
The Kinematics of Social Action: Visual Signals Provide Cues for What Interlocutors Do in Conversation


Abstract
:1. Introduction
2. Methods
2.1. Participants
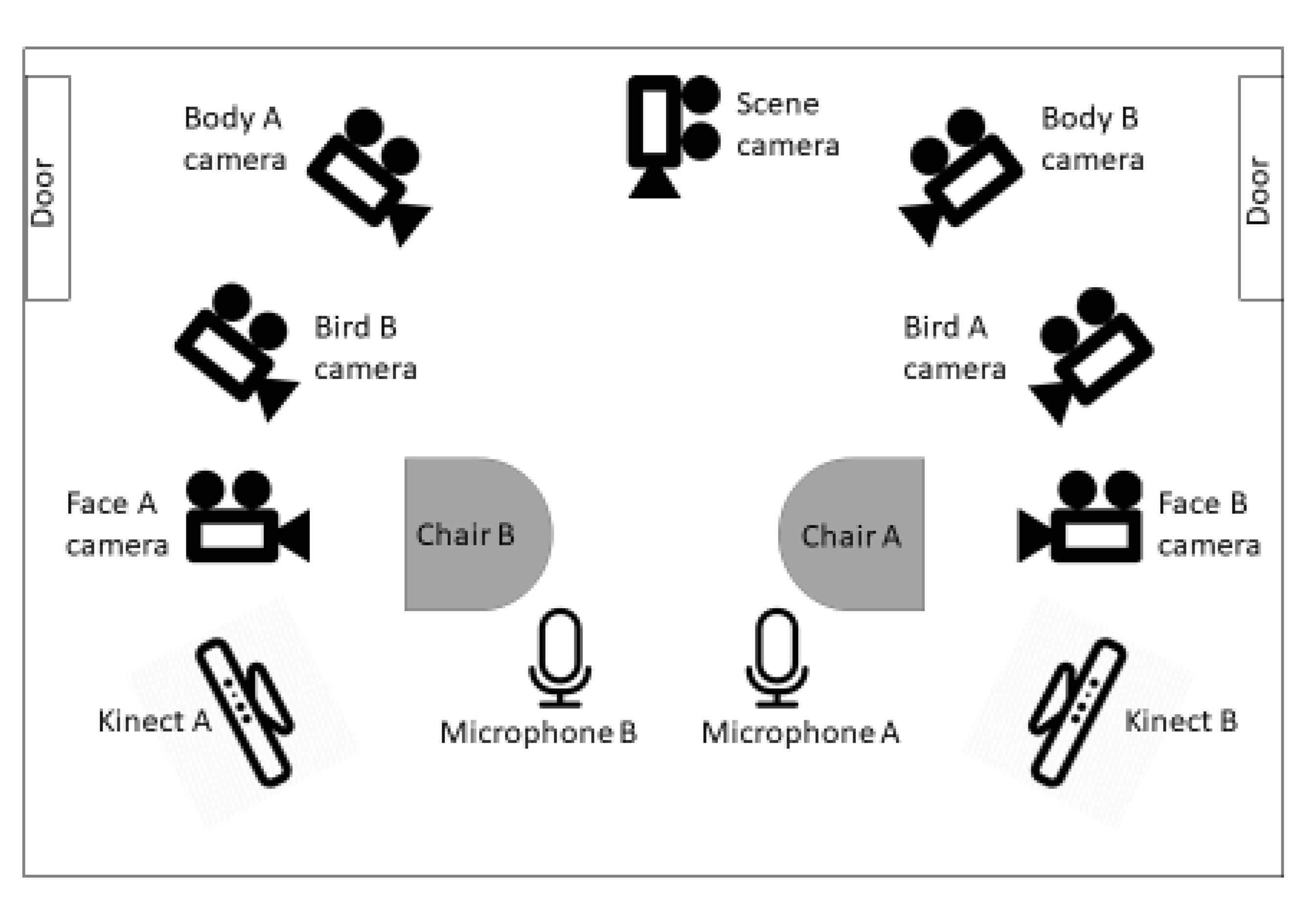
2.2. Data Collection
2.3. Data Annotation: Questions
2.4. Data Annotation: Social Action Categories
2.5. Kinematic Data Extraction
2.6. Analyses
3. Results
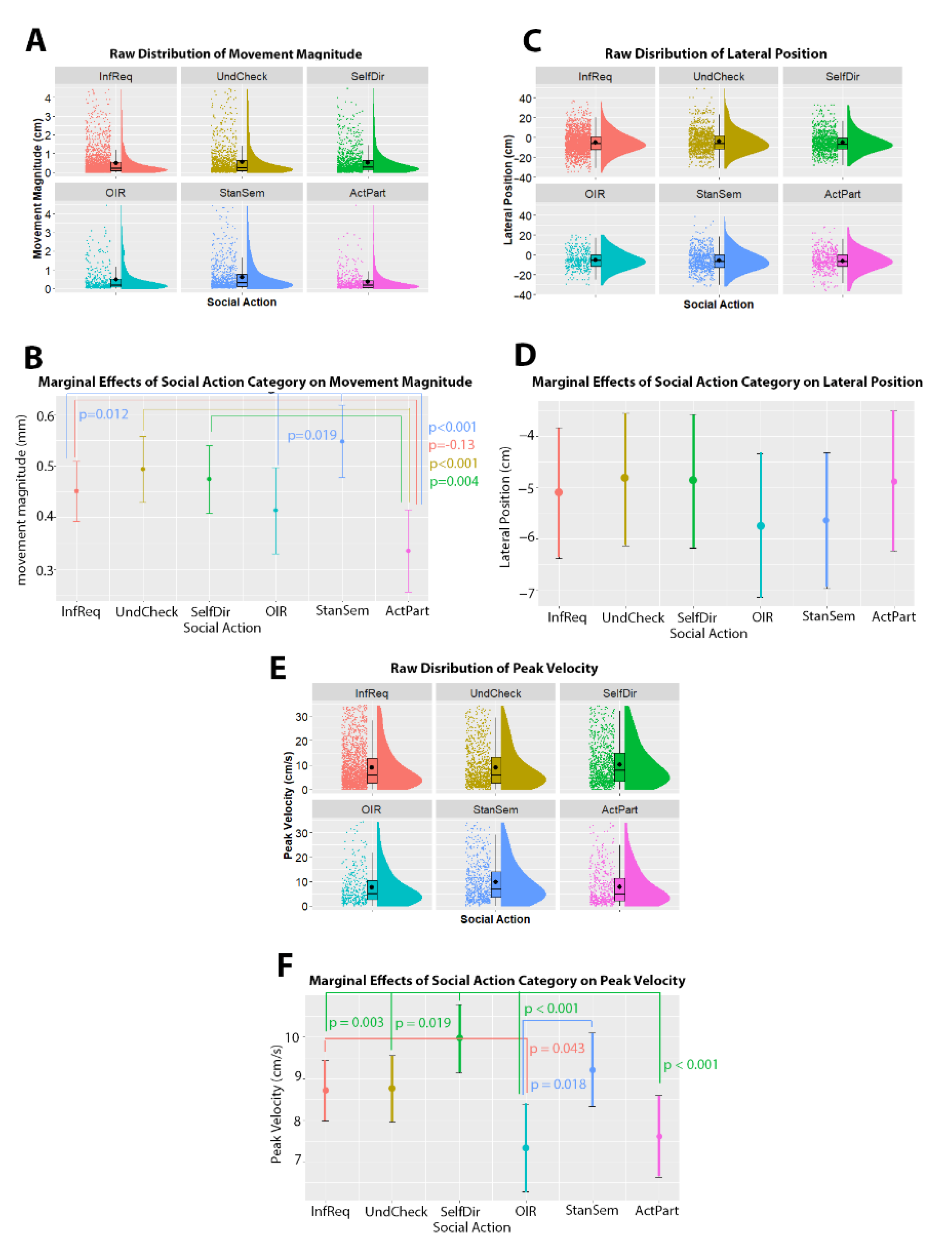
3.1. Torso Movements
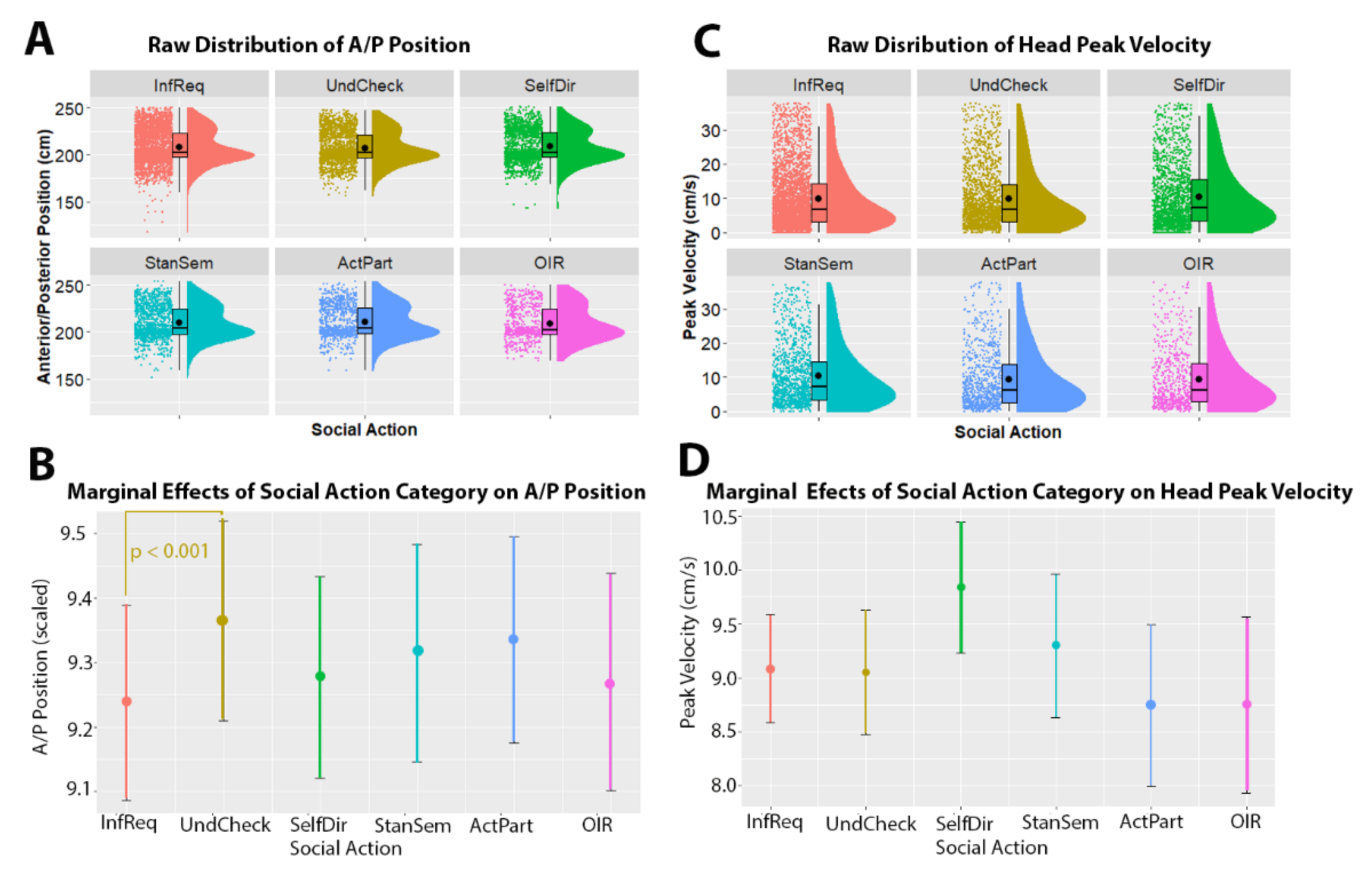
3.2. Head Movements
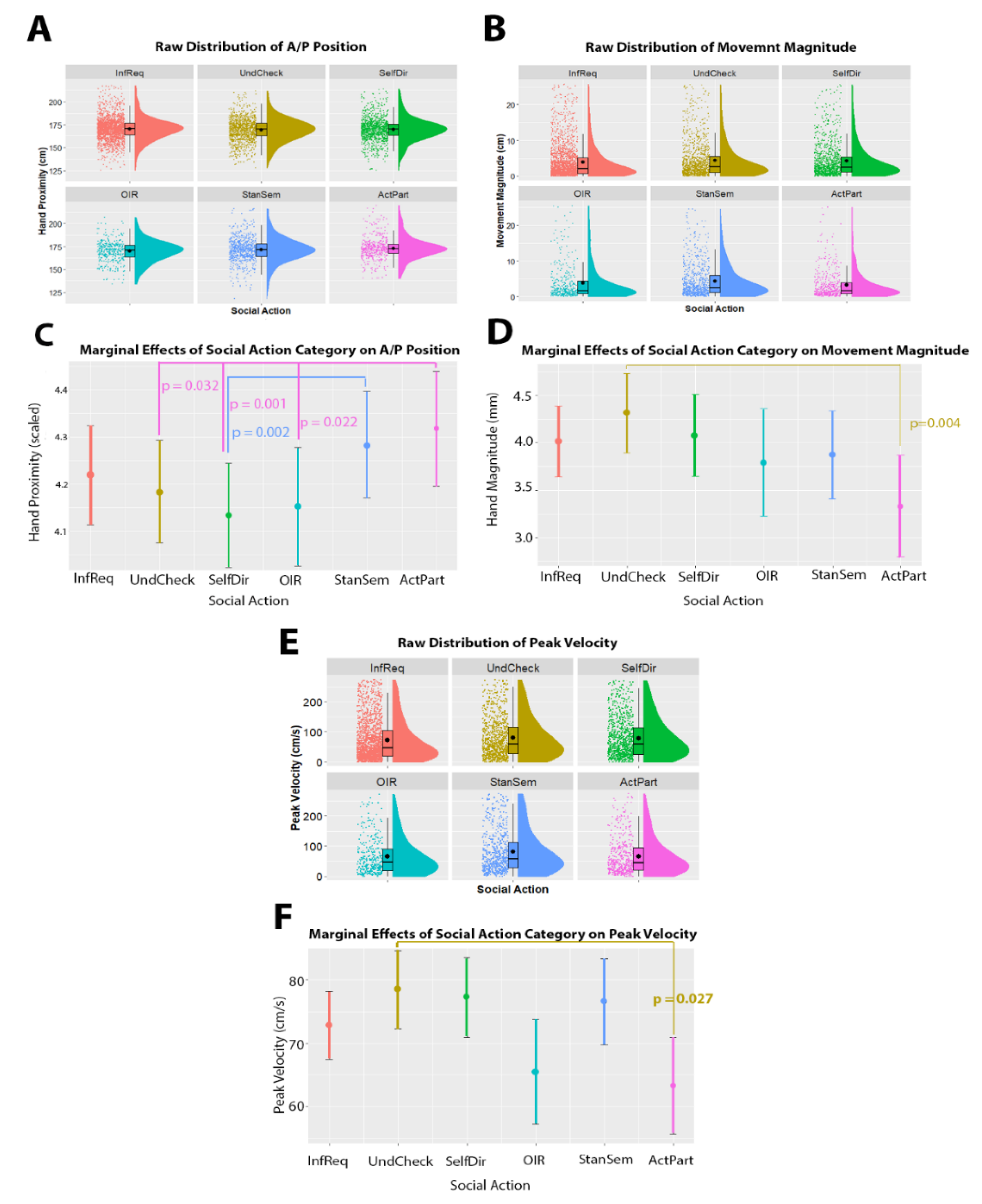
3.3. Manual Movements
4. Discussion
4.1. Limitations
4.2. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Social Action | Median Duration (ms) | Min Duration (ms) | Max Duration (ms) |
|---|---|---|---|
| ActPart | 434.5 | 301 | 1840 |
| StanSem | 1320.0 | 320 | 10,143 |
| UndCheck | 1334.0 | 322 | 9476 |
| SelfDir | 1064.0 | 314 | 6851 |
| OIR | 846.0 | 320 | 3306 |
| PlanAct | 1571.0 | 451 | 5918 |
