Dubious Claims about Simplicity and Likelihood: Comment on Pinna and Conti (2019)


Abstract
1. Introduction
2. Contrast Polarity
3. Incorrect Assumptions
“The salience and visibility, derived by the largest amplitude of luminance dissimilarity imparted by contrast polarity, precedes any holist or likelihood organization due to simplicity/Prägnanz and Bayes’ inference.”[2] (p. 12 of 32)
“Contrast polarity was shown to operate locally, eliciting results that could be independent from any global scale and that could also be paradoxical. These results weaken and challenge theoretical approaches based on notions like oneness, unitariness, symmetry, regularity, simplicity, likelihood, priors, constraints, and past knowledge. Therefore, Helmholtz’s likelihood principle, simplicity/Prägnanz, and Bayes’ inference were clearly questioned since they are supposed to operate especially at a global and holistic level of vision.”[2] (p. 26 of 32)
It is true that simplicity and likelihood approaches may aim to arrive at global stimulus interpretations, but a general objection against the above stance is that they (can) do so by including local factors as well. For instance, van Lier [16] presented a theoretically sound and empirically adequate simplicity model for the integration of global and local aspects in amodal completion (see also [17]). A methodological objection is that Pinna and Conti introduced contrast polarity changes in stimuli but pitted these against alleged simplicity and likelihood predictions for the unchanged stimuli. As I specify next, this is unfair, and in my view, scientifically inappropriate.“The highlighting strength of contrast polarity determines even the grouping effectiveness against the global and holistic rules and factors expected by Helmholtz’s likelihood principle, simplicity/Prägnanz, and Bayes’ inference.”[2] (p. 26 of 32)
3.1. Likelihood
3.2. Simplicity
3.3. Summary (1)
4. Simplicity and Likelihood Are Not Equivalent
This is an extraordinary claim. It therefore requires extraordinary evidence, but Pinna and Conti actually provided no corroboration at all (in their earlier draft, they cited Chater [46]; see Section 4.1. Instead, they seem to have jumped on the bandwagon of an idea that, for the past 25 years, has lingered on in the literature—in spite of refutations. As said, Pinna and Conti had been informed about its falsehood but chose to persist. It is therefore expedient to revisit the alleged equivalence of simplicity and likelihood (see Table 1 for a synopsis of relevant issues and terminologies).“[…] the visual object that minimizes the description length is the same one that maximizes the likelihood. In other terms, the most likely hypothesis about the perceptual organization is also the outcome with the shortest description of the stimulus pattern.”[2] (p. 3 of 32)
4.1. Chater (1996)
4.2. MacKay (2003)
In other words, he argued that conditional probabilities, as used in Bayesian modeling, show a bias towards hypotheses with low prior complexity. This is definitely interesting and compelling, and as he noted, it reveals subtle intricacies in Bayesian inference.“Simple models tend to make precise predictions. Complex models, by their nature, are capable of making a greater variety of predictions […]. So if is a more complex model [than ], it must spread its predictive probability more thinly over the data space than . Thus, in the case where the data are compatible with both theories, the simpler will turn out more probable than , without our having to express any subjective dislike for complex models.”[55] (p. 344)
4.3. Summary (2)
5. Conclusions
Funding
Conflicts of Interest
References
- D’Angiulli, A. (Ed.) Special Issue “Vividness, Consciousness, And Mental Imagery: Making The Missing Links Across Disciplines and Methods”; Brain Science; MDPI: Basel, Switzerland, 2019; Volume 9. [Google Scholar]
- Pinna, B.; Conti, L. The limiting case of amodal completion: The phenomenal salience and the role of contrast polarity. Brain Sci. 2019, 9, 149. [Google Scholar] [CrossRef]
- Bell, J.; Gheorghiu, E.; Hess, R.F.; Kingdom, F.A.A. Global shape processing involves a hierarchy of integration stages. Vision Res. 2011, 51, 1760–1766. [Google Scholar] [CrossRef] [PubMed]
