A Parallel Feature Fusion Network Combining GRU and CNN for Motor Imagery EEG Decoding

Abstract
:1. Introduction
2. Methods
2.1. System Architecture
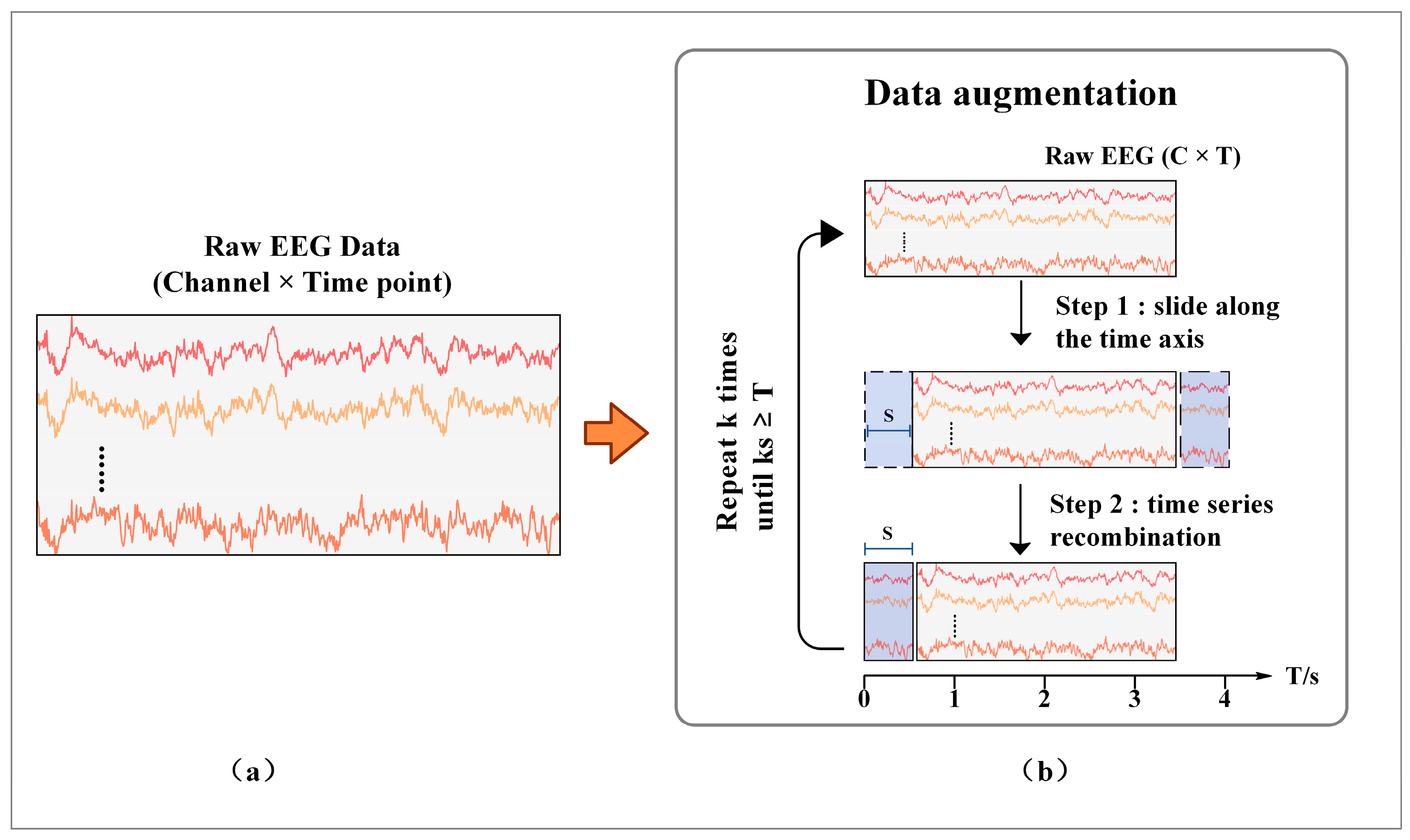
2.2. Data Augmentation Method
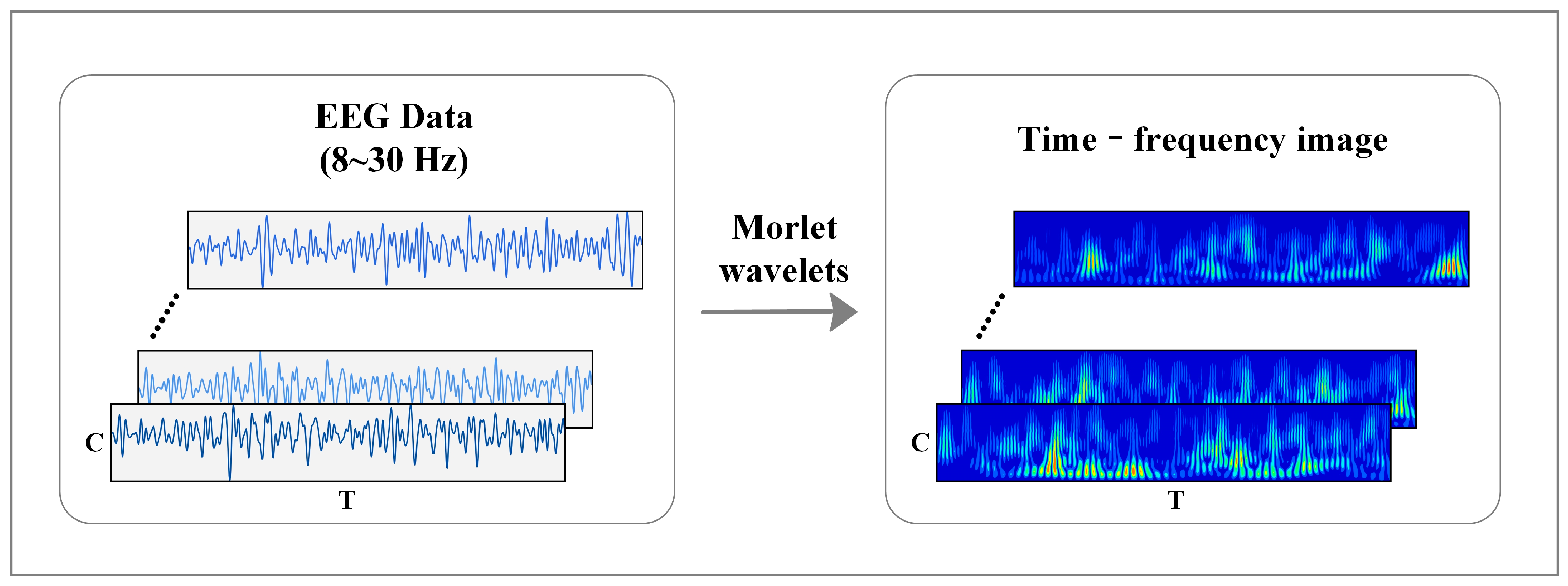
2.3. MI-EEG Feature Representation
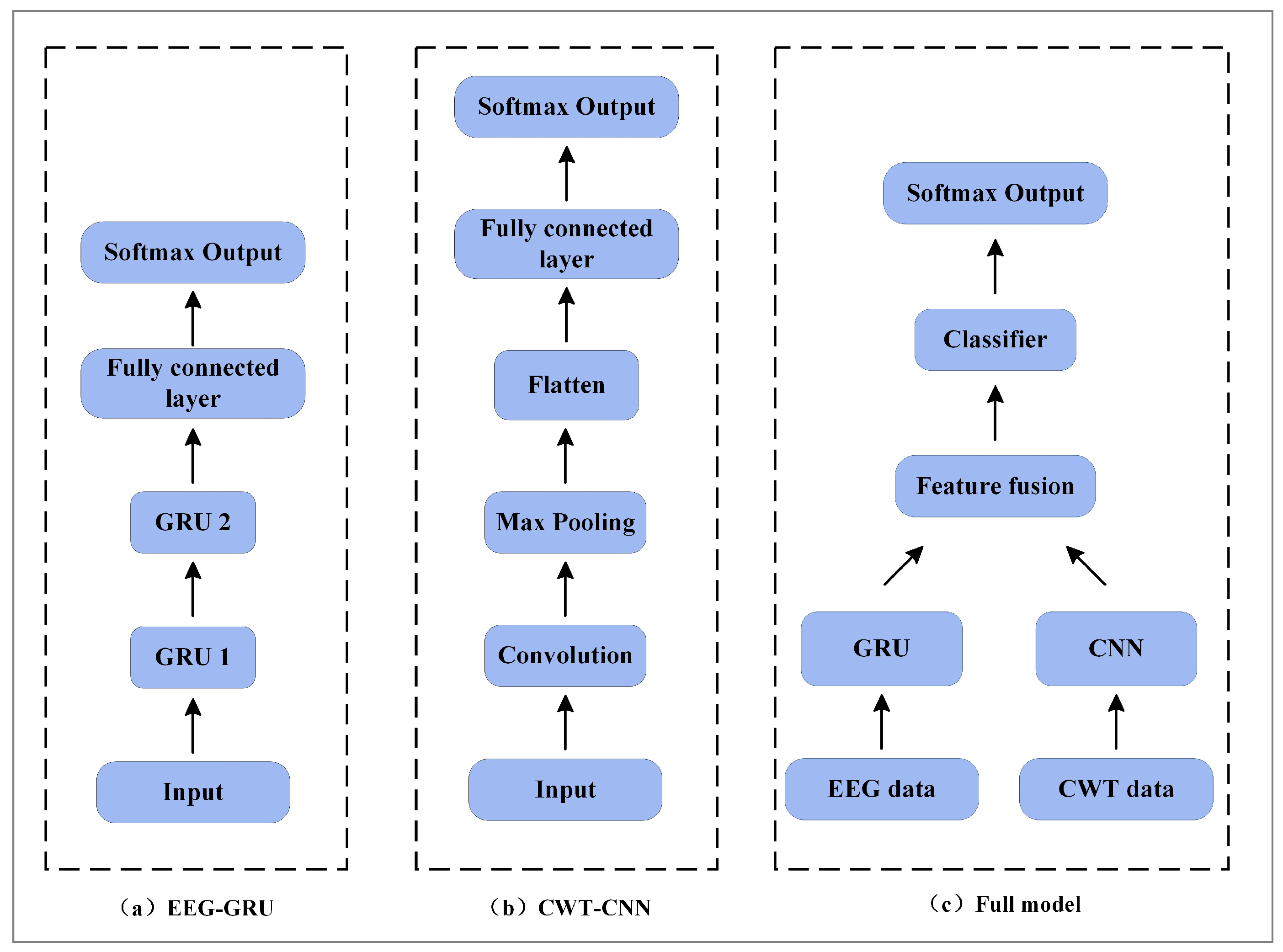
2.4. Proposed GCFN Architecture
3. Dataset and Results
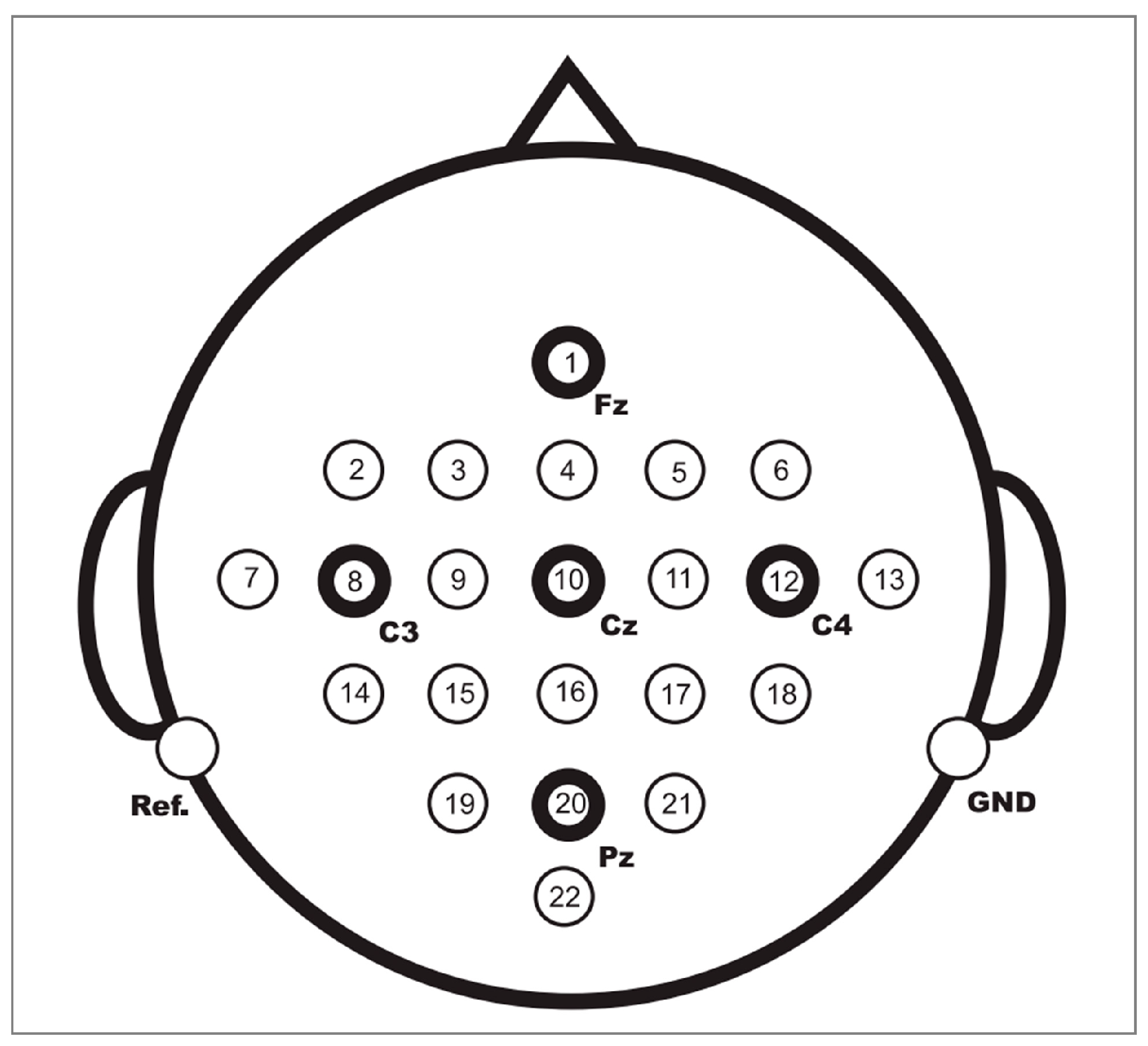
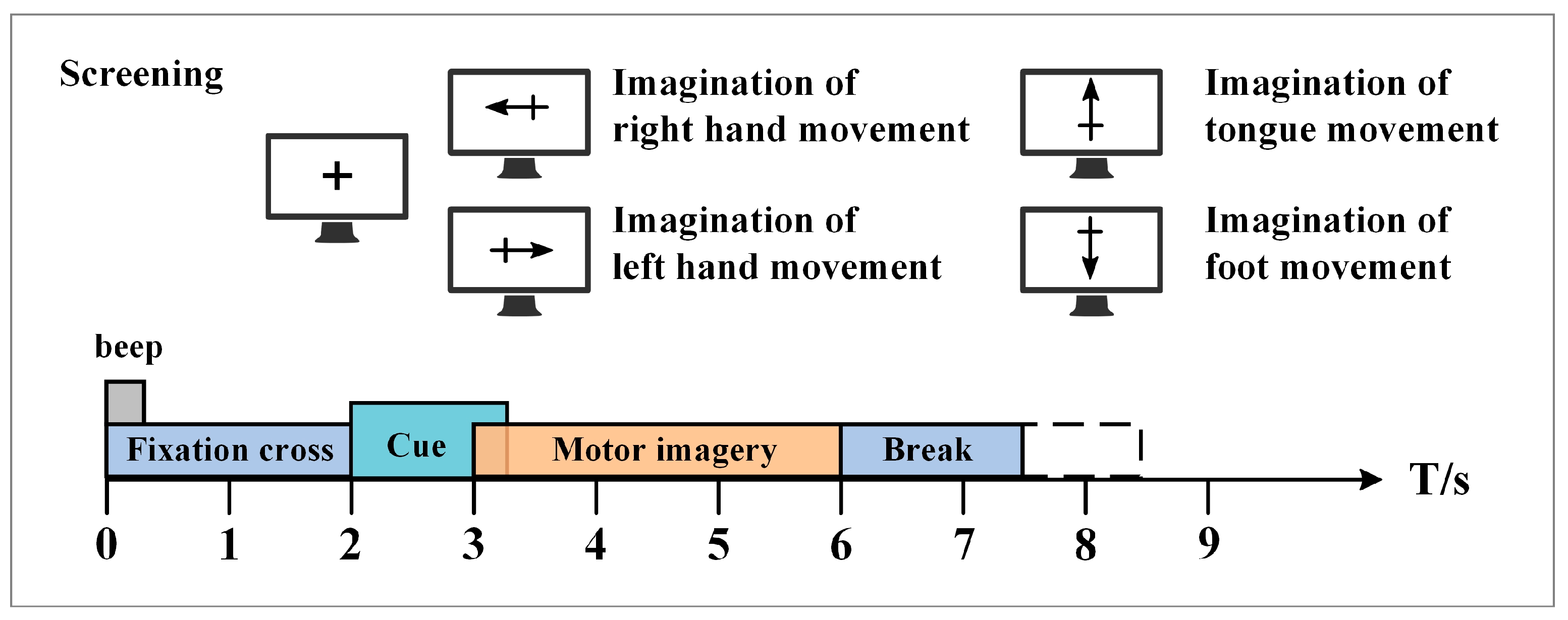
3.1. Experimental Dataset
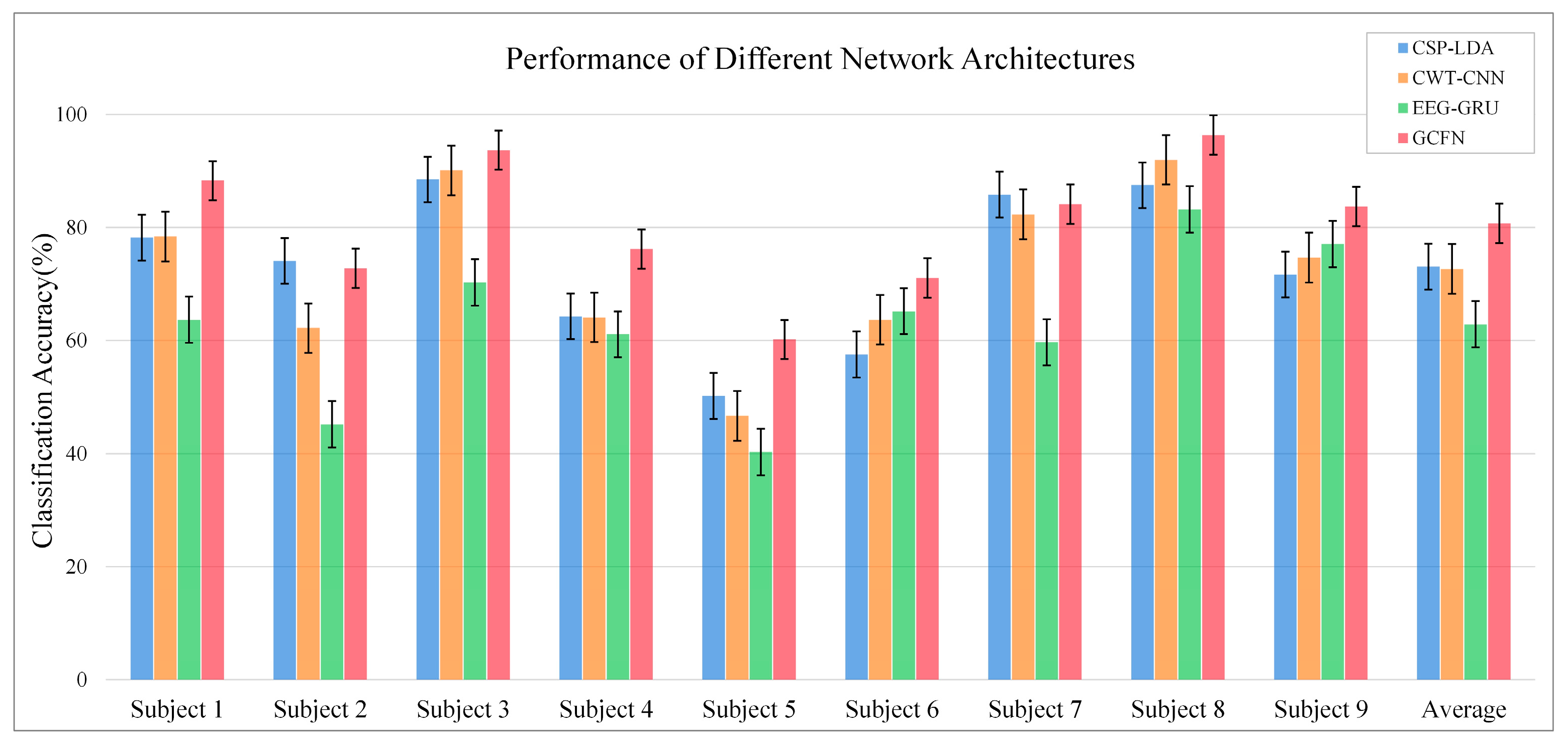
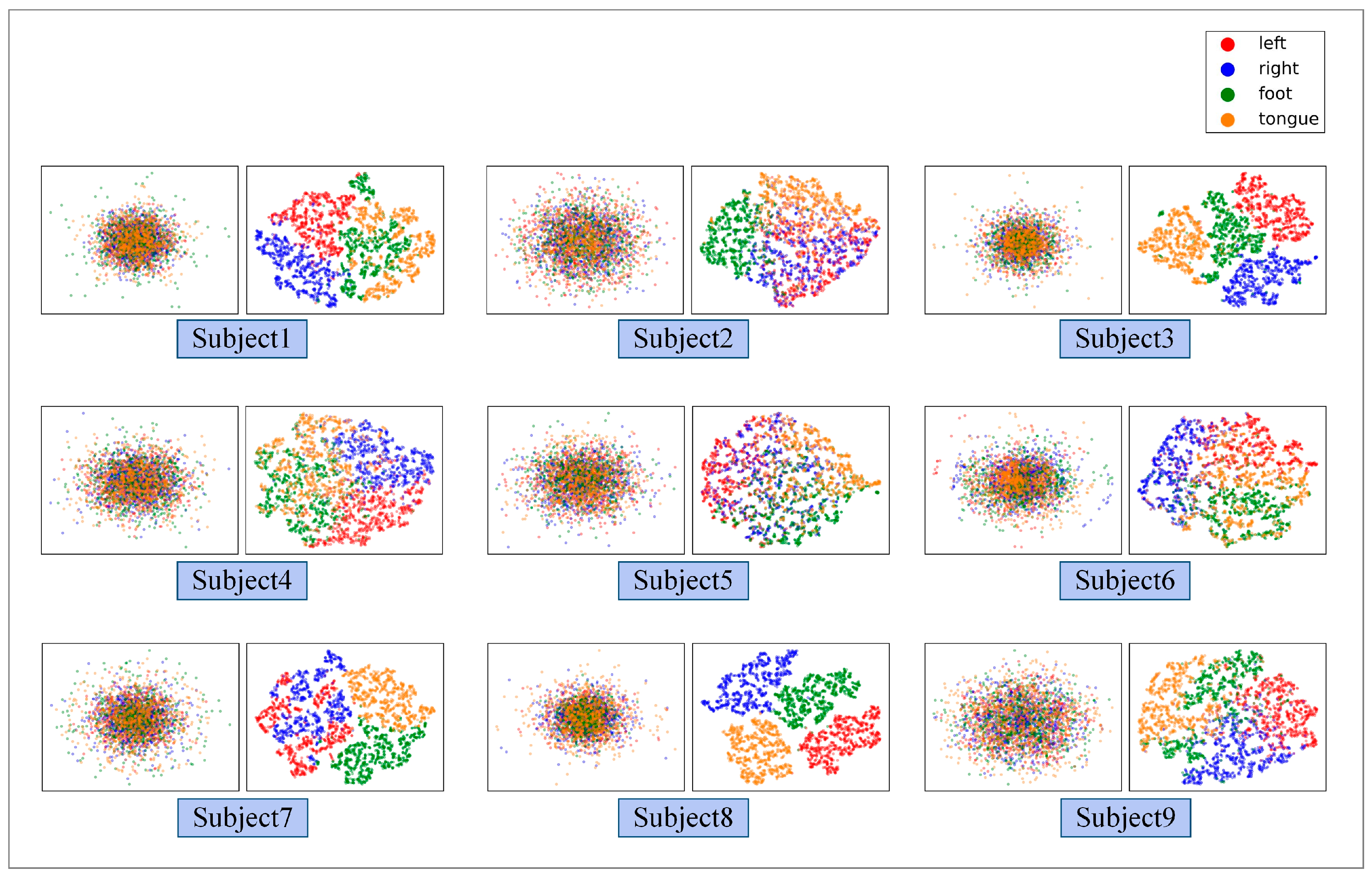
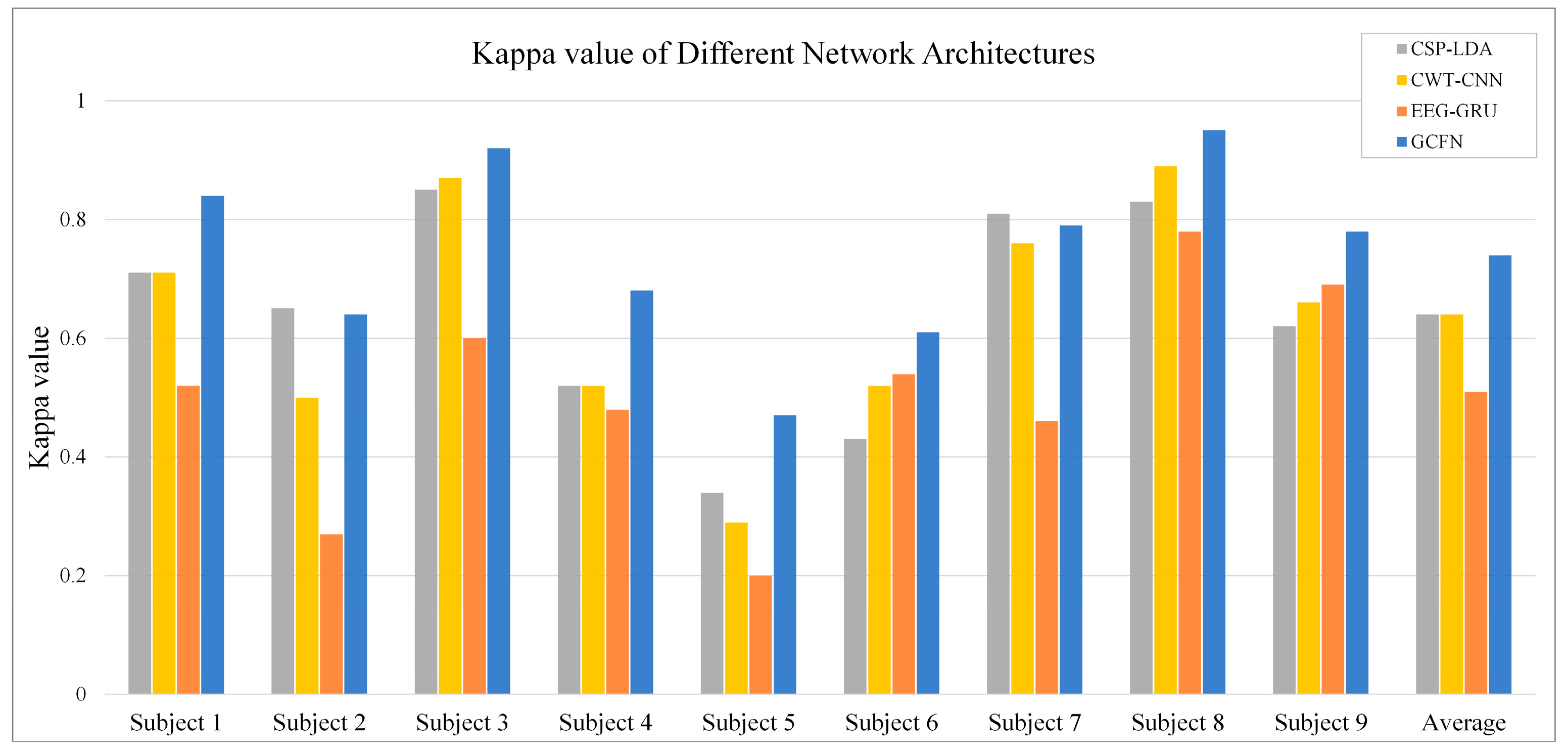
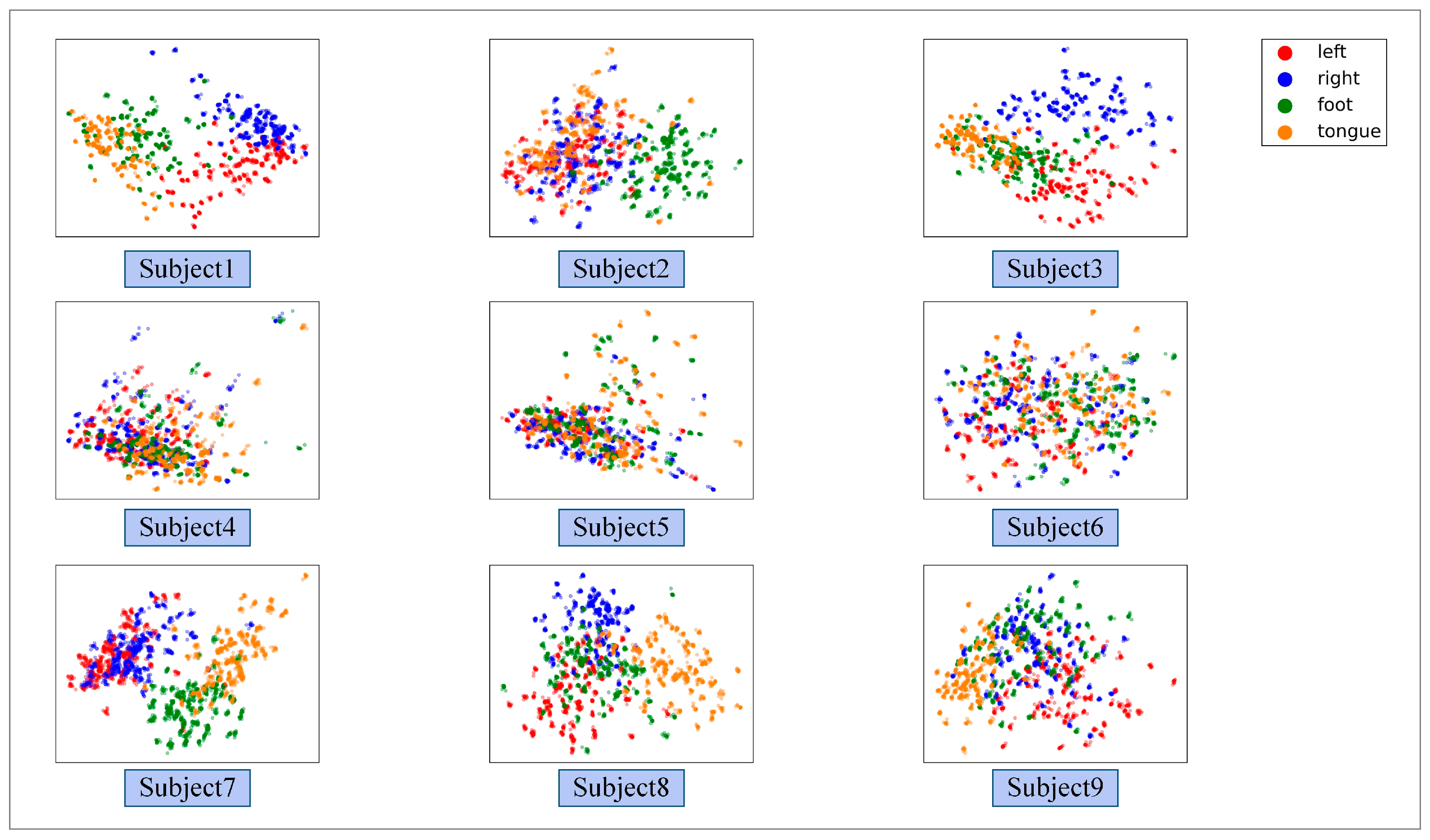
3.2. Performance of the Proposed GCFN
3.3. Comparison with Other Published Results
4. Discussion
5. Conclusions
6. Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MI | Motor Imagery |
| EEG | Electroencephalography |
| BCI | Brain-Computer Interface |
| GRU | Gated Recurrent Unit |
| CNN | Convolution Neural Network |
| SNR | Signal-to-Noise Ratio |
| SSVEP | Steady-State Visual Evoked Potential |
| ERP | Event-Related Potential |
| ERD | Event-Related Desynchronization |
| ERS | Event-Related Synchronization |
| PSD | Power Spectral Density |
| CSP | Common Spatial Pattern |
| FBSCSP | Filter Bank Common Spatial Pattern |
| CSSP | Common Spatio-Spectral Pattern |
| CSSSP | Common Sparse Spectral Spatial Pattern |
| SBCSP | Sub-Band Common Spatial Pattern |
| LDA | Linear Discriminant Analysis |
| FFT | Fast Fourier Transform |
| TSGSP | Temporally Constrained Sparse Group Spatial Pattern |
