
Accurate Feature Extraction from Historical Geologic Maps Using Open-Set Segmentation and Detection

 , , , , and
, , , , and
Abstract
:1. Introduction
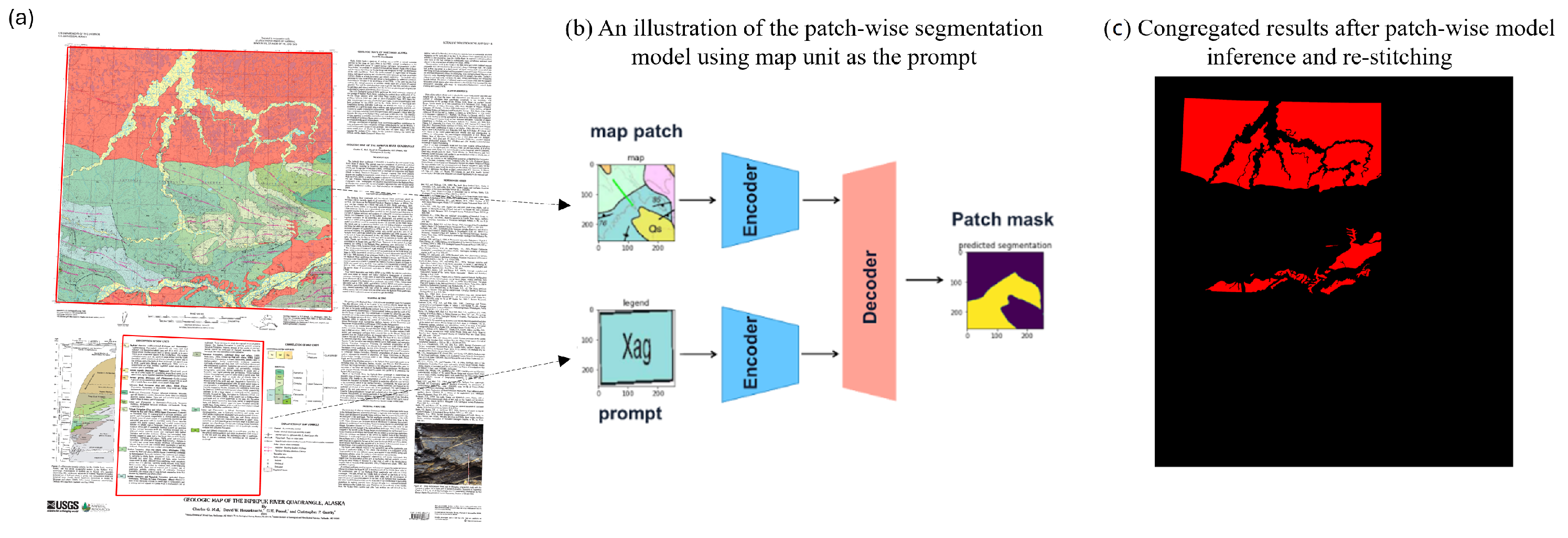
- We developed an automated pipeline for geologic map feature extraction. Initially, we extracted map units from the legend region, and then we used a prompt-based method for open-set polygon and point feature extraction, utilizing the legend items as prompts.
- We systematically evaluated the effects of patch size, model backbone, and data augmentation methods on model performance, including hyperparameter tuning, to enhance both accuracy and generalizability.
- We vectorized the extracted polygon and point features to facilitate their integration with geophysical and geochemical data, enabling multi-source mineral prospectivity mapping.
