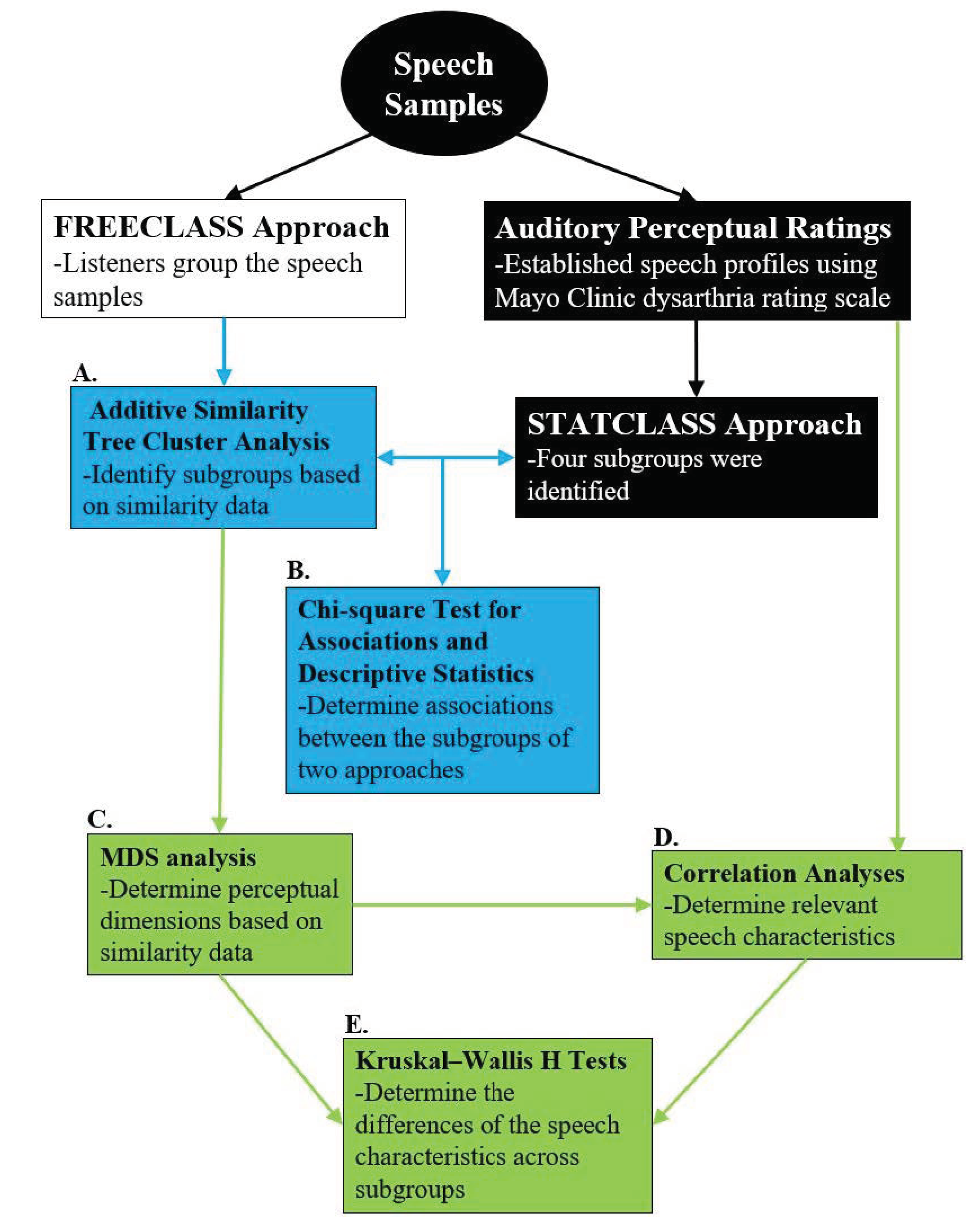
1. Introduction
Dysarthria is a neurogenic motor speech disorder that impairs speech motor execution due to paralysis, weakness, and/or incoordination [
1]. Talkers with dysarthria differ in their perceptual speech characteristics. Although some of these perceptual characteristics can be observed in virtually all talkers with dysarthria (e.g., imprecise consonants), other speech characteristics are unique to only some talkers (e.g., strained-strangled voice). Therefore, a dysarthria classification system is needed to account for this heterogeneity of dysarthria symptoms and to provide a conceptual framework of dysarthria as a neurogenic motor speech disorder.
