
A Bayesian Mixture Modelling of Stop Signal Reaction Time Distributions: The Second Contextual Solution for the Problem of Aftereffects of Inhibition on SSRT Estimations



Abstract
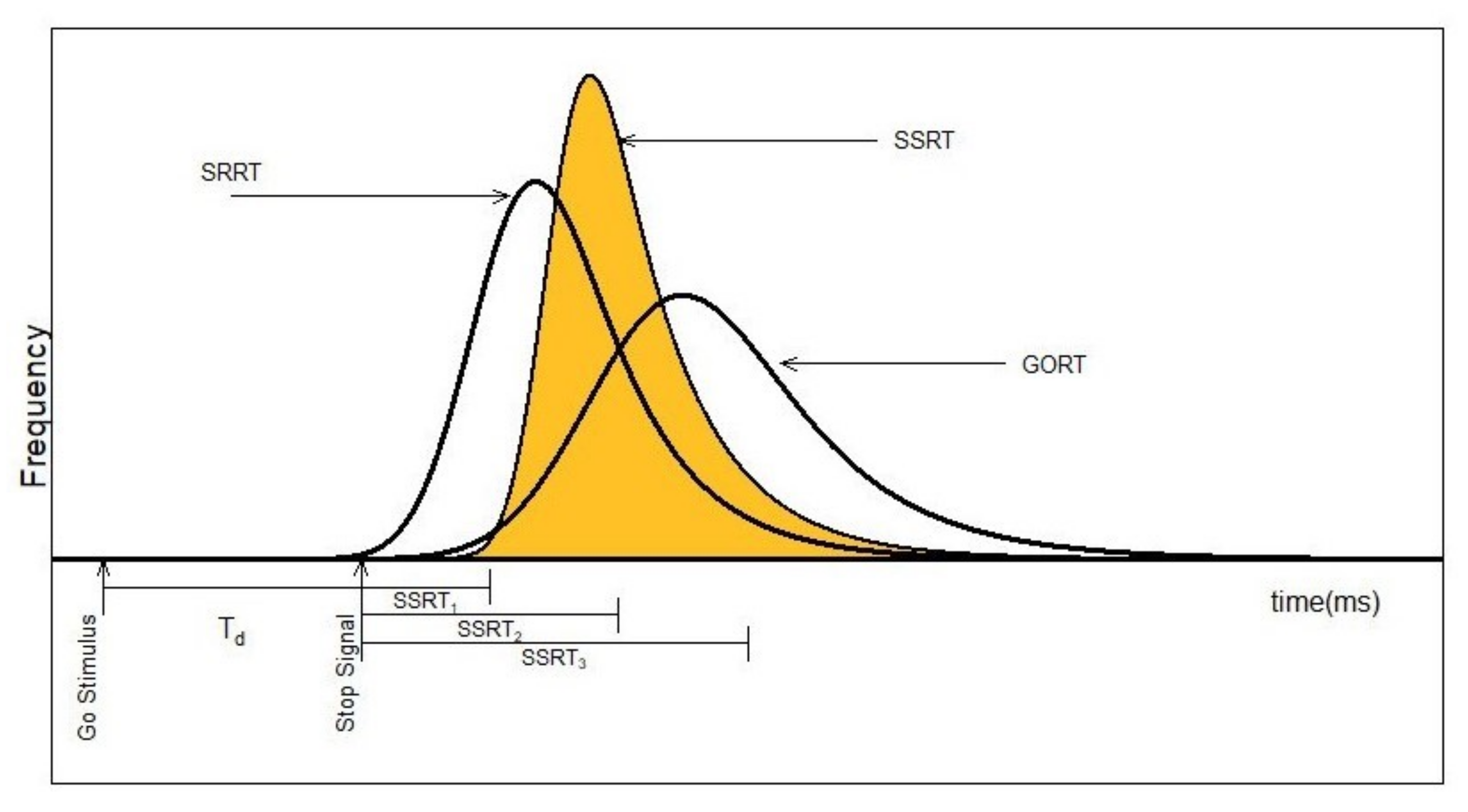
:1. Introduction
1.1. Reactive Inhibition
1.2. Estimation Methods: Context and Components
1.3. SSRT Estimation and Aftereffects of Inhibition: Constant vs. Distribution
1.3.1. The Assumption
1.3.2. Constant Index
1.3.3. Motivation
1.4. Study Outline
2. Materials and Methods
2.1. The Data and Study Design
2.2. The Sample and Variables
2.2.1. Cluster Type SST Data
- 1
- Type-A SST data cluster: all trial preceded by go trials (See Appendix A)
- 2
- Type-B SST data cluster: all trials preceded by stop trials (See Appendix A)
- 3
- Type-S Single SST data cluster: all trials when considered for one single SSRT distribution
- 4
- Type-M Mixture SST data cluster: all trials when considered for the mixture SSRT distribution.