- Elder, J.; Zucker, S. The effect of contour closure on the rapid discrimination of two-dimensional shapes. Vision Res. 1993, 33, 981–991. [Google Scholar] [CrossRef]
- Schira, M.M.; Spehar, B. Differential effect of contrast polarity reversals in closed squares and open L-junctions. Front. Psychol. Perception Sci. 2011, 2, 47. [Google Scholar] [CrossRef] [PubMed]
- Spehar, B. The role of contrast polarity in perceptual closure. Vision Res. 2002, 42, 343–350. [Google Scholar] [CrossRef]
- Su, Y.; He, Z.J.; Ooi, T.L. Surface completion affected by luminance contrast polarity and common motion. J. Vision 2010, 10, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Reed, S.K. Structural descriptions and the limitations of visual images. Mem. Cogn. 1974, 2, 329–336. [Google Scholar] [CrossRef] [PubMed]
- Mancini, S.; Sally, S.L.; Gurnsey, R. Detection of symmetry and antisymmetry. Vision Res. 2005, 45, 2145–2160. [Google Scholar] [CrossRef]
- Saarinen, J.; Levi, D.M. Perception of mirror symmetry reveals long-range interactions between orientation-selective cortical filters. Neuroreport 2000, 11, 2133–2138. [Google Scholar] [CrossRef]
- Tyler, C.W.; Hardage, L. Mirror symmetry detection: Predominance of second-order pattern processing throughout the visual field. In Human Symmetry Perception and Its Computational Analysis; Tyler, C.W., Ed.; VSP: Zeist, The Netherlands, 1996; pp. 157–172. [Google Scholar]
- Wenderoth, P. The effects of the contrast polarity of dot-pair partners on the detection of bilateral symmetry. Perception 1996, 25, 757–771. [Google Scholar] [CrossRef]
- Wilson, J.A.; Switkes, E.; De Valois, R.L. Glass pattern studies of local and global processing of contrast variations. Vision Res. 2004, 44, 2629–2641. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Or, C.C.-F.; Khuu, S.K.; Hayes, A. The role of luminance contrast in the detection of global structure in static and dynamic, same- and opposite-polarity, Glass patterns. Vision Res. 2007, 47, 253–259. [Google Scholar] [CrossRef] [PubMed]
- Prazdny, K. On the perception of Glass patterns. Perception 1984, 13, 469–478. [Google Scholar] [CrossRef]
- Van Lier, R.J.; van der Helm, P.A.; Leeuwenberg, E.L.J. Integrating global and local aspects of visual occlusion. Perception 1994, 23, 883–903. [Google Scholar] [CrossRef] [PubMed]
- Van der Helm, P.A. Simplicity versus likelihood in visual perception: From surprisals to precisals. Psychol. Bull. 2000, 126, 770–800. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. The free-energy principle: A rough guide to the brain? Trends Cogn. Sci. 2009, 13, 293–301. [Google Scholar] [CrossRef] [PubMed]
- Luccio, R. Limits of the application of Bayesian modeling to perception. Perception 2019, 48, 901–917. [Google Scholar] [CrossRef] [PubMed]
- Radomski, B.M. The Theoretical Status of the Free-Energy Principle. Ph.D. Thesis, Ruhr-University Bochum, Bochum, Germany, 2019. [Google Scholar]
- Kwisthout, J.; van Rooij, I. Computational resource demands of a predictive Bayesian brain. Comput. Brain Behav. 2019. [Google Scholar] [CrossRef]
- Van der Helm, P.A. Structural coding versus free-energy predictive coding. Psychon. B. Rev. 2016, 23, 663–677. [Google Scholar] [CrossRef]
- Wang, P. The limitation of Bayesianism. Artif. Intell. 158 2004, 1, 97–106. [Google Scholar] [CrossRef]
- Chomsky, N. A review of B. F. Skinner’s Verbal Behavior. Language 35 1959, 1, 26–58. [Google Scholar] [CrossRef]
- Van der Helm, P.A. Simplicity in Vision: A Multidisciplinary Account of Perceptual Organization; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Van der Helm, P.A.; Treder, M.S. Detection of (anti)symmetry and (anti)repetition: Perceptual mechanisms versus cognitive strategies. Vision Res. 2009, 49, 2754–2763. [Google Scholar] [CrossRef]
- Leeuwenberg, E.L.J. Structural Information of Visual Patterns: An Efficient Coding System in Perception; Mouton & Co.: Hague, The Netherlands, 1968. [Google Scholar]
- Leeuwenberg, E.L.J. Quantitative specification of information in sequential patterns. Psychol. Rev. 1969, 76, 216–220. [Google Scholar] [CrossRef]
