1. Introduction
The current geological epoch in which humankind is rapidly changing the global landscape is coined the Anthropocene. With the increasing demand for resources and living space, humans have a negative impact on Earth’s climate and biosphere [
1,
2,
3]. Wind energy plays an essential role in improving climate health. On the other hand, wind turbines cause measurable harm to ecosystems of flying animals like birds and bats. Bats roosting and foraging close to wind energy plants are likely to collide with rotor blades or experience barotrauma, leading to high fatality rates [
4,
5,
6,
7,
8,
9,
10,
11,
12]. In fact, many bats are highly endangered species and susceptible to anthropogenic changes of their ecosystems [
13,
14]. Recent evaluations have revealed that many species provide significant monetary benefits to the agricultural industry [
14]. Moreover, because they inhabit a multitude of different areas around the world and given their innate sensitivity to environmental changes, bats are considered essential bioindicators [
15,
16].
Acoustic surveillance of bat activity is of great importance for mitigation and curtailment systems of wind turbines [
17,
18] and for general population monitoring apart from wind energy applications [
19]. Non-invasive acoustic monitoring of bat activity has a long history of improvements regarding hardware, data management and analysis methodology [
19]. Continuous acoustic monitoring of bat activity generates large volumes of data. The manual labeling process of such data, mainly done by human experts, is a time-consuming and costly endeavor. To enhance the quality and consistency of bat conservation, there is a need for fast and robust automated detection systems similar to Sonobat [
20] and Kaleidoscope [
21].
Traditional sound detection methods apply different thresholds for frequency and amplitude or quantify the areas of smooth frequency changes. Many such methods struggle to reliably differentiate between all species or genera [
22]. Conventional species identification, on the other hand, relies upon hand-tailored features, like various frequency levels, call durations and interpulse intervals [
22]. Common statistical models for species classification include random forests [
23,
24,
25,
26,
27], k-nearest neighbor [
27], support-vector machines [
23,
27,
28] and discriminant function analysis [
23,
27,
29].
After the first significant triumph of convolutional neural networks (CNNs) as image classifiers in 2012 [
30], such deep learning models became the state of the art in a multitude of disciplines and domains. A CNN can be used to detect bat sounds within audio recordings or even identify their species by learning spectrograms computed via a short-time Fourier transform (STFT) from such audio data. The great advantage of (deep) neural networks is their strong ability to find meaningful patterns inside the training data, making the need for feature engineering mostly irrelevant. The first deep-learning-based model to detect bat echolocation sounds from audio data was Bat Detective [
31], which was recently expanded into a joint model that performs bat sound detection and species identification [
32]. The first iteration consists of two versions of a CNN trained on single bat pulses. For the prediction step, it moves in a sliding-window fashion along the spectrogram in order to detect individual pulses with a window size of 23 ms [
31]. The second iteration is a CNN performing complete end-to-end bounding-box detection for spectrograms of less than two seconds [
32]. This approach allows a model to learn temporal dependencies between consecutive bat pulses. Additional works on bat species identification with CNNs can be found in [
33,
34,
35,
36,
37]. The works of Chen et al. [
33], Kobayashi et al. [
34] and Schwab et al. [
35] are involved the use of small windows of 20 ms, 27 ms or 10 ms in size to detect individual bat pulses, similar to the work of Aodha et al. [
31]. In contrast, Tabak et al. [
36] trained their CNN with noiseless plots of five to fifteen consecutive pulses. Finally, Zualkernan et al. [
37] used STFT-based images of 3 s audio segments to train their CNN model.
In this work, we propose a CNN-based approach that expands the developments of Paumen et al. [
38] regarding the behavioral analysis of used models and datasets. We also use the same CNN structure to classify Mel-frequency cepstral coefficients (MFCC) of 1 s audio segments containing noise, either with or without bat sounds. With the additional help of an unsupervised geometric analysis via a convolutional autoencoder followed by UMAP clustering, we provide useful insights for model and dataset choice before training the CNN classifier. This auxiliary process is similar to that proposed by Kohlsdorf et al. [
39], who trained a convolutional recurrent autoencoder followed by k-means clustering and T-SNE 2D projection. A related approach to gain additional knowledge about the data by k-means clustering was proposed by Yoh et al. [
24]. Our approach involves the use of three separately trained classifiers in order to perform bat sound detection, genus identification and species identification. Combined with human expert domain knowledge, this also allows for more authentic interpretation of the classifiers behavior. Compared to Paumen et al. [
38], our data is extended by three additional collections of data, which allows for the comparative analysis of two collections with different locations in the same year and two collections from different years but at the same location. All four collections were gathered from the NatForWINSENT wind test field in Germany between 2019 and 2020. Most of the previously named works using CNNs and other machine learning models examined datasets with only individual bat species, whereas our four data collections contain individual species, genera, groups of similar echolocation behavior and various types of stationary and non-stationary noise recordings. This offers new insights in the handling of sophisticated bioacoustic data. We claim our data processing pipeline to be novel in the context of bioacoustic data, since we could not find any previous study that combines unsupervised learning with supervised learning techniques in a seamless pipeline. Additionally, no previous study on bat echolocation sound analysis has elaborated on the presence of background noise recordings in such detail as this work. Furthermore, with the full code being open-source, an educational template is provided to the community of biologists to foster collaboration. In the field of automated bat sound analysis, open-source code is rare in comparison to commercial tools like Sonobat [
20], Kaleidoscope [
21], BatCallID [
40], BatSound [
41] and Anabat Insight [
42].
