
New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived




Abstract
:1. Introduction
2. Literature Review
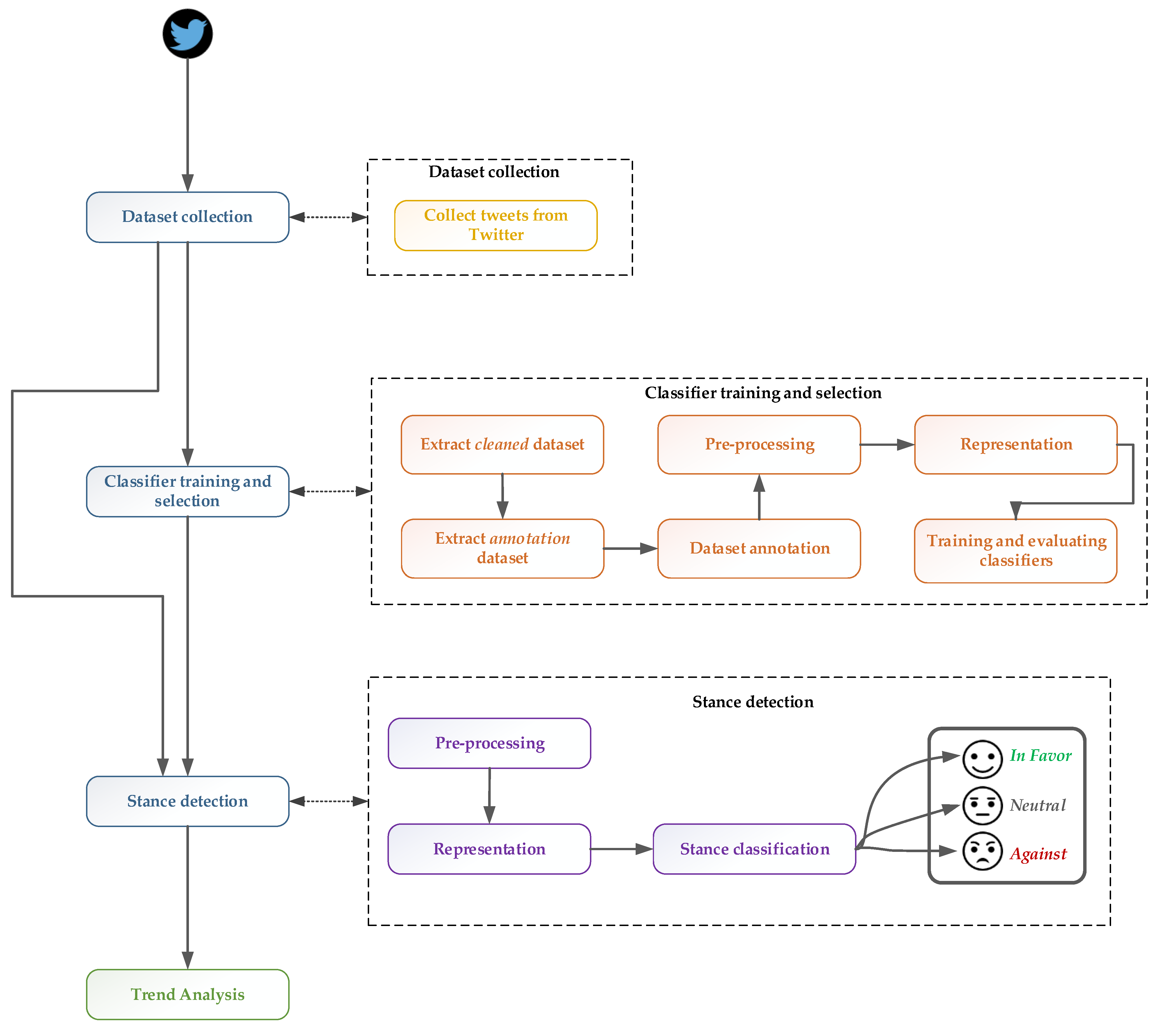
3. Methodology
3.1. COVID-19 Public Opinion
3.1.1. Dataset Collection
3.1.2. Classifier Training and Selection
3.1.3. Stance Detection
3.1.4. Trend Analysis
3.2. COVID-19 Vaccination Hesitancy Analysis through Hashtags, N-grams and Latent Dirichlet Allocation
3.2.1. Hashtag Analysis
3.2.2. N-gram Analysis
3.2.3. Latent Dirichlet Allocation
4. COVID-19 Vaccine Stance Dataset and Classification Performance
