1. Introduction
Two recent neuroimaging studies [
1,
2] have decoded the structure and semantic content of static visual images from human brain activity. Considerable interest has developed in decoding stimuli or mental states from brain activity measured by functional magnetic resonance imaging (fMRI). The significant advantage of fMRI is that it does not use radiation, as is the case with X-rays, computed tomography (CT), and positron emission tomography (PET) scans. If performed correctly, fMRI poses virtually no risks. It can be used to safely, non-invasively, and effectively evaluate brain function [
3]. fMRI is easy to use, and the produced images have very high resolution (as detailed as 1 millimeter). Compared to the traditional questionnaire methods of psychological evaluation, fMRI is much more objective.
Technological advances have led to significant evolution in user–computer interfaces. Hence, there are new opportunities to facilitate and simplify computer access, including the practical use of these interfaces in vast applications [
4,
5] and a broad spectrum of user communities. Designing models that can predict brain activity is an extensive research field, where one crucial aspect is feature selection, which is used to find the patterns that describe data.
At present, different techniques are used for feature selection, such as probability, logic, optimization, and so on, to solve various problems and to obtain the best features to solve a classification problem [
6,
7,
8]. Having the most representative features for the description of the problem allows the classifier to converge to the correct solution. Deep learning [
9] is a current group of techniques, within the range of black-box solutions, producing the most promising results. With deep learning, some architectures such as convolutional neural network (CNN) with different layers extract features from the image, and others perform classification within the same architecture. In some scenarios with large amounts of high-dimensional data, without considering the distributions and the correlations between features, overfitting problems can occur.
One possible solution is implementing a benchmark combined with a validation technique, such as
k-fold cross-validation, to determine which models can solve a classification problem [
10], the training of the models is usually run over a different data set, in order to obtain scores for different algorithms and choose the best one, according to the input data. This method is often impractical for larger numbers of hyperparameters, depending on the model used; for example, a natural question is: Which classification algorithm can be used to solve a particular problem? For this, we could use neural networks or a support vector machine (SVM) with linear or non-linear kernels. This is an essential decision, as one algorithm can converge to the solution faster than the others with similar accuracy, depending on the type of input data. Notably, these algorithms usually randomly initialize their parameters and cannot reproduce the same percentage of accuracy in each execution, even when using the same hyperparameters. In classification algorithm applications, we need to analyze the relation of the trained models and the input training data set to determine the complexity of the problem.
Many applications of machine learning and, most recently, computer vision have been disrupted by the use of CNNs [
11,
12,
13,
14,
15]. Combining a minimal need for human design and the efficient training of large and complex models has allowed them to achieve state-of-the-art performance on several benchmarks. However, this performance is only possible with a high computational cost, due to the use of chains of several convolutional layers, often requiring implementations on GPUs or highly optimized distributed CPU architectures to process large data sets [
16]. The increasing use of these networks for detection in sliding window approaches and the desire to apply CNNs in real-world systems mean that the inference speed has become an essential factor for various applications [
16].
One significant problem is choosing the correct CNN architecture [
17,
18,
19]. The sample size for training the CNN architecture usually is enormous, considering that it will depend on the election of filters and the rest of the hyperparameters in a CNN. Thus, transfer learning has been one of the most used techniques in the past years, implementing pre-trained architectures for classification [
20,
21]. This approach brings some advantages, reducing the processing time in training and reducing the amount of data required. One of the new challenges of this approach is choosing the sample size for training and the correct generalization of the features for new classification problems. Based on the above arguments, the most straightforward answer is that more data is needed to improve the results, and, in some scenarios, it is impossible to improve the results, thus leading to overfitting [
22]. The sample size depends on the nature of the problem and the implemented architecture. Still, co-dependency can occur, making it necessary to test different architectures with appropriate data. Real-world data are never perfect and often suffer from corruption produced by noise, which may impact the interpretation of the training data and affect the performance of the model [
23]. Additionally, noise can reduce the system performance regarding classification accuracy and training processing time. Existing learning algorithms integrate various approaches to enhance their learning abilities in noisy environments however, these approaches can have severe negative impacts.
