
Impact Evaluation of Score Classes and Annotation Regions in Deep Learning-Based Dairy Cow Body Condition Prediction



Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Data Preprocessing
2.3. Choice of Model Architecture
2.4. Evaluation Metrics
2.5. Model Screening
2.6. Model Training and Prediction
2.6.1. With 12 BCS Classes
2.6.2. With Three BCS Classes for Four Practical Target Intervals
3. Results
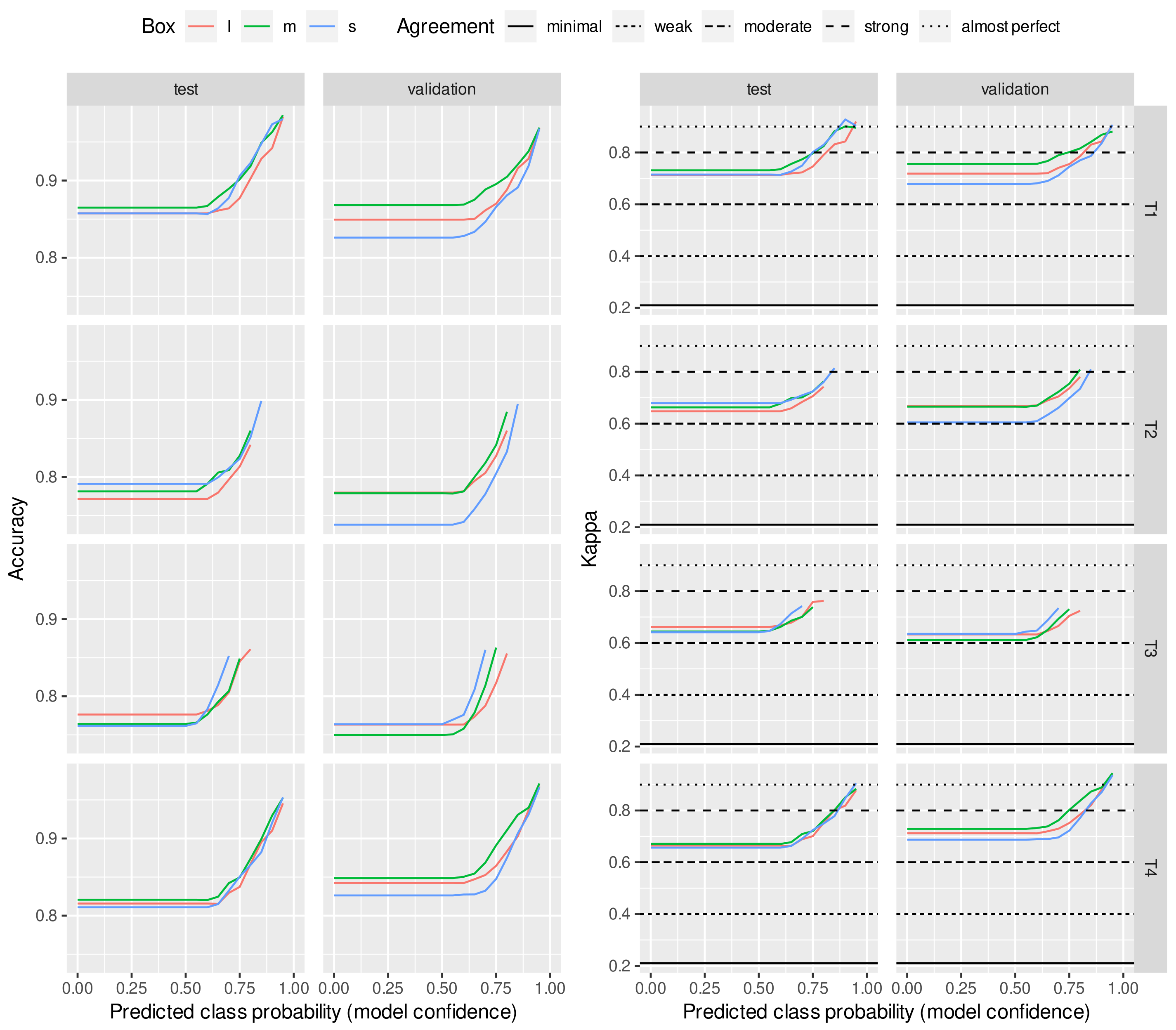
3.1. Prediction with 12 BCS Classes
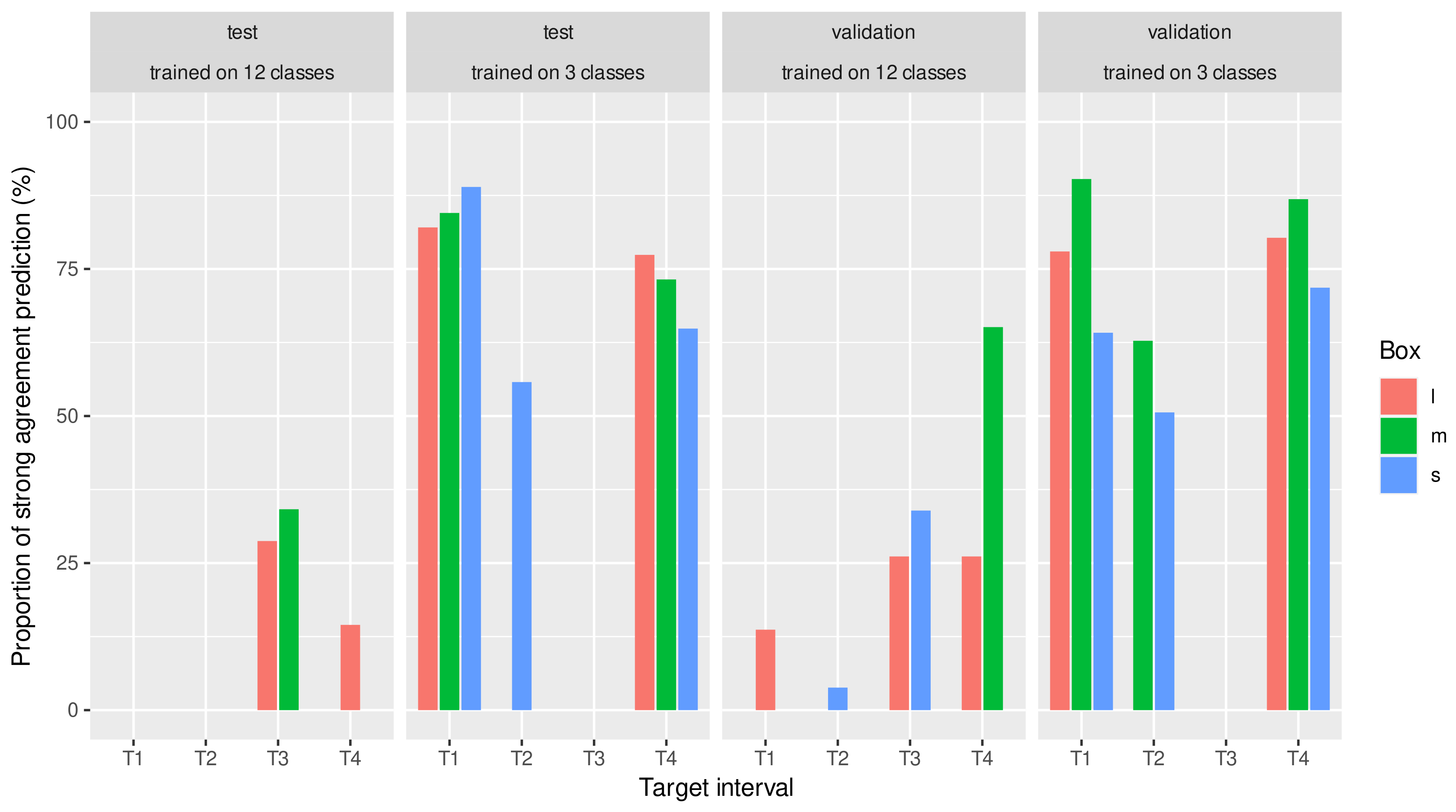
3.2. Prediction with Three BCS Classes
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Edmonson, A.; Lean, I.; Weaver, L.; Farver, T.; Webster, G. A body condition scoring chart for Holstein dairy cows. J. Dairy Sci. 1989, 72, 68–78. [Google Scholar] [CrossRef]
- Ferguson, J.D.; Galligan, D.T.; Thomsen, N. Principal descriptors of body condition score in Holstein cows. J. Dairy Sci. 1994, 77, 2695–2703. [Google Scholar] [CrossRef]
- Roche, J.; Dillon, P.; Stockdale, C.; Baumgard, L.; VanBaale, M. Relationships among international body condition scoring systems. J. Dairy Sci. 2004, 87, 3076–3079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bewley, J.; Schutz, M. An interdisciplinary review of body condition scoring for dairy cattle. Prof. Anim. Sci. 2008, 24, 507–529. [Google Scholar] [CrossRef] [Green Version]
