1. Introduction
A brain–computer interface (BCI) provides a direct control pathway between the human brain and external devices, without relying on peripheral nerve and muscle systems [
1]. BCIs have demonstrated potential in medical rehabilitation, education, smart homes, and so on. Most non-invasive BCIs are based on EEG signals, and the neural response patterns are decoded by well-designed algorithms, which can convert movement intentions into computer commands to control external devices, such as a wheelchair [
2], an artificial limb [
3], a spelling system [
4,
5], or a quadcopter [
6]. Steady-state visual evoked potential (SSVEP), P300, and motor imagery (MI) are widely studied neural response paradigms for BCIs. SSVEP and P300 have shown breakthroughs in spelling applications [
4,
5,
6], while MI is prized for its simple stimulus paradigm design, and allows subjects to express motor intention in a natural way [
7].
Motor imagery is accompanied by event-related desynchronization/event-related synchronization (ERD/ERS) in the functional motor area [
8,
9], and effective characterization of the ERD/ERS phenomenon is paramount for a motor imagery-based brain–computer interface (MI-BCI) system. Due to non-stationary EEG signals, the conventional BCI system requires users to undergo a long period of training to obtain substantial labeled instances for a robust model. However, long and monotonous training not only causes a psychological burden to users, but also jeopardizes the adaptability of the BCI system [
10,
11]. Domain adaptation has been developed to deal with limited training data from the target by employing data from other sources. The objective of domain adaptation is to transfer useful knowledge from a source group into the target training set, to overcome the problem of limited calibration data [
12]. As a result, a well-performing classifier can be obtained without a large number of labeled EEG samples from the target subject, thus shortening the training time.
However, the large inter-subject variability of EEG signals has been an impediment to domain adaptation learning. Borgwardt et al. [
13] proposed a maximum mean discrepancy (MMD) criterion for comparing cross-domain distributions. MMD is nonparametric and can estimate the distance between the means of two domains without requiring any labels. Based on MMD, many effective domain adaptation methods have been derived. Transfer component analysis (TCA) learns a common subspace across domains in a Reproducing Kernel Hilbert Space (RKHS) to minimize the distance between the sample means of the source and target data [
13]. The joint distribution adaptation (JDA) method measures the distributional discrepancy using the unweighted sum of marginal and conditional MMDs [
14], and the balanced distribution adaptation (BDA) method leverages the importance of the marginal and conditional distribution [
15]. Domain transfer multiple kernel learning (DTMKL) learns a linear combination of multiple kernels by minimizing both the distribution mismatch between the source and target domains, and the structural risk [
16]. Manifold embedded distribution alignment learns a domain-invariant classier in the Grassmann manifold with structural risk minimization, while performing dynamic distribution alignment by considering the differing importance of marginal and conditional distributions [
17].
Although the abovementioned domain adaptation methods have performed well in computer vision and image sets’ classification, they cannot be directly applied to the EEG signal classification. Since each column (row) of an EEG record is a non-stationary time series signal, it requires a relatively stable descriptor, such as the mean, variance, entropy, or power spectrum. The description of the MI-EEG characteristics has a great impact on the domain adaptation. The common spatial pattern (CSP) is a widespread feature extractor. In order to improve CSP’s ability to handle the interference of noise and non-stationarities in the EEG signals, many improved CSPs have been proposed. Regularization CSP (RCSP) improves the generalization ability of CSP by adding a priori information into the estimation of the inter-class covariance matrix [
18,
19,
20]. The filter bank-based CSP subdivides EEG signals into several sub-bands to find the most discriminative features [
21,
22]. A temporally constrained sparse group spatial pattern (TSGSP) [
23] jointly extracted the significant features from both the filter bank and multiple time windows. In [
24], Dempster–Shafer theory (DST) was employed for the feature selection rules for internal selection. Additionally, combining CSP with domain adaptation approaches provides an effective means for feature extraction in a cross-subject scenario. The complex common spatial pattern (CCSP) linearly combines the inter-class covariance matrices according to the Kullback–Leibler (KL) divergence between the target and sources [
25]. The sparse group representation model (SGRM) constructs a composite dictionary matrix with CSP features from both the target and other subjects [
11]. However, CSP is a supervised feature extractor, and CSP will fail when the sample set is small or there is no label in the target domain. The covariance matrix descriptor of the EEG signal provides a way to circumvent feature extraction.
Barachant et al. pioneered the use of the geometric structure of the EEG signal covariance matrix, and proposed the minimum distance to the Riemannian mean algorithm (MDRM) [
26] and linear classification algorithms in tangent space (TSVM) [
27]. The results outperformed complex and highly parametrized CSP classifiers. Additionally, covariance matrices as features yielded competitive results on the classification of evoked potentials, such as SSVEP [
28], and event-related potentials, such as P300 [
29]. By capitalizing on the geometric properties of the symmetric positive definite (SPD) matrices, many domain alignment techniques have been proposed to make the time-series data from different sessions/subjects comparable. The parallel transport (PT) [
30] projected the SPD matrices from different subsets to a common tangent space, and the Riemannian Procrustes analysis [
31] aligned the statistical distributions of two datasets using simple geometric transformations, and after the alignment in the Riemannian manifold, all cross-subject covariance matrices were mapped into a shared tangent space to train a classifier. The manifold embedded transfer learning (METL) [
32] aligned the covariance matrices of the EEG trials on the SPD manifold, and then learned a domain-invariant classifier of the tangent vectors’ features by combining the structural risk minimization of the source domain and joint distribution alignment of source and target domains. Similarly, the manifold embedded knowledge transfer (MEKT) framework [
33] first whitened the SPD matrices of cross-subjects to an identity matrix, and then performed domain adaptation using tangent vectors to minimize the joint probability distribution shift between the source and the target domains, while preserving their geometric structures.
