
Agents Strongly Preferred: ERP Evidence from Natives and Non-Natives Processing Intransitive Sentences in Spanish


Abstract
:1. Introduction
2. The Present Study
2.1. Hypotheses
2.2. Participants
2.3. Materials
2.4. Procedure
2.5. EEG Recording
2.6. Data Analysis
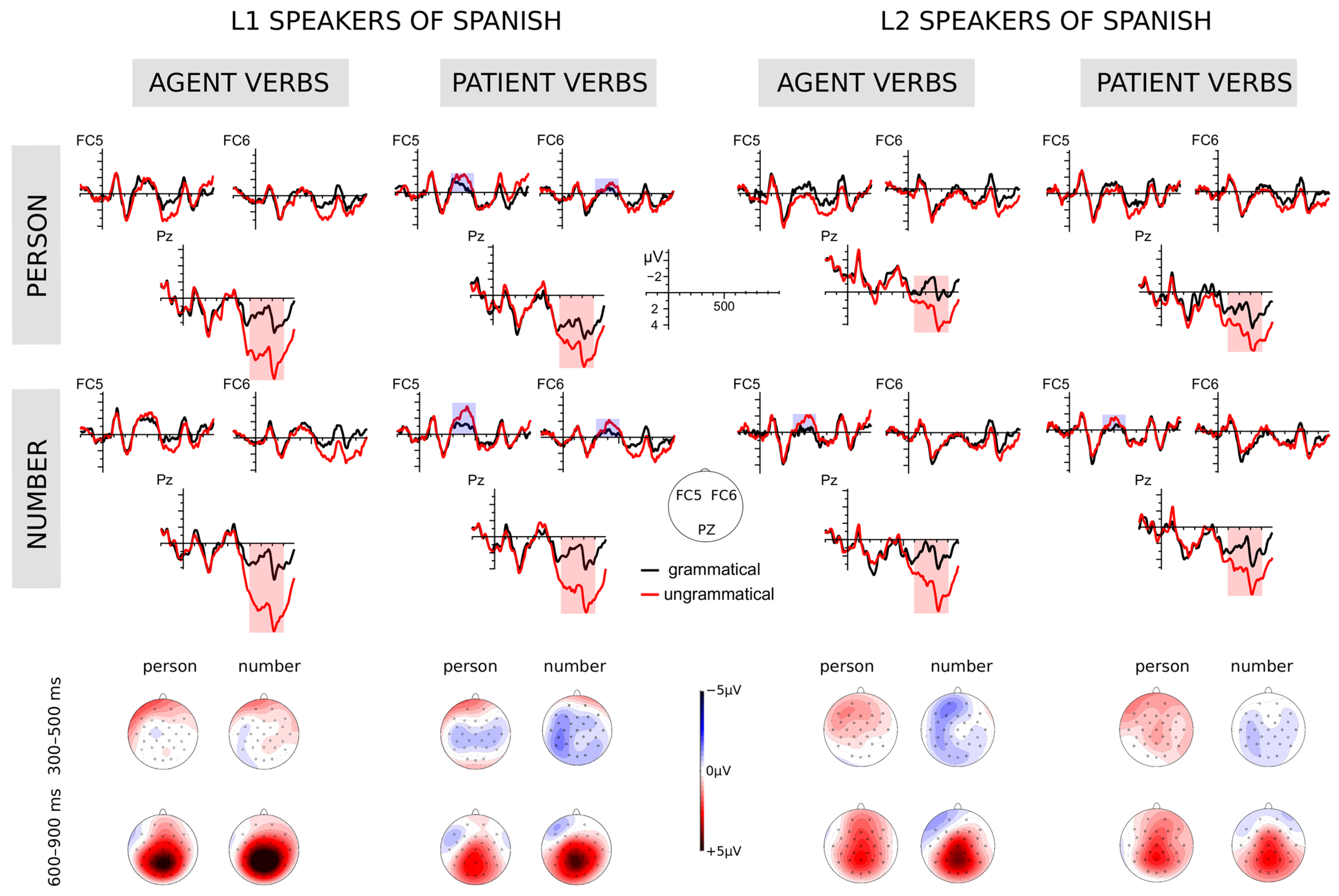
3. Results
3.1. Behavioral Results
3.2. Electrophysiological Results
3.3. Summary of the Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Diaz, B.; Erdocia, K.; De Menezes, R.F.; Mueller, J.L.; Sebastián-Gallés, N.; Laka, I. Electrophysiological Correlates of Second-Language Syntactic Processes Are Related to Native and Second Language Distance Regardless of Age of Acquisition. Front. Psychol. 2016, 7, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erdocia, K.; Zawiszewski, A.; Laka, I. Word order processing in a second language: From VO to OV. J. Psycholinguist. Res. 2014, 43, 815–837. [Google Scholar] [CrossRef] [PubMed]
- Proverbio, A.M.; Cok, B.; Zani, A. Electrophysiological measures of language processing in bilinguals. J. Cogn. Neurosci. 2002, 14, 994–1017. [Google Scholar] [CrossRef] [PubMed]
- Weber-Fox, C.M.; Neville, H.J. Maturational constraints on functional specializations for language processing: ERP and behavioural evidence in bilingual speakers. J. Cogn. Neurosci. 1996, 8, 231–256. [Google Scholar] [CrossRef] [PubMed]
- Zawiszewski, A.; Gutiérrez, E.; Fernández, B.; Laka, I. Language distance and non-native syntactic processing: Evidence from event-related potentials. Biling. Lang. Cogn. 2011, 14, 400–411. [Google Scholar] [CrossRef] [Green Version]
- Kotz, S.A. A critical review of ERP and fMRI evidence on L2 syntactic processing. Brain Lang. 2009, 109, 68–74. [Google Scholar] [CrossRef]
- Zawiszewski, A.; Laka, I. Bilinguals processing noun morphology: Evidence for the language distance hypothesis from event-related potentials. J. Neurolinguist. 2020, 55, 100908. [Google Scholar] [CrossRef]
- Bornkessel-Schlesewsky, I.; Schlesewsky, M. The role of prominence information in the real-time comprehension of transitive constructions: A cross-linguistic approach. Lang. Linguist. Compass 2009, 3, 19–58. [Google Scholar] [CrossRef]
- Tanner, D. On the left anterior negativity (LAN) in electrophysiological studies of morphosyntactic agreement: A commentary on “Grammatical agreement processing in reading: ERP findings and future directions” by Molinaro et al., 2014. Cortex 2015, 66, 149–155. [Google Scholar] [CrossRef]