2. Related Work
2.1. Geologic Map Digitization
2.2. Open-Set Segmentation
2.3. Open-Set Detection
3. Dataset and Methods
3.1. Dataset Description
3.2. Data Engineering—Spatial Indexing and Grid Construction
3.3. Map Unit Extraction
3.4. Polygon Feature Extraction
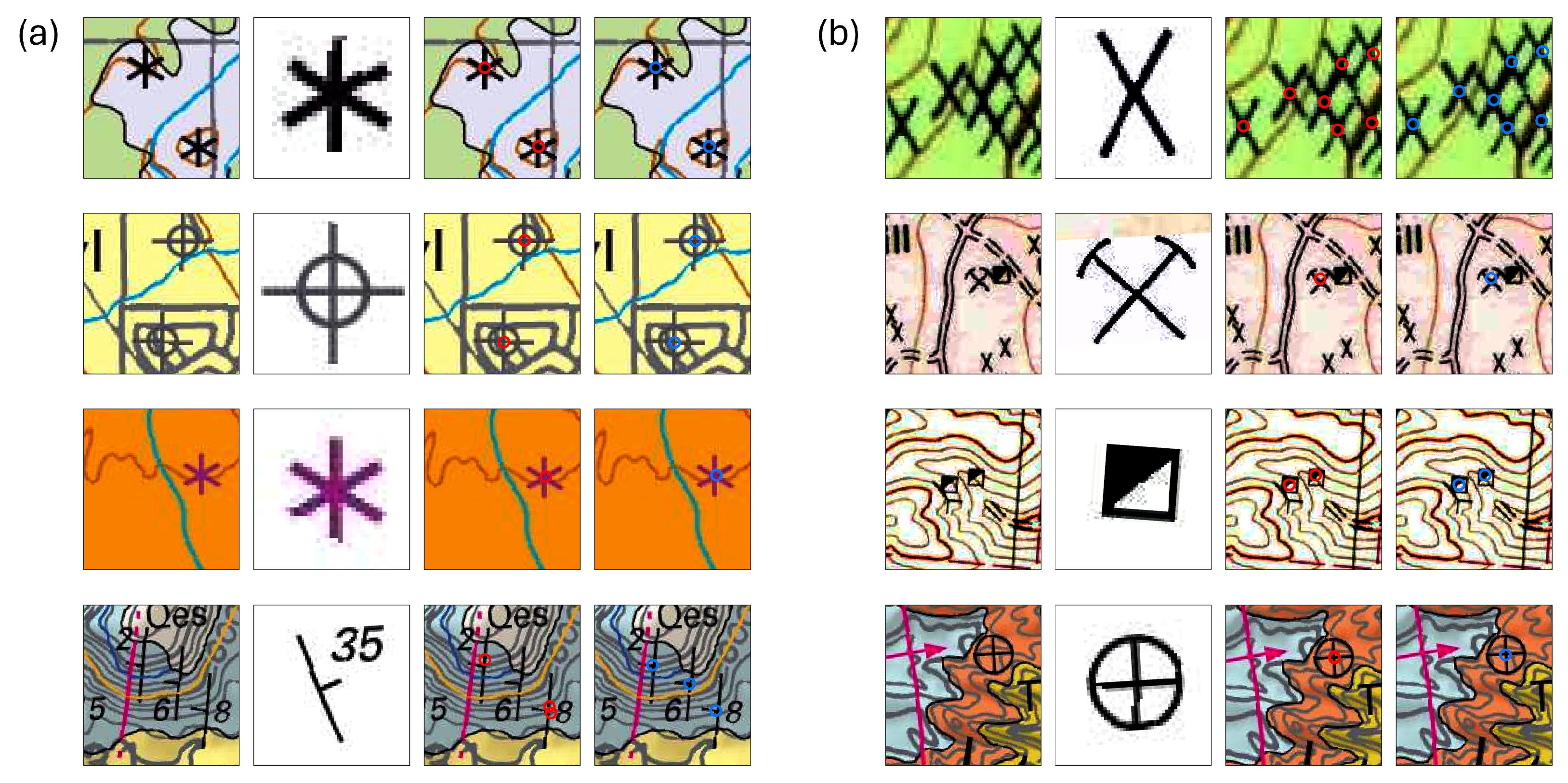
3.5. Point Feature Extraction
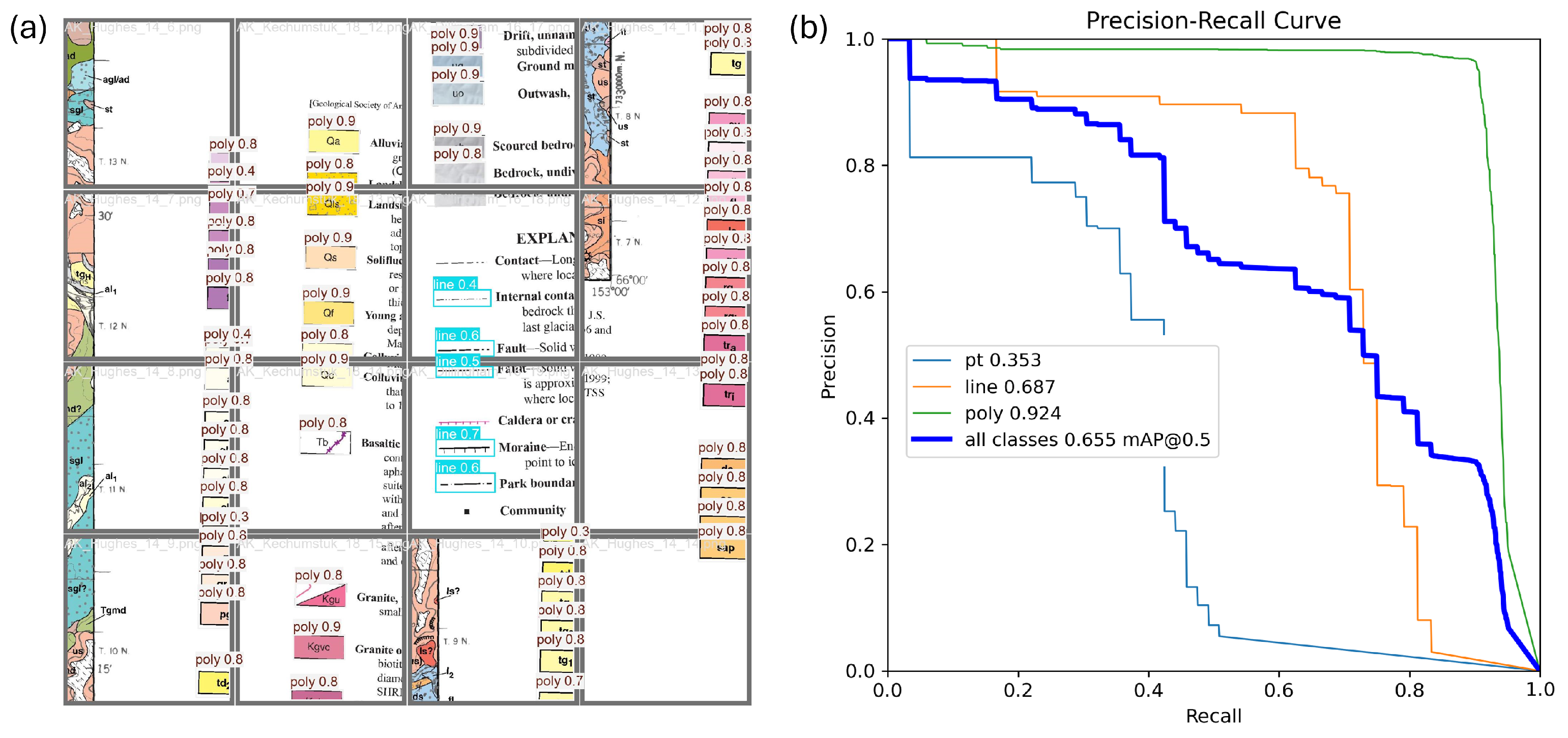
3.6. Evaluation Metrics
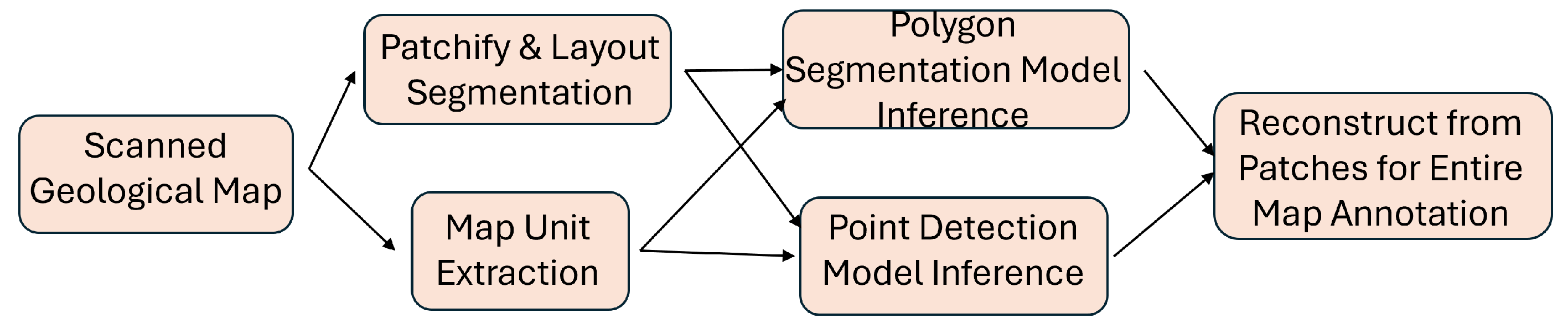
3.7. Workflow Design
4. Results and Discussion
4.1. Map Unit Extraction
4.2. Polygon Feature Segmentation
4.2.1. Patch and Overlap Size Optimization
4.2.2. Model Search and Hyperparameter Tuning
4.2.3. Whole Map Evaluation
4.3. Model Performance for Point Detection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thomas, W.A.; Hatcher, R.D. Meeting Challenges with Geologic Maps; American Geological Institute: Alexandria, VA, USA, 2004. [Google Scholar]
- Soller, D.R.; Berg, T.M. The US national geologic map database project: Overview & progress. In Current Role of Geological Mapping in Geosciences, Proceedings of the NATO Advanced Research Workshop on Innovative Applications of GIS in Geological Cartography, Kazimierz Dolny, Poland, 24–26 November 2003; Springer: Dordrecht, The Netherlands, 2005; pp. 245–277. [Google Scholar]
- Fortier, S.M.; Hammarstrom, J.; Ryker, S.J.; Day, W.C.; Seal, R.R. USGS critical minerals review. Min. Eng. 2019, 71, 35–47. [Google Scholar]
- Xu, Y.; Li, Z.; Xie, Z.; Cai, H.; Niu, P.; Liu, H. Mineral prospectivity mapping by deep learning method in Yawan-Daqiao area, Gansu. Ore Geol. Rev. 2021, 138, 104316. [Google Scholar] [CrossRef]
- Luo, S.; Saxton, A.; Bode, A.; Mazumdar, P.; Kindratenko, V. Critical minerals map feature extraction using deep learning. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 8002005. [Google Scholar] [CrossRef]