Assuming that the number of recording electrodes is
, then the dimension of the corresponding tangent vector is
. With the increase of
, the dimension of the vector will expand rapidly, and may even exceed the number of training samples, resulting in over-fitting of the classifier [
34,
35]. In addition, the reference point has a great influence on the tangent plane, and the tangent space determined by different reference points varies greatly [
36].
The SPD matrices have been proven to be a powerful data representation approach for images or image sets via covariance [
37], region covariance descriptors [
38], or sparse coding of the covariance matrices [
39,
40]. In MI-BCI, the second-order statistics of the EEG signal contain discernible information about the subject’s mental state, and the most widespread problem-solving idea is to decompose the covariance matrix and extract the projection vectors with large inter-class variance. CSP is a typical algorithm derived from this concept. Moreover, many studies have demonstrated that the Riemannian metric is more effective than Euclidean distance in describing the discrepancy between covariance matrices [
37,
38,
39,
40,
41]. For the non-linearity of the Riemannian manifold, three approaches have been summarized in the literature: (i) Given that a manifold is a topological space with local Euclidean properties, the Riemannian manifold is locally flattened via tangent spaces. (ii) Under the assumption that the intrinsic structure of the data is inherently low-dimensional, several dimensionality reduction algorithms have been designed to discover the intrinsic low-dimensional manifold, such as Locally Linear Embedding, Isometric Feature Mapping, and Locality Preserving Projection. (iii) One could embed the manifold in a high-dimensional Reproducing Kernel Hilbert Space (RKHS), where subspace learning can be carried out. This concept has been confirmed in image set classification [
38,
42], but it has not yet been applied to motor imagery classification.
In light of the above, we proposed a kernel-based Riemannian manifold domain adaptation (KMDA) method to sidestep the tedious process of feature extraction and take advantage of Riemannian geometry, while avoiding the dimensional explosion of tangent vectors. In our framework, we considered the covariance matrices of EEG signals as features, and aligned the covariance matrices of the source and target in the Riemannian manifold. Then, the log-Euclidean-based Gaussian kernel permitted us to embed the manifold in a high-dimensional RKHS, wherein subspace learning was performed by minimizing the conditional distribution distance between the sources and the target, while preserving the discriminative information of the target. Additionally, we present a feature construction scheme for converting the EEG timing series into 2D frames, which not only fully exploits the electrode position and frequency band of the signal, but also further reduces the dimension of the covariance matrix.
To sum up, the main contributions of this paper include:
- (1)
The KMDA classifies the motor imagery tasks without any target labels.
- (2)
The KMDA defines a subspace learning framework in a RKHS space defined by a kernel on the SPD manifold.
- (3)
The KMDA not only minimizes the marginal and conditional distributions, but also considers intra/inter-class discriminative information of sources and the principal components of the target.
- (4)
A feature construction scheme is presented to reduce the dimension of the SPD matrix and the computational cost.
The rest of the paper proceeds as follows:
Section 2 introduces the Riemannian metric theory of the SPD manifold, and the definition of Gaussian kernel applicable for Riemannian manifolds.
Section 3 details our proposed framework,
Section 4 provides a detailed description of the experiment design and results on three datasets,
Section 5 presents a series of discussions, and a conclusion is drawn in
Section 6.
2. Preliminaries
This section provides an overview on the geometry of the symmetric positive definite (SPD) manifold and some Riemannian metrics for the kernel method. denotes the space spanned by the SPD matrices, and is the tangent space on the point of . represents the single trail of recorded EEG signal with electrodes and time samples. represents a covariance matrix in Euclidean space, and is the point in the Riemannian manifold. designates the Frobenius norm, denotes the transpose operator, and is the sum of the diagonal elements. The principal matrix exponential, , is defined as ; similarly, the matrix logarithmic operator is defined as , with . and denote the exponential and logarithmic maps at the reference point , respectively.
2.1. Riemannian Metrics
The covariance matrix of a single trial,
, was normalized with the total variance, as follows:
A covariance matrix is a typical symmetric positive definite (SPD) matrix,
, and the value of its determinant is a direct measure of the dispersion of the associated multivariate Gaussian [
43]. However, Euclidean geometry forms a non-complete space [
35], which often leads to a swelling effect in regression or average operations [
44] that for the determinant of the Euclidean mean can be strictly larger than the original determinants [
35,
43], giving spurious variation to the data. To fully circumvent these issues, Riemannian metrics are proposed for the SPD manifold.
Tangent Space: The covariance matrices of multi-channel EEG signals define an SPD space, which is locally homeomorphic to the Euclidean space, i.e., the topological manifold is a locally differential manifold [
43,
45]. The curvatures of the curves that pass through each point on the smooth differential manifold define a linear approximation space, also known as the tangent space. For the SPD manifold, there exists a pair of mappings transporting points from the manifold to its corresponding tangent space, and vice versa. Specifically, the logarithmic map is used to embed the neighbors of a given point into the tangent space with the point as a reference, and the exponential map reverses a tangent vector back to the manifold:
As depicted in
Figure 1, any vector in
is identified as a geodesic starting at point
on the manifold; conversely, any bipoint
can be mapped into a vector of
. It is worth noting that the tangent space of a manifold is not unique and depends on the reference point. Conventionally, the reference point is either an identity matrix or the Riemannian mean.
Riemannian mean: The Riemannian mean is defined as the point minimizing the following metric dispersion:
where
denotes a distance suitable for the SPD manifold. Formula (3) does not define a closed-form solution [
41], but it can be solved through an iterative algorithm [
30].
Affine-Invariant Riemannian Metric: The affine-invariant Riemannian metric (AIRM) is a powerful and pervasive metric endowed to the SPD manifold, with the properties of uniquely defining the geodesic between two metrices and the mean of a set of metrices.
