
Neural Correlates of Voice Learning with Distinctive and Non-Distinctive Faces

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Stimuli
2.2.1. Voices
2.2.2. Faces
2.3. Procedure
2.4. EEG Recordings
3. Results
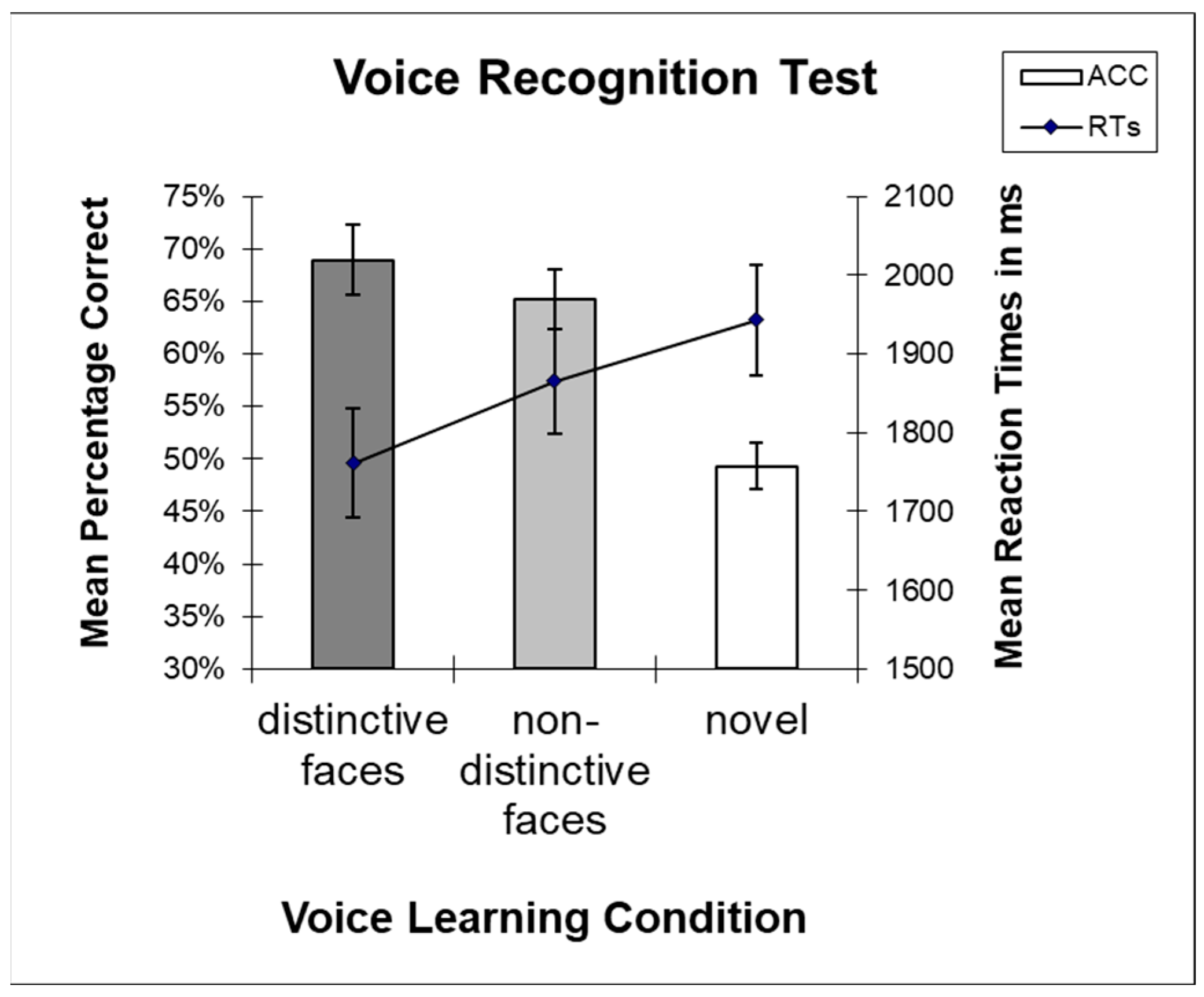
3.1. Behavioral Results Test Phase
3.1.1. Accuracies
3.1.2. Reaction Times
3.2. EEG Results
3.2.1. ERPs Learning Phases
Faces
Voices
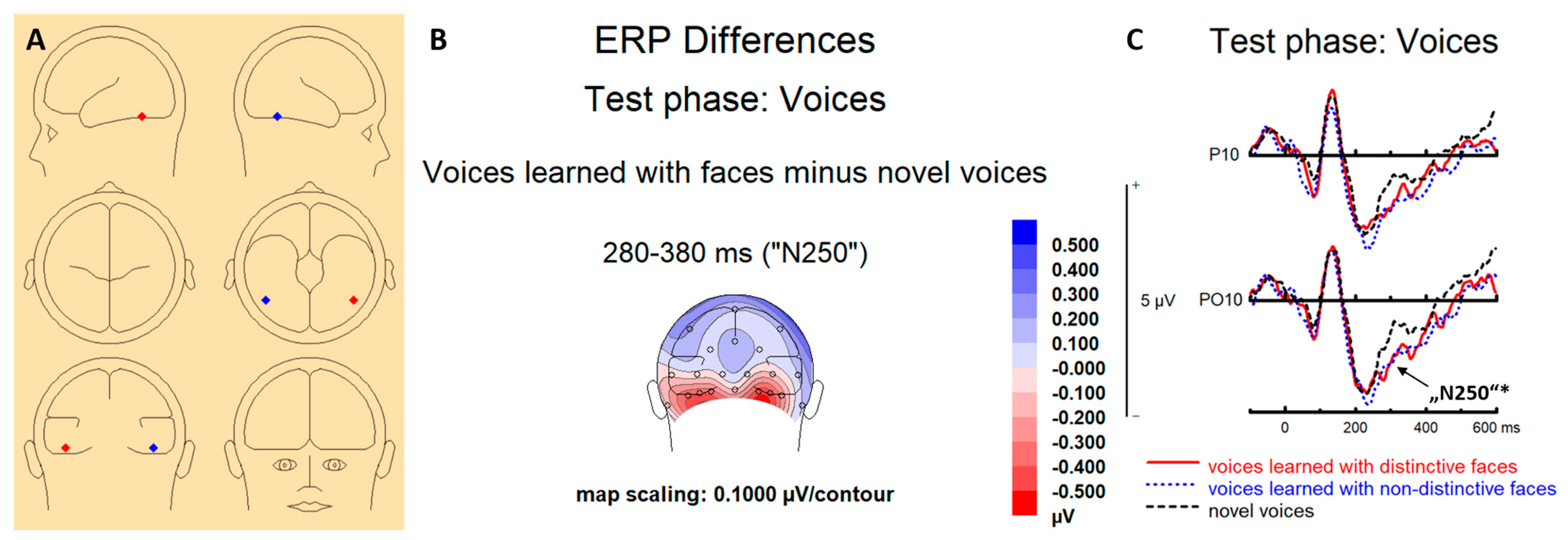
3.2.2. ERPs Test Phases (Voices)
3.2.3. Source Localization Test Phase
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Young, A.W.; Frühholz, S.; Schweinberger, S.R. Face and Voice Perception: Understanding Commonalities and Differences. Trends Cogn. Sci. 2020, 24, 398–410. [Google Scholar] [CrossRef] [PubMed]
- von Kriegstein, K.; Kleinschmidt, A.; Sterzer, P.; Giraud, A.L. Interaction of face and voice areas during speaker recognition. J. Cogn. Neurosci. 2005, 17, 367–376. [Google Scholar] [CrossRef] [PubMed]
- Kaufmann, J.M.; Schweinberger, S.R. The faces you remember: Caricaturing shape facilitates brain processes reflecting the acquisition of new face representations. Biol. Psychol. 2012, 89, 21–33. [Google Scholar] [CrossRef]
- Skuk, V.G.; Schweinberger, S.R. Gender differences in familiar voice identification. Hear. Res. 2013, 296, 131–140. [Google Scholar] [CrossRef] [PubMed]
- Blank, H.; Wieland, N.; von Kriegstein, K. Person recognition and the brain: Merging evidence from patients and healthy individuals. Neurosci. Biobehav. Rev. 2014, 47, 717–734. [Google Scholar] [CrossRef] [Green Version]
- von Kriegstein, K.; Dogan, O.; Grüter, M.; Giraud, A.-L.; Kell, C.A.; Grüter, T.; Kleinschmidt, A.; Kiebel, S.J. Simulation of talking faces in the human brain improves auditory speech recognition. Proc. Natl. Acad. Sci. USA 2008, 105, 6747–6752. [Google Scholar] [CrossRef] [Green Version]
- Blank, H.; Anwander, A.; von Kriegstein, K. Direct Structural Connections between Voice- and Face-Recognition Areas. J. Neurosci. Off. J. Soc. Neurosci. 2011, 31, 12906–12915. [Google Scholar] [CrossRef] [Green Version]
- Ellis, H.D.; Jones, D.M.; Mosdell, N. Intra- and inter-modal repetition priming of familiar faces and voices. Br. J. Psychol. 1997, 88, 143–156. [Google Scholar] [CrossRef]
- Lavan, N.; Collins, M.R.N.; Miah, J.F.M. Audiovisual identity perception from naturally-varying stimuli is driven by visual information. Br. J. Psychol. 2022, 113, 248–263. [Google Scholar] [CrossRef]
- Hanley, J.R.; Turner, J.M. Why are familiar-only experiences more frequent for voices than for faces? Q. J. Exp. Psychol. Sect. A-Hum. Exp. Psychol. 2000, 53, 1105–1116. [Google Scholar] [CrossRef]