- Kutas, M.; Federmeier, K.D. Thirty years and counting: Finding meaning in the N400 component of the event-related brain potential (ERP). Annu. Rev. Psychol. 2011, 62, 621–647. [Google Scholar] [CrossRef] [Green Version]
- Frisch, S.; Schlesewsky, M. The N400 reflects problems of thematic hierarchizing. Neuroreport 2001, 12, 3391–3394. [Google Scholar] [CrossRef] [PubMed]
- Van Petten, C.; Luka, B.J. Neural bases of semantic context effects in electromagnetic and hemodynamic studies. Brain Lang. 2006, 97, 279–293. [Google Scholar] [CrossRef] [PubMed]
- Regel, S.; Meyer, L.; Gunter, T.C. Distinguishing neurocognitive processes reflected by P600 effects: Evidence from ERPs and neural oscillations. PLoS ONE 2014, 9, e96840. [Google Scholar] [CrossRef] [PubMed]
- Tanner, D.; van Hell, J. ERPs reveal individual differences in morphosyntactic processing. Neuropsychologia 2014, 56, 289–301. [Google Scholar] [CrossRef] [PubMed]
- Mueller, J.; Hirotani, M.; Friederici, A. ERP evidence for different strategies in the processing of case markers in native speakers and non-native learners. BMC Neurosci. 2007, 8, 18. [Google Scholar] [CrossRef] [Green Version]
- Rossi, S.; Gugler, M.F.; Friederici, A.D.; Hahne, A. The impact of proficiency on syntactic second-language processing of German and Italian: Evidence from event-related potentials. J. Cogn. Neurosci. 2006, 18, 2030–2048. [Google Scholar] [CrossRef] [Green Version]
- Bornkessel, I.; Schlesewsky, M. The extended argument dependency model: A neurocognitive approach to sentence comprehension across languages. Psychol. Rev. 2006, 113, 787–821. [Google Scholar] [CrossRef] [Green Version]
- Primus, B. Cases and Thematic Roles: Ergative, Accusative and Active; Niemeyer: Tübingen, Germany, 1999. [Google Scholar]
- Riesberg, S.; Malcher, K.; Himmelmann, N.P. How universal is agent-first? Evidence from symmetrical voice languages. Language 2019, 95, 523–561. [Google Scholar] [CrossRef]
- Abbot-Smith, K.; Chang, F.; Rowland, C.; Ferguson, H.; Pine, J. Do two and three year old children use an incremental first-NP-as-agent bias to process active transitive and passive sentences?: A permutation analysis. PLoS ONE 2017, 12, e0186129. [Google Scholar] [CrossRef] [Green Version]
- Demiral, Ş.B.; Schlesewsky, M.; Bornkessel-Schlesewsky, I. On the universality of language comprehension strategies: Evidence from Turkish. Cognition 2008, 106, 484–500. [Google Scholar] [CrossRef]
