
Diagnostic Classification and Biomarker Identification of Alzheimer’s Disease with Random Forest Algorithm †



Abstract
:1. Introduction
2. Materials and Methods
2.1. Brain MRI Data
2.2. Feature Selection
2.3. Random Forest Algorithm (RF)
2.4. Classification Analysis
2.5. RF-Based Biomarker Analysis
3. Results
3.1. Classification Accuracy
3.2. Biomarker Identification
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alzheimer’s Association. Alzheimer’s Association 2016 Alzheimer’s Disease Facts and Figures. Alzheimers Dement. 2016, 12, 459–509. [Google Scholar] [CrossRef] [PubMed]
- Lahiri, D.K.; Farlow, M.R.; Greig, N.H.; Sambamurti, K. Current Drug Targets for Alzheimer’s Disease Treatment. Drug Dev. Res. 2002, 56, 267–281. [Google Scholar] [CrossRef]
- Morris, J.C. The Clinical Dementia Rating (CDR): Current Version and Scoring Rules. Neurology 1993, 43, 2412–2414. [Google Scholar] [CrossRef]
- Teng, E.L.; Chui, H.C.; Schneider, L.S.; Metzger, L.E. Alzheimer’s Dementia: Performance on the Mini-Mental State Examination. J. Consult. Clin. Psychol. 1987, 55, 96–100. [Google Scholar] [CrossRef]
- Gauthier, S.; Reisberg, B.; Zaudig, M.; Petersen, R.; Ritchie, K.; Broich, K.; Belleville, S.; Brodaty, H.; Bebbet, D.; Chertkow, H.; et al. Mild Cognitive Impairment. Lancet 2006, 367, 1262–1270. [Google Scholar] [CrossRef]
- Sepulcre, J.; Schultz, A.P.; Sabuncu, M.; Gomez-Isla, T.; Chhatwal, J.; Becker, A.; Sperling, R.; Johnson, K.A. In Vivo Tau, Amyloid, and Gray Matter Profiles in the Aging Brain. J. Neurosci. 2016, 36, 7364–7374. [Google Scholar] [CrossRef] [Green Version]
- Blennow, K. Cerebrospinal Fluid Protein Biomarkers for Alzheimer’s Disease. J. Am. Soc. Exp. Neurother. 2004, 1, 213–225. [Google Scholar] [CrossRef]
- Geekiyanage, H.; Jicha, G.A.; Nelson, P.T.; Chan, C. Blood Serum MiRNA: Non-Invasive Biomarkers for Alzheimer’s Disease. Exp. Neurol. 2012, 235, 491–496. [Google Scholar] [CrossRef] [Green Version]
- Scinto, L.F.; Daffner, K.R.; Dressler, D.; Ransil, B.I.; Rentz, D.; Weintraub, S.; Mesulam, M.; Potter, H. A Potential Noninvasive Neurobiological Test for Alzheimer’s Disease. Science 1994, 266, 1051–1054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jeong, J. EEG Dynamics in Patients with Alzheimer’s Disease. Clin. Neurophysiol. 2004, 115, 1490–1505. [Google Scholar] [CrossRef]
- Ieracitano, C.; Mammone, N.; Bramanti, A.; Hussain, A.; Morabito, F.C. A Convolutional Neural Network Approach for Classification of Dementia Stages Based on 2D-Spectral Representation of EEG Recordings. Neurocomputing 2019, 323, 96–107. [Google Scholar] [CrossRef]
