

Processing Aspectual Agreement in a Language with Limited Morphological Inflection by Second Language Learners: An ERP Study of Mandarin Chinese

Abstract
:
1. Introduction
b. Right now, John is learning his courses
Anna kan le bisai
Anna watch-le bisai
Anna watched the game
b. 安娜 看 着 比赛
Anna kan zhe bisai
Anna watch-zhe bisai
Anna is watching the game
1.1. ERP Studies on the Aspect and Tense
b. * Right now, Sophie swims in the pool.
* Sujun zhengzai yubei le shuiguo he tiandian
* Sujun zhengzai prepare-le fruits and dessert
* Sujun is preparing le fruits and dessert
* Sujun zhengzai (PROG, ‘ongoing’) prepare le (PERF) fruit and cookies.
His grandmother *cooking/cooks very well
“His grandmother *cooking/cooks very well”
b. * El/Los niños están jugando
* The-SING/the-PL boys are playing
“*The-SING/the-PL boys are playing”
c. Ellos fueron a *un/una fiesta
they went to *a-MASC/a-FEM party
“They went to *a-MASC/a-FEM party”
1.2. Comparison of Temporal Information Coding in Three Languages
Mama yijing dasao le fangjian
Mother already clean le the room
Mother has cleaned the room
b. 妈妈 正在 打扫 着 房间
Mama zhengzai dasao zhe fangjian
Mother zhengzai cleaning zhe the room
Mother is cleaning the room
Chinese: 爸爸 已经 表扬 了 哥哥 和 姐姐
English word: Dad already praise le brother and elder sister
English: Dad has praised her brother and elder sister
Chinese: 爸爸 已经 表扬 哥哥 和 姐姐
English word: Dad already praise brother and elder sister
English: Dad has praised her brother and elder sister
1.3. The Present Study
2. Materials and Methods
2.1. Experiment Design
2.2. Participants
2.3. Materials
2.4. Procedure
2.5. Data Preprocessing and Analysis
3. Results
3.1. Behavioral Performance
3.2. ERP Data
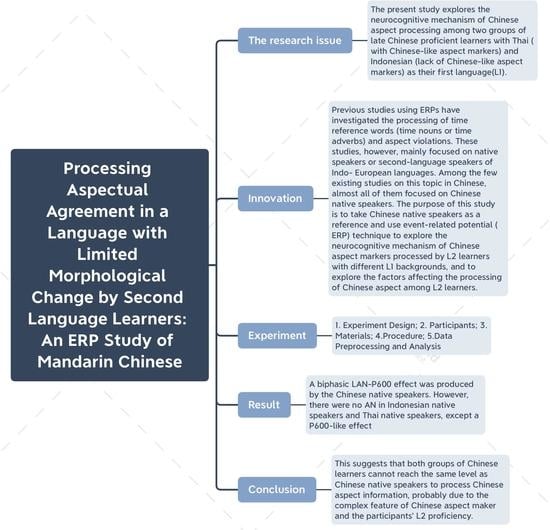
3.2.1. The Native Group
- Midline
- Lateral
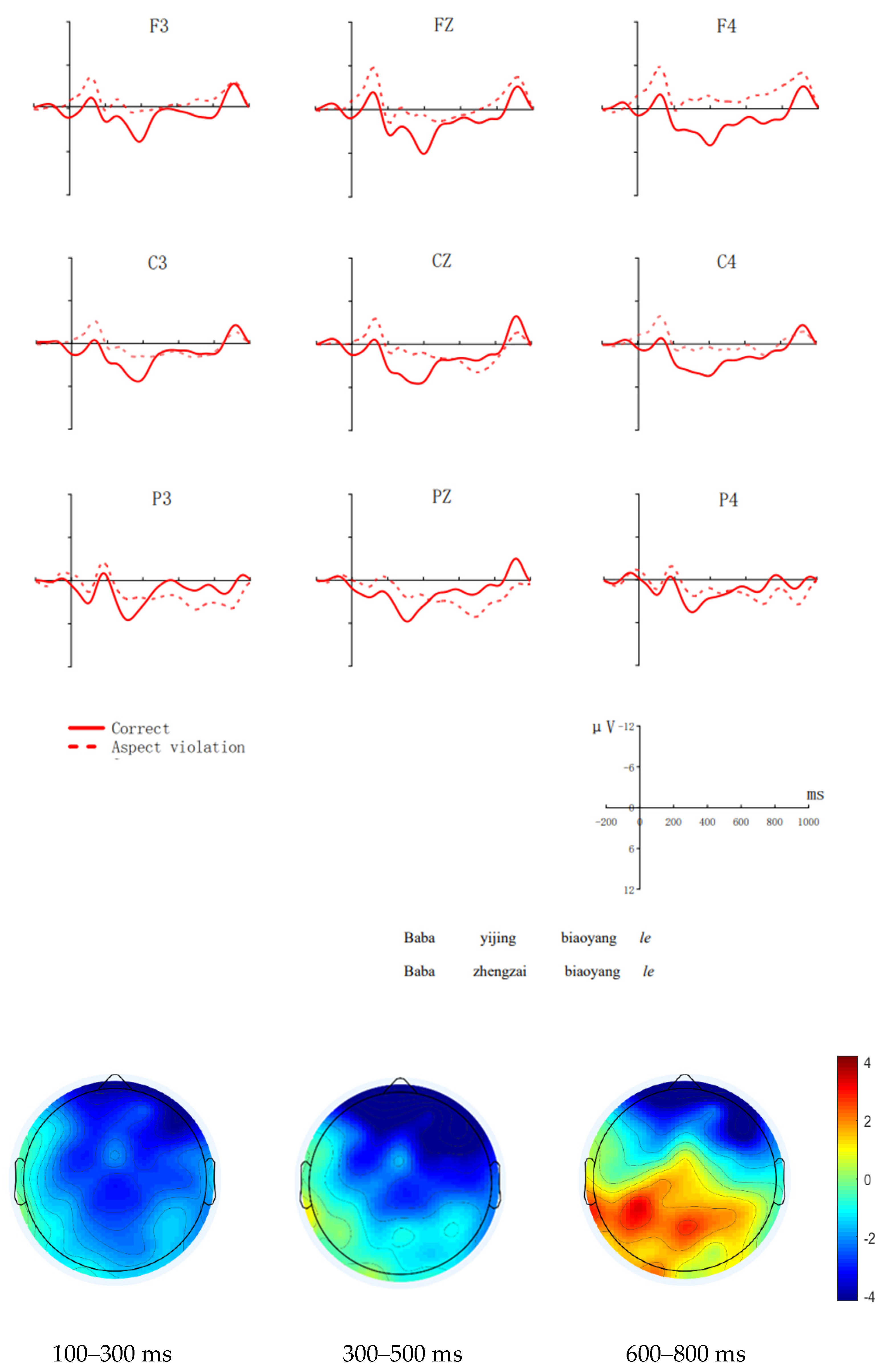
3.2.2. The Indonesian Group
- Midline
- Lateral
3.2.3. The Thai Group
- Midline
- Lateral
4. Discussion
4.1. The Native Speaker Group
4.2. The Second Language Group
4.3. The Mechanism of the Difference Found among the Three Groups
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Klein, W. How time is encoded. In The Expression of Time, 2nd ed.; Klein, W., Li, P., Eds.; Mouton de Gruyter: Berlin, Germany, 2009; pp. 39–81. [Google Scholar]
- Comrie, B. Tense; Cambridge University Press: Cambridge, UK, 1985. [Google Scholar]
- Comrie, B. Aspect: An Introduction to the Study of Verbal Aspect and Related Problems; Cambridge University Press: Cambridge, UK, 1976. [Google Scholar]
- Kruisinga, E. A Handbook of Present-Day English, 5th ed.; Noordhoff: Groningen, The Netherlands, 1932. [Google Scholar]
