
Differential Deep Convolutional Neural Network Model for Brain Tumor Classification

 , ,
, ,
Abstract
:
1. Introduction
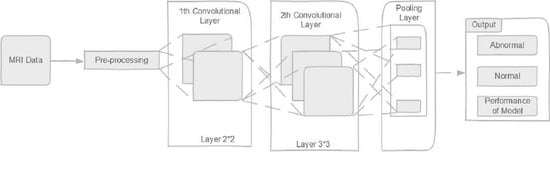
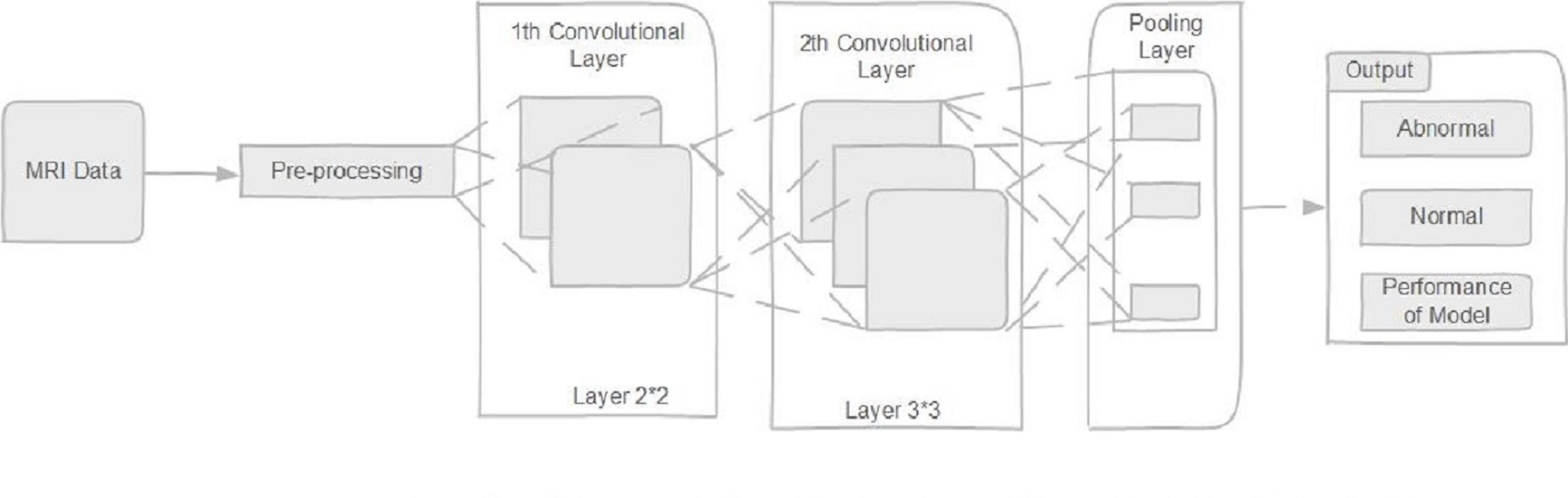
2. Methodology
2.1. Deep Convolutional Neural Network
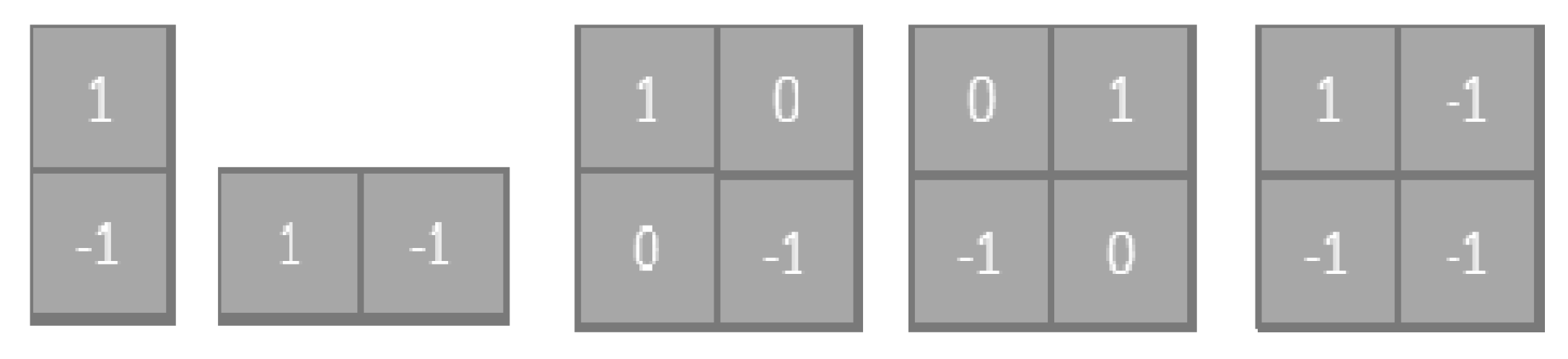
2.1.1. Convolution Layer
2.1.2. Activation Function
2.1.3. Back Propagation
2.2. Differential Deep Convolutional Feature Map
2.3. Back Propagation
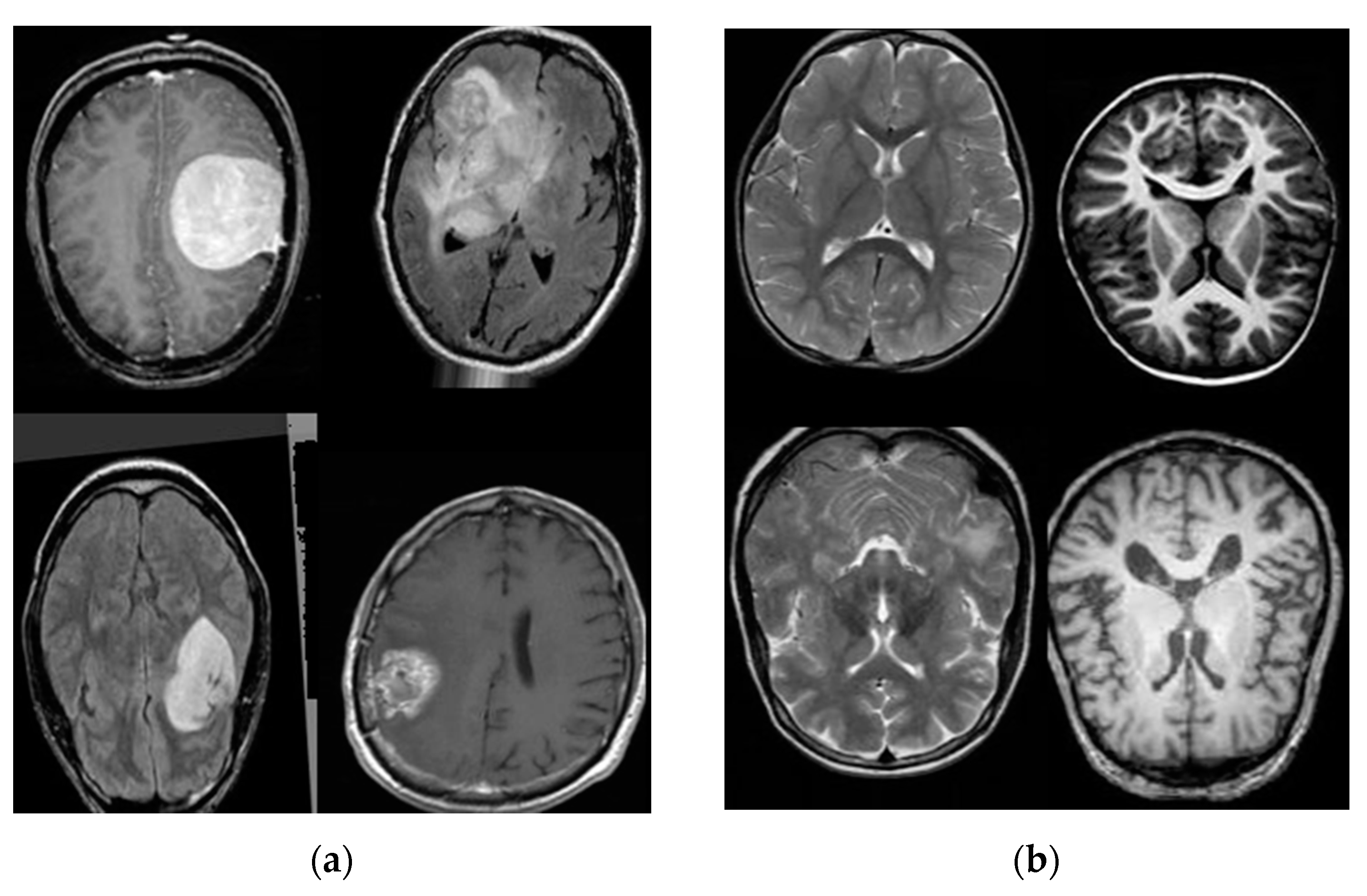
3. Databases
3.1. Database Collection
3.2. Database Augmentation
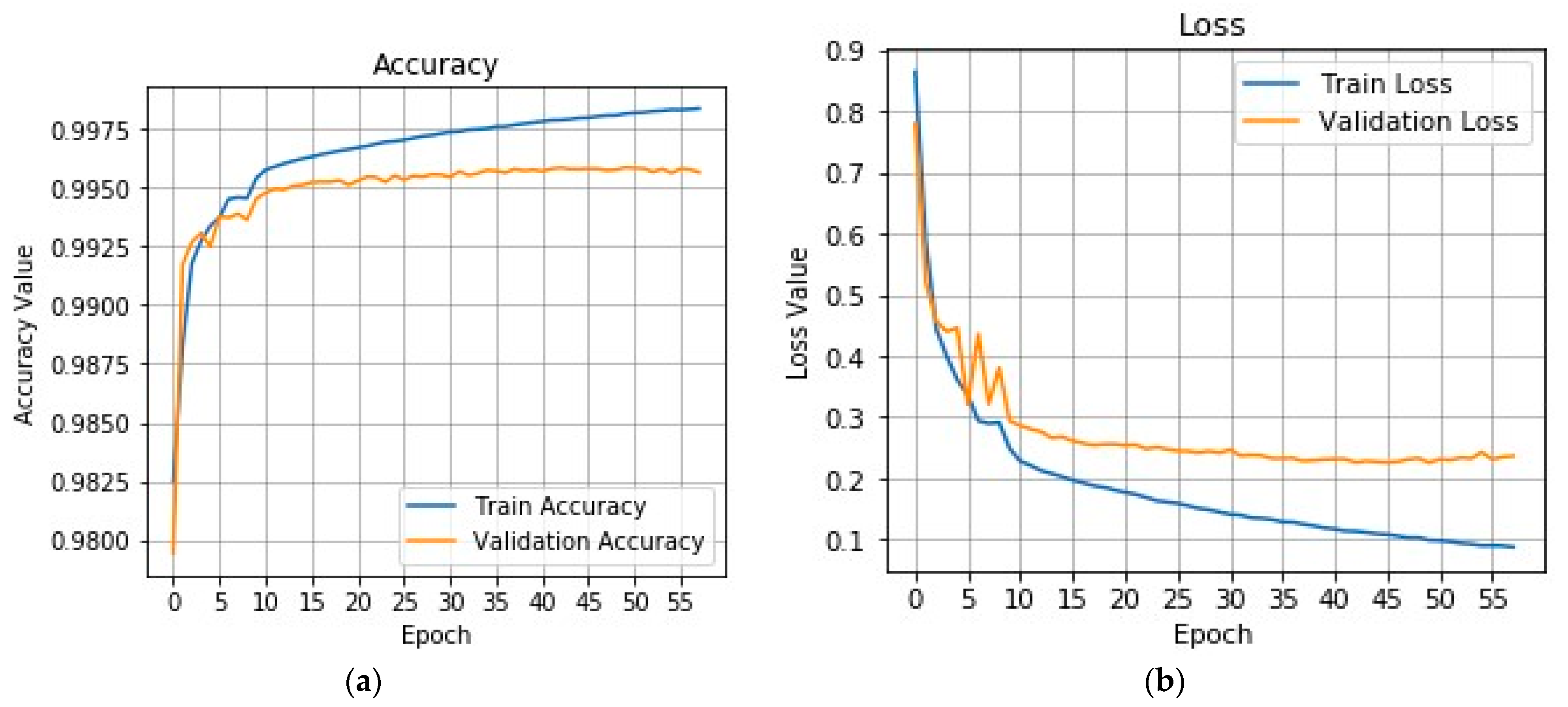
4. Experiments Results
4.1. K-Nearest Neighbors Model (KNN)
4.2. Convolutional Neural Network with the Supper-Vector Machine Model (CNN-SVM)
4.3. Traditional Convolutional Neural Network Model (CNN)
4.4. Modified Deep Convolutional Neural Network (M-CNN)
4.5. Alex- Net, GoogleNet, and VGG-16 Models
4.6. BrainMRNet Model
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MRI | magnetic resonance imaging |
| CNN | convolution neural network |
| WHO | Word Health Organization |
| LG | low grade |
| HG | high grade |
| TUCMD | Tianjin Universal Center of Medical Imaging and Diagnostic |
References
- Goodenberger, M.L.; Jenkins, R.B. Genetics of adult glioma. Cancer Genet. 2012, 205, 613–621. [Google Scholar] [CrossRef] [PubMed]
- Louis, D.N.; Perry, A.; Reifenberger, G.; Von Deimling, A.; Figarella-Branger, D.; Cavenee, W.K.; Ohgaki, H.; Wiestler, O.D.; Kleihues, P.; Ellison, D.W. The 2016 World Health Organization Classification of Tumors of the Central Nervous System: A summary. Acta Neuropathol. 2016, 131, 803–820. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mesfin, F.B.; Al-Dhahir, M.A. Cancer, Brain Gliomas. 2017, pp. 2872–2904. Available online: https://europepmc.org/article/nbk/nbk441874 (accessed on 20 July 2017).