- Morrow, D.A. Fat cow syndrome. J. Dairy Sci. 1976, 59, 1625–1629. [Google Scholar] [CrossRef]
- Roche, J.R.; Kay, J.K.; Friggens, N.C.; Loor, J.J.; Berry, D.P. Assessing and managing body condition score for the prevention of metabolic disease in dairy cows. Vet. Clin. Food Anim. Pract. 2013, 29, 323–336. [Google Scholar] [CrossRef]
- Silva, S.R.; Araujo, J.P.; Guedes, C.; Silva, F.; Almeida, M.; Cerqueira, J.L. Precision technologies to address dairy cattle welfare: Focus on lameness, mastitis and body condition. Animals 2021, 11, 2253. [Google Scholar] [CrossRef] [PubMed]
- Albornoz, R.I.; Giri, K.; Hannah, M.C.; Wales, W.J. An improved approach to automated measurement of body condition score in dairy cows using a three-dimensional camera system. Animals 2022, 12, 72. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; Li, F.; Sun, Y. Development and implementation of a training dataset to ensure clear boundary value of body condition score classification of dairy cows in automatic system. Livest. Sci. 2022, 259, 104901. [Google Scholar] [CrossRef]
- Truman, C.M.; Campler, M.R.; Costa, J.H. Body condition score change throughout lactation utilizing an automated BCS system: A descriptive study. Animals 2022, 12, 601. [Google Scholar] [CrossRef]
- Zhao, K.; Zhang, M.; Shen, W.; Liu, X.; Ji, J.; Dai, B.; Zhang, R. Automatic body condition scoring for dairy cows based on efficient net and convex hull features of point clouds. Comput. Electron. Agric. 2023, 205, 107588. [Google Scholar] [CrossRef]
