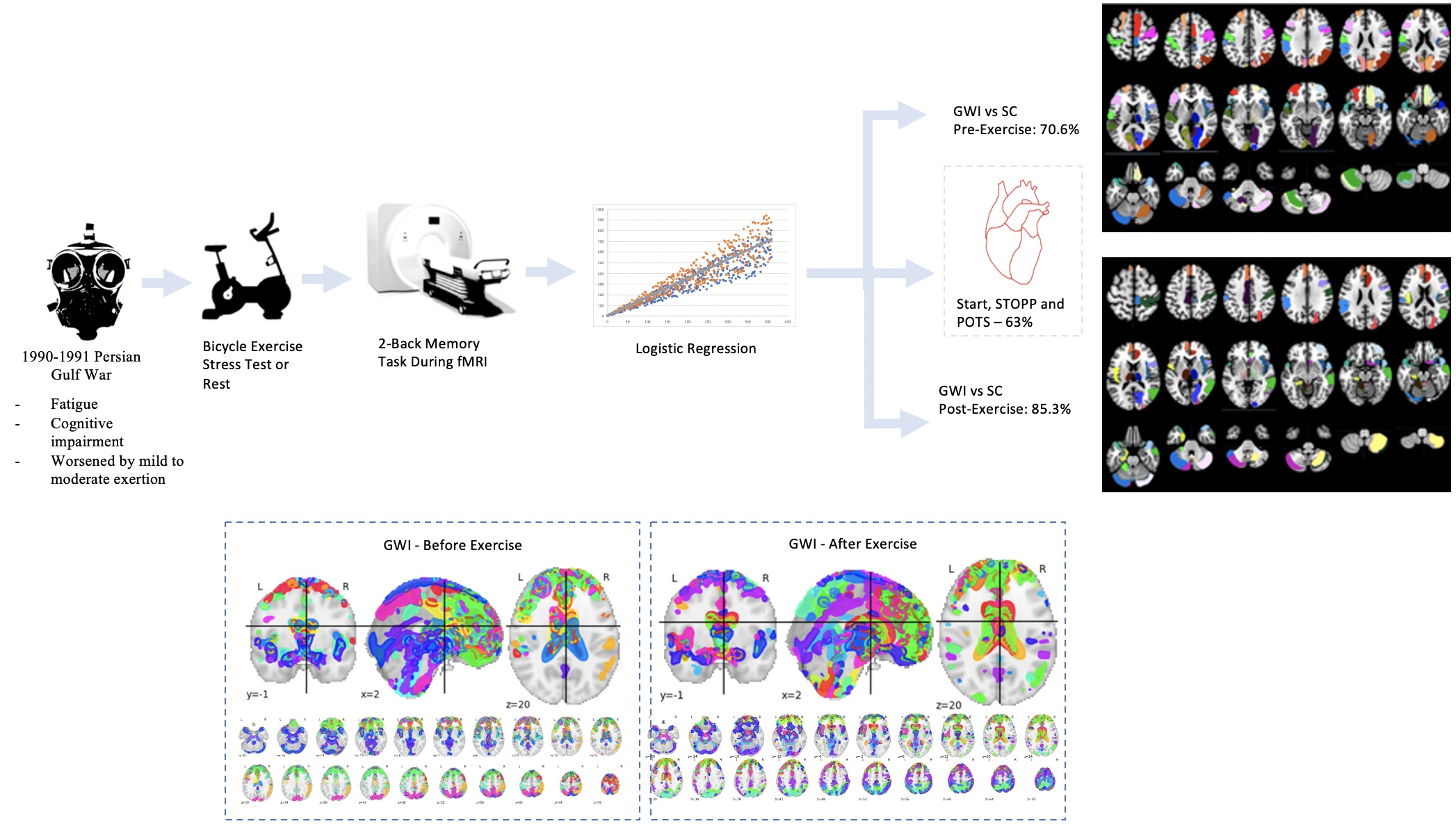
2.3. Subjects
Candidates responded to online and personal contacts and gave verbal informed consent for screening by telephone. After explaining the protocol and assessing chronic medical and psychiatric diseases, 105 of the 216 candidates declined to participate or were excluded from participation [
1,
3]. GWI was confirmed in person using the Chronic Multisymptom Illness (CMI) and Kansas criteria. The Kansas criteria require moderate or severe chronic symptoms in at least three of six domains: fatigue/sleep, muscle/joint pain, neurological/cognitive/mood, gastrointestinal, respiratory, and skin symptoms [
1]. Complete history and physical examination, exercise, and fMRI data were collected for 80 GWI and 31 control subjects (
n = 111). All subjects had a sedentary lifestyle with less than 40 min of active aerobic work or exercise per week.
