The Role of Orthotactics in Language Switching: An ERP Investigation Using Masked Language Priming




Abstract
:1. Introduction
2. Experiment 1
2.1. Materials and Methods
2.1.1. Participants
2.1.2. Stimuli
2.1.3. Procedure
2.1.4. Electroencephalogram (EEG) Recording Procedure
2.1.5. Data Analysis
2.2. Results
2.2.1. Behavioral Results
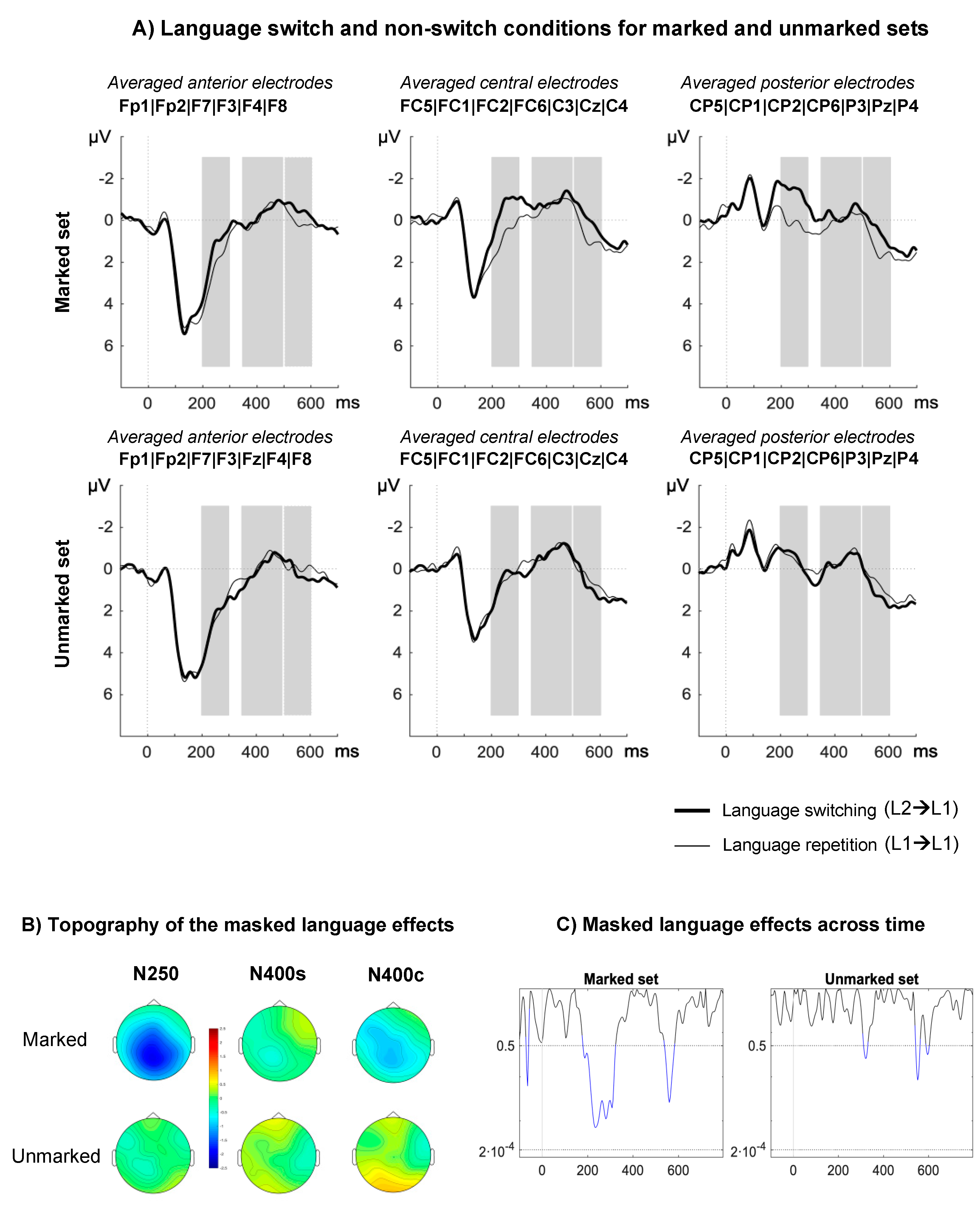
2.2.2. ERPs Results
3. Experiment 2
3.1. Materials and Methods
3.1.1. Participants
3.1.2. Materials
3.2. Results
3.2.1. Behavioral Results
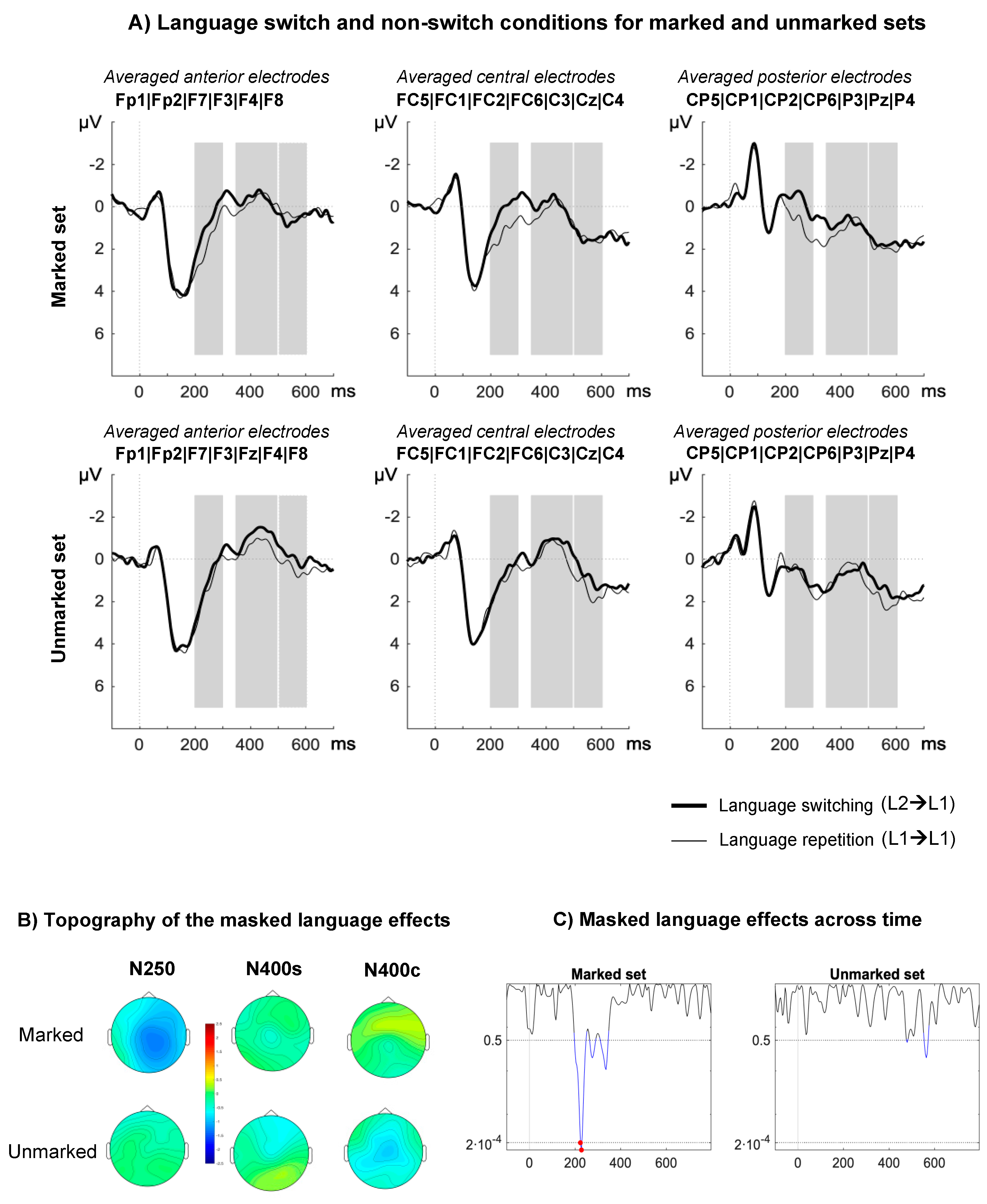
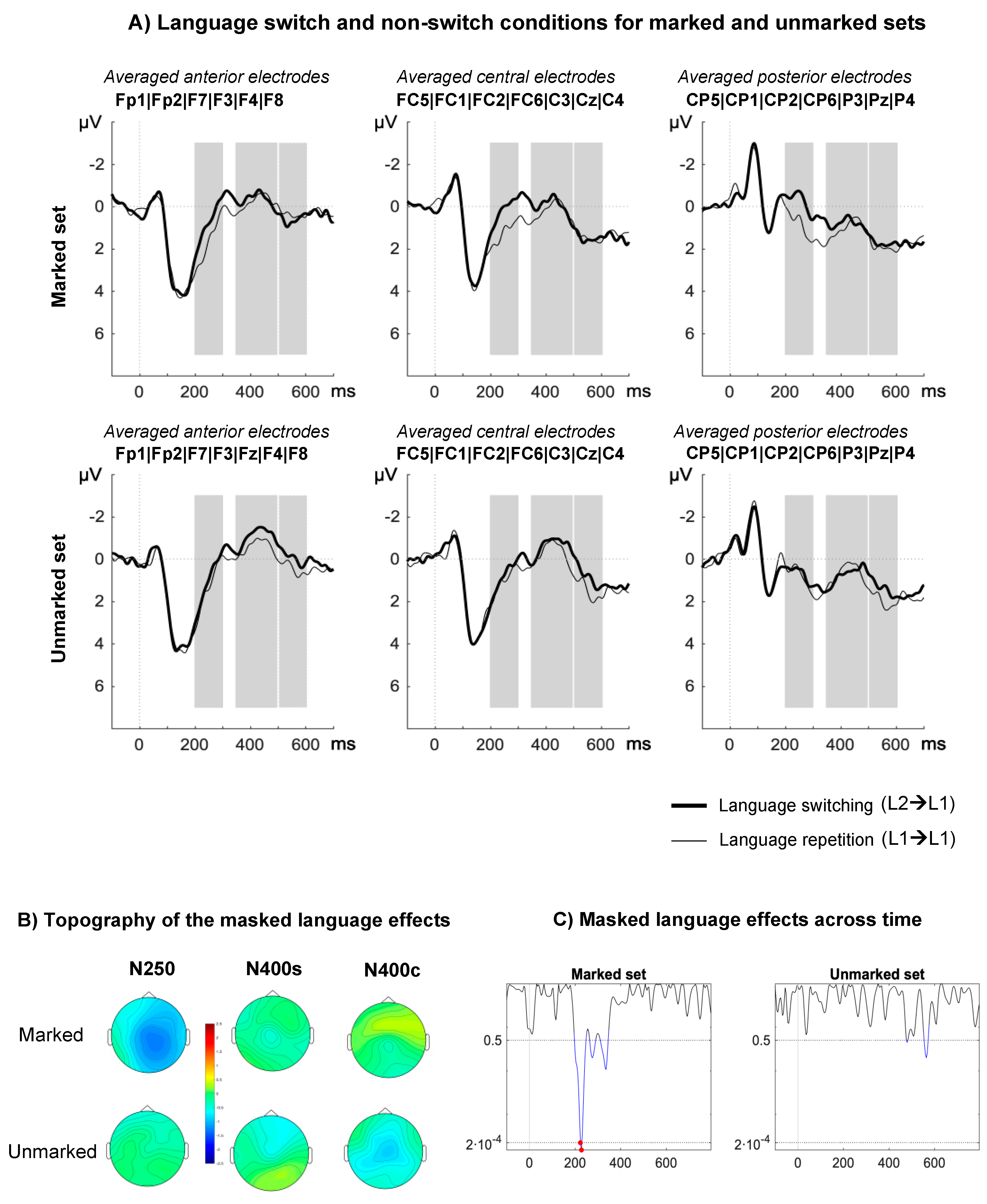
3.2.2. ERP Results
4. Discussion
4.1. Orthotactic, Phonotactic, and Feature Language Nodes
4.2. Sub-Lexical Language Nodes and Lexical Access
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Prime Words | Target Words | ||||
|---|---|---|---|---|---|
| Basque | Spanish | Spanish | |||
| Marked | Unmarked | Marked Controls | Unmarked Controls | Marked Set | Unmarked Set |
| zuku | ahur | jugo | palma | camarero | vuelo |
| hozkada | ontasun | bocado | bondad | salud | quiebra |
| kode | amorru | clave | rabia | suelo | parado |
| nazka | garaipen | asco | triunfo | enfermera | despido |
| txanda | sorgin | turno | bruja | desierto | membrana |
| txano | arrazoi | gorro | motivo | habla | árbol |
| txartel | zaindari | tarjeta | guardián | problema | rigor |
| umetoki | laburpen | útero | resumen | vertiente | cuchillo |
| altxor | aurrerabide | tesoro | progreso | facilidad | convenio |
| beroki | xehetasun | abrigo | detalle | esposa | libertad |
| etsai | apaltasun | enemigo | humildad | jardín | alumno |
| etxola | neurri | cabaña | medida | pito | hijo |
| hauts | barealdi | polvo | calma | blasfemia | sequía |
| irrits | sudur | pasión | nariz | cabo | oscuridad |
| jainko | mingostasun | dios | amargura | candidato | excusa |
| kopeta | igorle | frente | emisor | ganador | prudencia |
| kotoi | erdi | algodón | mitad | aula | energía |
| ostiko | itun | patada | alianza | difusión | vuelta |
| sukar | kirol | fiebre | deporte | hito | asesinato |
| txoko | isiltasun | rincón | silencio | vara | venganza |
| akats | gezur | defecto | mentira | concejal | intestino |
| amets | ipurdi | fantasía | culo | saludo | altura |
| arratsalde | zabaltasun | tarde | amplitud | sombrero | idiota |
| atsegin | jauzi | deleite | salto | huella | principio |
| atsekabe | egile | pesar | autor | infancia | enseñanza |
| aukera | orrialde | opción | página | muchacho | umbral |
| aurrezki | zuritasun | ahorro | blancura | abuela | rueda |
| azoka | ondorengo | mercado | sucesor | prometida | validez |
| batuketa | hezur | suma | hueso | sabiduría | consejo |
| begiratoki | zorabio | mirador | mareo | nieto | portavoz |
| erruki | apar | piedad | espuma | origen | población |
| gonbidatu | hiriburu | invitado | capital | garganta | empuje |
| kontu | gorespen | cautela | exaltación | modelo | anillo |
| lanbro | onura | bruma | beneficio | sanción | reino |
| lokarri | iruzur | cordón | engaño | expresión | gestión |
| lokatz | masail | barro | mejilla | entrada | volcán |
| norako | eramaile | destino | portador | hermana | taller |
| oinordeko | nortasun | heredero | personalidad | odio | semana |
| txanpon | gelditasun | moneda | quietud | camisa | labio |
| txantxa | iturri | broma | fuente | afición | duda |
| txerto | abantaila | vacuna | ventaja | suciedad | discusión |
| txosten | jostailu | informe | juguete | suspiro | olor |
| ukimen | bidaia | tacto | viaje | conocedor | abandono |
| aldizkari | arautegi | revista | normativa | frialdad | mina |
| atseden | atari | descanso | portal | panorama | yema |
| bizkar | errai | espalda | entraña | luna | pesadilla |
| burrunba | gerri | zumbido | cintura | mercancía | palacio |
| errauts | zurruntasun | ceniza | rigidez | madera | fila |
| euritako | gidari | paraguas | conductor | acción | municipio |
| gerriko | batasun | cinturón | unidad | saber | formación |
| gonbidapen | negu | invitación | invierno | oreja | comisión |
| hildako | etenaldi | fallecido | pausa | estación | denuncia |
| hizketa | leuntasun | discurso | suavidad | lago | rabo |
| idazkari | garbitasun | secretario | limpieza | mimbre | asomo |
