
Syntax Acquisition in Healthy Adults and Post-Stroke Individuals: The Intriguing Role of Grammatical Preference, Statistical Learning, and Education

 , ,
, ,
Abstract
:1. Introduction
1.1. First, Is the Depth of Embedding an Overarching Principle Relevant for Syntax Acquisition?
1.2. Second, to What Extent Is Syntax Acquisition Affected by the Presence of Aphasia?
1.3. Third, Is Syntax Acquisition Affected by Working Memory Deficits?
1.4. Fourth, Do Stroke-Induced Brain Damage, Brain Reserve and Brain Cognition Play a Role in Syntax Acquisition in Stroke Patients?
2. Materials and Methods
2.1. Study Design
2.2. Participants
2.2.1. The Ideal Learner Group
2.2.2. Left-Hemispheric Stroke Patients
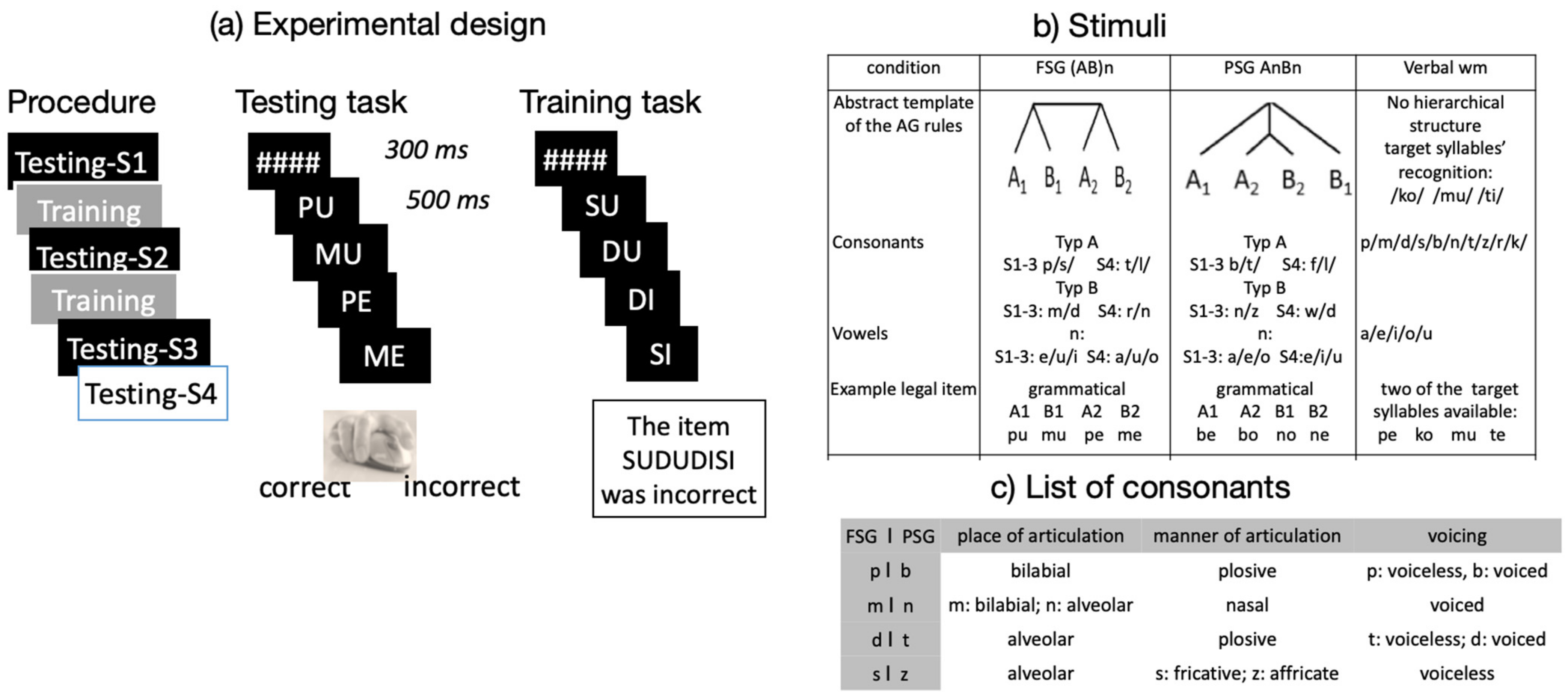
2.3. The Experimental Design
2.4. Stimuli
- Correct stimuli:
- Incorrect stimuli
2.5. Procedure
2.6. Data Analysis
2.6.1. The Data Set
2.6.2. Mixed Effects Logistic Regression Analysis
- Basic Models
- Models including syntax-external factors
3. Results
3.1. Syntax Acquisition in Healthy Participants (Ideal Native Speaker–Listeners)
3.1.1. Best-Fit Model for AG Learning
3.1.2. Sessions Effects in AGL
3.1.3. Trial Effects during Pre-Training Sessions
3.1.4. The Effect of Error Type on Performance for Ungrammatical Items
3.1.5. AG Generalization
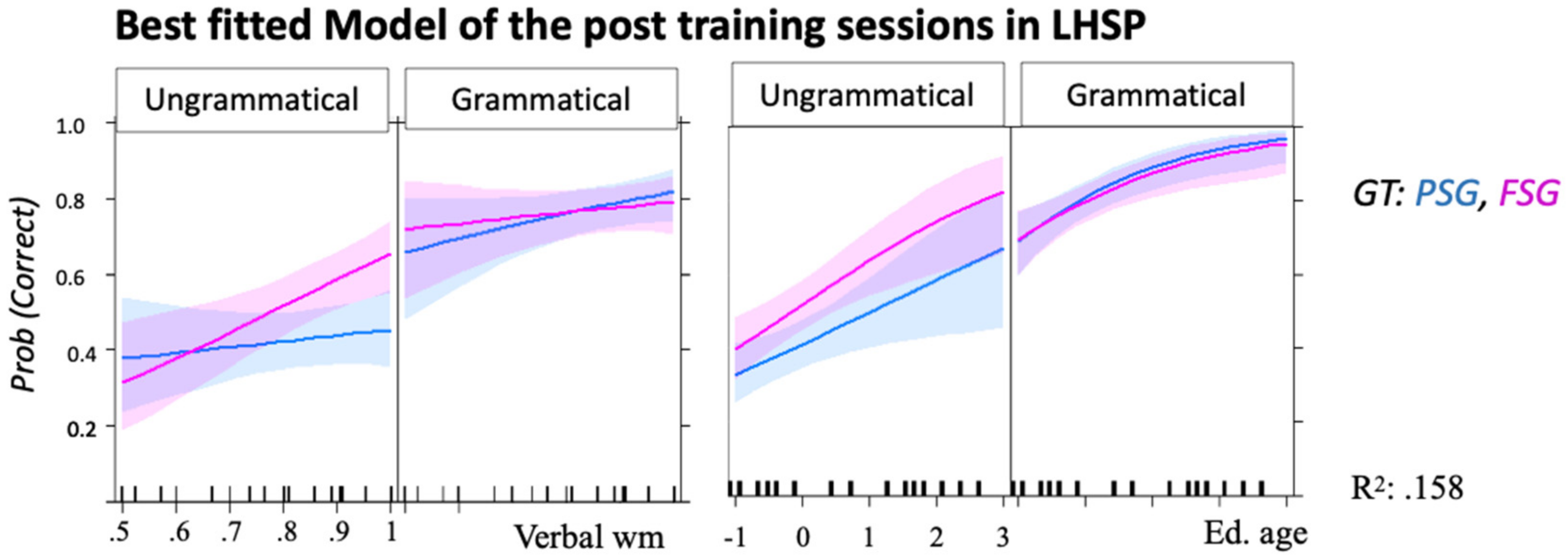
3.2. Syntax Acquisition in Left-Hemispheric Stroke Patients (Non-Ideal Native Speaker–Listeners)
3.2.1. The Best-Fit Model for AGL
3.2.2. Sessions Effects in AGL
3.2.3. AG Generalization
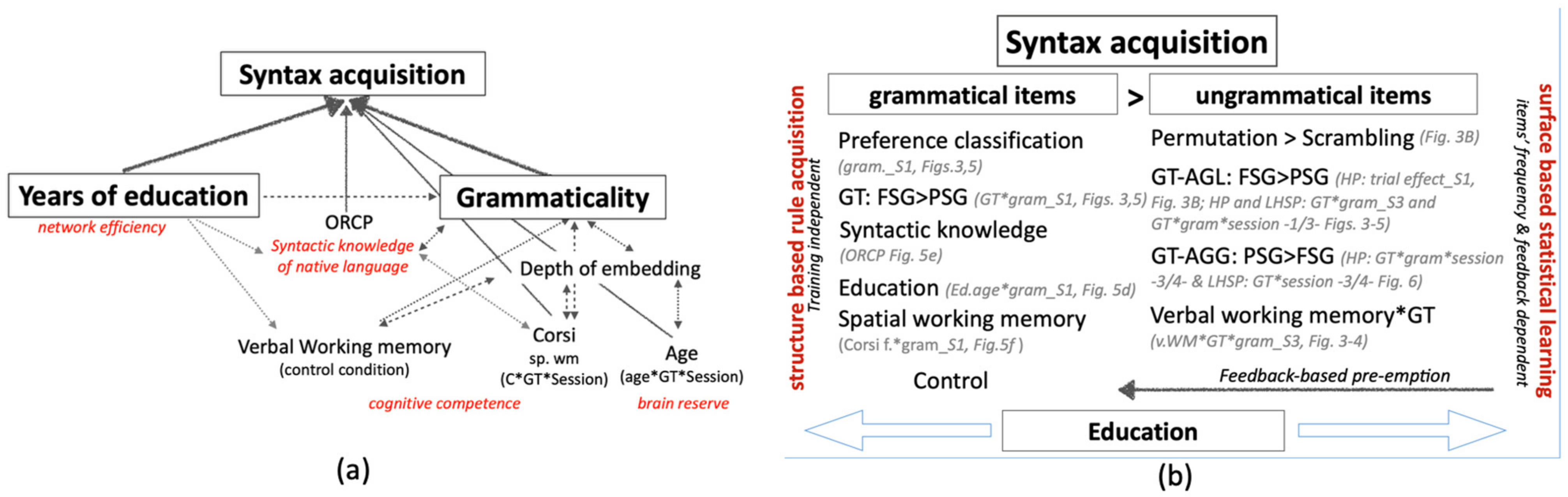
4. Discussion
4.1. The Grammaticality Effect and the Dual-Process Account of AG
4.2. The Effect of Education
5. Conclusions
6. Limitations
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Darwin, C. Descent of Man; John Murray: London, UK, 1871. [Google Scholar]
- Chomsky, N. On Certain Formal Properties of Grammars. Inf. Control 1959, 2, 137–167. [Google Scholar] [CrossRef] [Green Version]
- Chomsky, N. Knowledge of Language: Its Nature, Origin, and Use; Greenwood Publishing Group: Westport, CT, USA, 1986. [Google Scholar]
- Pinker, S. Talk of genetics and vice versa. Nature 2001, 413, 465–466. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Gleitman, L. Turning the tables: Language and spatial reasoning. Cognition 2002, 83, 265–294. [Google Scholar] [CrossRef] [Green Version]
- Gould, J.L.; Marler, P. Lernen durch Instinkt; Spektrum Wiss: Oslo, Norway, 1987; pp. 104–119. [Google Scholar]
- Musso, M.; Moro, A.; Glauche, V.; Rijntjes, M.; Reichenbach, J.R.; Büchel, C.; Weiller, C. Broca’s area and the language instinct. Nat. Neurosci. 2003, 6, 774–781. [Google Scholar] [CrossRef] [PubMed]
- Smith, N.; Tsimpli, I.A. The Mind of a Savant; Blackwell Publishers: Hoboken, NJ, USA, 1996. [Google Scholar]
- Yang, C.D. Universal Grammar, statistics or both? Trends Cogn. Sci. 2004, 8, 451–456. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.D. Knowledge and Learning in Natural Language; Oxford University Press: Oxford, UK, 2002. [Google Scholar]
- Lidz, J.; Gagliardi, A. How nature meets nurture: Universal grammar and statistical learning. Annu. Rev. Linguist. 2015, 1, 333–353. [Google Scholar] [CrossRef] [Green Version]
- Chomsky, N. The Minimalist Program; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Chomsky, N. Syntactic Structures; Gravenhage, S., Ed.; De Gruyter Mouton: The Hague, The Netherlands, 1957; Volume IV. [Google Scholar]
- Hauser, M.D.; Chomsky, N.; Fitch, W.T. The faculty of language: What is it, who has it, and how did it evolve? Science 2002, 298, 1569–1579. [Google Scholar] [CrossRef]
- Fitch, W.T.; Hauser, M.D. Computational constraints on syntactic processing in a nonhuman primate. Science 2004, 303, 377–380. [Google Scholar] [CrossRef] [Green Version]
- Gentner, T.Q.; Fenn, K.M.; Margoliash, D.; Nusbaum, H.C. Recursive syntactic pattern learning by songbirds. Nature 2006, 440, 1204–1207. [Google Scholar] [CrossRef]
- Chomsky, N. Persistent topics in linguistic theory. Diogenes 1965, 13, 13–20. [Google Scholar] [CrossRef]