- Zäske, R.; Volberg, G.; Kovacs, G.; Schweinberger, S.R. Electrophysiological Correlates of Voice Learning and Recognition. J. Neurosci. 2014, 34, 10821–10831. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Humble, D.; Schweinberger, S.R.; Dobel, C.; Zäske, R. Voices to remember: Comparing neural signatures of intentional and non-intentional voice learning and recognition. Brain Res. 2019, 1711, 214–225. [Google Scholar] [CrossRef] [PubMed]
- Zäske, R.; Mühl, C.; Schweinberger, S.R. Benefits for Voice Learning Caused by Concurrent Faces Develop over Time. PLoS ONE 2015, 10, e0143151. [Google Scholar] [CrossRef] [PubMed]
- Humble, D.; Schweinberger, S.R.; Mayer, A.; Jesgarzewsky, T.L.; Dobel, C.; Zäske, R. The Jena Voice Learning and Memory Test (JVLMT): A standardized tool for assessing the ability to learn and recognize voices. Behav. Res. Methods 2022. [Google Scholar] [CrossRef] [PubMed]
- Sheffert, S.M.; Olson, E. Audiovisual speech facilitates voice learning. Percept. Psychophys. 2004, 66, 352–362. [Google Scholar] [CrossRef] [Green Version]
- Tomlin, R.J.; Stevenage, S.V.; Hammond, S. Putting the pieces together: Revealing face-voice integration through the facial overshadowing effect. Vis. Cogn. 2017, 25, 629–643. [Google Scholar] [CrossRef]
- Cook, S.; Wilding, J. Earwitness testimony 2. Voices, faces and context. Appl. Cogn. Psychol. 1997, 11, 527–541. [Google Scholar] [CrossRef]
- McAllister, H.A.; Dale, R.H.I.; Bregman, N.J.; McCabe, A.; Cotton, C.R. When Eyewitnesses Are Also Earwitnesses—Effects on Visual and Voice Identifications. Basic Appl. Soc. Psychol. 1993, 14, 161–170. [Google Scholar] [CrossRef] [Green Version]
- Stevenage, S.V.; Howland, A.; Tippelt, A. Interference in Eyewitness and Earwitness Recognition. Appl. Cogn. Psychol. 2011, 25, 112–118. [Google Scholar] [CrossRef]
- Lavan, N.; Bamaniya, N.R.; Muse, M.M.; Price, R.L.M.; Mareschal, I. The effects of the presence of a face and direct eye gaze on voice identity learning. Br. J. Psychol. 2023. online ahead of print. [Google Scholar] [CrossRef]
- Cook, S.; Wilding, J. Earwitness testimony: Effects of exposure and attention on the face overshadowing effect. Br. J. Psychol. 2001, 92, 617–629. [Google Scholar] [CrossRef]
- Schweinberger, S.R.; Robertson, D.M.C. Audiovisual integration in familiar person recognition. Vis. Cogn. 2017, 25, 589–610. [Google Scholar] [CrossRef]