2.2.2. Ex-Gaussian Random Variable
2.2.3. Mixture SSRT Random Variable
- : Number of cluster types,
- : Number of trials in SST data,
- : Parameters of Ex-Gaussian SSRT distribution of the ith cluster
- Here:
- Here:
- Here:
- Prior Probability of clusters
- : ith SST trial,
2.3. Statistical Analysis
2.3.1. Comparisons Context: Real Numbers and Random Variables
2.3.2. Comparisons Procedure: Random Variables
| Stage (1) | |
| Data | Individual Priors |
| Stage (2) | |
| Data | Priors |
3. Results
3.1. Descriptive and Shape Statistics
3.2. Bayesian Mixture SSRT Estimation and Comparisons
3.3. The Role of Cluster Type Weights in the Comparisons
4. Discussion
4.1. Present Work
- The descriptive and shape statistics
- The distributional comparisons at the individual level and the population level
- With the validity of the results in the first two observations across the entire spectrum of the weights
4.2. Future Work
4.3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADHD | Attention Deficit Hyperactivity Disorder |
| BEESTS | Bayesian Ex-Gaussian Estimation of Stop Signal RT distributions |
| BPA | Bayesian Parametric Approach |
| ExG | Ex-Gaussian distribution |
| FWER | Family-Wise Error Rate |
| GORT | Reaction Time in a go trial |
| GORTA | Reaction Time in a type A go trial |
| GORTB | Reaction Time in a type B go trial |
| HBPA | Hierarchical Bayesian Parametric Approach |
| IBPA | Individual Bayesian Parametric Approach |
| MCMC | Marco Chain Monte Carlo |
| OCD | Obsessive Compulsive Disorder |
| PSPDT | Paired Samples Parametric Distribution Test |
| SSD | Stop Signal Delay |
| SRRT | Reaction Time in a failed stop trial |
| SRRTA | Reaction Time in a failed type A stop trial |
| SRRTB | Reaction Time in a failed type B stop trial |
| SSRT | Stop Signal Reaction Times in a stop trial |
| SSRTA | Stop Signal Reaction Times in a type A stop trial |
| SSRTB | Stop Signal Reaction Times in a type B stop trial |
| SST | Stop Signal Task |
| TF | Trigger Failure |
| TSBPA | Two-Stage Bayesian Parametric Approach |
Appendix A. Sample SST Data and Its Clusters
| Block | Trial | GORT (ms) | SRRT (ms) | SSD (ms) | Trial | Inhibition | Cluster |
| 1 | 1 | 356.4 | −999 | −999 | Go | NA | A |
| 1 | 2 | 426.5 | −999 | −999 | Go | NA | A |
| 1 | 3 | −999 | 380 | 350 | Stop | 0 | A |
| 1 | 4 | 397.2 | −999 | −999 | Go | NA | B |
| 1 | 5 | −999 | −999 | 200 | Stop | 1 | A |
| 1 | 6 | −999 | −999 | 100 | Stop | 1 | B |
| 1 | 7 | 283.6 | −999 | −999 | Go | NA | B |
| 1 | 8 | 457.3 | −999 | −999 | Go | NA | A |
| 1 | 9 | 361.9 | −999 | −999 | Go | NA | A |
| 1 | 10 | 375.7 | −999 | −999 | Go | NA | A |
| 1 | 11 | 478.5 | −999 | −999 | Go | NA | A |
| 1 | 12 | 355.9 | −999 | −999 | Go | NA | A |
| 1 | 13 | −999 | −999 | 150 | Stop | 1 | A |
| 1 | 14 | 300.5 | −999 | −999 | Go | NA | B |
| 1 | 15 | 347 | −999 | −999 | Go | NA | A |
| 1 | 16 | 390.3 | −999 | −999 | Go | NA | A |
| 1 | 17 | 327.2 | −999 | −999 | Go | NA | A |
| 1 | 18 | 300.4 | −999 | −999 | Go | NA | A |
| 1 | 19 | 382.2 | −999 | −999 | Go | NA | A |
| 1 | 20 | 326.9 | −999 | −999 | Go | NA | A |
| 1 | 21 | −999 | 389.8 | 200 | Stop | 0 | A |
| 1 | 22 | −999 | 445.4 | 200 | Stop | 0 | B |
| 1 | 23 | 352.4 | −999 | −999 | Go | NA | B |
