1. Introduction
In natural language, a referential pronoun is often used to denote an previously mentioned individual [
1]. Pragmatically, a significant role of pronouns is to connect new information to what has already been presented in the context [
2]. Pronoun resolution is thus a fundamental process in language comprehension [
3]. Although it is argued that the readers determine pronoun referents mainly based on the gender of the pronoun [
4], this task is complicated by the fact that pronouns may present referential ambiguity, where the gender information is insufficient for referent identification. The resolution of ambiguous pronouns, which pose a challenge in language comprehension, has aroused wide interest in the transdisciplinary research field of linguistics, psychology, neuroscience, and machine learning. For instance, the Google AI team has recently presented and released a gender-balanced corpus of 8908 ambiguous pronoun–noun pairs based on real-world text [
5].
In the field of human–machine interaction, understanding the cognitive states of language comprehension becomes increasingly important, as it could be applied to improve the working efficiency of artificial intelligence. Discovering the cognitive mechanism underlying pronoun resolution is a critical component of understanding human language comprehension. Approaches for characterizing the cognitive procedures of pronoun resolution vary by level of analysis. At the behavioral level, psycholinguists normally study pronoun resolution via analysis of behavioral data, such as response accuracy and reaction time collected from designed questionnaires [
6,
7]. A group of psycholinguistic studies investigated how a reader identifies the referent of a pronoun. In the cases of unambiguous pronoun resolution, gender information was mainly used to determine the referent of a pronoun [
4]. In comparison, ambiguous pronoun resolution required more information from linguistic cues, such as verb-bias, focus, and implicit causality [
8,
9]. A limitation of behavioral analysis is that its reliability largely depends on the experimental design. For instance, when certain task circumstances require a human operator to perform manual operations without expressions and interruptions, data from rating questionnaires and external behaviors is difficult to collect [
10,
11].
At the neural level, cognitive neuroscientists have attempted to reveal the neural correlates underlying the cognitive procedure of pronoun resolution. Neural measures provide complementary information to discover the cognitive function of language. Neurophysiological signals have attracted much attention, since they can be decoded to investigate the inner cognitive state [
12,
13,
14]. A handful of studies based on fMRI tried to identify the neuroanatomic mechanism of pronoun resolution as related to a decision-making process. In a review work, Chen argued that the reward and cost evaluation in the process of decision making was correlated with an activation in the forebrain structures [
15]. Nieuwland et al. studied the brain activity during pronoun resolution in Dutch and identified the recruitment of decision-making-related neural correlates (including media frontal, right superior, medial parietal, and bilateral inferior parietal cortex) while resolving ambiguous pronouns compared to unambiguous cases, suggesting ambiguous pronoun processing involves a cognitive process of decision making [
16]. McMillan et al. studied pronoun resolution in English and identified the involvement of brain areas related to probabilistic evaluation (dorsolateral prefrontal cortex) and risk evaluation (orbital frontal cortex) during ambiguous pronoun resolution [
17]. These empirical results are consistent with an influential trend of pragmatic tradition, namely Gricean theory for pragmatic reasoning [
18]. According to a game-theoretic framework of Gricean tradition [
19,
20,
21,
22,
23], ambiguous pronoun resolution will trigger a cognitive mechanism of decision making. It is argued that readers resolve an ambiguous pronoun following two cognitive steps [
24]: first, they strategically select the referent of the pronoun in a probabilistic way, maximizing the possibility of correctly understanding the pronoun sentence; second, they evaluate the likelihood of selecting the incorrect referent of the pronoun, minimizing the risk of misinterpreting the sentence. On the other hand, a small number of ERP studies have provided neural information on pronoun resolution. Ledoux et al. suggested that the processing of pronoun resolution occurs between 250 and 500 milliseconds [
25]. According to a review work of Nieuwland and Van Berkum, the processing of ambiguous pronoun resolution will induce a continuous frontal negative-going ERP [
26]. Daltrozzo et al. reported different ERP effects, comparing automatic with controlled processes of speech perception [
27].
Although the above research was conducted on the neural measurement of reference resolution, not much is known about the essential differences in cognitive workload recruited to support different tasks of unambiguous pronoun resolution and ambiguous pronoun resolution in Chinese. Unlike English, Chinese is a tonal language and thus has suprasegmental features such as pitch changes, resulting in a great number of homophones in the vocabulary [
28]. Based on a recent fMRI study, Ge et al. reported the differences in neural correlates underlying speech comprehension between English and Chinese: the latter involves additional activation of the right hemisphere, which has long been considered as largely unrelated to language processing [
29]. It is worthwhile mentioning that the electroencephalogram (EEG) with portable sensors can be conveniently implemented in a passive brain–computer interfacing system to measure human cognitive workload [
30,
31]. Compared to fMRI and ERP, EEG signals provide continuous observation of brain activities through cortical networks at a sampling frequency greater than 1000 Hz [
32], with millisecond-range temporal resolution [
33]. Thus, EEG data are commonly used to study various human cognitive functions, such as emotion [
34,
35], language processing [
36,
37], and memory [
38,
39]. A challenge for studying the cognitive workload correlated to pronoun resolution based on EEG data is to find approaches to decoding EEG signals across different participants and dimensionalities.
At the level of algorithm, the methods of machine learning and deep learning have received much attention. Ladekar et al. used energy, band entropy, non-linear energy, and signal length to extract features and used a K-nearest neighbor (KNN) classifier to identify cognitive workload [
40]. Maldonado et al. computed the statistics (i.e., mean, median, and variance) of each EEG signal, extracted the EEG feature of entropy by discrete wavelet transform (DWT), and employed the support vector machine (SVM) as the approach of feature selection [
41]. Based on the features obtained by wavelet transform decomposition of EEG signals and by ensemble subspace K-nearest Neighbor (ESKNN), Gupta and Manthalkar obtained a classification accuracy of 86.12% [
42]. Bhattacharyya et al. extracted the temporal and spectral entropies from the multichannel EEG signal. These features were smoothed and applied to the sparse autoencoder random forest (ARF) classifier [
43]. Based on a wavelet transformation, Zhang and Wang added time and frequency dimensions to EEG topographic maps and proposed a concatenated structure of deep recurrent and 3D convolutional neural networks (R3DCNN) to identify cognitive workload levels [
44]. In recent studies, Zhang et al. proposed the two-stream neural networks to fuse the extracted EEG features from two relevant domains [
45]. The feature embedding was generated by combining spectral and temporal information from the spatial distribution of the EEG power. Almogbel et al. applied a 10-layer convolutional neural network to identify a two-level workload under a simulated driving task [
46]. The classification accuracy was achieved at 86.5% when four-channel EEG with fast Fourier transformation was applied. Fan et al. evaluated the affective state and workload of adolescents with autism spectrum disorder using wireless EEG signals [
47]. By using the leave-one-subject-out cross-validation paradigm, the classification accuracy of the workload was 86%. Accuracies of enjoyment and frustration were 90% and 88%, respectively. Blanco et al. used dry EEG sensors to quantify the workload of flight pilots, and the median of the classification was 90.17% [
48]. They found that the feature combination and the classifiers should be personalized to fit the distribution of each participant. Lim and Sourina applied transfer component analysis to identify workload across two independent databases with 48 subjects and 18 subjects, respectively [
49]. The average classification accuracy was 30% for four-class classification. Wang et al. applied a wireless EEG system to evaluate human workload under three conditions [
50]. Based on a proximal support vector machine, the classification rate was higher than 80%. The above works indicate the effectiveness of using EEG to evaluate cognitive workload under a variety of cognitive tasks.