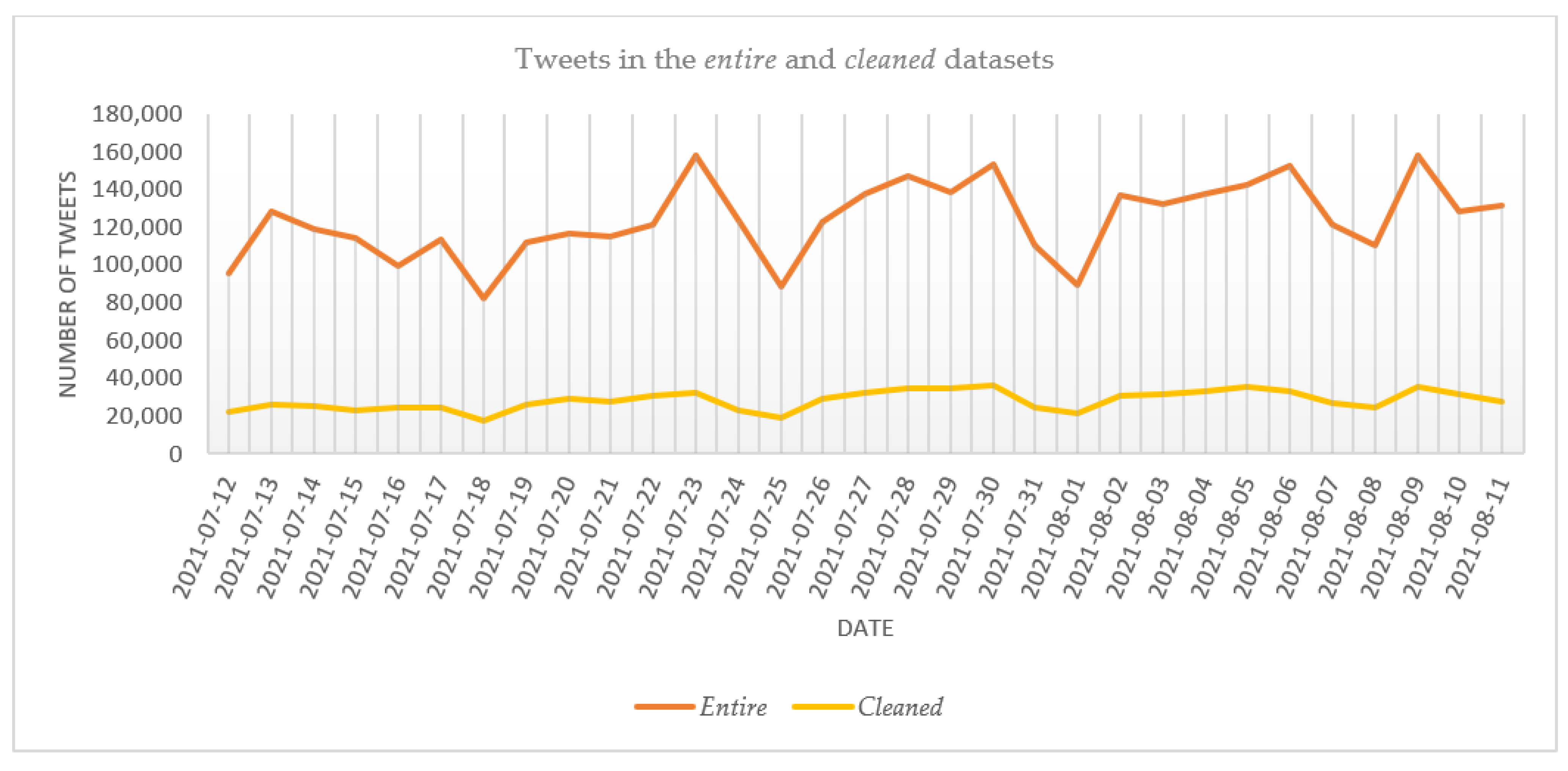
4.1. COVID-19 Vaccine Datasets
4.2. COVID-19 Vaccine Stance Dataset
4.3. COVID-19 Classifiers Performance
4.3.1. Classifiers’ Performance in Terms of Precision
4.3.2. Classifiers Performance in Terms of Recall
4.3.3. Classifiers Performance in Terms of F-Score
4.3.4. Classifiers’ Performance in Terms of Accuracy
4.3.5. Classifiers Performance in Terms of AUC
5. COVID-19 Vaccine Stance Detection
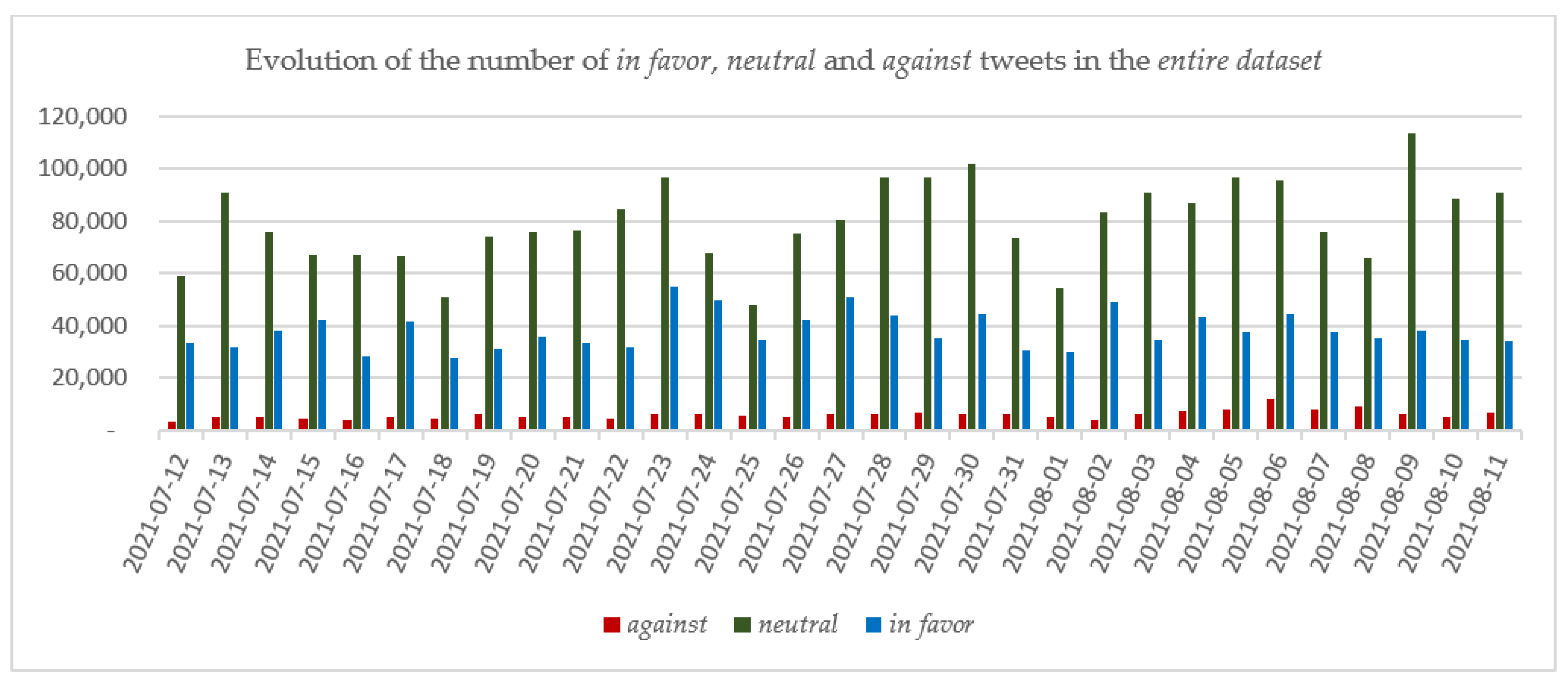
