1. Introduction
Alzheimer’s disease (AD) is an incurable neurological disorder that causes the degeneration of neurons in the brain, progressing first from dementia to the eventual inability of the brain to conduct basic bodily functions. AD incidence is increasing and is projected to rise to 13.8 million Americans by 2060 [
1]. AD is the most common form of dementia, making up an estimated 60% to 80% of global cases of dementia. With the world population aging, people over the age of 65 are expected to increase by 50% halfway through the century, and the social and economic impact of AD is expected to grow rapidly. Current data suggest that 68% of this growing impact is expected to occur in low- and middle-income countries. Age and heredity are the two key risk factors for the onset of AD. However, the understanding of AD etiopathogenesis remains an enigma. There is an unmet need to uncover the underlying mechanism(s) of the onset and progression and to identify biomarkers associated with onset to be able to screen vulnerable populations, diagnose at-risk patients early, and monitor progression and response to therapeutics [
2].
Being a progressive disease, AD manifests initially with preclinical AD through subjective cognitive impairment (not all cases transition to AD), then mild cognitive impairment (MCI), and finally dementia (which continually worsens over time), making it paramount that the disease be detected as early as possible in order to slow its progression and impact [
1]. Currently, the diagnosis of AD using conventional clinical methods requires a specialty clinic, which can be invasive, expensive, and time-consuming. Additionally, these methods are often inaccurate and not cost-effective, particularly in identifying the early stages of the disease. Furthermore, nonspecialist clinicians often struggle to accurately identify early AD and MCI. As a result, there is a growing demand for noninvasive and/or cost-effective tools that can identify individuals in the preclinical or early clinical stages of AD, allowing for early interventions that could improve lifestyle and for the evolution of pharmacological treatments. This is particularly important for lower-income individuals who may have fewer resources to cope with AD; therefore, a more effective, accurate, and cost-effective way of detecting early AD is necessary [
3].
As the stages of AD progress, aphasia (the inability to understand or formulate language) and dysgraphia (the inability to write), some of AD’s most common symptoms, become worse, being marked by a predictable set of changes. Firstly, language and speech are impaired by the inability to find certain words, most commonly those pertaining to items or people the patient interacts with often, causing an increase in the use of pauses and filler words. In later stages, these symptoms are exacerbated, and the patient’s verbal acuteness and fluency are significantly impaired [
4]. While some studies have shown that not all facets of speech and language change drastically in the first stages of the disease, the linguistic quality and complexity of the content of patients’ speech does, making it possible for artificial intelligence (AI) to conduct natural language processing (NLP) tasks for the automatic detection of AD (ADAD), based partially or entirely on the patient’s language [
5,
6].
NLP is a cross-disciplinary technique that aims to enable AI, specifically through large language models (LLMs), to understand and process text, enabling it to convey meaning to other models that can create summaries, responses, or, in this case, classify text. Thanks to the massive advances in LLMs and AI as a whole, in recent years, NLP methods have improved drastically, enabling models to understand deeper and more complex semantic features [
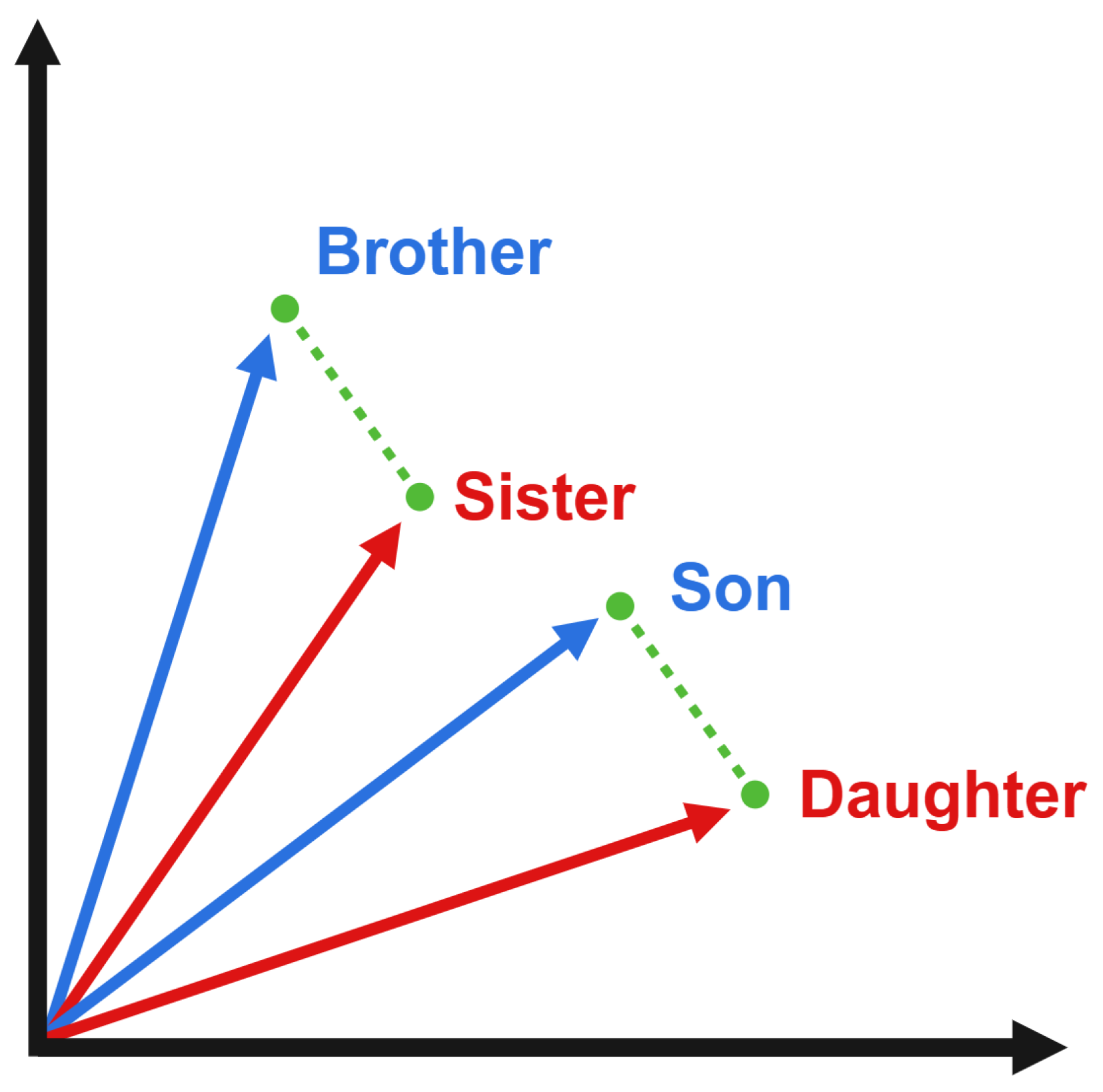
7]. To perform NLP, most models use word embeddings, which are N-dimensional vector representations of words (
Figure 1). Embeddings allow neural networks (NNs) and other machine learning classifiers (MLCs) to process language through semantic meaning, unlike other techniques that focus on the frequency of specific words, among other aspects [
8]. One of the most advanced LLMs is OpenAI’s Generative Pre-trained Transformer 3 (GPT-3), which is known for its use in ChatGPT. Based on the GPT-3 architecture, OpenAI offers a set of highly advanced, cost-effective embedding models [
9]. First-generation versions of these models have shown promising results when it comes to the NLP-based automatic detection of AD [
10].
