The following segment outlines the methodology for transforming raw EEG signals into four-dimensional (4D) feature data, as well as the overall structures of the CA-ACGAN model and its constituent modules.The CA-ACGAN model is capable of accurately recognizing and generating high-quality 4D feature data.
This paper’s key symbols and terms are compiled in Abbreviations.
2.1. Model Structure
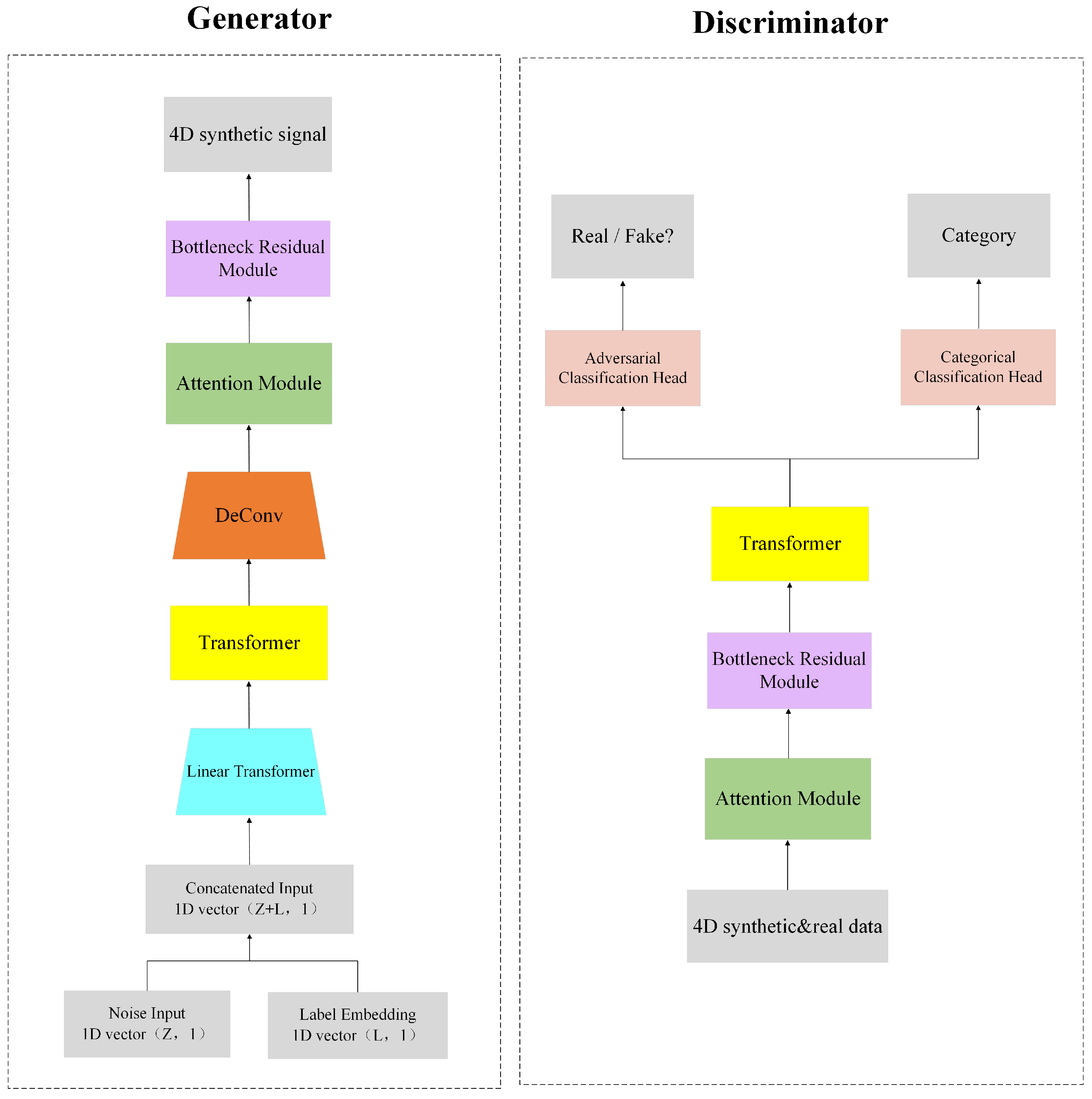
Figure 1 illustrates the overall framework of the CA-ACGAN model, which comprises a pair of key units: a generator and a discriminator. Three main modules are embedded in the ACGAN (a GAN with classification header) model: an attention module, a bottleneck residual module, and the Transformer module, which together optimize the system’s capacity for data analysis. With the attention module, the model’s frequency and spatial feature recognition is enhanced; the bottleneck residual module optimizes the computational process to extract frequency and spatial features; and the Transformer module assists the model to understand the long-term dependencies among the data.