- Leeuwenberg, E.L.J. A perceptual coding language for visual and auditory patterns. Am. J. Psychol. 1971, 84, 307–349. [Google Scholar] [CrossRef] [PubMed]
- Van der Helm, P.A.; Leeuwenberg, E.L.J. Accessibility, a criterion for regularity and hierarchy in visual pattern codes. J. Math. Psychol. 1991, 35, 151–213. [Google Scholar] [CrossRef]
- Van der Helm, P.A.; Leeuwenberg, E.L.J. Goodness of visual regularities: A nontransformational approach. Psychol. Rev. 1996, 103, 429–456. [Google Scholar] [CrossRef] [PubMed]
- Makin, A.D.J.; Wright, D.; Rampone, G.; Palumbo, L.; Guest, M.; Sheehan, R.; Cleaver, H.; Bertamini, M. An electrophysiological index of perceptual goodness. Cereb. Cortex 2016, 26, 4416–4434. [Google Scholar] [CrossRef]
- Van der Helm, P.A. Transparallel processing by hyperstrings. Proc. Natl. Acad. Sci. USA 2004, 101, 10862–10867. [Google Scholar] [CrossRef]
- Leeuwenberg, E.L.J.; van der Helm, P.A. Unity and variety in visual form. Perception 1991, 20, 595–622. [Google Scholar] [CrossRef]
- Leeuwenberg, E.L.J.; van der Helm, P.A.; van Lier, R.J. From geons to structure: A note on object classification. Perception 1994, 23, 505–515. [Google Scholar] [CrossRef]
- Nyquist, H. Certain factors affecting telegraph speed. Bell Syst. Tech. J. 1924, 3, 324–346. [Google Scholar] [CrossRef]
- Hartley, R.V.L. Transmission of information. Bell Syst. Tech. J. 1928, 7, 535–563. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Von Helmholtz, H.L.F. Treatise on Physiological Optics; Original work published 1909; Dover: New York, NY, USA, 1962. [Google Scholar]
- Wallace, C.; Boulton, D. An information measure for classification. Comput. J. 1968, 11, 185–194. [Google Scholar] [CrossRef]
- Hochberg, J.E.; McAlister, E. A quantitative approach to figural “goodness”. J. Exp. Psychol. 1953, 46, 361–364. [Google Scholar] [CrossRef] [PubMed]
- Rissanen, J. Modelling by the shortest data description. Automatica 1978, 14, 465–471. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three approaches to the quantitative definition of information. Probl. Inform. Transm. 1965, 1, 1–7. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference, Part 1. Inform. Control 1964, 7, 1–22. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference, Part 2. Inform. Control 1964, 7, 224–254. [Google Scholar] [CrossRef]
- Chater, N. Reconciling simplicity and likelihood principles in perceptual organization. Psychol. Rev. 1996, 103, 566–581. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Hurri, J.; Hoyer, P.O. Natural Image Statistics; Springer: London, UK, 2009. [Google Scholar]
- Renoult, J.P.; Mendelson, T.C. Processing bias: Extending sensory drive to include efficacy and efficiency in information processing. Proc. R. Soc. B 2019, 286, 20190445. [Google Scholar] [CrossRef]
- Feldman, J. Tuning your priors to the world. Top. Cogn. Sci. 2013, 5, 13–34. [Google Scholar] [CrossRef]
- Hoffman, D.D. What do we mean by “The structure of the world”? In Perception as Bayesian Inference; Knill, D.C., Richards, W., Eds.; Cambridge University Press: Cambridge, MA, USA, 1996; pp. 219–221. [Google Scholar]
- Friston, K.; Chu, C.; Mourão-Miranda, J.; Hulme, O.; Rees, G.; Penny, W.; Ashburner, J. Bayesian decoding of brain images. NeuroImage 2008, 39, 181–205. [Google Scholar] [CrossRef] [PubMed]
- Feldman, J. Bayes and the simplicity principle in perception. Psychol. Rev. 2009, 116, 875–887. [Google Scholar] [CrossRef] [PubMed]
- Feldman, J. The simplicity principle in perception and cognition. WIREs Cogn. Sci. 2016, 7, 330–340. [Google Scholar] [CrossRef] [PubMed]
- Thornton, C. Infotropism as the underlying principle of perceptual organization. J. Math. Psychol. 2014, 61, 38–44. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Van der Helm, P.A. Bayesian confusions surrounding simplicity and likelihood in perceptual organization. Acta Psychol. 2011, 138, 337–346. [Google Scholar] [CrossRef]
- Van der Helm, P.A. On Bayesian simplicity in human visual perceptual organization. Perception 2017, 46, 1269–1282. [Google Scholar] [CrossRef]