Past research into the automatic detection of AD using speech has focused on using either acoustic features or NLP techniques [
10,
11]. While acoustic feature-based models have been shown to perform effectively, achieving accuracies of 63.6% in Chlasta and Wolk’s work [
12] using a convolutional neural network (CNN) and 65.6% in Balugopalan and Novikova’s work [
13] using a support vector machine (SVM) classifier, Balugopalan and Novikova showed that a word embedding or combination approach was more effective. They performed better in nearly all metrics using several machine learning classifiers, achieving an accuracy of 66.9% for embeddings and 69.2% for the combination using SVM. Cruz et al. [
14] used NLP techniques, specifically sentence embeddings, using Siamese BERT-Networks (SBERT) to create embeddings and test the effectiveness of several types of ML classifiers. They found that SVMs and neural networks (NNs) were the most effective, achieving accuracies and F-1 scores (the harmonic mean of precision and recall) of 0.77 and 0.80 (SVM) and 0.78 and 0.76 (NN), respectively.
Agbavor and Liang built upon the research of both Balugopalan and Novikov and Cruz et al. [
14] Using audio files from the ADReSSo dataset, they extracted acoustic features, and they converted audio to text automatically using a transcription program, extracting embeddings using OpenAI first-generation embedding models. Using these acoustic features and embeddings, they trained multiple models using different combinations of NLP methods and ML classifiers. When comparing models, they found that the most effective model produced used only word embeddings, and it was classified using an SVM. This model was able to achieve an accuracy of 0.803 and 0.829 for accuracy and F-1 [
10]. These results demonstrate that the integration of SVM classifiers with advanced word embeddings constitutes one of the most efficacious approaches in the scientific domain for automatic Alzheimer’s disease detection.
This study aims to build on past research and optimize an NLP-based automatic AD detection system, increasing its performance. By optimizing the methods required to implement one of these systems, we hope to characterize the full potential of this technology in its current form while also identifying areas of improvement necessary to assist in the creation of a real-world application. Specifically, using audio files from the Pitt Corpus of the Dementia Bank Database, we aim to optimize the transcription process to increase the quality of the GPT word embeddings and the subsequent classification models that they train [
15,
16]. We will exclusively use GPT word embeddings and SVM classifiers to test the effectiveness of these techniques due to their proven efficacy in previous studies. To optimize these methodologies, we seek to evaluate the performances of several AI-based audio transcription systems, using cloud- and locally-based transcription services, in addition to an audio enhancement system to aid in automatic transcription. We also aim to compare the performance of manual transcripts to those made with AI and seek to understand the impact of including interviewers in recordings. Using these various methodologies, we will characterize their performances in various classification tasks utilizing different diagnosis types.
2. Methodology
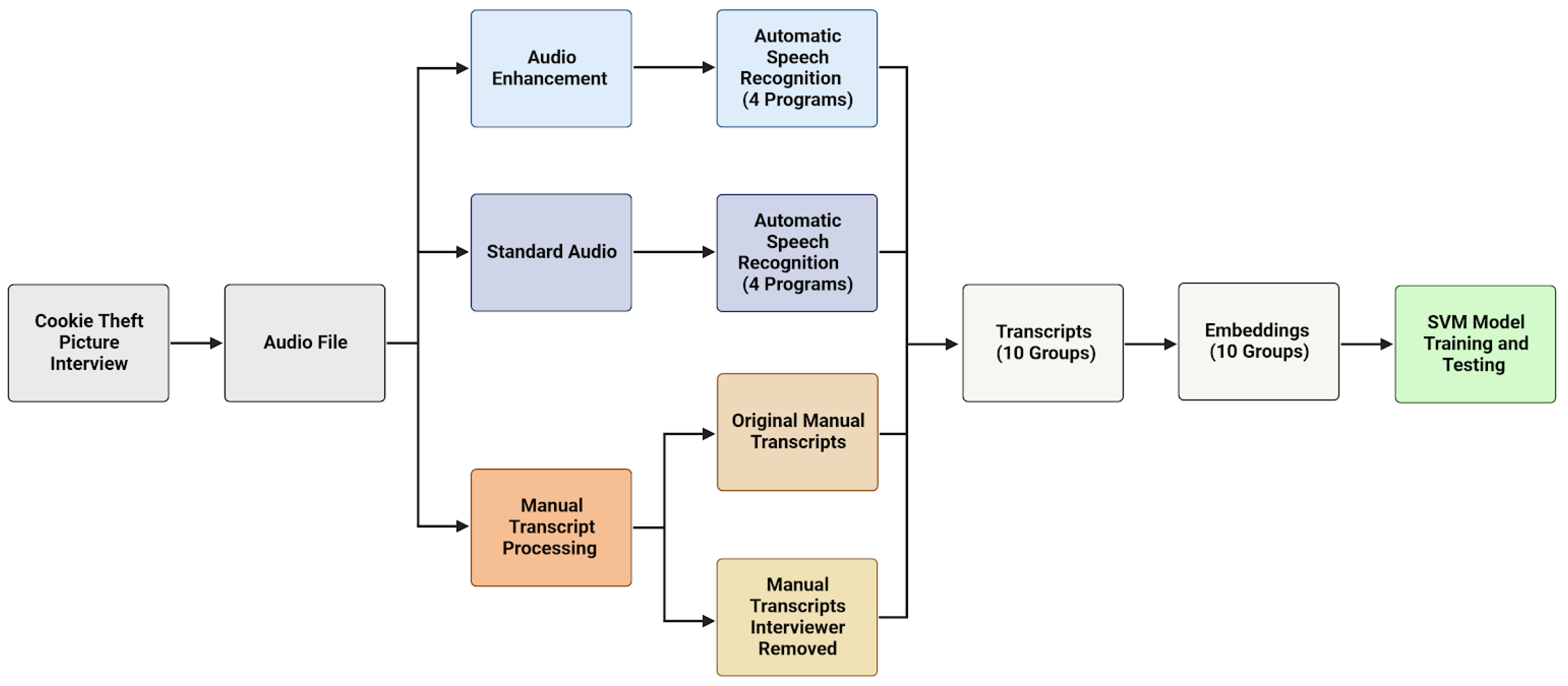
The overall approach of this study can be explained as follows, and a visual overview of the process can be found in
Figure 2.