In terms of specialized functionality, the generator G transforms the concatenated vector, comprising the noise vector z and the target categorical label l, into data through a linear mapping. The randomization in the production of the label l enhances the generator’s capability to produce data across various categories.The Transformer module receives as its input. In the data processing phase, the generator employs a Deconvolution (DeConv) layer and a reshape operation to expand the data , which has been processed by the Transformer module, into 4D feature data . This serves as the input for the attention module and the bottleneck residual module, which facilitates the generation of synthetic signal characterized by a 4D structure, denoted as . It is noteworthy that , , , and are instantiated within specific dimensional spaces, denoted as and , thereby delineating the structural framework of the generated data. In the document presented, it has been established that the value of 2T equals 16, with the parameters h, w, and d assigned the values of 6, 9, and 5 respectively.
The objective of discriminator D is to assess whether the input signal is authentic and to identify its respective category. Specifically, the real EEG data needs to be converted into 4D feature data , and either or the generated 4D data can be used as input for the discriminator. The data processing procedure encompasses a feature extraction phase, which also involves the deployment of the attention module, the bottleneck residual module, and the Transformer module. The conditional discriminator is equipped with two classification heads, one head is responsible for recognizing the truth of the signal (), and the other head is used to identify the category of the signal (), i.e., and . Such a configuration not only improves the accuracy of the model in recognizing the authenticity of data, but also enhances its classification performance, which provides effective support for handling complex data situations.
2.1.1. Constructing EEG Data with 4D Features
In recent explorations, there has been a growing trend toward amalgamating the dimensions of frequency, spatial orientation, and time within EEG data into a unified four-dimensional feature construct. This advancement is poised to enhance methodologies in fields like motor imagery processing and the identification of emotional states. A novel method for EEG-based emotion recognition using a four-dimensional convolutional recurrent neural network (4D-CRNN) [
20], which improves accuracy by integrating the frequency, spatial, and temporal information of multichannel EEG signals, has been proposed. Concurrently, the 4D Attention-Based Neural Network (4D-aNN) represents an innovative approach developed to facilitate the recognition of emotions from EEG signals [
21]. Some approaches to motor imagery processing also offer novel insights into the precise parsing of brain activity by incorporating the multidimensional aspects of EEG signals [
22].
In referring to the extant literature, the conversion of raw EEG data into a 4D format encompasses several critical steps, as depicted in
Figure 2. Initially, raw EEG signals undergo preliminary preprocessing operations, including amplification and filtering, aimed at eliminating background noise and accentuating useful signals. Subsequently, the preprocessed signals are segmented into multiple temporal segments tailored to the experimental design and analytical requirements. Afterward, various feature extraction techniques are employed in order to identify characteristics of EEG signal frequency ranges across different time intervals. This step generates a three-dimensional data structure incorporating both frequency and spatial (i.e., electrode position) dimensions. In the final stage, to accommodate the needs of further analysis or model training, these 3D data are augmented into a 4D structure through techniques such as stacking, with the fourth dimension embodying the temporal aspect. Through this series of processing, the raw EEG signals are transformed into 4D data that can comprehensively reflect the dynamics of brain activity and its characteristics.
Next, we elucidate the construction process in detail. Initially, we introduce a novel feature termed differential entropy (DE) [
23], which demonstrates stability and efficacy as a characteristic in classifying fatigue. This feature is employed to quantify the complexity inherent in continuous random variables. Calculating differential entropy relies on the random variable’s probability density function, as demonstrated in Equation (
1):
In this context, x represents a random variable, whereas signifies its corresponding probability density function.
