

Application of Pseudo-Three-Dimensional Residual Network to Classify the Stages of Moyamoya Disease
Abstract
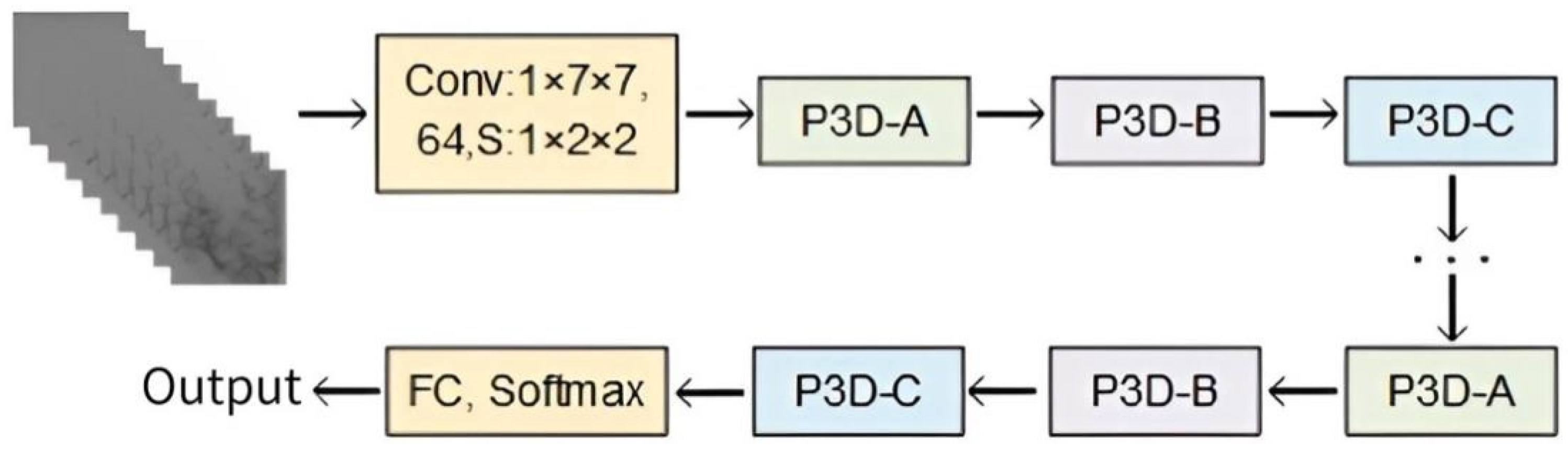
:1. Introduction
2. Materials and Methods
2.1. Data Processing
2.2. Operating Environment
2.3. Design of P3D ResNet
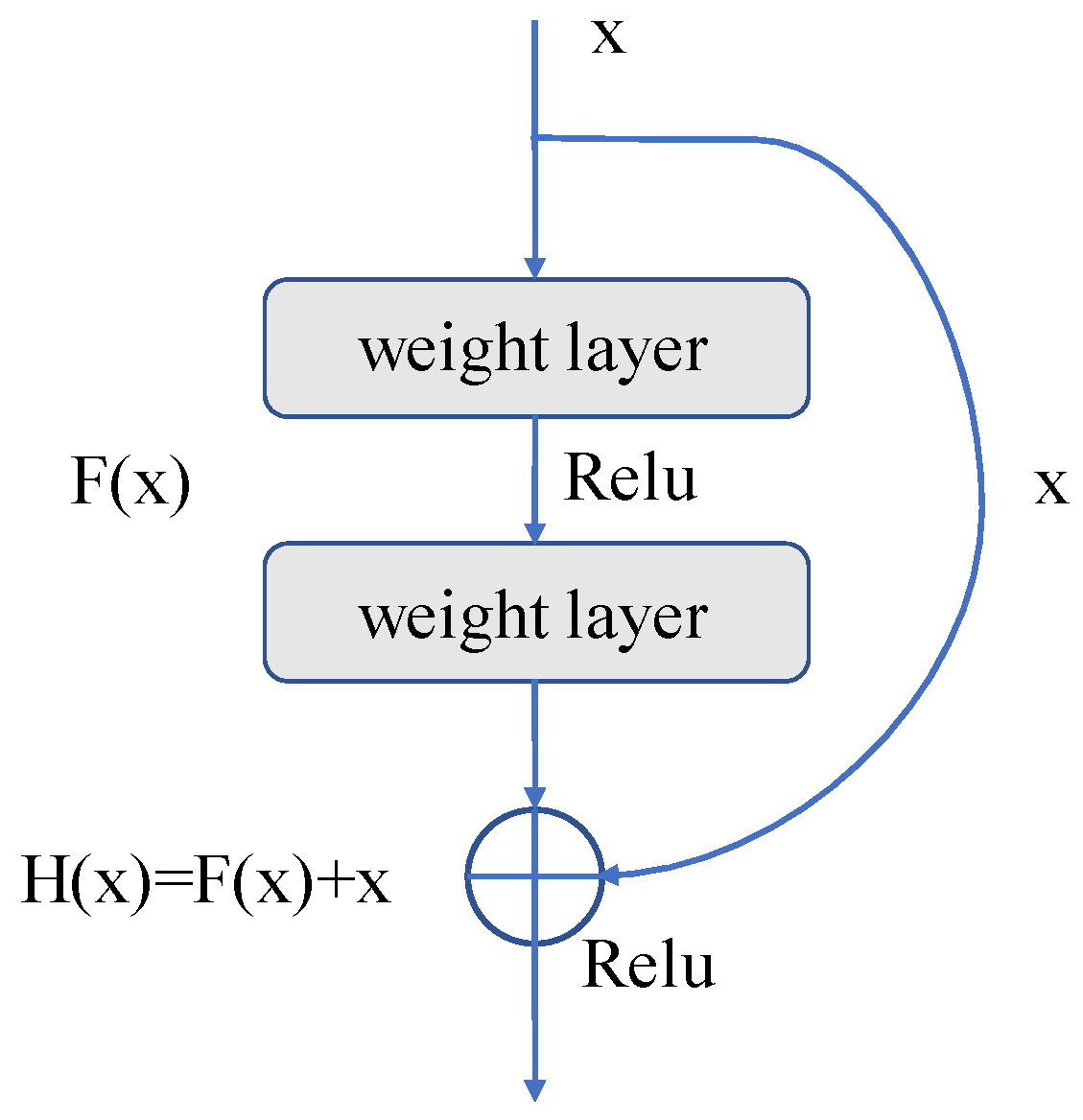
2.3.1. Residual Unit
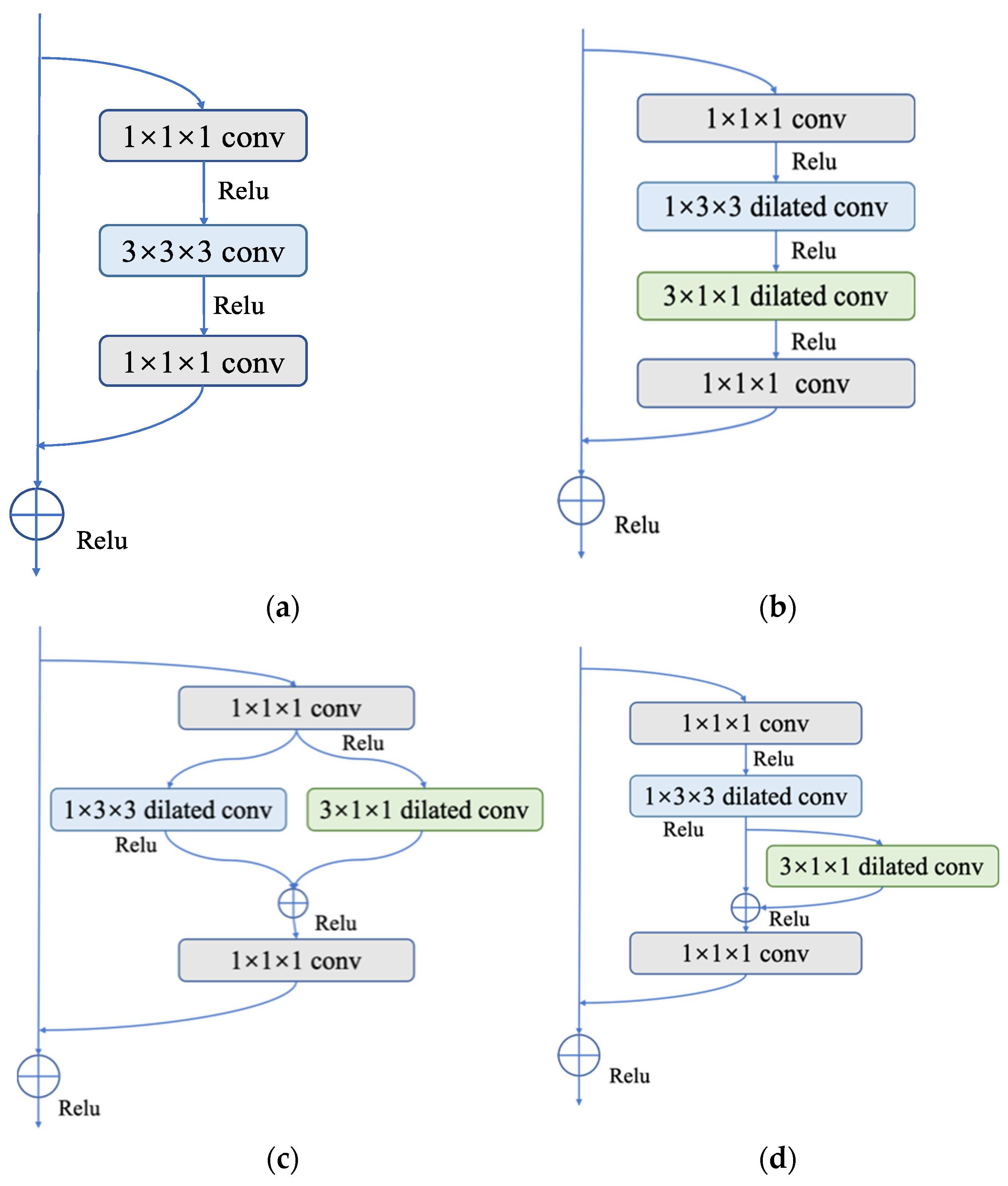
2.3.2. P3D Modules
- (1)
- P3D-A: Both the spatial and temporal dimension convolutions are cascaded in P3D-A. To create the final result, the feature maps are first used to perform a 2D spatial convolution calculation, followed by a 1D temporal convolution calculation. The equation can be written as follows:
- (2)
- P3D-B: There is no symbiotic relationship between spatial and temporal dimension convolutions. The two run parallel to one another. These two outcomes can be combined with the input of the module to obtain the final output. The equation reads as follows:
- (3)