- Ieracitano, C.; Mammone, N.; Hussain, A.; Morabito, F.C. A Novel Multi-Modal Machine Learning Based Approach for Automatic Classification of EEG Recordings in Dementia. Neural Netw. 2020, 123, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Mammone, N.; Ieracitano, C.; Adeli, H.; Bramanti, A.; Morabito, F.C. Permutation Jaccard Distance-Based Hierarchical Clustering to Estimate EEG Network Density Modifications in MCI Subjects. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5122–5135. [Google Scholar] [CrossRef]
- Mammone, N.; Salvo, S.D.; Bonanno, L.; Ieracitano, C.; Marino, S.; Marra, A.; Bramanti, A.; Morabito, F.C. Brain Network Analysis of Compressive Sensed High-Density EEG Signals in AD and MCI Subjects. IEEE Trans. Ind. Inform. 2019, 15, 527–536. [Google Scholar] [CrossRef]
- Wenk, G.L. Neuropathologic Changes in Alzheimer’s Disease. J. Clin. Psychiatry 2003, 64, 7–10. [Google Scholar] [PubMed]
- Chincarini, A.; Bosco, P.; Calvini, P.; Gemme, G.; Esposito, M.; Olivieri, C.; Rei, L.; Squarcia, S.; Rodriguez, G.; Bellotti, R.; et al. Local MRI Analysis Approach in the Diagnosis of Early and Prodromal Alzheimer’s Disease. NeuroImage 2011, 58, 469–480. [Google Scholar] [CrossRef] [PubMed]
- Salvatore, C.; Cerasa, A.; Battista, P.; Gilardi, M.C.; Quattrone, A.; Castiglioni, I. Magnetic Resonance Imaging Biomarkers for the Early Diagnosis of Alzheimer’s Disease: A Machine Learning Approach. Front. Neurosci. 2015, 9. [Google Scholar] [CrossRef] [Green Version]
- Oh, K.; Chung, Y.-C.; Kim, K.W.; Kim, W.-S.; Oh, I.-S. Classification and Visualization of Alzheimer’s Disease Using Volumetric Convolutional Neural Network and Transfer Learning. Sci. Rep. 2019, 9, 18150. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An Empirical Comparison of Supervised Learning Algorithms. In Proceedings of the 23rd international conference on Machine learning—ICML ’06, Pittsburgh, PA, USA, 25–29 June 2006; ACM Press: Pittsburgh, PA, USA, 2006; pp. 161–168. [Google Scholar]
- Menze, B.H.; Kelm, B.M.; Masuch, R.; Himmelreich, U.; Bachert, P.; Petrich, W.; Hamprecht, F.A. A Comparison of Random Forest and Its Gini Importance with Standard Chemometric Methods for the Feature Selection and Classification of Spectral Data. BMC Bioinform. 2009, 10, 213. [Google Scholar] [CrossRef] [Green Version]