- Robertson, D.M.C.; Schweinberger, S.R. The role of audiovisual asynchrony in person recognition. Q. J. Exp. Psychol. 2010, 63, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Schweinberger, S.R.; Robertson, D.; Kaufmann, R.M. Hearing facial identities. Q. J. Exp. Psychol. 2007, 60, 1446–1456. [Google Scholar] [CrossRef] [PubMed]
- Latinus, M.; VanRullen, R.; Taylor, M.J. Top-down and bottom-up modulation in processing bimodal face/voice stimuli. BMC Neurosci. 2010, 11, 36. [Google Scholar] [CrossRef] [Green Version]
- Schulz, C.; Kaufmann, J.M.; Kurt, A.; Schweinberger, S.R. Faces forming traces: Neurophysiological correlates of learning naturally distinctive and caricatured faces. Neuroimage 2012, 63, 491–500. [Google Scholar] [CrossRef]
- Mullennix, J.; Ross, A.; Smith, C.; Kuykendall, K.; Conard, J.; Barb, S. Typicality Effects on Memory for Voice: Implications for Earwitness Testimony. Appl. Cogn. Psychol. 2011, 25, 29–34. [Google Scholar] [CrossRef]
- Stevenage, S.V.; Neil, G.J.; Parsons, B.; Humphreys, A. A sound effect: Exploration of the distinctiveness advantage in voice recognition. Appl. Cogn. Psychol. 2018, 32, 526–536. [Google Scholar] [CrossRef]
- Zäske, R.; Skuk, V.G.; Schweinberger, S.R. Attractiveness and distinctiveness between speakers’ voices in naturalistic speech and their faces are uncorrelated. R. Soc. Open Sci. 2020, 7, 201244. [Google Scholar] [CrossRef]
- Karlsson, T.; Schaefer, H.; Barton, J.J.S.; Corrow, S.L. Effects of Voice and Biographic Data on Face Encoding. Brain Sci. 2023, 13, 148. [Google Scholar] [CrossRef]
- Stevenage, S.V.; Hamlin, I.; Ford, B. Distinctiveness helps when matching static faces and voices. J. Cogn. Psychol. 2017, 29, 289–304. [Google Scholar] [CrossRef]
- Bülthoff, I.; Newell, F.N. Distinctive voices enhance the visual recognition of unfamiliar faces. Cognition 2015, 137, 9–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bülthoff, I.; Newell, F.N. Crossmodal priming of unfamiliar faces supports early interactions between voices and faces in person perception. Vis. Cogn. 2017, 25, 611–628. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Mondloch, C.J.; Segalowitz, S.J. The timing of individual face recognition in the brain. Neuropsychologia 2012, 50, 1451–1461. [Google Scholar] [CrossRef] [PubMed]
- Schweinberger, S.R.; Neumann, M.F. Repetition effects in human ERPs to faces. Cortex 2016, 80, 141–153. [Google Scholar] [CrossRef]
- Wuttke, S.J.; Schweinberger, S.R. The P200 predominantly reflects distance-to-norm in face space whereas the N250 reflects activation of identity-specific representations of known faces. Biol. Psychol. 2019, 140, 86–95. [Google Scholar] [CrossRef]