- P3D-C: This operation combines the two earlier approaches. The input first passes through spatial 2D convolution, and the results are then added to those of the temporal 1D convolution operation. Finally, it is possible to establish the following formula:
2.3.3. Dilated Convolution
2.3.4. Bottleneck Structure of P3D Module
3. Results and Discussion
3.1. Evaluation Metrics
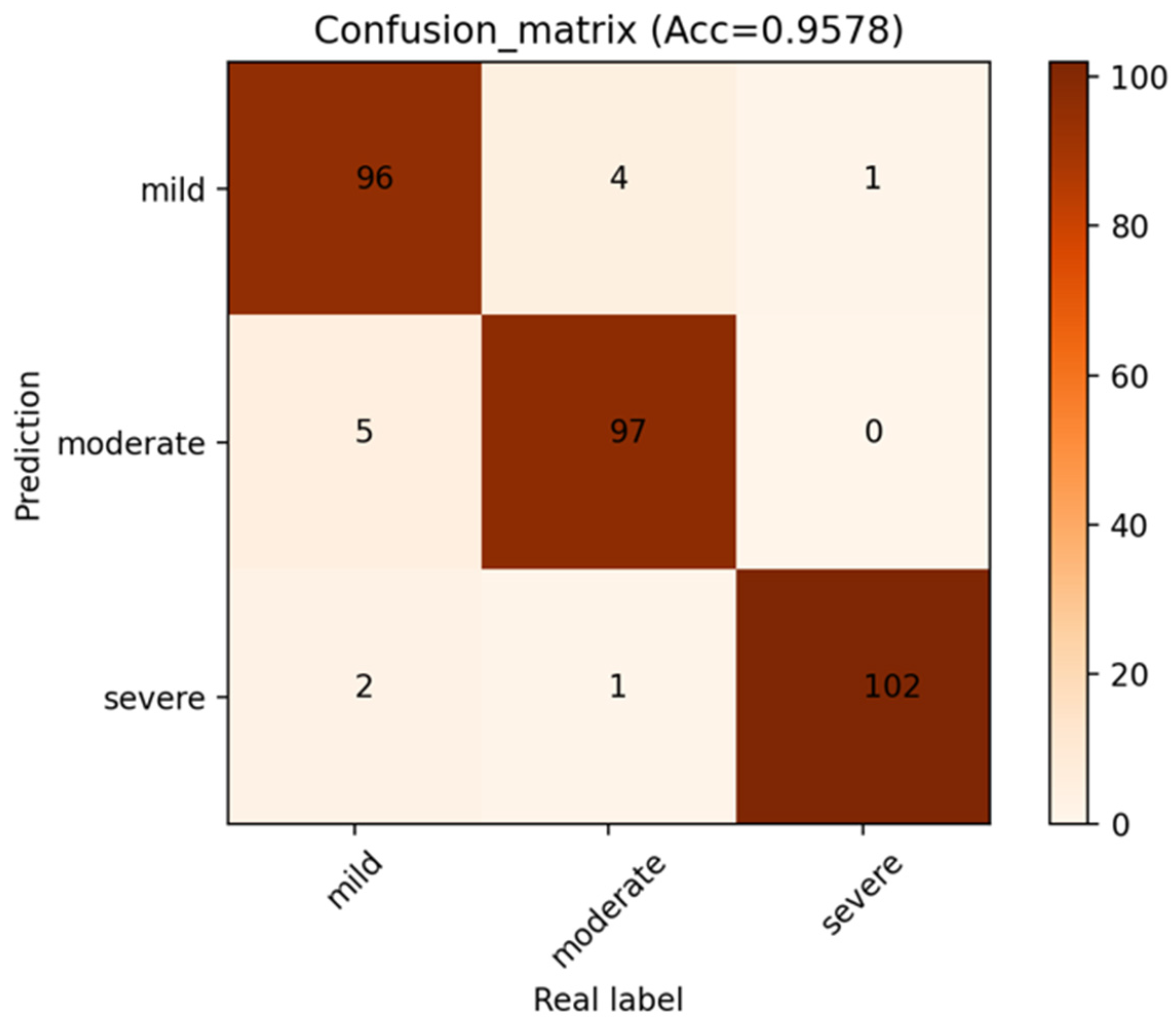
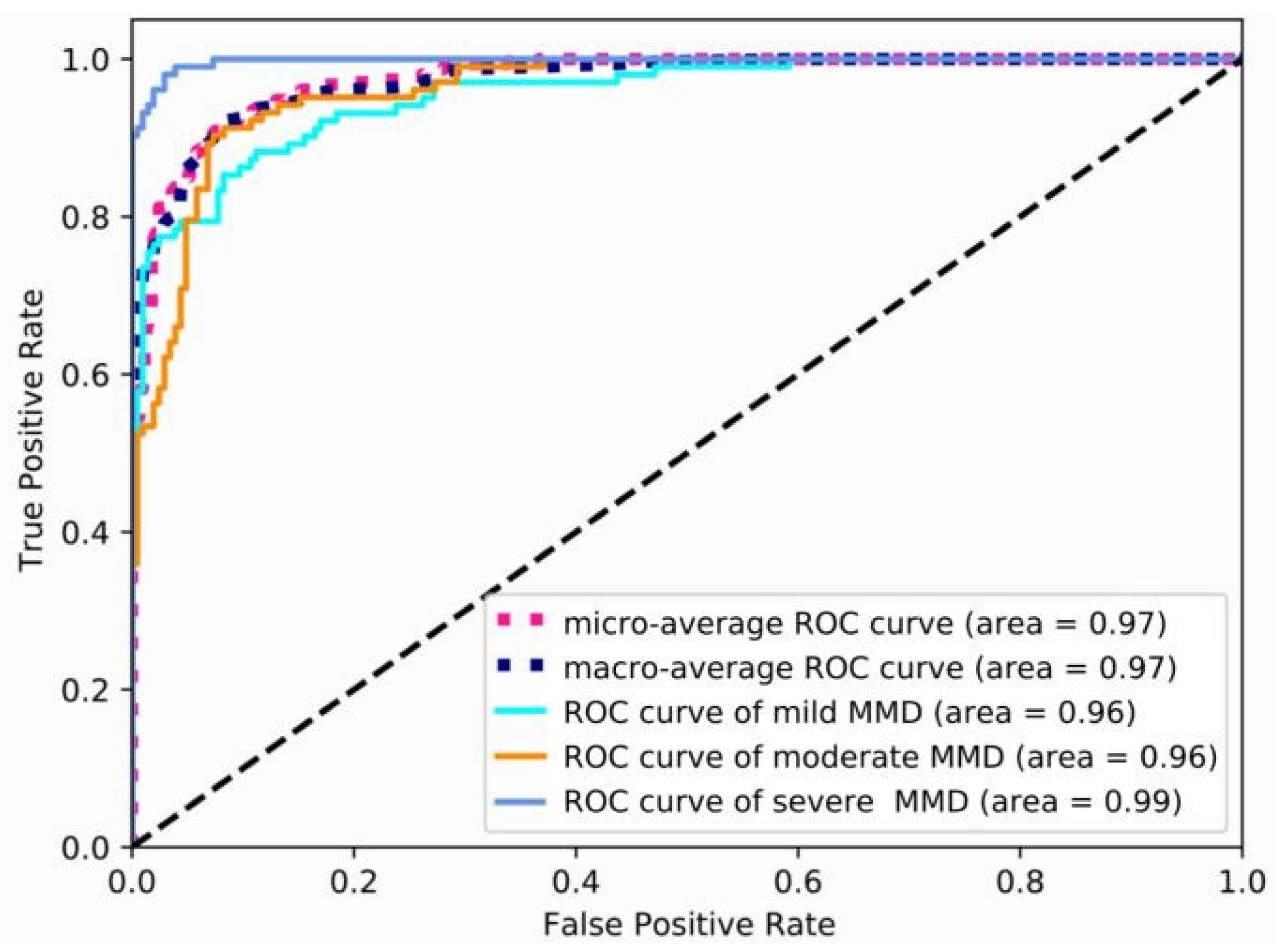
3.2. The Performance of P3D ResNet
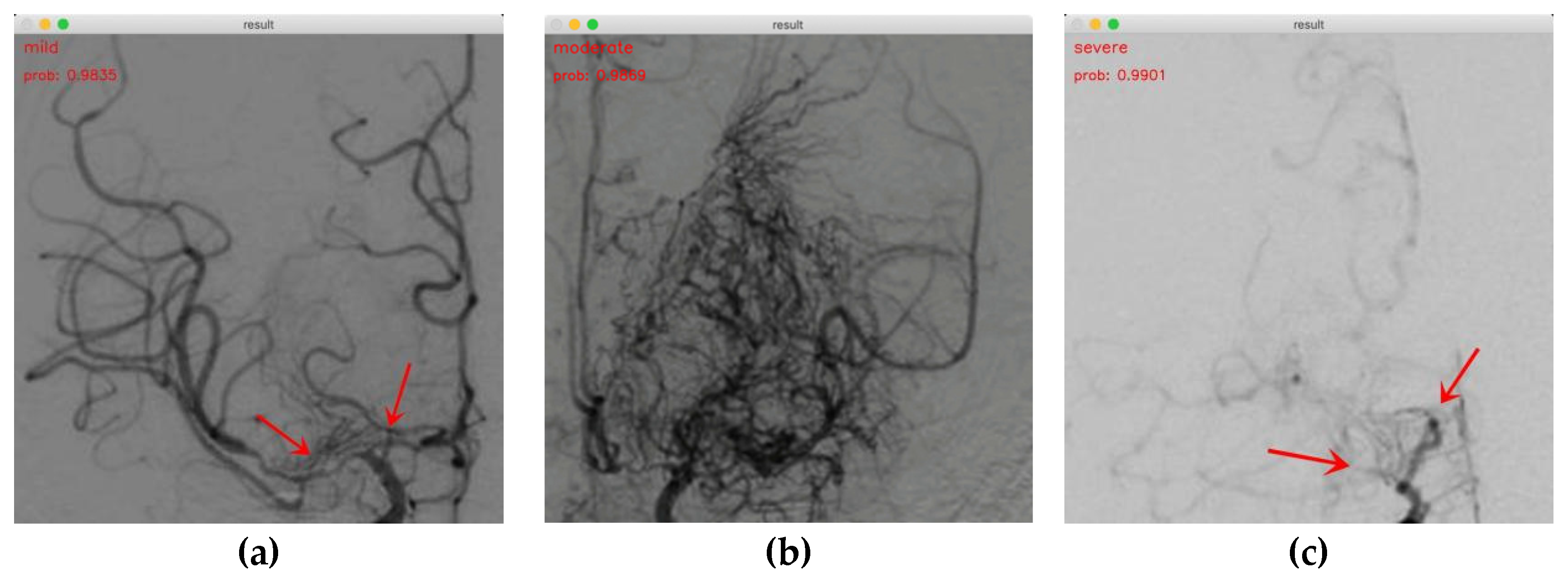
3.3. Demonstrations of MMD Staging Based on P3D ResNet
3.4. Comparison among P3D ResNet Variants
3.5. Comparison of P3D ResNet with Different Dilation Rates
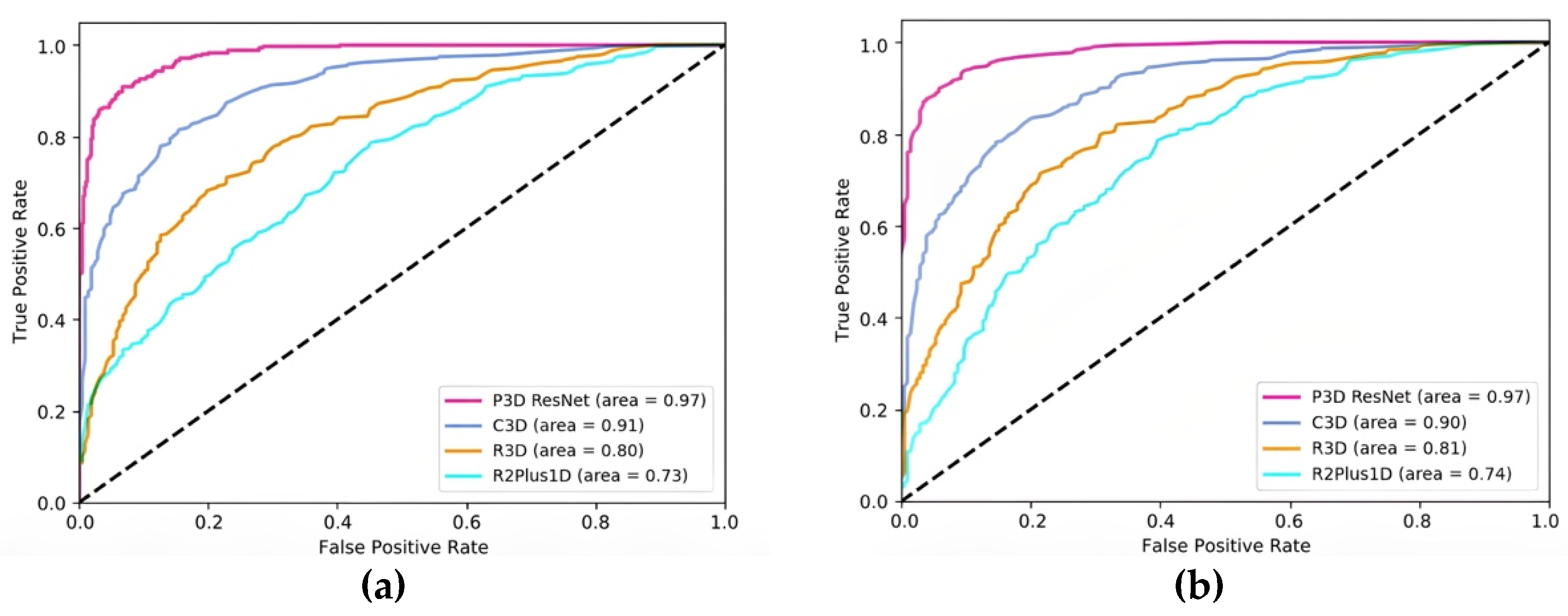
3.6. Comparison with Other Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kuroda, S. Moyamoya disease: Current concepts and future perspectives. Lancet Neurol. 2008, 7, 1056–1066. [Google Scholar] [PubMed]
- Yu, J.; Zhang, J.; Chen, J. The Significance to Determine Factors Related to Postoperative Cerebral Infarction in Patients with Moyamoya Disease. Cerebrovasc. Dis. 2020, 49, 233–234. [Google Scholar] [CrossRef] [PubMed]