Our investigation had the goal of studying the underlying cognitive mechanisms of pronoun resolution. Although machine learning and deep learning applied to the analysis of the big EEG data are useful for investigating the underlying neural correlates of pronoun resolution, how EEG signals reveal the cognitive states of pronoun resolution remains largely uncharacterized. The current study aims to explore the cognitive mechanisms of pronoun resolution for two types of pronouns: unambiguous and ambiguous pronouns. We hypothesize that the resolution of unambiguous and ambiguous pronouns involves different cognitive mechanisms. More specifically, we hypothesize that ambiguous pronoun resolution is associated with more than one adequate answer and thus may induce a decision-making process. This hypothesis is consistent with fMRI evidence, since recruitment of decision-making-related neural correlates has been observed [
16,
17]. Accordingly, compared to unambiguous conditions, people may spend more time choosing a referent for an ambiguous pronoun, as the answer is undetermined, while people may also feel more flexible, as it is less risky to make a mistake. To test these hypotheses, we examined the cognitive workload recruited in pronoun resolution for two types of pronouns. We used EEG to investigate the neural correlates of pronoun resolution. Behavioral data including reaction time and response selection as well as the EEG signals were collected during the pronoun resolution task. We applied pre-trained deep convolutional neural networks (CNNs) to represent spatial patterns of the EEG power features of multiple frequency bands. In particular, two heterogeneous architectures, GoogLeNet [
51] and EfficientNet [
52], of the deep neural networks were simultaneously employed to find useful hidden information behind combinations of channels and frequency bands. Extracted high-level EEG representations were then fused as a single feature vector to the shallow learning machines to distinguish binary levels of the cognitive workload. Under such a paradigm, the designed deep network could be pre-trained by the huge size of a natural image training set, and then weights of its last layer could be fine-tuned by a specific EEG database with target cognitive workload labels to ensure the generalization capability.
2. Materials and Methods
2.1. Participants
As an extension of our previous study [
53], seventeen volunteers participated in our pronoun resolution task. All volunteers were undergraduate or graduate students from the USST, male, right-handed, in good health with no history of neurological difficulty, and native speakers of Chinese. All participants gave informed consent under the Declaration of Helsinki and a protocol approved by the Ethical Committee of USST (protocol code 1801002). None of the participants had any experience in performing similar cognitive tasks aiming at avoiding the learning effects.
2.2. Behavioral Stimuli
As the behavioral stimuli of our experiments, 200 combinations of noun sentences and pronoun sentences were constructed following three steps. First, we identified 40 Chinese gender-neutral nouns and 40 Chinese gender-biased nouns. The nouns were first chosen manually based on a self-built corpus from articles published in a Chinese magazine named
Duzhe, which is one of the best-selling magazines in China. We then asked 30 students from the University of Shanghai for Science and Technology (USST) to rate each noun according to the gender of the noun. The rules of gender rating are shown in
Table 1. On a five-point scale, the student rates a noun (e.g.,
taitai ‘madam’) one point if he thinks it definitely represents a female, a noun (e.g.,
hushi ‘nurse’) two points for being weakly female, a noun (e.g.,
tongshi ‘colleague’) three points for being gender neutral, a noun (e.g.,
fanren ‘prisoner’) four points for being weakly male, a noun (e.g.,
xiaonanhai ‘little boy’) five points for being definitely male. We then converted the five-point scale to a three-point scale: we replaced all of the two- and four-point responses with two points, indicating that the noun is weakly gender-biased; we replaced all the three-point responses with one point, indicating that the noun is gender neutral. A statistical analysis based on the rating data from thirty students suggested that the identified gender-neutral nouns (
M = 1.33;
SD = 0.18) were significantly more neutral than gender-biased nouns (
M = 2.98;
SD = 0.06;
t (78) = 54.25;
p < 0.0001). The statistical analysis justified our choices of nouns according to gender information.
Second, with these 80 nouns, we constructed 200 noun sentences by pairing two nouns with one verb to create each complete and meaningful noun sentence. We constructed the noun sentences with two different syntactic structures: 100 sentences with the structure of subject-verb-object (S-V-O, for short) and the other 100 sentences with the structure of noun-noun-verb (N1-N2-V, for short). Sentences structured as S-V-O appear in both Chinese and English, while those structured as N1-N2-V appear only in Chinese rather than in English. Third, we paired each noun sentence with a pronoun sentence. Each pronoun sentence consisted of a pronoun in the form of the third person singular (i.e., ta, ‘he’ or ‘she’) and an intransitive verb (e.g., xiao, ‘smile’). Each pair of sentences formed a separate and meaningful context. For each sentence pair, at least one proper candidate could be identified as the referent of the pronoun, whereas no candidates could be excluded in principle by pragmatic reasoning or by the information of linguistic cues (e.g., verb bias, focus, causality, etc.), except for gender information.
We divided the behavioral stimuli into two types: (i) Type 0, where the referent of the pronoun is undetermined by the gender information alone, namely, the pronoun is ambiguous in the context; (ii) Type 1, where the pronoun unambiguously refers to a noun provided with the gender information. Sentences of different syntactic structures (i.e., S-V-O or N1-N2-V) were distributed into the two types of cases. For instance, “
Nanren (‘man’)
xiangxin (‘believe’)
nüer (‘daughter’)
Ta (‘he’)
xiao-le (‘smile ASP’) ‘The man believed the daughter. He smiled.’”, with the structure of S-V-O, belongs to Type 1, while “
Qizi (‘wife’)
he (‘and’)
xiaonühai (‘little girl’)
jianmian (‘meet’).
Ta (‘she’)
manzu-le (‘satisfy ASP’). ‘The wife met the little girl. She satisfied.’”, with the structure of N1-N2-V, belongs to Type 0. To cover all the cases, we considered all combinations of conditions, including the gender of nouns, gender of the pronoun, and the syntactic structure. For each combination of the conditions, the number of trials was 20. Of the 200 trials, 120 trials contained ambiguous pronouns (including 60 trials with S-V-O and 60 trials with N1-N2-V), and 80 trials contained unambiguous pronouns (including 40 trials with S-V-O and 40 trials with N1-N2-V). A description of the behavioral stimuli is shown in
Table 2.
2.3. Experimental Procedure
The experiment was conducted in a clean, silent room at 26 °C, controlled by an air conditioner. The participant sat comfortably in a chair with a distance of approximately 60 cm to a laptop screen that could provide programmed information of the pronoun resolution task. All experiments were conducted in the evening in order to avoid circadian rhythm.