2.1. Database Information
For the study, we used the Pitt Corpus, which can be found in the Dementia Bank Database [
15]. Dementia Bank is a database that is part of the Talk Bank project, which collects and makes available several different types of multimedia files that relate and can contribute to the study of language and communication of dementia [
16]. The Pitt Corpus, which is derived from Becker et al. [
15], was gathered as part of a larger project to study dementia at the University of Pittsburgh School of Medicine. According to the data sheet available with the Pitt Corpus, the dataset included 244 samples of Probable AD, 87 samples of Possible AD, 16 samples of Vascular Dementia, 6 samples of other dementias, 12 samples of people who had cognitive problems yet lacked a diagnosis, 23 samples of MCI, and 121 samples of a Control group.
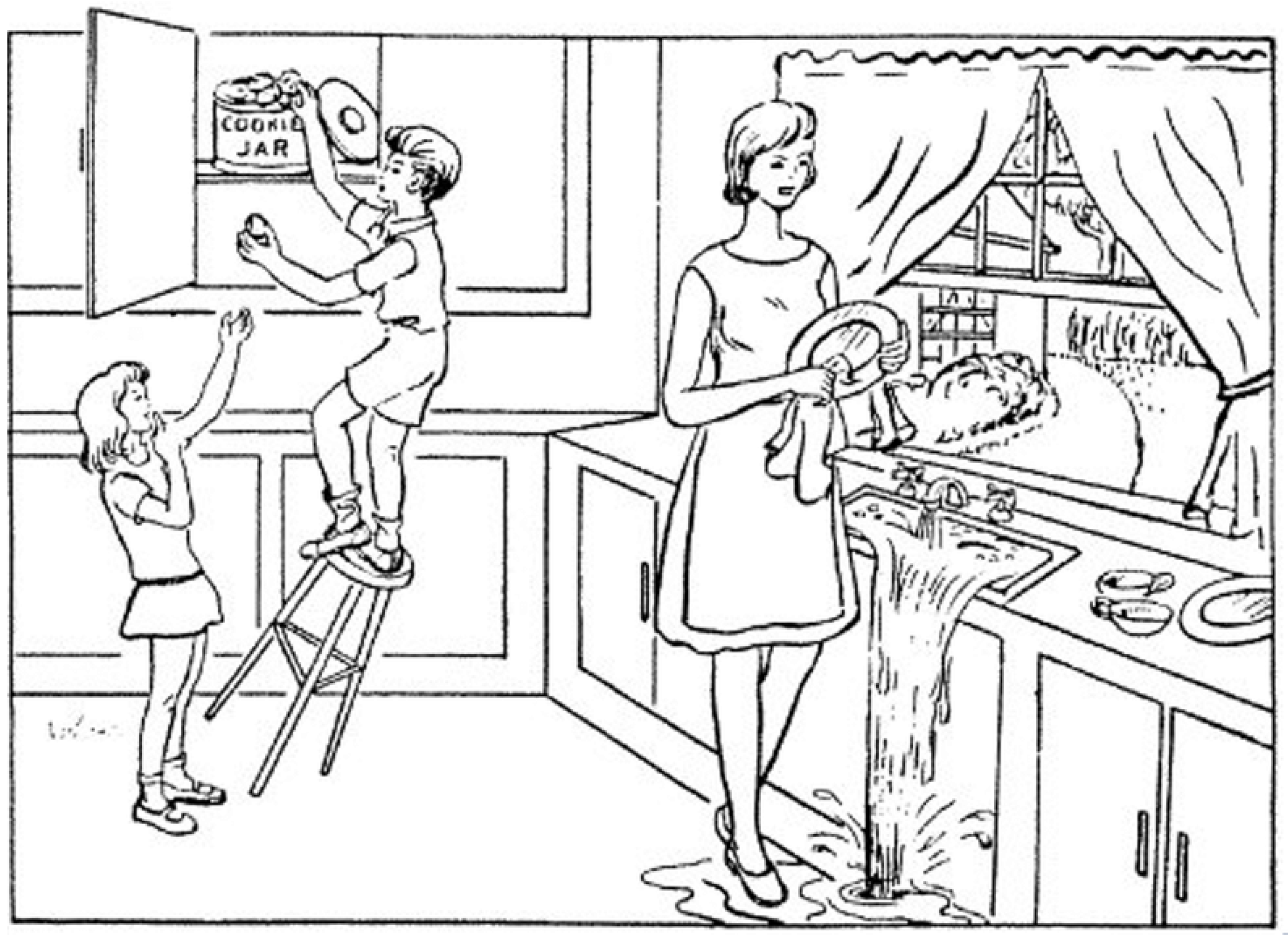
For every individual interview (sample), an original audio file, an enhanced audio file, and a written transcript in CHAT file format of the patient describing the Cookie Theft image (
Figure 3) were included as well [
15]. The Cookie Theft image is an image included in a sub-test of the Boston Diagnostic Aphasia Examination that has risen to prominence thanks to its potential to reveal a wide range of cognitive and linguistic skills and deficits [
18]. For this sub-test, patients are shown a drawing of a mother cleaning dishes next to the sink. They are instructed to tell the interviewer all that they see going on in the picture. The Cookie Theft picture contains a wide range of describable features, including people, objects, and actions [
19].
2.2. Organizing Database Data
Upon accessing the files, we immediately noticed a discrepancy between the quantities of samples listed and those actually available. This meant that it would be impossible to sort through the included files using the available data sheet. Instead, we opted to write a program using the Python (3.11.4) programming language that separated all of the original (or standard quality) and enhanced audio files as well as the manual transcripts by diagnosis type using the diagnosis information available in the CHAT file format of the transcripts. Once both types of audio files and the CHAT transcripts were organized by diagnosis type, we re-counted the total for each diagnosis type; we found 234 samples of Probable AD, 21 samples of Possible AD, 42 samples of MCI, 3 samples of MCI with only memory problems, 5 samples of Vascular Dementia, 1 sample with another diagnosis, and 242 samples of Control. Using this information, we removed the MCI with memory problems only, vascular dementia, and other diagnosis groups, as they lacked enough data to train and test a model.
2.3. Audio Enhancement
Included in the Pitt Corpus were the original and enhanced versions of each interview’s audio file [
15]. Audio files were enhanced by removing background frequencies using an implementation of Boll Spectral Subtraction available for Mathworks MATLAB (R2020a) program [
17,
20]. Boll Spectral Subtraction works by assuming background frequencies and subtracting them from the original audio file. Spectral Subtraction offers a computationally efficient, consistent, and effective way of removing consistent background frequencies, but it is not able to remove inconsistent and random audio artifacts [
21]. This implementation of Boll Spectral Subtraction uses the first 0.25 s of audio, which is presumed by the program to be representative of background frequencies, and estimates the average background noise frequency using spectral averaging. Using this estimated frequency or range of frequencies, it subtracts them from the original audio file. Following this, a secondary residual noise reduction is done to enhance the quality of the audio files [
17].
