Evolving Government Information Processes for Service Delivery: Identifying Types & Impact



Abstract
:1. Introduction
- (1)
- the collection of initial data serving as information input;
- (2)
- a range of processing activities to make the input usable and
- (3)
- the availability of output information enabling the achievement of objectives.
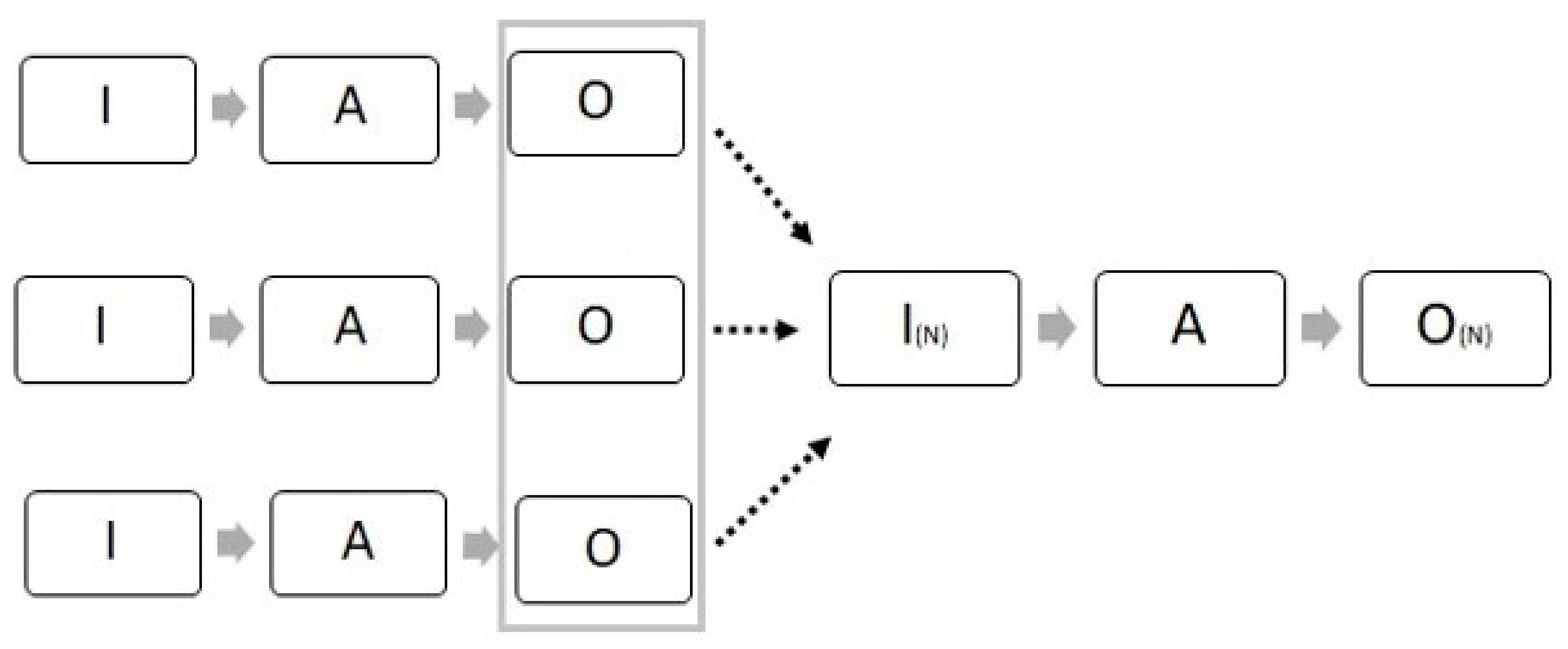
- (a)
- the use of present output information for the achievement of new objectives
- (b)
- better achievement of existing objectives by applying additional data processing activities to the initial data
- (c)
- new sorts of output information, based on the integration of existing output information, leading to new objectives.