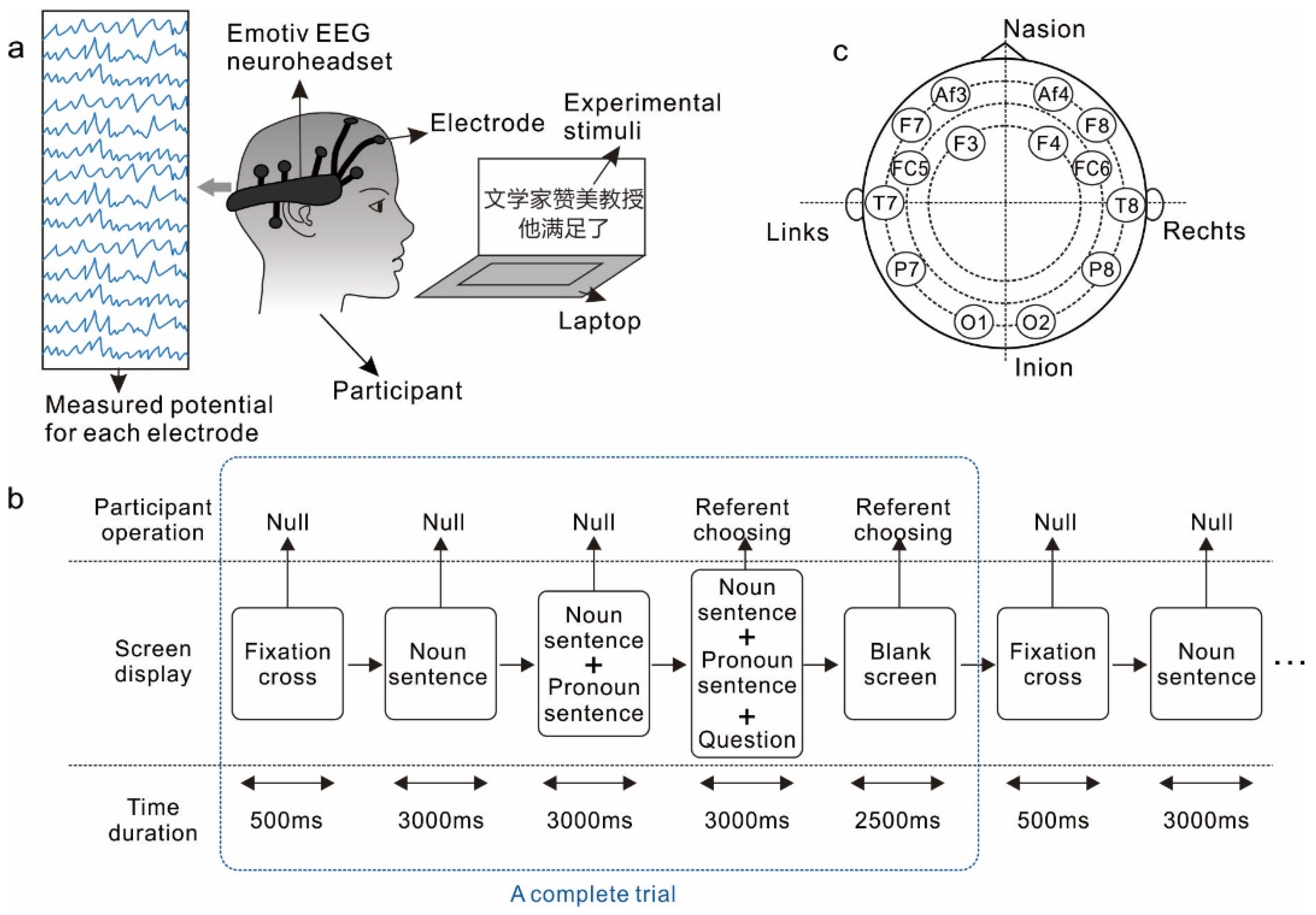
Participants were required to complete the task of identifying the referent of the pronoun in various pairs of Chinese sentences, which were programmed and displayed on a 14 inch laptop computer screen (Dell Windows 10 operation system, Inteli5 CPU 1.6 GHZ, and 12 GRAM configurations). The EEG signals were recorded via an acquisition device, i.e., EMOTIV Epoc+ headset, linked to another laptop computer, and were continuously monitored by an experimenter during the whole procedure. EMOTIV is made up of 16 individual electrodes, of which two are reference potentials, and the other 14 are hydration sensors.
Figure 1 illustrates the schematic of the experimental setting, experimental procedure of the pronoun resolution task, and the locations of the 14 electrodes.
Each participant completed 200 experimental trials, and each trial lasted for 12 seconds. Instead of using timing markers, we directly recorded a whole section of the EEG output of each participant, and then segmented the data according to the experimental process to mark the EEG output of each trial. A single experimental trial started by a fixation cross lasting 500 milliseconds, followed by three stimulus events, each lasting 3000 milliseconds. In the first event, the participant was presented with a noun sentence (for instance, Taitai weixie nüyanyuan: ‘The madam threatened the actress’) displayed on the computer screen. In the second event, the participant was presented with both the noun sentence and a pronoun sentence (for instance, Ta shengqi-le: ‘She was angry’) on the screen. In the third stimulus event, the participant was presented with the noun sentence, the pronoun sentence, and a question that required the participant to choose a referent of the pronoun from the two nouns in the noun sentence. The participant was instructed to choose the noun that appeared on the left (for instance, taitai: ‘the madam’ in the previous example) by pressing ‘Z’ on the keyboard or the one on the right (for instance, nüyanyuan: ‘the actress’ in the previous example) by press ‘M’. After the question disappeared, a blank screen would last for 2500 milliseconds. From the appearance of the question until the end of the blank screen, the choice of the participant could be recorded. We divided the 200 trials into 5 blocks, and each block contained 40 trials. The participant was allowed a 2 minute break between every two blocks. Before the experiment began, an experimenter introduced details of the number of trials, types of Chinese sentences, and how to answer the designed questions. Prior to the EEG recording session, the participants were allowed to practice ten trials to make sure that they had fully understood the task.