An arbitrary invariant distance on
satisfies
, where
is a real invertible
matrix. Choosing
, this distance is transformed to be a distance to the identity:
, where the affine-invariant Riemannian distance between two points,
and
, is transformed to be the Riemannian distance between
and
. Based on this, the distance
can be solved by calculating the geodesic distance of
starting at the identity matrix, which amounts to calculating the vector of
in the tangent space of
. Hence, the Affine-Invariant Riemannian Metric (AIRM) distance,
, between
and
is defined as:
Equivalently, we can write (4) as:
where
is the eigenvalues of
.
Log-Euclidean Metric: The log-Euclidean metric (LEM) can also define the real geodesic distance of two SPD matrices [
46], by computing the distance between their corresponding tangent vectors at the identity matrix, and we have:
Let be the eigen-decomposition of SPD matrix , and is the diagonal matrix of the eigenvalue. Its logarithmic map can be computed easily by: . Compared with the AIRM, the log-Euclidean consumes less computation, while conserving excellent theoretical properties.
In addition to LEM and AIRM, another two metrics derived from Bergman divergences, namely Stein and Jeffrey divergence, are extensively used in manifold analysis. Stein and Jeffrey divergence are symmetric and affine invariants [
41], which prompts the choice of these metrics in the Riemannian mean. Algorithm 1 illustrates the iterative process of estimating a Riemannian mean by AIRM.
| Algorithm 1. Riemannian mean by AIRM. |
| Input: Training set , iteration , and termination criteria |
| Output: The Riemannian mean |
Initialize the reference matrix with an identity matrix. Calculate the covariance matrices of training samples by (1) for i = 1: Map each matrix to the tangent space at by (2). Obtain their Arithmetic mean in the tangent space. Embed the Arithmetic mean to Riemannian space by (2), obtaining corresponding matrix if break for; end if ← end for ←
|
2.2. Positive Definite Kernel on Manifold
Embedding into RKHS through kernel methods is a well-established and prevalent approach in machine learning [
14]. However, embedding SPD manifolds into RKHS requires the kernel functions to be positive definite. The Gaussian kernel has worked well in mapping the data from Euclidean space into an infinite dimensional Hilbert space. In Euclidean, the Gaussian kernel is expressed as
, which relies heavily on the Euclidean distance of two points. To define a Gaussian kernel applicable to the Riemannian manifold, a naive means is to replace the Euclidean distance with the geodesic distance on the premise that the generated kernel is positive definite.
Therefore, we defined the kernel:
by
for all points,
.
is a positive definite kernel for all
only if the Riemannian geodesic metric,
, is negative definite [
42]. Herein, we consider the log-Euclidean metric as the geodesic distance, and we need to prove
for all
with
. It is easy to prove that
is a symmetric function:
, for all matrixes in the SPD manifold.
We analyzed the positive definiteness of the log-Euclidean metric as follows:
The Equation (7) provides the proof that the log-Euclidean kernel guarantees the positive definite of the Riemannian kernel, and satisfies the Mercer theorem.
3. Proposed Framework
We assume that the sources have labeled instances , where denotes a single recorded EEG signal in the source domain, and is the corresponding label. may be collected from one subject or from multiple subjects. is a collection of unlabeled records from the target. We assume that there is the same feature space and label space between domains, but, due to dataset shift, the marginal and conditional probability distribution are different. We use , to map the feature vector to the RKHS space.
In this section, we elaborate on the proposed KMDA framework. KMDA aims to classify the unlabeled target data by exploiting the labeled data from multiple source domains. For the sake of simplicity, only one source domain is considered.
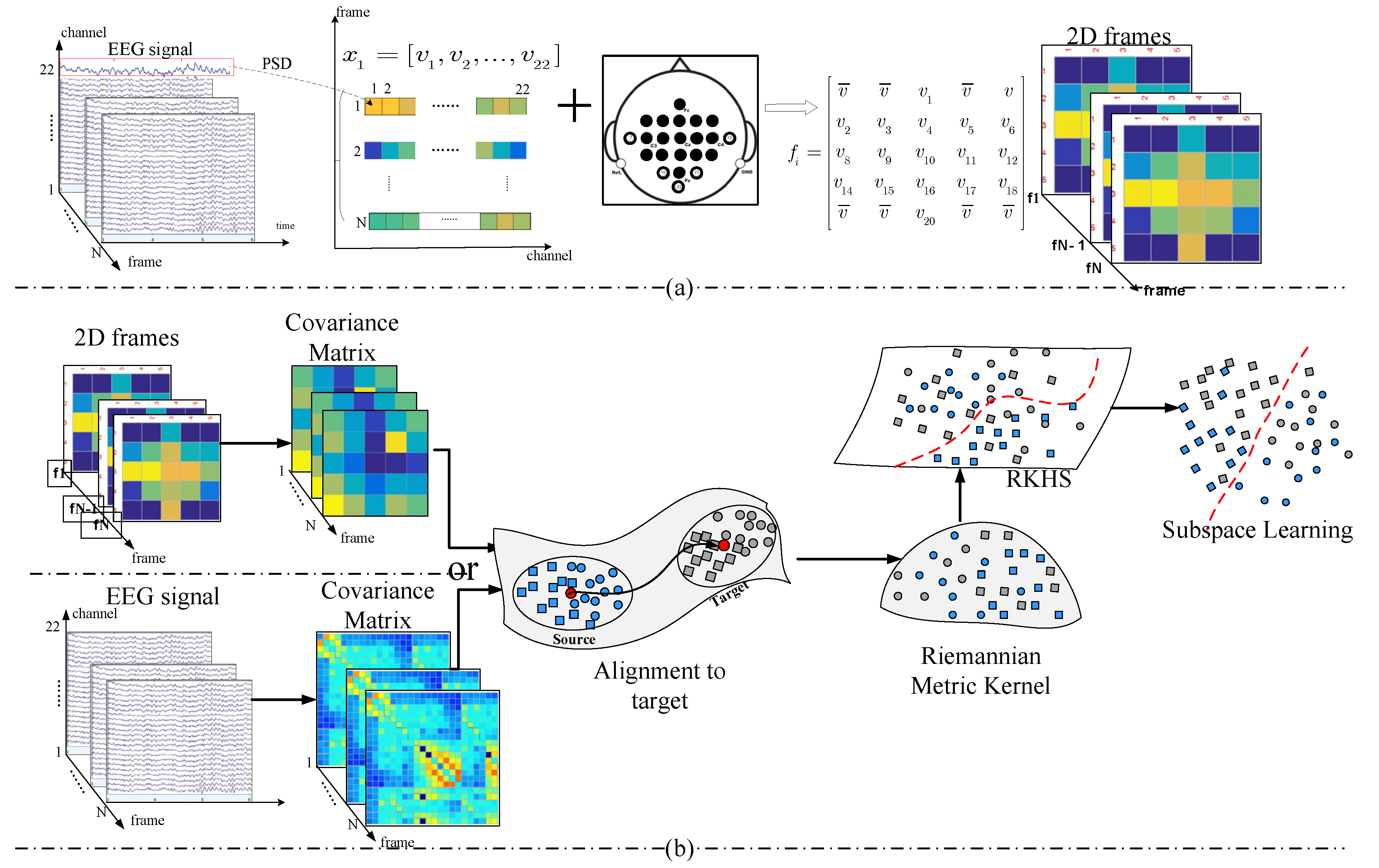
In KMDA, we take the covariance matrix of each EEG record as the feature. Covariance matrices define a symmetric positive definite space (SPD) that can be described by the Riemannian metrics. Due to individual differences in response patterns, and the deviation of the electrode installation position, there is a domain shift between the source and target covariance matrices. Hence, we first performed an alignment in the Riemannian manifold (RA). Subsequently, we embedded the manifold space into a high-dimensional Euclidean space through the log-Euclidean Gaussian kernel, where a discriminative subspace was learned. Alternatively, the SPD matrices can be defined by a set of 2D frames converted from a set of EEG records.
Figure 2 shows the overall workflow of KMDA.