1.1. Research Objectives
- (1)
- to provide insight into how the traditional government information process is evolving,
- (2)
- to develop a typology of evolutions and
- (3)
- to explore the impact of these evolutions on the information process and service creation, delivery, and improvement.
1.2. Structure of the Paper
2. The Traditional Government Information Process
- (1)
- The production of national or regional statistics through surveys: Surveys are a traditional instrument for governments to obtain useful societal information. Typical examples include household budget surveys, consumer price index surveys, national health surveys and tourism surveys (see e.g., (Eurostat 2018)). Initial data is collected from citizens or companies who are invited to fulfil questionnaires serving as input (=I). These questionnaires need to be processed. The processing activities such as data cleansing, data analysis, and visualization of the analysis (=A) result in usable statistics (=O). This output facilitates informed decision-making, for instance to improve existing services or develop new services related to social, economic, or health domains.
- (2)
- The granting of benefits by governments: In order to receive particular benefits, applicants (e.g., citizens, companies, non-profit organizations) need to provide initial data such as identity data and data related to the conditions of the benefit, e.g., income and family status of an individual or the type of company or organization (=I). These initial data need to be analyzed by the responsible government agencies or delegated entities. The processing activities, whether manual or automated, involve for instance the verification of the initial data and assessment of these data related to benefit criteria. The results of the analysis (=O) allows an administration to decide if an application is valid and if the service will be offered or rejected.
3. Methodology
4. A Typology of Evolutions Concerning the Traditional Government Information Process
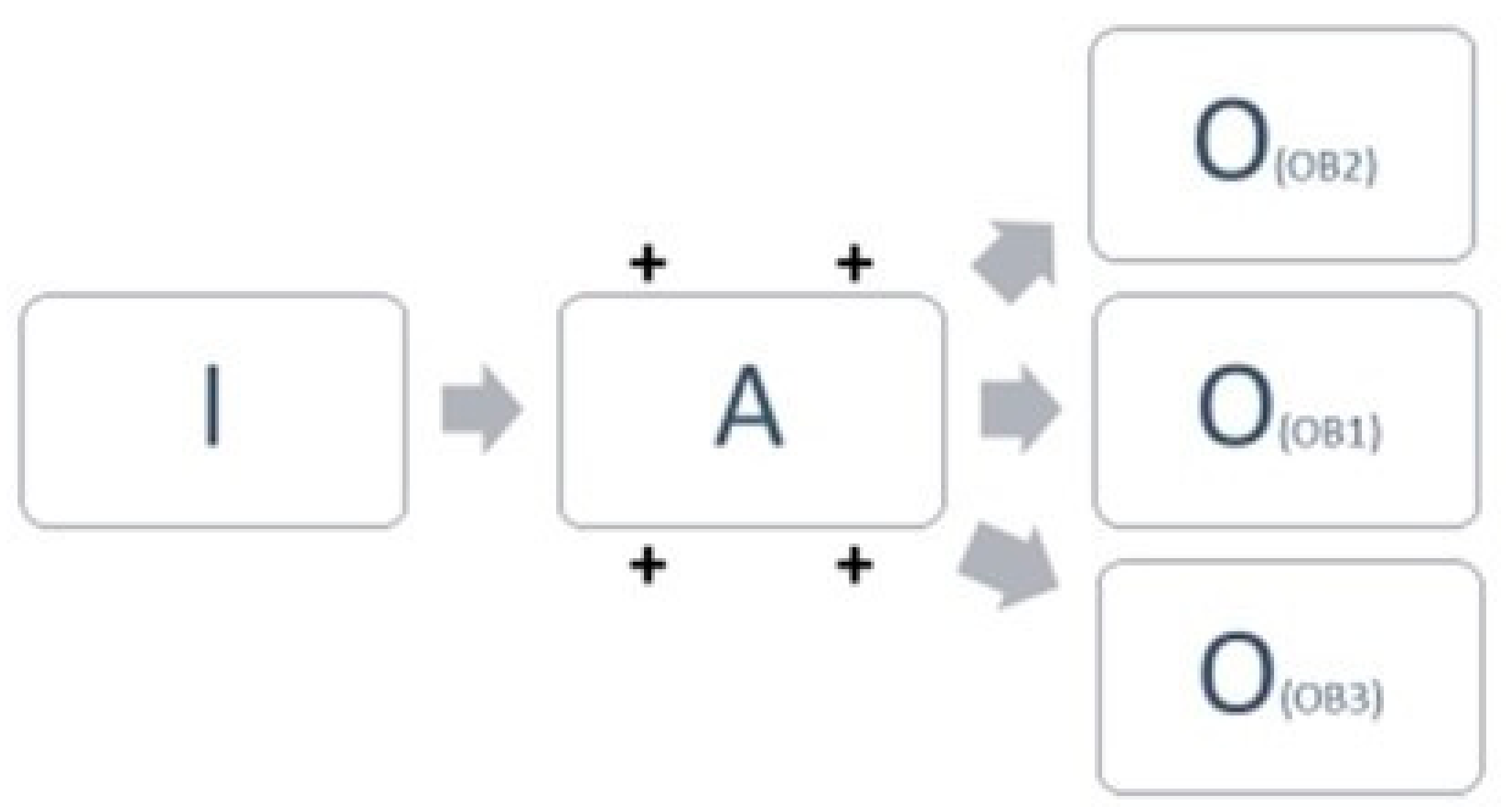
4.1. Process Evolution Type A: Initial Data—New Activities—Expansion of Output Information Objectives
4.1.1. Example: Extensive Use of License Plate Data
4.1.2. Example: The Extensive Use of Camera Networks