- Kang, S.; Liu, X.; Zhang, D.; Wang, R.; Zhang, Y.; Zhang, Q.; Yang, W.; Zhao, J. Natural course of moyamoya disease in patients with prior hemorrhagic stroke. Stroke 2019, 50, 1060–1066. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, J.C.; Funaki, T.; Houkin, K.; Kuroda, S.; Fujimura, M.; Tomata, Y.; Miyamoto, S. Impact of cortical hemodynamic failure on both subsequent hemorrhagic stroke and effect of bypass surgery in hemorrhagic moyamoya disease: A supplementary analysis of the Japan Adult Moyamoya Trial. J. Neurosurg. 2021, 134, 940–945. [Google Scholar] [CrossRef] [PubMed]
- Jeon, C.; Yeon, J.; Jo, K.; Hong, S.C.; Kim, J.S. Clinical Role of Microembolic Signals in Adult Moyamoya Disease with Ischemic Stroke. Stroke 2019, 50, 1130–1135. [Google Scholar] [CrossRef] [PubMed]
- Jung, M.; Lee, H.; Tani, J. Adaptive detrending to accelerate convolutional gated recurrent unit training for contextual video recognition. Neural Netw. 2018, 105, 356–370. [Google Scholar] [CrossRef] [PubMed]
- Takagi, Y.; Kikuta, K.; Nozaki, K.; Hashimoto, N. Histological features of middle cerebral arteries from patients treated for Moyamoya disease. Neurol. Med.-Chir. (Tokyo) 2007, 47, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, J.; Takaku, A. Cerebrovascular “moyamoya” disease. Disease showing abnormal net-like vessels in base of brain. Arch. Neurol. 1969, 20, 288–299. [Google Scholar] [CrossRef] [PubMed]
- Kobayashi, N.; Saito, Y. Infarction and circulation in cerebrum effect of recanalization and/or collateral circulation on the lesion and prognosis. Neuroradiology 1978, 16, 108–112. [Google Scholar] [CrossRef] [PubMed]
- McDermott, M.; Jacobs, T.; Morgenstern, L. Critical care in acute ischemic stroke. Handb. Clin. Neurol. 2017, 140, 153–176. [Google Scholar] [PubMed]
- Kim, T.; Heo, J.; Jang, D.K.; Sunwoo, L.; Kim, J.; Lee, K.J.; Kang, S.H.; Park, S.J.; Kwon, O.; Oh, C.W. Machine learning for detecting moyamoya disease in plain skull radiography using a convolutional neural network. EBioMedicine 2019, 40, 636–642. [Google Scholar] [CrossRef] [PubMed]
