2.4.1. Original SSD Model for BCS Assessing
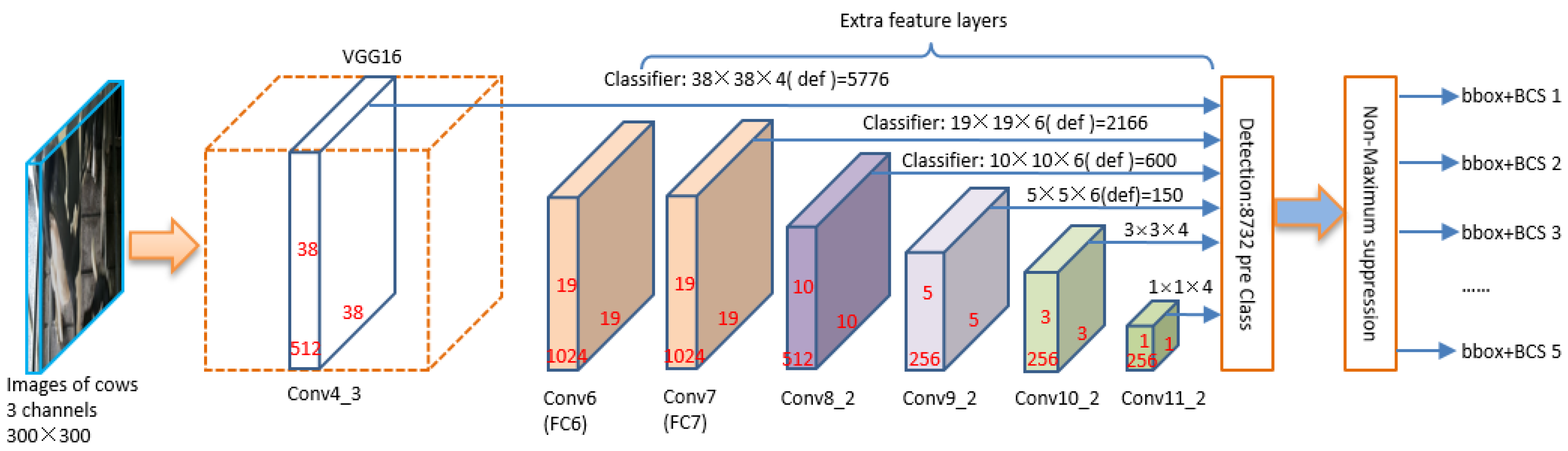
The SSD is a relatively fast and robust method. It is based on a feed forward convolution network that makes full use of the features of different output layers for object detection. The network structure used for BCS assessing for dairy cow is shown in
Figure 5. It can be divided into two parts: the VGG-16 and the extra feature layers. The front of the network for BCS classification is VGG-16, which is the baseline network with 16 layers including 13 convolution layers and 3 Fully-Connected (FC) layers. The filters of all layers are used with a very small receptive field: 3 × 3, which is a main contribution to improve the classification ability and decrease the amounts of parameters. The second part of the network is extra feature layers. There are six different scales of feature maps to detect different size of objects. Low-level layers such as FC6 and FC7 are used to detect small targets, and high-level layers such as Conv10_2 and Conv11_2 are used to detect targets of large size.