4.1.3. Context
4.1.4. Impact of the Evolution on the Process and Service Creation, Delivery, and Improvement
4.2. Process Evolution Type B: Initial Data—New Activities—Improved Output Information
4.2.1. Example: Fraud Detection in Taxation and Social Security
4.2.2. Example: Job Searching Assistance for Unemployed Workers
4.2.3. Context
- (1)
- the use and the combination of multiple, large datasets, from various sources, both external and internal to the organization;
- (2)
- the use and the combination of structured (traditional) and less structured or unstructured (non-traditional) data in analysis activities;
- (3)
- the use of incoming data streams in real time or near real time;
- (4)
- the development and application of advanced analytics and algorithms, distributed computing, and/or advanced technology to handle very large and complex computing tasks;
- (5)
- the innovative use of existing datasets and/or data sources for new and radically different applications than the data were gathered for or spring from.
4.2.4. Impact of the Evolution on the Process and Service Creation, Delivery and Improvement
- a quality assessment of the added (new) data sources in light of the objectives of the internal or external service;
- possible trade-offs between the benefits using sensitive, personal data (e.g., social media data, mobile phone tracking data, website clickstream data) and privacy or ethical concerns and
- transparency and accountability regarding applied analytics.
4.3. Process Change Type C: A Merger of Output Information Forms New Input—Activities—New Output
4.3.1. Example: The Solar Map
4.3.2. Context
4.3.3. Impact of the Evolution on the Process and Service Creation, Delivery, and Improvement
4.4. Typology Overview and Limitations
- replacement of census and household surveys by the use of mobile positioning data or electricity smart meter data (Florescu et al. 2014; World Bank 2017);
- replacement of land surveys and land registrations by data derived from satellites and drones (World Bank 2017)
- replacement of socio-economic surveys (concerning for instance unemployment) by combining data from social media, Google searches, credit cards, online shops etc. (Mergel et al. 2016).