- Brownsett, S.L.; Warren, J.E.; Geranmayeh, F.; Woodhead, Z.; Leech, R.; Wise, R.J. Cognitive control and its impact on recovery from aphasic stroke. Brain 2014, 137, 242–254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cho-Reyes, S.; Thompson, C.K. Verb and sentence production and comprehension in aphasia: Northwestern Assessment of Verbs and Sentences (NAVS). Aphasiology 2012, 26, 1250–1277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ditges, R.; Barbieri, E.; Thompson, C.K.; Weintraub, S.; Weiller, C.; Mesulam, M.M.; Kümmerer, D.; Schröter, N.; Musso, M. German Language Adaptation of the NAVS (NAVS-G) and of the NAT (NAT-G): Testing Grammar in Aphasia. Brain Sci. 2021, 11, 474. [Google Scholar] [CrossRef] [PubMed]
- Menn, L.; Duffield, C.J. Aphasias and theories of linguistic representation: Representing frequency, hierarchy, constructions, and sequential structure. Wiley Interdiscip. Rev. Cogn. Sci. 2013, 4, 651–663. [Google Scholar] [CrossRef] [PubMed]
- Caramazza, A.; Capitani, E.; Rey, A.; Berndt, R.S. Agrammatic Broca’s aphasia is not associated with a single pattern of comprehension performance. Brain Lang. 2001, 76, 158–184. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ballard, K.J.; Thompson, C.K. Treatment and generalization of complex sentence production in agrammatism. J. Speech Lang. Heart Res. 1999, 42, 690–707. [Google Scholar] [CrossRef] [PubMed]
- Thompson, C.K.; Shapiro, L.P.; Ballard, K.J.; Jacobs, B.J.; Schneider, S.S.; Tait, M.E. Training and generalized production of wh-and NP-movement structures in agrammatic aphasia. J. Speech Lang. Heart Res. 1997, 40, 228–244. [Google Scholar] [CrossRef]
- Berndt, R.S.; Caramazza, A. How “regular” is sentence comprehension in Broca’s aphasia? It depends on how you select the patients. Brain Lang. 1999, 67, 242–247. [Google Scholar] [CrossRef] [Green Version]
- Petersson, K.-M.; Folia, V.; Hagoort, P. What artificial grammar learning reveals about the neurobiology of syntax. Brain Lang. 2012, 120, 83–95. [Google Scholar] [CrossRef] [Green Version]
- Petersson, K.M.; Hagoort, P. The neurobiology of syntax: Beyond string sets. Philos. Trans. R. Soc. B Biol. Sci. 2012, 367, 1971–1983. [Google Scholar] [CrossRef] [Green Version]
- Dick, F.; Bates, E.; Wulfeck, B.; Utman, J.A.; Dronkers, N.; Gernsbacher, M.A. Language deficits, localization, and grammar: Evidence for a distributive model of language breakdown in aphasic patients and neurologically intact individuals. Psychol. Rev. 2001, 108, 759. [Google Scholar] [CrossRef] [PubMed]
- Patel, A.D.; Iversen, J.R.; Wassenaar, M.; Hagoort, P. Musical syntactic processing in agrammatic Broca’s aphasia. Aphasiology 2008, 22, 776–789. [Google Scholar] [CrossRef]
- Musso, M.; Weiller, C.; Horn, A.; Glauche, V.; Umarova, R.; Hennig, J.; Schneider, A.; Rijntjes, M. A single dual-stream framework for syntactic computations in music and language. NeuroImage 2015, 117, 267–283. [Google Scholar] [CrossRef] [PubMed]
- Musso, M.; Fürniss, H.; Glauche, V.; Urbach, H.; Weiller, C.; Rijntjes, M. Musicians use speech-specific areas when processing tones: The key to their superior linguistic competence? Behav. Brain. Res. 2020, 390, 112662. [Google Scholar] [CrossRef] [PubMed]
- Marcus, G.F.; Vijayan, S.; Bandi Rao, S.; Vishton, P.M. Rule learning by seven-month-old infants. Science 1999, 283, 77–80. [Google Scholar] [CrossRef]
- Safran, J.R.; Aslin, R.N.; Newport, E.L. Statistical learning by 8-month-old infants. Science 1996, 274, 1926–1928. [Google Scholar] [CrossRef] [Green Version]
- Zimmerer, V.C.; Cowell, P.E.; Varley, R.A. Artificial grammar learning in individuals with severe aphasia. Neuropsychologia 2014, 53, 25–38. [Google Scholar] [CrossRef]
- Huber, W.; Poeck, K.; Weniger, D.; Willmes, K. Aachener Aphasie Test (AAT). Handanweisung Göttingen; Beltz Verlag: Weinheim, Germany, 1983. [Google Scholar]
- Willmes, K.; Poeck, K.; Weniger, D.; Huber, W. Facet theory applied to the construction and validation of the Aachen Aphasia Test. Brain Lang. 1983, 18, 259–276. [Google Scholar] [CrossRef]
- Schuchard, J.; Thompson, C.K. Implicit and explicit learning in individuals with agrammatic aphasia. J. Psycholinguist. Res. 2014, 43, 209–224. [Google Scholar] [CrossRef]
- Scott, R.B.; Dienes, Z. The conscious, the unconscious, and familiarity. J. Exp. Psychol. Learn. Mem. Cogn. 2008, 34, 1264. [Google Scholar] [CrossRef] [Green Version]
- Knowlton, B.J.; Squire, L.R. Artificial grammar learning depends on implicit acquisition of both abstract and exemplar-specific information. J. Exp. Psychol. Learn. Mem. Cogn. 1996, 22, 169. [Google Scholar] [CrossRef] [PubMed]