- Afshar, P.; Plataniotis, K.N.; Mohammadi, A. Capsule Networks for Brain Tumor Classification Based on MRI Images and Coarse Tumor Boundaries. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1368–1372. [Google Scholar]
- Badža, M.M.; Barjaktarović, M.Č. Classification of Brain Tumors from MRI Images Using a Convolutional Neural Network. Appl. Sci. 2020, 10, 1999. [Google Scholar] [CrossRef] [Green Version]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohsen, H.; El-Dahshan, E.-S.A.; El-Horbaty, E.-S.M.; Salem, A.-B.M. Classification using deep learning neural networks for brain tumors. Future Comput. Inform. J. 2018, 3, 68–71. [Google Scholar] [CrossRef]
- Zhan, Z.; Cai, J.-F.; Guo, D.; Liu, Y.; Chen, Z.; Qu, X. Fast Multiclass Dictionaries Learning With Geometrical Directions in MRI Reconstruction. IEEE Trans. Biomed. Eng. 2015, 63, 1850–1861. [Google Scholar] [CrossRef] [PubMed]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain Tumor Segmentation Using Convolutional Neural Networks in MRI Images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. (Eds.) Cnn-rnn: A unified framework for multi-label image classifica-tion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Las Vegas, NV, USA, 2016; pp. 2285–2294. [Google Scholar]
- Mzoughi, H.; Njeh, I.; Wali, A.; Ben Slima, M.; Benhamida, A.; Mhiri, C.; Ben Mahfoudhe, K. Deep Multi-Scale 3D Convolutional Neural Network (CNN) for MRI Gliomas Brain Tumor Classification. J. Digit. Imaging 2020, 33, 903–915. [Google Scholar] [CrossRef] [PubMed]
- Bhandari, A.; Koppen, J.; Agzarian, M. Convolutional neural networks for brain tumour segmentation. Insights Imaging 2020, 11, 1–9. [Google Scholar] [CrossRef]
