
Constrain Bias Addition to Train Low-Latency Spiking Neural Networks

Abstract
:1. Introduction
2. Materials and Methods
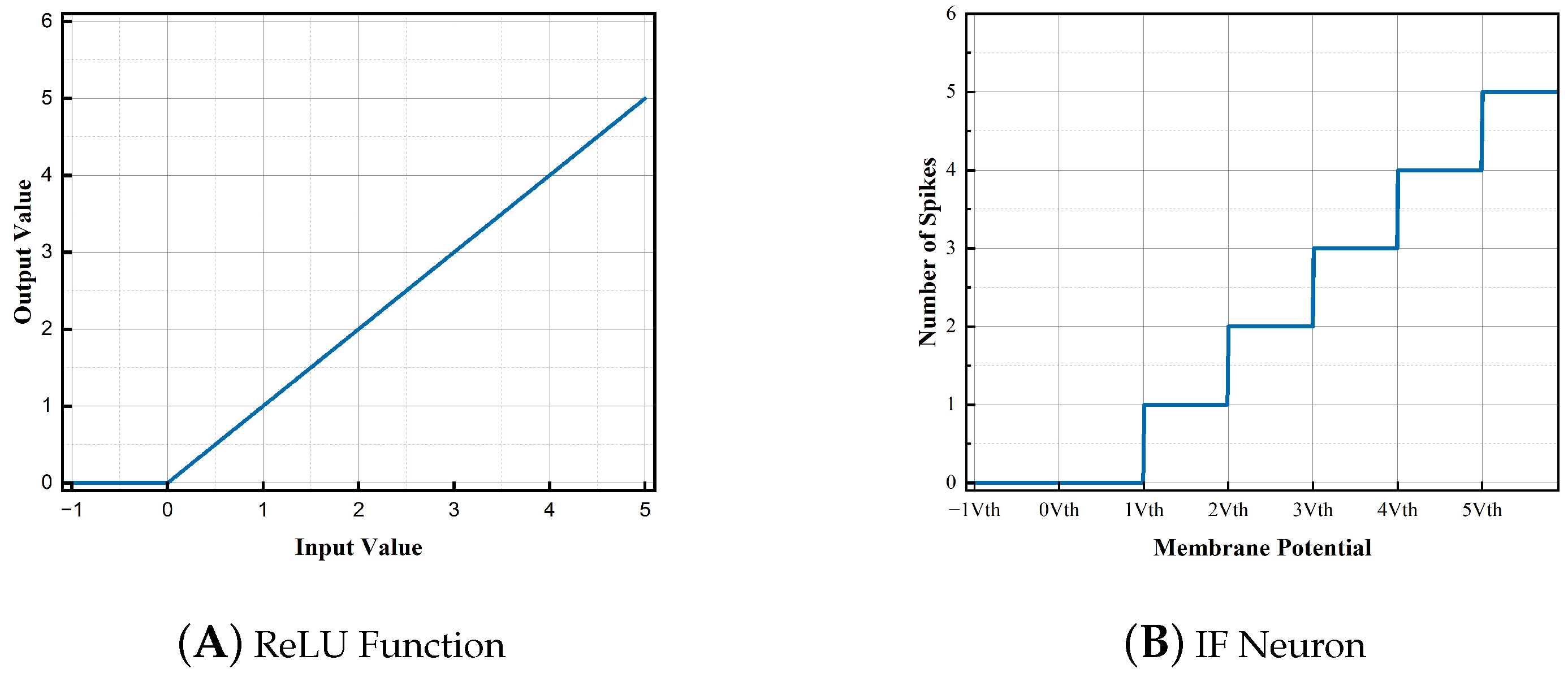
2.1. Spiking Neuron Model
2.2. Spike Encoding Method
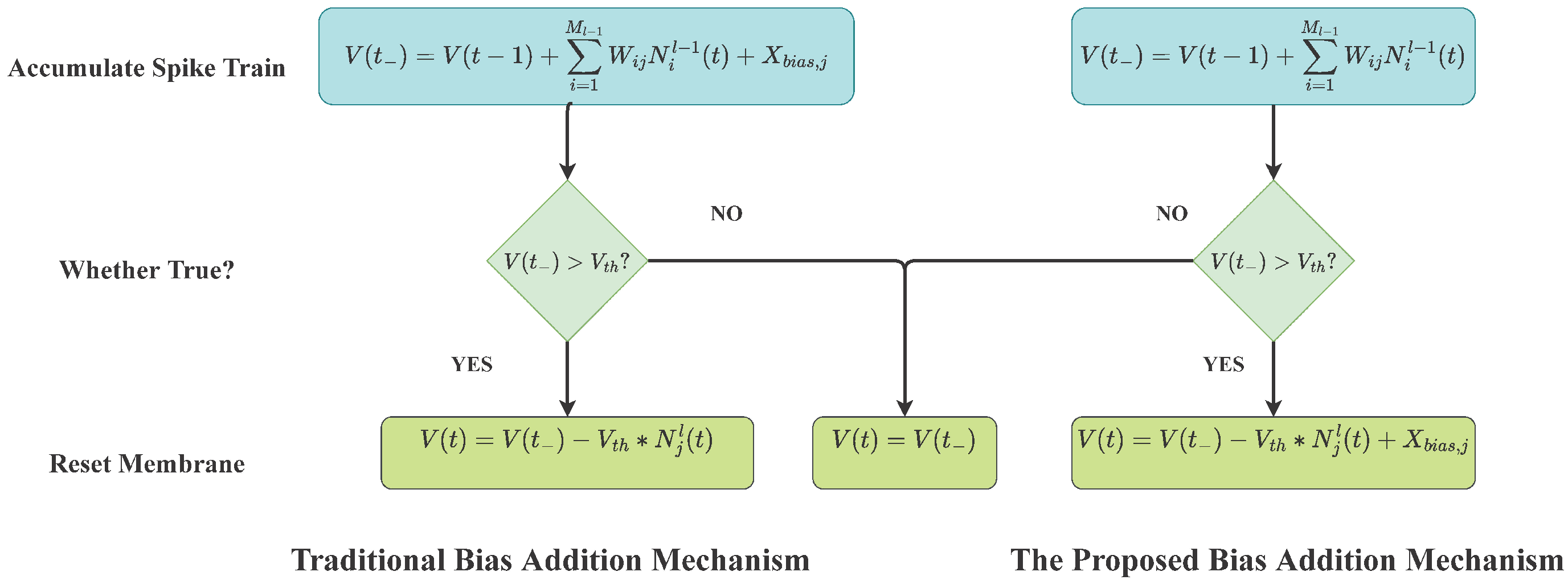
2.3. Supervised Training of Deep Spiking Neural Network
2.3.1. Spiking Neuron Gradient Estimation
2.3.2. Spike-Based Backpropagation Algorithm
| Algorithm 1: Training process of the proposed SNN model and SDE method. |
Input: Network input , , ; sample label Y; time windows T;
|
3. Results
3.1. Experimental Setup
3.1.1. Experimental Environment
3.1.2. Datasets
3.1.3. Experimental Chapter Arrangement
3.2. Environmental Sound Classification
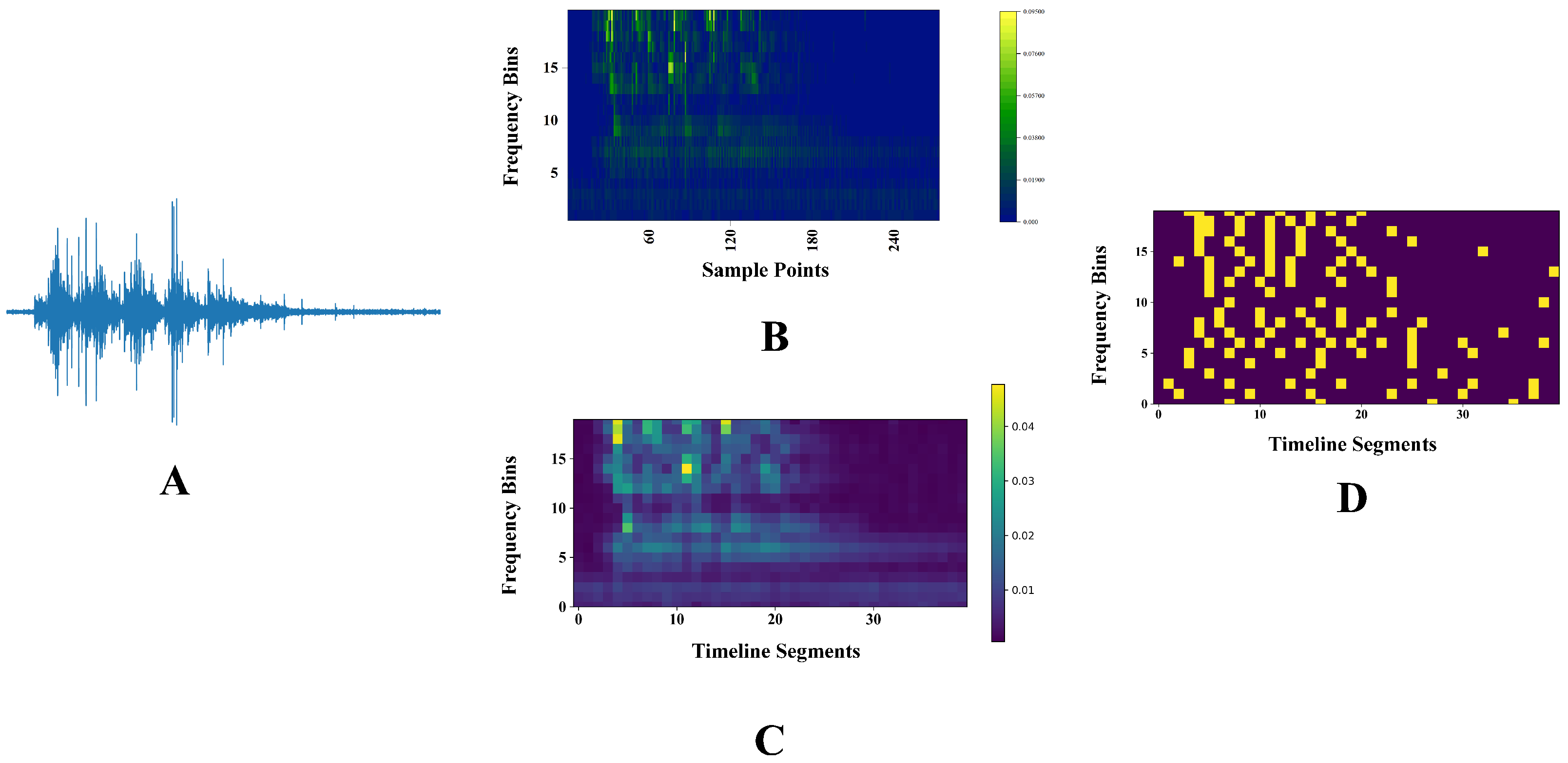
3.2.1. Constant-Q Transform
3.2.2. Network Structure and Parameter Setting
3.2.3. Classification Performance
3.3. Image Classification
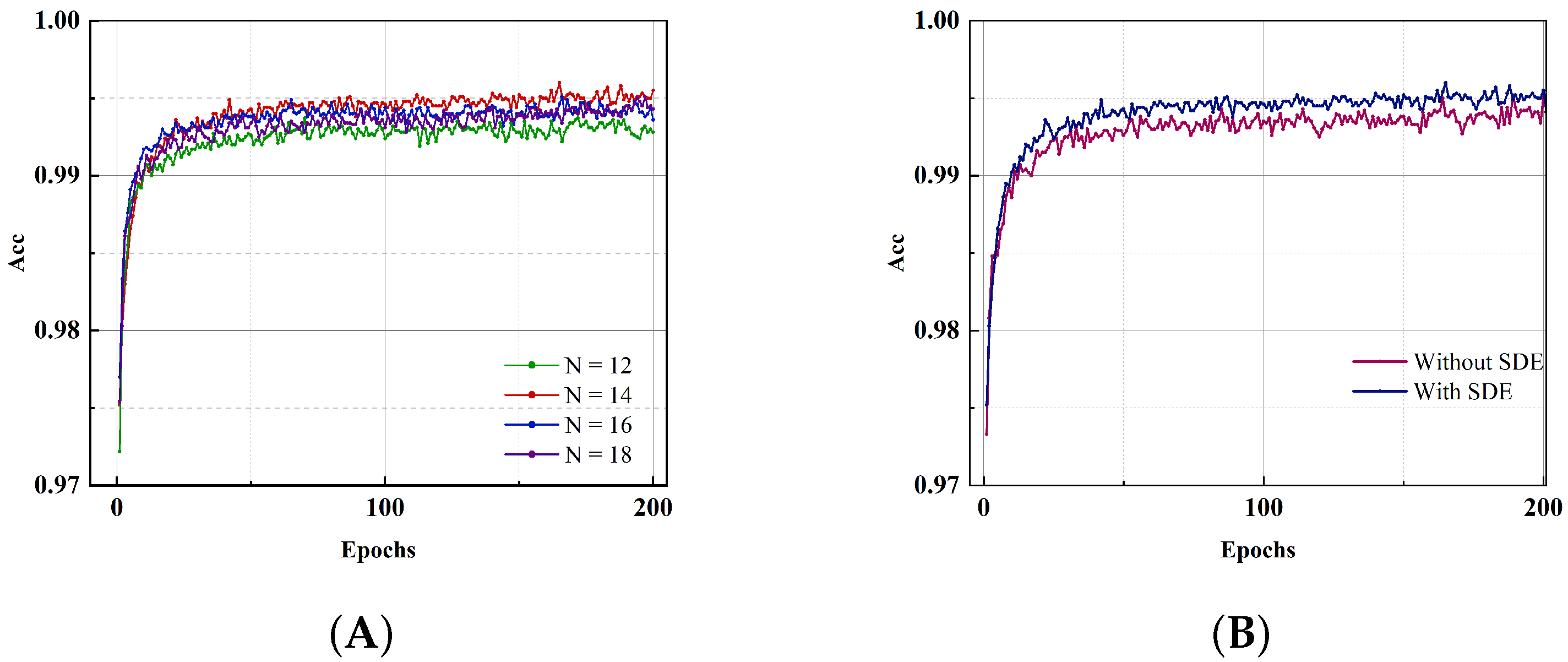
3.3.1. Network Structure and Parameter Settings
3.3.2. MNIST Dataset
3.3.3. Fashion-MNIST Dataset
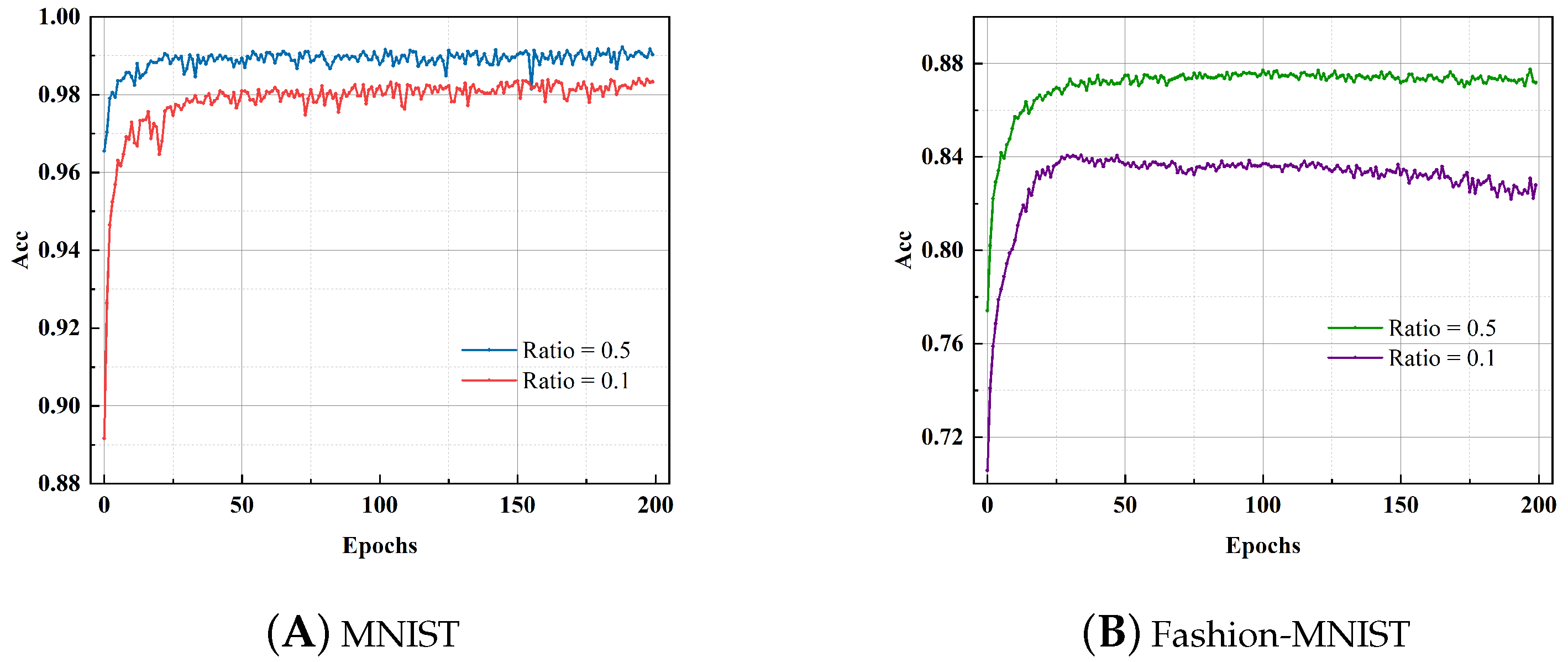
3.4. Training with Less Data
3.5. Algorithm Efficiency
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ponulak, F.; Kasinski, A. Introduction to spiking neural networks: Information processing, learning and applications. Acta Neurobiol. Exp. 2011, 71, 409–433. [Google Scholar]
- Yan, Y.; Chu, H.; Jin, Y.; Huan, Y.; Zou, Z.; Zheng, L. Backpropagation With Sparsity Regularization for Spiking Neural Network Learning. Front. Neurosci. 2022, 16, 760298. [Google Scholar] [CrossRef] [PubMed]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The spinnaker project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.J.; et al. Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Naud, R.; Sprekeler, H. Sparse bursts optimize information transmission in a multiplexed neural code. Proc. Natl. Acad. Sci. USA 2018, 115, E6329–E6338. [Google Scholar] [CrossRef] [PubMed]