3.1. Alignment of the SPD Matrices
The correlation alignment (CORAL) has proven that aligning the second-order statistics can effectively mitigate the distribution differences across domains [
47]. Referring to CORAL, we proposed an alignment in the Riemannian manifold, referred to as Riemannian alignment (RA), to align the symmetric positive definite matrices on the Riemannian manifold, which skillfully skips the tedious process of feature extraction from the EEG signal.
In RA, we whitened the source domain first to remove the correlations of the source domain, by:
Then, we recolored the source with correlations of the target domain.
where
denotes the source matrix after recollection, and
is the Riemannian mean of the target obtained through Algorithm 1. Equation (9) was used to reconstruct the source matrices using the target Riemannian mean, and after that, the source and target distributions differed little, so they can be considered to have an identical marginal probability distribution.
3.2. Kernel on Riemannian Manifold
Due to the non-Euclidean geometry of Riemannian manifolds, Euclidean algorithms yield inferior results on SPD matrices. We defined a Gaussian radial basis function-based positive definite kernel on the Riemannian manifold to embed the SPD manifold in a high-dimensional Reproducing Kernel Hilbert Space. The kernel makes it possible to utilize algorithms developed for linear spaces on nonlinear manifold data.
We employed the log-Euclidean distance as the Riemannian metric. One reason for this is that the log-Euclidean distance defines the real geodesic distance between two symmetric positive definite matrices, and more importantly, the Gaussian kernel with the log-Euclidean metric yields a positive definite kernel, satisfying the conditions of Mercer’s theorem, as proven by (7).
The SPD matrices can be transformed into the RKHS with:
3.3. Learning Mapping Matrix
Since the RA reconstructs the source using the eigenvectors and eigenvalues of the target, we assumed that the marginal distribution of the source and target remains identical in RKHS. The purpose of KMDA is to learn a transformation matrix, , in RKHS, so as to minimize the conditional divergence of the source and target while maximizing the variance of the target domain and preserving the discriminative information of the source domain as much as possible.
- (1)
Target Variance
For an effective subspace, it should maximize the preservation of the principal components of the target and avoid projecting the features into irrelevant dimensions. Since the target labels are unknown, variance is used to measure the distinguishable information of target features. Hence, the objective function is defined as:
- (2)
Source Discriminative Information
The discriminative information of the source domain should be preserved in the new subspace. To this end, we exploited the labels to define the discernibility of the source; that is, we maximized the distance between classes while minimizing the distance within classes:
where
is the within-class scatter matrix of the source data,
is the between-class scatter matrix, in which
is the number of source data of
-class,
is the mean of samples from class
, and
is the mean of all source data.
- (3)
Condition Distribution
In the new subspace, the discrepancy between samples of the same type in the source and the target domain should be small, i.e., the conditional distribution distance should be minimized. We used the MMD as the criterion to measure the distribution divergencies.
Then, we obtained the objective function:
where
are the kernel matrices defined by (10) on the Riemannian manifold in the target domain, source domain, and cross-domain, respectively.
- (4)
Overall Objective Function
Combining all of the above optimization objectives, we formulated the overall objective function of the proposed KMDA method:
We simplified (15) as:
where
,
, and
are the trade-off parameters to balance the importance of each term.
By the Lagrange operator, we deformed the optimization function into:
By setting
, we found:
The optimal are given by the leading eigenvectors of the eigen-decomposition of (18).
Let and , then we get , , , and , where is the center matrix, is the identity matrix, and is the column vector with all ones. In , we get and , with , .
Given a new instance, , from the target, its projection, , in the discriminant subspace was obtained by: , where and . The classification was performed on the classifier trained with the source data.
The pseudo-codes of the KMDA algorithm are described in Algorithm 2.
| Algorithm 2. Kernel-Based Manifold Domain Adaptation. |
Input: EEG and source labels: , ;
Parameters: , , , . |
| Output: Transformation matrix: ; Target labels . |
- 1.
Calculate covariance matrices and . - 1′.
Or Calculate the covariance matrices of 2D frames. - 2.