5. Discussion and Future Research
- type (A) initial data—new activities—expansion of output information objectives
- type (B) initial data—new activities—improved output information
- type (C) a merger of output information forms new input—activities—new output
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Amankwah-Amoah, Joseph. 2015. Safety or no safety in numbers? Governments, big data and public policy formulation. Industrial Management & Data Systems 115: 1596–603. [Google Scholar]
- Article 29 Data Protection Working Party. 2013. Opinion 03/2013 on Purpose Limitation. 00569/13/EN, WP 203. Brussels: European Commission. [Google Scholar]
- Attard, Judie, Fabrizio Orlandi, Simon Scerri, and Sören Auer. 2015. A systematic review of open government data initiatives. Government Information Quarterly 32: 399–418. [Google Scholar] [CrossRef]
- Australian Government Information Management Office. 2009. National Government Information Sharing Strategy—Unlocking Government Information Assets to Benefit the Broader Community; Parkes: Department of Finance and Deregulation, Australia.
- Bannister, Frank, and Regina Connolly. 2011. The Trouble with Transparency: A Critical Review of Openness in e-Government. Policy and Internet 3: 8. [Google Scholar] [CrossRef]
- Barocas, Solon, Sophie Hood, and Malte Ziewitz. 2013. Governing Algorithms: A Provocation Piece. Available online: https://ssrn.com/abstract=2245322 (accessed on 2 May 2018).
- Bekkers, V., and V. M. F. Hamburg. 2005. E-Government, Changing Jurisdictions and Boundary Management. In The Information Ecology of E-Government. Amsterdam: IOS Press, pp. 53–71. [Google Scholar]
- Billiet, Jaak, and Hans Waege. 2003. Een Samenleving Onderzocht. Methoden van Sociaal-Wetenschappelijk Onderzoek. Antwerpen: De Boeck. [Google Scholar]
- Boyd, Danah, and Kate Crawford. 2012. Critical Questions for Big Data. Information, Communication and Society 15: 662–79. [Google Scholar] [CrossRef]
- Breckenridge, Keith, and Simon Szreter. 2012. Registration and Recognition: Documenting the Person in World History. Oxford: Oxford University Press. [Google Scholar]
- Cerrilo-i-Martinez, Agusti. 2012. Fundamental interests and open data for re-use. International Journal of Law and Information Technology 20: 203–22. [Google Scholar] [CrossRef]
- Chen, Hsinchun, Roger H. L. Chiang, and Veda C. Storey. 2012. Business Intelligence and Analytics: From Big Data to Big Impact. MIS Quarterly 36: 1165–88. [Google Scholar]
- Commissie voor de Bescherming van de Persoonlijke Levenssfeer. 2017. Advies Betreffende het Voorontwerp van Wet tot Wijziging van de Wet op het Politieambt en de Wet van 21 Maart 2007 tot Regeling van de Plaatsing en het Gebruik van Bewakingscamera’s (CO-A-2017-054). Advies nr. 53/2017 van 20 September 2017. Brussels: Commissie voor de Bescherming van de Persoonlijke Levenssfeer. (In Dutch) [Google Scholar]
- Crawford, Kate. 2013. The Hidden Biases in Big Data. Harvard Business Review. Available online: https://hbr.org/2013/04/the-hidden-biases-in-big-data (accessed on 11 December 2017).
- Crompvoets, Joep, and H. G. Van der Voort. 2016. Big data en de toezichthouder: Een gesprek met Gaël Kermarrec. Bestuurskunde 25: 3–8. (In Dutch). [Google Scholar] [CrossRef]
- Deloitte. 2016. Big Data Analytics for Policy Making. A Study Prepared for the European Commission DG Informatics. Brussels: European Union. [Google Scholar]
- Diakopoulos, Nicholas. 2016. Accountability in algorithmic decision making. Communications of the ACM 59: 56–62. [Google Scholar] [CrossRef]
- Dong, Haiwei, Gobindbir Singh, Aarti Attri, and Abdulmotaleb El Saddik. 2017. Open Data-Set of Seven Canadian Cities. IEEE 5: 529–43. [Google Scholar] [CrossRef]
- Dumortier, Jos, and Frank Robben. 2010. User and Access Management in Belgian e-Government. In ISSE 2009 Securing Electronic Business Processes. Wiesbaden: Vieweg+Teubnern, pp. 97–107. [Google Scholar]
- Dunleavy, Patrick, Helen Margetts, Simon Bastow, and Jane Tinkler. 2008. Digital Era Governance: IT Corporations, the State, and E-Government. Oxford: Oxford University Press. [Google Scholar]
- European Commission. 2017. New European Interoperability Framework Promoting Seamless Services and Data Flows for European Public Administrations. Luxembourg: Publications Office of the European Union. [Google Scholar]
- Eurostat. 2018. Publications. Available online: http://ec.europa.eu/eurostat/publications/statistical-reports (accessed on 8 April 2018).