| 1 | 24 | 403.1 | −999 | −999 | Go | NA | A |
| 2 | 1 | 256.4 | −999 | −999 | Go | NA | A |
| 2 | 2 | 426.5 | −999 | −999 | Go | NA | A |
| 2 | 3 | −999 | 360 | 350 | Stop | 0 | A |
| 2 | 4 | 353.2 | −999 | −999 | Go | NA | B |
| 2 | 5 | −999 | −999 | 200 | Stop | 1 | A |
| 2 | 6 | −999 | −999 | 100 | Stop | 1 | B |
| 2 | 7 | 253.6 | −999 | −999 | Go | NA | B |
| 2 | 8 | 427.3 | −999 | −999 | Go | NA | A |
| 2 | 9 | 351.9 | −999 | −999 | Go | NA | A |
| 2 | 10 | 355.7 | −999 | −999 | Go | NA | A |
| 2 | 11 | 455.5 | −999 | −999 | Go | NA | A |
| 2 | 12 | 335.9 | −999 | −999 | Go | NA | A |
| 2 | 13 | −999 | −999 | 150 | Stop | 1 | A |
| 2 | 14 | 321.5 | −999 | −999 | Go | NA | B |
| 2 | 15 | 322 | −999 | −999 | Go | NA | A |
| 2 | 16 | 340.5 | −999 | −999 | Go | NA | A |
| 2 | 17 | 317.2 | −999 | −999 | Go | NA | A |
| 2 | 18 | 303.1 | −999 | −999 | Go | NA | A |
| 2 | 19 | 322.9 | −999 | −999 | Go | NA | A |
| 2 | 20 | 316.5 | −999 | −999 | Go | NA | A |
| 2 | 21 | −999 | 368.7 | 200 | Stop | 0 | A |
| 2 | 22 | −999 | 435.2 | 200 | Stop | 0 | B |
| 2 | 23 | 342.3 | −999 | −999 | Go | NA | B |
| 2 | 24 | 413.5 | −999 | −999 | Go | NA | A |
Appendix B. SSRT ExG Cluster Type Parameter Estimations
| Parameter | Parameter | Parameter | |||||||
| # | |||||||||
| 1 | 67.899 | 110.575 | 74.101 | 92.015 | 174.890 | 128.896 | 118.238 | 180.543 | 96.303 |
| 2 | 80.776 | 134.302 | 74.966 | 115.760 | 161.009 | 114.076 | 98.747 | 164.481 | 72.904 |
| 3 | 101.214 | 73.414 | 240.510 | 69.946 | 86.953 | 246.686 | 62.308 | 58.302 | 224.543 |
| 4 | 76.125 | 101.214 | 81.148 | 70.314 | 97.988 | 161.328 | 60.001 | 103.904 | 87.476 |
| 5 | 107.774 | 115.981 | 144.308 | 133.990 | 216.231 | 136.901 | 137.250 | 175.537 | 120.983 |
| 6 | 82.189 | 72.291 | 116.641 | 80.937 | 104.697 | 152.139 | 66.669 | 82.550 | 129.349 |
| 7 | 91.065 | 102.595 | 98.262 | 98.313 | 187.322 | 160.173 | 61.743 | 107.831 | 96.720 |
| 8 | 104.330 | 104.326 | 161.787 | 132.146 | 119.162 | 217.623 | 109.687 | 102.335 | 167.392 |
| 9 | 65.595 | 79.870 | 102.948 | 90.731 | 166.297 | 139.209 | 54.418 | 92.445 | 102.436 |
| 10 | 51.841 | 57.038 | 118.292 | 138.916 | 90.925 | 244.038 | 87.252 | 57.347 | 163.274 |
| 11 | 68.697 | 101.933 | 87.970 | 96.996 | 180.128 | 120.074 | 69.633 | 123.469 | 89.641 |
| 12 | 46.706 | 104.368 | 58.037 | 163.780 | 185.456 | 139.646 | 59.603 | 140.534 | 62.199 |
| 13 | 68.347 | 132.873 | 74.025 | 153.626 | 245.102 | 144.620 | 78.252 | 175.639 | 80.781 |
| 14 | 97.394 | 96.609 | 227.966 | 173.632 | 130.787 | 247.703 | 130.172 | 98.451 | 205.539 |
| 15 | 82.559 | 72.106 | 129.965 | 77.780 | 126.941 | 142.630 | 67.081 | 82.437 | 139.205 |
| 16 | 117.957 | 171.526 | 95.175 | 95.554 | 171.345 | 104.171 | 128.851 | 214.714 | 98.275 |
| 17 | 64.794 | 94.754 | 76.374 | 114.202 | 123.549 | 203.176 | 58.881 | 107.584 | 89.813 |
| 18 | 87.286 | 193.774 | 120.393 | 155.274 | 209.582 | 184.605 | 96.340 | 200.869 | 122.920 |
| 19 | 94.714 | 125.221 | 81.660 | 111.226 | 168.084 | 136.605 | 99.098 | 159.208 | 100.093 |
| 20 | 75.245 | 81.478 | 141.656 | 97.756 | 118.291 | 181.230 | 104.026 | 110.761 | 160.693 |
| 21 | 71.062 | 95.747 | 64.564 | 58.011 | 118.150 | 173.817 | 52.313 | 105.009 | 85.212 |