Within the classic Mayo Clinic dysarthria classification system, some neurological diseases are associated with specific dysarthria types that are further characterized by specific perceptual speech patterns [
2,
3,
4]. Darley and his colleagues, for example, determined that Parkinson’s disease (PD) is associated with hypokinetic dysarthria and is characterized by reduced loudness (hypophonia) and a variety of impaired articulation (e.g., fast/variable rate and short rushes of speech). Similarly, Huntington’s disease (HD) is associated with hyperkinetic dysarthria and characterized by prolonged intervals, a variable or reduced articulation rate, imprecise consonants, and excess intensity variations [
1,
5]. Similarly, within the Mayo Clinic dysarthria classification framework, a perceptual speech pattern can be characteristic of a specific disease (e.g., myasthenia gravis) and help facilitate its diagnosis or be suggestive of specific neuropathology (e.g., bilateral upper motor neuron lesions) [
1]. However, recent perceptual studies have also shown that perceptual speech patterns of individuals who share a disease that is conventionally associated with a specific dysarthria type (e.g., HD → hyperkinetic dysarthria) can vary greatly and may even resemble perceptual speech patterns of dysarthria types that are typically associated with other neurologic conditions with unrelated underlying neuropathologies (e.g., cerebellar ataxia) [
6]. Therefore, it is not surprising that clinicians have reported difficulties with the differential diagnosis of dysarthria, even when they were trained to use the Mayo Clinic dysarthria classification system [
7]. Given these challenges, the question arises of how best to group talkers with dysarthria to adequately account for the heterogeneous perceptual speech characteristics that can be found within disease types that are typically associated with one specific dysarthria type.
For about a decade, dysarthria subgroup approaches have been sought out to address the heterogeneity of dysarthria manifestation within disease types [
8,
9]. These approaches sought to establish subgroups of talkers with similar perceptual speech patterns using a “bottom-up” approach; that is, acoustic or perceptual speech characteristics rather than the disease type formed the basis for their grouping decisions. Diehl and colleagues (2019) [
10] submitted the perceptual speech profiles of 48 talkers with HD to an unsupervised k-means cluster analysis (hereafter referred to as the STATCLUSTER approach). The perceptual speech profiles of these talkers with HD were established by six judges who were trained to assess perceptual speech characteristics based on the Mayo Clinic dysarthria rating scale [
2]. The scale consists of 38 dimensions (i.e., perceptual speech characteristics) that are rated using a 7-point scale (1 = normal, 7 = severely deviant). Four dysarthria subgroups were identified. These subgroups predominantly differed in ratings of perceived speech rate and overall perceived bizarreness and intelligibility (i.e., slow rate/mild-dysarthria, slow rate/moderate-dysarthria, adequate rate/mild-dysarthria, fast rate/mild-dysarthria).
Presumably, the STATCLUSTER approach, when based on perceptual speech profiles, will create subgroups of talkers with dysarthria whose deviant speech patterns are perceptually similar due to overlapping perceptual speech profiles. However, this notion hinges on the assumption that there is a linear association between the severity rating of the deviant perceptual speech characteristics and their perceptual saliency as one aspect of the overall perceptual speech pattern. Indeed, Darley and colleagues reported that some dimensions (i.e., perceptual speech characteristics) of the classic Mayo Clinic dysarthria rating scale frequently received greater mean scale values than others and speculated that these dimensions might be “more interesting” to listeners [
2]. Along these lines, Zyski and Weisiger (1987) [
11] suggested that perceptual speech characteristics with greater mean scale values may be “more salient” to listeners and may predominantly account for the perceptual-based differentiation of dysarthria types.
However, it is also conceivable that the association between the rating of a deviant perceptual speech characteristic and its perceptual saliency is nonlinear. That is, the presence of a deviant perceptual speech characteristic, even when barely detectable (e.g., a strained-strangled voice quality), may stand out and distinguish some talkers with dysarthria from their peers. Such perceptual saliency may even occur when the severity rating of the deviant perceptual speech characteristic does not differ from those of other deviant perceptual speech characteristics that are shared by most talkers within the cohort. Stated differently, the interval scale used for the severity rating of each perceptual speech characteristic in the Mayo classification system may not always accurately represent the perceptual magnitude between each point on the interval scale [
12,
13].
The auditory free classification task (from here on referred to as FREECLASS) is an approach that can also be used to create talker subgroups based on their perceptual speech patterns [
14]. However, in contrast to the STATCLUSTER approach where perceptual speech profiles are subjected to cluster analysis, the talker groups that result from a FREECLASS approach are solely driven by the saliency of perceptual speech characteristics [
6,
14,
15,
16]. Specifically, during a FREECLASS approach, listeners are instructed to establish subgroups of talkers with dysarthria who share similar perceptual speech patterns. However, unlike the STATCLUSTER approach, no specific list of perceptual speech characteristics or severity rating scale is provided to the listeners. Instead, FREECLASS requires that listeners establish their own sorting rules based on the various speech samples.
Clopper and colleagues (2004) [
17] were some of the earliest researchers to employ the auditory FREECLASS approach using speech stimuli. They demonstrated that listeners could make similarity judgments of talkers’ regional dialects. They further examined the extent to which the findings of the free classification task overlapped with those of a forced-choice categorization task and discovered similar patterns of findings across the approaches. Although the findings of Clopper and colleagues (2004) [
17] suggest a close link between perceptual ratings and saliency of perceptual speech characteristics for regional dialects, it is unknown if such a relationship also exists for dysarthria.