- Budig, B.; van Dijk, T.C. Active learning for classifying template matches in historical maps. In Discovery Science, Proceedings of the 18th International Conference, DS 2015, Banff, Banff, AB, Canada, 4–6 October 2015; Proceedings 18; Springer: Cham, The Netherlands, 2015; pp. 33–47. [Google Scholar]
- Budig, B.; van Dijk, T.C.; Feitsch, F.; Arteaga, M.G. Polygon consensus: Smart crowdsourcing for extracting building footprints from historical maps. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016; pp. 1–4. [Google Scholar]
- Soliman, A.; Chen, Y.; Luo, S.; Makharov, R.; Kindratenko, V. Weakly supervised segmentation of buildings in digital elevation models. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7004205. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Wang, J.; Wang, L.; Gao, J.; Lee, Y.J. Segment everything everywhere all at once. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; Volume 36. [Google Scholar]
- Sun, Y.; Chen, J.; Zhang, S.; Zhang, X.; Chen, Q.; Zhang, G.; Ding, E.; Wang, J.; Li, Z. VRP-SAM: SAM with visual reference prompt. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 23565–23574. [Google Scholar]
- Luo, L.; Li, P.; Yan, X. Deep learning-based building extraction from remote sensing images: A comprehensive review. Energies 2021, 14, 7982. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic segmentation deep learning for extracting surface mine extents from historic topographic maps. Remote Sens. 2020, 12, 4145. [Google Scholar] [CrossRef]
- Vasuki, Y.; Holden, E.J.; Kovesi, P.; Micklethwaite, S. An interactive image segmentation method for lithological boundary detection: A rapid mapping tool for geologists. Comput. Geosci. 2017, 100, 27–40. [Google Scholar] [CrossRef]
- Nunes, I.; Laranjeira, C.; Oliveira, H.; dos Santos, J.A. A systematic review on open-set segmentation. Comput. Graph. 2023, 115, 296–308. [Google Scholar] [CrossRef]