The problem of learning in noisy environments [
24] has been the focus in fields related to machine learning and inductive learning algorithms. In real-world applications, classifiers are developed and trained without a clear understanding of the noise factor. Thus, comprehensive knowledge of the noise in each data set avoids possible pitfalls during training. To overcome this type of problem, some approaches have experimented with different deep learning architectures, as they can extract features in their hidden layers without the need for human intervention however, this creates other problems. In deep learning, to compare the efficiency of different architectures with respect to the same problem [
25], the benchmarks use different tests, such as cross-validation [
10]. Even in this scenario, one of the problems with benchmark architectures is overkill. Due to the infinite number of possible architectures that can be proposed within the deep learning design area, it is impossible to test all of them. In addition, a large amount of information is needed to train this type of architecture. The larger the architecture, the higher the number of parameters that need to be trained. Due to this, techniques such as transfer learning [
26] have become popular, utilizing the application of architectures that have been trained previously to solve new classification problems. These models can effectively serve as a generic model of the visual world, with different approximations [
11,
12,
13,
15].
Transfer learning takes advantage of these learned feature maps without having to start from scratch by training a large model on an extensive data set [
26,
27,
28,
29]. However, one of the main drawbacks of transfer learning is its dependency on heavy architectures, which are often excessive for specific problems. Thus, in this work, we introduce a series of texture amortization map features and a novel geometric classification score. These texture amortization map (TAM) features are based on the texture ideas that improve the generation of new features, with inherent adaptability according to the input data. The geometric classification score (GCS) is a score that can help to choose the best convolutional layers or a combination thereof, given a pre-trained architecture and a training data set for a specific classification problem.
4. Geometric Classification Score (GCS)
In the present study, we work with different CNN architectures to optimize the selection of features obtained from the convolutional layers. This analysis helped us to understand what is happening during the training stage or inside a trained CNN. Not all the convolutional layers or combinations thereof are the best transformations for the input data. Sometimes, the aim is to identify which convolutional layers should be kept and which should be removed, in order to obtain the best representation of the data.
For this, we can use the concept of an outlier. An outlier is defined as an observation extremely far from the main set of observations. Thus, we need to identify and remove them [
68]. Outliers are frequently a source of noise in the data, thus affecting the classification problem. We know that a point or set of points creates noise in the classes when they are mixed under some parameters in the nearby class, as shown in
Figure 4.
An outlier will not necessarily invariably be defined as a noise point. In some cases, these outliers are intrinsic to the phenomenon being modeled with the data. Furthermore, in several instances, an outlier can be classified without any significant issues, as shown in
Figure 5, which shows how the blue point that is far from the rest of the data set is considered an outlier however, it is not surrounded by points of the red class, which means that the data can be linearly separated, even though an outlier is near the red class.
A crucial step is defining if the point in the map is noise, which directly depends on some parameters that we use to measure the amount by which the classification is affected. Remember that some problems are classified as linearly separable or non-linearly separable data. We can analyze whether a point is noise, concerning the other class. For this, we take a sample point of the blue class and draw a radius to analyze the points of the red class within that neighborhood, delimited by the circle shown in
Figure 5. We can see that the blue point is an outlier, and the other class points do not surround it. This means that we can draw a line between these data to achieve classification, and not consider this point as noise.
Let us consider a finite data set of
M samples with
N features
and a set of hypotheses
, such that
. We can consider the data set as a multi-class problem [
69], when we have
K classes for which there are subsets of
. If we want to determine if a class
is noise, with respect to the rest of the classes in the data set, we can extract class
from
to form an
tuple to compare, with respect to
. In this scenario, we can consider the problem as a dichotomy. As such, we need to define a measure, GCS, to determine if
is noise concerning the new
tuple.
Proposition 1. The GCS measures the number of noise points present in class one with respect to class two, classifying each noise point of class one according to the number of points in class two that surround each point.
Construction 1. To have a dichotomy generated byon the set of points in, we extract classto measure the number of noise points with respect to the rest of the points. As such, we obtain the subset(Equation (12),
where we can test if each point from subset
is noise with respect to the subset
. So, we take a point from
that is the center of an
n-sphere. An
n-sphere (or
n-hypersphere) is a topological space that is homeomorphic to a standard
n-sphere [
70]. It is a set of points in
-dimensional Euclidean space situated at a constant distance
r from a fixed point. The
n-hypersphere is a generalization of a circle (or a 2-sphere); for example, the usual sphere is a 3-sphere [
71]. For dimensions
, we can define a sphere as a set of
of points
, such that:
where
R is the hypersphere radius and represents the constant distance of its points to the center. In terms of the standard norm, the
n-sphere is defined as in Equation (
14),
and an
n-sphere of radius
r can be defined as:
The n-dimensional sphere is the surface or boundary of an -dimensional ball.