| itsasalde | oihal | costa | tela | registro | palabra |
| itxura | osagarri | aspecto | complemento | mediodía | ocio |
| jokabide | berezitasun | proceder | singularidad | margen | fibra |
| kokapen | egiatasun | ubicación | veracidad | longitud | tema |
| konketa | atezain | lavabo | portero | reproche | fuerza |
| kontalari | argibide | narrador | explicación | pecho | dicha |
| kopuru | trebetasun | cuantía | habilidad | mierda | rival |
| korapilo | erraldoi | nudo | gigante | terremoto | tapa |
| mutiko | aberastasun | chiquillo | riqueza | variante | censo |
| ordezkari | berdintasun | delegado | igualdad | compasión | serie |
| ordoki | gozotasun | llanura | dulzura | costumbre | chica |
| otsail | argitalpen | febrero | edición | hambre | carga |
| sukalde | ezaguera | cocina | conocimiento | carbón | burla |
| txapelketa | ahultasun | campeonato | debilidad | conexión | cara |
| txistu | erru | silbido | culpa | lentitud | explosión |
| zenbateko | amildegi | importe | abismo | traductor | velocidad |
| bukaera | osotasun | desenlace | plenitud | aguja | educación |
| danbada | ibilbide | estruendo | trayecto | regazo | promoción |
| edukiera | zailtasun | capacidad | dificultad | vencedor | aversión |
| edukitze | salbuespen | posesión | excepción | dedo | vigilante |
| ekoizpen | ezintasun | producción | impotencia | carrera | sillón |
| erauzketa | ibilaldi | extracción | excursión | nido | osadía |
| etsipen | suziri | resignación | cohete | liderazgo | quehacer |
| ezkongai | lasaitasun | soltero | tranquilidad | aparición | hierba |
| gainbehera | epai | decadencia | veredicto | toma | mando |
| hizketaldi | ondoez | tertulia | malestar | parada | instinto |
| hizkuntza | gogortasun | lenguaje | dureza | medición | enero |
| ikastetxe | gertaera | colegio | suceso | lista | duración |
| iragazki | ahalegin | filtro | esfuerzo | pantalón | invención |
| itxaropen | iragarpen | esperanza | anuncio | cerebro | peregrino |
| jokaera | aditu | actuación | experto | violencia | mesa |
| kokots | auzitegi | barbilla | tribunal | orina | espina |
| konponbide | ateraldi | solución | ocurrencia | ombligo | maraña |
| korridore | arintasun | pasillo | ligereza | molino | entorno |
| kutxatila | handitasun | estuche | grandeza | edad | hilo |
| lotsa | epaitegi | vergüenza | juzgado | piel | necesidad |
| marrazki | betebehar | dibujo | obligación | sacudida | permiso |
| ordezko | nerabezaro | sustituto | adolescencia | canal | travesía |
| sukaldari | goraipamen | cocinero | elogio | apoyo | vendedor |
| txilin | jazarpen | campanilla | persecución | porqué | sudor |
| aukeraketa | nagusitasun | selección | superioridad | desafío | avenida |
| baliokide | hurbiltasun | equivalente | cercanía | prioridad | obstáculo |
| bereizketa | duintasun | separación | dignidad | muerte | manzana |
| bitxilore | lapurreta | margarita | robo | talla | apellido |
| ehuneko | ezgaitasun | porcentaje | incapacidad | vientre | maldad |
| etxebizitza | egonezin | vivienda | inquietud | veneno | hallazgo |
| ezkontza | urruntasun | matrimonio | lejanía | juego | pastor |
| ezkortasun | urduritasun | pesimismo | nerviosismo | costado | sala |
| gatazka | begirune | conflicto | respeto | asiento | semanario |
| harrokeria | hondamen | vanidad | ruina | bullicio | carnaval |
| hiruhileko | jarraipen | trimestre | continuación | muralla | comarca |
| iruzkin | irudi | comentario | imagen | sobrino | vapor |
| itsustasun | urteurren | fealdad | aniversario | calor | zona |
| jainkotasun | ipuin | divinidad | cuento | propiedad | accidente |
| jatetxe | jarraitasun | restaurante | continuidad | compañía | cortina |
| matxinada | emari | rebelión | caudal | sorpresa | poeta |
| orrazketa | ipar | peinado | norte | llave | falda |
| truke | neurritasun | intercambio | moderación | guante | confesor |
| aurrekontu | afari | presupuesto | cena | hombro | obispo |
| bizkortasun | ugaritasun | agilidad | abundancia | cerco | bolsillo |
| hautsontzi | bateratasun | cenicero | convergencia | jaula | cliente |
| iradokizun | ezabapen | sugerencia | eliminación | corredor | desayuno |
| konponketa | argitasun | arreglo | claridad | caricia | inventor |