- Kristensen, E.; Dueholm, L.; Vink, D.; Andersen, J.; Jakobsen, E.; Illum-Nielsen, S.; Petersen, F.; Enevoldsen, C. Within-and across-person uniformity of body condition scoring in Danish Holstein cattle. J. Dairy Sci. 2006, 89, 3721–3728. [Google Scholar] [CrossRef] [PubMed]
- Mullins, I.L.; Truman, C.M.; Campler, M.R.; Bewley, J.M.; Costa, J.H. Validation of a commercial automated body condition scoring system on a commercial dairy farm. Animals 2019, 9, 287. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, X.; Bokkers, E.; Van Mourik, S.; Koerkamp, P.G.; Van Der Tol, P. Automated body condition scoring of dairy cows using 3-dimensional feature extraction from multiple body regions. J. Dairy Sci. 2019, 102, 4294–4308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Visual Object Tagging Tool (VoTT). 2020. Available online: https://github.com/microsoft/VoTT (accessed on 28 December 2022).
- Tkachenko, M.; Malyuk, M.; Holmanyuk, A.; Liubimov, N. Label Studio: Data Labeling Software, 2020–2022. Open Source Software. Available online: https://github.com/heartexlabs/label-studio (accessed on 28 December 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015. NIPS’15. pp. 91–99. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 28 December 2022).