Further information regarding the study protocol, screening, demographics, subject symptoms, subject pain perception, orthostatic measurements, interoceptive complaints, chemical sensitivity questionnaires, and subject quality of life domain data are reported in previous published articles from our group and online as
Supplementary Materials [
13,
18,
19,
20]. It should be noted that all subjects were screened for ability to perform the task prior to fMRI data collection, and were able to practice the N-back memory task until they felt comfortable prior to recording. Performance data from the GWI group was reported in a previous study to be markedly lower (on average about 26% lower) than the sedentary control both before and after exercise [
13].
We admitted subjects to the Georgetown Howard Universities Clinical Translation Science Clinical Research Unit as described previously [
21]. After overnight rest, they first performed the zero-back and two-back portions of the N-back working memory tasks while undergoing an\fMRI scan, and then practiced the submaximal exercise stress test (Day 1). The next day they performed the same exercise test then repeated the fMRI scanning procedure and cognitive tests.
The continuous N-Back task assesses verbal working memory and attention [
13,
15]. Subjects practiced the task in a mock scanner until satisfactory performance was achieved. The task had five blocks of fixation, 0-Back and 2-Back components. Each block began with fixation as subjects viewed a blank screen for eight seconds. 0-Back testing proceeded by observation of strings of nine letters for two seconds each. The letters (A, B, C, D) were shown at random. Subjects viewed each letter and pressed a corresponding button with both hands on a fiber-optic button box (ePrime software) [
22]. After a second fixation period, an additional string of nine letters was shown for the 2-Back task. Subjects were shown a partial string of letters where they were encouraged to recall the first and second letters. While being shown the third letter in the string, subjects pressed the button for the letter seen two letters previously (the first letter seen four seconds prior). While viewing the fourth letter, subjects pressed the button for the next letter seen two letters previously (second letter in the series).
This continuous task was designed for subjects to engage their working memory on a string, rearrange the letters, and disengage their working memory to re-focus their attention to the next letter.
Subjects have individual strategies for remembering single letters in series (e.g., A-B-C-D) or through “chunks” (AB-BC-CD, or ABC-BCD). Each one-minute block was repeated five times. Final data from this five-minute task was in the form of time series scans of 45 letters for the first 0-Back stimulus response, and 35 letters for the second letter back (2-Back task) response. This corresponded to five blocks of seven responses each.
2.4. Data Collection
Neuroimaging was performed in a Siemens 3T Tim Trio scanner equipped with a transmit-receive body coil and a commercial 12-channel head coil array. Structural 3D T1-weighted Magnetization Prepared Rapid Acquisition Gradient Echo (MPRAGE) image parameters were TR/TE = 1900/2.52 ms, TI = 900 ms, field-of-view (FoV) = 250 mm, 176 slices, slice resolution = 1.0 mm, and voxel size 1 × 1 × 1 mm. Functional T2*-weighted gradient-echo planar imaging (EPI) parameters were number of slices = 47, TR/TE = 2000/30 ms, flip angle = 90°, matrix size = 64 × 64, FoV = 205 mm2, and voxel siz = 3.2 mm2 (isotropic).
The CONN version 17 toolbox was used to pre-process BOLD data according to the default procedure [
23]. These pre-processing steps included: (a) time alignment through slice timing correction (STC), (b) smoothing with a stationary Gaussian filter of 6 mm full-width at half maximum (FWHM), (c) spatial pre-processing and positioning of the resulting fMRI images to the Montreal Neurological Institute (MNI) standard stereotactic space, (d) segmentation and outlier detection on Artifact Detection Tools, (e) rectification of the functional images to remove warping [
24], Spatial normalization resulted in a voxel size of 2.0 mm
3 (isotropic). Preprocessed EPI data for each subject was modeled with SPM12 software to the following: instruction, fixation, 0-Back, and 2-Back [
25]. We determined that the contrast of interest was 2-Back > 0-Back and opted for a one-sample t-test with motion parameters such as translation and rotation to be covariates of no-interest. Using this 2-Back > 0-Back condition allowed us to identify voxels that had increased significance in activation during the high cognitive 2-Back load over the low cognitive 0-Back load.