| ordezkapen | heldutasun | sustitución | madurez | amante | susto |
| sakontasun | orga | profundidad | carro | salida | viento |
| suntsidura | zubi | destrucción | puente | recurso | lectura |
| bitartekotza | hilobi | mediación | tumba | retraso | sede |
| elkarrizketa | isuri | conversación | flujo | colección | gana |
| bazkalondo | elur | sobremesa | nieve | occidente | huida |
| hots | beldur | ruido | miedo | mención | alba |
| isats | auzi | cola | pleito | huerto | locura |
| lekuko | izate | testigo | ente | baile | extensión |
| bazkide | gauerdi | socio | medianoche | cuna | lana |
| ezkor | zati | pesimista | pedazo | recuerdo | hielo |
| kezka | euri | preocupación | lluvia | lector | examen |
| konkor | mihi | bulto | lengua | mezcla | subida |
| soka | aldi | cuerda | temporada | opresión | cuero |
| borroka | goiburu | pelea | lema | ramo | cerveza |
| txinparta | beira | chispa | vidrio | cosecha | juez |
| barrunbe | zauri | cavidad | herida | escucha | plomo |
| zoritxar | zoru | desdicha | piso | camino | helada |
| bizkarralde | orri | respaldo | hoja | carta | llamada |
| hozkailu | ostegun | nevera | jueves | lunes | nuca |
| lanbide | argizari | profesión | cera | caza | amigo |
| zaldizko | apaiz | jinete | cura | deseo | saliva |
| herrixka | sabai | aldea | techo | posada | sonrisa |
| Prime Words | Target Words | ||||
|---|---|---|---|---|---|
| English | Spanish | Spanish | |||
| Marked | Unmarked | Marked Controls | Unmarked Controls | Marked Set | Unmarked Set |
| cassock | exhausting | sotana | agotador | sabio | jersey |
| knock | exchange | golpe | intercambio | bendito | oreja |
| holy | umbrella | santo | paraguas | potente | piso |
| lawyer | milestone | abogado | hito | verdadero | pantalón |
| assembly | flax | montaje | lino | arma | invierno |
| fodder | plentiful | pienso | abundante | zona | marrón |
| rubber | shirt | caucho | camisa | ritmo | diente |
| black | dumb | negro | mudo | espina | triunfo |
| mockery | storm | burla | tormenta | salud | ceniza |
| stick | prominence | vara | protagonismo | pandilla | receta |
| dirty | damaging | sucio | perjudicial | salvaje | mojado |
| track | recipient | camino | receptor | cirugía | ángulo |
| term | pupil | plazo | alumno | fusil | esperanza |
| length | magazine | duración | revista | áspero | guerra |
| kick | chapel | patada | capilla | tronco | pedazo |
| gully | receptacle | barranco | recipiente | fundador | humedad |
| nephew | qualified | sobrino | titulado | espacial | regla |
| footprint | freedom | huella | libertad | canto | fiebre |
| sworn | disabled | jurado | impedido | casualidad | lanza |
| knee | forecast | rodilla | previsión | vivienda | tarifa |
| madness | prayer | locura | oración | espalda | juventud |
| knot | limit | nudo | tope | medición | minucioso |
| kindness | chain | amabilidad | cadena | yate | jugo |
| fiancée | exit | prometida | salida | bocado | gracioso |
| enjoyment | unchanging | disfrute | inmutable | agosto | marzo |
| sweetness | shivering | dulzura | temblor | fraile | susto |
| address | government | domicilio | gobierno | prado | lana |
| coldness | foam | frialdad | espuma | marinero | herrero |
| racket | cheap | bullicio | barato | mejilla | blancura |
| happy | unexpected | feliz | inesperado | punta | lector |
| dawn | uprising | alba | revuelta | extranjero | muslo |
| proximity | stream | cercanía | arroyo | siglo | multa |
| darkness | shit | oscuridad | mierda | enfermera | campesino |
| smuggling | chest | contrabando | pecho | martillo | bailarín |
| upward | lip | ascendente | labio | busca | congreso |
| privacy | moon | intimidad | luna | lamentable | creencia |
| safety | surname | seguridad | apellido | disco | sombra |
| knowledge | lid | saber | tapa | sueldo | cuento |
| threshold | beard | umbral | barba | vencedor | cocina |
| breakfast | school | desayuno | escuela | afortunado | pito |
| sudden | pregnant | repentino | embarazada | conyugal | campana |
| happiness | beginning | dicha | principio | romero | regazo |
| opposite | star | contrario | astro | mayo | pelea |
| thickness | raincoat | espesor | gabardina | mando | hueso |
| everyday | disgust | cotidiano | asco | cabal | lejanía |