- Bickel, B.; Witzlack-Makarevich, A.; Choudhary, K.K.; Schlesewsky, M.; Bornkessel-Schlesewsky, I. The Neurophysiology of Language Processing Shapes the Evolution of Grammar: Evidence from Case Marking. PLoS ONE 2015, 10, e0132819. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Silva-Pereyra, J.F.; Carreiras, M. An ERP study of agreement features in Spanish. Brain Res. 2007, 1185, 201–211. [Google Scholar] [CrossRef] [PubMed]
- Mancini, S.; Molinaro, N.; Rizzi, L.; Carreiras, M. A person is not a number: Discourse involvement in subject–verb agreement computation. Brain Res. 2011, 1410, 64–76. [Google Scholar] [CrossRef] [PubMed]
- Zawiszewski, A.; Santesteban, M.; Laka, I. Phi-features reloaded: An ERP study on person and number agreement processing. Appl. Psycholinguist. 2016, 37, 601–626. [Google Scholar] [CrossRef]
- Mancini, S. Features and Processing in Agreement; Cambridge Scholars Publishing: Cambridge, UK, 2018. [Google Scholar]
- De Rijk, R. Standard Basque: A Progressive Grammar; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar] [CrossRef]
- Martinez de la Hidalga, G.; Zawiszewski, A.; Laka, I. Eppur non si muove: Experimental evidence for the Unaccusative Hypothesis and distinct ɸ-feature processing in Basque. Glossa J. Gen. Linguist. 2019, 4, 120. [Google Scholar] [CrossRef] [Green Version]
- Molinaro, N.; Barber, H.A.; Carreiras, M. Grammatical agreement processing in reading: ERP findings and future directions. Cortex 2011, 47, 908–930. [Google Scholar] [CrossRef]
- Oldfield, R.C. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia 1971, 9, 97–113. [Google Scholar] [CrossRef]
- Benveniste, E. Problemes de Linguistique Generale; Gallimard: Paris, France, 1966. [Google Scholar]
- Harley, H.; Ritter, E. Person and number in pronouns: A feature-geometric analysis. Language 2002, 78, 482–526. [Google Scholar] [CrossRef]
- Martinez de la Hidalga, G.; Zawiszewski, A.; Laka, I. Going Native? Yes, If Allowed by Cross-Linguistic Similarity. Front. Psychol. 2021, 12, 742127. [Google Scholar] [CrossRef]
- Gratton, G.; Coles, M.G.; Donchin, E. A new method for off-line removal of ocular artifact. Electroencephalogr. Clin. Neurophysiol. 1983, 55, 468–484. [Google Scholar] [CrossRef]
- Greenhouse, S.W.; Geisser, S. On methods in the analysis of profile data. Psychometrika 1959, 24, 95–112. [Google Scholar] [CrossRef]
- Hahne, A. What’s different in second-language processing? Evidence from event-related brain potentials. J. Psycholinguist. Res. 2001, 30, 251–266. [Google Scholar] [CrossRef] [PubMed]