- Pothos, E.M. Theories of artificial grammar learning. Psychol. Bull. 2007, 133, 227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conway, C.M.; Christiansen, M.H. Statistical learning within and between modalities: Pitting abstract against stimulus-specific representations. Psychol. Sci. 2006, 17, 905–912. [Google Scholar] [CrossRef] [PubMed]
- Tomasello, M. Acquiring linguistic constructions. In Handbook of Child Psychology: Cognition, Perception, and Language; John Wiley and Sons Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Goldberg, A.E. Constructions at Work: The Nature of Generalization in Language; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Ullman, M.T.; Corkin, S.; Coppola, M.; Hickok, G.; Growdon, J.H.; Koroshetz, W.J.; Pinker, S. A neural dissociation within language: Evidence that the mental dictionary is part of declarative memory, and that grammatical rules are processed by the procedural system. J. Cogn. Neurosci. 1997, 9, 266–276. [Google Scholar] [CrossRef] [Green Version]
- Witt, K.; Nühsman, A.; Deuschl, G. Intact artificial grammar learning in patients with cerebellar degeneration and advanced Parkinson’s disease. Neuropsychologia 2002, 40, 1534–1540. [Google Scholar] [CrossRef]
- Bowden, H.W.; Sanz, C.; Stafford, C. Age, sex, working memory, and prior knowledge. In Mind and Context in Adult Second Language Acquisition: Methods, Theory, and Practice; Georgetown University Press: Washington, DC, USA, 2005; pp. 105–128. [Google Scholar]
- Goschke, T.; Friederici, A.D.; Van Kampen Kotz, S.A. Procedural learning in Broca’s aphasia: Dissociation between the implicit acquisition of spatio-motor and phoneme sequences. J. Cogn. Neurosci. 2001, 13, 370–388. [Google Scholar] [CrossRef]
- Bloom, P. Language and Space; MIT press: Cambridge, MA, USA, 1999. [Google Scholar]
- Paulraj, S.R.; Schendel, K.; Curran, B.; Dronkers, N.F.; Baldo, J.V. Role of the left hemisphere in visuospatial working memory. J. Neurolinguist. 2018, 48, 133–141. [Google Scholar] [CrossRef]
- King, J.; Just, M.A. Individual differences in syntactic processing: The role of working memory. J. Mem. Lang. 1991, 30, 580–602. [Google Scholar] [CrossRef]
- Gibson, E. Linguistic complexity: Locality of syntactic dependencies. Cognition 1998, 68, 1–76. [Google Scholar] [CrossRef]
- Antonenko, D.; Brauer, J.; Meinzer, M.; Fengler, A.; Kerti, L.; Friederici, A.D.; Flöel, A. Functional and structural syntax networks in aging. NeuroImage 2013, 83, 513–523. [Google Scholar] [CrossRef]
- Hope, T.M.; Seghier, M.L.; Leff, A.P.; Price, C.J. Predicting outcome and recovery after stroke with lesions extracted from MRI images. NeuroImage Clin. 2013, 2, 424–433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lipson, D.M.; Sangha, H.; Foley, N.C.; Bhogal, S.; Pohani, G.; Teasell, R.W. Recovery from stroke: Differences between subtypes. Int. J. Rehabil. Res. 2005, 28, 303–308. [Google Scholar] [CrossRef] [PubMed]
- Dąbrowska, E. Different speakers, different grammars: Individual differences in native language attainment. Linguist. Approaches Biling. 2012, 2, 219–253. [Google Scholar] [CrossRef]
- Lazar, R.M.; Minzer, B.; Antoniello, D.; Festa, J.R.; Krakauer, J.W.; Marshall, R.S. Improvement in aphasia scores after stroke is well predicted by initial severity. Stroke 2010, 41, 1485–1488. [Google Scholar] [CrossRef] [Green Version]
- Brott, T.; Adams, H.P., Jr.; Olinger, C.P.; Marler, J.R.; Barsan, W.G.; Biller, J.; Spilker, J.; Holleran, R.; Eberle, R.; Hertzberg, V. Measurements of acute cerebral infarction: A clinical examination scale. Stroke 1989, 20, 864–870. [Google Scholar] [CrossRef] [Green Version]
- Umarova, R.M.; Sperber, C.; Kaller, C.P.; Schmidt, C.S.M.; Urbach, H.; Klöppel, S.; Weiller, C.; Karnath, H.O. Cognitive reserve impacts on disability and cognitive deficits in acute stroke. J. Neurol. 2019, 266, 2495–2504. [Google Scholar] [CrossRef]
- Lazar, R.M.; Speizer, A.E.; Festa, J.R.; Krakauer, J.W.; Marshall, R.S. Variability in language recovery after first-time stroke. J. Neurol. Neurosurg. Psychiatry 2008, 79, 530–534. [Google Scholar] [CrossRef]
- Everett, D. Cultural constraints on grammar and cognition in Pirahã: Another look at the design features of human language. Curr. Anthropol. 2005, 46, 621–646. [Google Scholar] [CrossRef] [Green Version]