Findings in the study by Diehl and colleagues (2019) [
10] revealed that subgroups based on the STATCLUSTER approach differed predominantly in their speech rate characteristics. It is possible that speech rate characteristics are most salient for listeners. However, it is also possible that speech rate characteristics predominantly index dysarthria severity. This notion is supported by the fact that bizarreness and speech intelligibility ratings moderately covaried with ratings of speech rate abnormalities, and also significantly differed across subgroups.
In sum, although the heterogeneous manifestation of dysarthria symptoms within disease types (e.g., PD, HD) has long been acknowledged (e.g., [
6,
10,
18,
19]), guidance on how to best establish dysarthria subgroups within disease types is still lacking. Therefore, the current study compared grouping decisions derived from a STATCLUSTER approach with those derived from a FREECLASS approach, with both approaches using the same cohort of talkers with HD. Specifically, we sought to determine a) the extent to which these two approaches overlap in their grouping decisions, and b) which perceptual speech characteristics significantly contributed to grouping decisions for each approach.
The findings of this study will provide insights into how different grouping approaches may or may not impact grouping decisions and which specific perceptual speech characteristics can be used to establish dysarthria subgroups for HD. Such knowledge will advance the design of future research studies on dysarthria in HD; for example, research efforts that aim to elucidate pathophysiologic factors that underlie various dysarthria subgroups. Findings will also offer improved study designs for investigations on the clinical management of dysarthria in these talkers.
4. Discussion
The purpose of the current study was to compare an auditory free classification approach (FREECLASS) and a statistical clustering approach (STATCLUSTER) to determine to what extent these approaches overlap in their subgrouping decisions. Furthermore, the perceptual speech characteristics that contributed to the subgrouping decisions of each approach were compared. The chi-square analysis revealed significant overlap between the two approaches. Relative to the STATCLUSTER approach in which overall dysarthria severity (index by bizarreness ratings) and speech rate abnormalities differentiated dysarthria subgroups, the FREECLASS dysarthria subgroups were driven by abnormal voice quality (i.e., strained-strangled voice, hoarse voice) and the talker’s sex, in addition to dysarthria severity and speech rate, which had also been identified for the STATCLUSTER approach.
4.1. Overlap between the FREECLASS and the STATCLUSTER Approach
The findings of the FREECLASS approach revealed four unique dysarthria subgroups of talkers with HD, which is congruent with the number of subgroups identified using the STATCLUSTER approach by Diehl and colleagues (2019) [
10] based on perceptual ratings from the Mayo Clinic dysarthria rating scale. However, not every listener grouped talkers with HD into four subgroups. The number of groups identified by listeners ranged from 4 to 13. Such variability in grouping decisions among listeners has been documented previously (see [