- Amihai, I.; Deouell, L.Y.; Bentin, S. Neural adaptation is related to face repetition irrespective of identity: A reappraisal of the N170 effect. Exp. Brain Res. 2011, 209, 193–204. [Google Scholar] [CrossRef] [Green Version]
- Eimer, M. The face-sensitive N170 component of the event-related brain potential. In The Oxford Handbook of Face Perception; Calder, A.J., Rhodes, G., Johnson, M.H., Haxby, J.V., Eds.; Oxford University Press: Oxford, UK, 2011; pp. 329–344. [Google Scholar]
- Eimer, M.; Gosling, A.; Duchaine, B. Electrophysiological markers of covert face recognition in developmental prosopagnosia. Brain 2012, 135, 542–554. [Google Scholar] [CrossRef]
- Schulz, C.; Kaufmann, J.M.; Walther, L.; Schweinberger, S.R. Effects of anticaricaturing vs. caricaturing and their neural correlates elucidate a role of shape for face learning. Neuropsychologia 2012, 50, 2426–2434. [Google Scholar] [CrossRef]
- Hillyard, S.A.; Vogel, E.K.; Luck, S.J. Sensory gain control (amplification) as a mechanism of selective attention: Electrophysiological and neuroimaging evidence. Philos. Trans. R. Soc. Lond. Ser. B-Biol. Sci. 1998, 353, 1257–1270. [Google Scholar] [CrossRef] [Green Version]
- Itz, M.L.; Schweinberger, S.R.; Kaufmann, J.M. Effects of Caricaturing in Shape or Color on Familiarity Decisions for Familiar and Unfamiliar Faces. PLoS ONE 2016, 11, e0149796. [Google Scholar] [CrossRef] [Green Version]
- Itz, M.L.; Schweinberger, S.R.; Schulz, C.; Kaufmann, J.M. Neural correlates of facilitations in face learning by selective caricaturing of facial shape or reflectance. Neuroimage 2014, 102, 736–747. [Google Scholar] [CrossRef] [PubMed]
- Hillyard, S.A.; Hink, R.F.; Schwent, V.L.; Picton, T.W. Electrical Signs of Selective Attention in Human Brain. Science 1973, 182, 177–180. [Google Scholar] [CrossRef] [Green Version]
- Altmann, C.F.; Nakata, H.; Noguchi, Y.; Inui, K.; Hoshiyama, M.; Kaneoke, Y.; Kakigi, R. Temporal dynamics of adaptation to natural sounds in the human auditory cortex. Cereb. Cortex 2008, 18, 1350–1360. [Google Scholar] [CrossRef] [Green Version]
- Kuriki, S.; Ohta, K.; Koyama, S. Persistent responsiveness of long-latency auditory cortical activities in response to repeated stimuli of musical timbre and vowel sounds. Cereb. Cortex 2007, 17, 2725–2732. [Google Scholar] [CrossRef] [Green Version]
- Nussbaum, C.; Schirmer, A.; Schweinberger, S.R. Contributions of fundamental frequency and timbre to vocal emotion perception and their electrophysiological correlates. Soc. Cogn. Affect. Neurosci. 2022, 17, 1145–1154. [Google Scholar] [CrossRef]