| newspaper | treatment | periódico | curación | expediente | suavidad |
| tiredness | church | cansancio | iglesia | paliza | suelo |
| weakness | mixing | debilidad | mezcla | infierno | nieve |
| pregnancy | airport | embarazo | aeropuerto | gripe | cuero |
| barracks | subject | cuartel | asignatura | pequeño | gorro |
| notebook | deaf | cuaderno | sordo | cima | fantasma |
| backside | slope | culo | cuesta | osadía | usuario |
| sickness | unit | mareo | unidad | chica | sorbo |
| knife | bedroom | cuchillo | dormitorio | cerveza | juzgado |
| shepherd | harvest | pastor | cosecha | prometido | miedo |
| strength | speech | fuerza | habla | auto | cerro |
| spring | bolsillo | fuente | escopeta | odio | |
| width | stairs | amplitud | escalera | precio | ancho |
| guilty | hip | culpable | cadera | trimestre | compuesto |
| checking | painful | revisión | doloroso | semejante | grande |
| lively | bishop | animado | obispo | sonoro | sacudida |
| threat | salesman | amenaza | vendedor | asesinato | ducha |
| apple | edict | manzana | bando | retrete | tela |
| news | lieutenant | noticia | teniente | crepúsculo | vela |
| weekly | fishing | semanal | pesca | voluntad | trago |
| rubbing | discharge | roce | alta | tabla | chorro |
| navy | ice | armada | hielo | ficha | semana |
| sword | event | espada | suceso | alquiler | carga |
| thread | fixed | hilo | fijo | bloqueo | hallazgo |
| neck | liqueur | cuello | licor | ternura | fundamento |
| ribbon | smell | cinta | olor | parcela | campamento |
| wicker | challenge | mimbre | desafío | venta | heredero |
| mercy | gum | piedad | goma | lavabo | costado |
| cradle | profit | cuna | beneficio | tesoro | edad |
| throwing | baroque | lanzamiento | barroco | lujo | poesía |
| lack | shortage | falta | escasez | hermano | huevo |
| clock | alleged | reloj | presunto | palabra | carbón |
| raw | oven | crudo | horno | estanque | millar |
| sweat | street | sudor | calle | concejal | gitano |
| joke | rostrum | broma | tribuna | baloncesto | mercado |
| atrocity | leadership | barbaridad | liderazgo | pueblo | viuda |
| ability | signature | capacidad | firma | flujo | suciedad |
| deity | stone | divinidad | piedra | maldito | cambio |
| pity | disgusting | pena | repugnante | toalla | comercio |
| neckline | slogan | escote | consigna | siguiente | izquierda |
| brick | changeable | ladrillo | cambiante | tercio | acta |
| lazy | spot | vago | mancha | ayudante | esquema |
| goodness | drum | bondad | tambor | desviación | puerto |
| cook | portrait | cocinero | retrato | ventana | pastel |
| hardness | homeland | dureza | patria | último | veloz |
| official | frost | funcionario | helada | reportaje | recurso |
| poverty | advisable | miseria | recomendable | grado | llave |
| quality | glove | calidad | guante | útil | quehacer |
| beauty | sloping | belleza | inclinado | ladrón | portador |
| payment | brain | pago | cerebro | mensajero | sierra |
| similarity | deceased | semejanza | fallecido | ahorro | cirujano |
| appearance | heart | aspecto | corazón | lectura | fiesta |
| bucket | exhibition | balde | exposición | necesidad | camarero |
| sphere | beach | esfera | playa | comarca | edición |
| ally | husband | aliado | marido | decadencia | orgulloso |
| spying | jump | espionaje | salto | limpio | teoría |
| heavy | fleet | pesado | flota | boca | susurro |
| attack | building | ataque | edificio | blando | bruja |
| daily | onion | diario | cebolla | codo | tarde |
| rocket | chin | cohete | barbilla | bienvenida | decorado |
| effective | leaf | eficaz | hoja | equilibrio | molestia |
| writing | developing | escritura | revelado | margarita | barro |
| throw | stop | tirada | parada | incapaz | cierre |
| midday | advantage | mediodía | ventaja | puente | corredor |
| effort | iron | esfuerzo | hierro | terremoto | invitado |
| throat | smile | garganta | sonrisa | compromiso | enseñanza |
| honesty | invoice | honradez | factura | rueda | raza |
| equality | depraved | igualdad | vicioso | actual | banda |
| mummy | misfortune | momia | desdicha | breve | amante |
| telephone | stable | telefónica | cuadra | resumen | laberinto |
| approval | rug | aprobación | alfombra | sospechoso | occidente |