2.4. EEG Data Preprocessing and Analysis
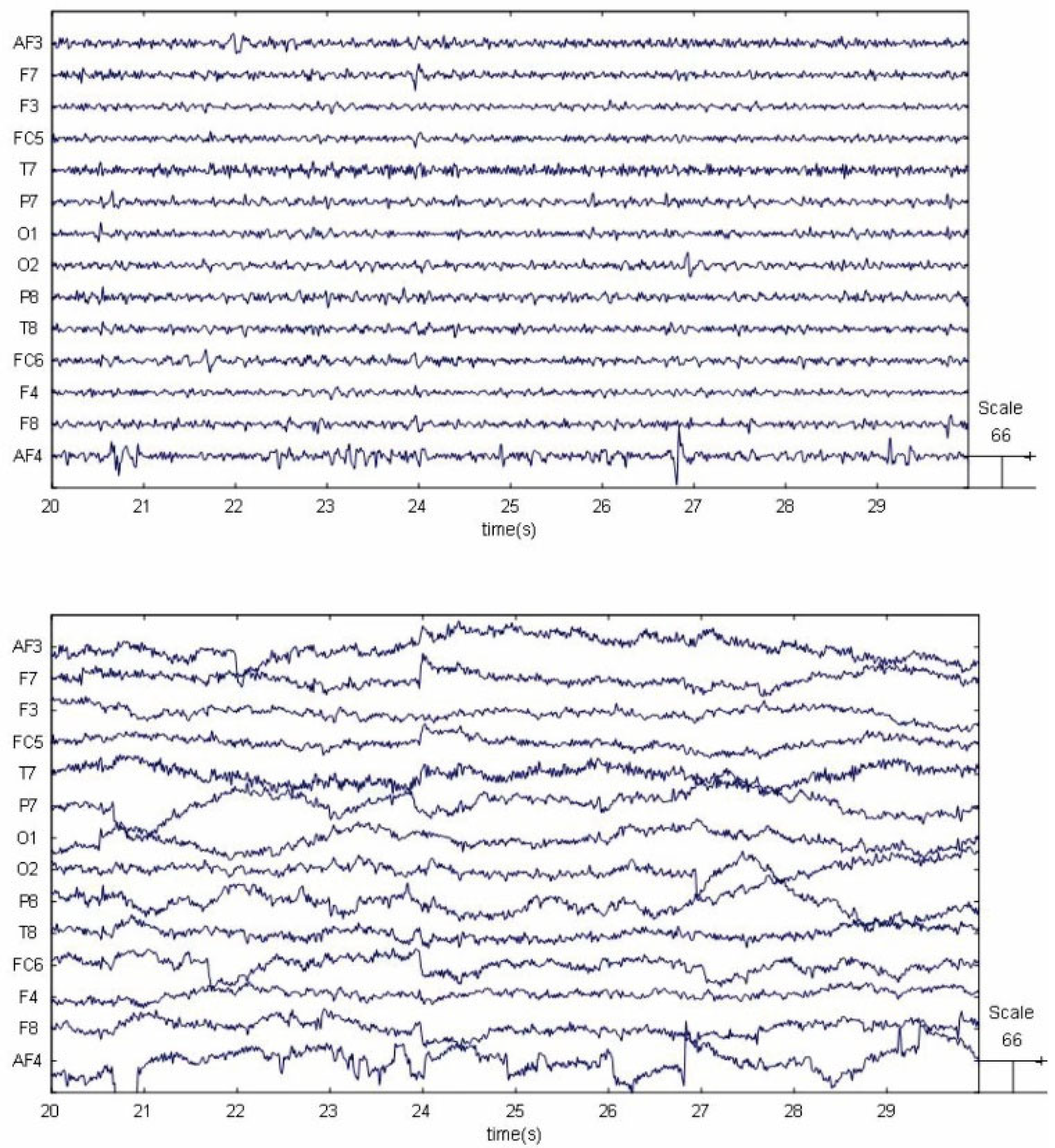
When the participants accomplished each trial, we used the EMOTIV Epoc+ (Emotive Systems, San Francisco, USA) EEG headset to record EEG signals of all the participants with a sampling rate of 128 Hz. The employed channel locations labeled with the 10–20 international EEG system are O1, O2, P7, P8, T7, T8, FC5, FC6, F3, F4, F7, F8, AF3, and AF4. EEGlab was used to process the raw data, and the interpolation was carried out to estimate the missing values. Then, the interpolated signals were preprocessed by a linear finite impulse response (FIR) filter. The cut-off frequencies of the passband were set at 4–45 Hz. The comparison of EEG signals before and after FIR passband filtering is shown in
Figure 2. Each experimental trial corresponds to a 12 second EEG segment. For each participant, 200 feature vectors corresponding to 200 EEG segments were extracted. For each feature vector, the power of theta (4–8 Hz), alpha (8–13 Hz), and the mean power of beta (14–30 Hz) and gamma (31–40 Hz) were computed by application of the discrete Fourier transform (DFT). Therefore, each EEG segment elicited 42 PSD features (3 features × 14 channels).
Since we plan to use supervised machine learning and deep learning methods to assess workload recognition performance, the target levels (category labels) of the workload for each feature vector should be predetermined. Considering the fact that the sentences in the experiment can be grouped as Type 0 and Type 1 according to the presence or absence of the ambiguous pronouns, the two categories of EEG feature vectors were labeled with 0 and 1, respectively.
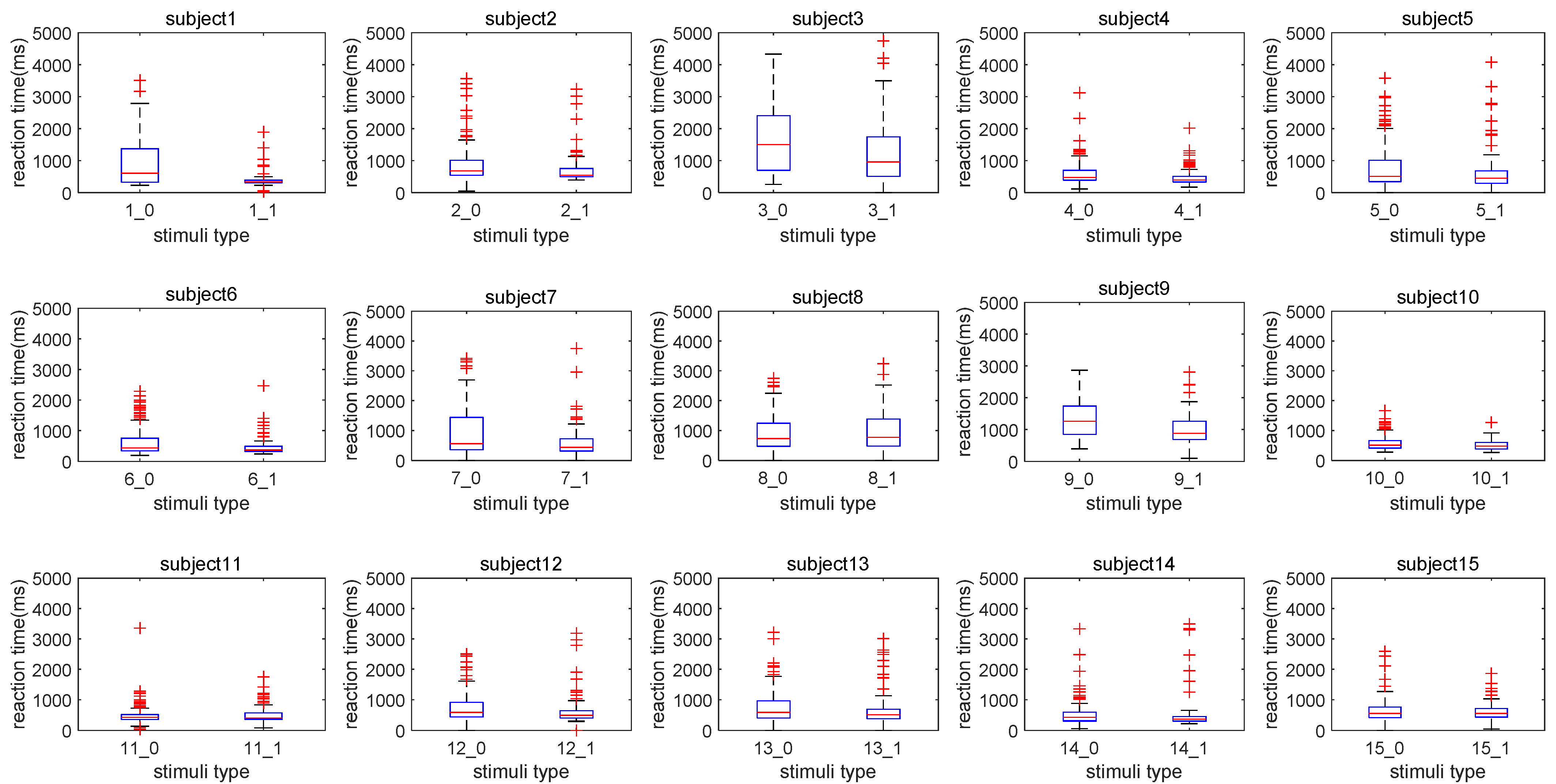
Behavioral data such as reaction times and participants’ responses were analyzed during the experiments. In each experimental trial, the specific point in time when a participant chose a referent by pressing ’Z’ or ‘M’ on the keyboard was recorded. The reaction time of the participant in this trial was then computed, given the time information when both the sentence pairs and the question appeared on the computer screen (i.e., the starting point when the participant made the choice). Participants’ reaction times in the cases of ambiguous pronoun resolution were compared to those in unambiguous cases via a two-sample t-test. With Type 1 stimuli (the cases of unambiguous pronoun resolution), the participants’ responses were compared to a standard answer, whereby accuracy rates were computed for each participant.