- Executive Office of the President. 2016. Big Data: A Report on Algorithmic Systems, Opportunity, and Civil Rights; White House Report; Washington: White House.
- Florescu, Denisa, Martin Karlberg, Fernando Reis, P. Rey Del Castillo, Michail Skaliotis, and Albrecht Wirthmann. 2014. Will ‘Big Data’ Transform Official Statistics? Available online: http://www.q2014.at/fileadmin/user_upload/ESTAT-Q2014-BigDataOS-v1a.pdf (accessed on 9 January 2018).
- Gamage, Pandula. 2016. New development: Leveraging ‘big data’ analytics in the public sector. Public Money & Management 36: 385–90. [Google Scholar]
- Gartner. 2017. IT Glossary. Big Data. Available online: www.gartner.com/it-glossary/big-data (accessed on 18 October 2017).
- Giest, Sarah. 2017. Big data for policymaking: Fad or fasttrack? Policy Sciences 50: 367–82. [Google Scholar] [CrossRef]
- Gil-Garcia, J. Ramon, InduShobha Chengalur-Smith, and Peter Duchessi. 2007. Collaborative E-government: Impediments and Benefits of Information-sharing Projects in the Public Sector. European Journal of Information Systems 16: 121–33. [Google Scholar] [CrossRef]
- Gitelman, Lisa. 2013. “Raw Data” Is an Oxymoron. Cambridge: The MIT Press. [Google Scholar]
- Gonzalez-Zapata, Felipe, and Richard Heeks. 2015. The multiple meanings of open government data: Understanding different stakeholders and their perspectives. Government Information Quarterly 32: 441–52. [Google Scholar] [CrossRef]
- Heijlen, Roel, and Joep Crompvoets. 2017. Clean data for cleaner air? Case study research about data streams concerning low-emission zones and car-free zones. Zenodo. [Google Scholar] [CrossRef]
- Henninger, Michael. 2013. The Value and Challenges of Public Sector Innovation. Cosmopolitan Civil Societies Journal 5: 75–95. [Google Scholar]
- Higgs, Edward. 2004. The Information State in England: The Central Collection of Information on Citizens Since 1500. Basingstoke: Palgrave Macmillan. [Google Scholar]
- Janssen, Marijn, Soon Ae Chun, and J. Ramon Gil-Garcia. 2009. Building the next generation of digital government infrastructures. Government Information Quarterly 26: 233–37. [Google Scholar] [CrossRef]
- Janssen, Marijn, Yannis Charalabidis, and Anneke Zuiderwijk. 2012. Benefits, Adoption Barriers and Myths of Open Data and Open Government. Information Systems Management 29: 258–68. [Google Scholar] [CrossRef]
- Janssen, Marijn, Haiko van der Voort, and Agung Wahyudi. 2017. Factors influencing big data decision-making quality. Journal of Business Research 70: 388–45. [Google Scholar] [CrossRef]
- Kim, Gang-Hoon, Silvana Trimi, and Ji-Hyong Chung. 2014. Big-Data Applications in the Government Sector. Communications of the ACM 57: 78–85. [Google Scholar] [CrossRef]
- Kitchin, Rob. 2014. The real-time city? Big data and smart urbanism. GeoJournal 79: 1–14. [Google Scholar] [CrossRef]
- Klievink, Bram, Bart-Jan Romijn, Scott Cunningham, and Hans de Bruijn. 2017. Big data in the public sector: Uncertainties and readiness. Information Systems Frontiers 19: 267–83. [Google Scholar] [CrossRef]
- Koskela, Hille. 2000. ‘The gaze without eyes’: Video-surveillance and the changing nature of urban space. Progress in Human Geography 24: 243–65. [Google Scholar] [CrossRef]
- Lesaffer, Pharmaceutica. 2017. VDAB Wil Surfgedrag van Werklozen Screenen. Gazet van Antwerpen. Available online: www.gva.be/cnt/dmf20170904_03051877/vdab-wil-surfgedrag-van-werklozen-screenen (accessed on 12 January 2018). (In Dutch).