- Zang, Y.; Hong, S.; De Schutter, E. Firing rate-dependent phase responses of Purkinje cells support transient oscillations. Elife 2020, 9, e60692. [Google Scholar] [CrossRef]
- Zang, Y.; De Schutter, E. The cellular electrophysiological properties underlying multiplexed coding in Purkinje cells. J. Neurosci. 2021, 41, 1850–1863. [Google Scholar] [CrossRef]
- Han, B.; Roy, K. Deep spiking neural network: Energy efficiency through time based coding. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 388–404. [Google Scholar]
- Kiselev, M. Rate coding vs. temporal coding-is optimum between? In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1355–1359. [Google Scholar]
- Sharma, V.; Srinivasan, D. A spiking neural network based on temporal encoding for electricity price time series forecasting in deregulated markets. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Pan, Z.; Zhang, M.; Wu, J.; Li, H. Multi-tones’ phase coding (mtpc) of interaural time difference by spiking neural network. arXiv 2020, arXiv:2007.03274. [Google Scholar]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Xie, Y.; Shi, L. Direct training for spiking neural networks: Faster, larger, better. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 8–12 October 2019; Volume 33, pp. 1311–1318. [Google Scholar]
- Froemke, R.C.; Debanne, D.; Bi, G.Q. Temporal modulation of spike-timing-dependent plasticity. Front. Synaptic Neurosci. 2010, 2, 19. [Google Scholar] [CrossRef]