6,
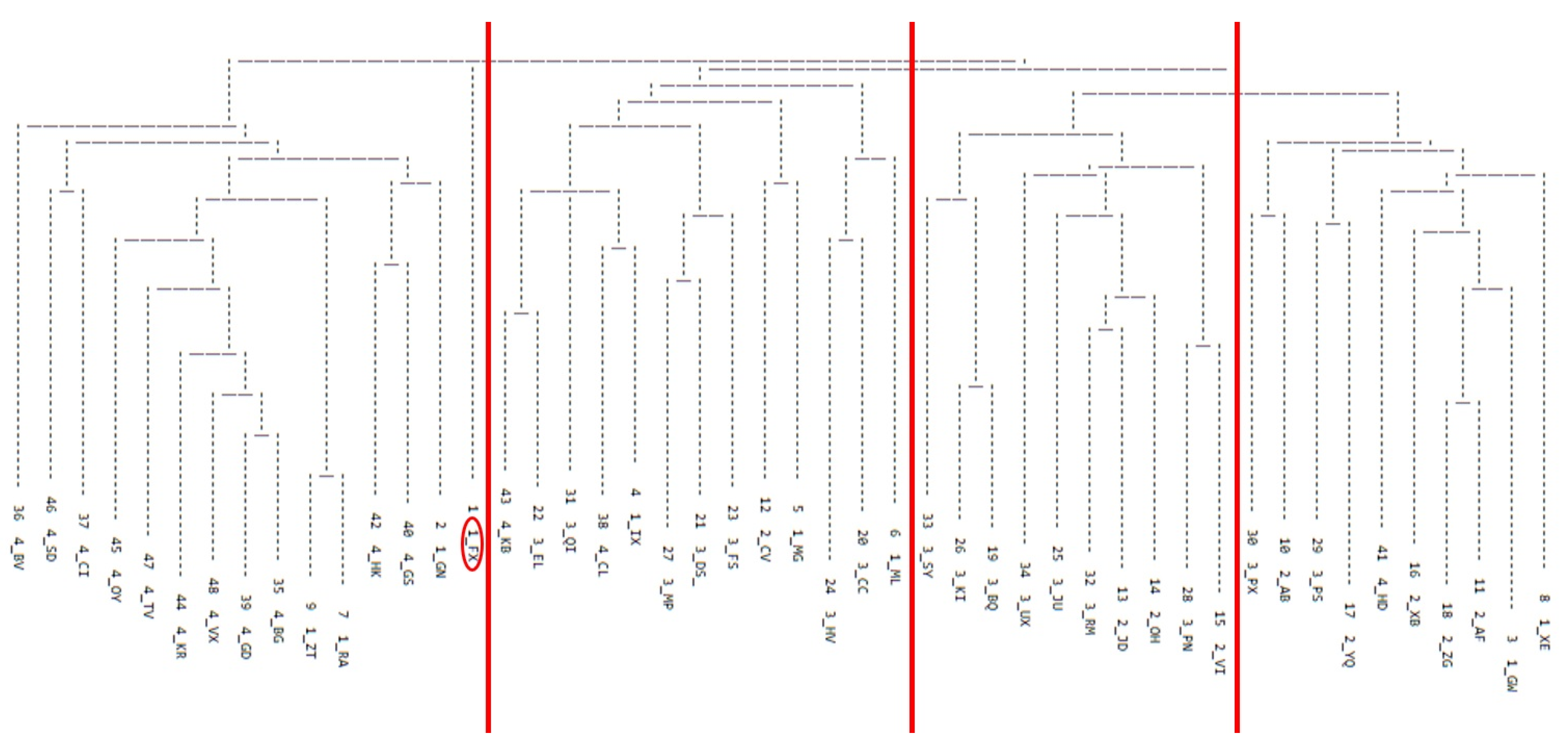
17]) and suggests that grouping strategies employed during a FREECLASS approach and the saliency of perceptual speech characteristics that contribute to grouping decisions are highly subjective. Nevertheless, the convergence on four dysarthria subgroups among talkers with HD, regardless of the approach, solidifies the notion that dysarthria in HD can manifest in different ways, and this heterogeneity should be considered in the design of future studies on dysarthria in HD.
Overall, the overlap of subgroup membership ranged from 50% to 78.6%. Thus, for at least half of the talkers with HD who participated in our study, statistical grouping decisions based on ratings of perceptual speech characteristics were congruent with listeners’ similarity judgments of dysarthric speech patterns. Specifically, subgroup 4 of the current study using the FREECLASS approach consisted entirely of the talkers from subgroups 1 (fast rate/mild dysarthria) and subgroup 4 (normal rate/mild dysarthria) previously established using the STATCLUSTER approach. Furthermore, talkers of subgroup 2 of the FREECLASS approach belonged either to subgroup 2 (slow rate/moderate dysarthria) or subgroup 3 (slow rate/mild dysarthria) of the STATCLUSTER approach.
However, the two grouping approaches did not yield a complete overlap in subgroups, suggesting that listeners weighed perceptual speech characteristics during the auditory free classification task differently than the perceptual ratings of the Mayo Clinic dysarthria rating scale had indicated. That is, perceptual speech characteristics that were rated higher or lower in the Mayo system may influence grouping decisions to a lesser or greater extent during the auditory free classification task, respectively. For example, a perceptual speech feature may receive a lower rating, indicating mild impairment (e.g., strained-strangled voice), but may still be more salient to listeners than other perceptual speech features that were rated as more severely impaired (e.g., slow speech). Furthermore, although several perceptual speech characteristics may be rated equally deviant on the Mayo Clinic perceptual rating scale, one deviant perceptual speech characteristic may be more salient and may contribute to the listeners’ grouping decision to a greater extent than the others. The algorithm in the STATCLUSTER approach assumes linear associations between perceptual ratings and their saliency. However, as discussed below, the findings of the current study suggest that such associations may be non-linear, at least for some perceptual speech characteristics.
4.2. Perceptual Speech Characteristics Contributing to Subgrouping Decisions
The strong correlations of D1 with bizarreness ratings and ratings of perceived speech rate indicate that these two variables played a prominent role in the FREECLASS subgrouping decisions. However, additional perceptual speech characteristics also impacted the listeners’ grouping decisions during the auditory free classification task (i.e., variable rate, strained-strangled voice, hoarse voice, talker’s sex). In the following sections, the findings of each dimension will be discussed in more detail.