2.5. Methods
We present in this section our approach for high-level feature abstractions of the EEG power features to classify pronoun resolution based on three convolutional neural networks (CNNs): LeNeT-5, GoogleNet, and EfficientNet. CNN is one of the most popular deep learning techniques. Initially, CNN is mainly applied to image analysis and shows superb performance on image feature abstraction and classification. It has also been proven that CNN has advantages in biomedical signal processing and recognition. We first introduce three CNN models for abstracting spatial EEG feature maps. Then, the scheme of the EEG feature fusion for heterogonous modes is presented.
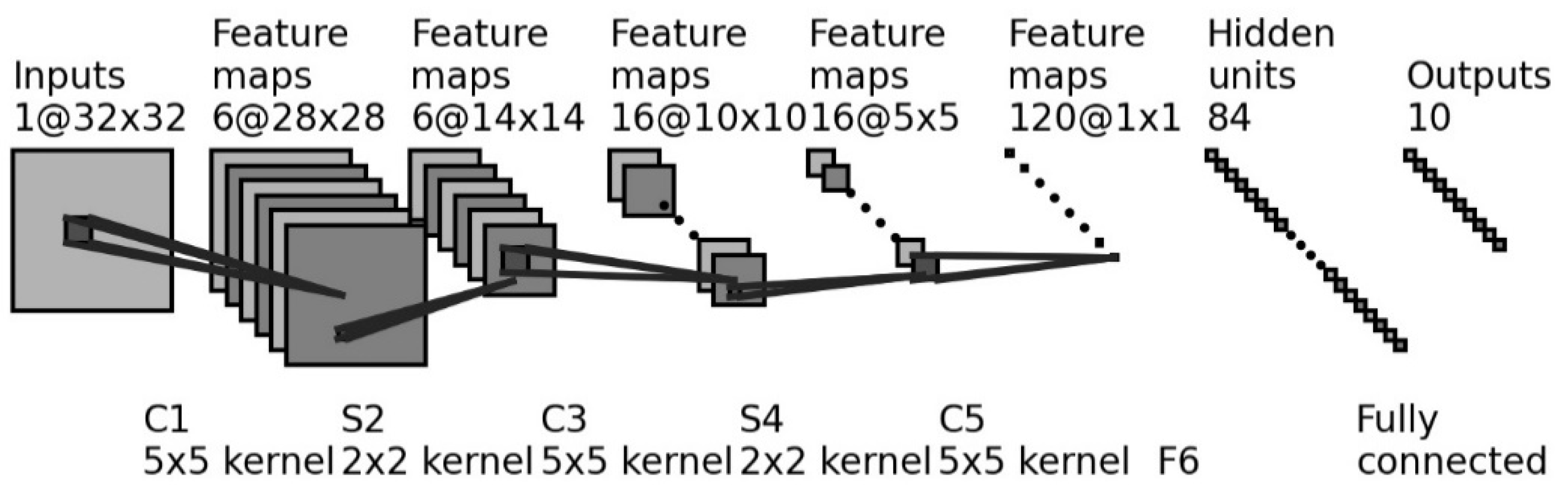
2.5.1. LeNet-5
LeNet-5 is a typical convolutional network proposed by LeCun et al., with eight cascade layers, i.e., an input layer, a convolutional layer (C1), a subsampling layer (S2), a second convolutional layer (C3), a second subsampling layer (S4), a third convolutional layer (C5), a fully connected layer (F6), and an output layer. The architecture of the LeNet-5 is shown in
Figure 3. The role of each layer is introduced as follows.
Layer C1 is set up for feature extraction. The input of EEG spatial features is operated with the convolution kernel size of 5 × 5, and then six feature maps are abstracted. Layer S2 is used for data dimension reduction. The size of each feature map is reduced to half by scanning a 2 × 2 patch. In order to reduce the data dimension, the activations of four nodes selected by the 2 × 2 patch are averaged. Its outputs are multiplied by a trainable weight matrix and added with a trainable bias vector. The sigmoid function is used as the activate function.
Layer C3 is similar to C1, while 16 feature maps are abstracted after the convolutional operation with the kernel size of 5 × 5. Similar to S2, S4 has 16 feature maps with the size of 5 × 5. Layer C5 is also a convolutional layer that has 120 feature maps after a convolutional operation. After applying the 5 × 5 convolution kernel on each feature map, the output size of C5 becomes a vector. Layer F6 has 84 units, all of which are fully connected to C5.
2.5.2. GoogLeNet
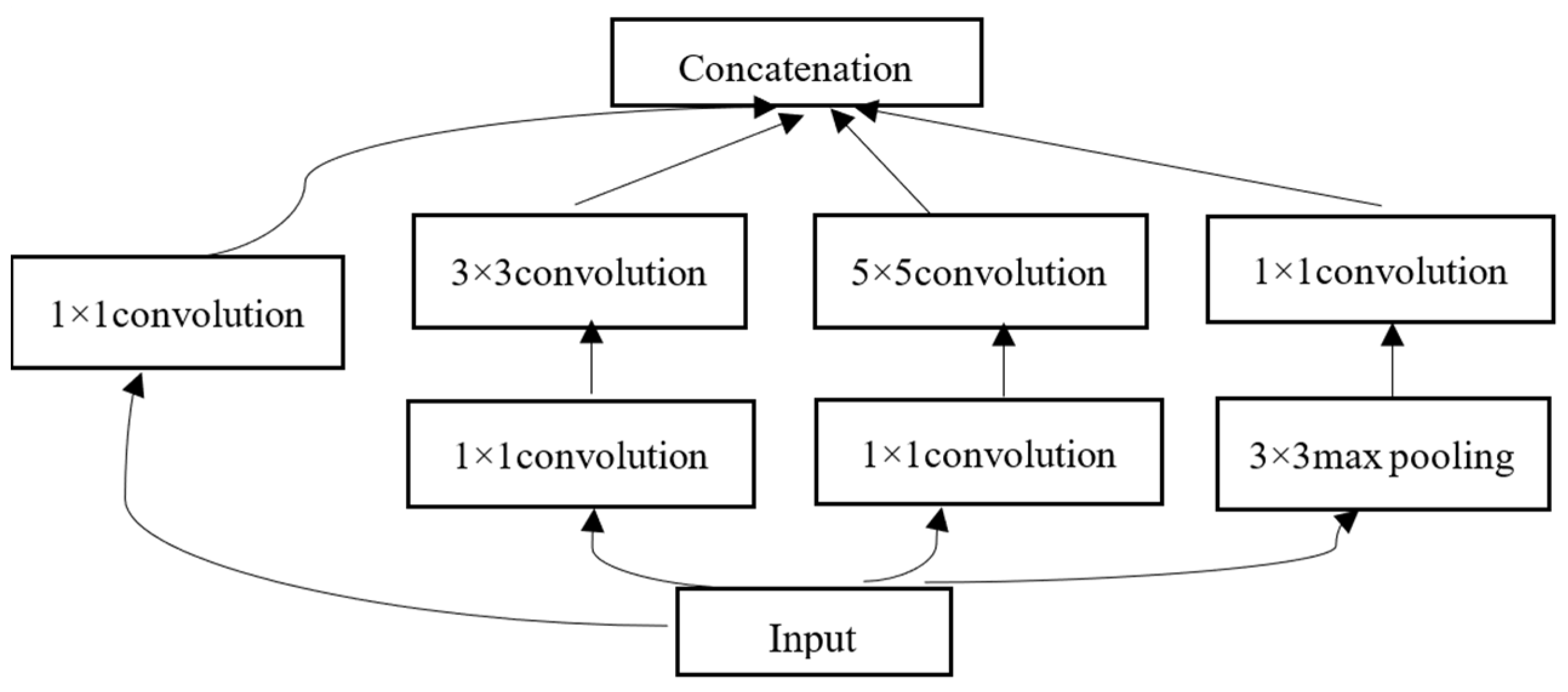
GoogLeNet is a deeper and wider convolutional network but with less trainable parameters compared to other CNNs with large depth. A large depth of network (22 layers with trainable parameters) and the possession of the Inception module improve the performance of GoogLeNet.