| 22 | 81.872 | 127.913 | 60.126 | 78.948 | 113.331 | 121.584 | 66.274 | 135.348 | 72.943 |
| 23 | 107.987 | 96.020 | 111.418 | 50.664 | 115.317 | 166.393 | 51.215 | 103.610 | 124.598 |
| 24 | 101.584 | 209.627 | 87.178 | 171.609 | 218.032 | 183.082 | 131.537 | 222.475 | 103.681 |
| 25 | 52.794 | 77.214 | 101.703 | 67.324 | 186.747 | 175.459 | 46.073 | 100.695 | 123.011 |
| 26 | 95.816 | 85.851 | 194.075 | 189.521 | 246.825 | 184.251 | 123.096 | 127.805 | 176.595 |
| 27 | 117.658 | 153.634 | 93.757 | 62.032 | 131.224 | 163.681 | 62.041 | 145.738 | 105.041 |
| 28 | 74.982 | 101.042 | 118.134 | 162.917 | 169.631 | 223.536 | 100.496 | 128.872 | 147.351 |
| 29 | 88.309 | 95.600 | 161.360 | 149.086 | 179.344 | 203.212 | 147.284 | 164.919 | 178.930 |
| 30 | 110.214 | 112.539 | 114.247 | 62.896 | 123.664 | 159.486 | 59.637 | 119.830 | 122.869 |
| 31 | 69.559 | 113.793 | 84.797 | 105.813 | 162.989 | 163.887 | 66.243 | 144.137 | 98.274 |
| 32 | 86.656 | 106.062 | 121.578 | 141.479 | 182.938 | 190.266 | 137.950 | 147.733 | 174.887 |
| 33 | 91.486 | 98.925 | 138.757 | 153.716 | 194.385 | 186.988 | 136.731 | 153.773 | 160.485 |
| 34 | 117.334 | 332.094 | 82.688 | 173.864 | 291.666 | 98.011 | 266.191 | 267.137 | 79.306 |
| 35 | 211.322 | 298.325 | 263.992 | 174.198 | 177.075 | 239.405 | 249.031 | 201.246 | 236.296 |
| 36 | 169.964 | 205.776 | 200.058 | 118.306 | 193.870 | 168.009 | 151.777 | 198.589 | 177.212 |
| 37 | 107.486 | 113.820 | 264.434 | 173.840 | 134.020 | 256.407 | 221.662 | 114.100 | 258.968 |
| 38 | 82.222 | 96.709 | 101.946 | 94.497 | 150.815 | 139.692 | 88.207 | 126.417 | 121.590 |
| 39 | 71.434 | 100.440 | 95.851 | 84.124 | 181.053 | 121.111 | 113.964 | 168.324 | 102.433 |
| 40 | 121.865 | 147.288 | 131.370 | 58.999 | 108.255 | 161.302 | 76.354 | 130.551 | 135.443 |
| 41 | 173.617 | 177.401 | 234.773 | 154.409 | 229.659 | 178.450 | 210.027 | 234.848 | 194.605 |
| 42 | 92.570 | 127.033 | 128.485 | 120.396 | 180.311 | 143.743 | 113.738 | 158.973 | 126.733 |
| 43 | 75.441 | 110.671 | 65.551 | 144.454 | 217.324 | 111.055 | 80.645 | 138.963 | 71.760 |
| 44 | 92.572 | 148.911 | 124.385 | 98.960 | 160.314 | 171.516 | 59.378 | 123.322 | 116.718 |
| Notes: μS, σS, τS: ExG SSRT parameters for single cluster SST data; μA, σA, τA: ExG SSRT parameters for type-A cluster SST data; μB, σB, τB: ExG SSRT parameters for type-B cluster SST data; IBPA: #Chains = 3; Simulations = 20,000; Burn-in = 5000 (for both single and mixture parameters). | |||||||||
References
- Johnstone, S.J.; Dimoska, A.; Smith, J.L.; Barry, R.J.; Pleffer, C.B.; Chiswick, D.; Clarke, A.R. The Development of Stop Signal and Go/No-go Response Inhibition in children Aged 7–12 Years: Performance and Event Related Potential Indices. Int. J. Psychol. 2007, 63, 25–38. [Google Scholar] [CrossRef]
- Schachar, R.; Logan, G.D.; Robaey, P.; Chen, S.; Ickowicz, A.; Barr, C. Restraint and Cancellation: Multiple Inhibition Deficits in Attention Deficit Hyperactivity Disorder. J. Abnorm. Child Psychol. 2007, 35, 229–238. [Google Scholar] [CrossRef] [PubMed]
- Matzke, D.; Verbrugen, F.; Logan, G.D. The Stop Signal Paradigm. In Steven Handbook of Experimental Psychology and Cognitive Neuroscience; Wixted, J.T., Ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Logan, G.D. On the Ability to Inhibit Thought and Action: A User’s Guide to the Stop Signal Paradigm. In Inhibitory Process in Attention, Memory and Language; Dagenbach, D., Carr, T.H., Eds.; Academic Press: San Diego, CA, USA, 1994. [Google Scholar]