4.2.1. Interpretations of D1
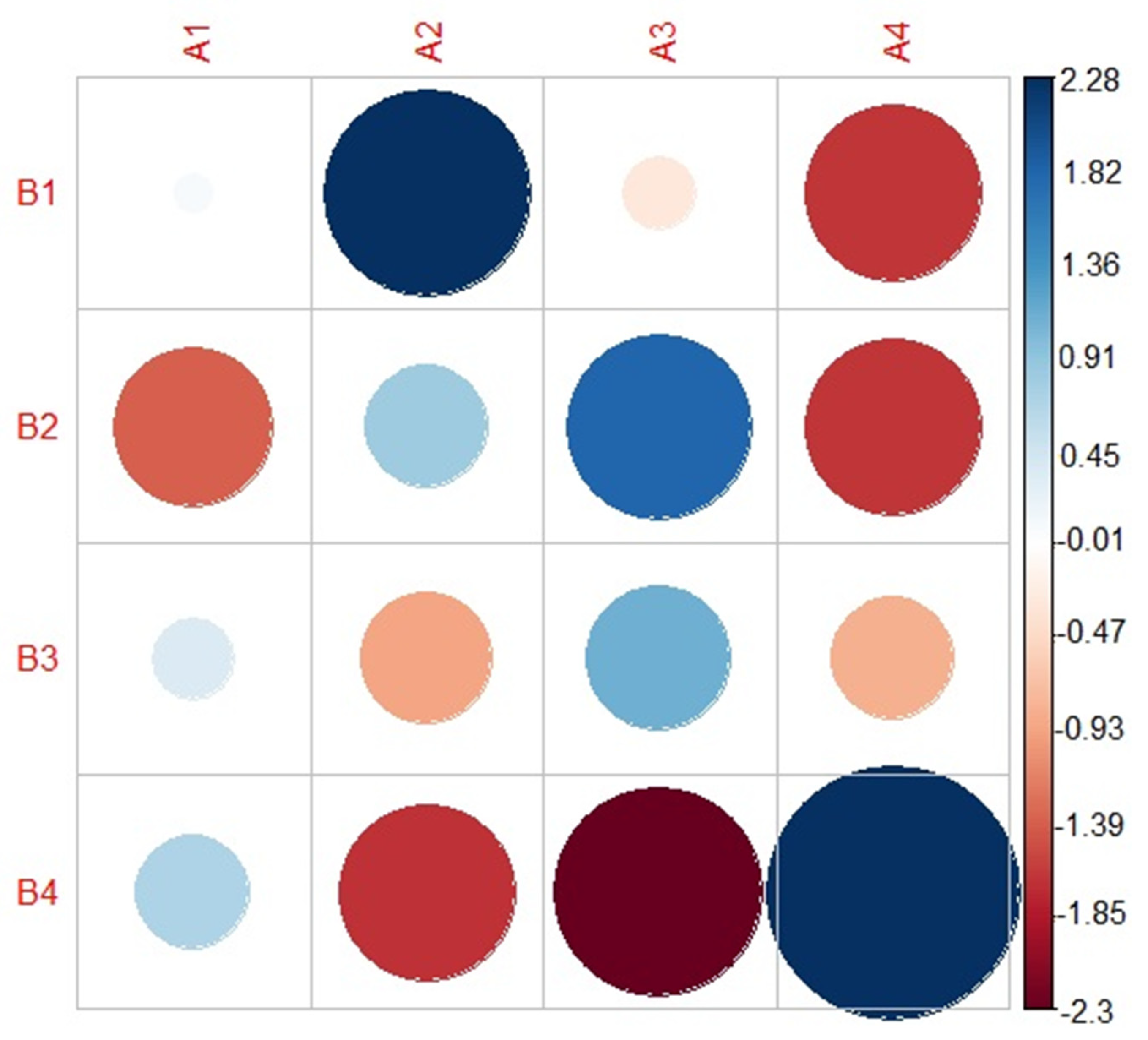
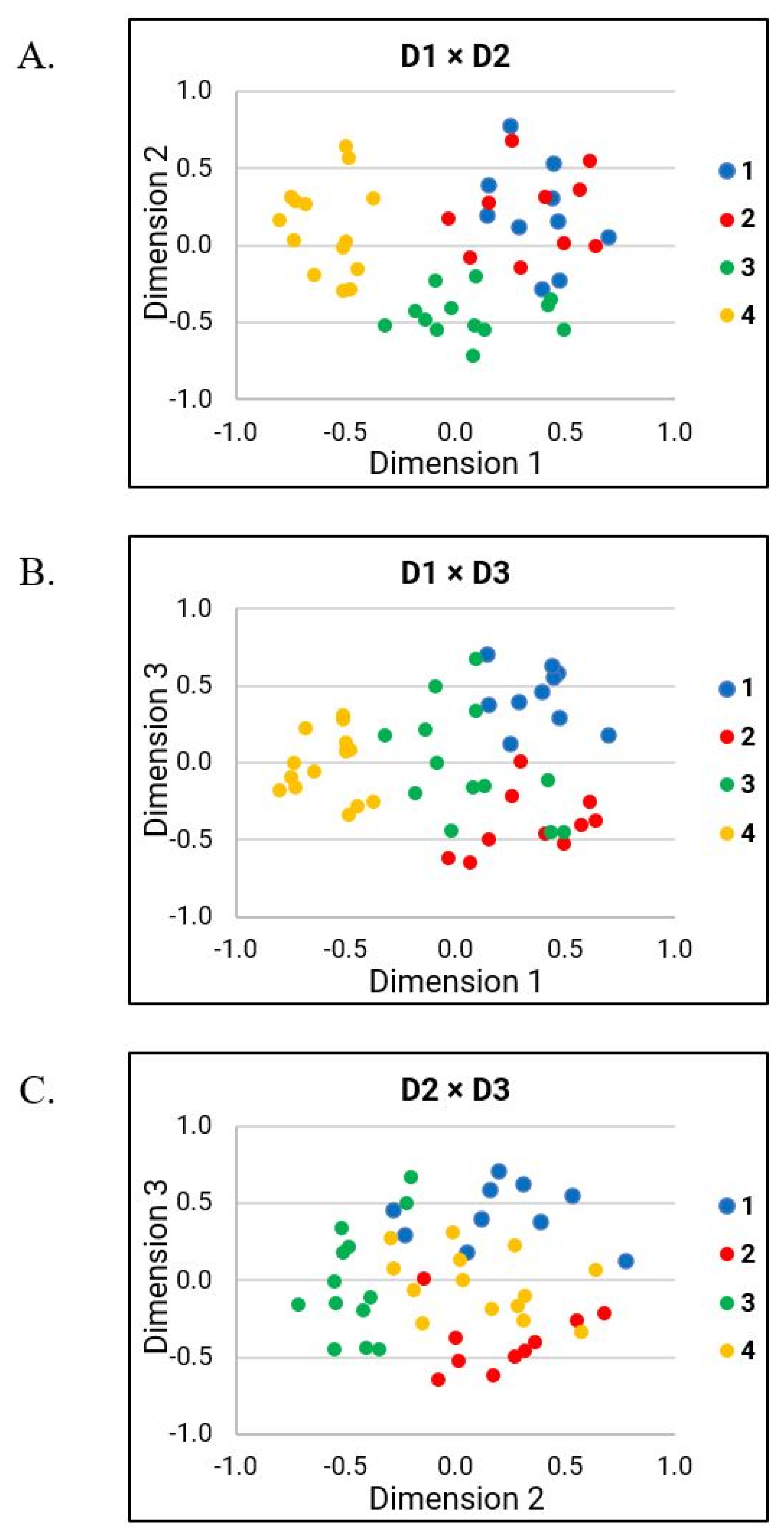
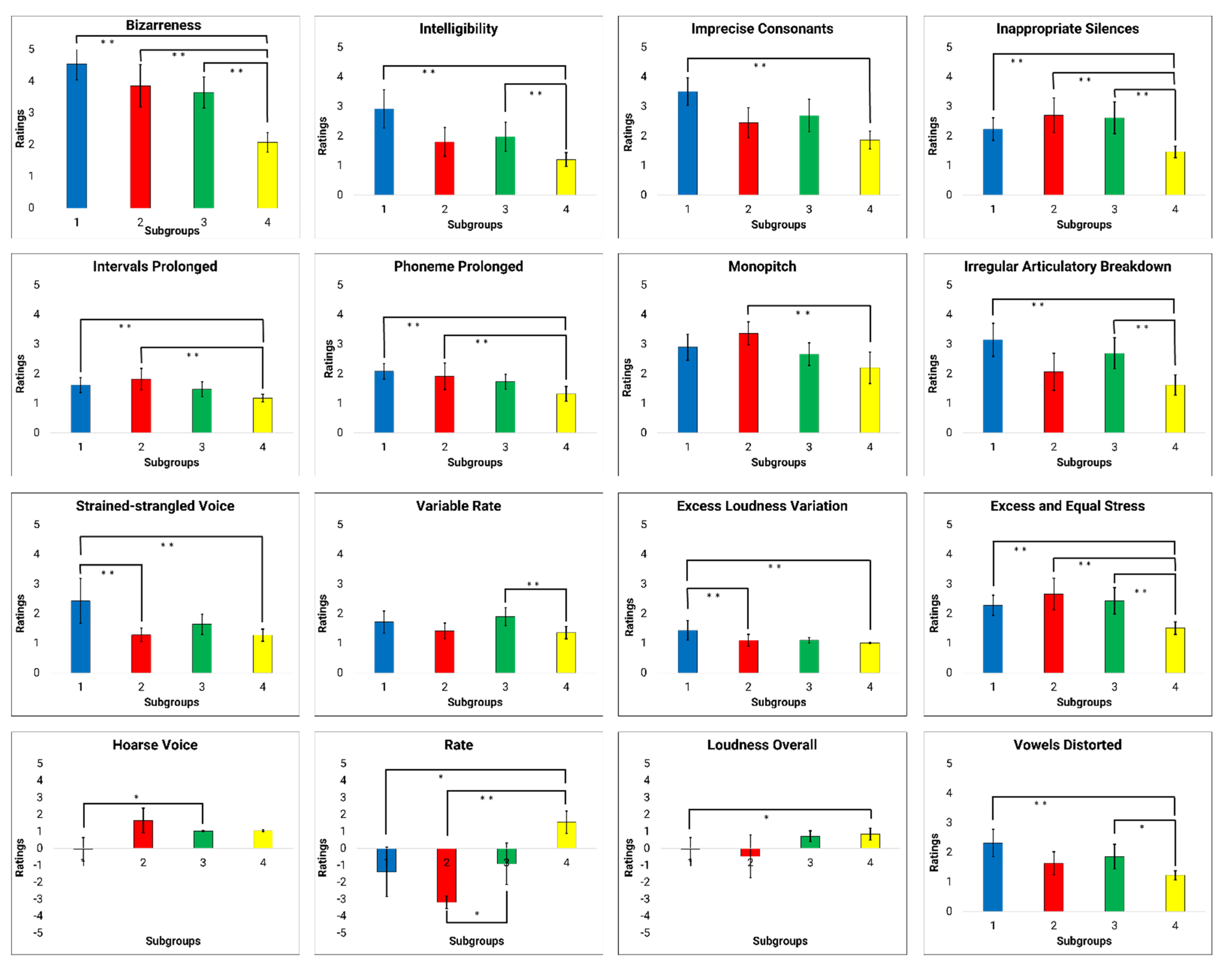
D1 findings suggest that grouping decisions were primarily based on overall bizarreness and intelligibility ratings, as well as ratings of several perceptual speech characteristics (i.e., perceived speech rate, excess and equal stress, prolonged intervals, inappropriate silences, imprecise consonants, prolonged phonemes, vowels distorted, irregular articulatory breakdown, monopitch, and excess loudness variation). These perceptual speech characteristics likely contributed to the overall bizarreness and intelligibility ratings. Based on our findings of MDS-related analyses (see
Figure 5), D1 likely explains the perceptual speech characteristics that account for subgroup 4. Although several perceptual speech characteristics were identified in D1, many were moderate to strongly collinear with the overall bizarreness ratings (see
Table 5). Thus, it is conceivable that listeners grouped talkers in subgroup 4 primarily because these talkers exhibited generally milder dysarthria symptoms than all other talkers, rather than because these talkers produced a specific combination of perceptual speech characteristics. However, we cannot exclude the possibility that a certain combination of perceptual speech characteristics associated with D1 accounted for the listeners’ grouping decision for subgroup 