The Inception module aims to achieve a better representation of the input by the use of several convolutional kernels of different sizes to realize perceptions on different scales. The original Inception module consists of four parts: 1 × 1 convolutions, 3 × 3 convolutions, 5 × 5 convolutions, and 3 × 3 max pooling. The input EEG spatial map is sent into four parallel subnetworks. After several convolution and pooling operations, the outputs of each part are concatenated, which form the final output of the Inception module. To reduce the computational cost, GoogLeNet adopts the Inception V1 based on the naïve Inception module. The 1 × 1 convolutions are used to compute reduced feature maps before the subnetworks and a rectified linear activation function is applied as shown in
Figure 4.
The structure of GoogLeNet is shown in
Table 3. In addition to the Inception module, the convolution layers and pooling layers are similar to popular CNNs like VGG and AlexNet. It is remarkable that GoogLeNet replaces three fully connected layers with an average pool layer and dropout layer to prevent overfitting.
2.5.3. EfficientNet
There are three common approaches to improving the performance of the network: increasing one of network width, depth, or resolution. The CNN model with a larger width of the kernel can capture fine-grain features, but it has difficulties in extracting high-level abstractions. Deeper CNN is able to extract richer features but has difficulty in training due to the vanishing of gradients. Increasing the resolution of the input EEG spatial map will obtain fine-grain patterns at the cost of increased computational time. The EfficientNet is a CNN architecture that balances three schemes to achieve competitive accuracy at a lower computational cost.
Table 4 shows the basic architecture of EfficientNet-B0 used in this study. The MBConv block uses the swish function as the activate function and adds a Squeeze-and-Excitation (SE) module. In an MBConv block, the input is sent into a 1 × 1 convolutional layer to increase the dimension. The number of convolutional kernels is
n times the input channels. Then, a
k × k depth-wise convolutional layer is applied. Feature maps obtained by the previous layer are sent into the SE module, which is formed by an average pooling layer and two fully connected layers. The outputs of the SE then go through a 1 × 1 convolutional layer and a dropout layer to find high-level feature representations.
2.5.4. Feature Fusion
Integrating different scales of features is an important method to improve classification performance. Low-level features have higher resolutions, while high-level features have more useful information. How to fuse these EEG feature abstractions in an effective way is the key to improving the generalization capacity of the deep CNN model. In general, feature fusion can be cataloged in two ways by the sequence of fusion and prediction, namely early fusion and late fusion. Here, we employ the scheme of early fusion at the feature level. Principal component analysis (PCA) is used to find the low dimensional embedding of the output abstractions from LeNet5, GoogLeNet, and EfficientNet.
The main purpose of the PCA is to reduce the dimension of features and to discover principal directions embedded in the original feature space. First, each dimension of the feature abstraction is standardized into the values with zero mean and unit variance. Second, assume that a unit vector with maximum variance is mapped from original feature abstractions. The variance can be defined as
Due to the standardized operation, Euation (1) can be written as
The process of finding the mapping matrix is equivalent to evaluating the maximum of the variance, i.e.,
Therefore, the output of the PCA model can be computed as follows:
In the equation, , , and are the feature abstractions computed by the LeNet5, GoogLeNet, and EfficientNet, respectively.
2.5.5. Performance Indicators
To evaluate the classification performance of the cognitive workload classifier, indicators including accuracy (ACC), sensitivity (SEN), and specificity (SPE) are used and described as follows.
where
TP (true positive) indicates that the number of EEG feature vectors corresponding to unambiguous pronoun resolution is correctly classified. The
FP (false positive) refers to the number of the EEG feature vectors of ambiguous pronoun resolution that are misclassified as unambiguous conditions. The
TN (true negative) indicates the number of the EEG feature vectors corresponding to the ambiguous pronoun resolution is correctly classified. The
FN (false negative) indicates misclassification as unambiguous pronoun resolution.
4. Discussion
According to the analysis of participants’ performances on the pronoun resolution trials, their reaction times, and the EEG distributions, we discover that the change of the manipulated task condition can induce the variation of the external behavior indicator of the main task. When gender information was not sufficient to identify the referent of a pronoun in the Chinese context, we observed a relatively longer reaction time consumed by pronoun resolution compared to unambiguous controls (
Figure 5 and
Table 7). In contrast, our EEG results suggested that unambiguous pronoun resolution was associated with a heavier cognitive workload than its ambiguous counterpart (
Table 8 and
Figure 6). We hypothesize that different cognitive mechanisms were recruited during the resolution procedures of different referential types, namely ambiguous and unambiguous pronouns. We argue that the cognitive workload as an indicator at a neurophysiological level may provide complementary information to understand the cognitive mechanisms of pronoun resolution. Specifically, we discuss the role of the behavioral representations and the cognitive workload in discovering the cognitive procedures of pronoun resolution based on a tripartite structure of analysis at different levels, namely the behavioral, neural, and algorithm levels.
To understand the cognitive mechanisms underlying pronoun resolution, we first compare our experimental results at the behavioral level. The overall high accuracy rate (
Table 5) in unambiguous conditions suggests that gender information could be used to determine the referent of an unambiguous pronoun and that all participants except one (i.e., P8) actively participated in our cognitive task of pronoun resolution. Previous investigations have reported the usefulness of gender information in determining a correct referent [
4,
16,
17]. We observed the consistency of the participants’ selections (
Table 6) in the ambiguous cases, which have previously been reported to reflect the fact that other linguistic cues such as verb bias could be used in identifying a pronoun’s referent [
8]. The reaction times, on the whole, revealed that ambiguous pronoun resolution was correlated to a more time-consuming cognitive mechanism compared to unambiguous controls. Several investigations also have implicated longer reading time for referentially ambiguous words [
54,
55]. For seven participants in our experiments, namely P1, P3, P4, P6, P7, P9, and P10, the significantly increased reaction time suggested an increased processing difficulty when ambiguous pronouns were identified by operators. Based on our literature review, we hypothesize that a two-step mechanism of decision making contributes to ambiguous pronoun resolution compared to unambiguous controls, causing greater reaction time.