- Schirmer, A.; Kotz, S.A. Beyond the right hemisphere: Brain mechanisms mediating vocal emotional processing. Trends Cogn. Sci. 2006, 10, 24–30. [Google Scholar] [CrossRef] [PubMed]
- Zäske, R.; Schweinberger, S.R.; Kaufmann, J.M.; Kawahara, H. In the ear of the beholder: Neural correlates of adaptation to voice gender. Eur. J. Neurosci. 2009, 30, 527–534. [Google Scholar] [CrossRef]
- Föcker, J.; Hölig, C.; Best, A.; Roeder, B. Crossmodal interaction of facial and vocal person identity information: An event-related potential study. Brain Res. 2011, 1385, 229–245. [Google Scholar] [CrossRef] [PubMed]
- Sommer, W.; Heinz, A.; Leuthold, H.; Matt, J.; Schweinberger, S.R. Metamemory, Distinctiveness, and Event-Related Potentials in Recognition Memory for Faces. Mem. Cogn. 1995, 23, 1–11. [Google Scholar] [CrossRef]
- Wiese, H.; Tüttenberg, S.C.; Ingram, B.; Chan, C.Y.X.; Gurbuz, Z.; Burton, A.M.; Young, A.W. A Robust Neural Index of High Face Familiarity. Psychol. Sci. 2019, 30, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schweinberger, S.R. Human brain potential correlates of voice priming and voice recognition. Neuropsychologia 2001, 39, 921–936. [Google Scholar] [CrossRef] [PubMed]
- Picton, T.W.; Woods, D.L.; Proulx, G.B. Human Auditory Sustained Potentials 1. Nature of Response. Electroencephalogr. Clin. Neurophysiol. 1978, 45, 186–197. [Google Scholar] [CrossRef] [PubMed]
- Faul, F.; Erdfelder, E.; Lang, A.G.; Buchner, A. G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods 2007, 39, 175–191. [Google Scholar] [CrossRef]
- Burton, A.M.; White, D.; McNeill, A. The Glasgow Face Matching Test. Behav. Res. Methods 2010, 42, 286–291. [Google Scholar] [CrossRef] [Green Version]
- Phillips, P.J.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Kaufmann, J.M.; Schweinberger, S.R.; Burton, A. N250 ERP Correlates of the Acquisition of Face Representations across Different Images. J. Cogn. Neurosci. 2009, 21, 625–641. [Google Scholar] [CrossRef]
- Schweinberger, S.R.; Pickering, E.C.; Jentzsch, I.; Burton, A.M.; Kaufmann, J.M. Event-related brain potential evidence for a response of inferior temporal cortex to familiar face repetitions. Cogn. Brain Res. 2002, 14, 398–409. [Google Scholar] [CrossRef]
- Huynh, H.; Feldt, L.S. Estimation of the box correction for degrees of freedom from sample data in randomized block and split block designs. J. Educ. Stat. 1976, 1, 69–82. [Google Scholar] [CrossRef]