- Meltzer-Asscher, A.; Mack, J.E.; Barbieri, E.; Thompson, C.K. How the brain processes different dimensions of argument structure complexity: Evidence from fMRI. Brain Lang. 2015, 142, 65–75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dekydtspotter, L.; Seo, H.-K. Transitivity in the processing of intransitive clauses: A Category-Based Prediction in Low-Intermediate Learners of English. Stud. Second Lang. Acquis. 2017, 39, 527–552. [Google Scholar] [CrossRef]

{kind=link}
| L1 Speakers of Spanish n = 24 | L2 Speakers of Spanish n = 24 | |
|---|---|---|
| Age | 20.5 (2.9) | 21.8 (2.9) |
| AoA of Spanish | - | 5.7 (1.9) |
| Sex (# males) | 10 | 5 |
| Relative use of Spanish | ||
| Before primary school (0–3yrs) | 1.56 (0.14) | 6.75 (0.09) |
| Primary school (4–12 yrs) | ||
| Home | 1.22 (0.12) | 6.63 (0.15) |
| School | 4.3 (0.33) | 6.58 (0.13) |
| Others | 2.22 (0.25) | 6.54 (0.12) |
| Secondary school (12–18 yrs) | ||
| Home | 1.3 (0.12) | 6.63 (0.13) |
| School | 3.74 (0.32) | 6.08 (0.18) |
| Others | 2.19 (0.23) | 6 (0.16) |
| At time of testing | ||
| Home | 1.37 (0.18) | 6.34 (0.22) |
| University/Work | 3.74 (0.32) | 5.58 (0.27) |
| Others | 3.07 (0.29) | 5.34 (0.25) |
| Self-rated proficiency: Spanish | ||
| Comprehension | 6.74 (0.09) | 6.5 (0.16) |
| Speaking | 6.74 (0.09) | 6.04 (0.15) |
| Reading | 6.67 (0.11) | 6.54 (0.13) |
| Writing | 6.6 (0.11) | 5.71 (0.19) |
| Self-rated proficiency: Basque | ||
| Comprehension | 6.59 (0.1) | 7 (0) |
| Speaking | 6.07 (0.14) | 6.92 (0.06) |
| Reading | 6.52 (0.12) | 6.92 (0.06) |
| Writing | 6.3 (0.13) | 6.75 (0.09) |
| Conditions | Sentence Examples | ||
|---|---|---|---|
| Subject Type | Feature | Grammaticality | |
| Agent | person | grammatical | (1) Tú, dentro de poco, actuarás en Hollywood. |
| you, within a little, act.FUT.2SG in Hollywood | |||
| ungrammatical | (2) Tú, dentro de poco, * actuaré en Hollywood. | ||
| you, within a little, act.FUT.1SG in Hollywood | |||
| “You will shortly play in Hollywood.” | |||
| number | grammatical | (3) Él/Ella dentro de poco, actuará en Hollywood. | |
| he/she, within a little, act.FUT.3SG in Hollywood | |||
| ungrammatical | (4) Él/ella, dentro de poco, actuarán en Hollywood. | ||
| he/she, within a little, act.FUT.3PL in Hollywood | |||
| “He/She will shortly play in Hollywood.” | |||
| Patient | person | grammatical | (5) Tú, lo antes posible, vendrás de visita. |
| you, the earliest possible, come.FUT.2SG of visit | |||
| ungrammatical | (6) Tú, lo antes posible, * vendré de visita. | ||
| you, the earliest possible, come.FUT.1SG of visit | |||
| “You will pay a visit as soon as possible.” | |||
| number | grammatical | (7) Él/ella, lo antes posible, vendrá de visita. | |