- Trommer, B.L.; Hoeppner, J.B.; Larber, R.; Armstrong, K.J. The Go-Nogo Paradigm in Attention Deficit Disorder. Ann. Neurol. 1988, 24, 610–614. [Google Scholar] [CrossRef] [PubMed]
- Schachar, R.J.; Tannock, R.; Logan, G.D. Inhibitory Control, Impulsiveness and Attention Deficit Hyperactivity Disorder. Clin. Psychol. Rev. 1993, 13, 721–739. [Google Scholar] [CrossRef]
- Schachar, R.J.; Tannock, R.; Logan, G.D. Deficient Inhibitory Control in Attention Deficit Hyperactivity Disorder. J. Abnorm. Child Psychol. 1995, 23, 411–437. [Google Scholar] [CrossRef]
- Logan, G.D. On the Ability to Inhibit Complex Movements: A Stop Signal Study of Type Writing. J. Exp. Psychol. Hum. Perceptions Perform. 1982, 8, 778–792. [Google Scholar] [CrossRef]
- Ollman, R.T.; Billington, M.J. The Deadline Model for Simple Reaction Times. Cogn. Psychol. 1972, 3, 311–336. [Google Scholar] [CrossRef]
- Logan, G.D. Attention, Automaticity, and the Ability to Stop a Speeded Choice Response. In Attention and Performance IX; Long, J., Baddeley, A.D., Eds.; Erlbaum: Hillsdale, NJ, USA, 1981. [Google Scholar]
- Boucher, L.; Palmeri, T.J.; Logan, G.D.; Schall, J.D. Inhibitory Control in Mind and Brain: An Interactive Race Model of Countermanding Saccades. Psychol. Rev. 2007, 114, 376–397. [Google Scholar] [CrossRef] [PubMed]
- Hanes, D.P.; Carpenter, R.H.S. Countermanding Saccades in Humans. Vis. Res. 1999, 39, 2777–2791. [Google Scholar] [CrossRef] [Green Version]
- Logan, G.D.; Cowan, W.B. On the Ability to Inhibit Thought and Action: A Theory of an Act of Control. Psychol. Rev. 1984, 91, 295–327. [Google Scholar] [CrossRef]
- Soltanifar, M.; Knight, K.; Dupuis, A.; Schachar, R.; Escobar, M. A Time Series-based Point Estimation of Stop Signal Reaction Times: More Evidence on the Role of Reactive Inhibition-Proactive Inhibition Interplay on the SSRT Estimations. Brain Sci. 2020, 10, 598. [Google Scholar] [CrossRef]
- Soltanifar, M.; Dupuis, A.; Schachar, R.; Escobar, M. A frequentist mixture modelling of stop signal reaction times. Biostat. Epidemiol. 2019, 3, 90–108. [Google Scholar] [CrossRef]
- Verbruggen, F.; Aron, A.R.; Band, G.P.; Beste, C.; Bissett, P.G.; Brockett, A.T.; Brown, J.W.; Chamberlain, S.R.; Chambers, C.D.; Colonius, H. Capturing the Ability to Inhibit Actions and Impulsive Behaviors: A Consensus Guide to the Stop Signal Task. eLife 2019, 9. [Google Scholar] [CrossRef]
- Steensen, C.L.; Elbaz, Z.K.; Douglas, V.I. Mean Response Times, Variability, and Skew in the Responding of ADHD Children: A Response Time Distributional Approach. Acta Psychol. 2000, 104, 167–190. [Google Scholar] [CrossRef]
- Belin, T.R.; Rubin, D.B. The Analysis of Repeated Measures Data on Schizophrenic Reaction Times Using Mixture Models. Stat. Med. 1995, 14, 747–768. [Google Scholar] [CrossRef] [PubMed]
- Colonius, H. A Note on the Stop Signal Paradigm, or How to Observe the Unobservable. Psychol. Rev. 1990, 97, 309–312. [Google Scholar] [CrossRef]