- Pei, L.; Vidyaratne, L.; Rahman, M.; Iftekharuddin, K.M. Context aware deep learning for brain tumor segmentation, subtype classification, and survival prediction using radiology images. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Çinar, A.; Yildirim, M. Detection of tumors on brain MRI images using the hybrid convolutional neural network architecture. Med. Hypotheses 2020, 139, 109684. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. BrainMRNet: Brain tumor detection using magnetic resonance images with a novel convolutional neural network model. Med. Hypotheses 2020, 134, 109531. [Google Scholar] [CrossRef]
- Özyurt, F.; Sert, E.; Avci, E.; Dogantekin, E. Brain tumor detection based on Convolutional Neural Network with neutrosophic expert maximum fuzzy sure entropy. Measurement 2019, 147, 106830. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.; Gul, N.; Yasmin, M.; Shad, S.A. Brain tumor classification based on DWT fusion of MRI sequences using convolutional neural network. Pattern Recognit. Lett. 2020, 129, 115–122. [Google Scholar] [CrossRef]
- Moeskops, P.; Viergever, M.A.; Mendrik, A.M.; De Vries, L.S.; Benders, M.J.N.L.; Isgum, I. Automatic Segmentation of MR Brain Images With a Convolutional Neural Network. IEEE Trans. Med. Imaging 2016, 35, 1252–1261. [Google Scholar] [CrossRef] [Green Version]
- Sourati, J.; Gholipour, A.; Dy, J.G.; Tomas-Fernandez, X.; Kurugol, S.; Warfield, S.K. Intelligent Labeling Based on Fisher Information for Medical Image Segmentation Using Deep Learning. IEEE Trans. Med. Imaging 2019, 38, 2642–2653. [Google Scholar] [CrossRef]
- Thyreau, B.; Taki, Y. Learning a cortical parcellation of the brain robust to the MRI segmentation with convolutional neural networks. Med. Image Anal. 2020, 61, 101639. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Anitha, J.; Naaji, A.; Geman, O.; Popescu, D.E.; Son, L.H.; Hoang, L. A Modified Deep Convolutional Neural Network for Abnormal Brain Image Classification. IEEE Access 2018, 7, 4275–4283. [Google Scholar] [CrossRef]
- Zhou, X.; Li, X.; Hu, K.; Zhang, Y.; Chen, Z.; Gao, X. ERV-Net: An efficient 3D residual neural network for brain tumor segmentation. Expert Syst. Appl. 2021, 170, 114566. [Google Scholar] [CrossRef]