Topologically, an
n-sphere can be constructed as a one-point compactification of
n-dimensional Euclidean space [
72]. Briefly, the
n-sphere can be described as
, which is an
n-dimensional Euclidean space plus a single point, representing infinity in all directions [
70]. In particular, if a single point is removed from an
n-sphere, it becomes homeomorphic to
. This constitutes the basis for stereographic projection [
73]. When working with a Euclidean space, we denote it by
. If
, then
has the shape of
with
, and
is designated an inner product, given by:
Now, consider the following geometric idea: When taking two points
and performing a subtraction, we obtain the vector
l that passes through
and
. If we take any other point
x, such that
is perpendicular to
l, we obtain the set
, which allows us to separate the Euclidean space
[
74]. The Euclidean coordinates in
-space,
, that define an
n-sphere
, are represented by Equation (
17),
where
is the center point of the
n-sphere with radius
r. To calculate the GCS, the point
in
is the center in Equation (
17). The
n-sphere (Equation (
17)) exists in
-dimensional Euclidean space and is an example of an
n-manifold. The volume,
, of an
n-sphere of radius
r is given in Equation (
18) [
73]:
Thus, we create a subset of all the points inside each
n-sphere measuring the Euclidean distance
of the point
in
, concerning all points
in
, to obtain the new subset
(Equation (
19)),
With this new subset, we obtain the subset of the closest neighbors to the center of the
n-sphere, in order to define whether the point will be labeled as noise or not. As we are using an approximation of the coverage of all the points of this new subset
, having the geometric shape of an
n-sphere, which does not describe the real geometric shape of the subset of points, the next step is to obtain the polytope that covers all the points of the subset. The affine envelope of a subset
is the smallest affine space containing
D. Thus, if we have a set of points
S in
,
S is convex and, for any two points
, we have a line segment connecting them inside the convex set:
By definition, a polytope is the convex hull of a finite non-empty set in
[
75]. Thus, a polytope is the convex hull of a given set of points
. Algebraically,
must be minimized for all
X of the form in Equation (
21),
If
are convex sets, then
is convex. To see this, consider two points
and
in
. Since any
is convex, the line segment
. Thus,
is convex. The convex hull
of
is the smallest convex hull containing the points, in view of:
the convex hull of a finite set
of points; that is, the set has the form in Equation (
23),
Accordingly, the convex hull is a finite set of points
, which can be written as a convex combination [
76]:
and
With the convex combination, we generate a polytope from the subset
, and we can evaluate whether the point
is inside the polytope, to consider it (or not) as a noise point, where
is the sum of the number of noise points for class
k. We repeat that process for all points in all the classes, as described in Algorithm 1. With this proposal, GCS allows us to identify if a point in a data set is classifiable or not; finally, it is defined as Equation (
26):
| Algorithm 1 Algorithm to obtain the GCS of a data set. |
Input: Output: score Method: noiseCounter = 0 Normalize for each in do for to M do for to N do if then end if end for Obtain convex hull() if Point is in convex hull: then end if end for end for Obtain score from noiseCounter return score
|
Obtaining a measure such as the GCS provides several possibilities, as well as questions to answer. For example, as mentioned in the Introduction, we know that many of the applications of deep neural networks particularly CNN (see, e.g., [
77,
78,
79]) depend on the original architecture being trained with large amounts of data. These architectures trained with large amounts of data sometimes need special hardware to handle this amount of information, in order to process and train the architecture [
20,
21]. The question is then not related to the amount of data or the hardware, but rather whether each layer within the CNN provides valuable information for classification. This leads to another question: Can the architecture be optimized? The typical approach is to use benchmarks to evaluate the performance of the architectures when classifying, but that does not describe if the architecture’s hidden layers are efficient. Thus, we can ask if the GCS can help us in this task, by measuring the level of data classification according to each transformation for each hidden layer within the deep learning architecture.