- Matzke, D.; Dolan, C.V.; Logan, G.D.; Brown, S.D.; Wagenmakers, E.J. Bayesian Parametric Estimation of Stop signal Reaction Time Distributions. J. Exp. Psychol. Gen. 2013, 142, 1047–1073. [Google Scholar] [CrossRef]
- Matzke, D.; Love, J.; Wiecki, T.V.; Brown, S.D.; Logan, G.D.; Wagenmakers, E.J. Release the BEESTS: Bayesian Estimation of Ex-Gaussian Stop Signal Reaction Time Distributions. Front. Psychol. 2013, 4, 918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Band, G.P.H.; van dr Molen, M.W.; Logan, G.D. Horse Race Model Simulations of the Stop Signal Procedure. Acta Psychol. 2003, 112, 105–142. [Google Scholar] [CrossRef]
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel Hierarchical Models; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Rouder, J.N.; Lu, J.; Speckman, P.; Sun, D.C.; Jiang , Y. A Hierarchical Model for Estimating Response Time Distributions. Psychol. Bull. Rev. 2005, 12, 195–223. [Google Scholar] [CrossRef] [Green Version]
- Chevalier, N.; Chatham, C.H.; Munakata, Y. The Practice of Going Helps Children to Stop: The Importance of Context Monitoring in Inhibitory Control. J. Exp. Psychol. Gen. 2014, 143, 959–965. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colzato, L.S.; Jongkees, B.J.; Sellaro, R.; van den Wildenberg, W.P.; Hommel, B. Eating to Stop: Tyrosine Supplementation Enhances Inhibiting Control but not Response Execution. Neuropsychologica 2014, 62, 398–402. [Google Scholar] [CrossRef] [Green Version]
- Matzke, D.; Love, J.; Heatcote, A. A Bayesian Approach for Estimating the Probability of Trigger Failures in the Stop Signal Paradigm. Behav. Res. 2017, 49, 267–281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dupuis, A.; Indralingam, M.; Chevrier, A.; Crosbie, J.; Arnold, P.; Burton, C.L.; Schachar, R. Response time adjustment in the Stop Signal Task: Development in children and adolescents. Child Dev. 2019, 90, e263–e272. [Google Scholar] [CrossRef] [PubMed]
- Kramer, A.F.; Humphrey, D.G.; Lanish, J.; Logan, G.D.; Strayer, D.L. Aging and Inhibition. In Proceedings of the Conference on Cognition and Aging, Atlanta, GA, USA, 12 April 1992. [Google Scholar]
- Verbruggen, F.; Logan, G.D. Models of Response Inhibition in the Stop Signal and Stop Change Paradigms. Neurosci. Biobehav. Rev. 2009, 38, 647–661. [Google Scholar] [CrossRef] [Green Version]
- Luce, R.D. Response Times: Their Role in Inferring Elementary Mental Organization; Oxford University Press: Oxford, UK, 1986; pp. 274–275. [Google Scholar]
- Crosbie, J.; Arnold, P.; Paterson, A.; Swanson, J.; Dupuis, A.; Li, X.; Shan, J.; Goodale, T.; Tam, C.; Strug, L.J.; et al. Response Inhibition and ADHD Traits: Correlates and Heritability in a Community Sample. J. Abnorm. Child Psychol. 2013, 41, 497–597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heatcote, A. RTSYS: A DOS Application for the Analysis of Reaction Times Data. Behav. Res. Methods Instrum. Comput. 1996, 28, 427–445. [Google Scholar] [CrossRef]
- Schwarz, W. The Ex-Wald Distribution as a Descriptive Model of Response Times. Behav. Res. Methods Instrum. Comput. 2001, 33, 457–469. [Google Scholar] [CrossRef] [Green Version]
- Del Prado Martin, F.M. A Theory of Reaction Times Distributions. 2008. (Unpublished). Available online: http://cogprints.org/6310 (accessed on 29 April 2017).