- Stanislaw, H.; Todorov, N. Calculation of signal detection theory measures. Behav. Res. Methods Instrum. Comput. 1999, 31, 137–149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Itz, M.L.; Schweinberger, S.R.; Kaufmann, J.M. Caricature generalization benefits for faces learned with enhanced idiosyncratic shape or texture. Cogn. Affect. Behav. Neurosci. 2017, 17, 185–197. [Google Scholar] [CrossRef] [Green Version]
- Talsma, D.; Woldorff, M.G. Selective attention and multisensory integration: Multiple phases of effects on the evoked brain activity. J. Cogn. Neurosci. 2005, 17, 1098–1114. [Google Scholar] [CrossRef]
- Schall, S.; Kiebel, S.J.; Maess, B.; von Kriegstein, K. Early auditory sensory processing of voices is facilitated by visual mechanisms. Neuroimage 2013, 77, 237–245. [Google Scholar] [CrossRef] [PubMed]
- Plante-Hebert, J.; Boucher, V.J.; Jemel, B. The processing of intimately familiar and unfamiliar voices: Specific neural responses of speaker recognition and identification. PLoS ONE 2021, 16, e0250214. [Google Scholar] [CrossRef] [PubMed]
- Kamachi, M.; Hill, H.; Lander, K.; Vatikiotis-Bateson, E. Putting the face to the voice’: Matching identity across modality. Curr. Biol. 2003, 13, 1709–1714. [Google Scholar] [CrossRef]
- Zäske, R.; Limbach, K.; Schneider, D.; Skuk, V.G.; Dobel, C.; Guntinas-Lichius, O.; Schweinberger, S.R. Electrophysiological correlates of voice memory for young and old speakers in young and old listeners. Neuropsychologia 2018, 116, 215–227. [Google Scholar] [CrossRef]
- Latinus, M.; Crabbe, F.; Belin, P. Learning-Induced Changes in the Cerebral Processing of Voice Identity. Cereb. Cortex 2011, 21, 2820–2828. [Google Scholar] [CrossRef] [Green Version]
- Zäske, R.; Hasan, B.A.S.; Belin, P. It doesn’t matter what you say: fMRI correlates of voice learning and recognition independent of speech content. Cortex 2017, 94, 100–112. [Google Scholar] [CrossRef]
- Rizio, A.A.; Dennis, N.A. Recollection after inhibition: The effects of intentional forgetting on the neural correlates of retrieval. Cogn. Neurosci. 2017, 8, 1–8. [Google Scholar] [CrossRef]
- Hayama, H.R.; Johnson, J.D.; Rugg, M.D. The relationship between the right frontal old/new ERP effect and post-retrieval monitoring: Specific or non-specific? Neuropsychologia 2008, 46, 1211–1223. [Google Scholar] [CrossRef] [Green Version]
- Hayama, H.R.; Rugg, M.D. Right dorsolateral prefrontal cortex is engaged during post-retrieval processing of both episodic and semantic information. Neuropsychologia 2009, 47, 2409–2416. [Google Scholar] [CrossRef] [Green Version]