- Liu, Shuhua Monica, and Qianli Yuan. 2015. The Evolution of Information and Communication Technology in Public Administration. Public Administration and Development 35: 140–51. [Google Scholar] [CrossRef]
- Lyon, David. 2014. Situating surveillance: History, Technology, Culture. Histories of State Surveillance in Europe and Beyond. New York: Routledge, pp. 332–46. [Google Scholar]
- McKinsey Global Institute. 2011. Big Data: The Next Frontier for Innovation, Competition and Productivity. New York: McKinsey & Company. [Google Scholar]
- Mergel, Ines, R. Karl Rethemeyer, and Kimberley Isett. 2016. Big data in Public Affairs. Public Administration Review 76: 928–37. [Google Scholar] [CrossRef]
- Munné, Ricard. 2016. Big Data in the Public Sector. In New Horizons for a Data-Driven Economy. New York: Springer International Publishing, pp. 195–208. [Google Scholar]
- O’Neill, Cathy. 2016. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. New York: Crown Publishing Group. [Google Scholar]
- OECD. 2014. Recommendation of the Council on Digital Government Strategies. Available online: www.oecd.org/governance (accessed on 14 January 2018).
- OECD. 2015. Data-Driven Innovation. Big Data for Growth and Well-Being. Paris: OECD Publishing. [Google Scholar]
- Ojo, Adegboyega, Edward Curry, and Fatemeh Ahmadi Zeleti. 2015. A tale of Open Data innovations in five smart cities. Paper presented at the 2015 48th Hawaii International Conference on System Sciences (HICSS), Washington, DC, USA, January 5–8; pp. 2326–35. [Google Scholar]
- Open Knowledge International. 2017. Open Data Handbook. Available online: http://opendatahandbook.org/ (accessed on 17 October 2017).
- Pardo, Theresa A., J. Ramon Gil-Garcia, and G. Brian Burke. 2008. Sustainable Cross-Boundary Information Sharing. In Digital Government. Integrated Series in Information Systems. Boston: Springer, vol. 17. [Google Scholar]
- Rogge, Nicky, Tommaso Agasisti, and Kristof De Witte. 2017. Big data and the measurement of public organizations’ performance and efficiency: The state of the art. Public Policy and Administration 32: 263–81. [Google Scholar] [CrossRef]
- Spiller, Keith. 2016. Experiences of accessing CCTV data: The urban typologies of subject access requests. Urban Studies 53: 2885–900. [Google Scholar] [CrossRef]
- Technopolis Group, Oxford Internet Institute, and Centre for European Policy Studies. 2015. Data for Policy: A Study of Big Data and Other Innovative Data-Driven Approaches for Evidence-Informed Policymaking. Amsterdam: Technopolis Group. [Google Scholar]
- United Nations. 2016. E-Government Survey 2016. E-Government for the Future We Want. New York: United Nations. [Google Scholar]
- Van Cauter, Lies. 2016. Government-to-Government Information System Failure in Flanders: An In-Depth Study. Ph.D. dissertation, Katholieke Universiteit Leuven, Leuven, Belgium. [Google Scholar]
- Van der Sloot, Bart, and Sashavan Schendel. 2016. International and Comparative Legal Study on Big Data. Working Paper 20. The Hague, The Netherlands: The Netherlands Scientific Council for Government Policy (WRR). [Google Scholar]
- Van der Voort, Haiko, and Joep Crompvoets. 2016. Big data: Een zoektocht naar instituties. Bestuurskunde 25: 3–8. (In Dutch). [Google Scholar] [CrossRef]
- Van Dooren, Wouter, Geert Bouckaert, and John Halligan. 2015. Performance Management in the Public Sector Oxon. Abingdon: Routledge. [Google Scholar]
- Van Zoonen, Liesbet. 2016. Privacy concerns in smart cities. Government Information Quarterly 33: 472–80. [Google Scholar] [CrossRef]
- Vickery, Graham. 2011. Review of Recent Studies on PSI Re-Use and Related Market Development. Paris: Information Economics. Available online: https://ec.europa.eu/digital-single-market/en/news/review-recent-studies-psi-reuse-and-related-market-developments (accessed on 17 October 2017).