- Rouder, J.N. Are Un-shifted Distributional Models Appropriate for Response Time? Psychometrica 2005, 70, 377–381. [Google Scholar] [CrossRef]
- SAS/STAT Software Version 9.4. SAS/STAT Software Version 9.4 of the SAS System for Windows; SAS Institute: Cary, NC, USA, 2012. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Shaked, M.; Shantikumar, J.G. Stochastic Orders and their Applications; Academic Press: Cambridge, MA, USA, 1994; pp. 323–348. [Google Scholar]
- Bujkiewicz, S.; Thompson, J.R.; Sutton, A.J.; Cooper, N.J.; Harrison, M.J.; Symmons, D.P.; Abrams, K.R. Multivariate Meta Analysis of Mixed Outcomes: A Bayesian Approach. Stat. Med. 2013, 32, 3926–3943. [Google Scholar] [CrossRef]
- Bujkiewicz, S.; Thompson, J.R.; Sutton, A.J.; Cooper, N.J.; Harrison, M.J.; Symmons, D.P.; Abrams, K.R. Use of Bayesian Meta Analysis to Estimate the HAQ for Mapping Onto the EQ-5D Questionnaire in Rheumatoid Arthritis. Stat. Med. 2014, 17, 109–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bajkiewicz, S.; Thompson, J.R.; Riley, R.D.; Abrams, K.R. Bayesian Meta Analytical Methods to Incorporate Multiple Surrogate Endpoints in Drug Development Process. Stat. Med. 2016, 35, 1063–1089. [Google Scholar] [CrossRef] [Green Version]
- Lunn, D.J.; Thomas, A.; Best, N.; Spiegelhalter, D. WinBUGS—A Bayesian Modelling Framework: Concepts, Structure, and Extensibility. Stat. Comput. 2000, 10, 325–337. [Google Scholar] [CrossRef]
- Hockley, W.E. Analysis of Response time Distributions in the Study of Cognitive Processes. J. Exp. Psychol. Learn. Mem. Cogn. 1984, 10, 598–615. [Google Scholar] [CrossRef]
- Goldman, M.; Kaplan, D.M. Comparing distributions by multiple testing across quantiles or CDF values. J. Econ. 2018, 206, 143–166. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Previous Trial | ||
|---|---|---|---|
| Go | Stop | ||
| Current Trial | Go | ||
| Stop | |||
| (a) Descriptive Results | ||
| Statistics (Mean (95%CI)) | ||
| Cluster Type | Mean | St.d |
| Type S | 196.8 | 157.8 |
| (173.5, 220.1) | (139.4, 176.2) | |
| Type A | 265.0 | 217.7 |
| (235.8, 294.2) | (199.1, 236.2) | |
| Type B | 253.6 | 213.2 |
| (222.9, 284.2) | (195.7, 231.0) | |
| (b) Two Samplettest | ||
| Statistics (Mean (95% CI)) | ||
| Comparison | Mean | St.d |
| Type B vs. Type A | −11.4 | −4.4 |
| (−53.5, 30.7) | (−33.5, 24.7) | |
| Type B vs. Type S | 56.8 *** | 55.5 *** |
| (32.2, 81.4) | (35.4, 75.7) | |
| Type A vs. Type S | 68.2 *** | 59.9 *** |
| (48.3, 88.1) | (44.4, 75.4) | |
| Type M vs. Type S | 63.7 *** | 71.4 *** |
| (57.2, 70.1) | (62.5, 80.3) |
| Alternative | Hypothesis | |||||
|---|---|---|---|---|---|---|
| Unequal | Greater | Less | ||||
| # | Statistics | p-Value | Statistics | p-Value | Statistics | p-Value |
| 1 | 0.2708 | 0.0017 | 0.0417 | 0.8465 | 0.2708 | 0.0009 |
| 2 | 0.2604 | 0.0029 | 0.0208 | 0.9592 | 0.2604 | 0.0015 |
| 3 | 0.3333 | 0.0001 | 0.0729 | 0.6002 | 0.3333 | 0.0001 |
| 4 | 0.3438 | 0.0001 | 0.0417 | 0.8465 | 0.3438 | 0.0001 |
| 5 | 0.2396 | 0.0079 | 0.0312 | 0.9105 | 0.2396 | 0.0040 |
| 6 | 0.2812 | 0.0009 | 0.0417 | 0.8465 | 0.2812 | 0.0005 |
| 7 | 0.3021 | 0.0003 | 0.0729 | 0.6002 | 0.3021 | 0.0002 |
| 8 | 0.2188 | 0.0200 | 0.0312 | 0.9105 | 0.2188 | 0.0101 |
| 9 | 0.3646 | 0.0001 | 0.0521 | 0.7707 | 0.3646 | 0.0001 |
| 10 | 0.2396 | 0.0079 | 0.0312 | 0.9105 | 0.2396 | 0.0040 |
| 11 | 0.3229 | 0.0001 | 0.0417 | 0.8465 | 0.3229 | 0.0001 |