A deep architecture such as a CNN has the advantage of being able to generalize the rules that characterize the classification problem being solved. Obtaining the set of rules that describes this process is not new; it has been investigated in other areas, such as the Vapnik–Chervonenkis theory [
80], where the objective is to identify the rules that can be generated within the hidden layers of a classification system and determine if this set of rules is transmitted in each layer. Thus, we need to continue and define shattered sets.
Definition 2. Let X be a set and Y a collection of subsets of X. A subset is shattered by Y if each subset of A can be expressed as the intersection of A with a subset T in Y. Symbolically, then, A is shattered by S if, for all , there exists some for which . If A is shattered by Y, then Y shatters A if [81]:where denotes the power set of A, in the field of machine learning theory. We usually consider the set A to be a sample of outcomes drawn according to a distribution D, with the set Y representing a collection of known concepts or laws. In this context, we can see the outputs of each hidden layer of a deep learning architecture as different sets of possible rules, if we combine it with transfer learning techniques. Thus, if we obtain the GCS measure in each layer, we obtain the best output candidate to solve the classification problem. We can consider this output as a set of rules A, where A is shattered by Y. As such, the set Y can explain the new rules obtained by solving the same job and optimizing the architecture.
Hypothesis 1 (H1). Suppose we assume that all the data transformations in the inner layers of a deep neural network still belong to a Euclidean space. In that case, we can evaluate the data transformations inside the hidden layers and determine how classifiable they are, in order to evaluate which are the best transformations of a CNN, for which Algorithm 2 is proposed. We can continue exploring this type of transformation for future work and begin to observe even manifolds that preserve belonging to a Euclidean space.
To analyze the representation of the data in each hidden layer of a trained CNN, Algorithm 1 can be used to obtain the GCS measure of each layer. As such, we can compare which layer or combination of layers can extract the best features in classification problems. Thus, we can better understand the number of layers that do not contribute new information to the solution. As soon as we obtain the GCS measures within the hidden layers of a CNN architecture, we know which layers to remove and analyze and which layers are generalizing the rules learned in the training stage.
In this section, we describe the two proposals of this work. First, we present the case where, due to the nature of the type of fMRI data, traditional computer vision filters do not obtain the best results. We observed that traditional filters attenuated the patterns to be recognized. Thus, we propose TAM, which is an amortized feature filter, depending on the neighborhood of the pixels when extracting features and enhancing the patterns that we are looking for, in order to solve the classification problem. Finally, we use deep learning architecture techniques to help us classify these data, using TAM processing for these classification problems. Still, we identified another problem: This type of architecture has too many parameters to be trained. Sometimes, some layers do not contribute to solving the classification problem; conversely, in some cases, some layers may even introduce noise. Thus, we propose the novel GCS measure, which allows us to analyze the behavior of the transformations within the hidden layers and provides a measure that allows us to identify how classifiable the data set is in each hidden layer, thus allowing us to identify which layers can be removed. Therefore, in the following section, we present the results and analysis of testing the techniques mentioned in this section under different scenarios.
| Algorithm 2 GCS cut |
Input: Output: Method: Build DNN architecture Load weights from DNN architecture for layer l in do Get end for Obtain max score in to get idLayer Cut DNN in idLayer Add multiclass layer to obtain dnnCut Train dnnCut with trainData Obtain errorRate with testData in dnnCut
|
5. Results
In (
Figure 6), we show a comparison between different data set examples. Different scenarios have the same data, but various amounts of noise points. In this scenario, we tested how classifiable a data set is through the score obtained from the GCS. We compare these data sets, including examples of linearly separable or non-linearly separable data, in order to analyze the behavior of the GCS. The GCS provides a value between
and 1. Any value close to one, regardless of the sign, indicates how classifiable a data set is, and the sign tells us if it is a linearly separable set or not. Otherwise, a value of zero indicates that the data set is not classifiable. In this example (
Figure 6), we can observe cases where there is no added noise, as the GCS is close to 1 or −1. As we add noise to the data set, the GCS value approaches 0. In this way, the GCS can tell us how classifiable the data set is.
We have now proven that the GCS provides a measure for estimating classification accuracy. A data set may or may not have some data transformation, depending on the pipeline that is being applied in data processing. We analyzed a deep learning architecture scenario, as described in the previous section. We know that, between each hidden layer, the input data suffer from data transformation. This led us to evaluate the effect of each data transformation in each hidden layer, through the score obtained from the GCS. Considering our initial hypothesis for the GCS, we assumed that the hidden layer transformations keep the data in Euclidean space. As such, with GCS, we know which layers help to solve the classification problem and which harm this training process. In order to obtain the results in this work, we conducted four experiments, as presented in the following subsections.