2.5. Feature Extraction
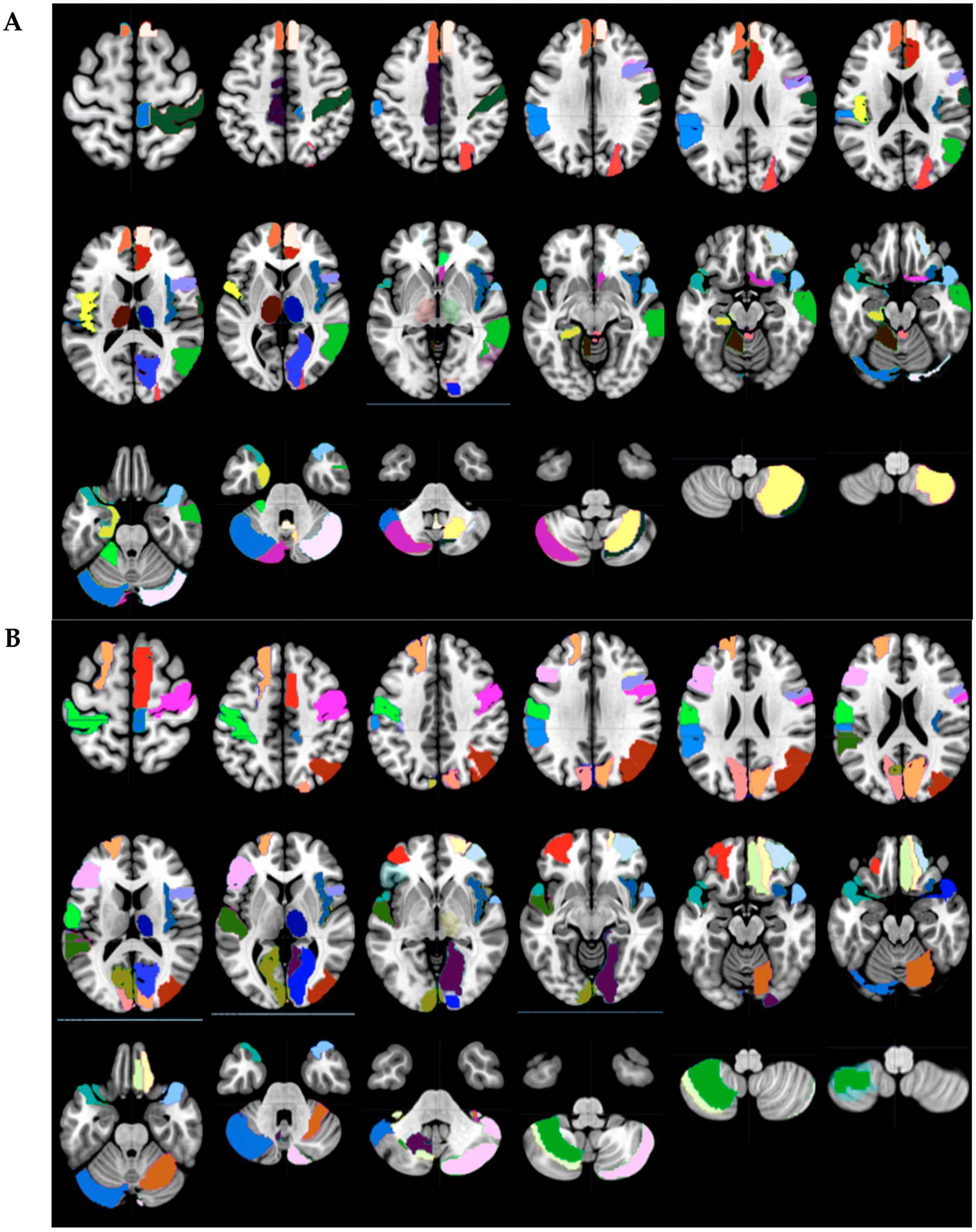
A customized MATLAB program that used functions from both SPM12 and xjView 9.6 grouped voxels into AAL regions as mapped out by the MNI coordinates extracted from resultant functional T-statistical maps [
26]. One-sample T values were generated from BOLD data based on the relative activation in the 2-Back > 0-Back condition of each individual. We determined the optimal threshold of voxel activation by plotting the total voxels activated as a function of T values as described in a previously [
14]. It was determined that voxels with T values exceeding 3.17 (
p < 0.001 uncorrected) maintained statistical significance while allowing a large number of voxels per person to remain in consideration. The Automated Anatomical Labeling (AAL) atlas (
Figure S1) was used as an anatomical map and significant voxels were grouped into corresponding regions [
15]. Each AAL region was considered a separate feature for modeling purposes. Total significant voxels for each AAL region were the “features” or independent variables that were fed into the model and analyzed for the purpose of model building. The full AAL depicting regions, centers of mass, and voxels per region are detailed in the
Supplementary Online Material (Table S1 and Figure S1) [
27].