- Hopper, P.; Thompson, S. Transitivity in grammar and discourse. Language 1980, 56, 251–299. [Google Scholar] [CrossRef]
- Smith, C. The Parameter of Aspect; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1997. [Google Scholar]
- Klein, W.; Li, P.; Hendriks, H. Aspect and assertion in Mandarin Chinese. Nat. Lang. Linguist. Theory 2000, 18, 723–770. [Google Scholar] [CrossRef]
- Huang, C.T.; Li, Y.H.A.; Li, Y. The Syntax of Chinese; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Lin, J.W. Temporal reference in Mandarin Chinese. J. East Asian Linguist. 2003, 12, 259–311. [Google Scholar] [CrossRef]
- Qiu, Y.C.; Zhou, X.L. Processing temporal agreement in a tenseless language: An ERP study of Mandarin Chinese. Brain Res. 2012, 51, 91–108. [Google Scholar] [CrossRef] [PubMed]
- Fonteneau, E.; Frauenfelder, U.; Rizzi, L. On the contribution of ERPs to the study of language comprehension. Bull. Suisse Linguist. Appliquée 1998, 68, 111–124. [Google Scholar]
- Steinhauer, K.; Ullman, M.T. Consecutive ERP effects of morpho-phonology and morpho-syntax. Brain Lang. 2002, 83, 62–65. [Google Scholar]
- Baggio, G. Processing temporal constraints: An ERP study. Lang. Learn. 2008, 58, 35–55. [Google Scholar] [CrossRef]
- Monique, F.; Kelly, W.; Dijkstra, T. ‘Right Now, Sophie *Swims in the Pool?’: Brain Potentials of Grammatical Aspect Processing. Front. Psychol. 2015, 6, 1–14. [Google Scholar]
- Zhang, Y.; Zhang, J. Brain responses to agreement violations of Chinese grammatical aspect. Neuroreport. 2008, 10, 1039–1104. [Google Scholar] [CrossRef]
- Tokowicz, N.; MacWhinney, B. Implicit and Explicit Measures of Sensitivity to Violations in Second Language Grammar: An Event-Related Potential Investigation. Stud. Second Lang. Acquis. 2005, 27, 173–204. [Google Scholar] [CrossRef]
- Julia, F.; Clahsen, H. How Germans prepare for the English past tense: Silent production of inflected words during EEG. Appl. Psycholinguist. 2016, 37, 487–506. [Google Scholar]
- Li, Y.; Manon, J.; Guillaume, T. Timeline blurring in fluent Chinese-English bilinguals. Brain Res. 2018, 17, 93–94. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yu, J.; Boland, J. Semantics does not need a processing license from syntax in reading Chinese. J. Exp. Psychol. Learn. Mem. Cogn. 2010, 36, 765–781. [Google Scholar] [CrossRef] [PubMed]
- Li, C.N.; Thompson, S.A. Mandarin Chinese:A Functional Reference Grammar; University of California Press: Berkeley, CA, USA, 1981; pp. 184–237. [Google Scholar]