- Nunes, I.; Pereira, M.B.; Oliveira, H.; dos Santos, J.A.; Poggi, M. Conditional reconstruction for open-set semantic segmentation. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 946–950. [Google Scholar]
- Da Silva, C.C.; Nogueira, K.; Oliveira, H.N.; dos Santos, J.A. Towards open-set semantic segmentation of aerial images. In Proceedings of the 2020 IEEE Latin American GRSS & ISPRS Remote Sensing Conference (LAGIRS), Santiago, Chile, 22–26 March 2020; pp. 16–21. [Google Scholar]
- Brilhador, A.; Lazzaretti, A.E.; Lopes, H.S. A prototypical metric learning approach for open-set semantic segmentation on remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5640114. [Google Scholar] [CrossRef]
- Lin, F.; Knoblock, C.A.; Shbita, B.; Vu, B.; Li, Z.; Chiang, Y.Y. Exploiting Polygon Metadata to Understand Raster Maps-Accurate Polygonal Feature Extraction. In Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, New York, NY, USA, 13–16 November 2023; pp. 1–12. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Cham, The Netherlands, 2014; pp. 740–755. [Google Scholar]
- Uhl, J.H.; Leyk, S.; Chiang, Y.Y.; Duan, W.; Knoblock, C.A. Spatialising uncertainty in image segmentation using weakly supervised convolutional neural networks: A case study from historical map processing. IET Image Process. 2018, 12, 2084–2091. [Google Scholar] [CrossRef]
- Jiao, C.; Heitzler, M.; Hurni, L. A fast and effective deep learning approach for road extraction from historical maps by automatically generating training data with symbol reconstruction. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102980. [Google Scholar] [CrossRef]