- Tribus, M. Thermostatics and Thermodynamics; Van Nostrand: Princeton, NJ, USA, 1961. [Google Scholar]
- Grünwald, P.D. The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications, 2nd ed.; Springer: New York, NY, USA, 1997. [Google Scholar]
- Penny, W.D.; Stephan, K.E.; Mechelli, A.; Friston, K.J. Comparing dynamic causal models. NeuroImage 2004, 22, 1157–1172. [Google Scholar] [CrossRef]
- Baxter, R.A.; Oliver, J.J. MDL and MML: Similarities and Differences; Tech Report 207; Monash University: Melbourne, Australia, 1994. [Google Scholar]
- MacKay, D.J.C. Bayesian Methods for Adaptive Models. Ph.D. Thesis, California Institute of Technology, Pasadena, CA, USA, 1992. [Google Scholar]
- Feldman, J.; Singh, M. Bayesian estimation of the shape skeleton. Proc. Natl. Acad. Sci. USA 2006, 103, 18014–18019. [Google Scholar] [CrossRef]
- Froyen, V.; Feldman, J.; Singh, M. Bayesian hierarchical grouping: Perceptual grouping as mixture estimation. Psychol. Rev. 2015, 122, 575–597. [Google Scholar] [CrossRef] [PubMed]
- Wilder, J.; Feldman, J.; Singh, M. Contour complexity and contour detection. J. Vision 2015, 15, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Wilder, J.; Feldman, J.; Singh, M. The role of shape complexity in the detection of closed contours. Vision Res. 2016, 126, 220–231. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
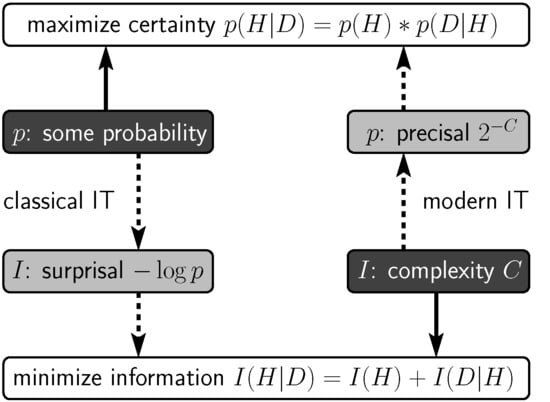
| Probabilistic framework |
| Classical information theory: |
| • information load of thing with probability p is surprisal [36,37] (information quantified by its probability, not by its content) |
| • codes are nominalistic labels referring to things (as, e.g., in the Morse Code) |
| • optimal coding by label codes the length of surprisals [38] (implying minimal long-term average code length, not individually shortest codes) |
| Likelihood principle [39]: |
| • preference for things with higher probabilities, i.e., with lower surprisals |
| Bayesian inference (incomputable [21]): |
| • in cognitive science: free-to-choose probabilities for free-to-choose things |
| • minimum message length principle (message length measured i.t.o. surprisals) [40] |
| Surprisals do not enable descriptive formulation |
| Descriptive framework |
| Modern information theory (triggered by the question: what if probabilities are unknown?): |
| • codes are hierarchical descriptions (i.e., reconstruction recipes) of individual things |
| • shorter descriptive codes by extracting regularities i.t.o. identity relationships between parts |
| • information load of thing is its complexity C, i.e., the length of its shortest descriptive code (information quantified by its content, not by its probability) |
| Simplicity principle: |
| • a.k.a. minimum principle [41] or minimum description length principle [42] |
| • preference for simpler things, i.e., things with shorter descriptive codes |
| Algorithmic information theory (mathematics) [43,44,45]: |
| • extraction of any imaginable regularity (incomputable) |
| • classification by complexity of simplest descriptive code |
| Structural information theory (cognitive science) [27,28,29]: |
| • extraction of theoretically and empirically grounded visual regularities (computable) [30,31,32,33] |
| • classification by hierarchical organization described by simplest descriptive code [34,35] |
| Precisals , a.k.a. algorithmic probabilities, enable probabilistic formulation |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
van der Helm, P.A. Dubious Claims about Simplicity and Likelihood: Comment on Pinna and Conti (2019). Brain Sci. 2020, 10, 50. https://doi.org/10.3390/brainsci10010050
van der Helm PA. Dubious Claims about Simplicity and Likelihood: Comment on Pinna and Conti (2019). Brain Sciences. 2020; 10(1):50. https://doi.org/10.3390/brainsci10010050
Chicago/Turabian Stylevan der Helm, Peter A. 2020. "Dubious Claims about Simplicity and Likelihood: Comment on Pinna and Conti (2019)" Brain Sciences 10, no. 1: 50. https://doi.org/10.3390/brainsci10010050
APA Stylevan der Helm, P. A. (2020). Dubious Claims about Simplicity and Likelihood: Comment on Pinna and Conti (2019). Brain Sciences, 10(1), 50. https://doi.org/10.3390/brainsci10010050