- Vargha-Khadem, F.; Watkins, K.E.; Price, C.J.; Ashburner, J.; Alcock, K.J.; Connelly, A.; Frackowiak, R.S.; Friston, K.J.; Pembrey, M.E.; Mishkin, M.; et al. Neural basis of an inherited speech and language disorder. Proc. Natl. Acad. Sci. USA 1998, 95, 12695–12700. [Google Scholar] [CrossRef] [Green Version]
- Chater, N.; Reali, F.; Christiansen, M.H. Restrictions on biological adaptation in language evolution. Proc. Natl. Acad. Sci. USA 2009, 106, 1015–1020. [Google Scholar] [CrossRef] [Green Version]
- Kessels, R.P.; van Zandvoort, M.J.; Postma, A.; Kappelle, L.J.; de Haan, E.H. The Corsi block-tapping task: Standardization and normative data. Appl. Neuropsychol. 2000, 7, 252–258. [Google Scholar] [CrossRef] [PubMed]
- Cohen, R.; Lutzweiler, W.; Woll, G. On the validity of the Token Test. Der Nervenarzt 1976, 47, 357–361. [Google Scholar] [PubMed]
- Schröder, A.; Lorenz, A.; Burchert, F.; Stadie, N. Komplexe Sätze: Störungen der Satzproduktion: Materialien für Diagnostik, Therapie und Evaluation; NAT-Verlag: Hofheim, Germany, 2009. [Google Scholar]
- Burchert, F.; Lorenz, A.; Schröder, A.; De Bleser, R.; Stadie, N. Sätze Verstehen: Neurolinguistische Materialien für die Untersuchung von Syntaktischen Störungen beim Satzverständnis; NAT-Verlag: Hofheim, Germany, 2011. [Google Scholar]
- Rohde, A.; Worrall, L.; Le Dorze, G. Systematic review of the quality of clinical guidelines for aphasia in stroke management. J. Eval. Clin. Pract. 2013, 19, 994–1003. [Google Scholar] [CrossRef] [PubMed]
- Papadatou-Pastou, M.; Ntolka, E.; Schmitz, J.; Martin, M.; Munafò, M.R.; Ocklenburg, S.; Paracchini, S. Human handedness: A meta-analysis. Psychol. Bull. 2020, 146, 481. [Google Scholar] [CrossRef]
- Kroll, J.F.; Dussias, P.E.; Bice, K.; Perrotti, L. Bilingualism, mind, and brain. Annu. Rev. Linguist. 2015, 1, 377–394. [Google Scholar] [CrossRef] [Green Version]
- Yourganov, G.; Smith, K.G.; Fridriksson, J.; Rorden, C. Predicting aphasia type from brain damage measured with structural MRI. Cortex 2015, 73, 203–215. [Google Scholar] [CrossRef] [Green Version]
- Jaecks, P.; Hielscher-Fastabend, M.; Stenneken, P. Diagnosing residual aphasia using spontaneous speech analysis. Aphasiology 2012, 26, 953–970. [Google Scholar] [CrossRef]
- Willmes, K. An approach to analyzing a single subject’s scores obtained in a standardized test with application to the Aachen Aphasia Test (AAT). J. Clin. Exp. Neuropsychol. 1985, 7, 331–352. [Google Scholar] [CrossRef]
- Thompson, C.K.; Shapiro, L.P. Complexity in treatment of syntactic deficits. Am. J. Speech Lang. Pathol. 2007, 16, 30–42. [Google Scholar] [CrossRef]
- Friederici, A.D.; Bahlmann, J.; Heim, S.; Schubotz, R.I.; Anwander, A. The brain differentiates human and non-human grammars: Functional localization and structural connectivity. Proc. Natl. Acad. Sci. USA 2006, 103, 2458–2463. [Google Scholar] [CrossRef] [Green Version]
- De Vries, M.H.; Monaghan, P.; Knecht, S.; Zwitserlood, P. Syntactic structure and artificial grammar learning: The learnability of embedded hierarchical structures. Cognition 2008, 107, 763–774. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strange, B.A.; Henson, R.N.; Friston, K.J.; Dolan, R.J. Anterior prefrontal cortex mediates rule learning in humans. Cereb. Cortex 2001, 11, 1040–1046. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Forkstam, C.; Elwér, A.; Ingvar, M.; Petersson, K.M. Instruction effects in implicit artificial grammar learning: A preference for grammaticality. Brain Res. 2008, 1221, 80–92. [Google Scholar] [CrossRef] [Green Version]
- Jamalabadi, H.; Alizadeh, S.; Schönauer, M.; Leibold, C.; Gais, S. Classification based hypothesis testing in neuroscience: Below-chance level classification rates and overlooked statistical properties of linear parametric classifiers. Hum. Brain Mapp. 2016, 37, 1842–1855. [Google Scholar] [CrossRef] [PubMed]
- Mealor, A.D.; Dienes, Z. Explicit feedback maintains implicit knowledge. Conscious. Cogn. 2013, 22, 822–832. [Google Scholar] [CrossRef]
- Linck, J.A.; Cunnings, I. The utility and application of mixed-effects models in second language research. Lang. Learn. 2015, 65, 185–207. [Google Scholar] [CrossRef]
- Team, R.C. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 12 April 2022).