| InfReq | 1282.0 | 307 | 8182 |
| SIMCA | 1397.0 | 426 | 9129 |
References
- Atkinson, J.M.; Heritage, J.; Oatley, K. Structures of Social Action; Cambridge University Press: Cambridge, UK, 1984. [Google Scholar]
- Kendrick, K.H.; Brown, P.; Dingemanse, M.; Floyd, S.; Gipper, S.; Hayano, K.; Hoey, E.; Hoymann, G.; Manrique, E.; Rossi, G.; et al. Sequence organization: A universal infrastructure for social action. J. Pragmat. 2020, 168, 119–138. [Google Scholar] [CrossRef]
- Raymond, C.W. Sequence Organization. In Oxford Research Encyclopedia of Communication; Oxford University Press: Oxford, UK, 2016. [Google Scholar] [CrossRef]
- Schegloff, E.A. Sequence Organization in Interaction: A Primer in Conversation Analysis I; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Levinson, S.C. Action Formation and Ascription. In The Handbook of Conversation Analysis; Sidnell, J., Stivers, T., Eds.; John Wiley & Sons, Ltd.: Chichester, UK, 2013; pp. 101–130. [Google Scholar] [CrossRef] [Green Version]
- Becchio, C.; Sartori, L.; Bulgheroni, M.; Castiello, U. The case of Dr. Jekyll and Mr. Hyde: A kinematic study on social intention. Conscious Cogn. 2008, 17, 557–564. [Google Scholar] [CrossRef]
- McEllin, L.; Knoblich, G.; Sebanz, N. Distinct kinematic markers of demonstration and joint action coordination? Evidence from virtual xylophone playing. J. Exp. Psychol. Hum. Percept. Perform. 2018, 44, 885–897. [Google Scholar] [CrossRef]
- Pezzulo, G.; Donnarumma, F.; Dindo, H. Human Sensorimotor Communication: A Theory of Signaling in Online Social Interactions. PLoS ONE 2013, 8, e79876. [Google Scholar] [CrossRef] [PubMed]
- Pezzulo, G.; Donnarumma, F.; Dindo, H.; D’Ausilio, A.; Konvalinka, I.; Castelfranchi, C. The body talks: Sensorimotor communication and its brain and kinematic signatures. Phys. Life Rev. 2019, 28, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Quesque, F.; Lewkowicz, D.; Delevoye-Turrell, Y.N.; Coello, Y. Effects of social intention on movement kinematics in cooperative actions. Front. Neurorobot. 2013, 7, 14. [Google Scholar] [CrossRef] [Green Version]
- Runeson, S.; Frykholm, G. Kinematic specification of dynamics as an informational basis for person-and-action perception: Expectation, gender recognition, and deceptive intention. J. Exp. Psychol. Gen. 1983, 112, 585–615. [Google Scholar] [CrossRef]
- Becchio, C.; Cavallo, A.; Begliomini, C.; Sartori, L.; Feltrin, G.; Castiello, U. Social grasping: From mirroring to mentalizing. NeuroImage 2012, 61, 240–248. [Google Scholar] [CrossRef]
- Cavallo, A.; Koul, A.; Ansuini, C.; Capozzi, F.; Becchio, C. Decoding intentions from movement kinematics. Sci. Rep. 2016, 6, 37036. [Google Scholar] [CrossRef] [Green Version]
- Trujillo, J.P.; Simanova, I.; Bekkering, H.; Özyürek, A. Communicative intent modulates production and comprehension of actions and gestures: A Kinect study. Cognition 2018, 180, 38–51. [Google Scholar] [CrossRef]
- Trujillo, J.P.; Simanova, I.; Bekkering, H.; Özyürek, A. The communicative advantage: How kinematic signaling supports semantic comprehension. Psychol. Res. 2019, 84, 1897–1911. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bavelas, J.B.; Chovil, N. Visible Acts of Meaning. J. Lang. Soc. Psychol. 2000, 19, 163–194. [Google Scholar] [CrossRef]
- Holler, J.; Levinson, S.C. Multimodal Language Processing in Human Communication. Trends Cogn. Sci. 2019, 23, 639–652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kendon, A. Gesture: Visible Action as Utterance; Cambridge University Press: Cambridge, UK, 2004; Available online: https://books.google.nl/books?hl=en&lr=&id=hDXnnzmDkOkC&oi=fnd&pg=PR6&dq=kendon+2004&ots=RK4Txd6XgG&sig=WJXG_VR0o-FXWjdCRsXbudT_lvA#v=onepage&q=kendon%202004&f=false (accessed on 13 April 2020).