- Gütig, R.; Sompolinsky, H. The tempotron: A neuron that learns spike timing–based decisions. Nat. Neurosci. 2006, 9, 420–428. [Google Scholar] [CrossRef] [PubMed]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking deep convolutional neural networks for energy-efficient object recognition. Int. J. Comput. Vis. 2015, 113, 54–66. [Google Scholar] [CrossRef]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International joint conference on neural networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Rueckauer, B.; Lungu, I.A.; Hu, Y.; Pfeiffer, M.; Liu, S.C. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Tang, H.; Pan, G. Spiking Deep Residual Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Park, S.; Na, B.; Yoon, S. Spiking-yolo: Spiking neural network for energy-efficient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11270–11277. [Google Scholar]
- Gerstner, W.; Kistler, W.M.; Naud, R.; Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Zang, Y.; Dieudonné, S.; De Schutter, E. Voltage-and branch-specific climbing fiber responses in Purkinje cells. Cell Rep. 2018, 24, 1536–1549. [Google Scholar] [CrossRef]
- Mun, S.; Fowler, J.E. DPCM for quantized block-based compressed sensing of images. In Proceedings of the 2012 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 1424–1428. [Google Scholar]
- Adsumilli, C.B.; Mitra, S.K. Error concealment in video communications using DPCM bit stream embedding. In Proceedings of the Proceedings (ICASSP’05), IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 18–23 March 2005; Volume 2, p. ii-169. [Google Scholar]
- Yoon, Y.C. Lif and simplified srm neurons encode signals into spikes via a form of asynchronous pulse sigma—Delta modulation. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1192–1205. [Google Scholar] [CrossRef]