- Bates, D.; Maechler, M.; Bolker, B.; Walker, S.; Christensen, R.H.B.; Singmann, H.; Walker, S.; Dai, B.; Scheipl, F.; Grothendieck, G.; et al. Package ‘lme4’. Linear Mixed-Effects Models Using S4 Classes; R Package Version; R Foundation for Statistical Computing: Vienna, Austria, 2011; p. 1. [Google Scholar]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H. lmerTest package: Tests in linear mixed effects models. J. Stat. Softw. 2017, 82, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression; Sage Publications: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Bartoń, K. MuMIn: Multi-Model Inference; R Package Version 1.40. 4; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Folia, V.; Uddén, J.; De Vries, M.; Forkstam, C.; Petersson, K.M. Artificial language learning in adults and children. Lang. Learn. 2010, 60, 188–220. [Google Scholar] [CrossRef]
- Dale, R.; Christiansen, M.H. Active and passive statistical learning: Exploring the role of feedback in artificial grammar learning and language. In Proceedings of the Annual Meeting of the Cognitive Science Society, Chicago, IL, USA, 4–7 August 2004. [Google Scholar]
- Jackendoff, R.; Wittenberg, E. Linear grammar as a possible stepping-stone in the evolution of language. Psychon. Bull. Rev. 2017, 24, 219–224. [Google Scholar] [CrossRef]
- Lieberman, P. On the evolution of human syntactic ability. Its pre-adaptive Bases—Motor control and speech. J. Hum. Evol. 1985, 14, 657–668. [Google Scholar] [CrossRef]
- Patel, A.D. Language, music, syntax and the brain. Nat. Neurosci. 2003, 6, 674–681. [Google Scholar] [CrossRef] [PubMed]
- MacDonald, M.C.; Christiansen, M.H. Reassessing working memory: Comment on Just and Carpenter (1992) and Waters and Caplan (1996). Psychol. Rev. 2002, 109, 35–54. [Google Scholar] [CrossRef] [PubMed]
- Santi, A.; Grodzinsky, Y. Working memory and syntax interact in Broca’s area. Neuroimage 2007, 37, 8–17. [Google Scholar] [CrossRef] [PubMed]
- Veltman, D.J.; Rombouts, S.A.; Dolan, R.J. Maintenance versus manipulation in verbal working memory revisited: An fMRI study. Neuroimage 2003, 18, 247–256. [Google Scholar] [CrossRef] [Green Version]
- Kümmerer, D.; Hartwigsen, G.; Kellmeyer, P.; Glauche, V.; Mader, I.; Klöppel, S.; Suchan, J.; Karnath, H.O.; Weiller, C.; Saur, D. Damage to ventral and dorsal language pathways in acute aphasia. Brain 2013, 136, 619–629. [Google Scholar] [CrossRef] [Green Version]
- Saur, D.; Kreher, B.W.; Schnell, S.; Kümmerer, D.; Kellmeyer, P.; Vry, M.S.; Umarova, R.; Musso, M.; Glauche, V.; Abel, S.; et al. Ventral and dorsal pathways for language. Proc. Natl. Acad. Sci. USA 2008, 105, 18035–18040. [Google Scholar] [CrossRef] [Green Version]
- Schwering, S.C.; MacDonald, M.C. Verbal working memory as emergent from language comprehension and production. Front. Hum. Neurosci. 2020, 14, 68. [Google Scholar] [CrossRef]
- Amici, F.; Sánchez-Amaro, A.; Sebastián-Enesco, C.; Cacchione, T.; Allritz, M.; Salazar-Bonet, J.; Rossano, F. The word order of languages predicts native speakers’ working memory. Sci. Rep. 2019, 9, 1124. [Google Scholar] [CrossRef] [Green Version]
- Freeman, D.E.L. The acquisition of grammatical morphemes by adult ESL students. TESOL Q. 1975, 9, 409–419. [Google Scholar] [CrossRef]
- Boyd, J.K.; Goldberg, A.E. Learning what not to say: The role of statistical preemption and categorization in a-adjective production. Language 2011, 87, 55–83. [Google Scholar] [CrossRef]
- Ingham, R.; Pinker, S. Learnability and cognition: The acquisition of argument structure. Cambridge, MA: The MIT Press, 1989. Pp. xv+ 411. J. Child Lang. 1992, 19, 205–211. [Google Scholar] [CrossRef]
- Barrière, I.M.; Lorch, P.; Le Normand, M.-T. On the overgeneralization of the intransitive/transitive alternation in children’s speech: A cross-linguistic account with new evidence from French. Int. J. Biling. 1999, 3, 351–362. [Google Scholar] [CrossRef] [Green Version]
- Pinker, S. Learnability and Cognition: The Acquisition of Argument Structure; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Hymes, D. On communicative competence. Sociolinguistics 1972, 269293, 269–293. [Google Scholar]
- Clark, E.V.; Carpenter, K.L. The notion of source in language acquisition. Language 1989, 65, 1–30. [Google Scholar] [CrossRef]