5.1. Stance Detection and Trend Analysis on the Entire Dataset
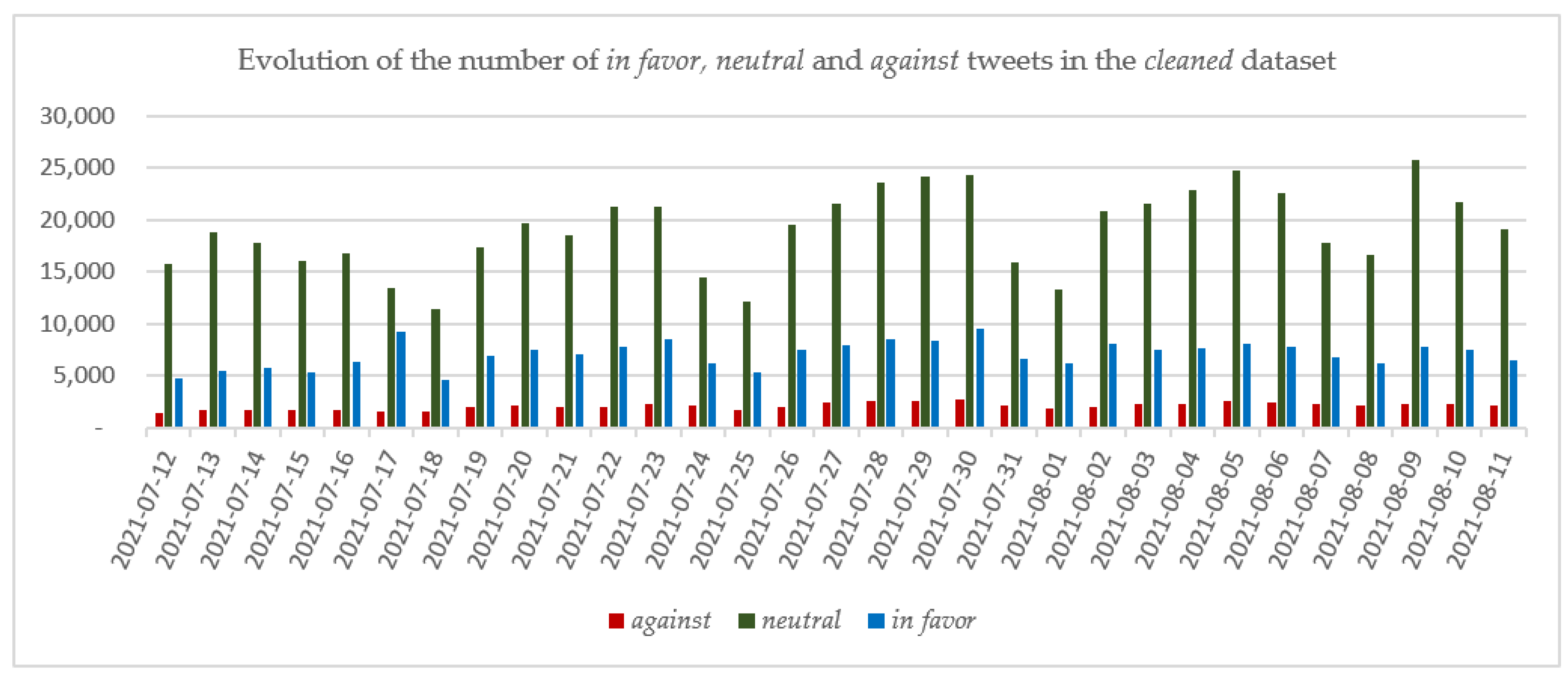
5.2. Stance Detection and Trend Analysis on the Cleaned Dataset
6. COVID-19 Vaccine Opinions Analysis
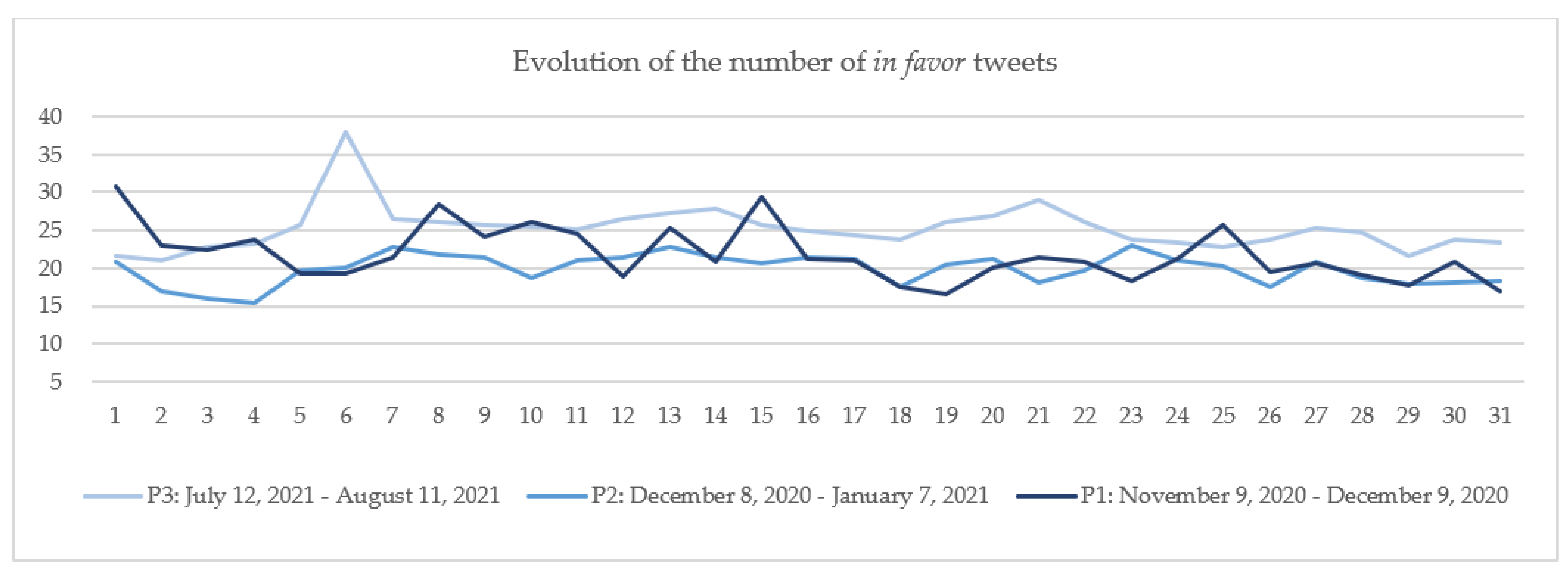
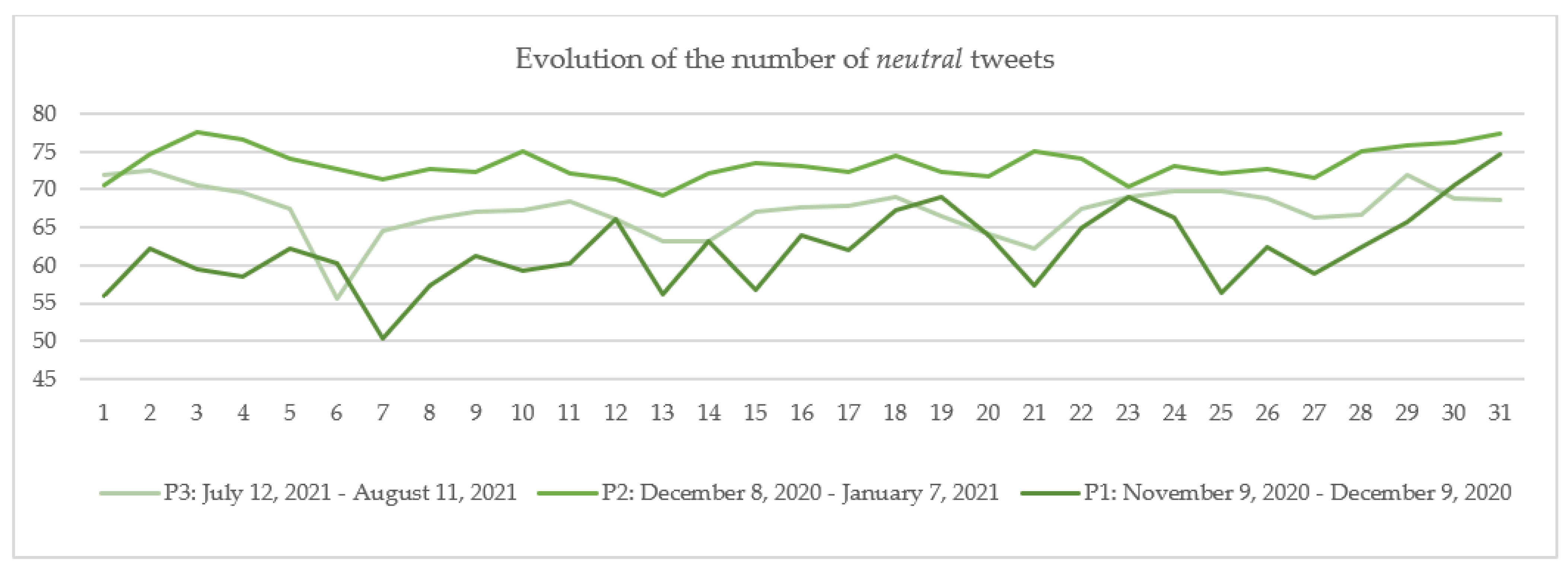
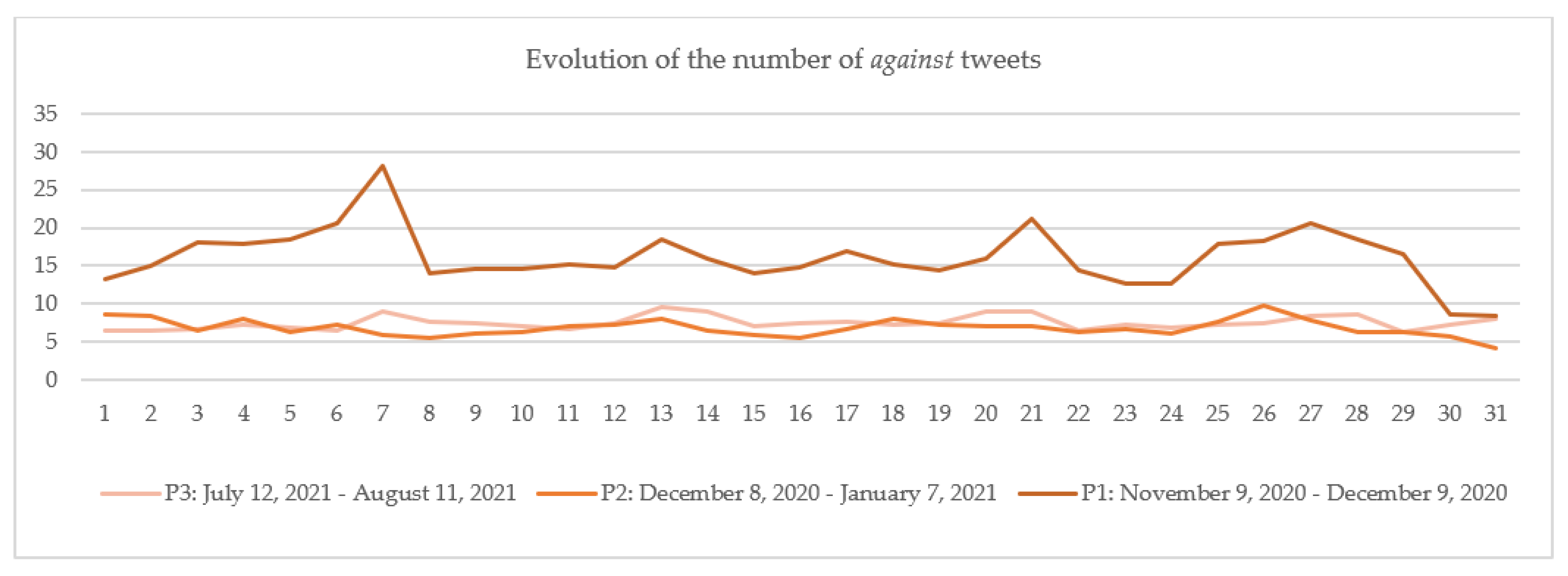
6.1. A Parallel with Other Periods
- 763,939 tweets between 9 November 2020–9 December 2020 (P1);
- 1,221,694 tweets between 8 December 2020–7 January 2021 (P2);
- 876,151 tweets between 12 July 2021–11 August 2021 (noted P3).