| he/she, the earliest possible, come.FUT.3SG of visit | |||
| ungrammatical | (8) Él/ella, lo antes posible, * vendrán de visita. | ||
| he/she, the earliest possible, come.FUT.3PL of visit | |||
| “He/she will pay a visit as soon as possible.” | |||
| Accuracy in % | Response Times in milliseconds | |||||||
|---|---|---|---|---|---|---|---|---|
| Grammatical | Ungrammatical | Grammatical | Ungrammatical | |||||
| Natives | Non-Natives | Natives | Non-Natives | Natives | Non-Natives | Natives | Non-Natives | |
| Agent person | 96.6 (1.2) | 96.5 (1.1) | 90.8 (1.3) | 81.6 (4.1) | 705.0 (58) | 730.0 (56) | 644.3 (55) | 697.9 (60) |
| Agent number | 95.3 (2.0) | 92.3 (1.7) | 91.4 (1.5) | 89.5 (2.4) | 711.4 (58) | 785.0 (55) | 576.2 (47) | 589.8 (38) |
| Patient person | 93.9 (1.6) | 92.3 (1.5) | 90.1 (0.9) | 81.2 (4.3) | 713.8 (54) | 734.5 (57) | 590.5 (46) | 703.0 (66) |
| Patient number | 95.1 (2.2) | 92.4 (1.4) | 92.7 (1.6) | 87.2 (2.6) | 718.2 (58) | 753.1 (48) | 576.1 (46) | 632.6 (44) |
| Accuracy | Response Times | |||
|---|---|---|---|---|
| F1 (1,46) | F2 (1,508) | F1 (1,46) | F2 (1,508) | |
| GROUP | 4.68 * | 69.15 *** | 0.57 | 3.98 * |
| GRAM | 16.78 *** | 131.6 *** | 19.98 *** | 201.64 *** |
| GRAM × GROUP | 2.21 | 16.94 *** | 0.19 | 0.03 |
| TYPE | 6.73 * | 3.71 a | 0.05 | 0.01 |
| TYPE × GROUP | 1.57 | 1.9 | 0.49 | 0.01 |
| FEAT | 1.69 | 7.88 *** | 1.75 | 0.84 |
| FEAT × GROUP | 0.46 | 2.34 | 0.06 | <0.01 |
| TYPE × GRAM | 2.38 | 0.95 | 0.01 | 0.59 |
| TYPE × GRAM × GROUP | 0.52 | 0.37 | 3.6 a | 3.8 a |
| GRAM × FEAT | 5.22 * | 30.89 *** | 5.81 * | 14.62 *** |
| FEAT × GRAM × GROUP | 2.53 | 2.19 | 1.24 | 1.18 |
| TYPE × GRAM × FEAT | 3.31 a | 12.28 *** | 4.72 * | 2.97 a |
| TYPE × FEAT × GRAM × GROUP | 2.75 | 2.43 | 0.09 | 0.05 |
| 300–500 ms | 600–900 ms | ||||
|---|---|---|---|---|---|
| Lateral | Midline | Lateral | Midline | ||
| df | F | F | F | F | |
| GROUP | 1,46 | 3.8 a | 2.78 | 0.04 | 0.38 |
| GRAM | 1,46 | 1.36 | 0.29 | *** 38.96 | *** 61.24 |
| GRAM × GROUP | 1,46 | 1.1 | 0.52 | 1.81 | 1.68 |
| TYPE | 1,46 | 0.5 | 0.7 | 0.13 | 0.15 |
| TYPE × GROUP | 1,46 | 1.99 | 2 | 0.06 | 0.07 |
| FEAT | 1,46 | * 6.53 | * 4.37 | 0.65 | 0.09 |
| FEAT × GROUP | 1,46 | ** 7.84 | ** 8.26 | 0.65 | 1.13 |
| TYPE × GRAM | 1,46 | 2.74 | 0.54 | * 7.21 | * 7.04 |
| TYPE × GRAM × GROUP | 1,46 | * 4.59 | 2.66 | 3.07 a | 1.9 |
| FEAT × GRAM | 1,46 | ** 7.81 | 3.28 a | 1.36 | 1.31 |
| FEAT × GRAM × GROUP | 1,46 | 3.33 a | 2.96 a | 2.2 | 1.22 |
| TYPE × FEAT × GRAM | 1,46 | 0.07 | 0.09 | <0.01 | 0.01 |