- Akiyama, Y.; Mikami, T.; Mikuni, N. Deep learning-based approach for the diagnosis of moyamoya disease. J. Stroke Cerebrovasc. Dis. 2020, 29, 105322. [Google Scholar] [CrossRef] [PubMed]
- Dong, M.; Fang, Z.; Li, Y.; Bi, S.; Chen, J. AR3D: Attention Residual 3D Network for Human Action Recognition. Sensors 2021, 21, 1656. [Google Scholar] [CrossRef] [PubMed]
- Ahad, M.A.R.; Ahmed, M.; Antar, A.D.; Makihara, Y.; Yagi, Y. Action recognition using Kinematics Posture Feature on 3D skeleton joint locations. Pattern Recognit. Lett. 2021, 145, 216–224. [Google Scholar] [CrossRef]
- Bi, Z.; Huang, W. Human action identification by a quality-guided fusion of multi-model feature—ScienceDirect. Future Gener. Comput. Syst. 2021, 116, 13–21. [Google Scholar] [CrossRef]
- Ding, W.; Ding, C.; Li, G.; Liu, K.; Ding, G. Skeleton-Based Square Grid for Human Action Recognition with 3D Convolutional Neural Network. IEEE Access 2021, 9, 54078–54089. [Google Scholar] [CrossRef]