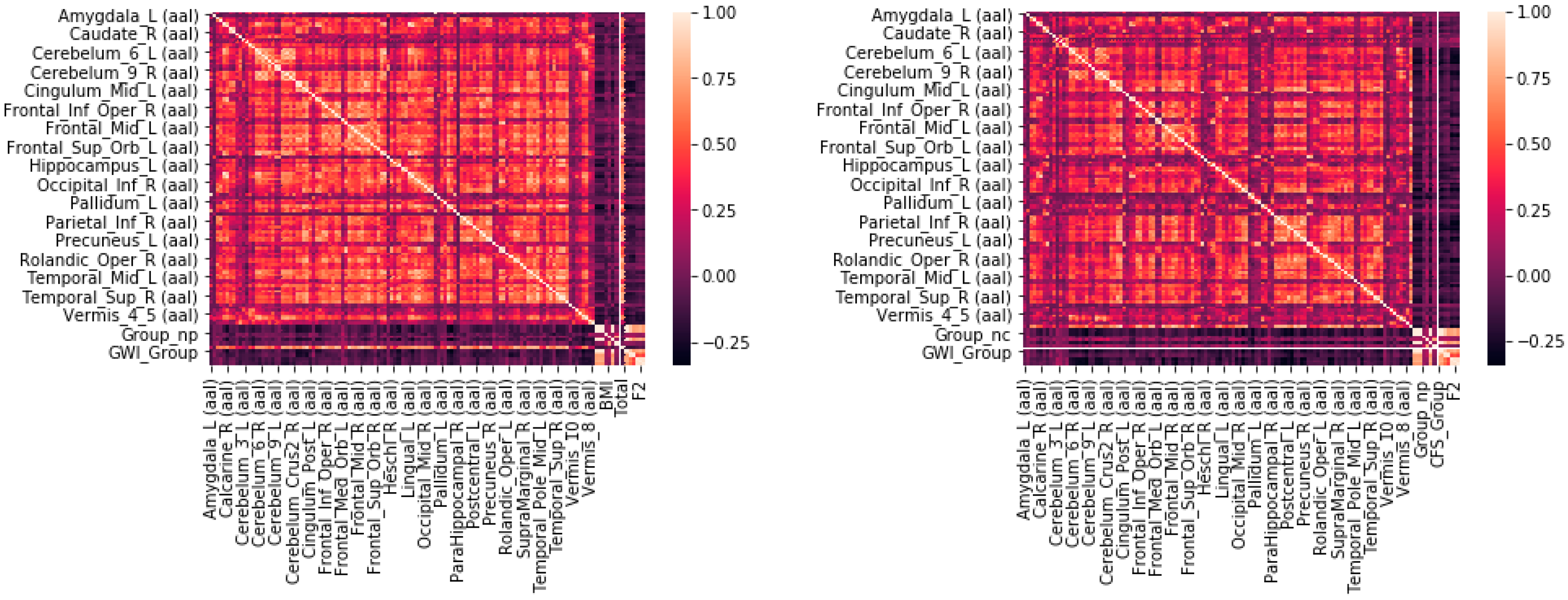
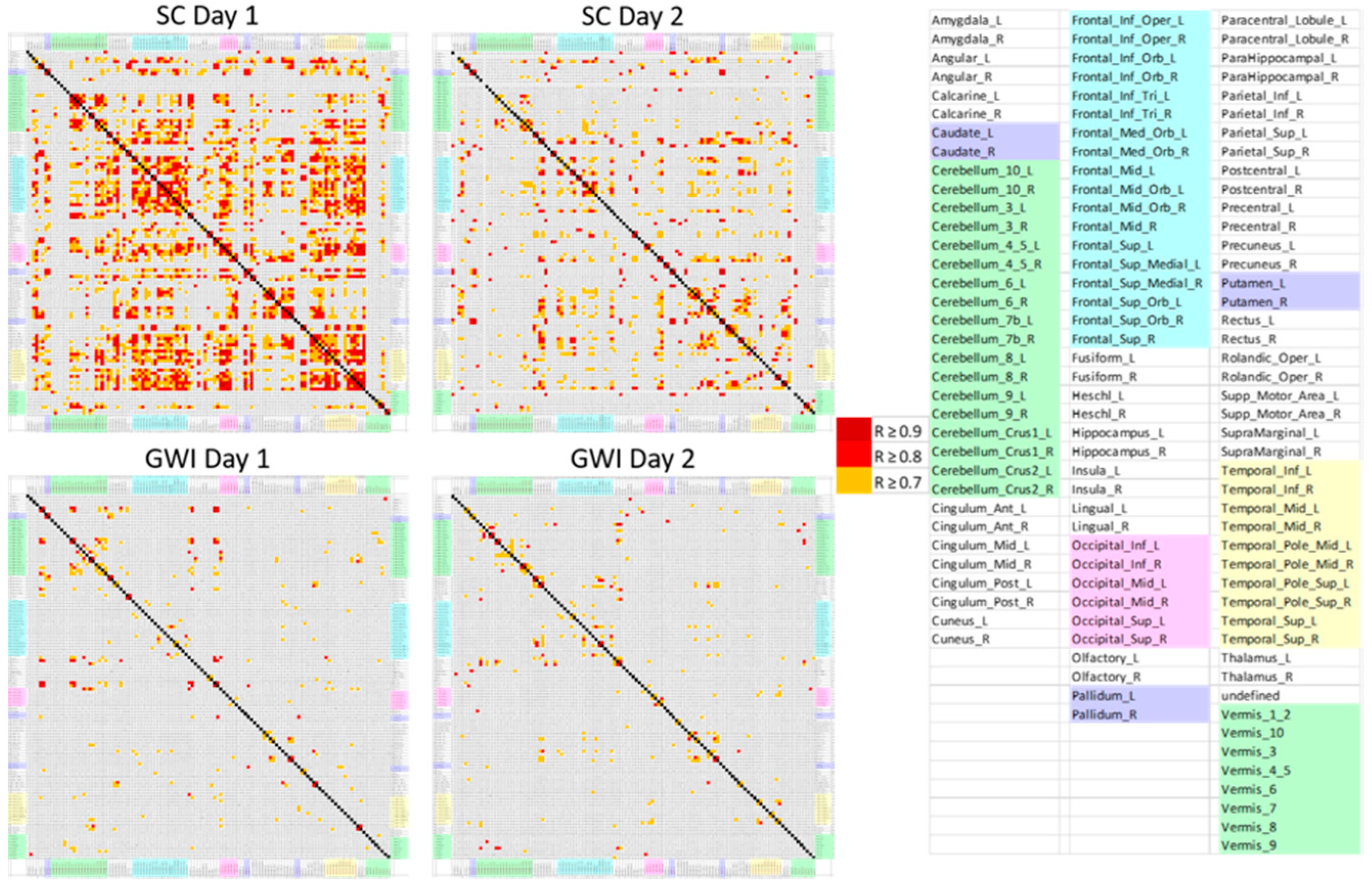
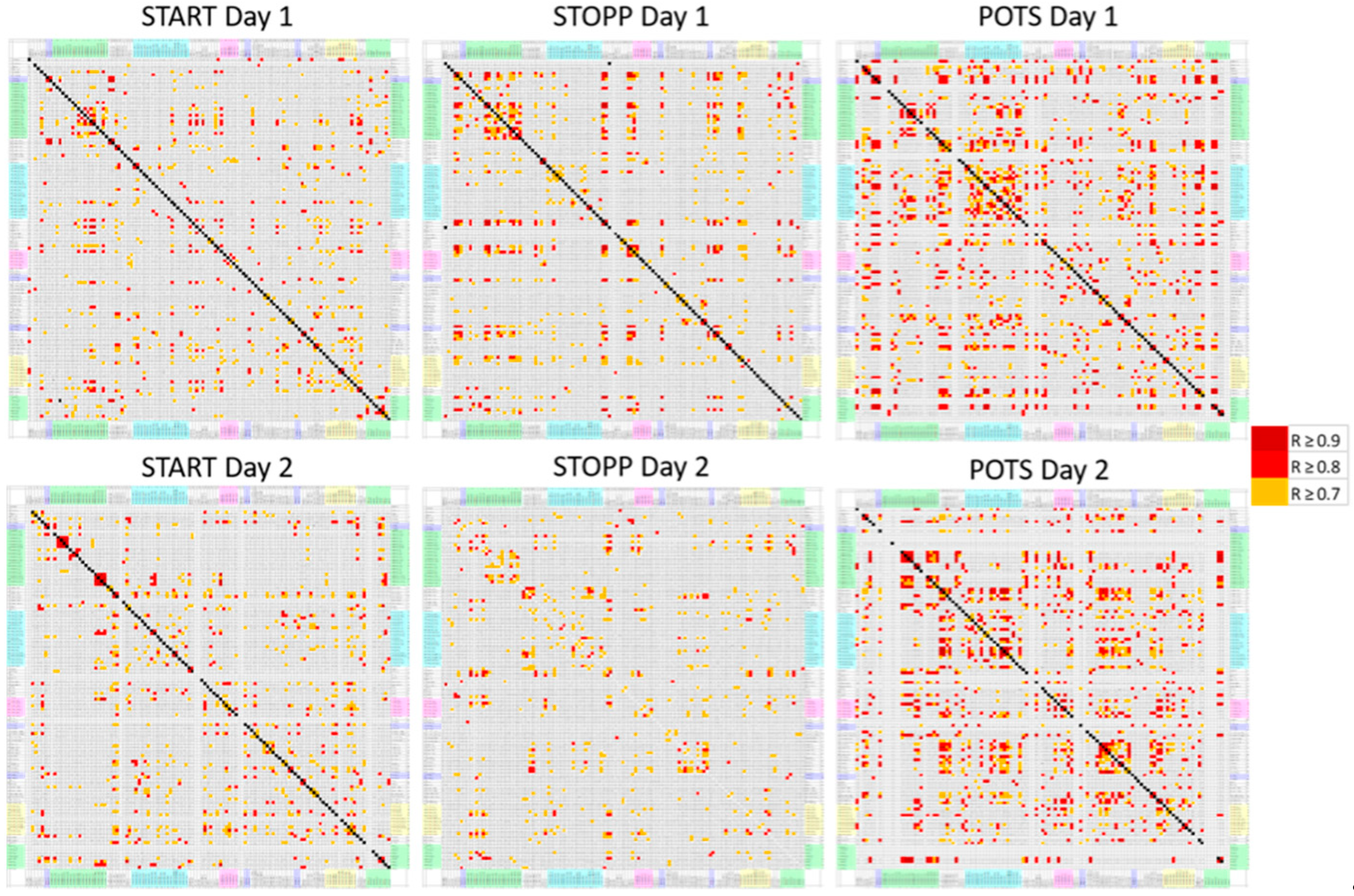
A multistep feature reduction process was used to determine the number of significant AAL regions, or features. In the first step, multicollinearity was assessed by finding the Pearson correlation coefficients between levels of BOLD activation for all subjects in all AAL regions. Every AAL region was compared against every other AAL region to create a matrix of correlation coefficients. A threshold of R < 0.9 was implemented in order to eliminate or combine highly correlated inputs from the model. If a region had a correlation coefficient of > 0.9 with any other region, it would be assumed that it could be linearly predicted from another coefficient and thus the resulting regions would need to be combined or compared and then removed. Although multicollinearity may not impact the accuracy or predictive power of a model, it can affect the coefficients and calculations of individual predictors, rendering the results for any single variable invalid [
28,
29]. For instances of perfect multicollinearity where one individual predictor is the perfect combination of the remainder, the design matrix has less than one full rank and therefore cannot be inverted, which can eliminate the ordinary least squares estimator [
30]. The presence of multicollinearity in a final model can cause excessively large standard errors for coefficients, inaccurate predictions of the model, and models that overfit the data [
31,
32]. Tests to ensure there were no correlations between variables were repeated three times on the training set, testing set, and combined training and testing set (full dataset) to make sure no regions of perfect multicollinearity persisted across any of the data.