Calculate the Riemannian means of source and target by Algorithm 1. - 3.
Align the SPD matrices of source and target by (8) and (9) - 4.
Initialize pseudo labels of target domain using the minimum distance to Riemannian mean algorithm [ 26]. - 5.
Construct - 6.
Repeat - 7.
Solve the generalized eigen-decomposition problem in (18) and select the leading eigenvectors as the transformation - 8.
Obtain the embedding features: , by . - 9.
Train a classifier on to update pseudo labels in target domain - 10.
Update . - 11.
Until convergence - 12.
Obtain transformation matrix and target labels
|
The joint geometrical and statistical alignment (JGSA) [
48] algorithm is a similar study to KMDA. JGSA mainly concentrates on finding two coupled projections that embed the source and target data into low-dimensional subspaces, where the domain shift is reduced while preserving the target domain properties and the discriminative information of source data, simultaneously. KMDA improves in two aspects. One is that, with the help of Riemannian alignment, KMDA transforms the source and target data into a common space, and hence it is reducible to solve an embedded subspace. Besides, the features in JGSA must be in the form of a flattened vector, while KMDA is characterized by the form of an SPD matrix.
- (5)
Converting Multichannel EEG Signals into 2D Frames
We assumed a set of EEG signals can be divided into segments by a sliding window, denoted by .
In each segment, we calculated the power of each channel in the 8~30 Hz frequency band in sequence.
welch (the built-in function package of MATLAB) was used first to calculate the power spectral density, followed by the
pwelch function for the power spectrum and then the
bandpower function to extract the power of the alpha and beta rhythm. As a result, we flattened a
EEG signal into a
vector, with each element corresponding to the power value
. For the purpose of maintaining spatial information among multiple adjacent channels, we further converted the vector
to a 2D frame according to the electrode distribution map.
Figure 2a illustrates the schematic diagram for 2D EEG frames in the 22-electrode scenario, where the electrodes circled in bold are the selected ones. The constructed frame,
, is expressed as:
and
must be a square matrix. We filled the central raw of the matrix
with electrodes located in the central functional area (marked with C1, C2, …, Cn), partitioning the matrix into upper and lower parts, and each part was associated with the physical installation positions. Then, we completed the matrix with task-related electrodes, and the unused electrodes and the positions without electrodes were represented by the average power of all electrodes,
. In this way, the chain-like EEG signals were converted to 2D frame sequences,
, and each frame,
, embodied the task-related power features and spatial information.
It is obvious that the size of a 2D frame is much smaller than that of an EEG signal, and is of great significance to improving the computation speed of Riemannian manifolds. Taking a 22-electrode setup as an example, the covariance matrix of an EEG trial is , whereas the size is for a 2D frame.
4. Experiments and Results
4.1. Dataset Description
BCI Competition IV Dataset IIa (Dataset IIa) consists of 9 subjects, ‘A01’, ‘A02’, …, ‘A09’. The 4-class cued motor imagery data were recorded by 22 EEG channels with a 250 Hz sampling rate. At t = 2 s, an arrow indicated that one of the four classes promoted the subject to perform the desired mental task until the cue disappeared at t = 6 s. Each subject recorded two sessions on different days, one for calibration, and the other for evaluation. Each session is comprised of 6 runs, and one run consists of 48 trials (12 trials per class), yielding 288 trails per session. In our experiment, we removed the trials containing an artifact label, marked with 1′ in the h.ArtifactSelection list.
BCI Competition III Dataset IVa (Dataset IVa) contains 2-class EEG signals recorded at 118 channels with a 1000 Hz sampling rate (down-sampled to 100 Hz in this paper) from 5 subjects, named as ‘AA’, ‘AY’, ‘AW’, ‘AL’, and ‘AV’. For each subject, a total of 280 cue-based trials are available. In each trial, a cue was indicated for 3.5 s, during which two MI tasks were performed: right hand and right foot. Then, the cue was intermitted by periods of random length, 1.75 to 2.25 s, in which the subject could relax.
BCI Competition III Dataset IIIa (Dataset IIIa) is a 4-class EEG dataset (left hand, right hand, foot, tongue) from 3 subjects (‘K3’, ‘K6’, ‘L1’), recorded by 60 channels, sampled at 250 Hz. The dataset consists of several runs, with 40 trials for each run. After the beginning of each trial, the subject rested in the first 2 s, then performed the indicated mental task from t = 3 s to t = 7 s. Each of the 4 cues appeared 10 times per run in a random order.
In our experiments, after the removal of EEG baseline drift, all datasets were filtered by a 6-order 8~30 Hz bandpass filter. The calibration and evaluation trials of Dataset IIa were extracted from the 2.5 to 4.5 s time interval recommended by the competition winner, and Dataset IVa and Dataset IIIa were extracted using a 3 s window after the cue onset at 0.5 s.
4.2. Experiment Design
We verified the merits of the proposed KMDA using three datasets, and compared it with the state-of-the-art domain adaptation algorithms.
Table 1 presents the descriptions of the concerned methods. Except for MEKT, none of the other control algorithms were originally designed for EEG analysis, and we adapted them slightly to fit the experimental situation.
Feature Extraction: MEKT maps the covariance matrices into the tangent space at the identity matrix, yielding a collection of corresponding tangent vectors, and the other algorithms concatenate the covariance matrices into flattened vectors. For the BCI Competition III Dataset IVa, for instance, the size of each trial was 118 × 300, and the size of its covariance matrix was 118 × 118, so the corresponding concatenated vector size was 1 × 13,924, and the vector in the tangent space was 1 × 7021. The high-dimensional vectors put forward a high demand for the size of the training set, otherwise, the model would be overfitted. Therefore, we proposed the method of converting multichannel EEG signals to 2D EEG frames to reduce the dimension. In the follow-up experiments, except for KMDA, all the control methods took the covariance matrices of 2D frames as input, so for the Dataset IVa, the dimension of the corresponding tangent vector was 1 × 66, and the dimension of the concatenated vector was 1 × 121. Both the covariance matrix of the 2D frames and the EEG signals are discussed in KMDA. For ease of differentiation, KMDA refers to the model with the covariance matrices of the 2D frames as input, while e-KMDA takes the covariance matrices of the EEG signals as input. The matrix dimensions before and after the conversion of the three datasets are shown in
Table 2.