6.2. COVID-19 Hesitancy Analysis
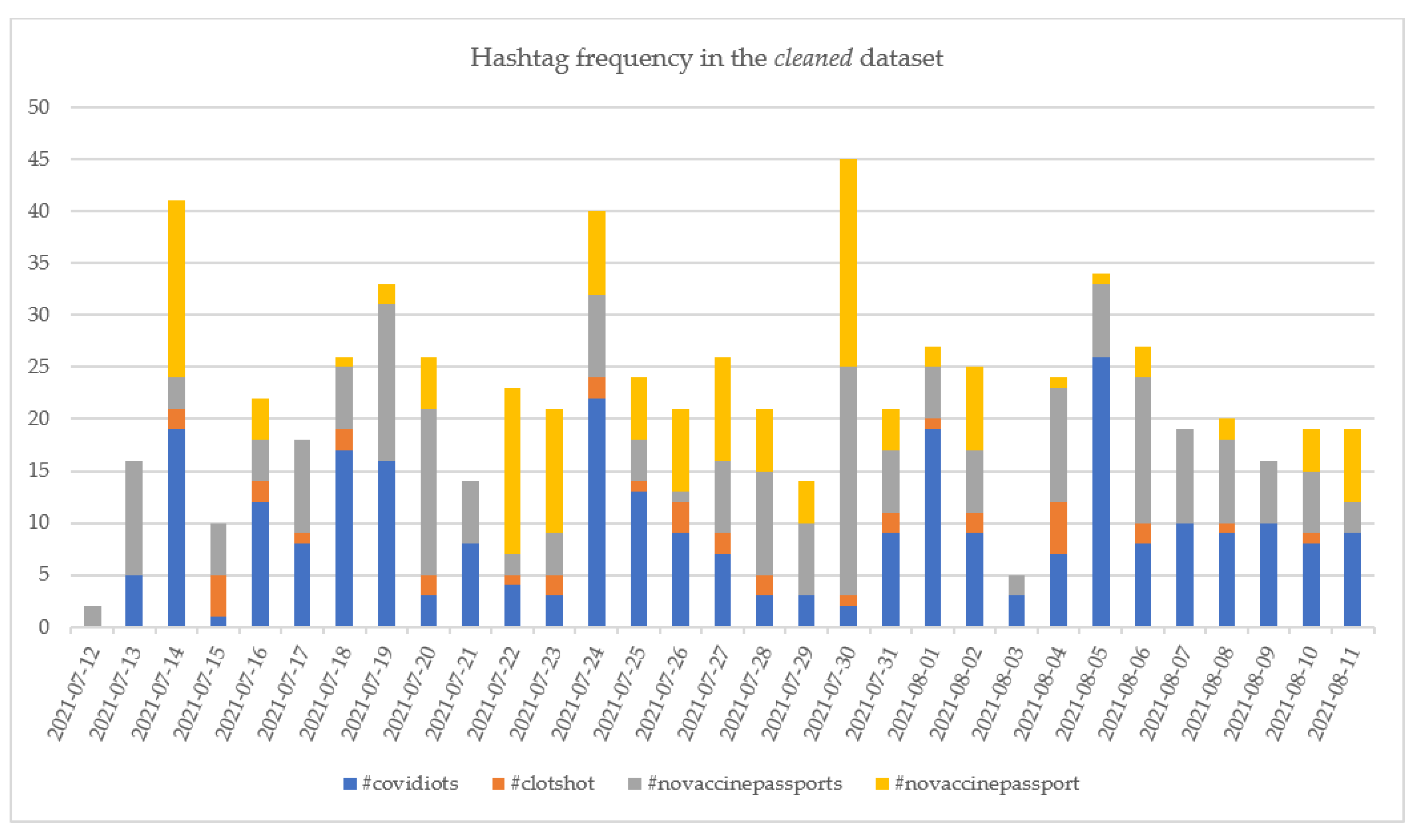
6.2.1. Hashtags Analysis
- Side effects, including death (e.g., “#NoVaccinePassports The MHRA has received 450 UK reports of suspected ADRs to the Pfizer vaccine in which the patient died shortly after vaccination, 960 reports for the AstraZeneca, 6 for the Moderna and 24 where the brand was unspecified. https://t.co/0OixzpqEUs”;
- Freedom (e.g., “Keep it voluntary. “Diversity and inclusion” starts here. #NoVaccinePassports https://t.co/UqicjOZnwb”; There are a lot of hypocrites on #MedTwitter and #MedEd who claim to be in favor of reducing inequalities, yet they support vaccine passports that are in complete defiance of WHO’s recommendations. Shame on you. #NoVaccinePassports https://t.co/8v3BiPOCWJ”).
6.2.2. N-Grams Analysis
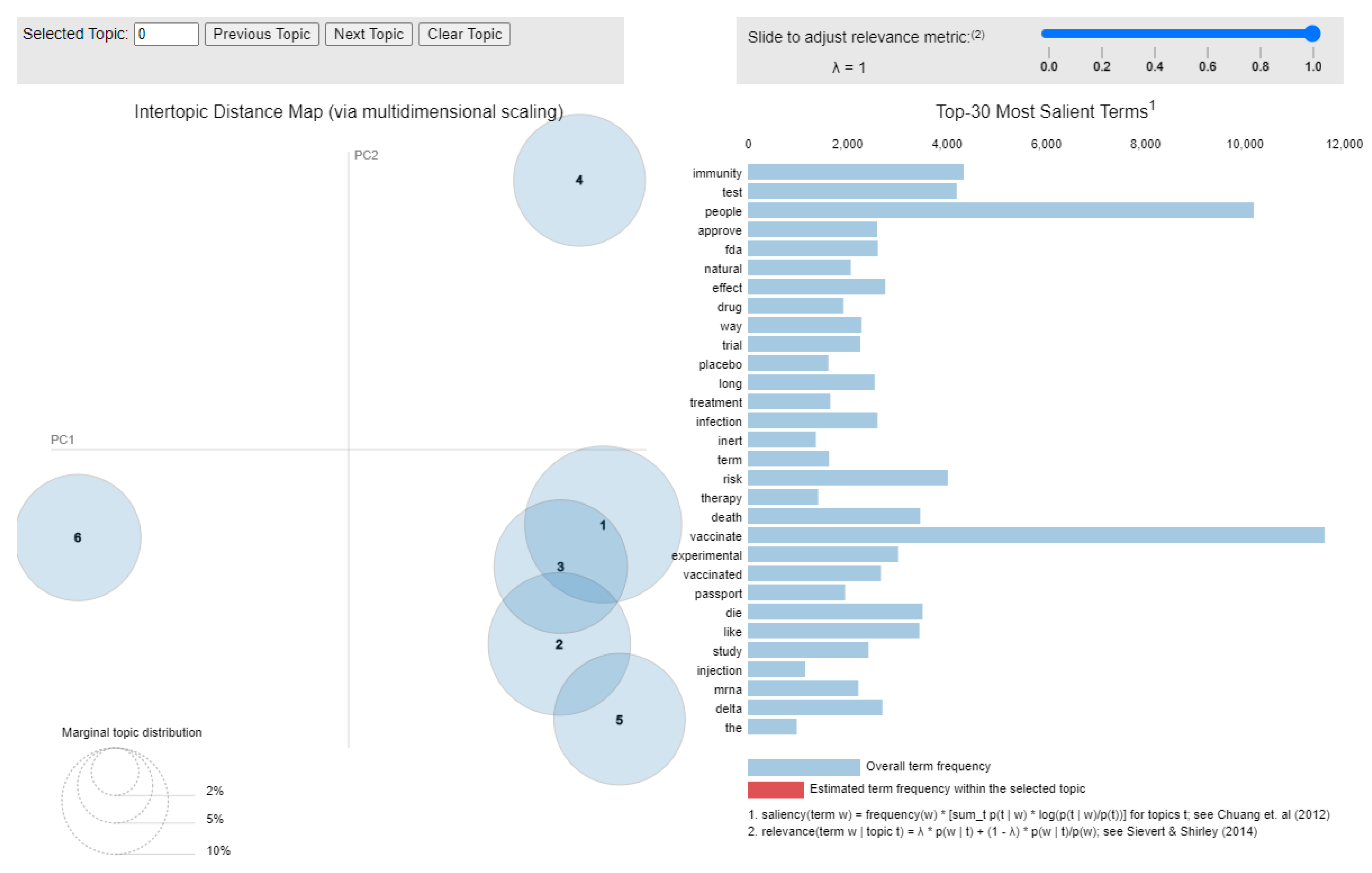
6.2.3. Latent Dirichlet Allocation
7. Discussions and Limitations
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- WHO Advice for Public. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/advice-for-public (accessed on 31 May 2020).