2.4. Manual Transcript Processing
Manual transcripts included in the Pitt Corpus data are complete documentation of the interview, including the interviewer’s questions and the patient’s responses. For example, the included transcript for interview ID 002-1 starts with the interviewer asking, “What do you see going on in that picture?” and the patient responds with, “Oh, I see the sink is running” [
15]. Since the goal of the study is to optimize an NLP approach to the automatic detection of AD, removing the healthy, unaffected interviewer would remove any erroneous data that could hurt the performance of the models [
22]. While it would be nearly impossible to differentiate between the interviewer and the participant in an automatic transcript, the CHAT format of the included manual transcripts indicates the speaker for every line of text. Using this, we wrote a program in the Python programming language that created a complete, unchanged transcript and a version with the interviewer removed. These new transcripts were exported in Excel format and only included text characters, removing any special characters included in the transcripts for CHAT file formatting conventions.
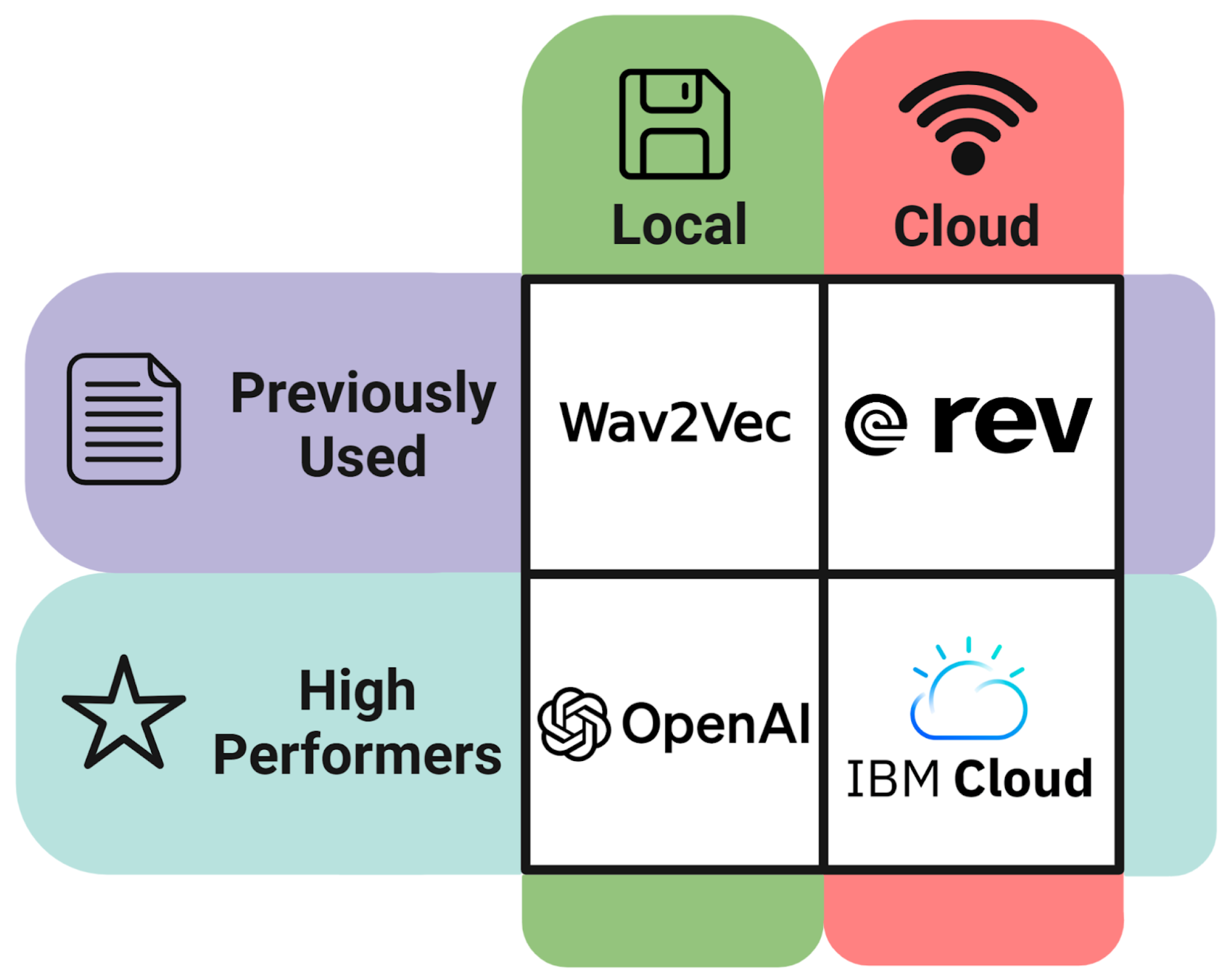
2.5. Automatic Audio Transcription
The original, or standard quality, and enhanced audio files were converted to text transcripts using four separate automatic speech recognition (ASR) programs (
Figure 4).
The first program that we used was a trained Wav2Vec model. This model showed promising results in Agbavor and Liang [
10]. The specific model that was used was the larger, most advanced model, facebook/wav2vec2-large-960h, which was trained and fine-tuned for transcription accuracy on 960 h of Librispeech on 16 kHz sampled speech audio [
23]. This model can be found on the Hugging Face platform [
24]. Audio files were transformed into waveforms using the Librosa library for Python [
25]. Then, using the Wav2Vec2Tokenizer (4.3.0), waveforms were parsed into smaller, more accessible, and computationally efficient sections. These sections were then converted into text using the Wav2Vec2ForCTC sub-model, which inherits and learns from the selected pre-trained model. Once all transcripts were created for both enhanced and standard audio, they were exported in Excel format.
The second model used for generating automatic transcriptions using ASR was Rev AI. This method, proposed by the Talk Bank project, attempts to streamline an efficient and user-friendly way of creating high-quality automatic transcriptions [
26]. The user interface is created through a program called Docker, which creates an access portal on one’s own device to upload files [
27]. Then, through the Docker portal, one uploads their Rev AI API key, allowing the interface to send the files to the Rev AI service, an industry-leading ASR program [
28,
29]. Once the files are converted to text, they are immediately downloaded to one’s computer in the CHAT file format. The Rev AI CHAT transcripts were then converted into Excel format.
The third model we used was OpenAI’s Whisper program. Whisper is an open-source, locally run ASR model that is designed to excel in a zero-shot learning environment. This means it is designed to work effectively without requiring a program to be prepared by training it with a downstream task through an approach such as fine-tuning, where one gives the pre-trained model a secondary dataset (in this case, a set of audio files and their correct transcripts) so that it can adjust to its task. Whisper was trained using 680,000 h of multilingual and multitasking supervised data from the internet, allowing it to succeed in standard benchmarks in multiple languages [
30]. Using a program written in the Python programming language, audio files were processed through the Whisper model, and the subsequent transcripts were exported in Excel format.
The final model we used for the transcription of the standard and enhanced audio files was the IBM Cloud-based Watson Speech-to-Text (STT) service. An API key was created using IBM Cloud’s web interface. Using this API key, as well as Librosa, to tokenize and partition audio files, we created a program in Python that accessed the Watson Speech-to-Text base model through the cloud [
25,
31]. Once transcripts were created, they were exported in Excel file format.