- O’Connor, P.; Gavves, E.; Welling, M. Training a spiking neural network with equilibrium propagation. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; pp. 1516–1523. [Google Scholar]
- O’Connor, P.; Gavves, E.; Welling, M. Temporally efficient deep learning with spikes. arXiv 2017, arXiv:1706.04159. [Google Scholar]
- Yousefzadeh, A.; Hosseini, S.; Holanda, P.; Leroux, S.; Werner, T.; Serrano-Gotarredona, T.; Barranco, B.L.; Dhoedt, B.; Simoens, P. Conversion of synchronous artificial neural network to asynchronous spiking neural network using sigma-delta quantization. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18–20 March 2019; pp. 81–85. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Lee, C.; Sarwar, S.S.; Panda, P.; Srinivasan, G.; Roy, K. Enabling spike-based backpropagation for training deep neural network architectures. Front. Neurosci. 2020, 14, 119. [Google Scholar] [CrossRef] [PubMed]
- Fang, W.; Chen, Y.; Ding, J.; Chen, D.; Yu, Z.; Zhou, H.; Masquelier, T.; Tian, Y.; Ismail, K.H.; Yolk, A.; et al. SpikingJelly. 2020. Available online: https://github.com/fangwei123456/spikingjelly (accessed on 10 November 2022).
- Nakamura, S.; Hiyane, K.; Asano, F.; Nishiura, T.; Yamada, T. Acoustical sound database in real environments for sound scene understanding and hands-free speech recognition. In Proceedings of the 2nd International Conference on Language Resources and Evaluation, Athens, Greece, 31 May–2 June 2000. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Schörkhuber, C.; Klapuri, A. Constant-Q transform toolbox for music processing. In Proceedings of the 7th Sound and Music Computing Conference, Barcelona, Spain, 21–24 July 2010; pp. 3–64. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference; Citeseer: University Park, PA, USA, 2015; Volume 8, pp. 18–25. [Google Scholar]