A SEED-VIG dataset’s raw EEG signal is represented as , , where m denotes the quantity of electrode channels available, and r signifies the rate of sampling. Specifically, m is assigned a value of 17, and r, a value of 200. To align each EEG datum with its respective label, we segmented the raw EEG signals into multiple non-overlapping segments, each 8 s in length. This segmentation approach leverages the dataset’s methodology of computing a label every 8 s, which is then assigned to the corresponding EEG segment. To concurrently augment the dataset, the segments derived from EEG signals were subsequently segmented into time frames, amounting to in total, with each frame spanning a duration of half a second. EEG can be decomposed into five distinct frequency bands: (1–4 Hz), (4–8 Hz), (8–14 Hz), (14–31 Hz), and (31–51 Hz), which have been strongly associated with fatigue levels in humans. It has been found that analyzing information from these frequency bands in combination provides a more accurate monitoring of fatigue status than relying on a single band alone. Hence, we processed the EEG signals by extracting these five standard frequency bands utilizing a Butterworth filter and computing their differential entropy (DE). This procedure transformed the original EEG signal segments into DE segments, denoted as , where d signifies the count of distinct frequency bands ().
The preceding process fails to maintain the spatial relationships inherent to electrode placements. To address this limitation, DE features are transformed into a localized 2D mapping, informed by the electrodes’ physical arrangement as illustrated in
Figure 3. This can better represent the spatial relationship between electrodes. With this mapping, we generate a minimal 2D matrix that covers all the electrode locations with significant effects, and the unused electrode locations are filled with 0. Through the 2D matrix, we synthesize to reveal 3D characteristics. Subsequently, these temporal 3D characteristics,
, are superimposed to form 4D attributes,
, which can be represented as
. Here,
h denotes the vertical measurement, and
w signifies the horizontal dimension of the 2D diagram. The dataset’s spatial arrangement, consisting of 17 channels, manifests as a 2D diagram with vertical and horizontal dimensions measuring 6 and 9 units, respectively.
To encapsulate, the four-dimensional feature encompasses not only the distinct entropy traits observed in EEG signals within five distinct frequency domains, but also encapsulates spatial information pertaining to the electrode placements while maintaining the temporal continuity among successive time windows. The discriminator D receives the genuine EEG signals from the 4D characteristics as its input, with the purpose of allowing the discriminator to learn its features in order to differentiate between the genuine signals and the synthetic signals.
2.1.2. Auxiliary Classifier Generation Adversarial Network (ACGAN)
The practice of embedding labels on generators and discriminators fails to generate meaningful synthetic data. In response, we implemented a methodology that leverages label information as a conditional input for the generator. This adjustment not only streamlines the generation of multi-category data, but also enhances the overall quality and diversity of the output. In addition, a categorization header is introduced as part of the assisted categorization task, which is capable of extracting information from the middle layer of the discriminator to predict the data’s category. The classification outcome for fatigue detection, associated with the initial EEG signal fragment, is determined after contrasting the prediction with the classification threshold, as depicted in
Figure 4.
2.1.3. Spatial and Frequency Attention
Roy introduced a novel method aimed at enhancing the efficacy of image segmentation tasks. This method involves the parallel integration of spatial and channel Squeeze and Excitation (SE) modules within a fully convolutional network framework [
24]. The investigation delineates three distinct variants of the SE module: cSE, sSE, and scSE. The cSE variant amplifies the channel dimension, the sSE variant targets the spatial dimension, while the scSE variant concurrently enhances both the channel and spatial dimensions. Empirical outcomes indicate that the incorporation of the SE module markedly enhances the precision of image segmentation tasks without contributing to increased model complexity. These findings usher in novel avenues for research and furnish the medical field with innovative technological instruments, underscoring the SE modules’ capacity to significantly boost model performance.
In this study, we introduced an attention module comprising two distinct components: spatial attention and frequency attention. It incorporates mechanisms for focusing on specific spatial locations and frequency ranges. The architecture of the attention module is identically implemented within the generator and the discriminator, as shown in
Figure 5.