- Puce, A.; Allison, T.; Asgari, M.; Gore, J.C.; McCarthy, G. Differential sensitivity of human visual cortex to faces, letterstrings, and textures: A functional magnetic resonance imaging study. J. Neurosci. 1996, 16, 5205–5215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kanwisher, N.; McDermott, J.; Chun, M.M. The fusiform face area: A module in human extrastriate cortex specialized for face perception. J. Neurosci. 1997, 17, 4302–4311. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schweinberger, S.R.; Kaufmann, J.M.; Moratti, S.; Keil, A.; Burton, A.M. Brain responses to repetitions of human and animal faces, inverted faces, and objects—An MEG study. Brain Res. 2007, 1184, 226–233. [Google Scholar] [CrossRef] [PubMed]
- Eger, E.; Schweinberger, S.R.; Dolan, R.J.; Henson, R.N. Familiarity enhances invariance of face representations in human ventral visual cortex: fMRI evidence. Neuroimage 2005, 26, 1128–1139. [Google Scholar] [CrossRef] [Green Version]
- von Kriegstein, K.; Giraud, A.L. Implicit multisensory associations influence voice recognition. PLoS Biol. 2006, 4, e326. [Google Scholar] [CrossRef]
- Rhone, A.E.; Rupp, K.; Hect, J.L.; Harford, E.E.; Tranel, D.; Howard, M.A.; Abel, T.J. Electrocorticography reveals the dynamics of famous voice responses in human fusiform gyrus. J. Neurophysiol. 2023, 129, 342–346. [Google Scholar] [CrossRef]
- Blank, H.; Kiebel, S.J.; von Kriegstein, K. How the Human Brain Exchanges Information Across Sensory Modalities to Recognize Other People. Hum. Brain Mapp. 2015, 36, 324–339. [Google Scholar] [CrossRef] [PubMed]
- Belin, P.; Fecteau, S.; Bedard, C. Thinking the voice: Neural correlates of voice perception. Trends Cogn. Sci. 2004, 8, 129–135. [Google Scholar] [CrossRef]
- Bodamer, J. Prosopagnosie. Arch. Der Psychiatr. Nervenkrankh. 1947, 179, 6–54. [Google Scholar] [CrossRef] [PubMed]
- van Lancker, D.R.; Kreiman, J.; Cummings, J. Voice Perception Deficits—Neuroanatomical Correlates of Phonagnosia. J. Clin. Exp. Neuropsychol. 1989, 11, 665–674. [Google Scholar] [CrossRef] [PubMed]
- Garrido, L.; Eisner, F.; McGettigan, C.; Stewart, L.; Sauter, D.; Hanley, J.R.; Schweinberger, S.R.; Warren, J.D.; Duchaine, B. Developmental phonagnosia: A selective deficit of vocal identity recognition. Neuropsychologia 2009, 47, 123–131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McConachie, H.R. Developmental Prosopagnosia. A Single Case Report. Cortex 1976, 12, 76–82. [Google Scholar] [CrossRef]