| RCSP | Regularized Common Spatial Pattern |
| SVM | Support Vector Machine |
| RBF | Radial Basis Function |
| OVR | One-Versus-Rest |
| DC | Divide-and-Conquer |
| PW | Pair-Wise |
| DL | Deep Learning |
| ML | Machine Learning |
| SAE | Stacked Autoencoder |
| TBTF-CNN | Two-Branch Time-Frequency Convolution Neural Network |
| ESI | EEG Source Imaging |
| RNN | Recurrent Neural Network |
| GCFN | GRU-CNN Feature Fusion Network |
| CWT | Continuous Wavelet Transform |
| LSTM | Long Short-Term Memory |
| FC | Fully Connected Layer |
References
- Wolpaw, J.R.; Birbaumer, N.; Heetderks, W.J.; McFarland, D.J.; Peckham, P.H.; Schalk, G.; Donchin, E.; Quatrano, L.A.; Robinson, C.J.; Vaughan, T.M. Brain-computer interface technology: A review of the first international meeting. IEEE Trans. Rehabil. Eng. 2000, 8, 164–173. [Google Scholar] [CrossRef] [PubMed]
- Lahane, P.; Jagtap, J.; Inamdar, A.; Karne, N.; Dev, R. A review of recent trends in EEG based Brain-Computer Interface. In Proceedings of the 2019 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 21–23 February 2019; pp. 1–6. [Google Scholar]
- Bonassi, G.; Biggio, M.; Bisio, A.; Ruggeri, P.; Bove, M.; Avanzino, L. Provision of somatosensory inputs during motor imagery enhances learning-induced plasticity in human motor cortex. Sci. Rep. 2017, 7, 9300. [Google Scholar] [CrossRef] [PubMed]
- McFarland, D.J.; Miner, L.A.; Vaughan, T.M.; Wolpaw, J.R. Mu and beta rhythm topographies during motor imagery and actual movements. Brain Topogr. 2000, 12, 177–186. [Google Scholar] [CrossRef]