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S.A.C. Multimodal brain tumor classification using deep learning and robust feature selection: A ma-chine learning application for radiologists. Diagnostics 2020, 10, 565. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Shi, L.; Liu, W.; Zhang, H.; Xie, Y.; Wang, D. A survey of GPU-based medical image computing techniques. Quant. Imaging Med. Surg. 2012, 2, 188–206. [Google Scholar]
- Kussul, E.; Baidyk, T. Improved method of handwritten digit recognition tested on MNIST database. Image Vis. Comput. 2004, 22, 971–981. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Mohamed, A.-R.; Dahl, G.E.; Hinton, G. Acoustic Modeling Using Deep Belief Networks. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 14–22. [Google Scholar] [CrossRef]
- Yang, J.; Xie, F.; Fan, H.; Jiang, Z.; Liu, J. Classification for Dermoscopy Images Using Convolutional Neural Networks Based on Region Average Pooling. IEEE Access 2018, 6, 65130–65138. [Google Scholar] [CrossRef]
- Jia, Y.; Huang, C.; Darrell, T. Beyond spatial pyramids: Receptive field learning for pooled image features. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3370–3377. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Matsuda, Y.; Hoashi, H.; Yanai, K. Recognition of Multiple-Food Images by Detecting Candidate Regions. IEEE Int. Conf. Multimed. Expo 2012. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Ni, D.; Qin, J.; Li, S.; Yang, X.; Wang, T.; Heng, P.A. Standard Plane Localization in Fetal Ultrasound via Domain Transferred Deep Neural Networks. IEEE J. Biomed. Health Inform. 2015, 19, 1627–1636. [Google Scholar] [CrossRef]
- Lei, B.; Huang, S.; Li, R.; Bian, C.; Li, H.; Chou, Y.-H.; Cheng, J.-Z. Segmentation of breast anatomy for automated whole breast ultrasound images with boundary regularized convolutional encoder–decoder network. Neurocomputing 2018, 321, 178–186. [Google Scholar] [CrossRef]