| suggestion | agreement | sugerencia | acuerdo | jinete | tema |
| package | debt | paquete | deuda | dama | tertulia |
| loyalty | coin | lealtad | moneda | nube | sombrero |
| robbery | freezing | robo | helado | cueva | aceite |
| certainty | uterus | certeza | útero | copa | caza |
| suffering | unemployed | sufrimiento | parado | motivo | vuelo |
| physiology | doorman | fisiología | portero | suspiro | mitad |
| myth | acceptance | mito | aceptación | aficionado | cinturón |
| symmetry | abrupt | simetría | brusco | occidental | vuelta |
| emphasis | player | énfasis | jugador | habitual | diversión |
| pharmacy | fault | farmacia | culpa | éxito | nido |
| copper | slim | cobre | delgado | taza | canción |
| nobility | pilgrim | nobleza | peregrino | seco | carta |
| block | screen | bloque | pantalla | silla | ético |
| deputy | scales | diputado | balanza | reglamento | pesar |
| offer | activist | oferta | militante | velocidad | jugada |
| writer | excitement | escritor | excitación | nacimiento | ligero |
| needle | shelter | aguja | cobijo | comentario | ateo |
| birthday | unloading | cumpleaños | descarga | maraña | bruma |
| drawing | roof | dibujo | techo | molino | gratuita |
| doubtful | errand | dudoso | recado | carretera | ligereza |
| support | dancing | apoyo | baile | habilidad | recto |
| midnight | amazing | medianoche | asombroso | plomo | sequía |
| unbearable | horn | insoportable | cuerno | maternidad | gramática |
| workshop | management | taller | gestión | carcajada | anillo |
| clumsy | goal | torpe | meta | desgaste | cerradura |
| armchair | blood | sillón | sangre | llamada | principal |
| unhappy | stamp | desdichado | sello | oriental | comandante |
| discomfort | lung | malestar | pulmón | calvo | asamblea |
| viewpoint | forehead | mirador | frente | apertura | altura |
| stiffness | retirement | rigidez | jubilación | pierna | pila |
| alms | educated | limosna | culto | pesadilla | sindical |
| cardboard | stage | cartón | fase | trato | boina |
| hierarchy | square | jerarquía | plaza | yema | negocio |
| philosophy | orchard | filosofía | huerto | temblorosa | autobús |
| abyss | cheese | abismo | queso | ente | informe |
References
- Van Assche, E.; Duyck, W.; Hartsuiker, R.J.; Diependaele, K. Does bilingualism change native-language reading? Cognate effects in a sentence context. Psychol. Sci. 2009, 20, 923–927. [Google Scholar] [CrossRef]
- Van Hell, J.G.; Dijkstra, T. Foreign language knowledge can influence native language performance in exclusively native contexts. Psychon. Bull. Rev. 2002, 9, 780–789. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Heuven, W.J.; Schriefers, H.; Dijkstra, T.; Hagoort, P. Language conflict in the bilingual brain. Cereb. Cortex 2008, 18, 2706–2716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dijkstra, T.; Van Heuven, W.J. The architecture of the bilingual word recognition system: From identification to decision. Biling. Lang. Cogn. 2002, 5, 175–197. [Google Scholar] [CrossRef] [Green Version]
- Dijkstra, T.; Timmermans, M.; Schriefers, H. On being blinded by your other language: effects of task demands on interlingual homograph recognition. J. Mem. Lang. 2000, 42, 445–464. [Google Scholar] [CrossRef]
- Zhang, T.; Van Heuven, W.J.B.; Conklin, K. Fast Automatic translation and morphological decomposition in Chinese-English bilinguals. Psychol. Sci. 2011, 22, 1237–1242. [Google Scholar] [CrossRef]
- Van Heuven, W.J.; Dijkstra, T.; Grainger, J. Orthographic neighborhood effects in bilingual word recognition. J. Mem. Lang. 1998, 39, 458–483. [Google Scholar] [CrossRef] [Green Version]
- Grossi, G.; Savill, N.; Thomas, E.; Thierry, G. Electrophysiological cross-language neighborhood density effects in late and early English-Welsh bilinguals. Front. Psychol. 2012, 3, 408. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, A.I.; Kroll, J.F.; Diaz, M. Reading words in Spanish and English: Mapping orthography to phonology in two languages. Lang. Cogn. Process. 2007, 22, 106–129. [Google Scholar] [CrossRef]
- Midgley, K.J.; Holcomb, P.J.; Vanheuven, W.J.; Grainger, J. An electrophysiological investigation of cross-language effects of orthographic neighborhood. Brain Res. 2008, 1246, 123–135. [Google Scholar] [CrossRef] [Green Version]