- Tsui, C.S.L.; Gan, J.Q.; Hu, H.S. A Self-Paced Motor Imagery Based Brain-Computer Interface for Robotic Wheelchair Control. Clin. EEG Neurosci. 2011, 42, 225–229. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Guan, C.; Phua, K.S.; Wang, C.; Teh, I.; Chen, C.W.; Chew, E. Transcranial direct current stimulation and EEG-based motor imagery BCI for upper limb stroke rehabilitation. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 4128–4131. [Google Scholar]
- He, Y.; Eguren, D.; Azorín, J.M.; Grossman, R.G.; Luu, T.P.; Contreras-Vidal, J.L. Brain–machine interfaces for controlling lower-limb powered robotic systems. J. Neural Eng. 2018, 15, 021004. [Google Scholar] [CrossRef] [PubMed]
- Bhagat, N.A.; Venkatakrishnan, A.; Abibullaev, B.; Artz, E.J.; Yozbatiran, N.; Blank, A.A.; French, J.; Karmonik, C.; Grossman, R.G.; O’Malley, M.K.; et al. Design and Optimization of an EEG-Based Brain Machine Interface (BMI) to an Upper-Limb Exoskeleton for Stroke Survivors. Front. Neurosci. 2016, 10, 122. [Google Scholar] [CrossRef]
- Yang, L.; Ma, R.; Zhang, H.M.; Guan, W.; Jiang, S. Driving behavior recognition using EEG data from a simulated car-following experiment. Accid. Anal. Prev. 2018, 116, 30–40. [Google Scholar] [CrossRef]
- Meng, J.; Zhang, S.; Bekyo, A.; Olsoe, J.; Baxter, B.; He, B. Noninvasive Electroencephalogram Based Control of a Robotic Arm for Reach and Grasp Tasks. Sci. Rep. 2016, 6, 38565. [Google Scholar] [CrossRef]
- Nicolas-Alonso, L.F.; Gomez-Gil, J. Brain Computer Interfaces, a Review. Sensors 2012, 12, 1211. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef]