The second step of the feature selection process sought to reduce the total number of features using an iterative recursive feature elimination algorithm. Recursive feature elimination (RFE) performs a greedy search algorithm that iteratively cycles through inputs and determines the best and worst performing inputs. After all inputs are explored, it seeks to reduce the model to the fewest possible inputs as the principles of Occam’s Razor dictates that simplest models lead to the most accurate results [
33]. Although this greedy search is similar in nature to a stepwise logistic regression, it was selected to optimize p-values, standard errors, confidence intervals, bias in R
2 values, and create un-biased parameter estimates. It was important to use RFE instead of a stepwise logistic regression because a stepwise algorithm can exacerbate collinearity problems in small datasets, and this was a very small sample size. The scikit-learn python package default recursive feature elimination (RFE) algorithm was used for this step [
34]. The weakest features were removed by an iterative process until an optimal number of features and accuracy were obtained. Iteratively eliminating a few inputs every loop reduces the potential for overfitting and decreases the total number of variables with inter-dependencies to produce an improved model.
The third step determined the optimal modeling method and partitioned the data into appropriate training and testing sets. In addition to testing logistic regression, the authors evaluated a series of other techniques including a support vector machine (SVM), neural net, decision tree, and random forest. The logistic regression was optimal because of its simplicity, generalizability, and ability to predict a binary dependent variable from multiple input independent variables [
35,
36]. The logistic was ultimately selected due to its ability to consistently predict GWI from an SC with similar results using the same variables upon repeated trials in addition to its speed. The Support Vector Machine for example ran for three days on one trial to no conclusion, and the Random Forest was difficult to replicate in practice. For example, if this algorithm was to go into effect in practice in the medical field, it would be difficult to code the potential 30,000 branches of a random forest into a standard fMRI analyzer. The logistic regression provided a consistent, generalizable, and easily implementable alternative. Although the logistic regression is described here, results from alternate modeling techniques are available in the
Supplementary Materials (Table S2). The data were partitioned into a series of training and test sets from 50:50 to 90:10 and iteratively tested to select the proportions that optimized accuracy. The optimal split was a 70:30 randomly stratified training to testing set. We determined this ratio through evaluation of the ultimate predictive power of the model. For example, if a model showed a high accuracy (e.g., 80%) initially, that could not be replicated on repeated attempts, it would be determined that this was likely too generous of a split and caused overfitting and a lack of generalizability. The ratio of 70:30 in the final model gave similar results upon repeated trials.
Logistic regression model algorithms available from scikit learn and the statsmodels python package were both evaluated in this process. Age, gender, and Body Mass Index (BMI) were included as independent covariates in all regressions to account for differences amongst groups.
It is important to note that this study did face potential biases due to the small sample size. The 70:30 split provided a substantially larger amount of samples in the training set; however, depending on the ultimate make-up of the testing set could have also been heavily overfit. Further studies with more data would eliminate this problem.
Logistic regression seeks to estimate coefficients for the logarithm of the odds (log-odds) pertaining to an outcome variable (GWI vs. control status) based on the linear combination of independent variables (voxel counts per AAL region) [
37]. It seeks to understand how each corresponding coefficient for an input variable can be “regressed” from the data [
38]. Logistic coefficients are obtained by the logistic regression model procedure, which seeks to fit coefficients to input variables according to the logit equation. The general form of the logit equation is
where β
0 is the intercept, which is a constant term, and β
1 is the corresponding coefficient for the first variable x
1, β
2 is the coefficient for variable x
2, and β
i represents the coefficient assigned to all additional variables [
39]. Coefficients are determined by first receiving a coefficient (β) that is next reduced according to the principles of stochastic gradient descent until the highest possible accuracy is obtained from a potential model. During the Stochastic gradient descent reduction process, steps are taken in an iterative fashion that are proportional to the negative gradient of the function at every point and then continued until a minimum is met [
40]. The probability (p(x)) calculated for each subject was used to predict GWI versus control status.