4. Discussion
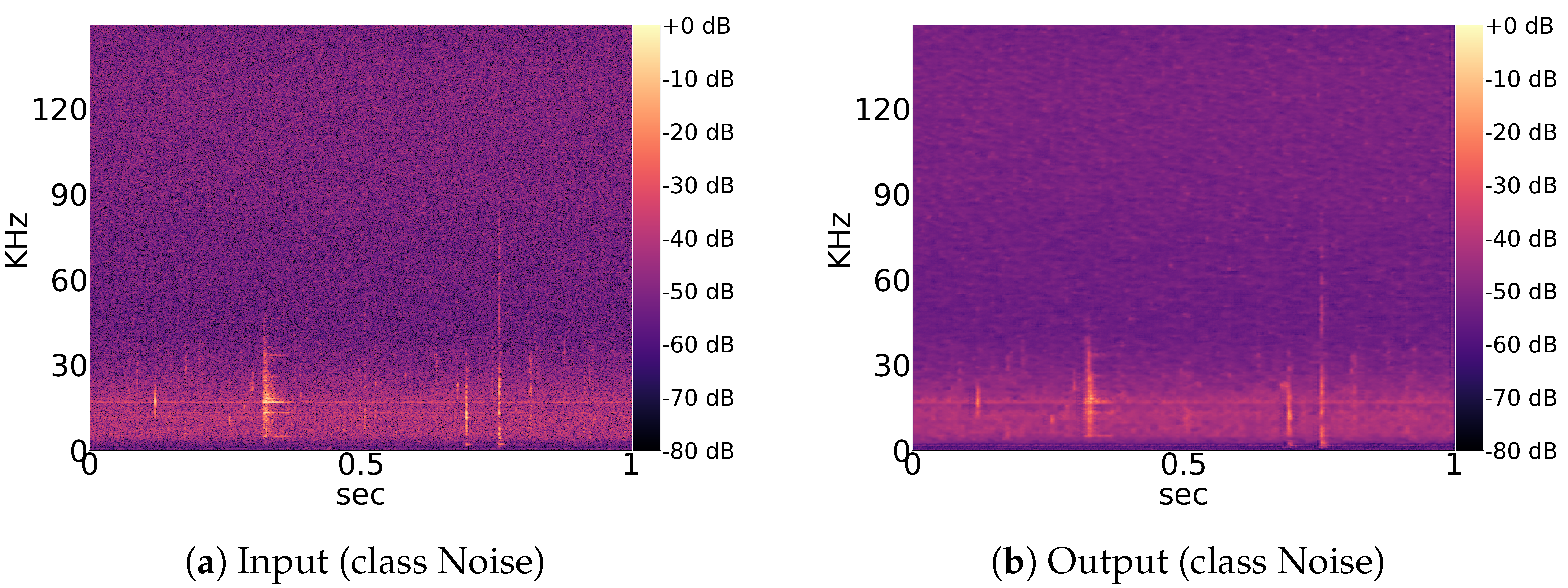
The idea of using an autoencoder to improve the convergence speed of UMAP comes from its ability to compress a single image by adapting to the whole dataset (
Figure 5). Other standard (lossy) image compression algorithms are probably more efficient but less dynamic and usually do not consider the whole dataset in order to compress individual images.
A quantitative comparison of our model was only possible with of Schwab et al. [
35] because comparable methods like those of Chen et al. [
33], Kobayashi et al. [
34] and Tabak et al. [
36] have recorded different bat species due to their measurement locations. The distribution of bat species investigated in Schwab et al. [
35] has a strong intersection with our dataset. Therefore, we computed the accuracies for our two species (
P_pip and
P_nat), the genus (
Myotis) and the group (
Nyctaloid). To facilitate a comparison between our results for
Myotis and
Nyctaloid with the findings of Schwab et al. [
35], we calculated the average accuracies of their best model specifically for the species present in our
Myotis and
Nyctaloid class, as listed in
Table 1.
Table 11 demonstrates a slightly higher performance compared to that obtained by Schwab et al. [
35], but this comparison must be considered under the following circumstances. First, both works investigated a different dataset, and the quality and difficulty of the data have a strong impact on the final model performance. With our model learning the full frequency range of the raw audio data, we argue that our model performs well under real-world conditions. Second, Schwab et al. [
35] trained a single model with 18 species. Although our work trained a different model for species and genera, we argue that our model is, by design, still able to handle a similar number of classes at once.