- Wu, J.; Chua, Y.; Zhang, M.; Li, H.; Tan, K.C. A spiking neural network framework for robust sound classification. Front. Neurosci. 2018, 12, 836. [Google Scholar] [CrossRef] [PubMed]
- Yu, Q.; Yao, Y.; Wang, L.; Tang, H.; Dang, J. A multi-spike approach for robust sound recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 890–894. [Google Scholar]
- Dennis, J.; Yu, Q.; Tang, H.; Tran, H.D.; Li, H. Temporal coding of local spectrogram features for robust sound recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 803–807. [Google Scholar]
- Peterson, D.G.; Nawarathne, T.; Leung, H. Modulating STDP With Back-Propagated Error Signals to Train SNNs for Audio Classification. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 89–101. [Google Scholar] [CrossRef]
- Yu, Q.; Yao, Y.; Wang, L.; Tang, H.; Dang, J.; Tan, K.C. Robust environmental sound recognition with sparse key-point encoding and efficient multispike learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 625–638. [Google Scholar] [CrossRef]
- Jin, Y.; Zhang, W.; Li, P. Hybrid macro/micro level backpropagation for training deep spiking neural networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Zhang, W.; Li, P. Spike-train level backpropagation for training deep recurrent spiking neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 7800–7811. [Google Scholar]
- Wu, H.; Zhang, Y.; Weng, W.; Zhang, Y.; Xiong, Z.; Zha, Z.J.; Sun, X.; Wu, F. Training spiking neural networks with accumulated spiking flow. In Proceedings of the AAAI conference on artificial intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 10320–10328. [Google Scholar]