- Minderer, M.; Gritsenko, A.; Stone, A.; Neumann, M.; Weissenborn, D.; Dosovitskiy, A.; Mahendran, A.; Arnab, A.; Dehghani, M.; Shen, Z.; et al. Simple open-vocabulary object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, The Netherlands, 2022; pp. 728–755. [Google Scholar]
- Kim, H.Y.; De Araújo, S.A. Grayscale template-matching invariant to rotation, scale, translation, brightness and contrast. In Advances in Image and Video Technology, Proceedings of the Second Pacific Rim Symposium, PSIVT 2007, Santiago, Chile, 17–19 December 2007; Proceedings 2; Springer: Berlin/Heidelberg, Germany, 2007; pp. 100–113. [Google Scholar]
- Korman, S.; Reichman, D.; Tsur, G.; Avidan, S. Fast-match: Fast affine template matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2331–2338. [Google Scholar]
- Guo, M.; Bei, W.; Huang, Y.; Chen, Z.; Zhao, X. Deep learning framework for geological symbol detection on geological maps. Comput. Geosci. 2021, 157, 104943. [Google Scholar] [CrossRef]
- Chanda, S.; Prasad, P.K.; Hast, A.; Brun, A.; Martensson, L.; Pal, U. Finding Logo and Seal in Historical Document Images-An Object Detection Based Approach. In Pattern Recognition, Proceedings of the 5th Asian Conference, ACPR 2019, Auckland, New Zealand, 26–29 November 2019; Revised Selected Papers, Part I 5; Springer: Cham, The Netherlands, 2020; pp. 821–834. [Google Scholar]
- Saeedimoghaddam, M.; Stepinski, T.F. Automatic extraction of road intersection points from USGS historical map series using deep convolutional neural networks. Int. J. Geogr. Inf. Sci. 2020, 34, 947–968. [Google Scholar] [CrossRef]
- Goldman, M.A.; Rosera, J.M.; Lederer, G.W.; Graham, G.E.; Mishra, A.; Yepremyan, A. Training and Validation Data from the AI for Critical Mineral Assessment Competition; U.S. Geological Survey Sata Release: Reston, VA, USA, 2023. [CrossRef]
- The HDF Group. Hierarchical Data Format, Version 5. Available online: https://github.com/HDFGroup/hdf5 (accessed on 1 November 2024).