- Sarıgül, M.; Ozyildirim, B.; Avci, M. Differential convolutional neural network. Neural Netw. 2019, 116, 279–287. [Google Scholar] [CrossRef]
- Chavan, N.V.; Jadhav, B.; Patil, P. Detection and classification of brain tumors. Int. J. Comput. Appl. 2015, 112, 8887. [Google Scholar]
- Özyurt, F.; Sert, E.; Avcı, D. An expert system for brain tumor detection: Fuzzy C-means with super resolution and convolutional neural network with extreme learning machine. Med. Hypotheses 2020, 134, 109433. [Google Scholar] [CrossRef] [PubMed]
- Toğaçar, M.; Ergen, B.; Cömert, Z.; Özyurt, F. A Deep Feature Learning Model for Pneumonia Detection Applying a Combination of mRMR Feature Selection and Machine Learning Models. IRBM 2020, 41, 212–222. [Google Scholar] [CrossRef]
- Budak, Ü.; Cömert, Z.; Rashid, Z.N.; Şengür, A.; Çıbuk, M. Computer-aided diagnosis system combining FCN and Bi-LSTM model for efficient breast cancer detection from histopathological images. Appl. Soft. Comput. 2019, 85, 105765. [Google Scholar] [CrossRef]
- Babaeizadeh, M.; Smaragdis, P.; Campbell, R.H. A Simple yet Effective Method to Prune Dense Layers of Neural Networks. 2016. Available online: https://openreview.net/pdf?id=HJIY0E9ge (accessed on 6 February 2017).
- Sajjad, M.; Khan, S.; Muhammad, K.; Wu, W.; Ullah, A.; Baik, S.W. Multi-grade brain tumor classification using deep CNN with extensive data augmentation. J. Comput. Sci. 2019, 30, 174–182. [Google Scholar] [CrossRef]
- Sultan, H.H.; Salem, N.M.; Al-Atabany, W. Multi-Classification of Brain Tumor Images Using Deep Neural Network. IEEE Access 2019, 7, 69215–69225. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I.; Akram, F.; Imran, M. A Deep Learning-Based Framework for Automatic Brain Tumors Classification Using Transfer Learning. Circuits Syst. Signal Process. 2020, 39, 757–775. [Google Scholar] [CrossRef]