- Müller-Gerking, J.; Pfurtscheller, G.; Flyvbjerg, H. Designing optimal spatial filters for single-trial EEG classification in a movement task. Clin. Neurophysiol. 1999, 110, 787–798. [Google Scholar] [CrossRef]
- Kai Keng, A.; Zheng Yang, C.; Haihong, Z.; Cuntai, G. Filter Bank Common Spatial Pattern (FBCSP) in Brain-Computer Interface. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 200; pp. 2390–2397.
- Lemm, S.; Blankertz, B.; Curio, G.; Muller, K. Spatio-spectral filters for improving the classification of single trial EEG. IEEE Trans. Biomed. Eng. 2005, 52, 1541–1548. [Google Scholar] [CrossRef]
- Dornhege, G.; Blankertz, B.; Krauledat, M.; Losch, F.; Curio, G.; Muller, K. Combined Optimization of Spatial and Temporal Filters for Improving Brain-Computer Interfacing. IEEE Trans. Biomed. Eng. 2006, 53, 2274–2281. [Google Scholar] [CrossRef]
- Novi, Q.; Guan, C.; Dat, T.H.; Xue, P. Sub-band Common Spatial Pattern (SBCSP) for Brain-Computer Interface. In Proceedings of the 2007 3rd International IEEE/EMBS Conference on Neural Engineering, Kohala Coast, HI, USA, 2–5 May 2007; pp. 204–207. [Google Scholar]
- Gaur, P.; Gupta, H.; Chowdhury, A.; McCreadie, K.; Pachori, R.B.; Wang, H. A Sliding Window Common Spatial Pattern for Enhancing Motor Imagery Classification in EEG-BCI. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Ko, L.W.; Lu, Y.C.; Bustince, H.; Chang, Y.C.; Chang, Y.; Ferandez, J.; Wang, Y.K.; Sanz, J.A.; Dimuro, G.P.; Lin, C.T. Multimodal Fuzzy Fusion for Enhancing the Motor-Imagery-Based Brain Computer Interface. IEEE Comput. Intell. Mag. 2019, 14, 96–106. [Google Scholar] [CrossRef]