- Tang, J.; Lai, J.H.; Zheng, W.S.; Yang, L.; Xie, X. Relaxation LIF: A gradient-based spiking neuron for direct training deep spiking neural networks. Neurocomputing 2022, 501, 499–513. [Google Scholar] [CrossRef]
- Zhao, D.; Zeng, Y.; Zhang, T.; Shi, M.; Zhao, F. GLSNN: A multi-layer spiking neural network based on global feedback alignment and local STDP plasticity. Front. Comput. Neurosci. 2020, 14, 576841. [Google Scholar] [CrossRef]
- Cheng, X.; Hao, Y.; Xu, J.; Xu, B. LISNN: Improving spiking neural networks with lateral interactions for robust object recognition. In Proceedings of the IJCAI, Yokohama, Japan, 11–17 July 2020; pp. 1519–1525. [Google Scholar]
- Mirsadeghi, M.; Shalchian, M.; Kheradpisheh, S.R.; Masquelier, T. Spike time displacement based error backpropagation in convolutional spiking neural networks. arXiv 2021, arXiv:2108.13621. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Parameter | Description | Value |
|---|---|---|
| T | Simlulation time | 20 |
| Threshold of spiking neurons | 3.0 | |
| b | bias voltage | 1.0 |
| The number of filters using in CQT | 20 | |
| The Number of Timeline segments | 40 | |
| Learning rate | 8 × 10 |
| Linear | Sine | ||||
|---|---|---|---|---|---|
| Time Window | Clean | Average | Time Window | Clean | Average |
| N = 12 | 99.83% | 66.46% | N = 12 | 99.53% | 71.49% |
| N = 14 | 99.73% | 67.23% | N = 14 | 99.53% | 71.38% |
| N = 16 | 99.63% | 66.73% | N = 16 | 99.68% | 70.53% |
| N = 18 | 99.80% | 66.12% | N = 18 | 99.38% | 69.27% |
| N = 20 | 99.85% | 66.42% | N = 20 | 99.65% | 69.11% |
| Methods | Accuracy | Methods | Accuracy |
|---|---|---|---|
| MFCC-HMM ([39]) | 99.00% | SPEC-DNN ([40]) | 100.00% |
| LSF-SNN ([41]) | 98.50% | SPEC-CNN ([40]) | 99.83% |
