1. Introduction
Lying is a common phenomenon in life [
1] and is considered to be a high-level executive control behavior that causes activity in the amygdala, insula, and prefrontal regions of the brain [
2], which in turn leads to changes in speech parameters such as frequency during speaking. There has been an attempt to improve the recognition rate of lie detection with advanced techniques. Deception detection techniques have been applied to criminal investigations [
3], psychotherapy [
4,
5], children’s education [
6], and national security [
7] with some success. Traditional deception detection methods require contact with the human body, which may bring psychological burdens and interfere with the results of deception detection [
8]. Aldert [
9] also pointed out that the application of medical devices to collect physiological and brain signals may make these signals invasive and inconvenient to use, while speech signals can produce better results. Compared with traditional deception detection methods, speech deception detection methods have the advantages of easy access to data, absence of time and space constraints, and high concealment. Therefore, deception detection using speech has a strong theoretical and practical restudy value for the study of cognitive brain science [
10].
Early relevant studies have confirmed that some acoustic features in speech are related to deception [
11]. Ekman et al. [
12] collected and analyzed the subjects’ impressions of some TV clips, and found that the fundamental frequency part of lies was higher than that of truth. Lying and stress are always related. Kaliappan and Hansen et al. [
13,
14] found that some acoustic parameters related to lying, such as resonance peak, Bark energy characteristics, and MFCC, changed with the alteration of pressure level. DePaulo et al. [
15] meta-analyzed 158 features proposed by previous polygraph research work and selected 23 speech and speech-related features with significant expressions. The study found that lies showed less detailed expressions, repetitive utterances, more content, shorter expression lengths, and incoherent speech utterances compared to the truth. The research team of Purdue University in the United States used the amplitude modulation model and frequency modulation model to conduct speech deception detection research, proving that Teager energy-related features could distinguish truth from lie [
16]. In addition, some relevant scholars considered combining multiple features for deception detection. Researchers at Columbia University considered combining acoustic features, prosodic features, and lexical features for research on lie detection in speech [
17]. In 2013, Kirchhuebel et al. used the acoustic and temporal features of speech to study the effects of different conversation modes on deception detection from three aspects: emotional arousal/stress [
18], cognitive load, and ultra control. Some scholars classify acoustic features into prosody features and spectral-based correlation analysis features [
19]. Speech prosody refers to the vocal modulations that accompany speech and comprises variations in fundamental frequency, duration, and energy. In recent years, speech prosody has been recognized in several disciplines, including psycholinguistics, as a bridge between speech acts and mental disorders [
20], and therefore has great research value in revealing the brain mechanisms behind speech communication. Spectral-based features can reflect the connection between speech tract shape and speech behavior [
21]. The cochlea of the human ear is the key to forming hearing, which can convert speech signals into neural pulses and send them to the auditory area of the brain, generating hearing. The basilar membrane of the cochlea is equivalent to a nonlinear filter bank, and its movement frequencies are converted into nerve impulses by outer hair cells and inner hair cells. The mel-frequency cepstrum coefficient (MFCC) [
22] is a feature parameter discovered based on this auditory mechanism, which is in nonlinear correspondence with frequency and has been widely used in the fields of speech emotion recognition and deception detection. Research has shown that early extraction and analysis of acoustic parameters affect the differentiation of early ERP responses, while stimuli caused by acoustic characteristics in the early stages can affect brain cognition in the later stages [
23]. The nervous system encodes these evolving acoustic parameters to obtain a clear representation of different speech patterns, further enabling the brain to clearly distinguish between lies and truth. With the development of deep learning technology, researchers extracted deep features through deep neural networks and applied them to speech deception detection research. Xie et al. [
24] combined spectral features that exploit the orthogonality and translational invariance of Hu moments with deep learning methods and used deep confidence networks for their experiments, achieving extremely high recognition results. Liang et al. [
25] extracted speech-depth features using convolutional long and short-time memory networks, and achieved good recognition results on the self-built deception detection database.