Hyper-parameter: Since the target data is assumed to be unlabeled, cross-validation is not applicable to the parameter determination. We set the parameters of (17) as and , the iterations , and the dimension of subspace , where is the dimension of the SPD matrix. The hyper-parameters for the other algorithms were set according to the recommendations in the corresponding literature.
Classifier: The k-Nearest Neighbor Classifier (KNN) was used for all methods. To facilitate the calculation, we fixed k = 3 for all the experiments.
Data setting: All our experiments were carried out on the calibration data from three datasets. Since the feature distributions of ‘A08’, ‘AL’, and ‘K3’ were distinguishable, they were treated as the source data for the corresponding dataset, and the rest of the subjects were taken as the target. Therefore, we had 8 + 4 + 2 = 14 transfer scenarios.
Measurement: For the classification evaluation of the four tasks (Dataset IIa and Dataset IIIa), we opted for the Kappa coefficient recognized by BCI competition, while for binary classification (Dataset IVa), we used accuracy as the evaluation index.
4.3. Results
Validation of Riemannian Alignment: Among the compared methods (as described in
Table 1), except for JDA and JGSA, all the methods contained unsupervised distribution alignment of the source and target domains in Euclidean space or manifold space.
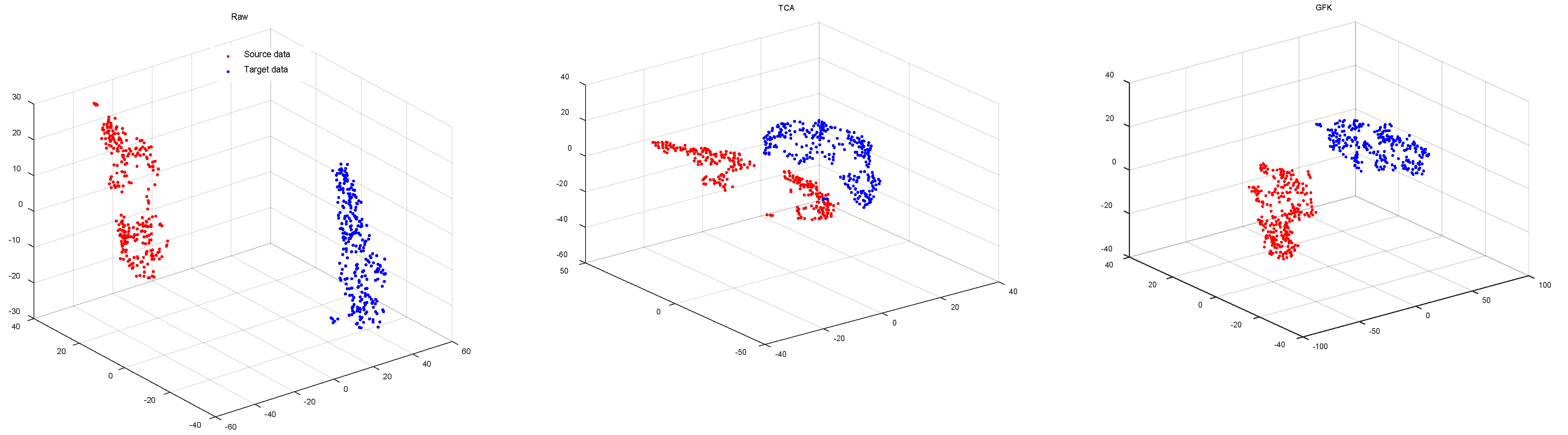
Figure 3 visualizes the distributions after unsupervised alignment by the investigated methods in transferring subject ‘AL’ to subject ‘AA’ from DIVa by t-SNE [
51]. The results indicated that the proposed RA not only aligns the marginal distributions of the source and target domain well, but also minimizes the distance between features of the two domains while preserving the characteristic of target distribution. Specifically, (a) to rectify the mismatch in distribution, TCA capitalizes on subspace learning [
13], while GFK resorts to a shared space [
50] to match the data distributions of different domains; however, both methods ignore the distribution characteristics of the target. (b) Both CORAL and SA align source data in the direction of the target domain. SA reconstructs the source data with the principal components of the target [
49], and CORAL restructures the source data with all the eigenvectors of the target covariance matrix [
47]. However, they fail to take into account the particularity of the covariance matrix as a feature, and the geometry of the SPD manifold. (c) The alignment approaches of MEKT and KMDA perform a parallel transport on the cone manifold of the SPD matrices to align the source with the target domain. However, MEKT whitens the covariance matrices of the source and target, resulting in an identical and uniform distribution [
33], which completely destroys the characteristics of the target. By contrast, KMDA aligns the source covariance matrices with the target, yielding a set of covariance matrices formally similar to those of the target and consistent with the principal axis of the target, thus minimizing the domain shift while preserving the distribution characteristics of the target.