- Sanz-Muñoz, I.; Tamames-Gómez, S.; Castrodeza-Sanz, J.; Eiros-Bouza, J.M.; de Lejarazu-Leonardo, R.O. Social Distancing, Lockdown and the Wide Use of Mask; A Magic Solution or a Double-Edged Sword for Respiratory Viruses Epidemiology? Vaccines 2021, 9, 595. [Google Scholar] [CrossRef] [PubMed]
- Coco, M.; Guerrera, C.S.; Santisi, G.; Riggio, F.; Grasso, R.; Di Corrado, D.; Di Nuovo, S.; Ramaci, T. Psychosocial Impact and Role of Resilience on Healthcare Workers during COVID-19 Pandemic. Sustainability 2021, 13, 7096. [Google Scholar] [CrossRef]
- Babicki, M.; Mastalerz-Migas, A. Attitudes of Poles towards the COVID-19 Vaccine Booster Dose: An Online Survey in Poland. Vaccines 2022, 10, 68. [Google Scholar] [CrossRef] [PubMed]
- Lopez Bernal, J.; Andrews, N.; Gower, C.; Gallagher, E.; Simmons, R.; Thelwall, S.; Stowe, J.; Tessier, E.; Groves, N.; Dabrera, G.; et al. Effectiveness of Covid-19 Vaccines against the B.1.617.2 (Delta) Variant. N. Engl. J. Med. 2021, 385, 585–594. [Google Scholar] [CrossRef]
- Payne, R.P.; Longet, S.; Austin, J.A.; Skelly, D.T.; Dejnirattisai, W.; Adele, S.; Meardon, N.; Faustini, S.; Al-Taei, S.; Moore, S.C.; et al. Immunogenicity of Standard and Extended Dosing Intervals of BNT162b2 MRNA Vaccine. Cell 2021, 184, 5699–5714.e11. [Google Scholar] [CrossRef]
- Bar-On, Y.M.; Goldberg, Y.; Mandel, M.; Bodenheimer, O.; Freedman, L.; Kalkstein, N.; Mizrahi, B.; Alroy-Preis, S.; Ash, N.; Milo, R.; et al. Protection of BNT162b2 Vaccine Booster against Covid-19 in Israel. N. Engl. J. Med. 2021, 385, 1393–1400. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- D’Andrea, E.; Ducange, P.; Bechini, A.; Renda, A.; Marcelloni, F. Monitoring the Public Opinion about the Vaccination Topic from Tweets Analysis. Expert Syst. Appl. 2019, 116, 209–226. [Google Scholar] [CrossRef]
- Giachanou, A.; Crestani, F. Like It or Not: A Survey of Twitter Sentiment Analysis Methods. ACM Comput. Surv. 2016, 49, 1–41. [Google Scholar] [CrossRef]
- Tavoschi, L.; Quattrone, F.; D’Andrea, E.; Ducange, P.; Vabanesi, M.; Marcelloni, F.; Lopalco, P.L. Twitter as a Sentinel Tool to Monitor Public Opinion on Vaccination: An Opinion Mining Analysis from September 2016 to August 2017 in Italy. Hum. Vaccines Immunother. 2020, 16, 1062–1069. [Google Scholar] [CrossRef]
- Golbeck, J.; Grimes, J.M.; Rogers, A. Twitter Use by the U.S. Congress. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 1612–1621. [Google Scholar] [CrossRef]
- Cotfas, L.-A.; Delcea, C.; Roxin, I.; Ioanas, C.; Gherai, D.S.; Tajariol, F. The Longest Month: Analyzing COVID-19 Vaccination Opinions Dynamics From Tweets in the Month Following the First Vaccine Announcement. IEEE Access 2021, 9, 33203–33223. [Google Scholar] [CrossRef] [PubMed]
- Cotfas, L.-A.; Delcea, C.; Gherai, R. COVID-19 Vaccine Hesitancy in the Month Following the Start of the Vaccination Process. Int. J. Environ. Res. Public Health 2021, 18, 438. [Google Scholar] [CrossRef] [PubMed]
- Paul, E.; Steptoe, A.; Fancourt, D. Attitudes towards Vaccines and Intention to Vaccinate against COVID-19: Implications for Public Health Communications. Lancet Reg. Health-Eur. 2021, 1, 100012. [Google Scholar] [CrossRef] [PubMed]
- Bell, S.; Clarke, R.; Mounier-Jack, S.; Walker, J.L.; Paterson, P. Parents’ and Guardians’ Views on the Acceptability of a Future COVID-19 Vaccine: A Multi-Methods Study in England. Vaccine 2020, 38, 7789–7798. [Google Scholar] [CrossRef] [PubMed]
- Soares, P.; Rocha, J.V.; Moniz, M.; Gama, A.; Laires, P.A.; Pedro, A.R.; Dias, S.; Leite, A.; Nunes, C. Factors Associated with COVID-19 Vaccine Hesitancy. Vaccines 2021, 9, 300. [Google Scholar] [CrossRef] [PubMed]
- Karlsson, L.C.; Soveri, A.; Lewandowsky, S.; Karlsson, L.; Karlsson, H.; Nolvi, S.; Karukivi, M.; Lindfelt, M.; Antfolk, J. Fearing the Disease or the Vaccine: The Case of COVID-19. Personal. Individ. Differ. 2021, 172, 110590. [Google Scholar] [CrossRef]
- Biasio, L.R.; Bonaccorsi, G.; Lorini, C.; Mazzini, D.; Pecorelli, S. Italian Adults’ Likelihood of Getting COVID-19 Vaccine: A Second Online Survey. Vaccines 2021, 9, 268. [Google Scholar] [CrossRef]
- Di Giuseppe, G.; Pelullo, C.P.; Della Polla, G.; Pavia, M.; Angelillo, I.F. Exploring the Willingness to Accept SARS-CoV-2 Vaccine in a University Population in Southern Italy, September to November 2020. Vaccines 2021, 9, 275. [Google Scholar] [CrossRef]
- Caserotti, M.; Girardi, P.; Rubaltelli, E.; Tasso, A.; Lotto, L.; Gavaruzzi, T. Associations of COVID-19 Risk Perception with Vaccine Hesitancy over Time for Italian Residents. Soc. Sci. Med. 2021, 272, 113688. [Google Scholar] [CrossRef]
- Rapisarda, V.; Vella, F.; Ledda, C.; Barattucci, M.; Ramaci, T. What Prompts Doctors to Recommend COVID-19 Vaccines: Is It a Question of Positive Emotion? Vaccines 2021, 9, 578. [Google Scholar] [CrossRef] [PubMed]
- Detoc, M.; Bruel, S.; Frappe, P.; Tardy, B.; Botelho-Nevers, E.; Gagneux-Brunon, A. Intention to Participate in a COVID-19 Vaccine Clinical Trial and to Get Vaccinated against COVID-19 in France during the Pandemic. Vaccine 2020, 38, 7002–7006. [Google Scholar] [CrossRef] [PubMed]
- Salmon, D.A.; Dudley, M.Z.; Brewer, J.; Kan, L.; Gerber, J.E.; Budigan, H.; Proveaux, T.M.; Bernier, R.; Rimal, R.; Schwartz, B. COVID-19 Vaccination Attitudes, Values and Intentions among United States Adults Prior to Emergency Use Authorization. Vaccine 2021, 39, 2698–2711. [Google Scholar] [CrossRef] [PubMed]
- Vallée, A.; Fourn, E.; Majerholc, C.; Touche, P.; Zucman, D. COVID-19 Vaccine Hesitancy among French People Living with HIV. Vaccines 2021, 9, 302. [Google Scholar] [CrossRef]
- Petravić, L.; Arh, R.; Gabrovec, T.; Jazbec, L.; Rupčić, N.; Starešinič, N.; Zorman, L.; Pretnar, A.; Srakar, A.; Zwitter, M.; et al. Factors Affecting Attitudes towards COVID-19 Vaccination: An Online Survey in Slovenia. Vaccines 2021, 9, 247. [Google Scholar] [CrossRef]
- Malik, A.A.; McFadden, S.M.; Elharake, J.; Omer, S.B. Determinants of COVID-19 Vaccine Acceptance in the US. EClinicalMedicine 2020, 26, 100495. [Google Scholar] [CrossRef]
- Reiter, P.L.; Pennell, M.L.; Katz, M.L. Acceptability of a COVID-19 Vaccine among Adults in the United States: How Many People Would Get Vaccinated? Vaccine 2020, 38, 6500–6507. [Google Scholar] [CrossRef]
- Latkin, C.A.; Dayton, L.; Yi, G.; Konstantopoulos, A.; Boodram, B. Trust in a COVID-19 Vaccine in the U.S.: A Social-Ecological Perspective. Soc. Sci. Med. 2021, 270, 113684. [Google Scholar] [CrossRef]