- Zhang, Y.; Nam, C.S.; Zhou, G.; Jin, J.; Wang, X.; Cichocki, A. Temporally Constrained Sparse Group Spatial Patterns for Motor Imagery BCI. IEEE Trans. Cybern. 2019, 49, 3322–3332. [Google Scholar] [CrossRef]
- Jin, J.; Miao, Y.; Daly, I.; Zuo, C.; Hu, D.; Cichocki, A. Correlation-based channel selection and regularized feature optimization for MI-based BCI. Neural Netw. 2019, 118, 262–270. [Google Scholar] [CrossRef]
- Ang, K.K.; Chin, Z.Y.; Wang, C.; Guan, C.; Zhang, H. Filter Bank Common Spatial Pattern Algorithm on BCI Competition IV Datasets 2a and 2b. Front. Neurosci. 2012, 6, 39. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Sheng, Q.Z.; Kanhere, S.S.; Gu, T.; Zhang, D. Converting Your Thoughts to Texts: Enabling Brain Typing via Deep Feature Learning of EEG Signals. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), Athens, Greece, 19–23 March 2018; pp. 1–10. [Google Scholar]
- Tabar, Y.R.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2016, 14, 016003. [Google Scholar] [CrossRef]
- Dai, G.; Zhou, J.; Huang, J.; Wang, N. HS-CNN: A CNN with hybrid convolution scale for EEG motor imagery classification. J. Neural Eng. 2020, 17, 016025. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Yang, D. A Densely Connected Multi-Branch 3D Convolutional Neural Network for Motor Imagery EEG Decoding. Brain Sci. 2021, 11, 197. [Google Scholar] [CrossRef]