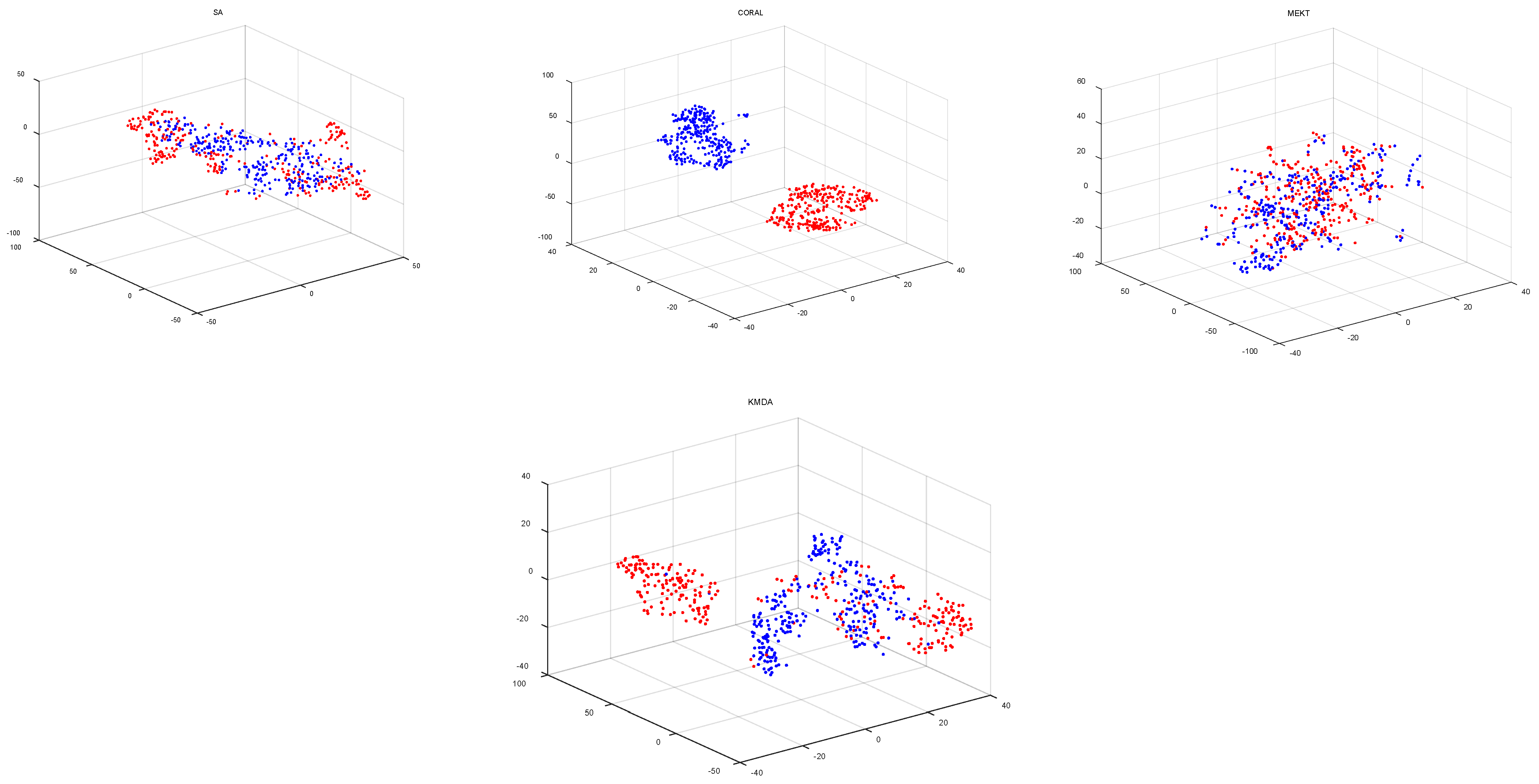
Validation of Subspace Learning: JDA, JGSA, MEKT, and KMDA aim to learn a discriminative subspace by leveraging labeled source data.
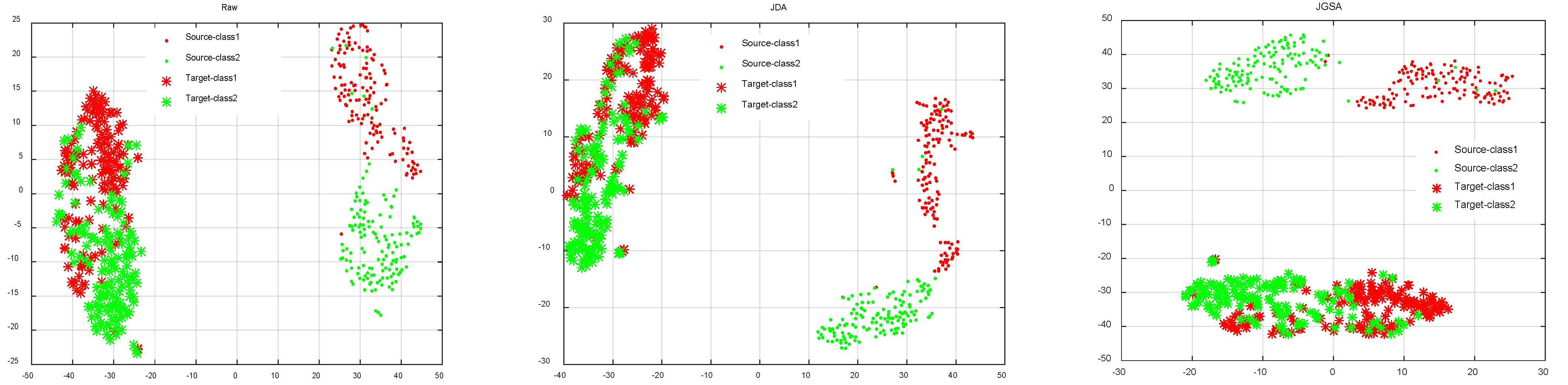
Figure 4 depicts results of transferring subject ‘AL’ to subject ‘AA’ using the four domain adaption approaches. As shown in
Figure 4, the raw source domain and target domain distribute differently, and their marginal distribution and conditional distribution are widely divergent. JDA and JGSA minimize the discrepancy of marginal and conditional distributions between the source and target, rather than the distance between features. MEKT and KMDA not only minimize the distribution divergence, but also make the features from the same class maximally close in the two domains. However, compared with MEKT, KMDA preserves more target distribution characteristics.
Classification accuracy: We evaluated KMDA and the other methods (list in
Table 2) on different cross-domain scenarios. A baseline refers to the results of classifying the target data directly by a classifier trained on the source.