- Liu, R.R.; Corrow, S.L.; Pancaroglu, R.; Duchaine, B.; Barton, J.J.S. The processing of voice identity in developmental prosopagnosia. Cortex 2015, 71, 390–397. [Google Scholar] [CrossRef] [Green Version]
- Tsantani, M.; Cook, R. Normal recognition of famous voices in developmental prosopagnosia. Sci. Rep. 2020, 10, 19757. [Google Scholar] [CrossRef]
- Liu, R.R.; Pancaroglu, R.; Hills, C.S.; Duchaine, B.; Barton, J.J.S. Voice Recognition in Face-Blind Patients. Cereb. Cortex 2016, 26, 1473–1487. [Google Scholar] [CrossRef] [Green Version]
- Cosseddu, M.; Gazzina, S.; Borroni, B.; Padovani, A.; Gainotti, G. Multimodal Face and Voice Recognition Disorders in a Case With Unilateral Right Anterior Temporal Lobe Atrophy. Neuropsychology 2018, 32, 920–930. [Google Scholar] [CrossRef]
- Gainotti, G. Laterality effects in normal subjects’ recognition of familiar faces, voices and names. Perceptual and representational components. Neuropsychologia 2013, 51, 1151–1160. [Google Scholar] [CrossRef]
- Schroeger, A.; Kaufmann, J.M.; Zäske, R.; Kovacs, G.; Klos, T.; Schweinberger, S.R. Atypical prosopagnosia following right hemispheric stroke: A 23-year follow-up study with MT. Cogn. Neuropsychol. 2022, 39, 196–207. [Google Scholar] [CrossRef]
- Neuner, F.; Schweinberger, S.R. Neuropsychological impairments in the recognition of faces, voices, and personal names. Brain Cogn. 2000, 44, 342–366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schweinberger, S.R.; Kloth, N.; Robertson, D.M. Hearing facial identities: Brain correlates of face-voice integration in person identification. Cortex 2011, 47, 1026–1037. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, I.Q.; Leon, M.A.B.; Belin, P.; Martinez-Quintana, Y.; Garcia, L.G.; Castillo, M.S. Person identification through faces and voices: An ERP study. Brain Res. 2011, 1407, 13–26. [Google Scholar] [CrossRef] [PubMed]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zäske, R.; Kaufmann, J.M.; Schweinberger, S.R. Neural Correlates of Voice Learning with Distinctive and Non-Distinctive Faces. Brain Sci. 2023, 13, 637. https://doi.org/10.3390/brainsci13040637
Zäske R, Kaufmann JM, Schweinberger SR. Neural Correlates of Voice Learning with Distinctive and Non-Distinctive Faces. Brain Sciences. 2023; 13(4):637. https://doi.org/10.3390/brainsci13040637
Chicago/Turabian StyleZäske, Romi, Jürgen M. Kaufmann, and Stefan R. Schweinberger. 2023. "Neural Correlates of Voice Learning with Distinctive and Non-Distinctive Faces" Brain Sciences 13, no. 4: 637. https://doi.org/10.3390/brainsci13040637