- Bock, K.; Irwin, D.E.; Davidson, D.J. Putting first things first. In The Interface of Language, Vision, and Action: Eye Movements and the Visual World; Psychology Press: Hove, UK, 2004; pp. 249–278. [Google Scholar]
- Clifton, C., Jr.; Staub, A.; Clifton, C. Syntactic influences on eye movements during reading. In The Oxford Handbook of Eye Movements; Oxford University Press: Oxford, UK, 2011; Volume 3. [Google Scholar]
- Hardy, S.M.; Segaert, K.; Wheeldon, L. Healthy aging and sentence production: Disrupted lexical access in the context of intact syntactic planning. Front. Psychol. 2020, 11, 257. [Google Scholar] [CrossRef]
- Stern, Y.; Barnes, C.A.; Grady, C.; Jones, R.N.; Raz, N. Brain reserve, cognitive reserve, compensation, and maintenance: Operationalization, validity, and mechanisms of cognitive resilience. Neurobiol. Aging 2019, 83, 124–129. [Google Scholar] [CrossRef]
- Geerligs, L.; Maurits, N.M.; Renken, R.J.; Lorist, M.M. Reduced specificity of functional connectivity in the aging brain during task performance. Hum. Brain Mapp. 2014, 35, 319–330. [Google Scholar] [CrossRef]
- Lustig, C.; Snyder, A.Z.; Bhakta, M.; O’Brien, K.C.; McAvoy, M.; Raichle, M.E.; Morris, J.C.; Buckner, R.L. Functional deactivations: Change with age and dementia of the Alzheimer type. Proc. Natl. Acad. Sci. USA 2003, 100, 14504–14509. [Google Scholar] [CrossRef] [Green Version]
- Geranmayeh, F.; Brownsett, S.L.; Wise, R.J. Task-induced brain activity in aphasic stroke patients: What is driving recovery? Brain 2014, 137, 2632–2648. [Google Scholar] [CrossRef]
- Musso, M.; Hübner, D.; Schwarzkopf, S.; Bernodusson, M.; LeVan, P.; Weiller, C.; Tangermann, M. Aphasia recovery by language training using a brain–computer interface: A proof-of-concept study. Brain Commun. 2022, 4, fcac008. [Google Scholar] [CrossRef]
- Barulli, D.; Stern, Y. Efficiency, capacity, compensation, maintenance, plasticity: Emerging concepts in cognitive reserve. Trends Cogn. Sci. 2013, 17, 502–509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reali, F.; Christiansen, M.H. Processing of relative clauses is made easier by frequency of occurrence. J. Mem. Lang. 2007, 57, 1–23. [Google Scholar] [CrossRef]
- Bornkessel, I.; Zysset, S.; Friederici, A.D.; von Cramon, D.Y.; Schlesewsky, M. Who did what to whom? The neural basis of argument hierarchies during language comprehension. NeuroImage 2005, 26, 221–233. [Google Scholar] [PubMed]
- Patel, A.D. Musical Rhythm, Linguistic Rhythm, and Human Evolution. Music. Percept. 2006, 24, 99–104. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Groups | Descriptive Statistics | One-Way ANOVA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| N | Mean | SD | Range | Shapiro-Wilk p | F | df1 | df2 | p | ||
| Age | Aphasia | 14 | 64.4 | 11.8 | 42 | 0.816 | 0.004 | 2 | 46 | 0.996 |
| Recovery | 20 | 64.8 | 14.7 | 50 | 0.064 | |||||
| no Aphasia | 15 | 64.5 | 12.8 | 48 | 0.485 | |||||
| Education | Aphasia | 14 | 12.6 | 3.4 | 11 | 0.557 | 0.402 | 2 | 46 | 0.671 |
| Recovery | 20 | 13.2 | 4.2 | 14 | 0.003 | |||||
| no Aphasia | 15 | 13.8 | 2.9 | 10 | <0.001 | |||||
| Lesion Vol nativ | Aphasia | 14 | 46.9 | 58.9 | 216 | 0.006 | 4.246 | 2 | 46 | 0.020 |
| Recovery | 20 | 24.9 | 29.0 | 119 | <0.001 | |||||
| no Aphasia | 15 | 7.0 | 10.7 | 34 | <0.001 | |||||
| NIHSS | Aphasia | 14 | 2.1 | 1.4 | 4 | 0.002 | 3.036 | 2 | 46 | 0.058 |
| Recovery | 20 | 0.4 | 1.0 | 4 | <0.001 | |||||
| no Aphasia | 15 | 1.5 | 3.0 | 10 | <0.001 | |||||
| Corsi | Aphasia | 14 | 4.6 | 1.2 | 5 | <0.001 | 4.229 | 2 | 46 | 0.021 |
| Recovery | 20 | 5.4 | 0.9 | 3 | 0.023 | |||||
| no Aphasia | 15 | 5.6 | 0.9 | 3 | 0.025 | |||||
| TT | Aphasia | 14 | 65.6 | 9.9 | 27 | 0.002 | 7.643 | 2 | 46 | 0.001 |
| Recovery | 20 | 72.2 | 2.1 | 7 | <0.001 | |||||
| no Aphasia | 15 | 72.7 | 1.0 | 4 | <0.001 | |||||
| Kruskal-Wallis Test | ||||||||||
| χ2 | df | p | ||||||||
| Syntax comprehension | Aphasia | 8 | 0.91 | 0.15 | 0.40 | 0.003 | 2.579 | 2 | 0.275 | |
| Recovery | 13 | 0.96 | 0.06 | 0.15 | <0.001 | |||||
| no Aphasia | 12 | 0.99 | 0.05 | 0.17 | <0.001 | |||||
| Syntax production | Aphasia | 8 | 0.78 | 0.17 | 0.52 | 0.009 | 0.949 | 2 | 0.622 | |
| Recovery | 13 | 0.88 | 0.17 | 0.52 | 0.002 | |||||
| no Aphasia | 12 | 0.90 | 0.11 | 0.33 | 0.047 | |||||
| ORCP | Aphasia | 8 | 0.69 | 0.40 | 1.00 | 0.033 | 0.479 | 2 | 0.787 | |
| Recovery | 13 | 0.80 | 0.33 | 0.95 | <0.001 | |||||