- Calle, M.L.; Urrea, V.; Boulesteix, A.-L.; Malats, N. AUC-RF: A New Strategy for Genomic Profiling with Random Forest. Hum. Hered. 2011, 72, 121–132. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Wang, M.; Zhang, H. The Use of Classification Trees for Bioinformatics. WIREs Data Min. Knowl. Discov. 2011, 1, 55–63. [Google Scholar] [CrossRef] [PubMed]
- Sarica, A.; Cerasa, A.; Valentino, P.; Yeatman, J.; Trotta, M.; Barone, S.; Granata, A.; Nisticò, R.; Perrotta, P.; Pucci, F.; et al. The Corticospinal Tract Profile in Amyotrophic Lateral Sclerosis: Corticospinal Tract Profile. Hum. Brain Mapp. 2017, 38, 727–739. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R.; Bernstein, M.A.; Fox, N.C.; Thompson, P.; Alexander, G.; Harvey, D.; Borowski, B.; Britson, P.J.; Whitwell, J.L.; Ward, C.; et al. The Alzheimer’s Disease Neuroimaging Initiative (ADNI): MRI Methods. J. Magn. Reson. Imaging 2008, 27, 685–691. [Google Scholar] [CrossRef] [Green Version]
- Fischl, B. FreeSurfer. NeuroImage 2012, 62, 774–781. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; CRC: Boca Raton, FL, USA, 1983; ISBN 978-0-412-04841-8. [Google Scholar]
- Sarica, A. Random Forest Algorithm for the Classification of Neuroimaging Data in Alzheimer’s Disease: A Systematic Review. Front. Aging Neurosci. 2017, 9, 12. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019; p. 12. [Google Scholar]
- Henneman, W.J.P.; Sluimer, J.D.; Barnes, J.; van der Flier, W.M.; Sluimer, I.C.; Fox, N.C.; Scheltens, P.; Vrenken, H.; Barkhof, F. Hippocampal Atrophy Rates in Alzheimer Disease: Added Value over Whole Brain Volume Measures. Neurology 2009, 72, 999–1007. [Google Scholar] [CrossRef] [Green Version]
- Poulin, S.P.; Dautoff, R.; Morris, J.C.; Barrett, L.F.; Dickerson, B.C. Amygdala Atrophy Is Prominent in Early Alzheimer’s Disease and Relates to Symptom Severity. Psychiatry Res. Neuroimaging 2011, 194, 7–13. [Google Scholar] [CrossRef] [Green Version]
- Bear, M.; Connors, B.; Paradiso, M. NeuroScience: Exploring the Brain, 4th ed.; Wolters Kluwer: Philadelphia, PA, USA, 2015; ISBN 978-1-4511-0954-2. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. arXiv 2019, arXiv:191010045v2. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Schoemaker, D.; Buss, C.; Head, K.; Sandman, C.A.; Davis, E.P.; Chakravarty, M.M.; Gauthier, S.; Pruessner, J.C. Hippocampus and Amygdala Volumes from Magnetic Resonance Images in Children: Assessing Accuracy of FreeSurfer and FSL against Manual Segmentation. NeuroImage 2016, 129, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Hoesen, G.W.; Hyman, B.T.; Damasio, A.R. Entorhinal Cortex Pathology in Alzheimer’s Disease. Hippocampus 1991, 1, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Du, A.T.; Schuff, N.; Amend, D.; Laakso, M.P.; Hsu, Y.Y.; Jagust, W.J.; Yaffe, K.; Kramer, J.H.; Reed, B.; Norman, D.; et al. Magnetic Resonance Imaging of the Entorhinal Cortex and Hippocampus in Mild Cognitive Impairment and Alzheimer’s Disease. J. Neurol. Neurosurg. Psychiatry 2001, 71, 441–447. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- deToledo-Morrell, L.; Stoub, T.R.; Bulgakova, M.; Wilson, R.S.; Bennett, D.A.; Leurgans, S.; Wuu, J.; Turner, D.A. MRI-Derived Entorhinal Volume Is a Good Predictor of Conversion from MCI to AD. Neurobiol. Aging 2004, 25, 1197–1203. [Google Scholar] [CrossRef]





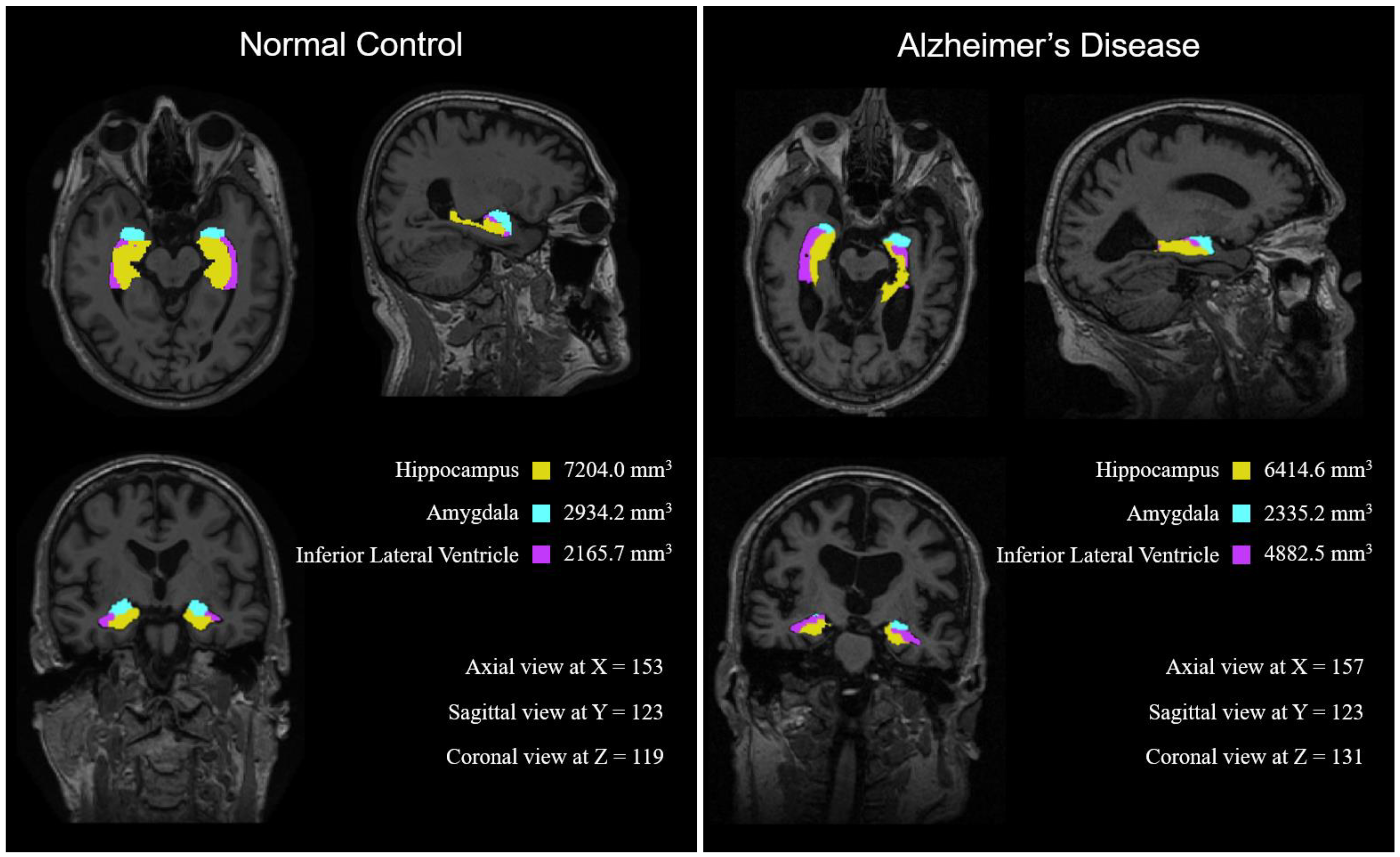

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NC | MCI | AD | |
|---|---|---|---|
| Subjects | 687 | 1094 | 469 |
| (Male, Female) | (357, 330) | (702, 392) | (249, 220) |
| Age | 76.41 ± 5.07 | 75.42 ± 7.08 | 75.05 ± 7.60 |
| CDR (Clinical Dementia Rating) | 0.01 ± 0.13 | 0.51 ± 0.14 | 0.85 ± 0.41 |
| (No. of subjects 1) | (687) | (1091) | (468) |
| MMSE (Mini-Mental State Exam) | 29.07 ± 1.11 | 26.51 ± 2.62 | 22.42 ± 3.32 |
| (No. of subjects 1) | (686) | (1090) | (468) |
| Name | Description | Name | Description |
|---|---|---|---|
| BrainSeg | Brain segmentation volume | Caudate | Volume of caudate |
| BrainSeg NotVent | Brain segmentation volume without ventricles | Putamen | Volume of putamen |
| BrainSeg NotVentSurf | Brain segmentation volume without ventricles from surf | Pallidum | Volume of pallidum |
| Ventricle ChoroidVol | Volume of ventricles and choroid plexus | 3rd-Ventricle | Volume of 3rd-Ventricle |
| Cortex | Total cortical gray matter volume | 4th-Ventricle | Volume of 4th-Ventricle |
| Cerebral WhiteMatter | Total cerebral white matter volume | 5th-Ventricle | Volume of 5th Ventricle |
| SubCortGray | Subcortical gray matter volume | Brain-Stem | Volume of brainstem |
| TotalGray | Total gray matter volume | Hippocampus | Volume of hippocampus |
| SupraTentorial | Supratentorial volume | Amygdala | Volume of amygdala |
| SupraTentorial NotVent | Supratentorial volume without ventricles | CSF | Volume of cerebrospinal fluid |
| SupraTentorial NotVentVox | Supratentorial volume without ventricles voxel count | Accumbens-area | Volume of the nucleus accumbens |