- Midgley, K.J.; Holcomb, P.J.; Grainger, J. Masked repetition and translation priming in second language learners: a window on the time-course of form and meaning activation using erps. Psychophysiol. 2009, 46, 551–565. [Google Scholar] [CrossRef] [Green Version]
- Meade, G.; Midgley, K.J.; Dijkstra, T.; Holcomb, P.J. Cross-language neighborhood effects in learners indicative of an integrated lexicon. J. Cogn. Neurosci. 2018, 30, 70–85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thierry, G.; Wu, Y.J. Electrophysiological evidence for language interference in late bilinguals. NeuroReport 2004, 15, 1555–1558. [Google Scholar] [CrossRef] [PubMed]
- Dimitropoulou, M.; Duñabeitia, J.A.; Carreiras, M. Masked translation priming effects with low proficient bilinguals. Mem. Cognit. 2011, 39, 260–275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thierry, G.; Wu, Y.J. Brain potentials reveal unconscious translation during foreign-language comprehension. Proc. Natl. Acad. Sci. USA 2007, 104, 12530–12535. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duyck, W.; Van Assche, E.; Drieghe, D.; Hartsuiker, R.J. Visual word recognition by bilinguals in a sentence context: Evidence for nonselective lexical access. J. Exp. Psychol. Learn. Mem. Cogn. 2007, 33, 663–679. [Google Scholar] [CrossRef] [Green Version]
- Duyck, W.; Warlop, N. Translation priming between the native language and a second language: new evidence from Dutch-French bilinguals. Exp. Psychol. 2009, 56, 173–179. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.J.; Thierry, G. Chinese–English Bilinguals Reading English Hear Chinese. J. Neurosci. 2010, 30, 7646–7651. [Google Scholar] [CrossRef]
- Hoshino, N.; Thierry, G. Language selection in bilingual word production: Electrophysiological evidence for cross-language competition. Brain Res. 2011, 1371, 100–109. [Google Scholar] [CrossRef]
- Dimitropoulou, M.; Duñabeitia, J.A.; Carreiras, M. Two Words, One meaning: Evidence of automatic co-activation of translation equivalents. Front. Psychol. 2011, 2, 188. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.J.; Cristino, F.; Leek, C.; Thierry, G. Non-selective lexical access in bilinguals is spontaneous and independent of input monitoring: Evidence from eye tracking. Cogn. 2013, 129, 418–425. [Google Scholar] [CrossRef] [PubMed]
- Spalek, K.; Hoshino, N.; Wu, Y.J.; Damian, M.; Thierry, G. Speaking two languages at once: Unconscious native word form access in second language production. Cogn. 2014, 133, 226–231. [Google Scholar] [CrossRef] [PubMed]
- Ng, S.; Wicha, N.Y.Y. Meaning first: a case for language-independent access to word meaning in the bilingual brain. Neuropsychol. 2013, 51, 850–863. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perea, M.; Duñabeitia, J.A.; Carreiras, M. Masked associative/semantic priming effects across languages with highly proficient bilinguals. J. Mem. Lang. 2008, 58, 916–930. [Google Scholar] [CrossRef]
- Chauncey, K.; Grainger, J.; Holcomb, P.J. Code-switching effects in bilingual word recognition: a masked priming study with event-related potentials. Brain Lang. 2008, 105, 161–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chauncey, K.; Grainger, J.; Holcomb, P.J. The role of subjective frequency in language switching: An ERP investigation using masked priming. Mem. Cogniti. 2011, 39, 291–303. [Google Scholar] [CrossRef] [Green Version]
- Dijkstra, T.; Grainger, J.; Van Heuven, W.J. Recognition of Cognates and Interlingual Homographs: The Neglected Role of Phonology. J. Mem. Lang. 1999, 41, 496–518. [Google Scholar] [CrossRef] [Green Version]
- Midgley, K.J.; Holcomb, P.J.; Grainger, J. Language effects in second language learners and proficient bilinguals investigated with event-related potentials. J. Neurolinguistics 2009, 22, 281–300. [Google Scholar] [CrossRef] [Green Version]
- Von Studnitz, R.E.; Green, D.W. Interlingual homograph interference in German–English bilinguals: Its modulation and locus of control. Biling. Lang. Cogn. 2002, 5, 1–23. [Google Scholar] [CrossRef]
- Dijkstra, T.; Van Heuven, W.J.; Grainger, J. Simulating cross-language competition with the bilingual interactive activation model. Psycholog. Belg. 1998, 38, 177–196. [Google Scholar]