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Medica 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Yukun, S.; Pengju, H.; Yujie, W.; Ziqi, C.; Yang, L.; Baisheng, D.; Runze, L.; Yonggen, Z. Automatic monitoring system for individual dairy cows based on a deep learning framework that provides identification via body parts and estimation of body condition score. J. Dairy Sci. 2019, 102, 10140–10151. [Google Scholar] [CrossRef]
- Alvarez, J.R.; Arroqui, M.; Mangudo, P.; Toloza, J.; Jatip, D.; Rodríguez, J.M.; Teyseyre, A.; Sanz, C.; Zunino, A.; Machado, C.; et al. Body condition estimation on cows from depth images using Convolutional Neural Networks. Comput. Electron. Agric. 2018, 155, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Çevik, K.K. Deep Learning Based Real-Time Body Condition Score Classification System. IEEE Access 2020, 8, 213950–213957. [Google Scholar] [CrossRef]
- Krukowski, M. Automatic Determination of Body Condition Score of Dairy Cows from 3D Images; Skolan för datavetenskap och kommunikation; Kungliga Tekniska Högskolan: Stockholm, Sweden, 2009. [Google Scholar]
- Bercovich, A.; Edan, Y.; Alchanatis, V.; Moallem, U.; Parmet, Y.; Honig, H.; Maltz, E.; Antler, A.; Halachmi, I. Development of an automatic cow body condition scoring using body shape signature and Fourier descriptors. J. Dairy Sci. 2013, 96, 8047–8059. [Google Scholar] [CrossRef]
- Anglart, D. Automatic Estimation of Body Weight and Body Condition Score in Dairy Cows Using 3D Imaging Technique; SLU, Department of Animal Nutrition and Management: Uppsala, Sweden, 2014. [Google Scholar]
- Shelley, A.N. Incorporating Machine Vision in Precision Dairy Farming Technologies; University of Kentucky: Lexington, KY, USA, 2016. [Google Scholar]
- Spoliansky, R.; Edan, Y.; Parmet, Y.; Halachmi, I. Development of automatic body condition scoring using a low-cost 3-dimensional Kinect camera. J. Dairy Sci. 2016, 99, 7714–7725. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shigeta, M.; Ike, R.; Takemura, H.; Ohwada, H. Automatic measurement and determination of body condition score of cows based on 3D images using CNN. J. Robot. Mechatronics 2018, 30, 206–213. [Google Scholar] [CrossRef]
- Yu, J.; Yang, B.; Wang, J.; Leader, J.K.; Wilson, D.O.; Pu, J. 2D CNN versus 3D CNN for false-positive reduction in lung cancer screening. J. Med. Imaging 2020, 7, 051202. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BCS | F1 & F2 Farm | F3 Farm | |
|---|---|---|---|
| Training | Validation | Test | |
| 1.00 | 162 | 41 | 22 |
| 1.50 | 215 | 54 | 31 |
| 2.00 | 363 | 91 | 53 |
| 2.50 | 370 | 93 | 65 |
| 2.75 | 182 | 46 | 42 |
| 3.00 | 323 | 81 | 41 |
| 3.25 | 381 | 95 | 50 |
| 3.50 | 659 | 165 | 66 |
| 3.75 | 74 | 18 | 9 |
| 4.00 | 58 | 14 | 11 |
| 4.50 | 46 | 12 | 6 |
| 5.00 | 89 | 22 | 11 |
| Total: | 2922 | 732 | 407 |
| Pretrained | Validation |
|---|---|
| Faster R-CNN Model | Loss |
| R_50_FPN_3x | 0.0612 |
| R_101_FPN_3x | 0.0628 |
| R_50_FPN_1x | 0.0637 |
| X_101_32x8d_FPN_3x | 0.0662 |
| R_50_DC5_1x | 0.0796 |
| R_50_DC5_3x | 0.0840 |
| R_101_C4_3x | 0.0848 |
| R_101_DC5_3x | 0.0848 |
| R_50_C4_1x | 0.1019 |
| R_50_C4_3x | 0.1040 |
| Mark | Target BCS Interval | |
|---|---|---|
| Min | Max | |
| T1 | 3.25 | 3.75 |
| T2 | 2.75 | 3.25 |
| T3 | 2.50 | 3.00 |
| T4 | 3.00 | 3.75 |
 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagy, S.Á.; Kilim, O.; Csabai, I.; Gábor, G.; Solymosi, N. Impact Evaluation of Score Classes and Annotation Regions in Deep Learning-Based Dairy Cow Body Condition Prediction. Animals 2023, 13, 194. https://doi.org/10.3390/ani13020194
Nagy SÁ, Kilim O, Csabai I, Gábor G, Solymosi N. Impact Evaluation of Score Classes and Annotation Regions in Deep Learning-Based Dairy Cow Body Condition Prediction. Animals. 2023; 13(2):194. https://doi.org/10.3390/ani13020194
Chicago/Turabian StyleNagy, Sára Ágnes, Oz Kilim, István Csabai, György Gábor, and Norbert Solymosi. 2023. "Impact Evaluation of Score Classes and Annotation Regions in Deep Learning-Based Dairy Cow Body Condition Prediction" Animals 13, no. 2: 194. https://doi.org/10.3390/ani13020194