- McNeill, D. Hand and Mind: What Gestures Reveal about Thought; University of Chicago Press: Chicago, IL, USA, 1992. [Google Scholar]
- Mondada, L. Challenges of multimodality: Language and the body in social interaction. J. Socioling. 2016, 20, 336–366. [Google Scholar] [CrossRef]
- Perniss, P. Why We Should Study Multimodal Language. Front. Psychol. 2018, 9, 1109. [Google Scholar] [CrossRef]
- Vigliocco, G.; Perniss, P.; Vinson, D. Language as a multimodal phenomenon: Implications for language learning, processing and evolution. Philos. Trans. R. Soc. B Biol. Sci. 2014, 369, 20130292. [Google Scholar] [CrossRef] [Green Version]
- Egorova, N.; Shtyrov, Y.; Pulvermuller, F. Early and parallel processing of pragmatic and semantic information in speech acts: Neurophysiological evidence. Front. Hum. Neurosci. 2013, 7, 86. [Google Scholar] [CrossRef] [Green Version]
- Gisladottir, R.S.; Chwilla, D.J.; Levinson, S.C. Conversation Electrified: ERP Correlates of Speech Act Recognition in Underspecified Utterances. PLoS ONE 2015, 10, e0120068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ter Bekke, M.; Drijvers, L.; Holler, J. The predictive potential of hand gestures during conversation: An investigation of the timing of gestures in relation to speech. PsyArXiv 2020. [Google Scholar] [CrossRef]
- Kaukomaa, T.; Peräkylä, A.; Ruusuvuori, J. Foreshadowing a problem: Turn-opening frowns in conversation. J. Pragmat. 2014, 71, 132–147. [Google Scholar] [CrossRef] [Green Version]
- Trujillo, J.P.; Vaitonytė, J.; Simanova, I.; Özyürek, A. Toward the markerless and automatic analysis of kinematic features: A toolkit for gesture and movement research. Behav. Res. Methods 2018, 51, 769–777. [Google Scholar] [CrossRef] [Green Version]
- Bonnechère, B.; Sholukha, V.; Omelina, L.; Jansen, B.; Van Sint Jan, S. Validation of trunk kinematics analysis through serious games rehabilitation exercises using the KinectTM sensor. In Proceedings of the 4th Workshop on ICTs for improving Patients Rehabilitation Research Techniques, Lisbon, Portugal, 13–14 October 2016; pp. 45–48. [Google Scholar] [CrossRef]
- Oh, B.-L.; Kim, J.; Kim, J.; Hwang, J.-M.; Lee, J. Validity and reliability of head posture measurement using Microsoft Kinect. Br. J. Ophthalmol. 2014, 98, 1560–1564. [Google Scholar] [CrossRef] [PubMed]
- Baron-Cohen, S.; Wheelwright, S. The Empathy Quotient: An Investigation of Adults with Asperger Syndrome or High Functioning Autism, and Normal Sex Differences. J. Autism Dev. Disord. 2004, 34, 163–175. [Google Scholar] [CrossRef]
- Watson, D.; Friend, R. Measurement of social-evaluative anxiety. J. Consult. Clin. Psychol. 1969, 33, 448–457. [Google Scholar] [CrossRef]
- Kisler, T.; Reichel, U.; Schiel, F. Multilingual processing of speech via web services. Comput. Speech Lang. 2017, 45, 326–347. Available online: https://clarin.phonetik.uni-muenchen.de/BASWebServices/interface/ASR (accessed on 12 May 2021). [CrossRef] [Green Version]
- ELAN. ELAN Version 5.2; Computer software. Max Planck Institute for Psycholinguistics: Nijmegen, The Netherlands, 2008. Available online: https://tla.mpi.nl/tools/tla-tools/elan/ (accessed on 26 June 2020).