- Cheng, J.; Huang, W.; Cao, S.; Yang, R.; Yang, W.; Yun, Z.; Wang, Z.; Feng, Q. Correction: Enhanced Performance of Brain Tumor Classification via Tumor Region Augmentation and Partition. PLoS ONE 2015, 10, e0144479. [Google Scholar] [CrossRef]
- Tripathi, P.C.; Bag, S. Non-invasively Grading of Brain Tumor Through Noise Robust Textural and Intensity Based Features. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 531–539. [Google Scholar]
- Pashaei, A.; Ghatee, M.; Sajedi, H. Convolution neural network joint with mixture of extreme learning machines for feature extraction and classification of accident images. J. Real-Time Image Process. 2020, 17, 1051–1066. [Google Scholar] [CrossRef]
- Gumaei, A.; Hassan, M.M.; Hassan, R.; Alelaiwi, A.; Fortino, G. A Hybrid Feature Extraction Method With Regularized Extreme Learning Machine for Brain Tumor Classification. IEEE Access 2019, 7, 36266–36273. [Google Scholar] [CrossRef]
- Ge, C.; Gu, I.Y.-H.; Jakola, A.S.; Yang, J. Deep Learning and Multi-Sensor Fusion for Glioma Classification Using Multistream 2D Convolutional Networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; Volume 2018, pp. 5894–5897. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Number of Feature Maps | Kernel Size | Stride | Size of Feature Maps |
|---|---|---|---|---|
| Input | 11 | 1020 × 1020 | ||
| Convolution (1) | 12 | 2 | 2 | 500 × 500 × 12 |
| Pooling (1) | 1 | 5 | 250 × 250 × 12 | |
| Convolution (2) | 5 | 2 | 1 | 250 × 250 × 60 |
| Pooling (2) | 1 | 6 | 125 × 125 × 60 | |
| Convolution (3) | 5 | 3 | 1 | 120 × 120 × 300 |
| Pooling (3) | 1 | 3 | 40 × 40 × 300 | |
| Convolution (4) | 2 | 2 | 1 | 40 × 40 × 600 |
| Pooling (4) | 1 | 3 | 20 × 20 × 600 | |
| Convolution (5) | 1 | 3 | 1 | 18 × 18 × 600 |
| Pooling (5) | 1 | 6 × 6 × 600 | ||
| F1 | 21,600 |