Each set of coefficients from the iterative training sets were applied to their test sets to assess model accuracy and generalizability. Model accuracy was determined by overall false positive rate (accuracy) from the validation data (testing set). Model was further validated using 10-fold cross-validation (k-cross validation with k = 10) and 10 smaller sampled subgroups drawn at random from the 30% validation data (testing set; out-of-sample testing). This process of cross validation reuses these smaller sampled subgroups on the validation data only to validate generalizability by recalculating false positive rates. The final result is averaged across each subgroup to obtain the ultimate accuracy. Due to the small sample size of the data, the total number of cross-validated subgroups was selected to be 10 to provide a generalizable outcome and potentially reduce overfitting. Results from a cross-validation procedure provide a more accurate method of assessing a model’s predictive performance and capacity on potential future data [
41]. However, even with the use of cross-validation there is still room for significant bias and over-fitting of the results that more data would alleviate. Multiple studies have detailed how cross-validation can be impacted by over-fitting [
42]. The authors would like to note that this bias exists and indicate the need for more data.
The use of cross validation ensured that the predictive model was first trained on multiple different re-sampled ratios of training: testing sets, tested on testing (validation) data separate from the training data that was re-sampled, and was re-built in an iterative fashion until the remaining set of input features and corresponding model coefficients allowed a high degree of both accuracy and generalizability. The final result of the model build was a predictive indicator that showed how a group of independent variables (in this case total voxels confined to each AAL region) was able to predict the dependent binary outcome (GWI vs. control). To correct for multiple comparisons for multiple regions the Sidak method was used and evaluated within the python procedure of the logistic regression [
43].
To assess statistical significance of the final predictive model, a “Shuffle Test” was then used for both Days 1 and 2. To run a Shuffle Test, the outcome labels on all subjects corresponding to GWI or SC were re-shuffled in python using a built-in randomization function. This newly labeled data was then passed through the model build process 1000 times to test both if the original accuracy and result could occur a majority of times due to random chance. It should be noted that the randomized sample was also split into a 70% training set and 30% testing set to mimic model build conditions. To ensure this Shuffle Test worked, the process was repeated up to 10,000 times if no Shuffled run could obtain an accuracy greater than or equal to the reported model accuracy for Day 1 and Day 2. The Shuffle Test attempts to determine the p-value and statistical significance of a predictive model. It can be assumed that a model that obtains accuracy equal to or less than the original 5% of the time would be significant at the p < 0.05 level.
The final model coefficients produced for the Logistic Regression signify the rate of change in the “log odds” of the input feature that changes as the outcome variable changes. In this way, the y-intercept term (β0) is therefore representative of the log-odds of the outcome or dependent variable when all of the inputs or predictors are set to 0. The model coefficients in a multivariate model also signify the importance of the variable in the predictive model, and not necessarily the importance of the variable fir the disease itself. As such, the model coefficients cannot be interpreted like the slope coefficients for a simpler linear regression. Instead they are representative of the change in the log-odds relative to one another. To clarify, if the first variable in the series has a corresponding coefficient of β = 1, the variable or x in turn would be multiplied by the log-odds of 1 or 10 (101). Similarly, a coefficient of 2 would cause the variable to be multiplied by 100 (102). Due to the inter-dependency between variables and basis of the multivariate model, although it could have a direct relationship, a coefficient with a negative slope may not necessarily indicate a negative correlation with the dependent variable. The presence of the remaining variables and corresponding coefficients in the multivariate model make it difficult to ascertain this relationship without alternate analysis.
This entire process was repeated to test for the ability to determine GWI orthostatic phenotypes (subgroups) START, STOPP, and POTS [
13,
23]. Postural tachycardia groups were defined by their postural change in heart rate between supine and standing before and after exercise. STOPP had normal changes (ΔHR 12 ± 5 mean ± SD). POTS developed tachycardia >30 beats per minute on standing both before and after exercise. START had normal heart rate changes before exercise, but events of postural tachycardia of >30 beats per minute in the first 24 h after exercise. Predictive models were similarly sampled, trained, and tested after being subjected to RFE on a variable that segmented the GWI population into START, STOPP, and POTS subgroups.
The corresponding AAL regions that were predicted to be significant in the final selected model were displayed by selection in Wake Forest PICK ATLAS, then imported into MarsBaR 0.44, and finally shown as color-coded axial slices (MRIcron) [
44].
The final component of the analysis to validate that the patterns of data were different re-used the original Pearson’s correlation coefficient analysis. The correlation coefficients corresponding to each remaining selected predictive AAL region were displayed for each group (GWI Day 1, SC Day 1, GWI Day 2, SC Day 2) and analyzed for total correlations and for the most correlations. This was repeated for the three orthostatic phenotypes.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}