Table 3 depicts the Kappa values of four metal tasks, and
Table 4 shows the accuracies of Dataset IVa. We observed that the domain adaptation methods improved transfer performance to varying degrees. In general, KMDA achieved a better performance compared with other methods, the average Kappa values of KMDA were 0.56 and 0.75, and the average accuracy was 81.56%, 0.08, 0.05, and 5.28% higher than e-KMDA, respectively, which indicates that the 2D frame framework helps to improve performance. The results of a Wilcoxon signed rank test further confirmed the significant superiority of KMDA over other methods.
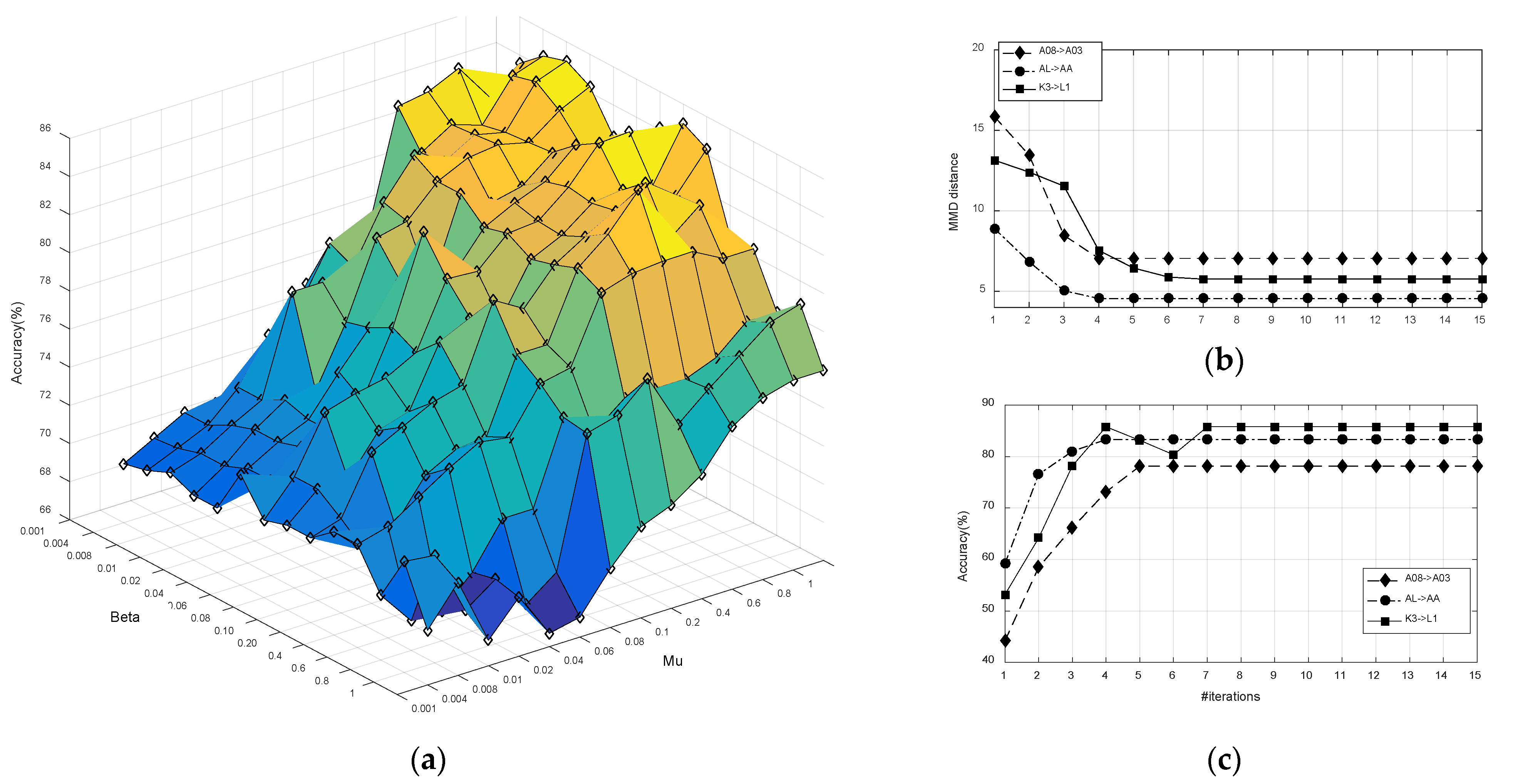
Parameter Sensitivity: We analyzed the parameter sensitivity of KMDA in the scenario of ‘A08->A03’. The objective function of KMDA (17) contains three parameters, where
,
, and
are trade-off parameters to balance the principal components of the target domain, the discrepancy of conditional probability distributions between the source and target, and the within- and between-class variance of the source, respectively. Since
only involves the target domain, and
and
involve the source domain, the evaluation of
,
, and
can be boiled down to the evaluation of
and
under the condition of
= 1.
Figure 5a demonstrates that the optimal values
and
are not unique, and a large range of
(
) and
(
) can be selected to obtain satisfactory performances. This is partly explained by the fact that, when the
exceeds 0.4, the model will overfit due to excessive attention to the discriminative information of the source.
Computation Complexity: We validated the convergence of KMDA, and checked the computation cost of the JDA, JGSA, MEKT, and KMDA/e-KMDA methods.
Figure 5b,c demonstrate the results in ‘A08->A03’, ‘AL->AA’, and ‘K3->L1’ scenarios. As can be seen from
Figure 5b,c in KMDA, the classification accuracy improved with the number of iterations, and the distribution distance gradually decreased and converged within 5 iterations.
Figure 6 depicts the average running time of different algorithms above three scenarios, with the iterations. Although the proposed KMDA did not show an overwhelming advantage in terms of computation consumption, it was competitive under the trade-off of time and performance. Additionally, KMDA saved nearly half of the time compared to e-KMDA.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}