Our classifier was designed in favor of future edge-AI applications. The simplicity of the main classification network (
Figure 6) still provides very high predictive capabilities as long as the natural intrinsic difference in sounds between the defined classes is provided under the additional premise of sufficient data volume. We show that the low complexity of the classification network is sufficient to allow for highly discriminative performance for all levels of classification from bat/noise classification to genus and even species classification (
Section 3.2 and
Section 3.3). Our work, unlike other studies mentioned in
Section 1, demonstrates that overly complex neural networks are not always necessary for bat echolocation sound analysis. For example, Schwab et al. [
35] used a modified ResNet-50, a network with 49 convolutional layers, as their best model. A network with that many layers is overly large, takes too long to train and fine tune and usually does not fit on low-power devices like microcontrollers. The variation in geometric patterns of bioacoustic data is much less compared to generic datasets such as ImageNet or MS-Coco. A large number of channels in convolutional layers becomes unnecessary and memory-expensive, since the model focuses on the relevant features of the input data. Many channels are then likely to be filled with redundant or even insignificant features. When implemented in a smaller framework, like TinyML or TensorFlow Lite, our model is fit for deployment on low-power devices such as microcontrollers and AI chips similar to that reported by Zualkernan et al. [
49].
Paumen et al. [
38] indicated that a classifier trained on a single recording height is able to safely detect bat sounds recorded at the other heights from the same year and location. On the other hand, a significant amount of noise samples from other heights is misclassified as bat sounds [
38]. The results reported in
Section 3.2.1 reveal similar behavior in our tests on noise recordings from data collections unknown to the optimized classifier for bat/noise classification. A more distinctive comparison of evaluation metrics with respect to single bat classes in the bat/noise classification in
Section 3.2.1 may reveal new reasons for the observed behavior, but this is beyond the scope of this work and requires more examples for rare species to be authentic.
Works evaluated in
Section 1 usually focused on optimizing a single model that learns a joined dataset from all sources or sites. Their goal is to maximize their discriminative model performance, as in
Section 3.3. Instead, we invested additional effort to further understand the impacts of conditional factors on the data and therefore the model robustness and generalization ability, as shown in
Section 3.2. The methods reported by Chen et al. [
33], Kobayashi et al. [
34], Schwab et al. [
35] and Aodha et al. [
31] only use small windows of a maximum pf 27 ms as input data for the neural network. Such short audio segments contain one pulse, at most. Instead, our model implicitly comprehends the common interpulse interval of a species in a 1 s MFCC without the need for manual extraction of this feature. The interpulse interval is a primary indicator in manual echolocation sound identification. Therefore, our model can provide a practical advantage over previously mentioned methods.
There is always the question of how to compare human cognitive performance with the performance of computational statistical models like neural networks. First, when a model is trained by human-labeled data, the labels are treated as correct by the model, i.e., the supervised model tries to imitate the labeling behavior of the human. Second, a neural network has a more rigid understanding of a class compared to a human brain. Human experts, as in our case, are trained to comprehend such audio data with multiple sources of knowledge or experience, which is usually a composition of various sensations.
In order to improve the robustness of the model and its ability to generalize well on the data, datasets may be improved in several ways. One approach is to extend the audio database of bat sound recordings. This can be managed by unifying multiple sources from different locations and audio recording devices shared between research organizations, as reported by Görföl et al. [
50]. Another way of improving the audio database is to consider habitat influences and corresponding bat sounds as reported by Findlay et al. [
51]. Inspired by the way humans perceive the world via multiple senses, it may be advisable to combine acoustic monitoring with video tracking of bat activity as reported by Thomas et al. [
52]. Examination of carcasses in areas where populations are tracked can help to offer probabilities of occurrence of different species for detection models as reported by Chipps et al. [
53].
5. Conclusions
This work introduces a novel approach for investigating and identifying real-world bat echolocation sound recordings. This study demonstrates that more authentic interpretations of auditory data can be made with the help of unsupervised learning methods like autoencoders and UMAP clustering. The following specific insights contribute to the research areas of bat echolocation sound analysis, acoustic monitoring and bat conservation.
Noise recordings that exceed the threshold parameters of devices like the BATmode S+ system can be of various forms and origin. They are difficult for the model to generalize on as long as their origin and full extent remain unknown, as revealed by UMAP clustering and a preceding convolutional autoencoder used for image compression. Neither the autoencoder or the UMAP algorithm are designed to comprehend low-level features from data samples, which explains their ineffectiveness on bat species of the same genus.
In the case of bat/noise classification, if a pretrained classifier is applied to unknown data from a different feature distribution, the detection of bats is much more reliable than the detection of noise. This is explained by the complexity of noise patterns and their unknown origins.
Bat genus classification and bat species classification experiments show that the performance of the classifiers in detecting genera and species depends on the location of measurements. Its performance is even influenced by the time of recordings, which is likely explained by environmental changes over time. Our results also indicate that after a certain number of examples of echolocation sound segments from all locations and years, any of the classes can be fully comprehended by the proposed model.
Moreover, the obtained results constitute practical proof that short, standard CNNs are fully sufficient for classifying bat echolocation sounds at the genus and species levels, making them attractive for edge-AI applications on low-power devices.
Most bat sound identification software is only commercially available, which may unnecessarily decelerate the progress in the field of bioacoustics. By providing an open-source version of our code, we intend to simplify the deployment of bat identification projects by shortening the initial time and financial resources required to perform first classifications.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}