- Dai, Y. Studies on Aspectual Systems of Modern Chinese (Xiandai Hanyu Shiti Xitong Yanjiu); Zhejiang Educational Publishing House: Hangzhou, China, 1997. [Google Scholar]
- Jo-Wang, L. Aspectual Selection and Temporal Reference of the Chinese Aspectual Marker-Zhe. Tsing Hua J. Chin. Stud. 2002, 32, 257–295. [Google Scholar]
- Editorial Board, Guangzhou Institute of Foreign Languages. Thai-Chinese Dictionary; Commercial Press: Beijing, China, 1990; p. 612. [Google Scholar]
- Jin, L. On the characteristics of tense and aspect of “le”. Lang. Teach. Res. 1998, 1, 105–106. [Google Scholar]
- Editorial Board, Chinese-Indonesian Dictionary. Chinese-Indonesian Dictionary; Foreign Language Press: Beijing, China, 1997; p. 1045. [Google Scholar]
- MacWhinney, B. A unified model of language acquisition. In Handbook of Bilingualism: Psycholinguistic Approaches; Kroll, J.F., de Groot, A.M.B., Eds.; Oxford University Press: New York, NY, USA, 2005; pp. 49–67. [Google Scholar]
- MacWhinney, B. A unified model. In Handbook of Cognitive Linguistics and Second Language Acquisition; Ellis, N., Robinson, P., Eds.; Lawrence Erlbaum Press: Mahwah, NJ, USA, 2008; pp. 341–371. [Google Scholar]
- MacWhinney, B. The logic of the unified model. In Handbook of Second Language Acquisition; Gass, S., Mackey, A., Eds.; Routledge: New York, NY, USA, 2012; pp. 211–227. [Google Scholar]
- Clahsen, H.; Felser, C. Continuity and shallow structures in language processing: A reply to our commentators. Appl. Psycholinguist. 2006, 27, 107–126. [Google Scholar] [CrossRef]
- Bachman, L.F.; Palmer, A.S. The construct validation of self-ratings of communicative language ability. Lang Test. 1989, 6, 14–29. [Google Scholar] [CrossRef]
- Friederici, A.D. Towards a neural basis of auditory sentence processing. Trends Cogn. Sci. 2002, 6, 78–84. [Google Scholar] [CrossRef]
- Hagoort, P.; Brown, C.; Groothusen, J. The Syntactic Positive Shift as an ERP Measure of Syntactic Processing. Lang. Cogn. Process. 1993, 8, 439–483. [Google Scholar] [CrossRef]
- Neville, H.; Nicol, J.L.; Barss, A.; Forster, K.I.; Garrett, M.F. Syntactically based sentence processing classes: Evidence from event-related brain potentials. J. Cogn. Neurosci. 1991, 3, 151–165. [Google Scholar] [CrossRef]
- Friederici, A.D.; Hahne, A.; Mecklinger, A. The temporal structure of syntactic parsing: Early and late effects elicited by syntactic anomalies. J. Exp. Psychol. Learn. Mem. Cognition. 1996, 22, 1219–1248. [Google Scholar] [CrossRef]