- Van Kesteren, R.; Dijkstra, T.; De Smedt, K. Markedness effects in Norwegian–English bilinguals: Task-dependent use of language-specific letters and bigrams. Q. J. Exp. Psychol. 2012, 65, 2129–2154. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Fornells, A.; Rotte, M.; Heinze, H.-J.; Nösselt, T.; Münte, T.F. Brain potential and functional MRI evidence for how to handle two languages with one brain. Nat. 2002, 415, 1026–1029. [Google Scholar] [CrossRef] [PubMed]
- Casaponsa, A.; Duñabeitia, J.A. Lexical organization of language-ambiguous and language-specific words in bilinguals. Q. J. Exp. Psychol. 2016, 69, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Casaponsa, A.; Carreiras, M.; Duñabeitia, J.A. Discriminating languages in bilingual contexts: the impact of orthographic markedness. Front. Psychol. 2014, 5, 424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Casaponsa, A.; Carreiras, M.; Duñabeitia, J.A. How do bilinguals identify the language of the words they read? Brain Res. 2015, 1624, 153–166. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.J.; Thierry, G. How reading in a second language protects your heart. J. Neurosci. 2012, 32, 6485–6489. [Google Scholar] [CrossRef] [Green Version]
- Oganian, Y.; Conrad, M.; Aryani, A.; Heekeren, H.R.; Spalek, K. Interplay of bigram frequency and orthographic neighborhood statistics in language membership decision. Biling. Lang. Cogn. 2015, 19, 578–596. [Google Scholar] [CrossRef] [Green Version]
- Dubey, N.; Witzel, N.; Witzel, J. Script differences and masked translation priming: Evidence from Hindi-English bilinguals. Q. J. Exp. Psychol. 2018, 71, 2421–2438. [Google Scholar] [CrossRef]
- Grainger, J.; Holcomb, P.J. Watching the word go by: On the time-course of component processes in visual word recognition. Lang. Linguistics Compass 2009, 3, 128–156. [Google Scholar] [CrossRef] [Green Version]
- Vaid, J.; Frenck-Mestre, C. Do orthographic cues aid language recognition? A laterality study with French-English bilinguals. Brain Lang. 2002, 82, 47–53. [Google Scholar] [CrossRef]
- Lemhöfer, K.; Koester, D.; Schreuder, R. When bicycle pump is harder to read than bicycle bell: effects of parsing cues in first and second language compound reading. Psychon. Bull. Rev. 2011, 18, 364–370. [Google Scholar] [CrossRef] [Green Version]
- Grainger, J.; Beauvillain, C. Language blocking and lexical access in bilinguals. Q. J. Exp. Psychol. Sect. A 1987, 39, 295–319. [Google Scholar] [CrossRef]
- Orfanidou, E.; Sumner, P. Language switching and the effects of orthographic specificity and response repetition. Mem. Cogn. 2005, 33, 355–369. [Google Scholar] [CrossRef]
- Gonzales, K.; Lotto, A.J. A bafri, un pafri: Bilinguals’ pseudoword identifications support language-specific phonetic systems. Psychol. Sci. 2013, 24, 2135–2142. [Google Scholar] [CrossRef]
- Ju, M.; Luce, P.A.; Hugenberg, K.; Bodenhausen, G.V. Falling on sensitive ears. Constraints on bilingual lexical activation. Psychol. Sci. 2004, 15, 314–318. [Google Scholar] [CrossRef]
- Davis, C.J.; Perea, M. BuscaPalabras: A program for deriving orthographic and phonological neighborhood statistics and other psycholinguistic indices in Spanish. Behav. Res. Methods 2005, 37, 665–671. [Google Scholar] [CrossRef] [Green Version]
- Perea, M.; Urkia, M.; Davis, C.J.; Agirre, A.; Laseka, E.; Carreiras, M. E-Hitz: A word frequency list and a program for deriving psycholinguistic statistics in an agglutinative language (Basque). Behav. Res. Methods 2006, 38, 610–615. [Google Scholar] [CrossRef] [Green Version]
- Holcomb, P.J.; Grainger, J. Exploring the temporal dynamics of visual word recognition in the masked repetition priming paradigm using event-related potentials. Brain Res. 2007, 1180, 39–58. [Google Scholar] [CrossRef] [Green Version]
- Hoshino, N.; Midgley, K.J.; Holcomb, P.J.; Grainger, J. An ERP investigation of masked cross-script translation priming. Brain Res. 2010, 1344, 159–172. [Google Scholar] [CrossRef] [Green Version]
- Duñabeitia, J.A.; Dimitropoulou, M.; Uribe-Etxebarria, O.; Laka, I.; Carreiras, M. Electrophysiological correlates of the masked translation priming effect with highly proficient simultaneous bilinguals. Brain Res. 2010, 1359, 142–154. [Google Scholar] [CrossRef]