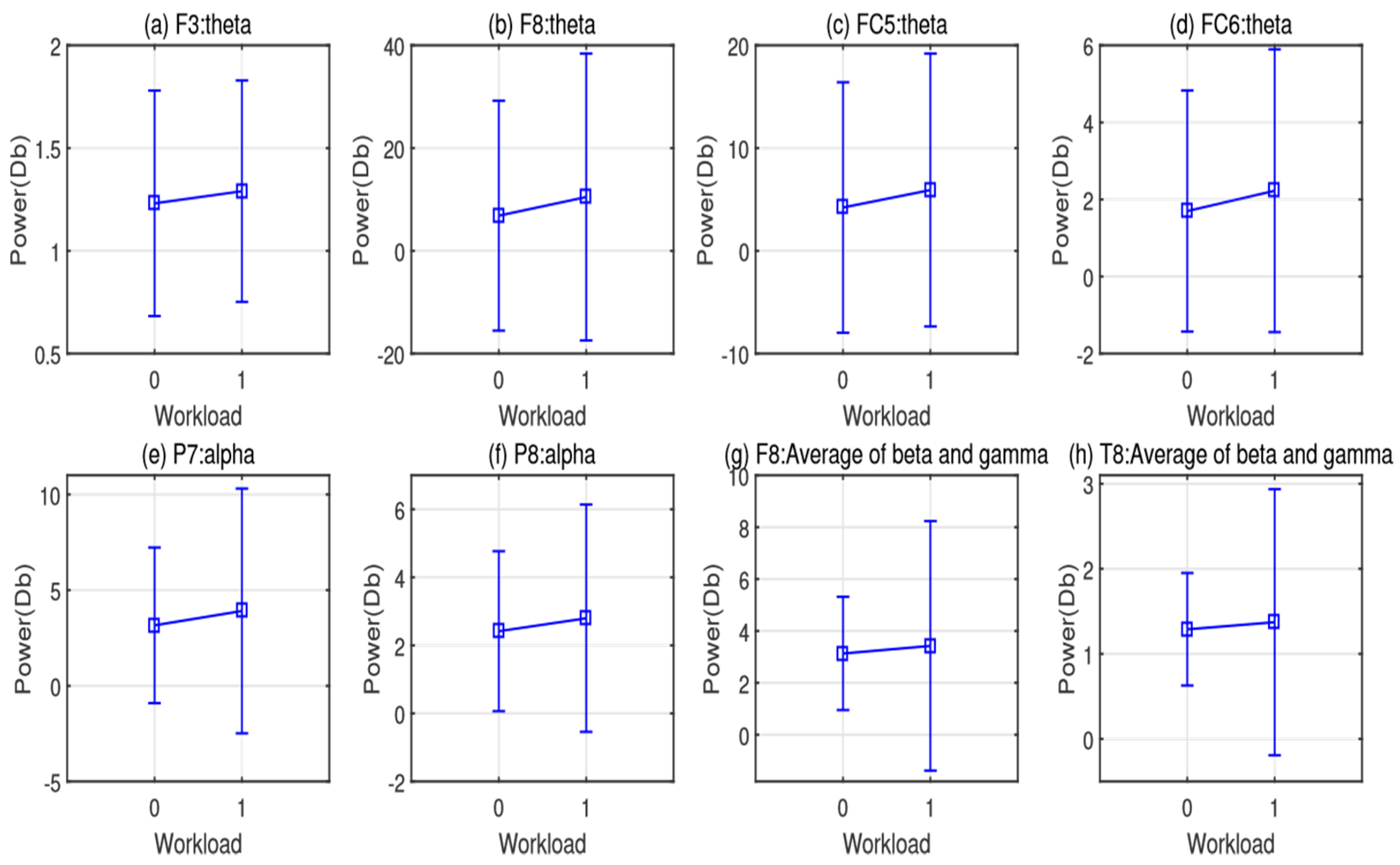
At the neural level, our EEG signals suggested a difference in cognitive workload recruited in ambiguous pronoun resolution in comparison to unambiguous conditions. For all participants, we extracted the EEG power features of multiple frequency bands. For each feature vector, we computed the power of theta (4–8 Hz), alpha (8–13 Hz), and the mean power of beta (14–30 Hz) and gamma (31–40 Hz). Results of our analysis on the mean values of the EEG features of these frequencies suggest significant differences between the two cognitive states underlying ambiguous pronoun resolution compared to the unambiguous controls. Specifically, we observed significant differences in the bilateral frontal area (F3, F8, FC5, FC6 channels) from theta, beta, and gamma, and in the bilateral parietal area (P7, P8) from theta (
Table 8 and
Figure 6). The theta power across two task conditions decreased and thus suggested a lower cognitive workload level correlated to a shorter reaction time. This was supported by previous studies of cognitive workload [
41,
44,
49]. Such a contradiction could be interpreted as the cognitive capacity needed to identify a pronoun’s referent determined by the gender information. In other words, a greater cognitive workload was required when a participant realized that the cognitive task had a standard answer in the cases of unambiguous pronoun resolution. On the contrary, when the pronoun’s referent was undetermined, the participant might feel freer to complete the resolution task in a more flexible way, processing the information given in the context. Such a cognitive process may not leverage additional working memory resources.
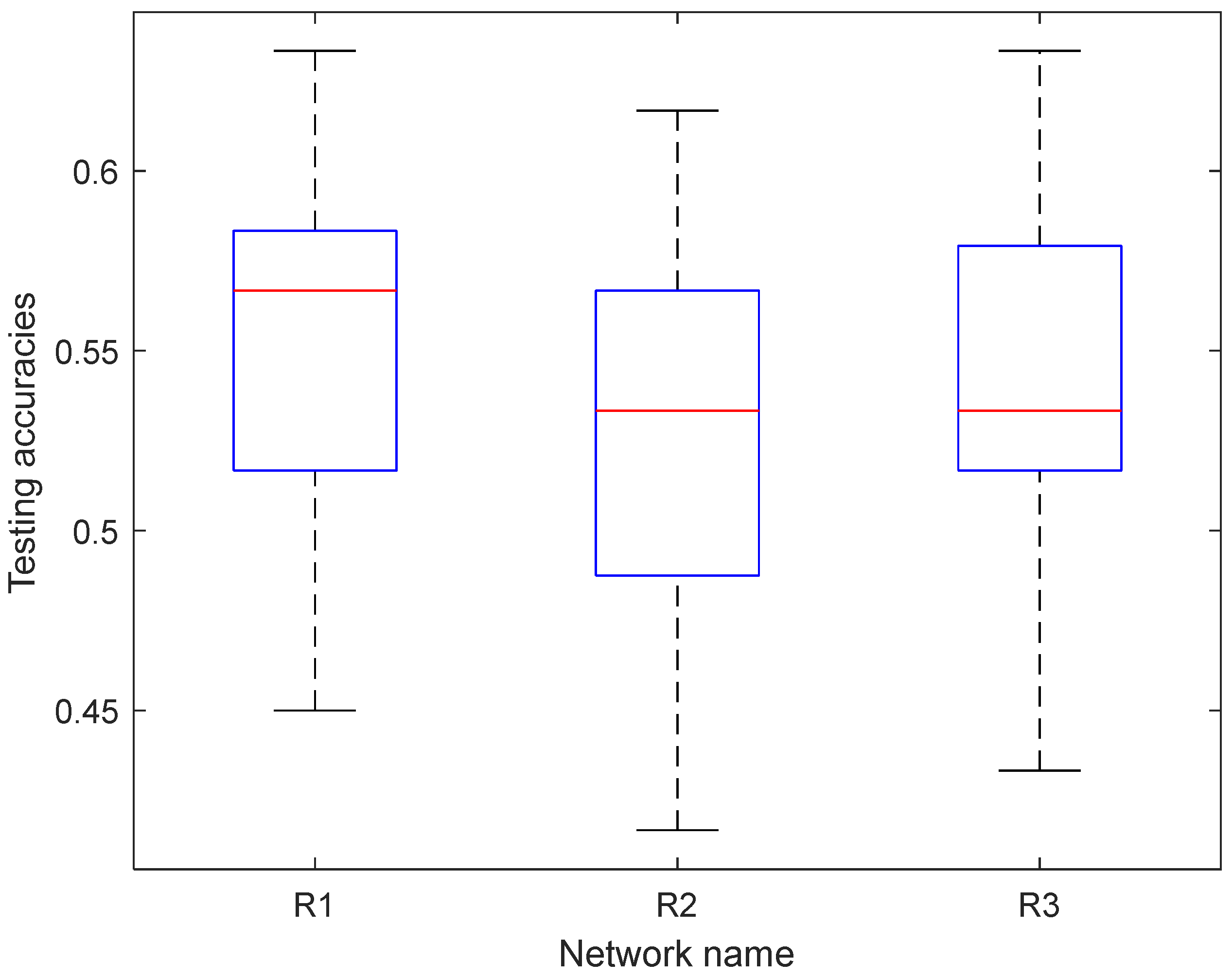
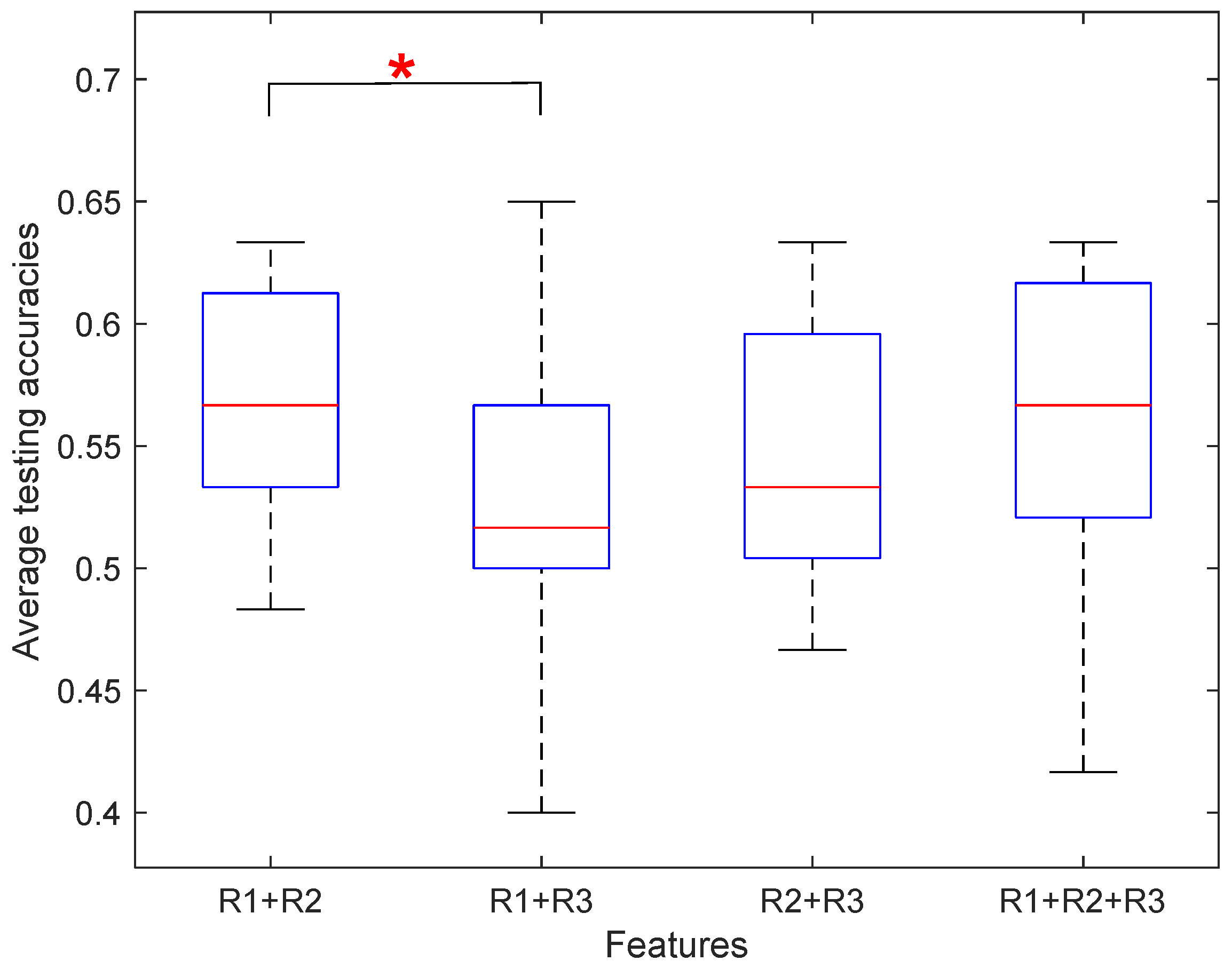
At the level of algorithm, we evaluated different computational models in the domain of machine learning methods. To differentiate between the neural states recruited in the two types of pronoun resolutions, we transformed the EEG feature map into an optimized EEG topology graph, aiming at validating the workload classifier performance. The original size of each feature map was transformed into an EEG topology graph with the size of 3 × 67 × 67, where 3 represents three features of the band frequencies, and 67 represents the interpolated resolution determined by trial and error. Based on this EEG topology, several computational models were evaluated in the domain of machine learning. To explore which network used in the research had relatively excellent performance, the results obtained from the experiments were analyzed. It could be seen from the results that EfficientNet performed the best of the datasets, with the highest accuracy of 55.44% (
Figure 8). These results were basically in line with previous findings on the accuracy of these models. EfficientNet has a deeper and wider architecture in contrast with LeNet-5 and GoogLeNet [
52]. A more complex architecture might lead to better performance by obtaining features with more useful information. In a seminal study, several different classifiers were compared, and the Support Vector Machine (SVM) was reported to obtain the highest accuracies among other popular classifiers, such as K-Nearest Neighbor (KNN) [