| SOM-SNN ([39]) | 99.60% | Peterson et al. ([42]) | 99.30% |
| KP-SNN ([43]) | 100.00% | ||
| This work | 99.85% |
| Methods | Clean | 20 dB | 10 dB | 0 dB | –5 dB | Average |
|---|---|---|---|---|---|---|
| MFCC-HMM ([39]) | 99.00% | 62.10% | 34.40% | 21.80% | 19.50% | 47.30% |
| SPEC-DNN ([40]) | 100.00% | 94.38% | 71.80% | 42.68% | 34.85% | 68.74% |
| SOM-SNN ([39]) | 99.60% | 79.15% | 36.25% | 26.50% | 19.55% | 52.21% |
| This Work (Sine) | 99.53% | 99.38% | 90.5% | 47.68% | 20.38% | 71.49% |
| This Work (Linear) | 99.73% | 98.70% | 77.85% | 41.68% | 18.18% | 67.23% |
| Network Parameter | Description | Value |
|---|---|---|
| Threshold of spiking neurons | 1.0 | |
| epochs | Training epochs | 200 |
| batch size | The number of samples selected for a training | 100 |
| One quarter of the learning rate decay period | 100 | |
| The initial value of learning rate | 5 × 10 | |
| The minimum value of learning rate | 1 × 10 |
| Time Window | Accuracy | Time Window | Accuracy |
|---|---|---|---|
| 8 | 99.32% | 14 | 99.60% |
| 10 | 99.35% | 16 | 99.46% |
| 12 | 99.37% | 18 | 99.51% |
| Model | Methods | Network Structure | Time Window | Accuracy |
|---|---|---|---|---|
| STBP [17] | Spike-based BP | 15C5-P2-40C5-P2-FC300-FC10 | 30 | 99.42% |
| HM2-BP [44] | Spike-based BP | 15C5-P2-40C5-P2-FC300-FC10 | 400 | 99.49% |
| ST-RSBP [45] | Spike-based BP | 15C5-P2-40C5-P2-FC300-FC10 | 400 | 99.62% |
| Lee et al. [32] | Spike-based BP | 20C5-P2-50C5-P2-FC200-FC10 | 120 | 99.59% |
| ASF-BP [46] | Spike-based BP | 20C5-P2-50C5-P2-FC200-FC10 | 300 | 99.65% |
| Relaxation LIF [47] | Spike-based BP | 15C5-P2-40C5-P2-FC300-FC10 | 10 | 99.53% |
| This work (without SDE) | Spike-based BP | 15C5-P2-40C5-P2-FC300-FC10 | 14 | 99.52% |