4. For example, pairwise between-group comparisons suggest that ratings of speech rate and monopitch differed between subgroup 4 and subgroup 2, whereas ratings for irregular articulatory breakdowns differentiated subgroup 4 and 1, as well as subgroup 4 and 3. Nevertheless, these perceptual speech characteristics were moderately correlated with the overall bizarreness ratings.
The overall bizarreness rating and perceived speech rate, which were two of the main contributors of the grouping decision in the FREECLASS approach, primarily accounted also for the dysarthria subgroups established by the STATCLUSTER approach in the study by Diehl and colleagues (2019) [
10]. Given that both studies were based on the same cohort of talkers with HD, this finding is not surprising. However, it is important to note that speech impairment severity and speech rate were also two main variables that contributed to the listeners’ grouping decisions in the study by Lansford and colleagues (2014) [
6]. In contrast to our study, their study included talkers with a variety of neurological conditions and dysarthria types. Based on the parallel findings, one could speculate that listeners may take a more holistic approach to differentiate talkers with dysarthria by focusing on the overall dysarthria severity first, and only considering specific speech perceptual characteristics (i.e., speech rate, voice quality) as a secondary strategy to further differentiate talkers within a specific dysarthria severity range, regardless of the talkers’ underlying etiology. Although our speech samples only included talkers with HD who exhibited mild dysarthria (70–100% intelligibility), the range in perceived bizarreness ratings across talkers still predominantly impacted the listeners’ decisions.
4.2.2. Interpretations of D2
Findings of D2 suggest that grouping decisions were based on variable rate, hoarse voice quality, and talker’s sex. In contrast to overall bizarreness ratings accounting for most of the grouping decisions in D1, the findings of D2 suggest that specific speech perceptual characteristics contributed to grouping decisions in D2. Based on the MDS-related analyses (see
Figure 5), the perceptual speech characteristics associated with D2 likely explain grouping decisions of subgroup 3, with only one specific perceptual speech characteristic differing talkers of subgroup 3 from those of subgroup 1 (i.e., variable rate) and 4 (i.e., perceived hoarse voice quality). Furthermore, the talker’s sex showed a trend as a potential grouping variable differentiating subgroup 3 from subgroup 2. The finding that the talker’s sex may contribute to the listeners’ grouping decision aligns with previous findings by Clopper and colleagues (2004) [
17]. In their study, the perceived sex of the talker was identified as an important perceptual speech characteristic in the similarity judgments of regional dialects.