Initially, the framework for spatial attention is engineered to leverage the 2D layout information of the electrode placements, thereby assigning specific weights to each temporal segment. This process generates a new spatial attention feature map using a convolutional kernel for feature compression in the frequency dimension and then applying a Sigmoid function activation. This step highlights the key features in the spatial dimension and merges them with the original features to update the time segments at the spatial level.
Subsequently, the frequency attention mechanism is tasked with examining the interactions across different frequency bands (totalling five) within each temporal slice to allocate corresponding weights. By reducing the dimensions of the original feature map from a structure of down to a compact format of , and applying dual convolutional layers for the further processing of the feature matrix, followed by Sigmoid function activation, a novel map focusing on frequency-based attention features was produced. This method prioritizes the relative significance among the five frequency ranges, merging them with the primary characteristics to update the temporal segments in the frequency dimension.
By integrating spatial and frequency attention-weighted time segments, we fine-tuned the spatial versus frequency dimensions of each time segment. This approach effectively enhances the model’s attention to spatially salient features and frequency-critical features, while suppressing minor features, thus significantly enhancing the comprehensive efficacy of the framework.
Within the CA-ACGAN architecture, the attention module is pivotal, orchestrating the intricate amalgamation of 4D features across the spatial and frequency domains. This amalgamation not only elevates the 4D features’ quality, rendering them more amenable for the bottleneck residual module to distill essential spatial and frequency insights, but also maintains the congruence of the input and output dimensions. In particular, the dimensions of the output data , derived from the input 4D structural data within the discriminator, along with the dimensions of the output data , which represent the outcome of the DeConv-processed data in the generator, are consistently preserved at . Through this approach, the model adeptly modulates and amplifies the spatial and frequency information’s weights within each time segment, ensuring the precision and salience of the data within the feature stream, and thereby significantly elevating the model’s overall performance.
2.1.4. Bottleneck Residual Module
Standard Convolutional Neural Networks (CNNs) are extensively employed for their proficiency in extracting high-dimensional features pertinent to EEG signals within the realm of deep learning. Nonetheless, the advent of lightweight convolutions has garnered increasing attention amidst the burgeoning necessity for model deployment on low-power platforms characterized by constrained computational resources. This inclination is attributed to the compact architecture and enhanced efficiency of lightweight convolutions, positing them as a potential viable substitute for standard convolutions with expectations of broader application prospects in future endeavors. A pertinent study unveiled an efficient CNN variant, dubbed MobileNet, which endeavors to equilibrate the interplay among model size, computational speed, and accuracy, thereby furnishing an efficient solution for mobile and embedded systems [
25]. MobileNet harness a streamlined design, employing Deep Separable Convolution (DSC) to forge lightweight deep neural networks. This approach empowers developers to tailor the network size appropriately, aligning it with the application’s resource limitations (e.g., latency, memory footprint). Empirical assessments across various scenarios have underscored MobileNet’s superiority in balancing resource consumption against accuracy. However, the ReLU activation function of DSC may lead to a large amount of missing feature information when processing lower dimensional outputs. In addition, training convolutional kernels during depthwise convolution (DC) is challenging, especially when a large number of convolutional kernel values tend to zero. Such phenomena not only diminish the model’s feature recognition capabilities, but may also instigate gradient vanishing issues, thereby impeding the learning efficacy and overall performance of the model.