Of the ASR services used in this study, two were cloud-based—IBM Cloud Watson STT and Rev AI—and two were open-source and locally based—Wav2Vec and Whisper [
23,
28,
30,
31]. The cloud services are thought to be more advanced but require payment, using a pay-as-you-go model, as computations were performed remotely through each company’s own servers and dedicated hardware. IBM Cloud Watson STT and Rev AI both used an affordable pricing scheme of USD 0.02 per minute of audio transcribed by each service [
28,
31]. OpenAI Whisper and Hugging Face Wav2Vec transcribed files locally using the computer’s own hardware and were free to use. For each type of ASR service, whether cloud or local, one service was selected for its use or proposed in past ADAD research—namely, Rev AI for the cloud base set and Wav2Vec for the local set [
10,
26]—and one was selected for its industry-leading performance—namely, IBM for cloud-based and Whisper for local [
30,
31].
2.6. Aggregation of Transcripts
Once the manual transcripts were processed and the audio files were transcribed, we combined and organized all of the new transcripts based on each interview. For each interview, there were 10 transcripts that could be used to train separate models to compare transcript methodology performances. The final transcript types that we combined and used were as follows: Unchanged Manual Transcript, Manual Transcript Interviewer Removed (also known as participant-only), Wav2Vec Standard, Wave2Vec Enhanced, Rev AI standard, Rev AI enhanced, Whisper Standard, Whisper Enhanced, IBM Standard, and IBM Enhanced. These transcripts were all combined in an Excel spreadsheet, where each row included interview information and 10 subsequent transcriptions using each methodology. Interviews that were unable to be transcribed through one of the methodologies were dropped from the data. In total, 18 interviews were removed: 9 from control, 7 from AD, 2 from MCI, and 0 from Possible AD. The final sizes of each diagnosis group in this study were 233 samples of Control, 227 samples of Probable AD, 40 samples of MCI, and 21 samples of Possible AD (
Table 1).
2.7. Creation of Embeddings
Embeddings were created using the OpenAI second-generation embedding model, called text-embedding-ada-002. An interpretation of word embeddings can be seen in
Figure 1. First proposed by Agbavor and Liang [
10], the first-generation OpenAI embedding models showed promising results, contributing to an approach that achieved an accuracy of 80.3%. Using the Python Pandas library, a data analysis package for Python (3.11.4), the combined transcripts were loaded as a data frame [
32]. Using this data frame and an OpenAI API key, we created an embedding program for all the transcripts using the second-generation embedding model through API requests to OpenAI’s servers [
9]. Pricing for the OpenAI second-generation embedding model is USD 0.0004 per 1000 tokens (which is slightly less than a word) or around 3000 pages per USD 1, much cheaper than the various first-generation models, which had worse performance and ranged from 6 to 300 pages per USD 1 [
33].
2.8. SMOTE
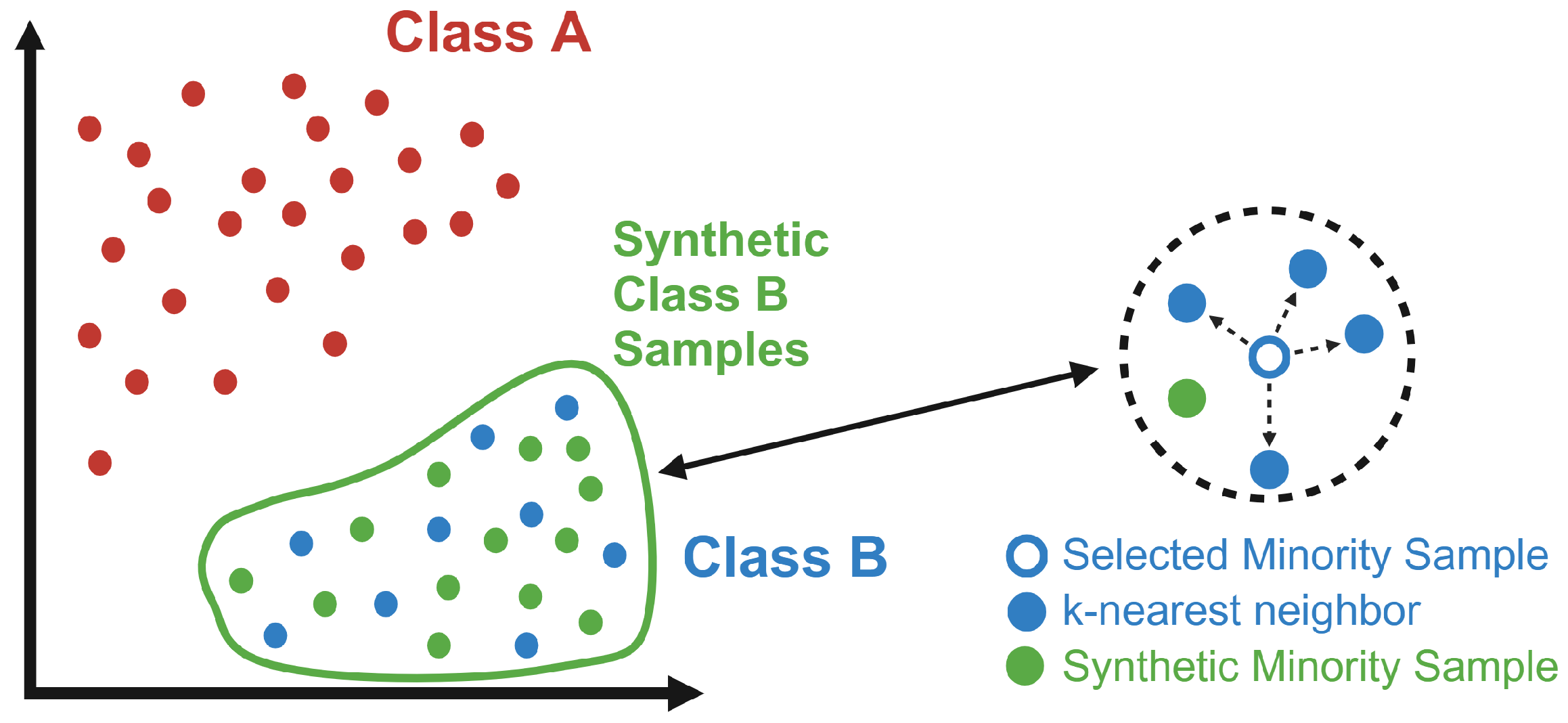
Once embeddings were created, we applied the Synthetic Minority Over-sampling Technique (SMOTE) to balance out the datasets. Balanced datasets are essential for machine learning classifier performance [
34]. SMOTE can be accessed through the imbalanced-learn library for Python [
35]. SMOTE is an algorithm that performs data augmentation and balancing by creating synthetic data based on the original minority data points. SMOTE works by selecting random minority data points, estimating their Euclidean distance from their k-nearest neighbors, multiplying the distance between the parent point and each k-nearest neighbor by a random number between 1 and 0, and then adding up those values to create a vector that is applied to the parent data point to create the synthetic one [
34]. However, since text-embedding-ada-002 generates embeddings with a dimensional size of 1536, we acknowledge the potential limitations of using SMOTE, as it is most effective within feature sizes below 1000, introducing possible distortions and bias into the data [
33,
36]. Future and more advanced embedding models that produce embeddings with fewer but higher quality and more useful dimensions or more advanced data augmentation techniques tailored for high-dimensional data would be more effective. Simply, SMOTE estimates the general area of the minority samples and creates synthetic samples in that general area to balance out the datasets. SMOTE was applied to the MCI and Possible AD diagnosis types, increasing their sample sizes from 40 and 21 to 100 each (
Figure 5). The final size of each diagnosis type, including synthetic data, is 233 samples of Control (unchanged), 227 samples of Probable AD (unchanged), 100 samples of MCI, and 100 samples of Possible AD.
