm. Animals 2019, 9, 287. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chun, J.L.; Bang, H.T.; Ji, S.Y.; Jeong, J.Y.; Kim, M.; Kim, B.; Lee, S.D.; Lee, Y.K.; Reddy, K.E.; Kim, K.H. A simple method to evaluate body condition score to maintain the optimal body weight in dogs. J. Anim. Sci. Technol. 2019, 61, 366. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Huang, Y.; Wang, Y.; Zhang, S.; Qu, H.; Ma, J.; Wang, L.; Li, L. A High-Performance Day-Age Classification and Detection Model for Chick Based on Attention Encoder and Convolutional Neural Network. Animals 2022, 12, 2425. [Google Scholar] [CrossRef] [PubMed]
- Mastrangelo, S.; Cendron, F.; Sottile, G.; Niero, G.; Portolano, B.; Biscarini, F.; Cassandro, M. Genome-wide analyses identifies known and new markers responsible of chicken plumage color. Animals 2020, 10, 493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, L.; Tao, P.; Martin, R.R. Livestock detection in aerial images using a fully convolutional network. Comput. Vis. Media 2019, 5, 221–228. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Hu, Z.; Liu, C.; Liu, H.; Kuang, Y.; Gao, Y. Cow face detection and recognition based on automatic feature extraction algorithm. In Proceedings of the ACM Turing Celebration Conference—China, Chengdu, China, 17–19 May 2019; pp. 1–5. [Google Scholar]
- Akçay, H.G.; Kabasakal, B.; Aksu, D.; Demir, N.; Öz, M.; Erdoğan, A. Automated Bird Counting with Deep Learning for Regional Bird Distribution Mapping. Animals 2020, 10, 1207. [Google Scholar] [CrossRef]
- Liu, H.W.; Chen, C.H.; Tsai, Y.C.; Hsieh, K.W.; Lin, H.T. Identifying Images of Dead Chickens with a Chicken Removal System Integrated with a Deep Learning Algorithm. Sensors 2021, 21, 3579. [Google Scholar] [CrossRef]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis, and Machine Vision; Cengage Learning: Boston, MA, USA, 2014. [Google Scholar]
- Davies, E.R. Machine Vision: Theory, Algorithms, Practicalities; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Davies, E.R. Computer and Machine Vision: Theory, Algorithms, Practicalities; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: Cham, Switzerland, 2012; Volume 454. [Google Scholar]
- Viitaniemi, V.; Laaksonen, J. Techniques for image classification, object detection and object segmentation. In Visual Information Systems: Web-Based Visual Information Search and Management—10th International Conference, VISUAL 2008, Salerno, Italy, 11–12 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 231–234. [Google Scholar]
- Yang, R.; Yu, Y. Artificial convolutional neural network in object detection and semantic segmentation for medical imaging analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Che, E.; Jung, J.; Olsen, M.J. Object recognition, segmentation, and classification of mobile laser scanning point clouds: A state of the art review. Sensors 2019, 19, 810. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- You, Y.; Zhang, Z.; Hsieh, C.J.; Demmel, J.; Keutzer, K. Imagenet training in minutes. In Proceedings of the 47th International Conference on Parallel Processing, Eugene, OR, USA, 13–16 August 2018; pp. 1–10. [Google Scholar]
- Naseem, I.; Togneri, R.; Bennamoun, M. Linear regression for face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2106–2112. [Google Scholar] [CrossRef]
- Gao, S.; Tsang, I.W.H.; Chia, L.T. Kernel sparse representation for image classification and face recognition. In Computer Vision—ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- Hoeser, T.; Kuenzer, C. Object detection and image segmentation with deep learning on earth observation data: A review-Part I: Evolution and recent trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2020; pp. 10781–10790. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020: 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Pflugfelder, R.; Kamarainen, J.K.; Cehovin Zajc, L.; Drbohlav, O.; Lukezic, A.; Berg, A.; et al. The seventh visual object tracking vot2019 challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- De Geus, D.; Meletis, P.; Dubbelman, G. Panoptic segmentation with a joint semantic and instance segmentation network. arXiv 2018, arXiv:1809.02110. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12475–12485. [Google Scholar]