4.2.3. Interpretations of D3
Findings of D3 suggest that specific grouping decisions were primarily based on strained-strangled voice quality, a characteristic that was exclusively correlated with D3. Based on the MDS-related analyses (see
Figure 5), the perceptual speech characteristics of D3 likely explain the listeners’ strategy in distinguishing the talkers in subgroup 1 from the talkers in subgroup 2. Although the perceptual speech characteristics that describe articulatory performance deficits (i.e., imprecise consonants, irregular articulatory breakdown, and vowels distorted) and general speech impairment severity (i.e., speech intelligibility) were also moderately correlated with D3, none of the between-group comparisons of these perceptual speech characteristics reflected the listeners’ decisions in differentiating subgroup 1 from subgroup 2. However, the between-group comparisons of strained-strangled voice demonstrated that the ratings of strained-strangled voice quality were significantly greater in subgroup 1 than in subgroups 2 and 4. That is, talkers in subgroup 1 were rated to produce a more pronounced strained-strangled voice quality than talkers in subgroups 2 and 4, who typically did not exhibit a strained-strangled voice or only a mild impairment. This finding is also consistent with the previous finding by Lansford and colleagues (2014) [
6], who also suggested that strained-strangled voice quality can account, in part, for grouping decisions. Therefore, strained-strangled voice quality appears perceptually more salient to listeners than some of the other perceptual speech characteristics that received similar ratings but did not contribute to grouping decisions.
Finally, it is also important to mention the one talker who was excluded from further analysis because the talker did not fit with any of the four identified subgroups of the additive similarity tree cluster analysis. This talker presented with a fast speaking rate, monopitch, imprecise consonants, and irregular articulatory breakdown. Although the excluded talker was perceived to have a fast speaking rate like the talkers in subgroup 4, the perceptual speech characteristics of the excluded talker were shared across those of the other three subgroups. Therefore, it is possible that the excluded talker represents another dysarthria subgroup of HD. Future research with a new, larger sample of talkers with HD is warranted to replicate and extend the current findings.
4.3. Limitations
Because listeners were instructed to group talkers based on similarity during an auditory free classification task, the resulting grouping decisions may be subjected to response bias that forces listeners to form more than one group. However, due to the nature of the auditory free classification task, it is impossible to remove such a response bias. Nevertheless, previous studies have used a bias parameter to determine the listeners’ response biases. These studies have shown that an auditory free classification task significantly reduces response bias compared to a forced-choice task providing predetermined perceptual features [
26,
27]. However, it is possible that listeners were biased or primed in their grouping decisions due to unintended focus on deviant perceptual characteristics as a result of their familiarity and training in motor speech disorders. Without such influence, they may have also focused on additional perceptual speech features, such as the talkers’ age. In addition, the reliability of listeners’ grouping decisions should also be tested in future studies. So far, such reliability testing has not been conducted; however, based on findings of a wide range of responses, such an analysis is warranted to determine trial-to-trial variability within listeners. Finally, it is possible that the perceived gender of talkers could have contributed to the listeners’ grouping decision. However, we did not ask the listeners about their perception of the talkers’ gender, and therefore we could not consider this possibility in the current study.
5. Conclusions
The current study revealed substantial overlap between subgroups of talkers with HD based on the FREECLASS approach and the subgroups based on the STATCLUSTER approach using the perceptual ratings of the Mayo Clinic dysarthria rating scale. This finding suggests that talkers with dysarthria due to HD could be differentiated based on severity (early stage dysarthria, progressed stage of dysarthria), as well as based on their speech rate characteristics (i.e., slow, adequate, fast) and vocal quality abnormalities (i.e., hoarse voice, adequate voice, strained-strangled voice). However, the lack of complete overlap across the two grouping approaches further indicates that listeners may find specific perceptual speech characteristics more salient than suggested by ratings of Mayo Clinic perceptual dimensions.
As a final note, it should be pointed out that the aim of this paper was not to identify a variety of potentially mixed dysarthria types for talkers with HD. Rather, our findings suggest that specific deviant perceptual speech characteristics should be considered when there is a need to minimize the heterogeneity of dysarthria symptoms in talkers with HD. Specifically, the consideration of rate- and voice-related perceptual speech characteristics, in addition to general severity ratings, can serve as a grouping strategy or as inclusion/exclusion criteria for research participants with HD. Such refinements in the study design may optimize investigations on underlying pathomechanisms of dysarthria in HD, as well as on the effectiveness of pharmaceutical and behavioral treatment approaches within specific dysarthria subgroups of HD.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}