- Lederer, G.W.; Solano, F.; Coyan, J.A.; Denton, K.M.; Watts, K.E.; Mercer, C.N.; Bickerstaff, D.P.; Granitto, M. Tungsten skarn mineral resource assessment of the Great Basin region of western Nevada and eastern California. J. Geochem. Explor. 2021, 223, 106712. [Google Scholar] [CrossRef]
- Glen, J.; Earney, T. GeoDAWN: Airborne Magnetic and Radiometric Surveys of the Northwestern Great Basin, Nevada and California; U.S. Geological Survey: Reston, VA, USA, 2024.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Cham, The Netherlands, 2015; pp. 234–241. [Google Scholar]
- Xu, Z.; Wang, S.; Stanislawski, L.V.; Jiang, Z.; Jaroenchai, N.; Sainju, A.M.; Shavers, E.; Usery, E.L.; Chen, L.; Li, Z.; et al. An attention U-Net model for detection of fine-scale hydrologic streamlines. Environ. Model. Softw. 2021, 140, 104992. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Cao, R.; Tan, C.L. Separation of overlapping text from graphics. In Proceedings of the Sixth International Conference on Document Analysis and Recognition, Seattle, WA, USA, 13 September 2001; pp. 44–48. [Google Scholar]
- Qiu, Q.; Tan, Y.; Ma, K.; Tian, M.; Xie, Z.; Tao, L. Geological symbol recognition on geological map using convolutional recurrent neural network with augmented data. Ore Geol. Rev. 2023, 153, 105262. [Google Scholar] [CrossRef]
- Bharadwaj, R.; Naseer, M.; Khan, S.; Khan, F.S. Enhancing Novel Object Detection via Cooperative Foundational Models. arXiv 2023, arXiv:2311.12068. [Google Scholar]
- Pan, H.; Yi, S.; Yang, S.; Qi, L.; Hu, B.; Xu, Y.; Yang, Y. The Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge. arXiv 2024, arXiv:2406.12225. [Google Scholar]
- Russakovsky, O.; Li, L.J.; Fei-Fei, L. Best of both worlds: Human-machine collaboration for object annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2121–2131. [Google Scholar]
- DARPA. Critical Mineral Assessments with AI Support (CriticalMAAS). Available online: https://shorturl.at/Tgacn (accessed on 1 November 2024).