5.1. MNIST Data set Classification
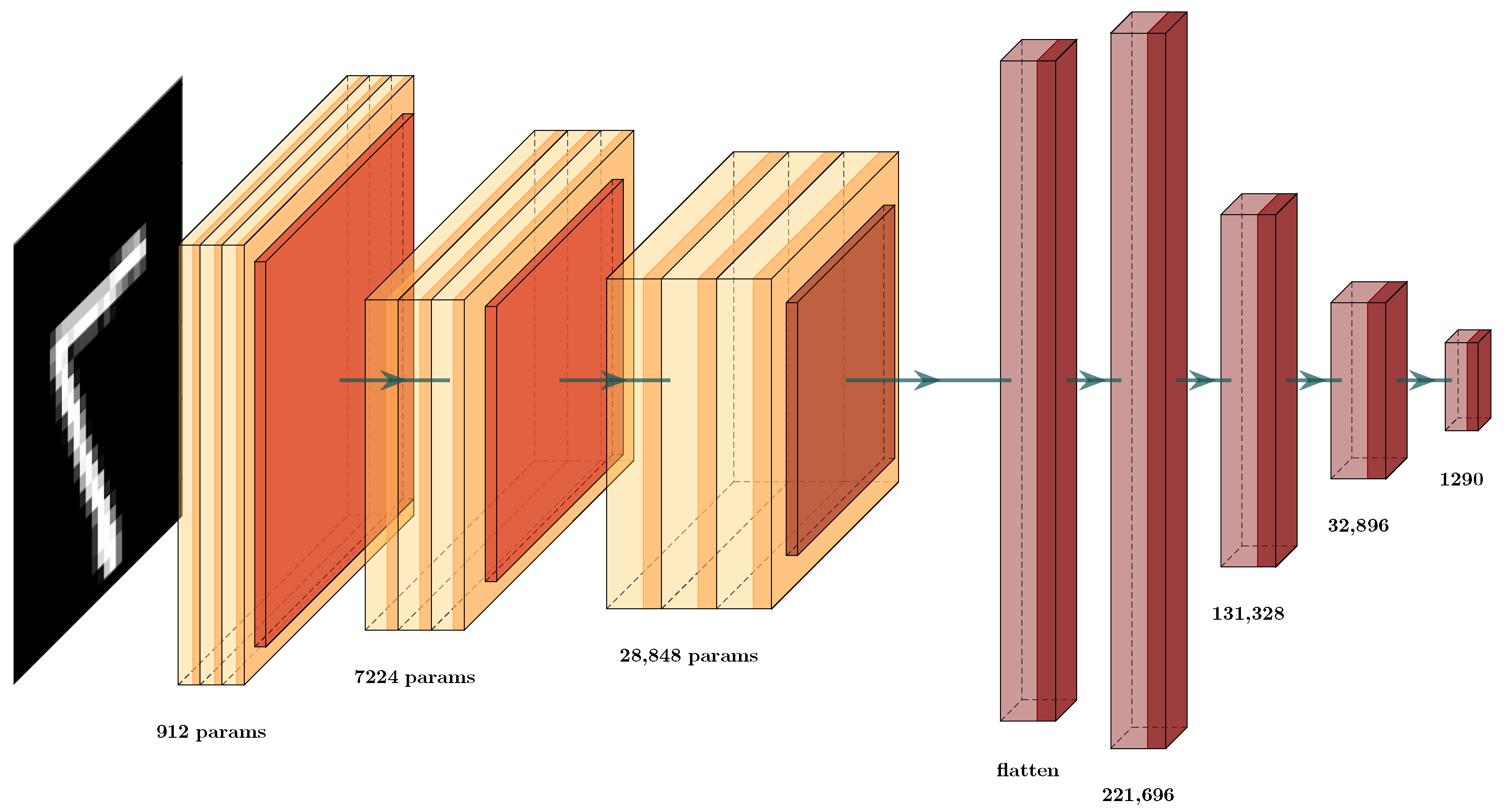
We tested the MNIST [
82] data set, due to its comprehensive use in state-of-the-art methods. In addition, a CNN architecture was designed, in order to analyze the behavior of GCS (
Figure 7), where a convolutional network was defined with the classic convolutional, max-pooling, and fully-connected layers. As previously mentioned, the convolutional layers possess a composition of different filters defined locally, which are optimized by the training process (
Figure 7). This is achieved through the well-known back-propagation process, through the use of automatic differentiation [
11]. We know that the aim of the convolution layers is to extract high-level features. This is why we obtain the GCS in the elements inside this architecture, in order to compare the behavior of each type of layer and determine how to optimize this architecture.