| no Aphasia | 12 | 0.8 | 0.25 | 0.67 | 0.007 | |||||
| χ2-Test | ||||||||||
| χ2-Testp | χ2 | df | p | |||||||
| Gender | Aphasia | 14 | 4 | 10 | 0.109 | 0.467 | 2 | 0.977 | ||
| Recovery | 20 | 6 | 14 | 0.074 | ||||||
| no Aphasia | 15 | 4 | 11 | 0.071 | ||||||
| A. Best Fitted Model (S3) R2 = 0.081, RI = 0.846 | B. Verbal Working Memory S3 R2 = 0.095, RI = 0.836 | ||||||
|---|---|---|---|---|---|---|---|
| Predictor | Log (Odds) | SE | z-Value | Predictor | Log (Odds) | SE | z-Value |
| Intercept | 2.165 | 0.169 | 12.807 *** | Intercept | 2.175 | 0.168 | 12.94 *** |
| GT (=E) | −0.089 | 0.083 | −1.084 | vwm | 0.137 | 0.162 | 0.844 |
| Gram (=no) | −0.564 | 0.083 | −6.784 *** | Gram (=no) | −0.562 | 0.084 | −6.697 *** |
| GT × Gram. | −0.165 | 0.083 | −1.998 * | GT (=E) | −0.09 | 0.083 | −1.077 |
| GT × Gram | −0.153 | 0.083 | −1.83 | ||||
| GT × vwm | −0.006 | 0.08 | −0.077 | ||||
| Gram × vwm | 0.11 | 0.081 | 1.36 | ||||
| GT × gram × vwn | 0.194 | 0.08 | 2.419 * | ||||
| C Session-number (S3, S1) R2 = 0.211, RI = 0.339 | D. Generalization (S3, S4) R2 = 0.007, RI = 0.853 | ||||||
| Predictor | Log (Odds) | SE | z-Value | Predictor | Log (Odds) | SE | z-Value |
| Intercept | 1.198 | 0.075 | 15.998 *** | Intercept | 2.233 | 0.157 | 14.212 |
| Session (=1) | −0.763 | 0.05 | −15.356 * | GT (=E) | −0.052 | 0.06 | −0.861 |
| G T (=E) | −0.218 | 0.049 | −4.408 ** | Gram (=0) | −0.533 | 0.06 | −8.846 *** |
| Gram (=no) | −0.516 | 0.05 | −10.427 *** | Session (=3) | −0.074 | 0.06 | −1.228 |
| Session × GT | −0.139 | 0.049 | −2.806 ** | GT × S | −0.018 | 0.06 | −0.603 |
| S × Gram | 0 | 0.049 | −0.003 | Gram × S | −0.02 | 0.06 | −0.603 |
| GT × Gram | −0.007 | 0.049 | −0.145 | Gram × GT | −0.018 | 0.06 | −0.297 |
| GT × Gram × S | 0.144 | 0.049 | 2.913 ** | GT × Gram × S | −0.145 | 0.06 | −2.424 * |
| E.I Trial Effect_S1 R2 = 0.041, RI = 0.140 | E.II. Trial Effect_S1 R2= 0.07, RI = 0.143 | ||||||
| Predictor | Log (Odds) | SE | z-Value | Predictor | Log (Odds) | SE | z-Value |
| Intercept | 0.085 | 0.111 | 0.765 | Intercept | 0.093 | 0.115 | 0.809 |
| GT (=E) | −0.03 | 0.109 | −0.277 | Gram (=no) | −0.568 | 0.112 | −5.05 *** |
| Trial | 0.028 | 0.009 | 3.166 ** | Trial | 0.028 | 0.009 | 3.118 ** |
| GT × Trial | −0.024 | 0.009 | −2.754 ** | Gram × Trial | 0.009 | 0.009 | 0.942 |
| F.I Error_type (ET)_S3 R2 = 0.066, RI = 0.946 | F.II Error code (EC)_S3 R2 = 0.063, RI = 0.908 | ||||||
| Predictor | Log (Odds) | SE | z-Value | Predictor | Log (Odds) | SE | z-Value |
| Intercept | 1.618 | 0.191 | 8.459 *** | Intercept | 1.591 | 0.185 | 8.607 *** |
| GT (=E) | −0.22 | 0.095 | −2.309 * | GT (=E) | −0.209 | 0.095 | −2.205 * |
| ET (=Perm) | 0.075 | 0.095 | 0.784 | EC (=Art) | −0.463 | 0.095 | −4.856 *** |
| ET × GT | −0.476 | 0.096 | −4.956 *** | ET × GT | 0.064 | 0.095 | 0.681 |
| Best Fitted Model R2 = 0.158, RI = 0.575 | |||
|---|---|---|---|
| Predictor | Log (Odds) | SE | z-Value |
| Intercept | 0.009 | 0.59 | 0.015 |
| GT (=E) | 0.166 | 0.313 | 0.53 |
| Gram (=no) | −0.816 | 0.316 | −2.582 ** |
| vwm | 0.692 | 0.69 | 1.003 |
| Ed. age (z-t) | 0.409 | 0.117 | 3.507 *** |
| GT × Gram | 0.525 | 0.311 | 1.69 |
| GT × Ed.age | −0.327 | 0.368 | −0.888 |
| GT × Gram × vwm | −0.771 | 0.364 | −2.114 * |
| A. Session-Number (S1 vs. S3) R2 = 0.167, RI = 0.443 | B. Aphasia S1, S3 R2 = 0.021, RI = 0.468 | C. Age S1, S3 R2 = 0.034, RI = 0.421 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Predictor | Log(Odds) | SE | z-Value | Predictor | Log(Odds) | SE | z-Value | Intercept | 0.279 | 0.075 | 3.406 *** |
| Intercept | 0.293 | 0.08 | 3.67 *** | Intercept | 0.24 | 0.082 | 2.923 ** | GT (=0) | −0.773 | 0.044 | −2.167 * |
| GT (=E) | −0.117 | 0.046 | −2.535 * | Chronic Aphasia | 0.011 | 0.121 | 0.088 | Age | −0.116 | 0.070 | −2.570 * |
| Gram (=no) | −0.803 | 0.046 | −17.408 *** | no Aphasia | −0.003 | 0.117 | −0.028 | Session (=1) | −0.257 | 0.044 | −5.942 *** |
| Session N. | −0.268 | 0.047 | −5.709 *** | Session (=1) | −0.227 | 0.043 | −5.523 *** | Session × GT | −0.009 | 0.044 | −0.220 |
| S × GT | −0.022 | 0.046 | −0.475 | Aphasia * Session | 0.176 | 0.065 | 2.848 * | Age × GT | 0.054 | 0.045 | 1.188 |
| GT × Gram | 0.041 | 0.046 | 0.902 | no Aphasia × Session | −0.035 | 0.063 | −0.578 | Session × age | 0.055 | 0.045 | 1.143 |
| S × Gram | −0.068 | 0.046 | −1.475 | Pairwaise S3 vs. S1 | GT × S × age | 0.09 | 0.044 | 2.157 * | |||