| Model | Accuracy % | Sensitivity % | Specificity % | Precision % | F-Score % |
|---|---|---|---|---|---|
| KNN | 78 | 46 | 50 | 72.11 | 68 |
| CNN-SVM | 95.62 | - | 95 | 92.12 | 93.11 |
| CNN | 96.5 | 95.07 | - | 94.81 | 94.93 |
| M-CNN | 96.4 | 95 | 93 | 95.7 | 94.2 |
| Alex_Net | 87.66 | 84.38 | 92.31 | 93.1 | 88.52 |
| Google-Net | 89.66 | 84.85 | 96 | 96.55 | 90.32 |
| VGG-16 | 84.48 | 81.25 | 88.48 | 89.66 | 85.25 |
| BrainMRNet | 96.5 | 95 | 93 | 92.3 | 94.12 |
| Proposed differential deep-CNN | 99.25 | 95.89 | 93.75 | 97.22 | 95.23 |
| Model/Year | Data | Model | Accuracy % |
|---|---|---|---|
| Phaye et al. [47] | Accidents Images | CNN | 93.68 |
| Gumaei et al. [48] | MRI | ELM-KELM | 94.23 |
| Muhammad Attique Khan et al. [23] | MRI BRATS | (ERV-Net) | 97.8 |
| Ge et al. [49] | MRI | Multi-stream CNN | 90.87 |
| Proposed differential deep-CNN | MRI | Differential D-CNN | 99.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abd El Kader, I.; Xu, G.; Shuai, Z.; Saminu, S.; Javaid, I.; Salim Ahmad, I. Differential Deep Convolutional Neural Network Model for Brain Tumor Classification. Brain Sci. 2021, 11, 352. https://doi.org/10.3390/brainsci11030352
Abd El Kader I, Xu G, Shuai Z, Saminu S, Javaid I, Salim Ahmad I. Differential Deep Convolutional Neural Network Model for Brain Tumor Classification. Brain Sciences. 2021; 11(3):352. https://doi.org/10.3390/brainsci11030352
Chicago/Turabian StyleAbd El Kader, Isselmou, Guizhi Xu, Zhang Shuai, Sani Saminu, Imran Javaid, and Isah Salim Ahmad. 2021. "Differential Deep Convolutional Neural Network Model for Brain Tumor Classification" Brain Sciences 11, no. 3: 352. https://doi.org/10.3390/brainsci11030352
APA StyleAbd El Kader, I., Xu, G., Shuai, Z., Saminu, S., Javaid, I., & Salim Ahmad, I. (2021). Differential Deep Convolutional Neural Network Model for Brain Tumor Classification. Brain Sciences, 11(3), 352. https://doi.org/10.3390/brainsci11030352