2.9. Data Subgroups for Classifier Models
Since SMOTE is not a perfect technique for data augmentation, as it still relies on past data to create synthetic data, and since the number of dimensions of our embeddings exceeds SMOTE’s most effective dimensional range, some degree of bias will be introduced into models using data augmented by SMOTE. Therefore, for the proposed comparisons that this study is trying to achieve, we created several models for each transcription methodology using different combinations of diagnosis types (
Table 2). The first data subgroup that we used for model training included all the Control and AD samples (approximately 230 each). This set of data gave us the most unbiased results, as it lacked any synthetic data and used all the data samples available for those two subgroups. The second is a subgroup that only used the downsized sample sizes for Control and AD (100 each). This subgroup lacks any bias from synthetic data but does not use all the data available (for Control and AD) so that it can be used for comparisons with other studies that have similar sample sizes. The third is a subgroup that only uses the downsized sample sizes for Control and AD and uses the synthetically up-scaled MCI sample size (100 each). These data will have some bias, as the MCI data type has been augmented with SMOTE and not all the samples of AD and Control will be used, as the sample size for each class needs to be equal. The final subgroup used 100 samples of all the data types: Control, AD, MCI, and Possible AD. This model will have the most bias since two of its classes have been augmented using SMOTE.
For the last two subgroups (AD, MCI, and Control (100×) and AD, MCI, Possible AD, and Control (100×)), which use synthetic data due to the lack of data available, both the train–test split and the 10-fold CV were run after data augmentation, since there were not enough samples to split data first and then augment the data with each separated group. This circumstance increases the bias produced by data augmentation, since features extracted from an original sample could appear in a synthetic sample in the other class.
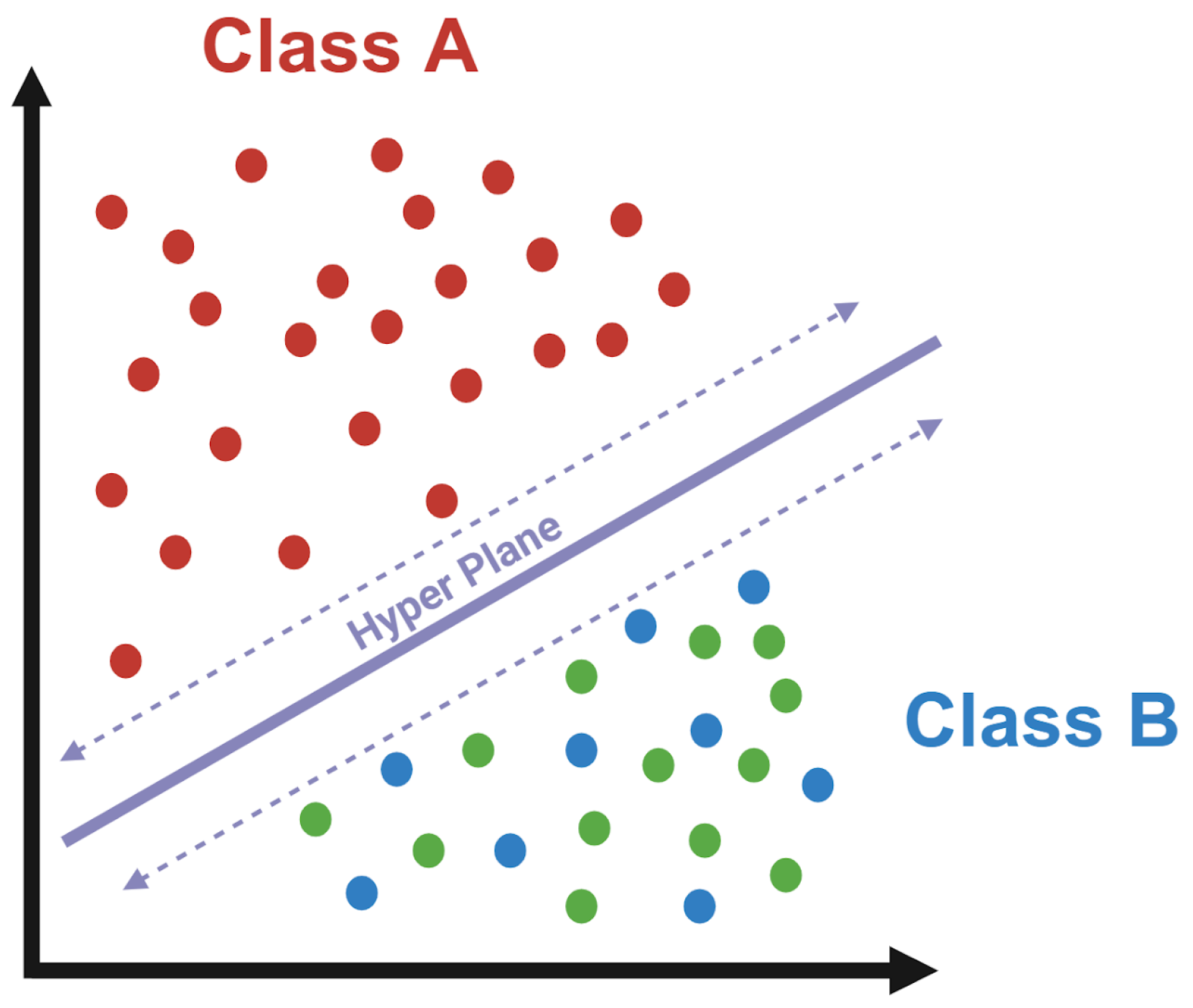
2.10. SVM Training and Testing
For diagnosis classifications, this study used a support vector classifier (SVC). A visual interpretation of an SVC can be seen in
Figure 6. In Agbavor and Liang [
10], SVCs were shown to have the best classification performance when compared to Random Forest (RF) and Logistic Regression (LR) classifiers for the binary classification of AD and Control. Building upon this research, we have chosen to train various SVCs using all four subgroups for every transcription group/methodology. SVCs and SVMs can be accessed using the SciKit-Learn platform and Python library [
37]. The NumPy and Pandas Python libraries were imported and used to format and process data/results [
32,
38], and the Matplotlib Python library was used to export model performances in a graphical format [
39].