- Benis, A.; Seidmann, A.; Ashkenazi, S. Reasons for Taking the COVID-19 Vaccine by US Social Media Users. Vaccines 2021, 9, 315. [Google Scholar] [CrossRef]
- Borriello, A.; Master, D.; Pellegrini, A.; Rose, J.M. Preferences for a COVID-19 Vaccine in Australia. Vaccine 2021, 39, 473–479. [Google Scholar] [CrossRef]
- Dodd, R.H.; Cvejic, E.; Bonner, C.; Pickles, K.; McCaffery, K.J.; Ayre, J.; Batcup, C.; Copp, T.; Cornell, S.; Dakin, T.; et al. Willingness to Vaccinate against COVID-19 in Australia. Lancet Infect. Dis. 2021, 21, 318–319. [Google Scholar] [CrossRef]
- Alley, S.J.; Stanton, R.; Browne, M.; To, Q.G.; Khalesi, S.; Williams, S.L.; Thwaite, T.L.; Fenning, A.S.; Vandelanotte, C. As the Pandemic Progresses, How Does Willingness to Vaccinate against COVID-19 Evolve? Int. J. Environ. Res. Public Health 2021, 18, 797. [Google Scholar] [CrossRef] [PubMed]
- Alfageeh, E.I.; Alshareef, N.; Angawi, K.; Alhazmi, F.; Chirwa, G.C. Acceptability of a COVID-19 Vaccine among the Saudi Population. Vaccines 2021, 9, 226. [Google Scholar] [CrossRef] [PubMed]
- Karami, A.; Zhu, M.; Goldschmidt, B.; Boyajieff, H.R.; Najafabadi, M.M. COVID-19 Vaccine and Social Media in the U.S.: Exploring Emotions and Discussions on Twitter. Vaccines 2021, 9, 1059. [Google Scholar] [CrossRef]
- Liu, S.; Liu, J. Public Attitudes toward COVID-19 Vaccines on English-Language Twitter: A Sentiment Analysis. Vaccine 2021, 39, 5499–5505. [Google Scholar] [CrossRef]
- Baj-Rogowska, A. Mapping of the Covid-19 Vaccine Uptake Determinants From Mining Twitter Data. IEEE Access 2021, 9, 134929–134944. [Google Scholar] [CrossRef]
- Martonosi, S.E.; Behzad, B.; Cummings, K. Pricing the COVID-19 Vaccine: A Mathematical Approach. Omega 2021, 103, 102451. [Google Scholar] [CrossRef]
- Ullah, I.; Khan, K.S.; Tahir, M.J.; Ahmed, A.; Harapan, H. Myths and conspiracy theories on vaccines and COVID-19: Potential effect on global vaccine refusals. Vacunas 2021, 22, 93–97. [Google Scholar] [CrossRef]
- Guidry, J.P.D.; Laestadius, L.I.; Vraga, E.K.; Miller, C.A.; Perrin, P.B.; Burton, C.W.; Ryan, M.; Fuemmeler, B.F.; Carlyle, K.E. Willingness to Get the COVID-19 Vaccine with and without Emergency Use Authorization. Am. J. Infect. Control 2021, 49, 137–142. [Google Scholar] [CrossRef]
- McPhedran, R.; Toombs, B. Efficacy or Delivery? An Online Discrete Choice Experiment to Explore Preferences for COVID-19 Vaccines in the UK. Econ. Lett. 2021, 200, 109747. [Google Scholar] [CrossRef]
- Yeh, Y.-C.; Chen, I.-H.; Ahorsu, D.K.; Ko, N.-Y.; Chen, K.-L.; Li, P.-C.; Yen, C.-F.; Lin, C.-Y.; Griffiths, M.D.; Pakpour, A.H. Measurement Invariance of the Drivers of COVID-19 Vaccination Acceptance Scale: Comparison between Taiwanese and Mainland Chinese-Speaking Populations. Vaccines 2021, 9, 297. [Google Scholar] [CrossRef]
- Alvarado-Socarras, J.L.; Vesga-Varela, A.L.; Quintero-Lesmes, D.C.; Fama-Pereira, M.M.; Serrano-Diaz, N.C.; Vasco, M.; Carballo-Zarate, V.; Zambrano, L.I.; Paniz-Mondolfi, A.; Rodriguez-Morales, A.J. Perception of COVID-19 Vaccination Amongst Physicians in Colombia. Vaccines 2021, 9, 287. [Google Scholar] [CrossRef] [PubMed]
- Nohl, A.; Afflerbach, C.; Lurz, C.; Brune, B.; Ohmann, T.; Weichert, V.; Zeiger, S.; Dudda, M. Acceptance of COVID-19 Vaccination among Front-Line Health Care Workers: A Nationwide Survey of Emergency Medical Services Personnel from Germany. Vaccines 2021, 9, 424. [Google Scholar] [CrossRef] [PubMed]
- Kwok, K.O.; Li, K.-K.; Wei, W.I.; Tang, A.; Wong, S.Y.S.; Lee, S.S. Influenza Vaccine Uptake, COVID-19 Vaccination Intention and Vaccine Hesitancy among Nurses: A Survey. Int. J. Nurs. Stud. 2021, 114, 103854. [Google Scholar] [CrossRef] [PubMed]
- Bălan, A.; Bejan, I.; Bonciu, S.; Eni, C.E.; Ruță, S. Romanian Medical Students’ Attitude towards and Perceived Knowledge on COVID-19 Vaccination. Vaccines 2021, 9, 854. [Google Scholar] [CrossRef]
- Harrison, J.; Berry, S.; Mor, V.; Gifford, D. “Somebody like Me”: Understanding COVID-19 Vaccine Hesitancy among Staff in Skilled Nursing Facilities. J. Am. Med. Dir. Assoc. 2021, 22, 1133–1137. [Google Scholar] [CrossRef]
- Kuter, B.J.; Browne, S.; Momplaisir, F.M.; Feemster, K.A.; Shen, A.K.; Green-McKenzie, J.; Faig, W.; Offit, P.A. Perspectives on the Receipt of a COVID-19 Vaccine: A Survey of Employees in Two Large Hospitals in Philadelphia. Vaccine 2021, 39, 1693–1700. [Google Scholar] [CrossRef]
- Kelekar, A.K.; Lucia, V.C.; Afonso, N.M.; Mascarenhas, A.K. COVID-19 Vaccine Acceptance and Hesitancy Among Dental and Medical Students. J. Am. Dent. Assoc. 2021, 152, 596–603. [Google Scholar] [CrossRef]
- Rossman, H.; Shilo, S.; Meir, T.; Gorfine, M.; Shalit, U.; Segal, E. COVID-19 Dynamics after a National Immunization Program in Israel. Nat. Med. 2021, 27, 1055–1061. [Google Scholar] [CrossRef]
- Dzinamarira, T.; Nachipo, B.; Phiri, B.; Musuka, G. COVID-19 Vaccine Roll-Out in South Africa and Zimbabwe: Urgent Need to Address Community Preparedness, Fears and Hesitancy. Vaccines 2021, 9, 250. [Google Scholar] [CrossRef]
- Troiano, G.; Nardi, A. Vaccine Hesitancy in the Era of COVID-19. Public Health 2021, 194, 245–251. [Google Scholar] [CrossRef] [PubMed]
- Praveen, S.; Ittamalla, R.; Deepak, G. Analyzing the Attitude of Indian Citizens towards COVID-19 Vaccine—A Text Analytics Study. Diabetes Metab. Syndr. Clin. Res. Rev. 2021, 15, 595–599. [Google Scholar] [CrossRef] [PubMed]
- Raghupathi, V.; Ren, J.; Raghupathi, W. Studying Public Perception about Vaccination: A Sentiment Analysis of Tweets. Int. J. Environ. Res. Public Health 2020, 17, 3464. [Google Scholar] [CrossRef]
- Ortiz-Sánchez, E.; Velando-Soriano, A.; Pradas-Hernández, L.; Vargas-Román, K.; Gómez-Urquiza, J.L.; Cañadas-De la Fuente, G.A.; Albendín-García, L. Analysis of the Anti-Vaccine Movement in Social Networks: A Systematic Review. Int. J. Environ. Res. Public Health 2020, 17, 5394. [Google Scholar] [CrossRef] [PubMed]
- Aloufi, S.; Saddik, A.E. Sentiment Identification in Football-Specific Tweets. IEEE Access 2018, 6, 78609–78621. [Google Scholar] [CrossRef]
- Baziotis, C.; Pelekis, N.; Doulkeridis, C. DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-Level and Topic-Based Sentiment Analysis. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017); Association for Computational Linguistics, Vancouver, WA, Canada, 3–4 August 2017; pp. 747–754. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit, 1st ed.; O’Reilly Media: Beijing, China, 2009; ISBN 978-0-596-51649-9. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Association for Computational Linguistics, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Zhang, M.-L.; Pena, J.M.; Robles, V. Feature Selection for Multi-Label Naive Bayes Classification. Inf. Sci. 2009, 179, 3218–3229. [Google Scholar] [CrossRef]