- (1)
Bottleneck residual block (BR):
Inspired by the MobileNetV2 architecture [
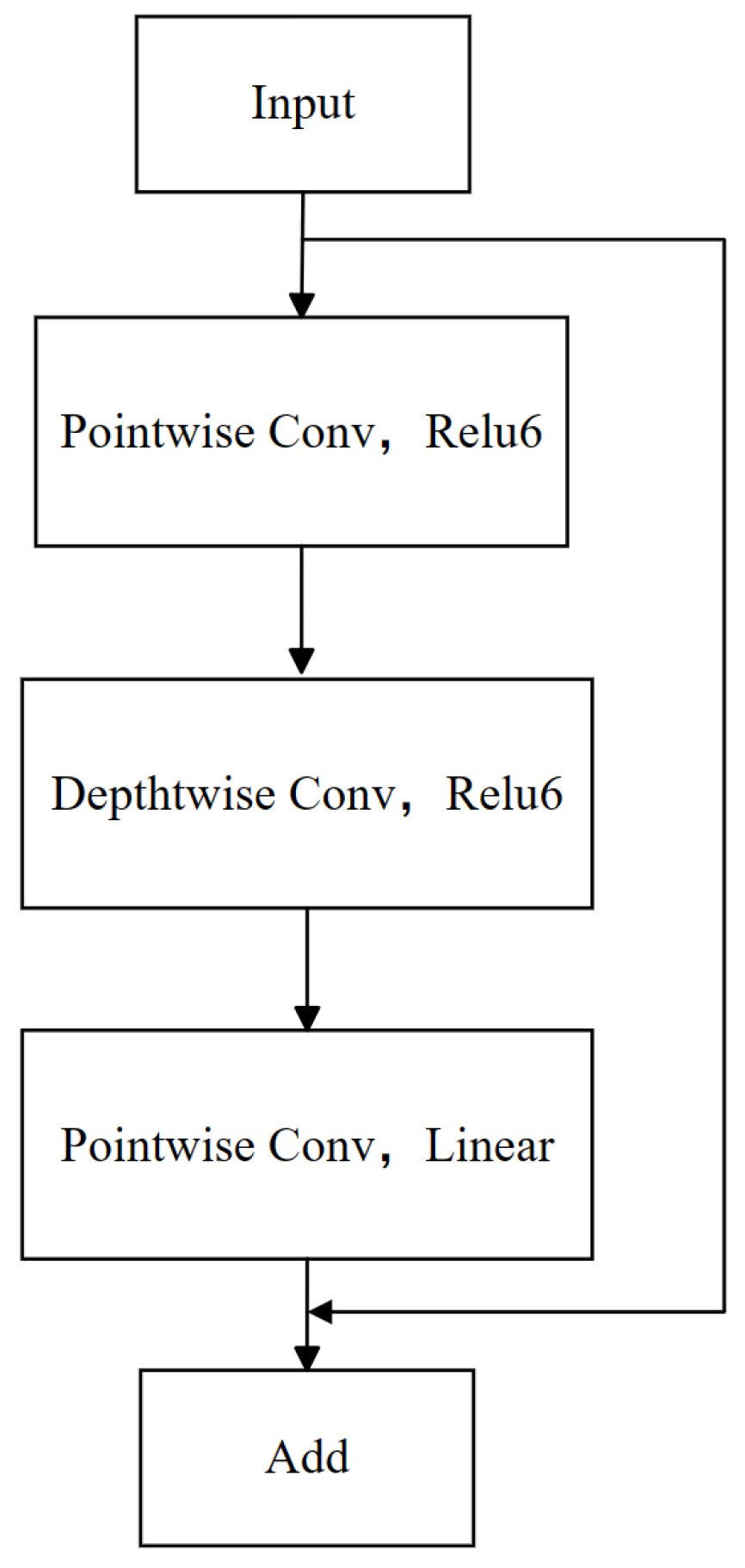
26], our model employs bottleneck residual blocks. Two core techniques were adopted to enhance the efficiency of feature extraction and reduce information loss. First, a reverse residual structure, characterized by diminished input–output dimensions and juxtaposed with an expanded middle layer dimension, is employed. This configuration facilitates the execution of convolutional operations in higher dimensions, thereby augmenting feature extraction capabilities and effectively curbing information loss during feature transfer. Subsequently, to further bolster the network’s efficiency in feature conduction, we introduced a linear bottleneck technique. This technique entails substituting the activation function in the network’s final layer from ReLU to linear activation. Such a modification preserves a greater extent of the original feature information, particularly within deep network structures, thus attenuating the potential for feature information loss attributable to nonlinear activation in low-dimensional outputs. Meanwhile, ReLU6 serves as the activation function in the other layers. As depicted in
Figure 6, the bottleneck residual block integrated into our model comprises several core components: depthwise convolution (Depthwise Conv), pointwise convolution (Pointwise Conv), and the linear and ReLU6 activation functions.