- Hu, T.; Lei, Y.; Su, J.; Yang, H.; Ni, W.; Gao, C.; Yu, J.; Wang, Y.; Gu, Y. Learning spatiotemporal features of DSA using 3D CNN and BiConvGRU for ischemic moyamoya disease detection. Int. J. Neurosci. 2023, 133, 512–522. [Google Scholar] [CrossRef] [PubMed]
- Majhi, S.; Dash, R.; Sa, P.K. Temporal pooling in inflated 3DCNN for weakly-supervised video anomaly detection. In Proceedings of the 11th International Conference on Computing, Communication and Networking Technologies, Kharagpur, India, 1–3 July 2020; pp. 1–6. [Google Scholar]
- Zhu, G.; Zhang, L.; Shen, P.; Song, J.; Shah, S.A.A.; Bennamoun, M. Continuous gesture segmentation and recognition using 3DCNN and convolutional LSTM. IEEE Trans. Multimed. 2019, 21, 1011–1021. [Google Scholar] [CrossRef]
- Kim, S.Y.; Lim, J.; Na, T.; Kim, M. Video super-resolution based on 3D-CNNS with consideration of scene change. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 2831–2835. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3D residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- Wang, G.; Li, W.; Ourselin, S.; Vercauteren, T. Automatic Brain Tumor Segmentation