The first model that was trained for every data subgroup used an 80/20 train–test split. Commencing with data preprocessing, the dataset was divided into distinct components, namely an 80% training set and a 20% testing set. To characterize the trained models’ full capabilities and potentials, we used the capabilities of the GridSearchCV object, which systematically traversed an array of parameter combinations (regularization parameter C, kernel selection, polynomial degree (where relevant), and the kernel coefficient gamma) through cross-validation (CV), finding the most effective settings for each model. Upon successful completion of the tuning process, the highest-performing model was automatically selected, and it was subsequently retrained using the determined optimal hyperparameters. For hyperparameter tuning, only the training data were used. Using this optimally tuned SVM classifier, the model performance was quantified using the unseen test data. All models (for each transcript methodology) used the transcripts of the same interviews for their own training and testing samples to allow for a more accurate and direct comparison.
A second SVM classifier was created to test model generalizability using a 10-fold cross-validation technique. We executed an 80/10/10 train–validation–test split to rigorously evaluate the performance of a support vector machine (SVM) classifier with a linear kernel. In this code, we performed k-fold cross-validation, where k is set to 10, to evaluate the performance of a support vector machine (SVM) classifier with a linear kernel. The dataset was initially split into 10 approximately equal and stratified subsets. Each of these subsets, referred to as “folds”, played a distinct role in the cross-validation process. During each iteration of the loop, one fold served as the validation set, while the remaining nine folds were used for training a linear SVM model. The “random_state” was set for each fold to ensure reproducibility and uniqueness. With each trained model, we then made predictions on the validation set and assessed its performance. The results of each fold, encompassing all the performance metrics, were collected in separate lists, allowing for the evaluation of the SVM model’s ability to generalize effectively across different subsets of the data.
4. Discussion
4.1. Data Used for Direct Comparisons and Observations of Transcription Methodologies
The data used for making direct comparisons between transcription methods are the AD and Control (230×) subgroups. AD and Control (230×) are also used to posit the most effective model as a whole created by this study. This group has the lowest amount of bias, as it does not include any synthetic data and uses all the data available to it. Furthermore, for comparisons between models, we use the data from the train–test SVM classifier, as all models (within the same subgroup) used samples from the same exact interview for their respective training and testing groups, which is not the case for the cross-validation test.
AD and Control (100×) are used to make overall comparisons to other studies that have predominantly used smaller databases of a similar size to this data group, such as the ADReSSo challenge and dataset, which has a size of 237 samples, around 120 samples per group. ADReSSo is a recurring competition that aims to create the best model for detecting and differentiating between AD and Control diagnoses using any audio-based method [
41]. This subgroup lacks any bias from synthetic data, but since it does not use all of the data available to it, it cannot find the most accurate results possible for each methodology and thus is not used for direct comparisons between methodologies.
The last two data subgroups are used to analyze the preliminary possibility of detecting MCI and Possible AD, as these subgroups include some degree of bias from synthetic data.
4.2. AD and Control (100×) Subgroup Results and Comparisons with Previous Studies
The results of the AD and Control (100×) subgroup are very promising. As stated earlier, four models achieved perfect or near-perfect results: Rev AI Enhanced and Wav2vec Enhanced, which performed perfectly (accuracy and F-1 of 1.00), as well as IBM Cloud Standard and Rev AI Standard, which were near-perfect (accuracy and F-1 of 0.98). Five of the remaining models achieved scores in the low 0.90 s and high 0.80 s, which are still extremely impressive. The Wav2Vec Standard scored 0.84 for accuracy and F-1 score, which was still quite good despite being the worst-performing model. When comparing the train–test split scores to the cross-validation results, they were overall much lower, only ranging from 0.80 to 0.63 for accuracy and 0.79 to 0.60 for F-1 score. This discrepancy is most extreme for some of the best-performing models in the train–test split test, which performed near the bottom for cross-validation. This is the case for the Rev AI Standard and Enhanced, which only scored 0.63 and 0.65 for accuracy and 0.60 and 0.64 for F-1 score, and not for Wav2Vec Enhanced and IBM Cloud Standard.
While this discrepancy between the performance of the train–test split and cross-validation in the Rev AI models is a possible indicator of overfitting, usually caused by a data leakage or a dataset that is too small (which this dataset is at risk of), the results of the Wav2Vec Standard model give the other results of this data subgroup credence for comparisons with other studies [
42]. This is because, when examining the results of Agbavor and Liang [
10], who used a methodology nearly identical to the Wav2Vec Standard, which included training on the ADReSSo dataset (120 for both AD and Control), using the standard audio of the study, and using Wav2Vec transcriptions, which were turned into embeddings using the GPT first-gen models, their performance is very similar. While we achieved 0.84 for accuracy and F-1 (train–test) for the Wav2Vec Standard methodology, they scored 0.803 for accuracy and 0.829 for F-1 using an SVC [
10]. Therefore, while some of the models are suffering from overfitting due to their poor generalizability when compared to train–test data, the similar performances of the Wav2Vec Standard methodology show that the rest of the transcript methodologies are much more effective overall than the previously used Wav2Vec Standard transcription methodology. This large improvement in performance indicates that, through the optimization of transcriptions, the performance of embedding-based AD detection programs can be improved dramatically.
4.3. Interpretation of the AD and Control (230×) Subgroup
Overall, the performance of the models using the AD and Control (230×) subgroup remained excellent. The best model by far was Wav2Vec Enhanced, which achieved an accuracy and F-1 of 0.99. Besides both Manual Transcript methodologies, Rev AI Enhanced, and Wav2Vec Standard method, the remaining five methodologies (IBM Cloud, OpenAI Whisper, and Rev AI Standard) had excellent performances, all achieving F-1 and accuracies between 0.91 and 0.96, which still outperform almost all other automated AD detection systems. The performance of both Manual Transcripts and Wav2Vec Standard was still quite good, scoring just below 0.90 in the upper 0.80s. The only poorly performing model was Rev AI Enhanced, which only was able to score an accuracy of 0.79 and an F-1 score of 0.78.
When compared to the results of the AD and Control (100×) subgroup, the performance of the AD and Control (230×) subgroup was much more consistent, which is to be expected when a larger sample size is used. The best-performing model was still Wav2Vec Enhanced, whose accuracy and precision only decreased by 0.01, to 0.99, when using more data samples. The other models that performed extremely well using the smaller dataset, Rev AI Enhanced/Standard and IBM Cloud Standard, had their train–test performances decrease and their CV performances increase. While Rev AI standard and IBM Cloud Standard were still the second and third best models using the train–test Split and the larger dataset, Rev AI Enhanced became the worst, having a similar train–test split performance as its CV scores (0.77 for accuracy and 0.76 for F-1). When we compare the train–test Split results to the CV results, the gap is smaller with the larger dataset (AD and Control (230×)) than with the smaller one (AD and Control (130×)). Similarly, the best-performing models for the larger dataset using the train–test split test (Wav2Vec Enhanced, Rev AI Standard, and IBM Cloud Standard) were not the worst models when it came to the CV, all scoring near the middle of the pack. Since the gap between the train–test Split and CV results decreased and the overall performances between both tests became more consistent, the larger database clearly helped mitigate the overfitting experienced by the models using the AD and Control (100×) data subgroup.