Although the above scholars have made many achievements in the field of deception detection, the data-driven deep neural network is extremely dependent on large-scale labeled high-quality speech data, and the problem of insufficient data has become a key problem restricting the development of the field of voice-based lie detection [
26]. The supervised model is the most common machine learning model, which is widely used in the field of speech deception detection and has achieved high recognition accuracy. When the amount of labeled data is insufficient, the improvement in lie detection accuracy by supervised models can appear to be inadequate. Unsupervised models, which can discover the intrinsic structure of data and are often used for data mining, may be particularly useful in cases where labeled data is not available or when there is a need to identify new patterns in speech. Due to the limitation of data volume, the application of unsupervised models in the field of lie detection in speech has yet to be further investigated. Semi-supervised learning is a learning method that combines supervised and unsupervised learning. Semi-supervised models learn the local features of a small amount of labeled data and the overall distribution of a large amount of unlabeled data to obtain acceptable or even better recognition results. Semi-supervised models offer a promising approach for lie detection in speech and other tasks. Tarvainen et al. [
27] proposed a method of averaging the weights of the mean-teacher model, combined with the consistent regularization method, by adding perturbed data points to push the decision boundary to the appropriate location, improving the generalization of the model, and significantly improving the learning speed and classification accuracy of the network. Liu et al. [
28] added a pseudo-label generation module under the framework of the classic domain confrontation network and reduced the impact of pseudo-label noise and the error rate of prediction results by introducing the mean-teacher model. In the field of speech deception detection, Fu H et al. [
29] proposed a speech deception detection model based on a semi-supervised denoising autoencoder network (DAE), which achieved good results using only a small amount of labeled data. Due to the limitations of traditional acoustic features, the trained network representation ability is insufficient, and it is difficult to achieve high recognition accuracy. Su et al. [
30] trained the BILSTM network and SVM models separately and further fused the classification results using a decision-level score fusion scheme to integrate all developed models. Fang et al. [
31] proposed a speech deception detection strategy combining the semi-supervised method and the full-supervised method, and constructed a hybrid model combining semi-supervised DAE and fully supervised LSTM network, effectively improving the accuracy of semi-supervised speech deception detection. Although the above research has made some achievements, it ignores the exploration of the multifeature deception detection algorithm under a fully semi-supervised framework. Improper fusion of features can easily lead to poor generalization ability of the semi-supervised model.
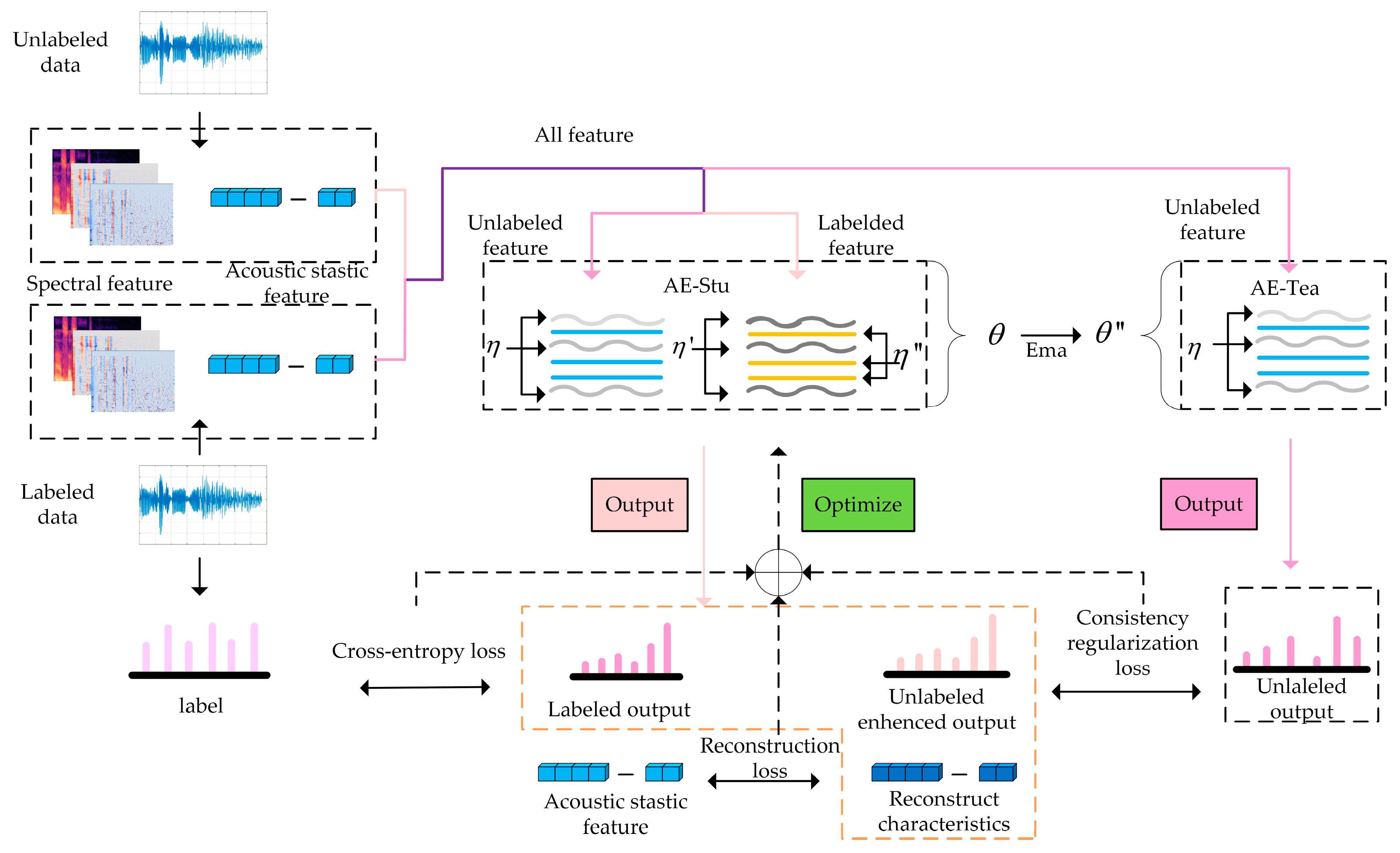