Using Convolutional Neural Networks with Test-Time Augmentation. In Proceedings of the International Workshop on Brainlesion, International Conference on Medical Imaging Computing for Computer Assisted Intervention, Granada, Spain, 16 September 2018; pp. 61–72. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.; Paluri, M. ConvNet architecture search for spatiotemporal feature learning. arXiv 2017, arXiv:1708.05038. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; Lecun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Precision | Recall | Specificity | F1 Score | AUC |
|---|---|---|---|---|---|
| Mild | 0.95 | 0.932 | 0.976 | 0.941 | 0.96 |
| Moderate | 0.951 | 0.951 | 0.976 | 0.951 | 0.96 |
| Severe | 0.971 | 0.99 | 0.985 | 0.98 | 0.99 |
| Model | Accuracy |
|---|---|
| P3D-A ResNet | 0.9285 |
| P3D-B ResNet | 0.9318 |
| P3D-C ResNet | 0.9383 |
| P3D ResNet | 0.9578 |
| Dilation Rates | Accuracy |
|---|---|
| 1 | 0.9448 |
| 2 | 0.9578 |
| 3 | 0.9318 |
| 4 | 0.8961 |
| Model | Pretraining | Accuracy | Parameters |
|---|---|---|---|
| R2Plus1D | / | 0.7370 | 33.18 M |
| R3D | / | 0.7922 | 33.18 M |
| C3D | √ | 0.8961 | 78.01 M |
| P3D ResNet | √ | 0.9578 | 65.68 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Wu, J.; Lei, Y.; Gu, Y. Application of Pseudo-Three-Dimensional Residual Network to Classify the Stages of Moyamoya Disease. Brain Sci. 2023, 13, 742. https://doi.org/10.3390/brainsci13050742
Xu J, Wu J, Lei Y, Gu Y. Application of Pseudo-Three-Dimensional Residual Network to Classify the Stages of Moyamoya Disease. Brain Sciences. 2023; 13(5):742. https://doi.org/10.3390/brainsci13050742
Chicago/Turabian StyleXu, Jiawei, Jie Wu, Yu Lei, and Yuxiang Gu. 2023. "Application of Pseudo-Three-Dimensional Residual Network to Classify the Stages of Moyamoya Disease" Brain Sciences 13, no. 5: 742. https://doi.org/10.3390/brainsci13050742
APA StyleXu, J., Wu, J., Lei, Y., & Gu, Y. (2023). Application of Pseudo-Three-Dimensional Residual Network to Classify the Stages of Moyamoya Disease. Brain Sciences, 13(5), 742. https://doi.org/10.3390/brainsci13050742