- Hahne, A.; Friederici, A.D. Electrophysiological evidence for two steps in syntactic analysis: Early automatic and late controlled processes. J. Cogn. Neurosci. 1999, 11, 193–204. [Google Scholar] [CrossRef] [PubMed]
- Mancini, S.; Molinaro, N.; Rizzi, L.; Carreiras, M. A person is not a number: Discourse involvement in subject-verb agreement computation. Brain Res. 2011, 1, 64–76. [Google Scholar] [CrossRef] [PubMed]
- Tanner, D.; Hell, J.V. ERPs reveal individual differences in morphosyntactic processing. Neuropsychologia 2014, 56, 289–301. [Google Scholar] [CrossRef] [PubMed]
- Beatty-Martínez, A.L.; Bruni, M.R.; Bajo, M.T.; Dussias, P.E. Brain potentials reveal differential processing of masculine and feminine grammatical gender in native Spanish speakers. Psychophysiology 2020, 3, e13737. [Google Scholar] [CrossRef]
- Bates, D.; Maechler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Newman, A.J.; Ullman, M.; Pancheva, R.; Waligura, D.L.; Neville, H. An ERP study of regular and irregular English past tense inflection. Neuroimage 2007, 3, 435–445. [Google Scholar] [CrossRef]
- Galloway, L.M. Bilingualism: Neuropsychological considerations. J. Res. Dev. Educ. 1982, 15, 12–28. [Google Scholar]
- Sussman, H.M.; Franklin, P.; Simon, T. Bilingual speech: Bilateral control? Brain Lang. 1982, 15, 125–142. [Google Scholar] [CrossRef]
- Scherer, L.C.; Fonseca, R.P.; Amiri, M.; Adrover-Roig, D.; Marcotte, K.; Giroux, F.; Senhadji, N.; Benali, H.; Lesage, F.; Ansaldo, A.I. Syntactic processing in bilinguals: An fNIRS study. Brain Lang. 2012, 121, 144–151. [Google Scholar] [CrossRef]
- Duff, P.; Li, D. The acquisition and use of perfective aspect in Mandarin. In The L2 Acquisition of Tense-Aspect Morphology; Salaberry, R., Shirai, Y., Eds.; Benjamins: Amsterdam, The Netherlands, 2002; pp. 417–454. [Google Scholar]
- Hernandez, A.E.; Li, P. Age of acquisition: Its neural and computational mechanisms. Psychol. Bull. 2007, 133, 638–650. [Google Scholar] [CrossRef] [PubMed]
- Park, S.H.; Kim, H. Cross-linguistic influence in the second language processing of korean morphological and syntactic causative constructions. Linguist. Approaches Biling. 2021. Available online: https://www.jbe-platform.com/content/journals/10.1075/lab.20026.par (accessed on 14 April 2022). [CrossRef]
- Hahne, A.; Friederici, A.D. Processing a second language: Late learners’ comprehension mechanism as revealed by event-related brain potentials. Biling. Lang. Cogn. 2001, 4, 339–556. [Google Scholar] [CrossRef]
- Rossi, S.; Gugler, M.F.; Friederici, A.D.; Hahne, A. The Impact of proficiency on syntactic second, language processing of German and Italian. Evidence from event-related potentials. J. Cogn. Neurosci. 2006, 18, 2030–2048. [Google Scholar] [CrossRef] [PubMed]