| Mask | Mask (skull tripped) volume | VentralDC | Volume of ventral diencephalon |
| BrainSegVol-to-eTIV | Ratio of BrainSegVol to eTIV | vessel | Total volume of the brain vessel |
| MaskVol-to-eTIV | Ratio of MaskVol to eTIV | choroid-plexus | Volume of choroid plexus |
| SurfaceHoles | Total number of defect holes in surfaces prior to fixing | WM-hypointensities | Dark white matter on a T1-weighted image |
| EstimatedTotal IntraCraniaVol | Estimated total intracranial volume | non-WM-hypointensities | Dark gray matter on a T1-weighted image |
| Lateral-Ventricle | Lateral-Ventricle volume | Optic-Chiasm | Volume of optic chiasm |
| Inf-Lat-Vent | Inferior Lateral Ventricle volume | CC_Posterior | Volume of the corpus callosum in the posterior subcortical |
| Cerebellum-White-Matter | Total cerebellum white matter volume | CC_Central | Volume of the corpus callosum in the central subcortical |
| Cerebellum-Cortex | Cerebellum cortical gray matter volume | CC_Anterior | Volume of the corpus callosum in the anterior subcortical |
| Thalamus-Proper | Total Thalamus area volume |
| Precision | Recall | F1-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|
| NC | MCI | AD | NC | MCI | AD | NC | MCI | AD | |
| 63 features | 92.9% | 86.5% | 97.9% | 91.2% | 96.5% | 74.1% | 92.0% | 91.2% | 84.4% |
| 29 features | 89.2% | 84.9% | 94.9% | 89.1% | 93.4% | 73.3% | 89.1% | 88.9% | 82.5% |
| 22 features | 88.3% | 83.9% | 93.9% | 87.9% | 93.3% | 70.5% | 88.0% | 88.3% | 80.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, M.; Jung, H.; Lee, S.; Kim, D.; Ahn, M. Diagnostic Classification and Biomarker Identification of Alzheimer’s Disease with Random Forest Algorithm. Brain Sci. 2021, 11, 453. https://doi.org/10.3390/brainsci11040453
Song M, Jung H, Lee S, Kim D, Ahn M. Diagnostic Classification and Biomarker Identification of Alzheimer’s Disease with Random Forest Algorithm. Brain Sciences. 2021; 11(4):453. https://doi.org/10.3390/brainsci11040453
Chicago/Turabian StyleSong, Minseok, Hyeyoom Jung, Seungyong Lee, Donghyeon Kim, and Minkyu Ahn. 2021. "Diagnostic Classification and Biomarker Identification of Alzheimer’s Disease with Random Forest Algorithm" Brain Sciences 11, no. 4: 453. https://doi.org/10.3390/brainsci11040453
APA StyleSong, M., Jung, H., Lee, S., Kim, D., & Ahn, M. (2021). Diagnostic Classification and Biomarker Identification of Alzheimer’s Disease with Random Forest Algorithm. Brain Sciences, 11(4), 453. https://doi.org/10.3390/brainsci11040453