- Sloetjes, H.; Wittenburg, P. Annotation by category—ELAN and ISO DCR. In Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Stivers, T.; Enfield, N. A coding scheme for question–response sequences in conversation. J. Pragmat. 2010, 42, 2620–2626. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Holle, H.; Rein, R. EasyDIAg: A tool for easy determination of interrater agreement. Behav. Res. Methods 2014, 47, 837–847. [Google Scholar] [CrossRef]
- Broersma, P.; Weenink, D. Praat: Doing Phonetics by Computer, Version 6.0.37. 2021. Available online: http://www.praat.org/ (accessed on 6 March 2020).
- Holler, J.; Kendrick, K.H.; Levinson, S.C. Processing language in face-to-face conversation: Questions with gestures get faster responses. Psychon. Bull. Rev. 2018, 25, 1900–1908. [Google Scholar] [CrossRef] [Green Version]
- Holler, J.; Kendrick, K.H. ‘Unaddressed participants’ gaze in multi-person interaction: Optimizing recipiency. Front. Psychol. 2015, 6, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Jurafsky, D. Pragmatics and Computational Linguistics. In Handbook of Pragmatics; Wiley: Hoboken, NJ, USA, 2003; pp. 578–604. [Google Scholar]
- Kendrick, K.H. The intersection of turn-taking and repair: The timing of other-initiations of repair in conversation. Front. Psychol. 2015, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sendra, V.C.; Kaland, C.; Swerts, M.; Prieto, P. Perceiving incredulity: The role of intonation and facial gestures. J. Pragmat. 2013, 47, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Kendrick, K.H.; Holler, J. Gaze Direction Signals Response Preference in Conversation. Res. Lang. Soc. Interact. 2017, 50, 12–32. [Google Scholar] [CrossRef]
- Couper-Kuhlen, E. What does grammar tell us about action? Pragmatics 2014, 24, 623–647. [Google Scholar] [CrossRef] [Green Version]
- Lubbers, M.; Torreira, F. Pympi-Ling: A Python Module for Processing ELAN’s EAF and Praat’s TextGrid Annotation Files. 2018. Available online: pypi.python.org/pypi/pympi-ling (accessed on 23 July 2021).
- R Core Team. R: A Language and Environment for Statistical Computing, version 1.1.463; R Foundation for Statistical Computing: Vienna, Austria, 2019.
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Usinglme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Lenth, R. Emmeans: Estimated Marginal Means, Aka Least-Squares Means. R package version 1.4.3.01. 2019. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 23 July 2021).