- Morgan-Short, K.; Sanz, C.; Steinhauer, K.; Ullman, M.T. Second language acquisition of gender agreement in explicit and implicit training conditions: An event-related potential study. Lang. Learn. 2010, 60, 154–193. [Google Scholar] [CrossRef] [PubMed]
- Tanner, D.; Mclaughlin, J.; Herschensohn, J.; Osterhout, L. Individual differences reveal stages of L2 grammatical acquisition: ERP evidence. Biling. Lang. Cogn. 2012, 16, 367–382. [Google Scholar] [CrossRef]
- Ullman, M. A cognitive neuroscience perspective on second language acquisition: The declarative/pro-cedural model. In Mind and Context in Adult Second Language Acquisition: Methods, Theory and Practice; Sanz, C., Ed.; Georgetown University Press: Washington, DC, USA, 2005. [Google Scholar]
- McLaughlin, J.; Tanner, D.; Pitkanen, I.; Frenck-Mestre, C.; Inoue, K.; Valentine, G.; Osterhout, L. Brain potentials reveal discrete stages of L2 grammatical learning. Lang. Learn. 2010, 60, 123–150. [Google Scholar] [CrossRef]
- Batterink, L.; Neville, H. Implicit and explicit second language training recruit common neural mechanisms for syntactic processing. J. Cogn. Neurosci. 2013, 25, 936–951. [Google Scholar] [CrossRef]
- Felser, C.; Roberts, L.; Marinis, T.; Gross, R. The processing of ambiguous sentences by first and second language learners of English. Appl. Psycholinguist. 2003, 24, 453–489. [Google Scholar] [CrossRef]
- Felser, C.; Roberts, L. Processing wh-dependencies in a second language: A cross-modal priming study. Second Lang. Res. 2007, 23, 9–36. [Google Scholar] [CrossRef]
- Papadopoulou, D.; Clahsen, H. Parsing strategies in L1 and L2 sentence processing: A study of relative clause attachment in Greek. Stud. Second. Lang. Acquis. 2003, 25, 501–528. [Google Scholar] [CrossRef]
- Marinis, T.; Roberts, L.; Felser, C.; Clahsen, H. Gaps in second language sentence processing. Stud. Second Lang. Acquis. 2005, 27, 53–78. [Google Scholar] [CrossRef]
- Rodriguez, G. Second Language Sentence Processing: Is it Fundamentally Different? University of Pittsburgh: Pittsburgh, PA, USA, 2008. [Google Scholar]
- Sun, D.J. Form and significance in grammar teaching of Chinese as a foreign language. Lang. Teach. Res. 2007, 5, 7–14. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chinese/Thai/Indonesian | |
|---|---|