During training, these parameters/weights are changed, given the updates by the forward and backward procedures of training. Thus, the convolutional layers act as modifiable filters, extracting features first from a low level of interpretation to higher levels of interpretation. Thus, we had a GCS function at each of these layers, in order to score how well the new features are separable. The aim of this was to score the layer’s importance during the learning procedure. This allows us to decide whether or not to prune particular layers of the deep neural network (DNN). For this, we combined the ideas of transfer learning, using the GCS measure for each layer of the architecture.
First, we trained the architecture (
Figure 7) and used the GCS score to decide which layers are important in the classification effort to produce the GCS measure. This allowed us to identify which layers provided the best transformations during data processing and training. After training, we obtained the GCS score for each layer (
Table 1 and
Table 2). Based on those scores, we decided to prune certain layers. In the example in
Figure 8, we can see the new architecture and how the GCS score helped to decrease the complexity of the layers of the DNN. This new architecture had a similar structure to that shown in
Figure 7. Here, we see that the layers in red were removed, and the retained layers were those with a GCS measure value close to 1 or
. For example, we compare the results obtained in
Table 3, where the number of parameters in the original architecture CNN (a) was 424,194 weights. After GCS architecture reduction, the number the parameters decreased to 60,514. Thus, we used only 14% of the original architecture parameters however, even with this smaller architecture, the testing error decreased from 3.5% to 2.8%. We conclude that the GCS score can help to reduce the number of parameters while maintaining the performance of the original architecture.
Now, in more detail, we examine the two architectures used to prove this hypothesis (
Figure 7 and
Figure 8). In
Table 3, we display the testing error of each architecture on the validation set. The column Testing Error (%) shows the results for these architectures; in row CNN (a), the testing error and number of parameters for the original CNN (
Figure 7) are given while, in row CNN-GCS (b), we see the results of the architecture after the GCS architecture reduction, as shown in
Figure 8. To test whether this result supported our hypothesis, we experimented with an architecture similar to the first one in
Figure 9, by changing the number of neurons in the dense layers. These results can be observed in row CNN (c); by applying the GCS architecture reduction through Algorithm 2, we optimized this architecture (
Figure 10) to obtain the results in row CNN-GCS (d), where we can see a reduction in the number of parameters from 3,130,458 to 54,202. Basically, 98% of the parameters were eliminated, and testing error decreased from 2.5% to 2.4%. Although the testing error percentage slightly decreased, the number of parameters was considerably reduced.
The previous examples showed how GCS architecture reduction can improve the performance of deep architectures. This is astonishing, as the new architectures have considerably fewer parameters, even when compared to other state-of-the-art similar-sized architectures [
83,
84].
Table 4 shows how the GCS score improved the architecture and the performance; we compare the accuracy of our architectures after GCS architecture reduction (
Table 4, columns CNN-GCS (b) and CNN-GCS (d)). We observed that, for the MNIST classification problem, when comparing our testing error to that of the other approaches, our error was higher by approximately 2% and, within the two proposed architectures, there was a variation of 0.4%. Compared to the others, this resulted in about 2 million fewer parameters, and the difference in testing error was very low however, the objective of using the GCS is optimization of the deep neural network architecture. Thus, we observed that the architectures were optimized by removing several layers of the proposed architecture. Notably, the proposed architectures were trained from scratch completely in the MNIST data set only, and the reduction was performed using the GCS score. This is different from the other architectures, as they are trained on much larger data sets [
84]. Then, transfer learning was performed in the MNIST, which is an advantage, as more general filters are generated on the larger data sets, allowing them to perform better. After several failed attempts to obtain those data sets, we decided to use only the MNIST data sets. Thus, this is the reason for the difference of 1% or 2% between their architectures and our reduced architectures however, even under those restrictions, we believe that the GCS-reduced architectures are able to perform well, compared to larger architectures. This is important for intelligent environments, where resources are scarce [
26].