| This work (with SDE) | Spike-based BP | 15C5-P2-40C5-P2-FC300-FC10 | 14 | 99.60% |
| Model | Network Structure | Time Window | Accuracy |
|---|---|---|---|
| ST-RSBP [45] | 400-R400 | 400 | 90.13% |
| GLSNN [48] | 10 | 89.02% | |
| LISNN [49] | 32C3-P2-32C3-P2-FC128-FC10 | 20 | 92.07% |
| STiDi-BP [50] | 20C5-P2-40C5-P2-1000-10 | 100 | 92.80% |
| This work | 15C5-P2-40C5-P2-FC300-FC10 | 20 | 90.26% |
| This work | 15C5-P2-40C5-P2-FC300-FC10 | 100 | 91.71% |
| Methods | Time Window | Ratio | Clean | 20 dB | 10 dB | 0 dB | −5 dB | Average |
|---|---|---|---|---|---|---|---|---|
| Linear | 14 | 0.9 | 99.70% | 98.88% | 80.38% | 40.88% | 20.00% | 68.00% |
| Linear | 14 | 0.1 | 98.97% | 97.35% | 76.07% | 43.55% | 18.75% | 66.90% |
| Sine | 12 | 0.9 | 99.75% | 99.625% | 92.125% | 50.50% | 24.00% | 73.20% |
| Sine | 12 | 0.1 | 97.292% | 97.318% | 88.916% | 47.21% | 21.915% | 70.53% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, R.; Dai, B.; Zhao, Y.; Chen, G.; Lu, H. Constrain Bias Addition to Train Low-Latency Spiking Neural Networks. Brain Sci. 2023, 13, 319. https://doi.org/10.3390/brainsci13020319
Lin R, Dai B, Zhao Y, Chen G, Lu H. Constrain Bias Addition to Train Low-Latency Spiking Neural Networks. Brain Sciences. 2023; 13(2):319. https://doi.org/10.3390/brainsci13020319
Chicago/Turabian StyleLin, Ranxi, Benzhe Dai, Yingkai Zhao, Gang Chen, and Huaxiang Lu. 2023. "Constrain Bias Addition to Train Low-Latency Spiking Neural Networks" Brain Sciences 13, no. 2: 319. https://doi.org/10.3390/brainsci13020319
APA StyleLin, R., Dai, B., Zhao, Y., Chen, G., & Lu, H. (2023). Constrain Bias Addition to Train Low-Latency Spiking Neural Networks. Brain Sciences, 13(2), 319. https://doi.org/10.3390/brainsci13020319