| Time Adverbs | 已经 (yijing)/แล้ว/sudah: “已经 (yijing)/แล้ว/sudah” is an adverb, and it is placed before the verb to indicate that the time has passed or that the action, situation, and thing were completed before a certain time. 正在 (zhengzai)/กำลัง/sedang: “正在 (zhengzai)/กำลัง/sedang” is an adverb, and it is placed before the verb to indicate that the action is in progress. |
| Aspect markers | 了 (le)/แล้ว: “了 (le)/แล้ว” is an aspect marker, and it is appended to the verb to indicate that the action has been completed. 着 (zhe)/กำลัง: “着 (zhe)/กำลัง” is an aspect marker, and it is appended to a verb to indicate that the action is in progress. |
| Dimension | Mean of Indonesian Group | Mean of Thai Group | Chisq | Df | Pr (>Chisq) |
|---|---|---|---|---|---|
| Grammatical competence | 2.871 | 2.893 | 0.379 | 1 | 0.538 |
| Pragmatic competence | 2.800 | 2.786 | 0.174 | 1 | 0.676 |
| Sociolinguistic competence | 2.643 | 2.607 | 0.798 | 1 | 0.371 |
| Correct 表扬 了 哥哥 和 姐姐 Dad already praise le brother and elder sister Dad has already praised her brother and sister | 爸爸 已经 |
| Baba yijing biaoyang le gege he jiejie | |
| Aspect violation *爸爸 正在 表扬 了 哥哥 和 姐姐 Baba zhengzai biaoyang le gege he jiejie Dad is praising le brother and elder sister Dad is praising her brother and elder sister |
| Native Speakers Group | Indonesian Group | Thai Group | ||||
|---|---|---|---|---|---|---|
| ACC (%) | RT (ms) | ACC (%) | RT (ms) | ACC (%) | RT (ms) | |
| Correct | 89.13/3.46 | 452.95/239.59 | 74.46/4.37 | 615.77/311.71 | 76.90/3.86 | 667.96/382.39 |
| Aspect violation | 80.71/5.21 | 504.21/226.20 | 67.67/6.25 | 634.64/297.48 | 70.35/4.72 | 723.24/432.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Y.; Duan, X.; Yan, Q. Processing Aspectual Agreement in a Language with Limited Morphological Inflection by Second Language Learners: An ERP Study of Mandarin Chinese. Brain Sci. 2022, 12, 524. https://doi.org/10.3390/brainsci12050524
Hao Y, Duan X, Yan Q. Processing Aspectual Agreement in a Language with Limited Morphological Inflection by Second Language Learners: An ERP Study of Mandarin Chinese. Brain Sciences. 2022; 12(5):524. https://doi.org/10.3390/brainsci12050524
Chicago/Turabian StyleHao, Yuxin, Xun Duan, and Qiuyue Yan. 2022. "Processing Aspectual Agreement in a Language with Limited Morphological Inflection by Second Language Learners: An ERP Study of Mandarin Chinese" Brain Sciences 12, no. 5: 524. https://doi.org/10.3390/brainsci12050524
APA StyleHao, Y., Duan, X., & Yan, Q. (2022). Processing Aspectual Agreement in a Language with Limited Morphological Inflection by Second Language Learners: An ERP Study of Mandarin Chinese. Brain Sciences, 12(5), 524. https://doi.org/10.3390/brainsci12050524