- Yang, J.; Gao, S.; Shen, T. A Two-Branch CNN Fusing Temporal and Frequency Features for Motor Imagery EEG Decoding. Entropy 2022, 24, 376. [Google Scholar] [CrossRef] [PubMed]
- Hou, Y.; Zhou, L.; Jia, S.; Lun, X. A novel approach of decoding EEG four-class motor imagery tasks via scout ESI and CNN. J. Neural Eng. 2020, 17, 016048. [Google Scholar] [CrossRef] [PubMed]
- Qiao, W.; Bi, X. Deep Spatial-Temporal Neural Network for Classification of EEG-Based Motor Imagery. In Proceedings of the the 2019 International Conference, Wuhan, China, 12–13 July 2019. [Google Scholar]
- Li, E.Z.; Xia, J.S.; Du, P.J.; Lin, C.; Samat, A. Integrating Multilayer Features of Convolutional Neural Networks for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Zhang, C.Y.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding Deep Learning (Still) Requires Rethinking Generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Xu, M.; Yao, J.; Zhang, Z.; Li, R.; Yang, B.; Li, C.; Li, J.; Zhang, J. Learning EEG topographical representation for classification via convolutional neural network. Pattern Recognit. 2020, 105, 107390. [Google Scholar] [CrossRef]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2021, 1–42. [Google Scholar] [CrossRef]
- Brunner, C.; Leeb, R.; Muller-Putz, G.R.; Schlogl, A. BCI competition 2008—Graz data set A 6. Graz Univ. Technol. 2008, 16, 1–6. [Google Scholar]
- Townsend, G.; Graimann, B.; Pfurtscheller, G. A comparison of common spatial patterns with complex band power features in a four-class BCI experiment. IEEE Trans. Biomed. Eng. 2006, 53, 642–651. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Yu, Z.L.; Lu, H.; Gu, Z.; Li, Y. Motor Imagery Classification Based on Bilinear Sub-Manifold Learning of Symmetric Positive-Definite Matrices. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 504–516. [Google Scholar] [CrossRef] [PubMed]