Inspired by the feature fusion method and semi-supervised learning, this paper proposes a semi-supervised speech deception detection algorithm that integrates acoustic statistical features and time-frequency two-dimensional features to solve the problems in the research of speech deception detection, aiming to suppress the dimension disaster caused by multiclass feature fusion and obtain features with more favorable information in the semi-supervised learning environment. Firstly, the proposed algorithm employs a hybrid network composed of a semi-supervised AE network and a mean-teacher model network to extract the fusion features of deception detection, with the aid of the mean-teacher model to extract spectral features rich in time-frequency information, and applies a semi-supervised AE network to extract low-dimensional, high-level acoustic statistical features. Secondly, the consistency regularization method is introduced, and the dropout method is added to improve the generalization ability of the model and suppress the over-fitting phenomenon. Finally, the fusion features are input into the softmax classifier for classification, and the model is optimized by using a dynamically adjusted weighted sum of the cross-entropy loss of labeled data, the consistency regularization of unlabeled data, and the reconstruction loss of the AE network.
4. Discussion
When people lie, they tend to use more complex language and take longer to respond to questions. This process is accompanied by changes in ERPs on the amygdala, insula, and prefrontal regions of the brain as well as changes in acoustic signature parameters associated with lying, with some studies demonstrating that these two changes are correlated [
23]. Drawing on the work of Low et al. [
47] and Pastoriza-Domínguez et al. [
48] who used machine learning algorithms based on acoustic feature analysis for detecting major mental disorders, we focused, in this paper, on choosing the acoustic feature parameters associated with the act of lying and used the trained neural network model to detect subtle changes in the acoustic feature parameters under different speech patterns to discriminate between lies and truth. This can help us better understand how speech is processed in the brain and enable researchers to further investigate the brain’s cognitive neural mechanisms during the lying process. Our models can also be modified and applied to the assessment and diagnosis of speech prosody in mental disorders, in terms of the automatic classification of prosodic events for detection.
Due to the specific nature of the act of lying, it is difficult to insulate subjects from the effects of the equipment when collecting EEG signals and facial information related to lies, which can lead to biases between the data collected and the actual data. Moreover, in many cases, it is only after the act of lying has occurred that people’s brains become aware of the lie. As mentioned in the literature [
49], the choice may have taken place before it was actually made. However, using speech signals alone for deception detection is not comprehensive; in some cases, EEG signals and facial information are more directly indicative of the true situation. Therefore, conducting multimodal lie detection research is meaningful [
50], as it can comprehensively explore the neural mechanisms of the lying process from multiple perspectives.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}