- DARPA. Critical Mineral Assessments with AI Support (CriticalMAAS). Available online: https://shorturl.at/MlhnK (accessed on 1 November 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pred_Point | Pred_Line | Pred_Polygon | Pred_Background | |
|---|---|---|---|---|
| True_Point | 0.36 | 0.03 | 0 | 0.61 |
| True_Line | 0 | 0.73 | 0 | 0.27 |
| True_Polygon | 0 | 0 | 0.91 | 0.09 |
| True_Background | 0.12 | 0.15 | 0.74 | 0 |
| Model | Patch Size | Overlap | Best Train F1 Score (%) | Best Validation F1 Score (%) | Difference (%) |
|---|---|---|---|---|---|
| Vanilla_Unet | 128 | 3 | 95.29 | 80.72 | 14.57 |
| 5 | 95.89 | 80.59 | 15.30 | ||
| 10 | 95.49 | 81.26 | 14.23 | ||
| 15 | 96.05 | 82.18 | 13.87 | ||
| 256 | 3 | 90.58 | 81.65 | 8.93 | |
| 5 | 91.24 | 82.26 | 8.98 | ||
| 10 | 92.18 | 84.23 | 7.95 | ||
| 15 | 93.54 | 84.39 | 9.15 | ||
| 32 | 94.02 | 85.72 | 8.30 | ||
| 512 | 3 | 78.84 | 75.43 | 3.41 | |
| 5 | 70.46 | 69.86 | 0.60 | ||
| 10 | 74.38 | 72.21 | 2.17 | ||
| 15 | 78.16 | 72.76 | 5.40 | ||
| 1024 | 3 | 23.44 | 20.02 | 3.42 | |
| 5 | 16.88 | 15.04 | 1.84 | ||
| 10 | 24.59 | 26.76 | −2.17 | ||
| 15 | 24.66 | 23.53 | 1.13 |
| Model | Best Train F1 | Best Validation F1 |
|---|---|---|
| Attention_Unet [35] | 92.34% | 82.49% |
| Vanilla_Unet [34] | 94.02% | 85.72% |
| MultiRes_Unet [36] | 58.93% | 56.87% |
| Methods | Validation | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 | Precision | Recall | IoU | F1 | Precision | Recall | IoU | |
| LOAM [19] | - | - | - | - | 80.90 | 89.10 | 91.50 | - |
| Prompted U-Net | 79.41 | 84.27 | 88.40 | 65.86 | 90.03 | 92.76 | 93.15 | 82.35 |
| U-Net + P | 83.62 | 87.18 | 89.77 | 71.85 | 90.90 | 94.21 | 93.27 | 83.31 |
| U-Net + P + A | 83.71 | 87.97 | 89.54 | 71.98 | 91.52 | 94.85 | 93.01 | 84.36 |
| Methods | Common Legends | Rare Legends | ||||
|---|---|---|---|---|---|---|
| F1 | Precision | Recall | F1 | Precision | Recall | |
| Prompted YOLO (Validation) | 72.59 | 82.12 | 70.59 | 39.21 | 32.58 | 69.46 |
| Prompted YOLO (Testing) | 48.10 | 53.84 | 80.16 | 0 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saxton, A.; Dong, J.; Bode, A.; Jaroenchai, N.; Kooper, R.; Zhu, X.; Kwark, D.H.; Kramer, W.; Kindratenko, V.; Luo, S. Accurate Feature Extraction from Historical Geologic Maps Using Open-Set Segmentation and Detection. Geosciences 2024, 14, 305. https://doi.org/10.3390/geosciences14110305
Saxton A, Dong J, Bode A, Jaroenchai N, Kooper R, Zhu X, Kwark DH, Kramer W, Kindratenko V, Luo S. Accurate Feature Extraction from Historical Geologic Maps Using Open-Set Segmentation and Detection. Geosciences. 2024; 14(11):305. https://doi.org/10.3390/geosciences14110305
Chicago/Turabian StyleSaxton, Aaron, Jiahua Dong, Albert Bode, Nattapon Jaroenchai, Rob Kooper, Xiyue Zhu, Dou Hoon Kwark, William Kramer, Volodymyr Kindratenko, and Shirui Luo. 2024. "Accurate Feature Extraction from Historical Geologic Maps Using Open-Set Segmentation and Detection" Geosciences 14, no. 11: 305. https://doi.org/10.3390/geosciences14110305
APA StyleSaxton, A., Dong, J., Bode, A., Jaroenchai, N., Kooper, R., Zhu, X., Kwark, D. H., Kramer, W., Kindratenko, V., & Luo, S. (2024). Accurate Feature Extraction from Historical Geologic Maps Using Open-Set Segmentation and Detection. Geosciences, 14(11), 305. https://doi.org/10.3390/geosciences14110305