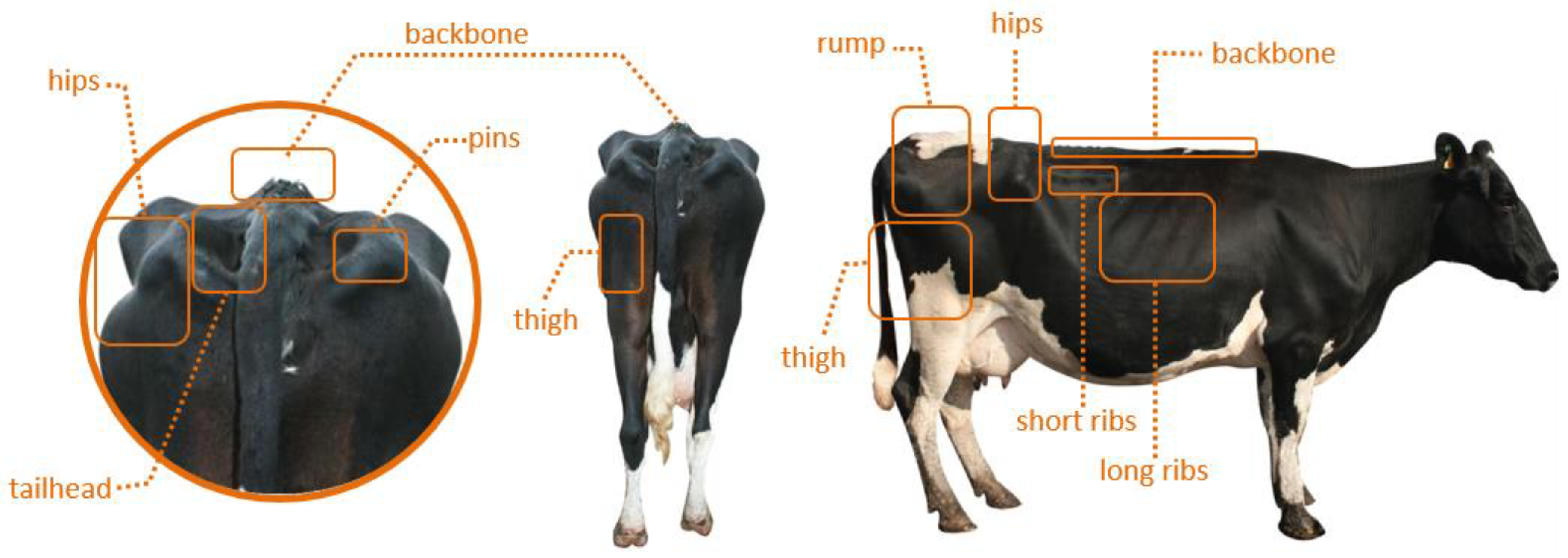
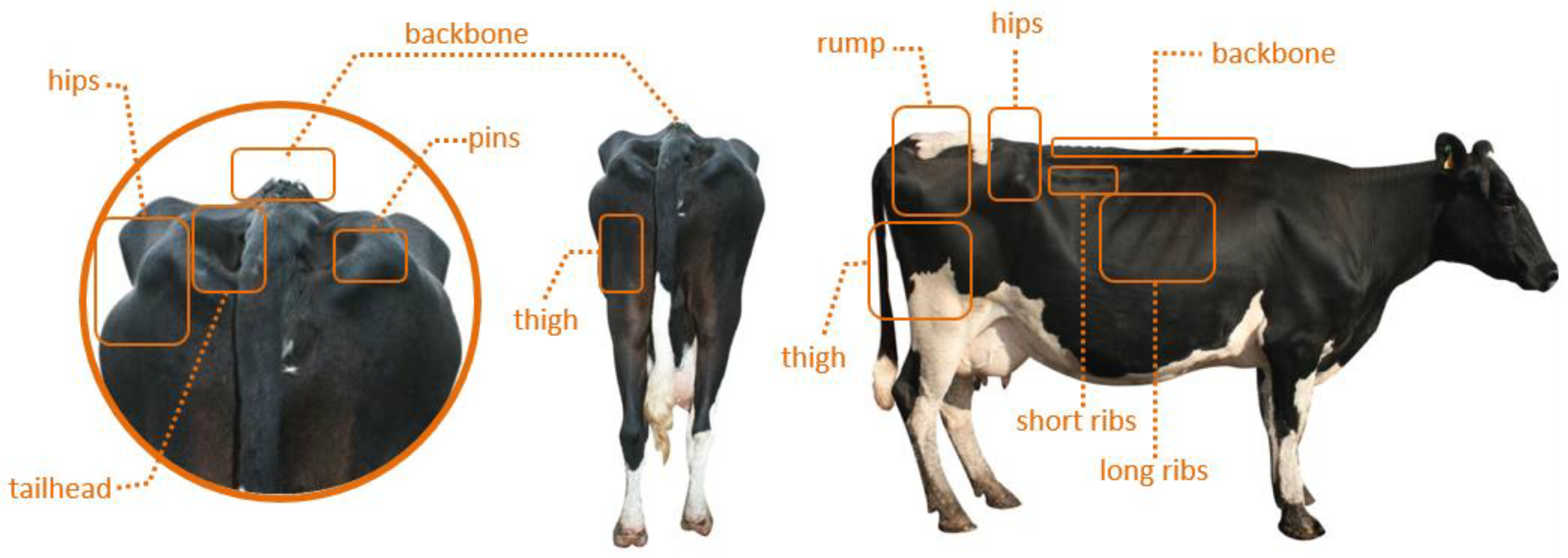
In the structure of SSD, when entering a back-view image of the cow and its label file, it uses a feature extraction network to generate a different size feature graph in which a 3 × 3 filter is used to evaluate the default box. After producing the default box, it will predict the migration and the probability of classification (BCS). Each feature map cell predicts the object BCS and migration of several default boxes, for the
k default boxes at some given location. And then the
c classification scores and 4 position offsets related to the ground-true box are calculated. The extra feature layers, in
Figure 5, are often added to the end of VGG-16. These layers help to decrease in size progressively and allow detecting predictions at multiple scales.