- Lüdecke, D. sjPlot—Data Visualization for Statistics in Social Science; Zenodo: Geneva, Switzerland, 2018. [Google Scholar] [CrossRef]
- Allen, M.; Poggiali, D.; Whitaker, K.; Marshall, T.R.; Van Langen, J.; Kievit, R.A. Raincloud plots: A multi-platform tool for robust data visualization. Wellcome Open Res. 2021, 4, 63. [Google Scholar] [CrossRef]
- Crane, E.; Gross, M. Motion Capture and Emotion: Affect Detection in Whole Body Movement. In Proceedings of the Second International Conference, Lisbon, Portugal, 12–14 September 2007; Springer: Berlin, Germany, 2007; pp. 95–101. [Google Scholar] [CrossRef]
- Dingemanse, M. Other-initiated repair in Siwu. Open Linguist. 2015, 1. [Google Scholar] [CrossRef] [Green Version]
- Floyd, S.; Manrique, E.; Rossi, G.; Torreira, F. Timing of Visual Bodily Behavior in Repair Sequences: Evidence from Three Languages. Discourse Process. 2015, 53, 175–204. [Google Scholar] [CrossRef]
- Manrique, E.; Enfield, N.J. Suspending the next turn as a form of repair initiation: Evidence from Argentine Sign Language. Front. Psychol. 2015, 6. Available online: https://www.frontiersin.org/articles/10.3389/fpsyg.2015.01326/full (accessed on 25 May 2021). [CrossRef] [Green Version]
- Li, X. Leaning and recipient intervening questions in Mandarin conversation. J. Pragmat. 2014, 67, 34–60. [Google Scholar] [CrossRef]
- Rasmussen, G. Inclined to better understanding—The coordination of talk and ‘leaning forward’ in doing repair. J. Pragmat. 2014, 65, 30–45. [Google Scholar] [CrossRef]
- Kendrick, K.H. Other-initiated repair in English. Open Linguist. 2015, 1. [Google Scholar] [CrossRef]
- Hömke, P.; Holler, J.; Levinson, S.C. Eyebrow Movements as Signals of Communicative Problems in Face-to-Face Conversation. Ph.D. Thesis, Radboud University, Nijmegen, The Netherlands, 2019. [Google Scholar]
- Delaherche, E.; Chetouani, M.; Mahdhaoui, A.; Saint-Georges, C.; Viaux, S.; Cohen, D. Interpersonal Synchrony: A Survey of Evaluation Methods across Disciplines. IEEE Trans. Affect. Comput. 2012, 3, 349–365. [Google Scholar] [CrossRef] [Green Version]
- Paxton, A.; Dale, R. Frame-differencing methods for measuring bodily synchrony in conversation. Behav. Res. Methods 2012, 45, 329–343. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hale, J.; Ward, J.A.; Buccheri, F.; Oliver, D.; Hamilton, A.F.D.C. Are You on My Wavelength? Interpersonal Coordination in Dyadic Conversations. J. Nonverbal Behav. 2019, 44, 63–83. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seo, M.-S.; Koshik, I. A conversation analytic study of gestures that engender repair in ESL conversational tutoring. J. Pragmat. 2010, 42, 2219–2239. [Google Scholar] [CrossRef]
- Furuyama, N. Gestural interaction between the instructor and the learner in origami instruction. In Language and Gesture; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Trujillo, J.P.; Simanova, I.; Özyürek, A.; Bekkering, H. Seeing the Unexpected: How Brains Read Communicative Intent through Kinematics. Cereb. Cortex 2019, 30, 1056–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paxton, A.; Dale, R. Interpersonal Movement Synchrony Responds to High- and Low-Level Conversational Constraints. Front. Psychol. 2017, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wallot, S.; Mitkidis, P.; McGraw, J.J.; Roepstorff, A. Beyond Synchrony: Joint Action in a Complex Production Task Reveals Beneficial Effects of Decreased Interpersonal Synchrony. PLoS ONE 2016, 11, e0168306. [Google Scholar] [CrossRef]
- Di Cesare, G.; de Stefani, E.; Gentilucci, M.; De Marco, D. Vitality Forms Expressed by Others Modulate Our Own Motor Response: A Kinematic Study. Front. Hum. Neurosci. 2017, 11, 565. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feyereisen, P. The behavioural cues of familiarity during social interactions among human adults: A review of the literature and some observations in normal and demented elderly subjects. Behav. Process. 1994, 33, 189–211. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trujillo, J.P.; Holler, J. The Kinematics of Social Action: Visual Signals Provide Cues for What Interlocutors Do in Conversation. Brain Sci. 2021, 11, 996. https://doi.org/10.3390/brainsci11080996
Trujillo JP, Holler J. The Kinematics of Social Action: Visual Signals Provide Cues for What Interlocutors Do in Conversation. Brain Sciences. 2021; 11(8):996. https://doi.org/10.3390/brainsci11080996
Chicago/Turabian StyleTrujillo, James P., and Judith Holler. 2021. "The Kinematics of Social Action: Visual Signals Provide Cues for What Interlocutors Do in Conversation" Brain Sciences 11, no. 8: 996. https://doi.org/10.3390/brainsci11080996