| 12 | 0.3229 | 0.0001 | 0.0000 | 1.0000 | 0.3229 | 0.0001 |
| 13 | 0.3021 | 0.0003 | 0.0208 | 0.9592 | 0.3021 | 0.0002 |
| 14 | 0.2396 | 0.0079 | 0.0104 | 0.9896 | 0.2396 | 0.0040 |
| 15 | 0.3229 | 0.0001 | 0.0625 | 0.6873 | 0.3229 | 0.0001 |
| 16 | 0.2500 | 0.0048 | 0.0312 | 0.9105 | 0.2500 | 0.0025 |
| 17 | 0.3229 | 0.0001 | 0.0417 | 0.8465 | 0.3229 | 0.0001 |
| 18 | 0.3542 | 0.0001 | 0.0000 | 1.0000 | 0.3542 | 0.0001 |
| 19 | 0.2604 | 0.0029 | 0.0417 | 0.8465 | 0.2604 | 0.0015 |
| 20 | 0.2604 | 0.0029 | 0.0312 | 0.9105 | 0.2604 | 0.0015 |
| 21 | 0.3854 | 0.0001 | 0.1042 | 0.3529 | 0.3854 | 0.0001 |
| 22 | 0.3438 | 0.0001 | 0.0417 | 0.8465 | 0.3438 | 0.0001 |
| 23 | 0.3646 | 0.0001 | 0.1146 | 0.2835 | 0.3646 | 0.0001 |
| 24 | 0.3021 | 0.0003 | 0.0104 | 0.9896 | 0.3021 | 0.0002 |
| 25 | 0.4896 | 0.0001 | 0.0833 | 0.5134 | 0.4896 | 0.0001 |
| 26 | 0.2604 | 0.0029 | 0.0104 | 0.9896 | 0.2604 | 0.0015 |
| 27 | 0.3958 | 0.0001 | 0.0729 | 0.6002 | 0.3958 | 0.0001 |
| 28 | 0.2708 | 0.0017 | 0.0208 | 0.9592 | 0.2708 | 0.0009 |
| 29 | 0.2396 | 0.0079 | 0.0104 | 0.9896 | 0.2396 | 0.0040 |
| 30 | 0.3750 | 0.0001 | 0.0729 | 0.6002 | 0.3750 | 0.0001 |
| 31 | 0.4062 | 0.0001 | 0.0312 | 0.9105 | 0.4062 | 0.0001 |
| 32 | 0.2500 | 0.0048 | 0.0208 | 0.9592 | 0.2500 | 0.0025 |
| 33 | 0.2500 | 0.0048 | 0.0208 | 0.9592 | 0.2500 | 0.0025 |
| 34 | 0.1562 | 0.1923 | 0.0000 | 1.0000 | 0.1562 | 0.0960 * |
| 35 | 0.2500 | 0.0048 | 0.0104 | 0.9896 | 0.2500 | 0.0025 |
| 36 | 0.3021 | 0.0003 | 0.0312 | 0.9105 | 0.3021 | 0.0002 |
| 37 | 0.1979 | 0.0463 | 0.0104 | 0.9896 | 0.1979 | 0.0233 * |
| 38 | 0.3125 | 0.0002 | 0.0312 | 0.9105 | 0.3125 | 0.0001 |
| 39 | 0.2917 | 0.0005 | 0.0625 | 0.6873 | 0.2917 | 0.0003 |
| 40 | 0.3750 | 0.0001 | 0.0521 | 0.7707 | 0.3750 | 0.0001 |
| 41 | 0.2188 | 0.0200 | 0.0417 | 0.8465 | 0.2188 | 0.0101 |
| 42 | 0.3021 | 0.0003 | 0.0208 | 0.9592 | 0.3021 | 0.0002 |
| 43 | 0.2188 | 0.0200 | 0.0104 | 0.9896 | 0.2188 | 0.0101 |
| 44 | 0.4062 | 0.0001 | 0.0312 | 0.9105 | 0.4062 | 0.0001 |
| Comparison | Statistics | p-Value |
|---|---|---|
| vs. | 0.2095 | <0.0312 |
| vs. | 0.1984 | <0.0562 |
| vs. | 0.2256 | <0.0152 |
| vs. | 0.0653 | >0.9999 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soltanifar, M.; Escobar, M.; Dupuis, A.; Schachar, R. A Bayesian Mixture Modelling of Stop Signal Reaction Time Distributions: The Second Contextual Solution for the Problem of Aftereffects of Inhibition on SSRT Estimations. Brain Sci. 2021, 11, 1102. https://doi.org/10.3390/brainsci11081102
Soltanifar M, Escobar M, Dupuis A, Schachar R. A Bayesian Mixture Modelling of Stop Signal Reaction Time Distributions: The Second Contextual Solution for the Problem of Aftereffects of Inhibition on SSRT Estimations. Brain Sciences. 2021; 11(8):1102. https://doi.org/10.3390/brainsci11081102
Chicago/Turabian StyleSoltanifar, Mohsen, Michael Escobar, Annie Dupuis, and Russell Schachar. 2021. "A Bayesian Mixture Modelling of Stop Signal Reaction Time Distributions: The Second Contextual Solution for the Problem of Aftereffects of Inhibition on SSRT Estimations" Brain Sciences 11, no. 8: 1102. https://doi.org/10.3390/brainsci11081102
APA StyleSoltanifar, M., Escobar, M., Dupuis, A., & Schachar, R. (2021). A Bayesian Mixture Modelling of Stop Signal Reaction Time Distributions: The Second Contextual Solution for the Problem of Aftereffects of Inhibition on SSRT Estimations. Brain Sciences, 11(8), 1102. https://doi.org/10.3390/brainsci11081102