- McCallum, A.; Nigam, K. Others A Comparison of Event Models for Naive Bayes Text Classification. In Proceedings of the Proc. AAAI Workshop Learn. Text Categorization. Citeseer 1998, 752, 41–48. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Misra, S.; Li, H. Noninvasive Fracture Characterization Based on the Classification of Sonic Wave Travel Times. In Machine Learning for Subsurface Characterization; Misra, S., Li, H., He, J., Eds.; Gulf Professional Publishing: Houston, TX, USA, 2020; pp. 243–287. ISBN 978-0-12-817736-5. [Google Scholar]
- Platt, J.C. Fast Training of Support Vector Machines Using Sequential Minimal Optimization. In Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. ISBN 978-0-262-19416-7. [Google Scholar]
- Mohammadi, V.; Minaei, S. Artificial Intelligence in the Production Process. In Engineering Tools in the Beverage Industry; Grumezescu, A.M., Holban, A.M., Eds.; The Science of Beverages; Woodhead Publishing: Cambridge, UK, 2019; pp. 27–63. ISBN 978-0-12-815258-4. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, (Long and Short Papers). pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:190711692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Peng, F.C.; Schuurmans, D. Combining Naive Bayes and N-Gram Language Models for Text Classification. In Advances in Information Retrieval; Sebastiani, F., Ed.; Springer: Milano, Italy, 2003; Volume 2633, pp. 335–350. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Rehurek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the Lrec 2010 Workshop on New Challenges for Nlp Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization Techniques for Assessing Textual Topic Models. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21-25 May 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 74–77. [Google Scholar]
- Islam, M.R.; Liu, S.; Wang, X.; Xu, G. Deep Learning for Misinformation Detection on Online Social Networks: A Survey and New Perspectives. Soc. Netw. Anal. Min. 2020, 10, 82. [Google Scholar] [CrossRef] [PubMed]
- Shams, A.B.; Hoque Apu, E.; Rahman, A.; Sarker Raihan, M.M.; Siddika, N.; Preo, R.B.; Hussein, M.R.; Mostari, S.; Kabir, R. Web Search Engine Misinformation Notifier Extension (SEMiNExt): A Machine Learning Based Approach during COVID-19 Pandemic. Healthcare 2021, 9, 156. [Google Scholar] [CrossRef] [PubMed]
- Khadafi, R.; Nurmandi, A.; Qodir, Z. Misran Hashtag as a New Weapon to Resist the COVID-19 Vaccination Policy: A Qualitative Study of the Anti-Vaccine Movement in Brazil, USA, and Indonesia. Hum. Vaccines Immunother. 2019, 18, 2042135. [Google Scholar] [CrossRef]
- Küçükali, H.; Ataç, Ö.; Palteki, A.S.; Tokaç, A.Z.; Hayran, O.E. Vaccine Hesitancy and Anti-Vaccination Attitudes during the Start of COVID-19 Vaccination Program: A Content Analysis on Twitter Data; Public and Global Health: San Francisco, CA, USA, 2021. [Google Scholar]
- Herrera-Peco, I.; Jiménez-Gómez, B.; Romero Magdalena, C.S.; Deudero, J.J.; García-Puente, M.; Benítez De Gracia, E.; Ruiz Núñez, C. Antivaccine Movement and COVID-19 Negationism: A Content Analysis of Spanish-Written Messages on Twitter. Vaccines 2021, 9, 656. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Entire Dataset | Cleaned Dataset | Date | Entire Dataset | Cleaned Dataset | Date | Entire Dataset | Cleaned Dataset | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| July | 12 | 95,877 | 21,899 | July | 23 | 158,257 | 32,204 | August | 3 | 132,002 | 31,384 |
| 13 | 128,208 | 25,935 | 24 | 123,736 | 22,974 | 4 | 137,450 | 32,835 | |||
| 14 | 119,361 | 25,158 | 25 | 88,270 | 19,193 | 5 | 142,740 | 35,537 | |||
| 15 | 114,203 | 23,085 | 26 | 122,915 | 29,234 | 6 | 152,467 | 32,887 | |||
| 16 | 99,482 | 24,838 | 27 | 137,744 | 32,036 | 7 | 121,262 | 26,787 | |||
| 17 | 113,643 | 24,291 | 28 | 147,068 | 34,692 | 8 | 110,653 | 24,929 | |||
| 18 | 82,749 | 17,603 | 29 | 138,891 | 35,125 | 9 | 158,312 | 35,770 | |||
| 19 | 111,832 | 26,275 | 30 | 153,311 | 36,667 | 10 | 128,561 | 31,463 | |||
| 20 | 117,093 | 29,349 | 31 | 110,618 | 24,883 | 11 | 131,879 | 27,946 | |||
| 21 | 114,847 | 27,641 | August | 1 | 89,678 | 21,433 | TOTAL | 3,841,594 | 876,151 | ||
| 22 | 121,548 | 31,068 | 2 | 136,937 | 31,030 | ||||||
| Class | In Favor | Neutral | Against | TOTAL |
|---|---|---|---|---|
| Number | 1164 | 3127 | 345 | 4636 |
| Percentage | 25.11% | 67.45% | 7.44% | 100.00% |
| Stance | Tweet |
|---|---|
| in favor | @Shonib4u @Barbara56532914 @mmaltaisLA @USATODAY Not odd. Medical intervention has only been used for dangerously low oxygen levels. As has been pointed out, 98% of people who Covid-19 survive w/o medical treatment. I understand that 2% is small but chances of vaccine averse events is 0.00001% which is much, much less. |
| YES, it’s worse because of selfish people not willing to get Covid-19 vaccine. #GetVaccinated https://t.co/xqo72l6RAC | |
| Birth control pills have a higher risk of blood clots than the covid-19 vaccine. Go get the vaccine guys | |
| neutral | 💉🏫 The California State University system announced it will require students, faculty and staff on-campus this fall to be vaccinated against COVID-19. 🏫💉 https://t.co/y6YA2pgpaN |
| Stanford University reported at least seven confirmed cases of COVID-19 among fully vaccinated students this week. https://t.co/9R906AQEmU | |
| United Airlines will require U.S. employees to be vaccinated against COVID-19, joining a growing list of corporations responding to a surge in virus cases. https://t.co/iPjv1UK85o | |
| against | More and more story’s like this are being exposed. These injections are pure poison. Autopsy on Dead Body of COVID-19 Vaccinated Individual Reveals Spike Proteins in Every Organ—https://t.co/VSl5l7zXew |
| Arrest me if the covid 19 vaccine becomes mandatory because i refuse to inject an aborted fetus into my body, and not know what my future holds. If i have covid i wont be getting tested i refuse to inhale ethylene oxide. do your research or be sheep 🐑👌 | |
| One shot, two shots, three shots… FIVE SHOTS!!! The more shots you take, the more infected you get ! The more infected you get, the more doctors get the HOTS!!! https://t.co/cxTSnjfOqe |