In this subsection, we show that architecture optimization by GCS reduces the number of parameters and, in some cases, also reduces the error on the testing set. Thus, in the following sections, we propose combining the improved TAM filters, deep learning, and GCS score to improve classification in the ERP data set.
5.2. Deep Learning Architecture Optimization by GCS for ERP Detection
In this subsection, we present a classification problem for ERP measurement using fMRI data. This data set is composed of BOLD fMRI records of individuals with specific labeled images [
85]. These images (
Figure 11) show different scenarios, such as people, animals, landscapes, and so on. Thus, the data set was composed of the fMRI record together with the image and correct labeling of that image. Specifically, the data obtained from the BOLD fMRI recording produced by the ERP brain response generates a data cube that provides 18 layers of images, where each image (
Figure 12) is a slice of the brain with dimensions of 64 × 64 pixels. This cube, with dimensions of 64 × 64 × 18, is the result of scanning the brain activity through the entire experiment described in [
86].
We propose the full integration of TAM and the GCS score in a deep learning architecture. First, we designed a simple deep learning architecture with the input 3D data and eight dense layers (
Figure 13). This architecture obtains the cubes from the fMRI. Then, it uses the architecture to solve the ERP classification problem.
Table 5 lists the accuracy results obtained from the proposed architecture with a testing error of 23.05%, which is unsatisfactory. Here, we had two options: Change the input samples from the original data set for TAM features or reduce the proposed architecture using this methodology. We obtained the results in
Table 6 for the GCS score. Even when the values from the layers obtained a GCS measure close to 1 or −1, we could not assure that the classifier would obtain 100% accuracy, as DNNs have different possible architectures with several different hyperparameters that provide different values in the prediction. Observing the results, we found that the value increased slightly as the number of layers increased until layer seven, where the value decreased. From this, we inferred that each transformation until the seventh layer helped to improve the classification performance of the CNN. Thus, we propose using the algorithm for the GCS score Algorithm 2 to select the correct set of layers for GCS architecture reduction.
Figure 14 displays the new architecture after the reduction, in which we compare the number of layers against the original architecture (
Figure 13), where the removed dense layers are indicated in red. In this scenario, the reduction only occurred in one layer. This indicates that the input data involve a complex classification problem, where each layer is helping to solve the classification problem or the input features that are not suitable to solve the problem. After implementing the GCS architecture reduction, the values did not change much (
Table 5). The number of hyperparameters decreased from 0.42 million to 0.41 million, and the testing error decreased from 23.05% to 21.03%. Thus, we could not conclude whether GCS helped to optimize the deep learning architecture. This may be due to different factors, such as the input data not having features that facilitate classification. The following subsection analyzes how TAM features with deep learning architectures can help us to solve this classification problem.
5.3. TAM Features and CNN Architecture Optimization by GCS for ERP Detection
We tested deep learning architectures to classify ERPs. Thus, we evaluated the combination of deep learning architectures and the different TAM features to identify the best one to solve the ERP classification problem. We also used the GCS measure to evaluate the features obtained. For this, we processed each TAM feature separately, and introduced it into the proposed deep learning architecture. This created a scenario with which to test each of the different TAM features entropy, energy, contrast, and homogeneity with a deep learning architecture (
Figure 15), and to use GCS architecture reduction.
Table 7 shows the GCS scores from the data TAM layer features through all the layers.
Table 7 shows how the GCS measurements in each hidden layer slightly varied however, these variations are not incremental; they increase and decrease due to the different transformations through each layer. Additionally the GCS score shows that some layers obtained better features, and other transformations seem to add noise. Then, it was possible to reduce the proposed architecture to obtain
Figure 16.
The results obtained by this reduction were compared to the original architecture that classified the TAM features individually in
Table 8. We can observe that the value of the testing error did not vary substantially however, we observed that the same error values could be obtained with much smaller architectures (
Figure 16). We compare the number of layers that we removed through GCS architecture reduction in red in
Figure 15. Thus, the results confirm our original hypothesis. We evaluated the data transformations in the hidden layers and optimized the number of parameters with GCS architecture reduction. This provides opportunities to address countless questions and new ideas, for example, how to obtain the best optimization of this type of architecture. This is mentioned in the Discussion
Section 6.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}