4.4. Negative Impact of Interviewer on Model Performance
When comparing both of the Manual Transcript methodologies, one can observe that there is a minor difference in performance. While the Manual Transcripts Unchanged model scored 0.87 for both accuracy and F-1, the Manual Transcripts Participant Only model scored 0.89 and 0.88 for accuracy and F-1, respectively. This improvement in performance indicates that it could be advantageous in the long run to remove interviewers from audio transcripts. This could be done in three ways, either by instructing the interviewer to begin the recording after the instructions, having the interviewer say a start and stop phrase between questions (so that their words could be removed), or through some sort of AI implementation (through voice recognition technology). Since more data are needed to more thoroughly test some of the methods proposed by this study and others so that a real-world application can be made, these suggestions should be taken into consideration when collecting data for a new database.
4.5. AI Transcription Models Outperforming Manual Transcripts
Interestingly, almost all of the AI-based ASR methodologies outperformed the pre-existing manual transcripts, despite some transcripts not having the same quality as the manual transcripts. For example, one phrase was manually transcribed as “the scene is in the in the kitchen, the mother is wiping dishes”, while Wav2Vec Standard transcribed it as “THE SEM IS IN E BIN KITCHEN A MOTHER IS WIPING DISHES”. Wav2Vec Standard outperformed the Manual Transcripts Unchanged methodology with these poorer transcripts. The reason for this improved performance with poorer transcripts is unclear and requires further examination of transcript quality and research. One possible explanation is that the AI transcripts were unable to capture “filler”/”function” words (pronouns, prepositions, conjunctions, and interjections) that do not convey as much meaning as “content” words (adjectives, nouns, verbs), which tend to be longer and more distinct.
4.6. Effect of Audio Enhancement
There was no clear advantage to enhancing the quality of audio files. In some cases, standard audio outperformed enhanced audio, while in others, enhanced audio performed better. Interestingly, using the more advanced cloud-based transcription programs, the standard audio performed consistently better. This worsened performance when using audio enhancement with cloud-based programs might be caused by the fact that these models have been trained with background noise in mind, and thus, the background noise removal of audio enhancement presents no advantages to these models, only disadvantages, as it might cause confusing noise artifacts. On the other hand, when using the Wav2Vec method (local), audio enhancement was extremely helpful, which indicates that it struggles heavily when presented with unclear audio. For Whisper, the other local method, there was no effect of using audio enhancement. Therefore, it would only make sense to use audio enhancement for locally-based ADAD systems.
4.7. The Most Effective Methodology for Real-World Applications
Since the real-world application of a speech-based automatic detection of AD program would be greatly affected by the distinction between using a locally-based and cloud-based methodology, it is of great importance to identify and differentiate between the best methodologies using each type of technology for future research and implementations. While a locally based ADAD service would have the advantage of perfect privacy and the lack of needing to pay for API or cloud fees (as all computations would be run locally and thus would not have to be saved on external servers), it would require the use of a powerful computer which could have high upfront costs. Alternatively, cloud-based systems need only minimal hardware (enough for a user interface) and a connection to the internet but would incur constant charges due to their use of cloud computing. Furthermore, a cloud system might cause privacy concerns among patients.
Based on the results of the AD and Control (230×) subgroup, the best methodology for a locally based system is the Wav2Vec Enhanced methodology. This methodology not only performed the best out of the locally based transcription methods, scoring 0.99 for both accuracy and F-1, but was the most effective method overall. The second best overall and best cloud-based methodology was the Talk Bank-proposed Rev AI methodology (using standard audio files). This methodology was able to score an impressive 0.96 for both accuracy and F-1 score. Overall, taking into account all ASR methods, neither system completely outperformed the other, showing that either type of implementation would be effective. Regardless, before any real-world implementation could be used, further research and testing would be necessary for either of these models.
4.8. Interpretation of Remaining Subgroups
The results of the AD, MCI, and Control (100×) and AD, MCI, Possible AD, and Control (100×) subgroups were promising but suffered heavily from overfitting, which is to be expected when using synthetic data. While SMOTE can be used to create synthetic data with a lower probability of suffering from overfitting, it is still possible. While the range of the AD, MCI, and Control (100×) using the train–test split was excellent, ranging from 0.98 to 0.90 for accuracy and 0.98 to 0.98 for F-1, the results of the CV test were quite poor. For accuracy, models only ranged from scoring 0.56 to 0.45, and for F-1, 0.55 to 0.43. While the train–test results are extremely promising, the CV results show that the models trained on this subset perform quite poorly when it comes to generalizability.
The most effective models for the AD, MCI, Possible AD, and Control (100×) subgroup using the train–test split were the IBM Cloud ones, which scored 0.96 (Enhanced) and 0.95 (Standard) for both accuracy and F-1. The worst model (Rev AI Enhanced) still did quite well, scoring 0.88 for accuracy and 0.87 for F-1 score. Similarly to the previous subgroup, the range for the train–test split test was very good, while the range of the CV scores was much poorer. The CV range for this data subgroup only spanned from 0.58 to 0.44 for accuracy and from 0.56 to 0.41 for F-1 score.
As discussed previously, a large discrepancy between the train–test and CV is highly indicative of overfitting. Since the Pitt Corpus is one of the largest databases of spontaneous speech, future research focused on collecting more data for MCI and Possible AD audio samples is necessary so that the results created by this study (for the final two subgroups) can be verified using original samples.
5. Conclusions and Future Research
The results of this research show that, with the current state of audio enhancement algorithms, AI-based ASR programs, AI-generated word embeddings, and machine learning classifiers, an accurate automatic speech-based AD detection system is possible. Furthermore, both these systems could be deployed through local or cloud-based computing, as both technologies produced machine-learning classification models that achieved near-perfect results when classifying between AD and a Control. To detect other diagnoses, such as MCI, more audio data are necessary for more accurate and reliable results.
Before any of these systems can be rolled out, more audio data (in addition to clinical trials) are necessary. These models were all trained using data from one specific area and time and, therefore, suffer from some intrinsic biases. A real-world application of this technology would need data from all over the world for each language, considering the various dialects and varying vernaculars that heavily influence speech. Unfortunately, current publicly available databases are highly limited, with the Pitt Corpus used by this study ranking as one of the largest databases available [
4]. Therefore, the collection of new data and the creation of new databases are essential for the advancement of this technology.
Additionally, since data collection is vital to allow further research in this area, studies planning on creating new datasets should be sure not to include interviewers’ unaffected speech. This speech creates unhelpful biases in addition to being noisy data, lowering the overall effectiveness of the models produced.
Understanding why the poorer quality AI transcripts largely outperformed the higher quality manual transcripts is essential to further improving automatic AD detection. This would enable the further optimization of these proposed methodologies by enabling the removal of noisy data and giving insights into the parts of speech that are most important for speech-based detection systems.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}