| Code | Classifier | Parameters | Class | ||
|---|---|---|---|---|---|
| In Favor | Neutral | Against | |||
| ML1 | MNB | n-gram: (1, 2), features: 3000 | 68.62% | 75.50% | 68.08% |
| ML2 | n-gram: (1, 3), features: 3000 | 67.47% | 73.55% | 67.29% | |
| ML3 | RF | n-gram: (1, 2), features: all | 69.74% | 68.72% | 65.63% |
| ML4 | n-gram: (1, 3), features: 3000 | 68.86% | 69.60% | 65.48% | |
| ML5 | SVM | n-gram: (1, 2), features: all | 69.52% | 77.21% | 72.50% |
| ML6 | n-gram: (1, 3), features: 3000 | 67.60% | 72.93% | 71.87% | |
| DL1 | BERT | cased: no | 73.58% | 82.71% | 77.90% |
| DL2 | cased: yes | 72.77% | 79.35% | 76.80% | |
| DL3 | RoBERTa | 75.65% | 86.62% | 78.89% | |
| DL4 | ALBERT | 70.71% | 83.45% | 73.12% | |
| Code | Classifier | Parameters | Class | ||
|---|---|---|---|---|---|
| In Favor | Neutral | Against | |||
| ML1 | MNB | n-gram: (1, 2), features: 3000 | 62.39% | 69.20% | 79.74% |
| ML2 | n-gram: (1, 3), features: 3000 | 59.65% | 69.59% | 78.57% | |
| ML3 | RF | n-gram: (1, 2), features: all | 53.40% | 73.38% | 76.28% |
| ML4 | n-gram: (1, 3), features: 3000 | 55.69% | 71.93% | 75.67% | |
| ML5 | SVM | n-gram: (1, 2), features: all | 67.92% | 73.60% | 77.17% |
| ML6 | n-gram: (1, 3), features: 3000 | 64.90% | 74.05% | 73.27% | |
| DL1 | BERT | cased: no | 77.58% | 75.90% | 79.45% |
| DL2 | cased: yes | 74.16% | 76.61% | 77.42% | |
| DL3 | RoBERTa | 81.16% | 75.84% | 82.66% | |
| DL4 | ALBERT | 74.34% | 73.16% | 77.67% | |
| Code | Classifier | Parameters | Class | ||
|---|---|---|---|---|---|
| In Favor | Neutral | Against | |||
| ML1 | MNB | n-gram: (1, 2), features: 3000 | 65.31 | 72.13 | 73.39 |
| ML2 | n-gram: (1, 3), features: 3000 | 63.28 | 71.46 | 72.44 | |
| ML3 | RF | n-gram: (1, 2), features: all | 60.30 | 70.85 | 70.46 |
| ML4 | n-gram: (1, 3), features: 3000 | 61.49 | 70.57 | 70.05 | |
| ML5 | SVM | n-gram: (1, 2), features: all | 68.61 | 75.29 | 74.59 |
| ML6 | n-gram: (1, 3), features: 3000 | 66.11 | 73.45 | 72.40 | |
| DL1 | BERT | cased: no | 75.43 | 79.01 | 78.35 |
| DL2 | cased: yes | 73.32 | 77.81 | 76.98 | |
| DL3 | RoBERTa | 78.26 | 80.69 | 80.68 | |
| DL4 | ALBERT | 72.30 | 77.74 | 75.07 | |
| Code | Classifier | Parameters | Accuracy |
|---|---|---|---|
| ML1 | MNB | n-gram: (1, 2), features: 3000 | 70.44% |
| ML2 | n-gram: (1, 3), features: 3000 | 69.27% | |
| ML3 | RF | n-gram: (1, 2), features: all | 67.68% |
| ML4 | n-gram: (1, 3), features: 3000 | 67.76% | |
| ML5 | SVM | n-gram: (1, 2), features: all | 72.89% |
| ML6 | n-gram: (1, 3), features: 3000 | 70.73% | |
| DL1 | BERT | cased: no | 77.63% |
| DL2 | cased: yes | 76.07% | |
| DL3 | RoBERTa | 79.93% | |
| DL4 | ALBERT | 75.05% |
| Code | Classifier | Parameters | AUC |
|---|---|---|---|
| ML1 | MNB | n-gram: (1, 2), features: 3000 | 86.83% |
| ML2 | n-gram: (1, 3), features: 3000 | 86.21% | |
| ML3 | RF | n-gram: (1, 2), features: all | 85.19% |
| ML4 | n-gram: (1, 3), features: 3000 | 84.50% | |
| ML5 | SVM | n-gram: (1, 2), features: all | 87.67% |
| ML6 | n-gram: (1, 3), features: 3000 | 83.48% | |
| DL1 | BERT | cased: no | 92.07% |
| DL2 | cased: yes | 91.17% | |
| DL3 | RoBERTa | 93.48% | |
| DL4 | ALBERT | 90.45% |
| Hashtag | Occurrences |
|---|---|
| #pcrscam | 202 |
| #casedemic | 210 |
| #huntdownmonsters | 177 |
| #folksriseup | 230 |
| Cleaned Dataset | Entire Dataset | ||
|---|---|---|---|
| #covidiots | 282 | #novaccinepassports | 4058 |
| #novaccinepassports | 225 | #novaccinepassport | 2198 |
| #clotshot | 194 | #covidiots | 433 |
| #novaccinepassport | 151 | #enoughisenough | 392 |
| Unigrams | Number of Appearances |
|---|---|
| immunity | 4271 |
| risk | 3161 |
| experimental | 2907 |
| delta | 2898 |
| fda | 2704 |
| effective | 2500 |
| effects | 2214 |
| approved | 2207 |
| disease | 2103 |
| deaths | 2060 |
| flu | 1913 |
| death | 1767 |
| placebo | 1500 |
| die | 1341 |
| dangerous | 1180 |
| Bigrams | Number of Appearances |
|---|---|
| fully vaccinated | 2033 |
| natural immunity | 1499 |
| delta variant | 1487 |
| side effects | 1356 |
| long term | 1223 |
| fda approved | 983 |
| vaccine passport | 954 |
| experimental vaccine | 835 |
| immune system | 769 |
| placebo vaccine | 716 |
| big pharma | 712 |
| vaccine passports | 659 |
| placebo substance | 670 |
| informed consent | 604 |
| herd immunity | 586 |
| Trigrams | Number of Appearances |
|---|---|
| placebo vaccine passport | 700 |
| placebo substance treatment | 670 |
| natural immunity vs | 515 |
| risk covid 19 | 467 |
| fully vaccinated people | 434 |
| fda approved vaccine | 380 |
| covid 19 delta | 369 |
| beast natural immunity | 349 |
| pfizer biontech covid | 347 |
| vaccines worsening clinical | 319 |
| trial subjects risk | 318 |
| consent disclosure vaccine | 316 |
| long term effects | 306 |
| let big pharma | 295 |
| vaccine recipients severe | 270 |
| Topic Extracted Using LDA | Keywords Included | Discussion Topic |
|---|---|---|
| Topic 1 | risk, trial, mandate, shot, virus, vaccinate, disease, health, dose, clinical | Side Effects |
| Topic 2 | immunity, vaccinate, way, natural, infection, study, mrna, effective, delta, big | Existence of Alternatives |
| Topic 3 | approve, fda, effect, long, drug, experimental, placebo, treatment, term, passport | Hiding Relevant Information |
| Topic 4 | people, vaccinate, virus, get, vaccinated, die, variant, work, mask, fully | Mistrust |
| Topic 5 | test, know, vaccinate, come, pandemic, stop, corona, pcr, positive, die | Scam |
| Topic 6 | death, like, force, cause, require, life, read, virus, say, rate | Side effects |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delcea, C.; Cotfas, L.-A.; Crăciun, L.; Molănescu, A.G. New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived. Vaccines 2022, 10, 881. https://doi.org/10.3390/vaccines10060881
Delcea C, Cotfas L-A, Crăciun L, Molănescu AG. New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived. Vaccines. 2022; 10(6):881. https://doi.org/10.3390/vaccines10060881
Chicago/Turabian StyleDelcea, Camelia, Liviu-Adrian Cotfas, Liliana Crăciun, and Anca Gabriela Molănescu. 2022. "New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived" Vaccines 10, no. 6: 881. https://doi.org/10.3390/vaccines10060881
APA StyleDelcea, C., Cotfas, L.-A., Crăciun, L., & Molănescu, A. G. (2022). New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived. Vaccines, 10(6), 881. https://doi.org/10.3390/vaccines10060881