| S × Gram × GT | 0.148 | 0.046 | 3.232 ** | no aphasia | −0.542 | 0.157 | −3.459 *** | ||||
| recovery | −0.750 | 0.124 | −5.815 *** | ||||||||
| aphasia | 0.155 | −0.761 | 0.974 | ||||||||
| D. Educational age S1, S3 R2 = 0.214, RI = 0.373 | E.I ORCP S1, S3 R2 = 0.123, RI = 0.452, RI = 0.439 | E.II ORCP S3 R2 = 0.978, RI = 0.717 | |||||||||
| Intercept | 0.272 | 0.071 | 3.805 *** | Intercept | −0.302 | 0.25 | −1.206 | Intercept | 0.373 | 0.808 | −0.317 |
| Gram (=no) | −0.800 | 0.045 | −17.501 *** | Gram (=0) | −0.433 | 0.128 | −3.384 *** | Gram (=0) | −0.152 | 0.159 | −0.954 |
| Session N. | −0.322 | 0.046 | −6.962 *** | ORCP | 0.624 | 0.304 | 2.056 * | ORCP | 0.803 | 0.452 | 1.778 |
| Ed. age (z-t) | 0.222 | 0.074 | 2.973 ** | Session (=1) | 0.254 | 0.129 | −1.968 * | GT | −0.196 | 0.161 | −1.125 |
| S × Gram | −0.050 | 0.045 | −1.118 | Session × Gram | −0.27 | 0.128 | −2.115 * | ORCP × Gram | −0.499 | 0.197 | −2.535 * |
| Gram × Ed.age | −0.224 | 0.048 | −4.603 *** | ORCP × Gram | −0.203 | 0.155 | −1.34 | ORCP × GT | 0.064 | 0.198 | 0.323 |
| S × Ed.age | −0.249 | 0.049 | −5.079 *** | S × ORCP | −0.079 | 0.157 | −0.506 | GT × gram | 0.056 | 0.159 | 0.352 |
| S × Gram× Ed.age | −0.140 | 0.049 | −2.874 ** | S × Gram × ORCP | 0.247 | 0.155 | 1.559 | ORCP × GT × gram | −0.186 | 0.196 | 0.402 |
| F.I Corsi f. S1, S3 R2 = 0.179, RI = 0.4296 | F.II Corsi f. S1, S3 R2 = 0.031, R.I. = 0.439 | F.III Corsi f. S3 R2 = 0.174, RI = 0.708 | |||||||||
| Intercept | 0.267 | 0.077 | 3.454 *** | Intercept | 0.247 | 0.077 | 3.223 ** | Intercept | −0.612 | 0.58 | −1.055 |
| Gram (=no) | −0.786 | 0.045 | −17.556 *** | GT (=E) | −0.096 | 0.042 | −2.287 * | GT (E) | −0.909 | 0.269 | −3.375 *** |
| Session N. | −0.302 | 0.045 | −6.653 *** | Session N. | −0.244 | 0.042 | −5.703 *** | Corsi (forward) | 0.236 | 0.11 | 2.149 * |
| Corsi f. | 0.133 | 0.080 | 1.670 | Corsi f. | 0.126 | 0.080 | 1.582 | Gram (=no) | −0.02 | 0.269 | −0.076 |
| S × Gram | −0.039 | 0.444 | −0.885 | S × GT | −0.006 | 0.043 | −0.164 | GT × Corsi | 0.162 | 0.052 | 3.11 ** |
| Gram × Corsi | −0.118 | 0.042 | −4.367 *** | GT × Corsi | 0.399 | 0.040 | 0.976 | GT × Gram | 0.47 | 0.267 | 1.758 |
| S × Corsi | −0.103 | 0.428 | −2.422 * | S × Corsi | −0.077 | 0.041 | −1.186 | Corsi × Gram | −0.148 | 0.052 | −2.847 ** |
| S × Gram × Corsi | −0.043 | −0.043 | 0.303 | S × GT × Corsi | −0.109 | 0.040 | −2.690 ** | GT × Corsi × Gram | −0.118 | 0.052 | −2.284 * |
| A. Generalization (S4, S3) R2 = 0.0118, RI = 0.814 | B. Education (S4, S3) R2 = 0.134, RI = 0.657 | ||||||
|---|---|---|---|---|---|---|---|
| Predictor | Log (Odds) | SE | z-Value | Predictor | Log (Odds) | SE | z-Value |
| Intercept | 0.063 | 0.123 | 4.979 *** | Intercept | 0.737 | 0.124 | 5.928 *** |
| GT (=E) | 0.016 | 0.051 | 0.422 | GT (=E) | 0.023 | 0.049 | 0.463 |
| Gram (=0) | −0.068 | 0.046 | −14.856 *** | Ed.age | 0.794 | 0.141 | 5.64 *** |
| Session (=3) | −0.005 | 0.047 | −0.121 | Session (=3) | −0.006 | 0.049 | −0.117 |
| GT × S | −0.07 | 0.049 | −2.534 * | GT × S | −0.135 | 0.049 | −2.739 ** |
| Gram × S | −0.044 | 0.048 | −1.542 | S × Ed.Age | 0.044 | 0.063 | 0.708 |
| Gram × GT | −0.099 | 0.049 | −1.549 | GT × Ed.Age | 0.014 | 0.063 | 0.224 |
| GT × S × Gram | −0.076 | 0.049 | −1.052 | GT × S × Ed.Age | −0.025 | 0.063 | −0.395 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kirsch, S.; Elser, C.; Barbieri, E.; Kümmerer, D.; Weiller, C.; Musso, M. Syntax Acquisition in Healthy Adults and Post-Stroke Individuals: The Intriguing Role of Grammatical Preference, Statistical Learning, and Education. Brain Sci. 2022, 12, 616. https://doi.org/10.3390/brainsci12050616
Kirsch S, Elser C, Barbieri E, Kümmerer D, Weiller C, Musso M. Syntax Acquisition in Healthy Adults and Post-Stroke Individuals: The Intriguing Role of Grammatical Preference, Statistical Learning, and Education. Brain Sciences. 2022; 12(5):616. https://doi.org/10.3390/brainsci12050616
Chicago/Turabian StyleKirsch, Simon, Carolin Elser, Elena Barbieri, Dorothee Kümmerer, Cornelius Weiller, and Mariacristina Musso. 2022. "Syntax Acquisition in Healthy Adults and Post-Stroke Individuals: The Intriguing Role of Grammatical Preference, Statistical Learning, and Education" Brain Sciences 12, no. 5: 616. https://doi.org/10.3390/brainsci12050616