- Mahamune, R.; Laskar, S.H. Classification of the four-class motor imagery signals using continuous wavelet transform filter bank-based two-dimensional images. Int. J. Imaging Syst. Technol. 2021, 31, 2237–2248. [Google Scholar] [CrossRef]
- Sakhavi, S.; Guan, C.; Yan, S. Learning Temporal Information for Brain-Computer Interface Using Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5619–5629. [Google Scholar] [CrossRef]
- Sadiq, M.T.; Yu, X.J.; Yuan, Z.H. Exploiting dimensionality reduction and neural network techniques for the development of expert brain-computer interfaces. Expert Syst. Appl. 2021, 164, 114031. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type (EEG/Image) | Units | Kernel Size | Stride | Output | Parameters | |
|---|---|---|---|---|---|---|
| CNN | Input | 224 × 93 × 1 | ||||
| Conv2D | 64 | 224 × 1 | 1 × 1 | 1 × 93 × 64 | 14,400 | |
| ReLU | ||||||
| Max-pooling | 1 × 3 | 1 × 3 | 1 × 31 × 64 | |||
| Flatten layer | 1984 | |||||
| GRU | Input | 875 × 22 | ||||
| GRU1 | 25 | 875 × 25 | 3675 | |||
| Tanh | ||||||
| GRU2 | 50 | 50 | 11,550 | |||
| Tanh | ||||||
| Fusion | Concatenation | 2034 | ||||
| Classifier | FC layer | 128 | 260,480 | |||
| ReLU | ||||||
| Dropout layer | p = 0.3 | |||||
| FC layer | 4 | 516 | ||||
| Softmax |
| Data Type | Channels | Format | Trials | Rate (Hz) |