- VITO. 2017. How Suitable Is Your Roof for the Installation of Solar Panels or a Solar Boiler? See for Yourself on the SOLAR MAP. Available online: https://vito.be/en/media-events/press-releases/how-suitable-is-your-roof-for-the-installation-of-solar-panels-or-a-solar-boiler-see-for-yourself-on-the-solar-map (accessed on 15 February 2018).
- Wamba, Samuel Fosso, Shahriar Akter, Andrew Edwards, Geoffrey Chopin, and Denis Gnanzou. 2015. How ‘Big Data’ Can Make Big Impact: Findings from a Systematic Review and a Longitudinal Case Study. International Journal of Production Economics 165: 234–46. [Google Scholar] [CrossRef]
- Welle Donker, Frederika, and Bastiaan van Loenen. 2016. Sustainable business models for public sector open data providers. JeDEM Journal of eDemocracy & Open Government 8: 28–61. [Google Scholar]
- World Bank. 2017. Big Data in Action for Government: Big Data Innovation in Public Services, Policy, and Engagement (English). Solutions Brief. Washington: World Bank Group, Available online: http://documents.worldbank.org/curated/en/176511491287380986/Big-data-in-action-for-government-big-data-innovation-in-public-services-policy-and-engagement (accessed on 2 May 2018).
- Zotano, Miguel Angel Gomez, and Hugues Bersini. 2017. A data-driven approach to assess the potential of Smart Cities: The case of open data for Brussels Capital Region. Energy Procedia 111: 750–58. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Input | Processing Activities | Output | Case Examples |
|---|---|---|---|---|
| A | Initial data | New activities such as
| Output stays (basically) the same but its use multiplies because of new objectives | Extensive use of license plate data and camera data |
| B | Initial data | New activities such as
| Improved output, better achievement of objectives | New insights for fraud detection (taxation, social security) and assistance for unemployed workers |
| C | A merge of existing output information forms together input information | The merge requires data linking, analytics, visualization etc. to become usable | New sort of output information | Innovative service: the Solar Map |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heijlen, R.; Crompvoets, J.; Bouckaert, G.; Chantillon, M. Evolving Government Information Processes for Service Delivery: Identifying Types & Impact. Adm. Sci. 2018, 8, 15. https://doi.org/10.3390/admsci8020015
Heijlen R, Crompvoets J, Bouckaert G, Chantillon M. Evolving Government Information Processes for Service Delivery: Identifying Types & Impact. Administrative Sciences. 2018; 8(2):15. https://doi.org/10.3390/admsci8020015
Chicago/Turabian StyleHeijlen, Roel, Joep Crompvoets, Geert Bouckaert, and Maxim Chantillon. 2018. "Evolving Government Information Processes for Service Delivery: Identifying Types & Impact" Administrative Sciences 8, no. 2: 15. https://doi.org/10.3390/admsci8020015
APA StyleHeijlen, R., Crompvoets, J., Bouckaert, G., & Chantillon, M. (2018). Evolving Government Information Processes for Service Delivery: Identifying Types & Impact. Administrative Sciences, 8(2), 15. https://doi.org/10.3390/admsci8020015