The detection results of different layers are merged in detection block which can decides if the area exists the targets and assigns predicted bounding boxes. While the non-maximum suppression (NMS) block is used to suppress redundant detection boxes. The objects are detected directly in the feature maps of each layers, consequently, there is no need to generate the candidate regions. Thus, that is why SSD can run at a high frame rate.
2.4.2. The Improved SSD Model
The original SSD performs very well in terms of both speed and accuracy by fully utilizing the feature maps of different layers. However, each layer contains its unique feature information, and is used independently, the close relationships between different layers is not well considered. On the other hand, the default boxes do not correspond to the actual receptive fields of each layer, and a better size of default boxes is effective so that its position and scale are better aligned with the receptive field of each position on a feature map [
24]. For these concerns, firstly, we introduce the DenseNet [
30] to improve the thin connection of original SSD between different layers, it can help to reduce information loss. Secondly, inception-v4 [
31,
32] block is employed to expand receptive field and reduce parameters of networks. The improved network structure used for BCS assessing is shown in
Figure 6.
(1) Replacing VGG-16 with DenseNet
In order to improve the performance of original SSD, in our study, we introduce the DenseNet that means the basic network VGG-16 is replaced by DenseNet. DenseNet is well considered the connection between any two layers with the same feature-map size. Instead of drawing representational power from extremely deep or wide structure, DenseNet exploit the potential of network through feature reemployment, producing condensed models, which are easy to train and highly parameter-efficient. Connecting feature maps that are learned by different layers enhances variation in the input of subsequent layers and improves efficiency.
The DenseNet [
30] consists of two parts: dense blocks and transitions. There are 3–6 dense blocks (we fix 6 dense blocks in our method) in the improved SSD networks. In the dense block as shown in
Figure 6, it comprises
L layers, each of which implements a non-linear transformation
, where
represents the layer. The input of each layer come from the outputs of all the preceding layers. Thus, it produces
L(
L + 1)/2 connection in each block. The advantage of this dense connection ensures that the information flowing throughout each layer is more complete. Considering one image
passed through a convolutional network, we assume that the
layer receives the feature maps of all the preceding layers
, …,
, as shown in the following formula:
where
represents the connection of each feature map produced in layer
.
is a composite function of three consecutive operations: batch normalization (BN), a rectified linear unit (ReLU), and a 3 × 3 convolution [
31]. Therefore, in our method, the relationships between each layer of the feature maps are well considered. The combination of rich details information in the low-level layers and strong semantic features in the high-level layers helps the new SSD method to fuse more features.
The second important part is transition which consists of a 1 × 1 Convolutional layer and a 2 × 2 average Pooling layer, as shown in
Figure 6, transition is the layer between dense blocks. For the connection operation (Equation 1) is not capable when the size of feature maps has been changed, convolutional networks are down-sampling layers that help to resize the shape of each layer. Thus, the shape of feature maps always keeps 2H × 2W that is equal to that of the target layer. The 1 × 1 convolutional layer is used to unify the channel dimension to 512. The function of average pooling layer is to reduce the amount of the parameters and computation in the network. At the end of the last dense block, a global average pooling is employed and a target detector is attached. The non- maximum suppression block is used to remove the redundant boxes in the detection task. The final output of the network is the BCS level of the given images.
(2) Introducing Inception-v4
There are 12 convolution layers in each dense block. In our study, we replace these common convolution layers with 6 Inception-v4 [
32] blocks, the schema of each block is shown in
Figure 7. Although VGG-16 in SSD method has the compelling feature of architectural simplicity, it comes at a high cost for a lot of computation. However, the computational cost of Inception-v4 is much lower than VGG. The parameters employed by Inception-v4 are also less than VGG. These factors meet the needs of high real-time requirements where memory or computational capacity is inherently limited. In order to design a compact, low-cost BCS assessing system, inception-v4 block is introduced to replace the single 3 × 3 convolution kernel. The overall schema of the Inception-v4 network in each dense block is shown in the
Figure 7.
The network design of Inception-v4 follows the previous version (Inception-v2/v3 [
32]). The filter concatenation functions as connecting the images according to depth. For example, the output of three 10 × 10 × 3 images is 10 × 10 × 9 by filter concatenation. The training speed of this module is greatly accelerated by combining with variants of these blocks (with various number of filters). Meanwhile, The Inception block expands receptive field and reduces parameters of the dense blocks. To see the effect of these improvements, the contrast experiments are carried out in
Section 3.
(3) The Architecture of Our SSD
The proposed SSD algorithm is a muti-scale proposal free detection framework which is similar to original SSD. And the framework of our SSD is built on the original SSD, therefore, the speed and accuracy advantages will be inherited obviously. In our method, the advantages of DenseNet and Inception-v4 are absorbed, the new network architecture is formed in
Table 2. There are 6 dense blocks and 6 transition layers, and each dense block contains 6 inception blocks (as shown in
Figure 7). The output size and the connection of each layer detail in the table.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}