The process enhances the network’s performance and stability. Initially, data are introduced into the network, followed by a stage of point convolution employing a convolution kernel, where k dictates a multiplicative increase in the dimensionality of the middle layer within the bottleneck residual blocks to integrate input features. At this juncture, the ReLU6 activation function, a variation of the rectified linear unit (ReLU) that confines the output to a range between 0 and 6, is applied to introduce nonlinearity. Subsequently, a deep convolution operation, utilizing a convolutional kernel and a stride of 1, is executed independently on each input channel, aiming to extract features in the spatial dimension while continuing to utilize the ReLU6 activation function to augment the nonlinear characteristics of the features. Following this, point convolution with a convolution kernel, where C specifies the dimensionality of the output feature layer, is employed once more, with a linear activation function, indicating that the output will directly reflect the input features without undergoing a nonlinear transformation. The culmination of this process involves integrating the output of the preceding point convolution and the original input through an addition operation, a technique termed residual join. This technique is specifically designed to mitigate the issue of gradient vanishing that deep learning networks might encounter during training sessions, thereby enhancing the stability of the training process. Collectively, this process amalgamates feature fusion, deep spatial feature extraction, and other strategies to augment the stability of network training.
EEG signals exhibit distinct characteristics from images, particularly regarding spatial and frequency correlations. This distinctive feature renders the bottleneck residual block particularly advantageous for the efficient extraction of spatial frequency features following the attention module.
- (2)
Bottleneck residual module
The configurations of the bottleneck residual module exhibit minor variations in the architecture of both the generator and the discriminator; similarly, the bottleneck residual module includes eight bottleneck residual blocks and a two-branch structure, and the difference is that the bottleneck residual module in the discriminator has one more average pooling layer as well as one more fully-connected layer, as shown in
Figure 7. When dealing with low-resolution feature maps such as EEG signals, we especially notice that although CNNs tend to reduce the size and computation of feature maps and prevent overfitting through multiple pooling layers, too much pooling may lead to the loss of important spatial information. To overcome this obstacle, a strategy involving the utilization of a solitary pooling layer has been adopted. This approach not only preserves the spatial integrity of the information, but also contributes to a reduction in the parameter count.
In the discriminator, the bottleneck residual module operates as follows: the input feature tensor is processed through a bottleneck residual convolution kernel of size . Initially, the feature map’s channel count is expanded from 5 to 128. Following a series of operations, this number is halved and subsequently directed into a bifurcated structure comprising two branches. Each branch houses a distinct arrangement of bottleneck residual blocks—one with a single block and the other with two—to amalgamate information across various receptive fields. The outputs from both branches are then combined, and the channel count is further reduced to 32 through the application of two bottleneck residual blocks. Subsequently, the feature map’s dimensions are condensed to through a averaging pooling layer. This layer not only diminishes the likelihood of overfitting, but also bolsters the network’s resilience. The resultant data from the pooling stage undergo expansion before being introduced into a fully connected layer comprising 64 nodes. This process yields an outcome, designated as , which exists within the realm of . It succinctly encapsulates both the spatial and frequency characteristics inherent to the segmented EEG signals initially obtained. These attributes are subsequently processed through the Transformer framework to distill temporal characteristics, thereby augmenting the model’s proficiency in identifying EEG signal characteristics. In the generator, the channel count is diminished to 5 through the concluding two bottleneck residual blocks. The feature tensor, , processed by the attention module, serves as the input, culminating in the final output, , which represents the synthesized data produced by the generator.
2.1.5. Transformer
The architecture of the Transformer model is characterized by two principal elements: the multi-head self-attention mechanism and the feed-forward multilayer perceptron (MLP) segment, which employs a GELU as its activation function. To enhance the efficiency of the training process, a normalization layer is introduced between these two components. Furthermore, a dropout layer is incorporated subsequent to the output of each section to mitigate the risk of overfitting. Additionally, to maintain uninterrupted information flow and circumvent the challenges associated with vanishing or exploding gradients, a residual linking strategy is implemented within both segments. This approach is elucidated in
Figure 8.
In our study, the Transformer modules of the generator and the discriminator are slightly different in terms of where they process the data stream. Specifically, within the discriminator, the Transformer module is utilized to discern temporal dependencies across time segments within the 4D features. Following the extraction of frequency and spatial characteristics from the 4D characteristic stream using a bottleneck residual module, the Transformer module commences temporal characteristic extraction, thus obtaining a comprehensive characterization of the EEG data in the dimensions of frequency, space, and time in an integrated manner. Upon the completion of EEG feature extraction, the derived features are subsequently input into the classification head to facilitate the categorization of fatigue status. In the generator, the Transformer module receives as its input and produces the output , which subsequently serves as the input for the DeConv layer.