| TYPE × FEAT × GRAM × GROUP | 1,46 | 0.21 | 0.12 | 0.13 | 0.35 |
| GRAM × HEM | 1,46 | 2.63 | - | ** 7.94 | - |
| GRAM × HEM × GROUP | 1,46 | 0.34 | - | <0.01 | - |
| TYPE × GRAM × HEM | 1,46 | <0.01 | - | 0.01 | - |
| TYPE × GRAM × HEM × GROUP | 1,46 | 0.01 | - | 0.08 | - |
| FEAT × GRAM × HEM | 1,46 | ** 7.48 | - | 0.44 | - |
| FEAT × GRAM × HEM × GROUP | 1,46 | 0.09 | - | 0.11 | - |
| TYPE × FEAT × GRAM × HEM | 1,46 | 1.19 | - | 0.94 | - |
| TYPE × FEAT × GRAM × HEM × GROUP | 1,46 | 1.19 | - | <0.01 | - |
| GRAM × REG | 2,92 | 3.65 | *** 10.21 | *** 36.19 | *** 38.83 |
| GRAM × REG × GROUP | 2,92 | 0.77 | *** 9.59 | * 3.94 | 3.19 ª |
| TYPE × GRAM × REG | 2,92 | 0.71 | 0.77 | 0.26 | 1.57 |
| TYPE × GRAM × REG × GROUP | 2,92 | 0.01 | 0.25 | 0.06 | 0.22 |
| FEAT × GRAM × REG | 2,92 | 1.4 | 1.5 | * 4.31 | ** 8.66 |
| FEAT × GRAM × REG × GROUP | 2,92 | 1.42 | 0.15 | 2.05 | 0.09 |
| TYPE × FEAT × GRAM × REG | 2,92 | 0.83 | 0.59 | 0.3 | 0.07 |
| TYPE × FEAT × GRAM × REG × GROUP | 2,92 | 0.07 | 0.74 | 0.02 | 0.66 |
| GRAM × HEM × REG | 2,92 | 0.44 | - | *** 9.53 | - |
| GRAM × HEM × REG × GROUP | 2,92 | 0.15 | - | 1.47 | - |
| TYPE × GRAM × HEM × REG | 2,92 | 1.24 | - | 0.25 | - |
| TYPE × GRAM × HEM × REG × GROUP | 2,92 | 0.6 | - | 2.01 | - |
| FEAT × GRAM × HEM × REG | 2,92 | 3.23 | - | 0.04 | - |
| FEAT × GRAM × HEM × REG × GROUP | 2,92 | 1.11 | - | 0.71 | - |
| TYPE × FEAT × GRAM × HEM × REG | 2,92 | 0.12 | - | 0.25 | - |
| TYPE × FEAT × GRAM × HEM × REG × GROUP | 2,92 | 0.25 | - | 0.27 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zawiszewski, A.; Martinez de la Hidalga, G.; Laka, I. Agents Strongly Preferred: ERP Evidence from Natives and Non-Natives Processing Intransitive Sentences in Spanish. Brain Sci. 2022, 12, 853. https://doi.org/10.3390/brainsci12070853
Zawiszewski A, Martinez de la Hidalga G, Laka I. Agents Strongly Preferred: ERP Evidence from Natives and Non-Natives Processing Intransitive Sentences in Spanish. Brain Sciences. 2022; 12(7):853. https://doi.org/10.3390/brainsci12070853
Chicago/Turabian StyleZawiszewski, Adam, Gillen Martinez de la Hidalga, and Itziar Laka. 2022. "Agents Strongly Preferred: ERP Evidence from Natives and Non-Natives Processing Intransitive Sentences in Spanish" Brain Sciences 12, no. 7: 853. https://doi.org/10.3390/brainsci12070853
APA StyleZawiszewski, A., Martinez de la Hidalga, G., & Laka, I. (2022). Agents Strongly Preferred: ERP Evidence from Natives and Non-Natives Processing Intransitive Sentences in Spanish. Brain Sciences, 12(7), 853. https://doi.org/10.3390/brainsci12070853