- Greenhouse, S.W.; Geisser, S. On methods in the analysis of profile data. Psychom. 1959, 24, 95–112. [Google Scholar] [CrossRef]
- Cohen, J. Eta-Squared and Partial Eta-Squared in Fixed Factor Anova Designs. Educ. Psychol. Meas. 1973, 33, 107–112. [Google Scholar] [CrossRef]
- Haase, R.F. Classical and partial eta square in multifactor ANOVA Designs. Educ. Psychol. Meas. 1983, 43, 35–39. [Google Scholar] [CrossRef]
- Davis, C.J. N-Watch: A program for deriving neighborhood size and other psycholinguistic statistics. Behav. Res. Methods 2005, 37, 65–70. [Google Scholar] [CrossRef] [PubMed]
- Hoversten, L.J.; Brothers, T.; Swaab, T.Y.; Traxler, M.J. Early processing of orthographic language membership information in bilingual visual word recognition: Evidence from ERPs. Neuropsychol. 2017, 103, 183–190. [Google Scholar] [CrossRef] [PubMed]


| Language Proficiency | Spanish | Basque |
|---|---|---|
| Speaking | 9.78 (0.43) | 7.88 (1.36) |
| Understand | 9.78 (0.43) | 8.50 (1.20) |
| Writing | 9.78 (0.54) | 7.22 (1.53) |
| Reading | 9.83 (0.38) | 8.50 (1.24) |
| General self-perception | 9.61 (0.61) | 7.66 (0.97) |
| Prime Words | Target Words | |||||
|---|---|---|---|---|---|---|
| Basque | Spanish | Spanish | ||||
| Marked | Unmarked | Marked Control | Unmarked Control | Marked | Unmarked | |
| Word frequency | 36.50 (74.78) | 33.91 (58.77) | 28.53 (36.29) | 29.87 (30.47) | 41.14 (47.53) | 38.66 (44.66) |
| Word length | 7.55 (1.86) | 7.37 (2.22) | 7.46 (1.91) | 7.30 (2.17) | 6.66 (1.62) | 6.45 (1.69) |
| Number of orthographic neighbors | 1.02 (1.77) | 1.26 (2.08) | 1.35 (2.52) | 1.68 (3.27) | 2.42 (4.00) | 2.53 (3.94) |
| Age of acquisition | 3.27 (0.47) | 3.24 (0.50) | 3.17 (0.53) | 3.16 (0.56) | 3.12 (0.57) | 3.09 (0.60) |
| Word concreteness | 4.08 (0.83) | 3.99 (0.86) | 4.01 (0.85) | 3.94 (0.94) | 4.05 (0.86) | 4.06 (0.91) |
| Spanish bigram frequency | 1.30 “ (0.44) | 1.31 “ (0.43) | 2.52 (0.29) | 2.49 (0.29) | ||
| Basque bigram frequency | 2.06 (0.27) | 2.04 (0.24) | ||||
| Number of Spanish-implausible bigrams | 1.16 * (0.45) | 0 (0) | ||||
| Language Proficiency | Spanish | English |
|---|---|---|
| Speaking | 9.78 (0.55) | 7.33 (1.08) |
| Understand | 9.83 (0.38) | 7.89 (0.96) |
| Writing | 9.56 (0.70) | 7.44 (0.92) |
| Reading | 10 (0.00) | 8.06 (1.25) |
| General self-perception | 9.83 (0.38) | 7.82 (0.88) |
| Prime Words | Target Words | |||||
|---|---|---|---|---|---|---|
| English | Spanish | Spanish | ||||
| Marked | Unmarked | Marked Control | Unmarked Control | Marked | Unmarked | |
| Word frequency | 33.98 (41.81) | 41.70 (60.37) | 29.68 (38.19) | 34.80 (49.48) | 41.01 (33.04) | 41.72 (33.36) |
| Word length | 6.75 (1.73) | 6.52 (2.04) | 6.99 (1.83) | 6.80 (1.84) | 6.90 (1.91) | 6.41 (1.57) |
| Number of orthographic neighbors | 1.66 (2.69) | 1.99 (3.15) | 1.95 (3.39) | 2.39 (3.46) | 2.17 (3.34) | 2.63 (3.91) |
| Spanish bigram frequency | 1.30 “ (0.52) | 1.38 “ (0.47) | 2.50 (0.30) | 2.54 (0.31) | 2.51 (0.33) | 2.55 (0.33) |
| English bigram frequency | 2.52 (0.36) | 2.55 (0.39 | ||||
| Number of Spanish-implausible bigrams | 1.11 * (0.39) | 0 (0) | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casaponsa, A.; Thierry, G.; Duñabeitia, J.A. The Role of Orthotactics in Language Switching: An ERP Investigation Using Masked Language Priming. Brain Sci. 2020, 10, 22. https://doi.org/10.3390/brainsci10010022
Casaponsa A, Thierry G, Duñabeitia JA. The Role of Orthotactics in Language Switching: An ERP Investigation Using Masked Language Priming. Brain Sciences. 2020; 10(1):22. https://doi.org/10.3390/brainsci10010022
Chicago/Turabian StyleCasaponsa, Aina, Guillaume Thierry, and Jon Andoni Duñabeitia. 2020. "The Role of Orthotactics in Language Switching: An ERP Investigation Using Masked Language Priming" Brain Sciences 10, no. 1: 22. https://doi.org/10.3390/brainsci10010022
APA StyleCasaponsa, A., Thierry, G., & Duñabeitia, J. A. (2020). The Role of Orthotactics in Language Switching: An ERP Investigation Using Masked Language Priming. Brain Sciences, 10(1), 22. https://doi.org/10.3390/brainsci10010022