With the CA-ACGAN model, we are able to comprehensively extract the space, frequency and time characteristics of EEG data, which provides a powerful tool for fatigue detection.
2.2. Loss Function
In a CA-ACGAN, the loss functions employed by the generator
G and the discriminator
D incorporate category labeling, marking a substantial deviation from the loss functions utilized in traditional GANs. Specifically, see Equations (
2) and (
3):
The adversarial loss quantifies the divergence between data synthesized by the generator and real data. Throughout the course of model training, the objective of generator G is to reduce the adversarial loss , whereas the discriminator D endeavors to maximize it. The classification loss, assesses the discrepancy between the model-generated predictions and the actual classifications. Hyperparameter is used to adjust the significance of the categorization loss in the total loss function by varying the value of , and the relative importance between the categorization loss and the adversarial loss can be adjusted. In this investigation, was set to 1, signifying that the classification loss was attributed equal importance as the adversarial loss.
This loss function was meticulously crafted to enable the CA-ACGAN to not only fabricate data of high fidelity, but also to guarantee the precision of the generated data in categorical terms, thereby enhancing the model’s efficacy in specific tasks.
- (1)
Adversarial Loss:
In our investigation, we implemented an enhanced variant of Wasserstein’s generative adversarial network (WGAN) loss function, as delineated in reference [
27]. The primary objective of the initial WGAN loss function centers on augmenting the fidelity of synthetically generated data by diminishing the Wasserstein distance between the distribution of the synthesized signals and that of the authentic signals. Nevertheless, the original WGAN necessitates the truncation of the discriminators’ weights during its execution, a requisite that could precipitate instability throughout the training regimen. To mitigate this issue, we introduced a gradient penalty term (GP), an innovative element within the loss function designed to penalize the magnitude of the gradient linked to the input and output of the discriminator, thereby ensuring a more stable training process.
The aforementioned loss function is formalized as in Equation (
4):
In this formulation, signifies the expected output of the discriminator when presented with the real data, x, with the discriminator’s objective being to maximize this value to enhance its capability in accurately identifying real data. depicts the anticipated outcome of the discriminator to the generator’s created data, which utilizes the noise vector z and the conditional variable c; here, the discriminator aims to minimize this value to effectively distinguish between generated and real data. The term denotes the coefficient of the gradient penalty, serving as a mechanism to regulate the strength of the gradient penalty, and was assigned a value of 10 within the scope of this study. The notation refers to a sample drawn from a hybrid distribution that combines the real data distribution with that of the generator. The expression represents the difference between the gradient paradigm of the discriminator at point and 1, which is used as a penalty term to guarantee the discriminator’s adherence to the 1-Lipschitz prerequisite, i.e., the gradient paradigm does not exceed 1.
- (2)
Classification Loss:
To augment the discriminator
D’s classification capability, an extra classification header was appended to it, and a corrective classification loss was incorporated during the discriminator and generator training phases. This specific classification loss aims to enhance the discriminator’s efficiency when processing genuine data signals. Within the context of the classification task, the cross-entropy loss function performs the role of a prevalent metric for gauging the divergence between the label distribution predicted by the model and the genuine label distribution. This loss function’s precise formulation is delineated as follows (Equation (
5)):
The symbol represents the categorical label associated with the real data signal. Through the minimization of this specified loss function, the discriminator is honed to precisely categorize the real signal x into its authentic category , thereby augmenting the model’s proficiency in accurately classifying real data.
In addition, the generator
G’s objective is to ensure that the signal it generates can be accurately classified into a given category
c by the discriminator. The adversarial loss expression is Equation (
6):
The expression depicts the negative logarithm of the probability that the discriminator accurately classifies the signal , generated by the generator, as belonging to category c, under the given condition c. Throughout the training process, the generator aims to minimize this loss value, thereby enhancing the conditional consistency of the data produced.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}