34]. In the current study, after a close examination of different classifiers, C-SVM stood out, with the highest accuracy of 56.78% (
Table 10). It could be inferred that C-SVM was more suitable than other classifiers when it came to the identification of cognitive workload level. Four combined models were put forward to test the performance. According to the experimental results, the feature combination of LeNet5 and GoogLeNet possesses the best performance on the dataset, with an accuracy of 56.67% with a leave-one-subject-out cross-validation test (
Table 12 and
Figure 9). Mean accuracy obtained by the same combination was reported as 55.73% with a ten-fold cross-validation test (
Table 13). Although EfficientNet had a good performance as a single model, the accuracy was not improved when it was combined with the other two networks. This is probably due to the differences in network structures.
Our investigation had the motivation of studying the difference in the responses to ambiguous pronouns compared to unambiguous controls in the perspective of cognitive workload. We collected not only behavioral data, including reaction time and response selection, but also the EEG signals during the pronoun resolution task. Together, these results highlight cognitive workload as a complementary indicator of differentiating between the cognitive procedures underlying ambiguous and unambiguous pronoun resolution. The other contribution of the present study is to apply pre-trained deep convolutional neural networks (CNNs) to represent spatial patterns of the EEG power features of multiple frequency bands. It is worth noting that the moderate accuracies that we gained will not affect any of our main conclusions. High accuracies may be considered a necessary criterion in studies of emotion recognition or fatigue detection, since human–computer interaction (HCI) systems are expected to identify human emotional states or fatigue levels based on these classification outcomes. In contrast, our study focuses on the cognitive mechanism of human language processing, which involves a more complicated cognitive function than emotion or attention. We collected and analyzed not only EEG data but also behavioral data such as reaction time and participant response. Accordingly, we adopted a tripartite structure of analysis at different levels, namely the behavioral, neural, and algorithm levels. Classification accuracy contributes only one part of our outcome, at the algorithm level. Indeed, we expect a multi-level assessment of the cognitive mechanisms, rather than an application of the accuracies in the identification of ambiguous/unambiguous pronoun resolution by an HCI system. This study has limitations. First, linguistic cues other than gender information were not considered during pronoun resolution. Second, the proposed model cannot effectively deal with the individual difference induced by the varied EEG feature distributions across all 15 participants. Third, considering the specific structural characteristics of Chinese, a generalization of the conclusions of the current study will require further research in other languages.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}