|---|---|---|---|---|
| No augmentation | 22 | 22 × 875 | 576 | 250 |
| Augmentation | 22 | 22 × 875 | 6336 | 250 |
| CSP-LDA (Baseline) | Ang et al. * [22] | Xie et al. [39] | Mahamune et al. [40] | Sakhavi et al. [41] | Qiao et al. [30] | Our Method | |
|---|---|---|---|---|---|---|---|
| Dataset | 2a (DA) | 2a | 2a | 2a | 2a | 2a | 2a (DA) |
| S1 | 78.2 | 76.0 | 81.8 | 87.1 | 87.5 | 89.1 | 88.3 |
| S2 | 74.1 | 56.5 | 62.5 | 56.2 | 65.3 | 69.2 | 72.8 |
| S3 | 88.5 | 81.3 | 88.8 | 93.0 | 90.3 | 89.5 | 93.7 |
| S4 | 64.3 | 61.0 | 63.7 | 68.7 | 66.7 | 71.6 | 76.2 |
| S5 | 50.2 | 55.0 | 62.9 | 39.8 | 62.5 | 64.1 | 60.2 |
| S6 | 57.5 | 42.3 | 58.5 | 52.0 | 45.5 | 50.7 | 71.1 |
| S7 | 85.8 | 82.8 | 86.6 | 89.9 | 89.8 | 89.2 | 84.1 |
| S8 | 87.5 | 81.3 | 85.1 | 72.1 | 83.3 | 84.1 | 96.4 |
| S9 | 71.7 | 70.8 | 90.0 | 82.6 | 79.5 | 82.1 | 83.7 |
| AVG | 73.1 | 67.8 | 75.5 | 71.2 | 74.5 | 76.6 | 80.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, S.; Yang, J.; Shen, T.; Jiang, W. A Parallel Feature Fusion Network Combining GRU and CNN for Motor Imagery EEG Decoding. Brain Sci. 2022, 12, 1233. https://doi.org/10.3390/brainsci12091233
Gao S, Yang J, Shen T, Jiang W. A Parallel Feature Fusion Network Combining GRU and CNN for Motor Imagery EEG Decoding. Brain Sciences. 2022; 12(9):1233. https://doi.org/10.3390/brainsci12091233
Chicago/Turabian StyleGao, Siheng, Jun Yang, Tao Shen, and Wen Jiang. 2022. "A Parallel Feature Fusion Network Combining GRU and CNN for Motor Imagery EEG Decoding" Brain Sciences 12, no. 9: 1233. https://doi.org/10.3390/brainsci12091233