- Zhang, Y.; Liu, X.; Wa, S.; Liu, Y.; Kang, J.; Lv, C. GenU-Net++: An Automatic Intracranial Brain Tumors Segmentation Algorithm on 3D Image Series with High Performance. Symmetry 2021, 13, 2395. [Google Scholar] [CrossRef]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Lin, J.; Fan, D.; Fu, J.; Lv, C. Symmetry GAN Detection Network: An Automatic One-Stage High-Accuracy Detection Network for Various Types of Lesions on CT Images. Symmetry 2022, 14, 234. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9157–9166. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. Upsnet: A unified panoptic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8818–8826. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Sudowe, P.; Leibe, B. Efficient use of geometric constraints for sliding-window object detection in video. In Computer Vision Systems: 8th International Conference, ICVS 2011, Sophia Antipolis, France, 20–22 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 11–20. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–799. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Zhang, Y.; Wa, S.; Sun, P.; Wang, Y. Pear Defect Detection Method Based on ResNet and DCGAN. Information 2021, 12, 397. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Liu, Y. Using Generative Module and Pruning Inference for the Fast and Accurate Detection of Apple Flower in Natural Environments. Information 2021, 12, 495. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Wa, S.; Chen, S.; Ma, Q. GANsformer: A Detection Network for Aerial Images with High Performance Combining Convolutional Network and Transformer. Remote Sens. 2022, 14, 923. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Zhang, L.; Lv, C. Automatic Plant Disease Detection Based on Tranvolution Detection Network with GAN Modules Using Leaf Images. Front. Plant Sci. 2022, 13, 875693. [Google Scholar] [CrossRef]
- Germain, M.; Gregor, K.; Murray, I.; Larochelle, H. Made: Masked autoencoder for distribution estimation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 881–889. [Google Scholar]
- Lee, M.; Mun, H.J. Comparison Analysis and Case Study for Deep Learning-based Object Detection Algorithm. Int. J. Adv. Sci. Converg. 2020, 2, 7–16. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Growth Stages | Living Situations |
|---|---|
| Chicks | Newborn–60 days of age. |
| Breeding stage | 61–150 days of age. |
| breeding chickens | |
| Adult stage | 151 days of age and above. |
| Reserved chickens | Hens that have not begun laying eggs; |
| breeding roosters that have not yet been mated. |
| Day-Old Age | Amount of Data Samples |
|---|---|
| 1–30 | 6491 |
| 31–60 | 1321 |
| 61–90 | 1467 |
| 91–120 | 4287 |
| 121–150 | 7109 |
| 150+ | 6988 |
| Label/Prediction | Positive | Negative |
|---|---|---|
| Positive | TP | FP |
| Negative | FN | TN |
| Method | F1 | mAP | FPS |
|---|---|---|---|
| Faster RCNN | 0.71 | 0.65 | 33 |
| Mask RCNN | 0.75 | 0.71 | 29 |
| EfficientDet | 0.86 | 0.71 | 35 |
| YOLOv3 | 0.85 | 0.73 | 51 |
| YOLOv5 | 0.87 | 0.72 | 58 |
| SSD | 0.82 | 0.68 | 45 |
| ours | 0.91 | 0.84 | 37 |
| Method | F1 | mAP |
|---|---|---|
| No augmentation (baseline) | 0.87 | 0.75 |
| GAN | 0.88 | 0.75 |
| DCGAN | 0.89 | 0.78 |
| MAE | 0.91 | 0.81 |
| DCGAN + MAE | 0.91 | 0.84 |
| Method | F1 | mAP |
|---|---|---|
| CutMix | 0.90 | 0.79 |
| DropBlock | 0.85 | 0.75 |
| Modified label smoothing | 0.87 | 0.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.; Lu, X.; Huang, Y.; Yang, X.; Xu, Z.; Mo, G.; Ren, Y.; Li, L. An Advanced Chicken Face Detection Network Based on GAN and MAE. Animals 2022, 12, 3055. https://doi.org/10.3390/ani12213055
Ma X, Lu X, Huang Y, Yang X, Xu Z, Mo G, Ren Y, Li L. An Advanced Chicken Face Detection Network Based on GAN and MAE. Animals. 2022; 12(21):3055. https://doi.org/10.3390/ani12213055
Chicago/Turabian StyleMa, Xiaoxiao, Xinai Lu, Yihong Huang, Xinyi Yang, Ziyin Xu, Guozhao Mo, Yufei Ren, and Lin Li. 2022. "An Advanced Chicken Face Detection Network Based on GAN and MAE" Animals 12, no. 21: 3055. https://doi.org/10.3390/ani12213055
APA StyleMa, X., Lu, X., Huang, Y., Yang, X., Xu, Z., Mo, G., Ren, Y., & Li, L. (2022). An Advanced Chicken Face Detection Network Based on GAN and MAE. Animals, 12(21), 3055. https://doi.org/10.3390/ani12213055